OpenSquilla がトークンコスト削減のためのオープンソース AI エージェントをリリース
OpenSquilla は、コンテキストの再利用とルーティング最適化によりトークン使用量を劇的に削減するオープンソース AI エージェントランタイムを公開した。
キーポイント
トークンコスト削減の実証データ
ローカルテストでは、279,762 トークンのうち約 80%(222,848 トークン)がキャッシュから提供され、セッション総コストはわずか 0.0094 ドルに抑えられた。
コンテキスト管理の革新
各呼び出しでコンテキストを再読み込みするのではなく、ターン間でコンテキストを再利用・保存することで、長期的なエージェント運用におけるコスト増を防ぐ。
多層的なルーティング戦略
単一の設定ではなく、メッセージ長などの手動信号と ML クラスファを組み合わせた協調的なスタックにより、クエリごとに最適な処理経路を決定する。
影響分析・編集コメントを表示
影響分析
このニュースは、AI エージェントの実装コストがボトルネックとなっている現状に対し、具体的な技術的解決策(キャッシュとルーティング)を提示した点で重要です。特にオープンソースかつ自己ホスト可能な形式であるため、大規模なトークン使用に悩む開発チームや企業にとって、即座に導入可能な実用価値が高いと言えます。
編集コメント
トークンコストの最適化は AI エージェントの実用化における最大の課題の一つであり、OpenSquilla のようなアプローチが業界標準となる可能性を秘めています。
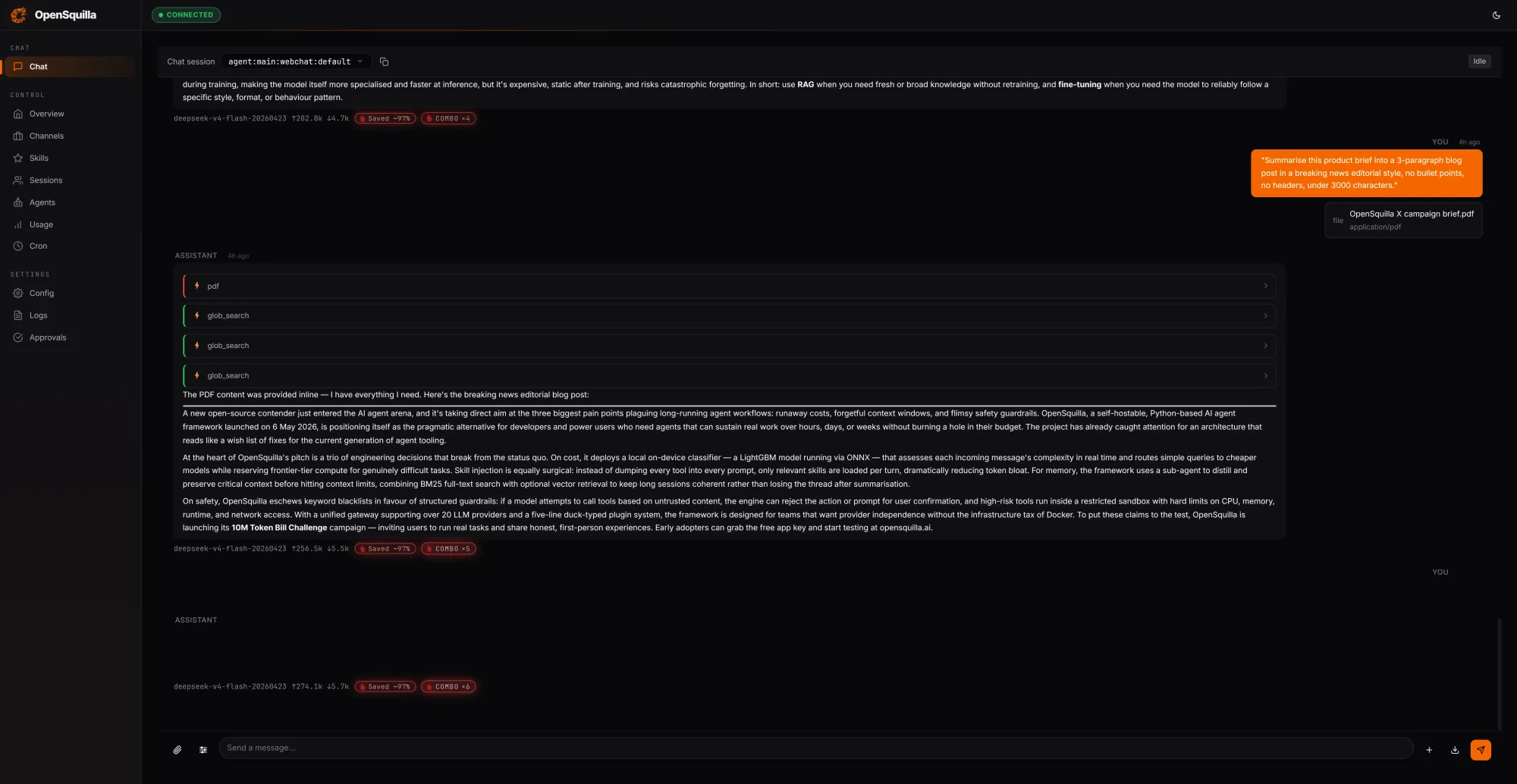
OpenSquilla は、最初の公開バージョンをリリースしました。これは「エージェントのデプロイメントの多くは、必要以上にトークンを消費しており、それを実行するフレームワークにはそれを防ぐ実効的な仕組みがない」という単一の前提に基づいて構築された、セルフホスト可能なオープンソース AI エージェントランタイムです。このプロジェクトは、セッション間でトークン請求が複利計算され、機能性よりもコンテキスト管理が運用上のボトルネックとなる、持続的で長期にわたるタスクのためにエージェントを実行する開発者やチームを対象としています。
ゲートウェイに対するローカルテスト実行では、単純な事実照会、中程度の複雑さを持つ技術要約、および AI エージェントフレームワークの完全な競合分析を扱う 3 つのプロンプトが処理され、合計で 279,762 トークン(セッション総コストは 0.0094 ドル)を消費しました。これらのトークンのうち 222,848 がキャッシュから提供され、入力トークンの約 80% を占めました。これは、OpenSquilla が各呼び出しで新規に読み込むのではなく、ターン間でコンテキストを再利用する結果です。ルーティング分類器はセッション全体を通じてアクティブであり、クエリごとにゲート決定をログ出力していました。セキュリティサンドボックス(security sandbox)は設計上 Windows では no-op モードで動作しますが、Linux 上の本番環境デプロイメントでは完全なシステムコールレベルの隔離が可能です。
さらに詳しく知る
ビジネス & 生産性ソフトウェア
AI ツール、チャットボット & バーチャルアシスタント
ソフトウェア
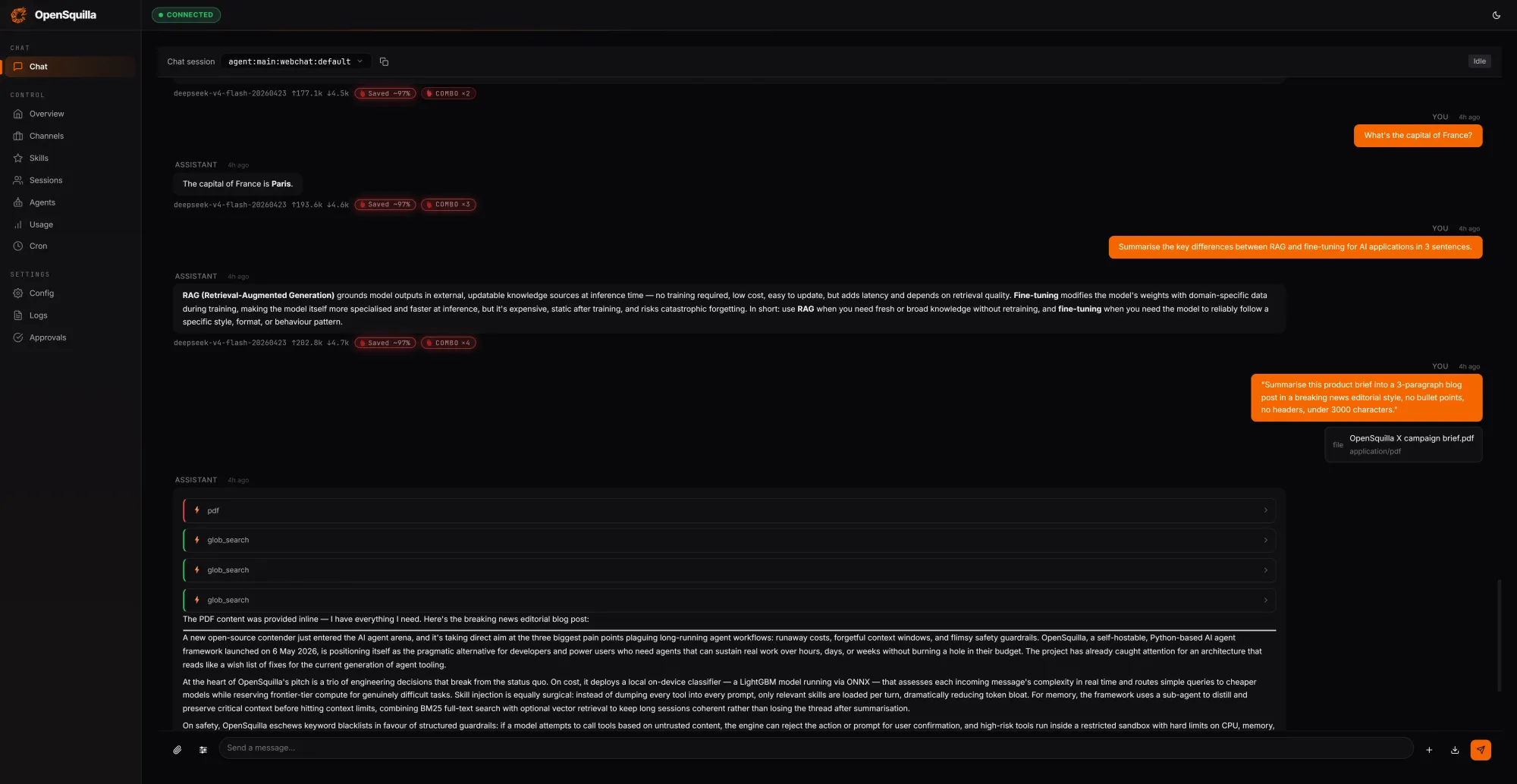
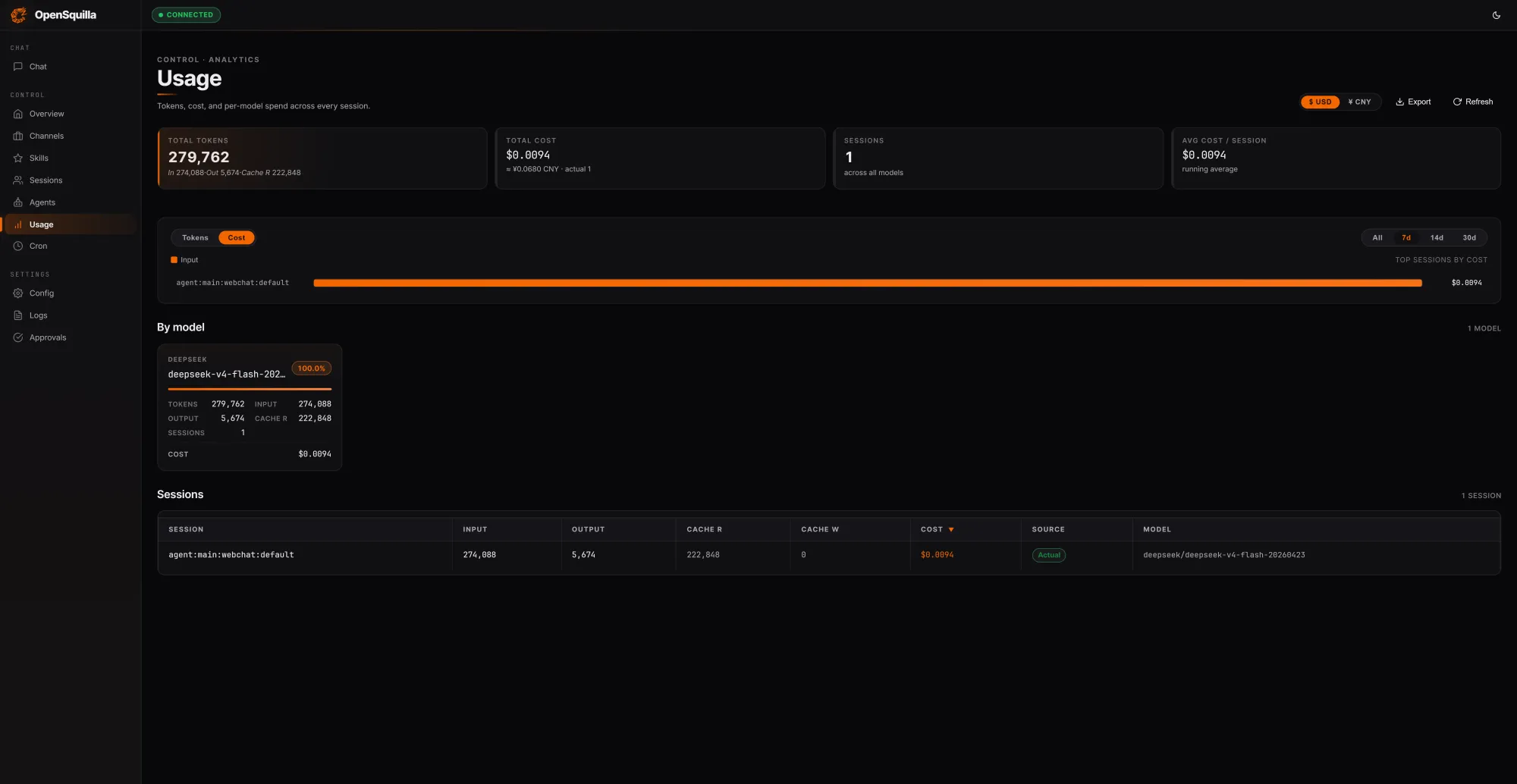 image OpenSquilla の使用状況タブにおけるコスト削減の根拠は、単一の調整ダイヤルではなく、ルーティング戦略を協調させたスタックにあります。機械学習(ML)分類器が、メッセージ長やコードブロックの有無、キーワードパターンといった手作業で設計されたシグナルと、埋め込みベースの意味特徴を組み合わせて、各 incoming リクエストの複雑さにスコアリングを行います。単純な問い合わせはより安価なモデルへルーティングされ、軽量タスクでは深い推論(deep reasoning)が無効化されるため、些細なプロンプトに対して拡張された思考連鎖(chain-of-thought)のための費用を支払う必要がありません。スキルはすべてのコンテキストウィンドウに一括して詰め込まれるのではなく、必要な時にオンデマンドで読み込まれます。OpenSquilla 自身のベンチマークによると、これらの戦略を組み合わせることで、フラットな単一モデル構成と比較してトークン使用料を 60〜80% 削減できます。クォータフック(quota hooks)と呼び出しごとのコスト追跡は最初から組み込まれており、過剰な支出を自動的に検知してスロットリングすることができます。
image OpenSquilla の使用状況タブにおけるコスト削減の根拠は、単一の調整ダイヤルではなく、ルーティング戦略を協調させたスタックにあります。機械学習(ML)分類器が、メッセージ長やコードブロックの有無、キーワードパターンといった手作業で設計されたシグナルと、埋め込みベースの意味特徴を組み合わせて、各 incoming リクエストの複雑さにスコアリングを行います。単純な問い合わせはより安価なモデルへルーティングされ、軽量タスクでは深い推論(deep reasoning)が無効化されるため、些細なプロンプトに対して拡張された思考連鎖(chain-of-thought)のための費用を支払う必要がありません。スキルはすべてのコンテキストウィンドウに一括して詰め込まれるのではなく、必要な時にオンデマンドで読み込まれます。OpenSquilla 自身のベンチマークによると、これらの戦略を組み合わせることで、フラットな単一モデル構成と比較してトークン使用料を 60〜80% 削減できます。クォータフック(quota hooks)と呼び出しごとのコスト追跡は最初から組み込まれており、過剰な支出を自動的に検知してスロットリングすることができます。
 image OpenSquilla の t1&t2 メモリ管理は、多くのエージェントフレームワークが近似するのではなく、人間の記憶構造をモデル化した 4 つの階層を持つ認知アーキテクチャを通じて行われます:
image OpenSquilla の t1&t2 メモリ管理は、多くのエージェントフレームワークが近似するのではなく、人間の記憶構造をモデル化した 4 つの階層を持つ認知アーキテクチャを通じて行われます:
- ワーキングメモリは現在のタスクを保持します。
- エピソード記憶は、セッションにわたる経験と因果関係を捉えます。
- 意味記憶は、永続的な事実やルールを保存します。
- 生データ(Raw memory)は監査と再トレーニングの基盤として機能します。
検索機能は、ベクトル・セマンティック検索と BM25 フルテキスト検索を並列で実行し、埋め込みベクトルはバンドルされた ONNX 推論(ONNX inference)によってローカルで処理されるため、外部プロバイダーを必要とせずデータをデバイス内に保持します。ホットメモリ昇格メカニズムにより、頻繁に参照される項目が自動的に前面に表示され、時間経過による減衰関数により、明示的に「不変(evergreen)」としてマークされない限り、古い記憶は徐々に薄れていきます。24 時間ごとに実行される統合処理によって、散在した記憶がより濃密で整理された知識へと再構築されます。このプロジェクトではこれを「メモリ・ドリーム・コンソリデーション」と呼び、人間の睡眠が記憶を定着させるプロセスとの類似性を強調しています。
 imageOpenSquilla t3On セキュリティについて、OpenSquilla は Docker をラップするのではなく、システムコール(syscall)レベルの分離を採用しています。ツールの実行方法を制御するポリシーは 3 つの階層で構成されています:
imageOpenSquilla t3On セキュリティについて、OpenSquilla は Docker をラップするのではなく、システムコール(syscall)レベルの分離を採用しています。ツールの実行方法を制御するポリシーは 3 つの階層で構成されています:
- 標準的な操作は直接実行されます。
- 厳格な操作にはサンドボックスの承認が必要です。
- ロックされた操作は、進行する前に人間のレビューを通過しなければなりません。
このサンドボックスは、コンテナランタイムへの依存なしに、Linux では Bubblewrap、macOS では Seatbelt を使用して、コードの実行を実際のファイルシステムから隔離します。拒否台帳(denial ledger)は、3 回の連続した拒否後にエージェントを一時停止し、制限されたアクションを押し通そうとするブルートフォース攻撃を防ぎます。プロンプトインジェクションのベクトルは、スキルメタデータとツール結果がモデルに到達する前に XML エスケープ処理を行うことで封じ込められます。
このアーキテクチャはマイクロカーネルとして記述されています:状態管理とパイプラインシーケンスを処理する約 100 行のコアオーケストレーターがあり、LLM プロバイダーやメモリバックエンドからチャネルアダプター、ツール統合に至るまでのすべての機能は、ユーザー空間でプラグイン可能なモジュールとして実行されます。プラグインの作成には、基底クラス、SDK パッケージ、またはマニフェストファイルを必要としない、5 行のダックタイピングされたクラスを書くだけで十分です。ゲートウェイは、Slack、Discord、Telegram、MS Teams、Matrix、およびいくつかのエンタープライズメッセージングプラットフォームを含む、10 以上の組み込みチャネルをサポートしています。
ランタイムは Apache-2.0 ライセンスの下で v0.1.0 として提供され、Python 3.12+ を必要とし、GitHub でセルフホスティングが可能です。チームはリリースに合わせて「10M トークンビルチャレンジ」を実施しており、現在のエージェントインフラストラクチャコストと比較してこのフレームワークをベンチマークしたい開発者に対して、無料のトークンクレジットを提供しています。
原文を表示
OpenSquilla has released its first public version, a self-hostable, open-source AI agent runtime built around a single premise: most agent deployments spend tokens they do not need to spend, and the frameworks running them offer no real mechanism to stop it. The project targets developers and teams running agents for sustained, long-horizon work, where token bills compound across sessions and context management becomes the operational ceiling before capability does.
In a local test run against the gateway, three prompts spanning a simple factual query, a medium-complexity technical summary, and a full competitive analysis of AI agent frameworks processed a combined 279,762 tokens for a total session cost of $0.0094. Of those tokens, 222,848 were served from cache, roughly 80% of all input tokens, a direct result of OpenSquilla reusing context across turns rather than reloading it fresh on every call. The routing classifier was active and logging gate decisions per query throughout the session. The security sandbox runs in a no-op mode on Windows by design, with full syscall-level isolation available in production deployments on Linux.
The cost case rests on a coordinated stack of routing strategies rather than a single dial. An ML classifier combines hand-crafted signals, including message length, presence of code blocks, and keyword patterns, with embedding-based semantic features to score each incoming request by complexity. Simple queries route to cheaper models. Deep reasoning is disabled for lightweight tasks, so teams are not paying for extended chain-of-thought on a trivial prompt. Skills load on demand rather than being packed wholesale into every context window. According to OpenSquilla's own benchmarks, the combined effect of these strategies cuts token spend by 60 to 80 percent compared to a flat, single-model configuration. Quota hooks and per-call cost tracking are built in from the start, so overspend can be caught and throttled automatically.
Memory is handled through a four-tier cognitive architecture modeled on how human memory is structured rather than how most agent frameworks approximate it:
- Working memory holds the current task.
- Episodic memory captures experience and causal relationships across sessions.
- Semantic memory stores persistent facts and rules.
- Raw memory functions as an audit and retraining base.
Retrieval combines vector-semantic search with BM25 full-text search, running in parallel, with embeddings processed locally via bundled ONNX inference, keeping data on-device without requiring an external provider. A hot memory promotion mechanism automatically surfaces frequently recalled items, while a temporal decay function lets dated memories fade unless explicitly marked as evergreen. Every 24 hours, a consolidation pass restructures scattered memories into denser, more organised knowledge. The project calls this Memory Dream Consolidation, drawing the parallel to how sleep consolidates human memory.
On security, OpenSquilla uses syscall-level isolation rather than wrapping Docker. Three policy tiers control how tools execute:
- Standard operations run directly.
- Strict operations require sandbox approval.
- Locked operations must pass human review before proceeding.
The sandbox uses Bubblewrap on Linux and Seatbelt on macOS to isolate code execution from the real filesystem, without a container runtime dependency. A denial ledger pauses the agent after three consecutive rejections, blocking brute-force attempts to push through restricted actions. Prompt injection vectors are closed by XML-escaping all skill metadata and tool results before they reach the model.
The architecture is described as a microkernel: a core orchestrator of roughly 100 lines that handles state management and pipeline sequencing, while every capability from LLM providers and memory backends to channel adapters and tool integrations runs as a pluggable module in user space. Writing a plugin requires a five-line duck-typed class with no base class, SDK package, or manifest file. The gateway serves over ten built-in channels, including Slack, Discord, Telegram, MS Teams, Matrix, and several enterprise messaging platforms. The runtime ships at v0.1.0 under Apache-2.0, requires Python 3.12+, and is available for self-hosting on GitHub. The team is running a 10M Token Bill Challenge alongside the release, offering free token credits for developers who want to benchmark the framework against their current agent infrastructure costs.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み