シークレットスキャンの信頼性向上:大規模な誤検知の削減
GitHub は Microsoft Security & AI のチームと協力し、LLM を活用した文脈推論機能を秘密スキャンに導入することで、偽陽性を大幅に削減し、開発者の信頼性と実効性を向上させました。
キーポイント
LLM を活用した文脈検証の導入
GitHub は Microsoft Security & AI の「Agentic Secret Finder」のアプローチを採用し、単なるパターンマッチングではなくコード内の文脈を分析する LLM ベースの検証ステップを追加しました。
偽陽性の削減と開発体験の向上
ノイズとなるアラートを減らすことで、開発者が実害のあるインシデントに集中できる時間を増やし、システム全体への信頼感を回復させることを目指しています。
既存パイプラインとの統合
この新機能は既存の検出パイプラインを置き換えるものではなく、後段の検証ステップに文脈認識能力を追加することで、精度を向上させるアプローチを採用しています。
高信号の文脈抽出による精度向上
大量のコードを送るのではなく、値がAPIリクエストや認証ヘッダーなどに使用されているかといった「使い方の文脈」を抽出し、モデルに提供することで偽陽性を効果的にフィルタリングします。
ファイル単位の分析でスケーラビリティを維持
コードベース全体ではなく、値がどのように使用されているかを判断できる「焦点を絞ったファイルレベルの文脈」だけで偽陽性を解決でき、低レイテンシと高い精度を両立しています。
75.76%の偽陽性削減実績
顧客が確認した数百件の偽陽性アラートに対して評価を行った結果、目標の65%を上回る75.76%の削減に成功し、開発者が信頼できるアラートに集中できるようになりました。
影響分析・編集コメントを表示
影響分析
この発表は、AI を単なる検出ツールとしてではなく、文脈を理解して判断を下す「推論エンジン」として活用する実例を示しており、DevSecOps の現場における AI 導入の質的転換を意味します。偽陽性の削減によりセキュリティツールの信頼性が向上すれば、組織全体のセキュリティ文化とインシデント対応速度にプラスの影響を与えるでしょう。
編集コメント
セキュリティツールにおける「精度」の定義が、単なる検出率から「文脈理解による誤検知の排除」へとシフトしている重要な転換点です。開発者の疲弊を防ぐための実用的な AI 応用例として注目すべきニュースです。
シークレットスキャンは、開発者と組織を保護する上で重要な役割を果たしています。これにより、露出した認証情報を早期に検出し、小さなミスが実際のインシデントに発展するのを防ぎます。
GitHub のような大規模環境では、わずかな非効率性でも実質的な摩擦を生み出します。偽陽性が多すぎると、アラートへの信頼性が低下します。
アラートがノイズのように感じられると、開発者は実際の問題の修正に費やす時間よりも、優先順位付けや選別(トライアージ)に多くの時間を割くことになります。時間が経つにつれ、これは修復プロセスを遅らせ、システムに対する信頼性を損ないます。
この課題に対処するため、GitHub は Microsoft Security & AI の Agents Offense チームと協力し、GitHub のシークレットスキャン検証に文脈に基づく推論(コンテキスト・リーゾニング)を導入しました。この協働では、Agentic Secret Finder から採用された検証アプローチが適用されました。これは、単なる秘密らしきパターンとの一致だけでなく、潜在的なシークレットを文脈として理解するために開発された、より広範な検出および検証システムです。これにより、GitHub は、シークレットスキャンで期待されるカバレッジを維持しつつ、低価値なアラートを削減する方法を探ることができました。
現在の GitHub におけるシークレットスキャン
GitHub のシークレットスキャンは、パターンベースの検出と AI ベースの検出を組み合わせて、潜在的なシークレットを特定します。パターンベースの検出では、トークンや API キーのためのパートナーパターンなど、既知の秘密フォーマットを検出します。AI 駆動の汎用シークレット検出は、既知のプロバイダーパターンに一致しないパスワードなどの非構造化シークレットへのカバレッジを拡大します。
GitHub はすでに、大規模なプロバイダーパターンに基づくシークレット検出において業界をリードする精度を有しており、数百万のリポジトリにまたがる数億回のプッシュを処理し、数千万人の開発者を保護しています。
GitHub が AI 駆動型のシークレット検出へと拡大するにつれ、次の課題は、AI によって検出されたシークレットの精度を、プロバイダーパターンによる検出と同じ高い基準に近づけることでした。この協働では、GitHub の大規模な検出パイプラインと LLM(大規模言語モデル)に基づく文脈検証を組み合わせて、アラートの品質と開発者の信頼性を向上させることに焦点を当てました。
私たちのアプローチ:シークレットスキャンアラートを信頼できるものにする
どのアラートに即座に対応が必要かを素早く判断できる場合に、シークレットスキャンは最も有用になります。
GitHub にはすでにノイズを削減するためのセーフガードが用意されていますが、一部の「シークレットらしき値」については、それが実際の露出を表すかどうかを判断するために、より多くの文脈情報が必要です。これらのアラートを信頼しやすくするため、検証ステップに推論プロセスを追加しました。
検出された値がコード内でどのように出現しているかを分析することで、システムは実際の露出と、単に見た目が機密性があるように見える値とをより明確に区別できるようになります。これにより、価値の低いアラートの調査にかける時間を減らし、重要な問題の修正に集中して取り組むことができます。
パイプラインにおける位置づけ
このアプローチは既存のシステムを直接拡張したものです。検出機能は引き続き候補を生成し、検証ステップでそれらを評価します。より文脈を意識する能力により、本物のシークレットとノイズを見分ける精度が向上します。
その結果、上位層の検出ロジックを変更したりカバレッジを削減したりすることなく、精度が高まります。
仕組みについて
検証における重要な課題は、どのような文脈を提供するかを決めることです。
コードの小さなスニペットだけでは、何かが本物のシークレットかどうかを判断するには不十分な場合がほとんどです。一方で、ファイル全体やリポジトリ全体を渡すと、ノイズが多すぎてコストとレイテンシが増大してしまいます。
より多くの文脈を提供するのではなく、より良い文脈を提供します。
大量のコードを送信する代わりに、値がどのように使用されているかを説明するのに役立つ高信号量の情報を小さなセットとして抽出します。具体的には、値が変数に代入され、その後 API リクエスト、認証ヘッダー、データベースクライアント、またはクラウド SDK 呼び出しへと渡されるケースを探します。パターンマッチングでは値がシークレットのように見えるかどうかは判断できますが、実際にその値がシークレットとして使用されているかどうかまでは判断できません。周囲の使用文脈により、モデルはファイル全体やリポジトリ全体をレビューすることなく、ランダムな UUID や不透明な文字列などの誤報と、実際の露出を見分けることができます。

より多くのデータではなく、焦点を絞った文脈
精度を高めるにはコードベースのより多くの部分を分析する必要があると考えるのは自然ですが、実際は逆です。
誤検知の多くは、焦点を絞ったファイルレベルの文脈で解決できます。重要なのはモデルがどの程度のコードを見るかではなく、適切なシグナルを持っているかどうかです。
多くの場合、値が実際の秘密鍵であるかどうかは、単一のファイル内での使用状況を確認することで判断できます。プレースホルダーやテストデータ、未使用の設定に似ている値は、より深い分析なしでフィルタリングできることがよくあります。
これにより、システムは効果的かつ実用的なまま維持されます:高い精度、低いレイテンシ、そして大規模なコードベース全体でのスケーラビリティです。
結果:実践における誤検知の削減
このアプローチを、数百件の顧客が確認した誤検知アラートに対して評価しました。
目標は 65% の削減でした。その結果、75.76% を達成し、強力な検出性能を維持しながらも目標を上回りました。
実践的には、これはノイズの大幅な減少と、アクションが必要なアラートの割合の高まりを意味します。
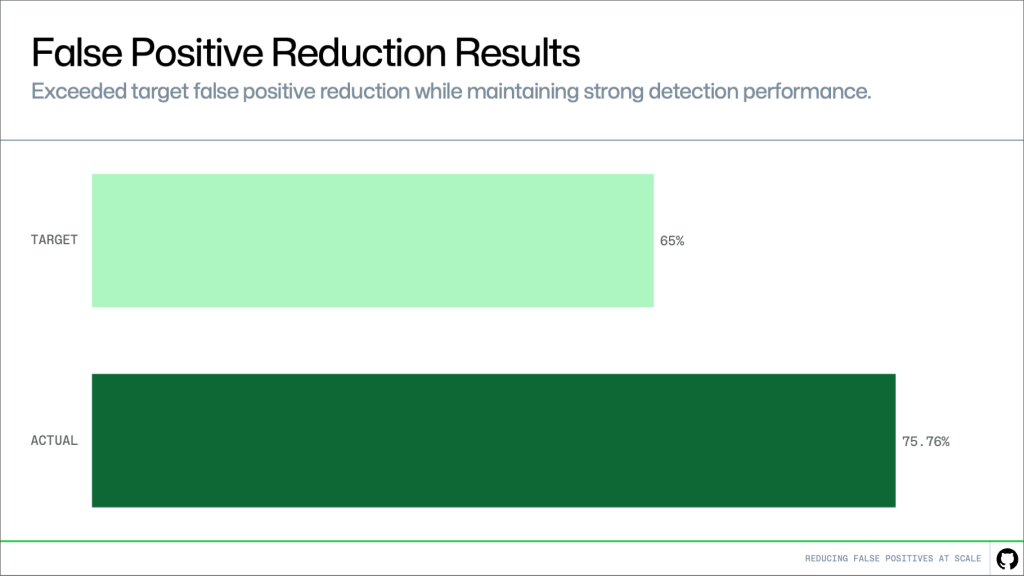 image 数百件の顧客が確認した誤検知アラートに基づく誤検知削減結果。
image 数百件の顧客が確認した誤検知アラートに基づく誤検知削減結果。
この改善は、開発者体験に直接的に現れます。無関係なアラートが減ることで、表示される情報の信頼性が向上します。ノイズの選別にかける時間が減り、実際の課題を優先してより迅速に修正できるようになります。
今後の展望
私たちは、このアプローチをより大規模なデータセットとライブトラフィック上で評価し続けると同時に、コンテキストの抽出方法および検証における活用方法を改善しています。
スケーラブルな環境における偽陽性の削減は、一貫して求められるニーズです。本取り組みでは、最も重要な箇所でシグナルの品質を向上させることに焦点を当て、アラートを信頼しやすく、かつ即座に対応可能にすることを目指しています。
目標はシンプルです:ノイズを減らし、明確なシグナルを提供し、実際のリスクに対して迅速な対応を行うことです。
まずは今日、組織向けのリスク評価を実行するか、または秘密検出(secret scanning)の詳細についてさらに学ぶことをお勧めします。
本記事「Making secret scanning more trustworthy: Reducing false positives at scale」は、元々 The GitHub Blog で公開されたものです。
原文を表示
Secret scanning plays a critical role in protecting developers and organizations. It helps catch exposed credentials early and prevents small mistakes from turning into real incidents.
At GitHub’s scale, even small inefficiencies create real friction. Too many false positives make alerts harder to trust.
When alerts feel noisy, developers spend more time triaging and less time fixing real issues. Over time, this slows down remediation and reduces confidence in the system.
To address this challenge, GitHub collaborated with Microsoft Security & AI’s Agents Offense team to bring more contextual reasoning into GitHub’s secret scanning verification. The collaboration applied the verification approach from Agentic Secret Finder, a broader detection and verification system developed to understand potential secrets in context, not just whether they match a secret-like pattern. This helped GitHub explore ways to reduce low-value alerts while preserving the coverage you expect from secret scanning.
Secret scanning at GitHub today
GitHub secret scanning combines pattern-based detection with AI-based detection to identify potential secrets. Pattern-based detection catches known secret formats, such as partner patterns for tokens and API keys. AI-powered generic secret detection expands coverage to unstructured secrets like passwords that don’t match a known provider pattern.
GitHub already has industry-leading precision for provider-pattern secret detection at massive scale, processing billions of pushes and protecting tens of millions of developers across millions of repositories.
As GitHub expanded into AI-powered secret detection, the next challenge was bringing the precision of AI-detected secrets closer to the same high standard as provider-pattern detections. This collaboration focused on combining GitHub’s large-scale detection pipeline with LLM-based contextual verification to improve alert quality and developer trust.
Our approach: Make secret scanning alerts trustworthy
Secret scanning is most useful when you can quickly tell which alerts need action.
GitHub already has safeguards to reduce noise, but some secret-like values need more context to determine whether they represent a real exposure. To make those alerts easier to trust, we added more reasoning to the verification step.
By looking at how a detected value appears in code, the system can better separate real exposures from values that only look sensitive. This helps you spend less time investigating low-value alerts and more time fixing the issues that matter.
Where this fits in the pipeline
This approach builds directly on the existing system. Detection continues to generate candidates, and the verification step evaluates them. More context-awareness makes this system better at distinguishing real secrets from noise.
The result is higher precision without changing upstream detection logic or reducing coverage.
How it works
A key challenge in verification is deciding what context to provide.
A small snippet of code is often not enough to determine whether something is a real secret. At the same time, passing entire files or repositories introduces too much noise and increases cost and latency.
Instead of giving more context, we’re giving better context.
Rather than send large amounts of code, we extract a small set of high-signal information that helps explain how the value is used. For example, we look for cases where a value is assigned to a variable and later passed into an API request, authentication header, database client, or cloud SDK call. Pattern matching can tell us that a value looks like a secret, but it can’t tell us whether the value is actually being used as one. The surrounding usage context helps the model distinguish real exposures from false alarms, such as random UUIDs or opaque strings, without reviewing the full file or repository.
Focused context, not more data
It’s natural to assume that improving accuracy requires analyzing more of the codebase. But the opposite is true.
Most false positives can be resolved with focused, file-level context. What matters is not how much code the model sees, but whether it has the right signals.
In many cases, you can determine whether a value is a real secret by looking at how it is used within a single file. Values that resemble placeholders, test data, or unused configuration can often be filtered out without deeper analysis.
This keeps the system both effective and practical: high accuracy, low latency, and the ability to scale across large codebases.
Results: reducing false positives in practice
We evaluated this approach on hundreds of customer-confirmed false positive alerts.
Our target was a 65% reduction. The result was 75.76%, exceeding that goal while maintaining strong detection performance.
In practice, this means significantly less noise and a higher proportion of alerts that require action.
imageFalse positive reduction results based on hundreds of customer-confirmed false positive alerts.
This improvement shows up directly in the developer experience. With fewer irrelevant alerts, it becomes easier to trust what you see. Less time is spent triaging noise, and real issues can be prioritized and fixed faster.
What’s next
We’re continuing to evaluate this approach on larger datasets and live traffic, while improving how context is extracted and used for verification.
Reducing false positives has been a consistent need at scale. This work focuses on improving signal quality where it matters most, making alerts easier to trust and act on.
The goal is simple: fewer distractions, clearer signals, and faster action on real risks.
Get started by running the risk assessment for your organization today, or learn more about secret scanning.
The post Making secret scanning more trustworthy: Reducing false positives at scale appeared first on The GitHub Blog.
関連記事
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み