ABEMAの多層キャッシュ機構をリアーキテクチャした話
サイバーエージェントのインターン生が、大規模サービス ABEMA の多層キャッシュ機構におけるロジック散在と責務混在を解消するためのリアーキテクチャとカプセル化手法について報告している。
キーポイント
多層キャッシュ構成の背景と課題
Pod スケール時にキャッシュが分散しヒット率が低下する問題を解決するため、in-memory から Valkey を介した「in-memory → Valkey → Bigtable」の多層構造へ移行したが、コード上のロジック散在という新たな課題が残っていた。
キャッシュロジックの共通化と抽象化
各エンティティごとに重複していた「in-memory → Valkey → DB」というアクセスパターンを共通化し、キャッシュ戦略の変更を容易にするためのカプセル化を行った。
データアクセス層の責務分離
クリーンアーキテクチャに基づき、本来はデータ取得のみを行うべきデータアクセス層に混在していたビジネスロジック(フィルタリング等)を分離し、レイヤ間の関心分離を実現した。
大規模トラフィックへの対応と学習
KEDA による自動スケーリング環境下で安定したサービス提供を実現する仕組みの理解を深め、マイクロサービスアーキテクチャの実践的な設計思想を体得した。
多層キャッシュの課題と解決
Pod 分散によるキャッシュヒット率低下を解消するため、in-memory と Valkey を共有する中間層を導入し、Bigtable への負荷を抑制しました。
コード構造の再設計と関心分離
散在していたキャッシュロジックを共通化するとともに、データアクセス層からビジネスロジックを分離し、各レイヤの責務を明確にしました。
Dark Canary による安全な検証
本番環境への影響を避けるため Dark Canary を活用し、キャッシュヒット/ミスやフォールバック挙動をログで確認してからリリースを行いました。
影響分析・編集コメントを表示
影響分析
本記事は、大規模トラフィックを捌くサービスにおけるキャッシュ戦略の実践的な課題と解決策を示しており、特にマイクロサービスアーキテクチャの保守性と拡張性を高めるための具体的なリファクタリング手法として参考価値が高いです。大規模システム開発に携わるエンジニアにとって、設計上の落とし穴(ロジック散在や責務混在)を回避するための重要な知見を提供しています。
編集コメント
大規模サービスのインフラ設計における「キャッシュの分散」問題と、コード品質を高めるための「責務分離」の重要性が具体的に描かれた実践的な技術記事です。
はじめに
はじめまして。東京電機大学大学院修士1年の佐藤聖璃です。
2026年4月の1ヶ月間、株式会社 AbemaTV の GrowthBackend チームに就業型インターンとして参加させていただきました。
本記事では、インターン期間中に取り組んだメインタスクである「多層キャッシュ機構のカプセル化と関心分離」について、設計の背景から本番リリースまでの流れを紹介します。
インターンに参加した目的
私はこれまで、サイバーエージェントの短期インターンシップに2回(GoCollege、UNIVERSE)参加しており、その中で「挑戦を歓迎する文化」に強く魅力を感じていました。今回の長期就業を通じて、その環境に身を置きながら、より深く現場のエンジニアリングに触れたいと考え応募しました。
技術面では、以下の2点を特に学びたいテーマとして挙げていました。
- 大規模トラフィックを捌く仕組みの理解:ABEMA という大規模サービスが、どのようにトラフィックを処理し、安定したサービス提供を実現しているのか
- マイクロサービスアーキテクチャ(Microservice Architecture)の解像度向上:実際のプロダクションコードを通してその設計思想を理解すること
取り組んだタスク : 多層キャッシュ機構のカプセル化と関心分離
コンテンツ情報を扱うマイクロサービスにおいて、キャッシュ層のリアーキテクチャに取り組みました。具体的には、散在していた多層キャッシュのロジックを共通化し、データアクセス層に混在していたビジネスロジックを分離するという内容です。
背景 : 多層キャッシュ構成の経緯
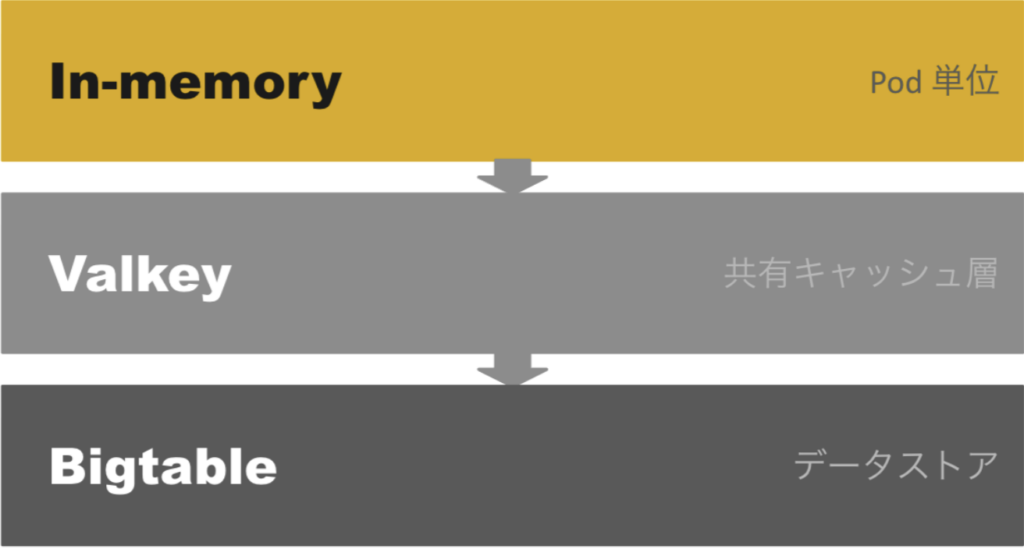
ABEMA のコンテンツ情報を扱うマイクロサービスでは、以下のような構成でデータを取得しています。
この構成に至るまでには、段階的な改善の経緯があります。
もともと、各サービスは Pod 単位の in-memory キャッシュのみを利用していました。Pod 内のメモリにキャッシュを持つことで高速にデータを返すことができますが、この方式にはスケール時の課題がありました。
ABEMAでは、KEDA(Kubernetes-based Event-Driven Autoscaler)による Pod スケール戦略を採用しています。トラフィックが増えるとPod 数が増加しますが、Pod ごとに独立した in-memory キャッシュを持つ構成では、Pod が増えれば増えるほどキャッシュが分散してしまい、それぞれの Pod で個別にキャッシュを温める必要が生じます。結果として、キャッシュヒット率が低下し、Bigtable へのリクエストも増えてしまうという問題がありました。
そこで、Pod 間で共有できる中間キャッシュ層として Valkey を導入し、現在の「 in-memory → Valkey → Bigtable 」という多層構成が実現されました。in-memory で高速なヒットを狙いつつ、ミスしても Valkey で吸収することで、Bigtable への負荷を抑える設計です。
課題 : キャッシュロジックの散在と責務の混在
このようにキャッシュ構成は洗練されてきた一方で、コードベース上ではいくつかの課題が残っていました。
1.同じパターンのキャッシュロジックが複数箇所に散在していた
コンテンツ情報には複数の種類があり、それぞれを扱うコードが存在します。しかし、どのコンテンツ情報でも「 in-memory を見て、ミスしたら Valkey を見て、それでもミスしたら Bigtable を参照する」という同じパターンが、各エンティティの実装の中に個別に書かれていました。そのため、キャッシュ戦略を変えたいときに、複数箇所を同様に修正する必要がありました。この共通パターンを抽象化し、一箇所にまとめたいというのが 1 つ目の課題です。
2.データアクセス層にビジネスロジックが混在していた
ABEMA の各マイクロサービスはクリーンアーキテクチャの考え方に基づいて実装されており、レイヤごとの責務が明確に定義されています。
タスクを設計する中でコードを読み進めるうちに、本来「 Bigtable からデータを取得すること」だけに責務を持つべきデータアクセス層に対して、取得結果のビジネス的なフィルタリング、キャッシュミス時のフォールバックの組み立てといった、本来上位レイヤが持つべき責務が混在していることに違和感を覚えました。これは、データアクセス層の単体テストが、キャッシュやビジネスルールに依存して書きにくくなるなどの問題に繋がります。
DB データアクセス・キャッシュ・ビジネスロジックの関心を分離したいというのが 2 つ目の課題です。
設計と実装 : 多層キャッシュ機構のカプセル化と関心分離
これらの課題に対するリアーキテクチャの方針を整理し、トレーナーさんに提案させていただいた上で、設計と実装を進める形で取り組みました。
関心分離後の構造を以下に示します。
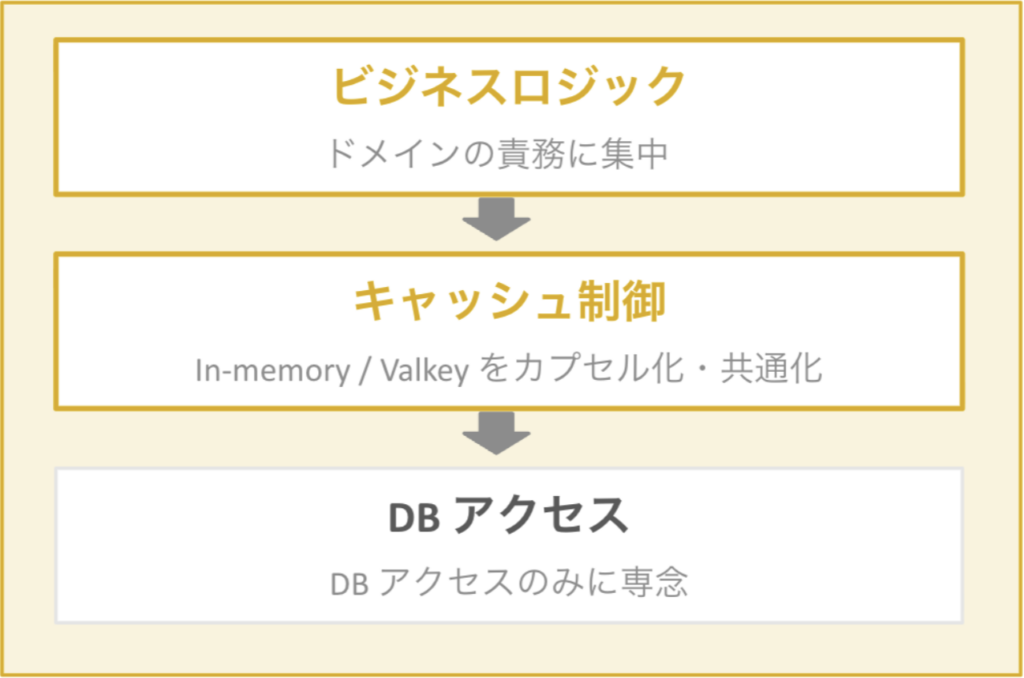
ポイントは、キャッシュ層 ( in-memory + Valkey ) は共通化できる一方で、Bigtable 層はエンティティごとに固有である設計にしたことです。
Bigtable へのアクセスは、エンティティごとに rowkey の設計、ReadRows のフィルタ条件、カラムファミリーの構成が異なります。そのため、ここを無理に共通化しようとすると逆に抽象化が破綻します。
共通化した部分はジェネリクス型として定義し、扱うエンティティの型に依存しない形で実装しました。また、それぞれの層が「何をするか」の責務を絞り込めたことで、コードの見通しが大きく改善されました。
検証 : Dark Canary による検証環境での確認
今回のリアーキテクチャは、コンテンツ情報の取得という影響範囲の大きい箇所に手を入れる変更でした。そのため、本番リリース前の動作確認を慎重に行う必要がありました。
ABEMA では、こうした検証のために Dark Canary という仕組みを利用しています。
Dark Canary の概要
Dark Canary は、本番と同じインフラ・設定のもとで稼働する検証環境に、検証用のリリースを行う仕組みです。通常のユーザーリクエストはこの環境には到達しないため、ユーザーには一切影響を与えずに、実際のインフラと設定の上で動作検証を行うことができます。
参考:https://developers.cyberagent.co.jp/blog/archives/60906/
検証環境では、以下のような観点でログを確認しながら、リアーキテクチャの正しさを検証しました。
- キャッシュヒット/ミスの挙動 : in-memory と Valkey のそれぞれで、期待した通りにヒット・ミスが記録されているか
- Bigtable へのフォールバック : キャッシュミス時に、想定通り Bigtable 層が呼ばれているか
これらをログで確認し、想定通りの挙動であることを検証したうえで、本番リリースに進みました。
結果
最終的に、対象としていた数種類のコンテンツ情報すべてについて、本番環境へのリリースを完了することができました。リアーキテクチャ後のコードベースは、各層の責務が明確になり、共通化したキャッシュ機構を通して、今後新しいコンテンツ情報を追加する際にも同じ仕組みを再利用できることを実現しました。
その他の活動
タスク以外の時間にも、たくさんの貴重な経験をさせていただきました。
- 1on1(エンジニア・ビジネス職の方々)
各チームの EM の方々をはじめ、さまざまな立場の方とお話しする機会をいただきました。「なりたい将来像に近づくために、具体的にどう動けばよいか」といった話まで踏み込んでアドバイスをいただけたことは、大きな財産になりました。
- ランチ
毎日出社し、渋谷のさまざまなお店に連れて行っていただきました。ランチの時間を通じて、業務では関わらない多くの社員の方々ともお話しできたのが嬉しかったです。
- テニス
勤務後に社員の方々と一緒にテニスをする機会もありました。業務外でも交流できる環境のあたたかさを感じました。
インターンを通じて得たもの
1.大規模トラフィックを捌く仕組みへの理解
目的の一つに掲げていた「大規模トラフィックを捌く仕組み」については、今回のタスクを通して学ぶことができました。多層キャッシュ構成( in-memory + Valkey + Bigtable )が、なぜ・どのように設計されているのか、その背景にある「 Pod 単位の in-memory ではキャッシュが分散してしまう」といった課題まで含めて、実際のコードと運用に紐づけて理解することができました。
また、自分のタスク以外でも、人気番組放送時の KEDA による Pod 単位のスケール戦略など、トラフィック対策の実装を現場のプロダクションコードを通して見ることができたのは大きな収穫でした。
2.マイクロサービスアーキテクチャへの解像度向上
もう一つの目的だった「マイクロサービスアーキテクチャの理解」についても、毎日の朝会やチームの MTG で関連するドメイン知識を吸収しながら、マイクロサービスが実際の本番環境でどう成立しているかの解像度を大きく上げることができました。
実際のコードと運用の中でどのように組み合わさって機能しているのかを、自分の目で確かめられたことは大きな学びでした。
3.違和感の言語化からリリースまでを自分で動かせた
コードを読んでいて感じた違和感を、設計上の課題として言語化し、提案→実装→検証→リリースまで一連の流れで動かすことができました。「なぜ問題なのか」「どう分離すべきか」を整理してトレーナーさんに提案し、本番リリースまで持っていくというプロセスを経験できたのは、技術的な学び以上に大きな財産になったと感じています。
おわりに
1 ヶ月という短い期間でしたが、ABEMA、そしてサイバーエージェントで働くイメージが、参加前よりもはっきりと、強く具体的なものになりました。活気あふれる現場の空気や、自分が持ち出した実装上の議題に対しても、実りある議論を一緒にしてくださった環境は、今回のインターンを通して特に印象に残ったポイントです。
今回学んだ技術的な知見と、現場で培われていたエンジニアリングへの向き合い方は、自分の中に持ち帰り、これからの開発にすぐに活かしていきたいと思います。
最後に、トレーナーさん、メンターさんをはじめ、関わってくださった全ての皆さんに心から感謝いたします。1 ヶ月間本当にありがとうございました!
原文を表示
はじめに
はじめまして。東京電機大学大学院修士1年の佐藤聖璃です。
2026年4月の1ヶ月間、株式会社 AbemaTV の GrowthBackend チームに就業型インターンとして参加させていただきました。
本記事では、インターン期間中に取り組んだメインタスクである「多層キャッシュ機構のカプセル化と関心分離」について、設計の背景から本番リリースまでの流れを紹介します。
インターンに参加した目的
私はこれまで、サイバーエージェントの短期インターンシップに2回(GoCollege、UNIVERSE)参加しており、その中で「挑戦を歓迎する文化」に強く魅力を感じていました。今回の長期就業を通じて、その環境に身を置きながら、より深く現場のエンジニアリングに触れたいと考え応募しました。
技術面では、以下の2点を特に学びたいテーマとして挙げていました。
- 大規模トラフィックを捌く仕組みの理解:ABEMA という大規模サービスが、どのようにトラフィックを処理し、安定したサービス提供を実現しているのか
- マイクロサービスアーキテクチャの解像度向上:実際のプロダクションコードを通してその設計思想を理解すること
取り組んだタスク : 多層キャッシュ機構のカプセル化と関心分離
コンテンツ情報を扱うマイクロサービスにおいて、キャッシュ層のリアーキテクチャに取り組みました。具体的には、散在していた多層キャッシュのロジックを共通化し、データアクセス層に混在していたビジネスロジックを分離するという内容です。
背景 : 多層キャッシュ構成の経緯
ABEMA のコンテンツ情報を扱うマイクロサービスでは、以下のような構成でデータを取得しています。
この構成に至るまでには、段階的な改善の経緯があります。
もともと、各サービスは Pod 単位の in-memory キャッシュのみを利用していました。Pod 内のメモリにキャッシュを持つことで高速にデータを返すことができますが、この方式にはスケール時の課題がありました。
ABEMAでは、KEDA による Pod スケール戦略を採用しています。トラフィックが増えるとPod 数が増加しますが、Pod ごとに独立した in-memory キャッシュを持つ構成では、Pod が増えれば増えるほどキャッシュが分散してしまい、それぞれの Pod で個別にキャッシュを温める必要が生じます。結果として、キャッシュヒット率が低下し、Bigtable へのリクエストも増えてしまうという問題がありました。
そこで、Pod 間で共有できる中間キャッシュ層として Valkey を導入し、現在の「 in-memory → Valkey → Bigtable 」という多層構成が実現されました。in-memory で高速なヒットを狙いつつ、ミスしても Valkey で吸収することで、Bigtable への負荷を抑える設計です。
課題 : キャッシュロジックの散在と責務の混在
このようにキャッシュ構成は洗練されてきた一方で、コードベース上ではいくつかの課題が残っていました。
1.同じパターンのキャッシュロジックが複数箇所に散在していた
コンテンツ情報には複数の種類があり、それぞれを扱うコードが存在します。しかし、どのコンテンツ情報でも「 in-memory を見て、ミスしたら Valkey を見て、それでもミスしたら Bigtable を参照する」という同じパターンが、各エンティティの実装の中に個別に書かれていました。そのため、キャッシュ戦略を変えたいときに、複数箇所を同様に修正する必要がありました。この共通パターンを抽象化し、一箇所にまとめたいというのが1つ目の課題です。
2.データアクセス層にビジネスロジックが混在していた
ABEMA の各マイクロサービスはクリーンアーキテクチャの考え方に基づいて実装されており、レイヤごとの責務が明確に定義されています。
タスクを設計する中でコードを読み進めるうちに、本来「 Bigtable からデータを取得すること」だけに責務を持つべきデータアクセス層に対して、取得結果のビジネス的なフィルタリング、キャッシュミス時のフォールバックの組み立てといった、本来上位レイヤが持つべき責務が混在していることに違和感を覚えました。これは、データアクセス層の単体テストが、キャッシュやビジネスルールに依存して書きにくくなるなどの問題に繋がります。
DB データアクセス・キャッシュ・ビジネスロジックの関心を分離したいというのが2つ目の課題です。
設計と実装 : 多層キャッシュ機構のカプセル化と関心分離
これらの課題に対するリアーキテクチャの方針を整理し、トレーナーさんに提案させていただいた上で、設計と実装を進める形で取り組みました。
関心分離後の構造を以下に示します。
ポイントは、キャッシュ層( in-memory + Valkey )は共通化できる一方で、Bigtable 層はエンティティごとに固有である設計にしたことです。
Bigtable へのアクセスは、エンティティごとに rowkey の設計、ReadRows のフィルタ条件、カラムファミリーの構成が異なります。そのため、ここを無理に共通化しようとすると逆に抽象化が破綻します。
共通化した部分はジェネリクス型として定義し、扱うエンティティの型に依存しない形で実装しました。また、それぞれの層が「何をするか」の責務を絞り込めたことで、コードの見通しが大きく改善されました。
検証 : Dark Canary による検証環境での確認
今回のリアーキテクチャは、コンテンツ情報の取得という影響範囲の大きい箇所に手を入れる変更でした。そのため、本番リリース前の動作確認を慎重に行う必要がありました。
ABEMA では、こうした検証のために Dark Canary という仕組みを利用しています。
Dark Canaryの概要
Dark Canary は、本番と同じインフラ・設定のもとで稼働する検証環境に、検証用のリリースを行う仕組みです。通常のユーザーリクエストはこの環境には到達しないため、ユーザーには一切影響を与えずに、実際のインフラと設定の上で動作検証を行うことができます。
参考:https://developers.cyberagent.co.jp/blog/archives/60906/
検証環境での確認内容
検証環境では、以下のような観点でログを確認しながら、リアーキテクチャの正しさを検証しました。
- キャッシュヒット/ミスの挙動 : in-memory と Valkey のそれぞれで、期待した通りにヒット・ミスが記録されているか
- Bigtableへのフォールバック : キャッシュミス時に、想定通り Bigtable 層が呼ばれているか
これらをログで確認し、想定通りの挙動であることを検証したうえで、本番リリースに進みました。
結果
最終的に、対象としていた数種類のコンテンツ情報すべてについて、本番環境へのリリースを完了することができました。リアーキテクチャ後のコードベースは、各層の責務が明確になり、共通化したキャッシュ機構を通して、今後新しいコンテンツ情報を追加する際にも同じ仕組みを再利用できることを実現しました。
その他の活動
タスク以外の時間にも、たくさんの貴重な経験をさせていただきました。
- 1on1(エンジニア・ビジネス職の方々)
各チームのEMの方々をはじめ、さまざまな立場の方とお話しする機会をいただきました。「なりたい将来像に近づくために、具体的にどう動けばよいか」といった話まで踏み込んでアドバイスをいただけたことは、大きな財産になりました。
- ランチ
毎日出社し、渋谷のさまざまなお店に連れて行っていただきました。ランチの時間を通じて、業務では関わらない多くの社員の方々ともお話しできたのが嬉しかったです。
- テニス
勤務後に社員の方々と一緒にテニスをする機会もありました。業務外でも交流できる環境のあたたかさを感じました。
インターンを通じて得たもの
1.大規模トラフィックを捌く仕組みへの理解
目的の一つに掲げていた「大規模トラフィックを捌く仕組み」については、今回のタスクを通して学ぶことができました。多層キャッシュ構成( in-memory + Valkey + Bigtable )が、なぜ・どのように設計されているのか、その背景にある「 Pod 単位の in-memory ではキャッシュが分散してしまう」といった課題まで含めて、実際のコードと運用に紐づけて理解することができました。
また、自分のタスク以外でも、人気番組放送時の KEDA による Pod 単位のスケール戦略など、トラフィック対策の実装を現場のプロダクションコードを通して見ることができたのは大きな収穫でした。
2.マイクロサービスアーキテクチャへの解像度向上
もう一つの目的だった「マイクロサービスアーキテクチャの理解」についても、毎日の朝会やチームの MTG で関連するドメイン知識を吸収しながら、マイクロサービスが実際の本番環境でどう成立しているかの解像度を大きく上げることができました。
実際のコードと運用の中でどのように組み合わさって機能しているのかを、自分の目で確かめられたことは大きな学びでした。
3.違和感の言語化からリリースまでを自分で動かせた
コードを読んでいて感じた違和感を、設計上の課題として言語化し、提案→実装→検証→リリースまで一連の流れで動かすことができました。「なぜ問題なのか」「どう分離すべきか」を整理してトレーナーさんに提案し、本番リリースまで持っていくというプロセスを経験できたのは、技術的な学び以上に大きな財産になったと感じています。
おわりに
1ヶ月という短い期間でしたが、ABEMA、そしてサイバーエージェントで働くイメージが、参加前よりもはっきりと、強く具体的なものになりました。活気あふれる現場の空気や、自分が持ち出した実装上の議題に対しても、実りある議論を一緒にしてくださった環境は、今回のインターンを通して特に印象に残ったポイントです。
今回学んだ技術的な知見と、現場で培われていたエンジニアリングへの向き合い方は、自分の中に持ち帰り、これからの開発にすぐに活かしていきたいと思います。
最後に、トレーナーさん、メンターさんをはじめ、関わってくださった全ての皆さんに心から感謝いたします。1ヶ月間本当にありがとうございました!
関連記事
メルペイのキャンペーン基盤をルールベース汎用システムへ再構築し、Otoku Revolution を実現したまでの話
メルカリのGrowth Platform Teamが、メルペイのポイント還元キャンペーン基盤「Santa」をルールベースの汎用システムに書き直し、大規模な機能刷新(Otoku Revolution)を実現した経緯について述べています。
セキュリティインサイトのスケーリング:グローバルスキャン能力を10倍に向上させた方法
クラウドフレアは、アカウントやDNSレコードのリスク検出頻度が低く、設定ミスが最大2週間放置される課題に対し、自動スキャンの仕組みを強化し、グローバルスキャン能力を10倍に増強した。
メルカリにおける独自ワークフローエンジンの設計と活用事例
メルペイのエンジニアが、分散システムでのデータ整合性課題に対し、内製したワークフローエンジンを用いた設計思想と実装事例を公開した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み