Amazon SageMaker AIにおける多ターン強化学習のベストプラクティス
AWS は Amazon SageMaker AI 上でマルチターンエージェントの強化学習を信頼性高く実行するためのベストプラクティスと、SOP ベンチマークを活用した具体的な実装手法を公開した。
キーポイント
マルチターン RL の課題と環境設計
依存するステップの連続やリカバリーが必要な複雑なタスクでは、報酬の欺き(reward hacking)や環境信号の汚染が起きやすく、信頼できるトレーニング環境の構築が不可欠である。
SageMaker AI MTRL の機能とアーキテクチャ
サーバーレス実行、非同期ロールアウトによる高速な勾配更新、そして PPO や GRPO などのネイティブアルゴリズムライブラリを提供し、GPU クラスタの管理なしで生産規模の学習を可能にする。
SOP ベンチマークを用いた評価と最適化
12 のビジネスドメインにわたる複雑な標準作業手順(SOP)に基づくタスク解決能力を評価する「SOP-Bench」データセットを活用し、エンドタスクに整合した報酬設計や外部評価の重要性を示している。
運用とモニタリングのベストプラクティス
エージェントが複数ターン実行された際の変化管理や、学習の進捗を判断する指標(メトリクス)の監視を通じて、継続的なイテレーションを回すための具体的な指針を提示している。
報酬関数の検証とハッキング防止
学習前に実際の出力で報酬関数を検証し、評価基準より緩いフォーマットを許容する「報酬ハッキング」を防ぐ必要があります。
ベースモデルの基礎能力確認
強化学習は既存の能力を強化するものであり、ベースモデルがタスクで一度も成功しない場合、学習は機能しません。
評価ジョブのスコアリング対象
評価ジョブはエージェント自身の報酬関数を使用してロールアウトを採点するため、これは保持された一般化能力を測定するものであり、報酬からの独立性を測るものではありません。
影響分析・編集コメントを表示
影響分析
この記事は、LLM エージェントが単発の応答から複雑な業務フロー(マルチターン)へ移行する際の技術的障壁を解消し、企業レベルでの実装を加速させる重要な指針となる。特にサーバーレス環境での強化学習と SOP ベンチマークの活用は、信頼性の高い自律型エージェントの実用化に向けた具体的なロードマップを提供しており、業界全体の開発効率向上に寄与する。
編集コメント
単なる機能紹介に留まらず、マルチターン RL が抱える「報酬の欺き」や「信号汚染」といった本質的な課題に対し、具体的な対策と評価指標を提示している点で非常に実用的です。特にサーバーレスでの大規模学習が可能になる点は、リソース制約のある企業にとって大きな追い風となるでしょう。
Amazon SageMaker AI でマルチターンエージェントをトレーニングしてサポートチケットの解決やコンテンツのモデレーションを行う場合、単一の応答ではなく、依存関係のある一連のステップを処理する必要があります。これらのエージェントは指示を読み取り、ツールの呼び出しを行い、結果を確認し、次のアクションを決定し、回答を確定する前にミスを回復します。この柔軟性が、アジェンティックな強化学習(RL)を困難にする要因でもあります。行動の選択肢が増えるほど、タスクを実行せずに報酬を満たす方法も増え、エージェントがトレーニングを行う環境が訓練信号を静かに汚染してしまう可能性があります。
本稿では、信頼できるマルチターン RL トレーニングのためのベストプラクティスをご紹介します。信頼できるトレーニング環境の構築方法、外部評価の設定、エンドタスクと整合した報酬設計、複数ターン実行時の変更点の管理、そして反復を行うべきタイミングを示す指標の監視について解説します。例は、12 のビジネスドメインにわたる複雑な標準作業手順(SOP)に基づいてタスク解決能力を評価する Amazon Science ベンチマークである SOP-Bench データセットから引用しています。
SageMaker AI マルチターン強化学習
Amazon SageMaker AI マルチターン RL(SageMaker AI MTRL)は、エージェントタスク向けのトレーニングループを提供します。あなたのエージェントは、Amazon Bedrock AgentCore、Amazon Elastic Kubernetes Service (Amazon EKS)、Amazon Elastic Compute Cloud (Amazon EC2)、AWS Fargate、または選択したインフラ上で実行できます。ツールサーフェスをロールアウトサーバーに公開する小型アダプターを介して接続し、SageMaker AI MTRL が残りの処理を担当します。
- 統合をローコードに保ちつつ、完全なアルゴリズム制御を提供するモジュラー型エージェント・環境インターフェース。カスタム報酬、カスタムツールループ、多ターン会話の形状はすべてユーザーが定義できます。
- インフラストラクチャの懸念を簡素化するサーバーレス実行により、GPU クラスターのプロビジョニングや管理を行わずに、トークン単価で本番規模のエージェント強化学習(Agentic RL)を利用可能です。
- 非同期ロールアウトと軌道収集により、オフポリシーの古さ(staleness)を制限します。生成と勾配更新は並列して実行され、現在のポリシーから過度に逸脱することなくトレーニング速度を向上させます。
- 近接政策最適化(Proximal Policy Optimization: PPO)、クリップド重要性サンプリング政策最適化(Clipped Importance Sampling Policy Optimization: CISPO)、および重要性サンプリング(IS)損失を含むネイティブアルゴリズムライブラリと、複数のグループベースのアドバンテージ推定器(GRPO, GRPO pass@k, RLOO など)を組み合わせます。これらは多ターンエージェント強化学習において最も関連性の高い選択肢を網羅しています。
- 長時間にわたる多ターンの軌道における壁時計時間(wall-clock time)の短縮を実現するシーケンス拡張トレーニング。
- Amazon SageMaker AI が管理する MLflow を介した軌道と報酬の観測機能により、エージェントがターンごとに、またトレーニングステップ全体で何を行ったかを確認できます。
- SageMaker AI エンドポイントや Amazon Bedrock へのデプロイ前に、報酬、pass@k、軌道メトリクスなどを報告する評価ジョブ。
このサービスはトレーニングループ、ハードウェア、オーケストレーションを提供します。信頼性の高いエージェントを得るかどうかを決定する選択肢はすべてユーザーにあります。エージェントが学習する環境を構築し、報酬以外の成功基準を測定し、報酬そのものを設計し、曲線が停滞した際の反復方法を決定するのはあなた次第です。
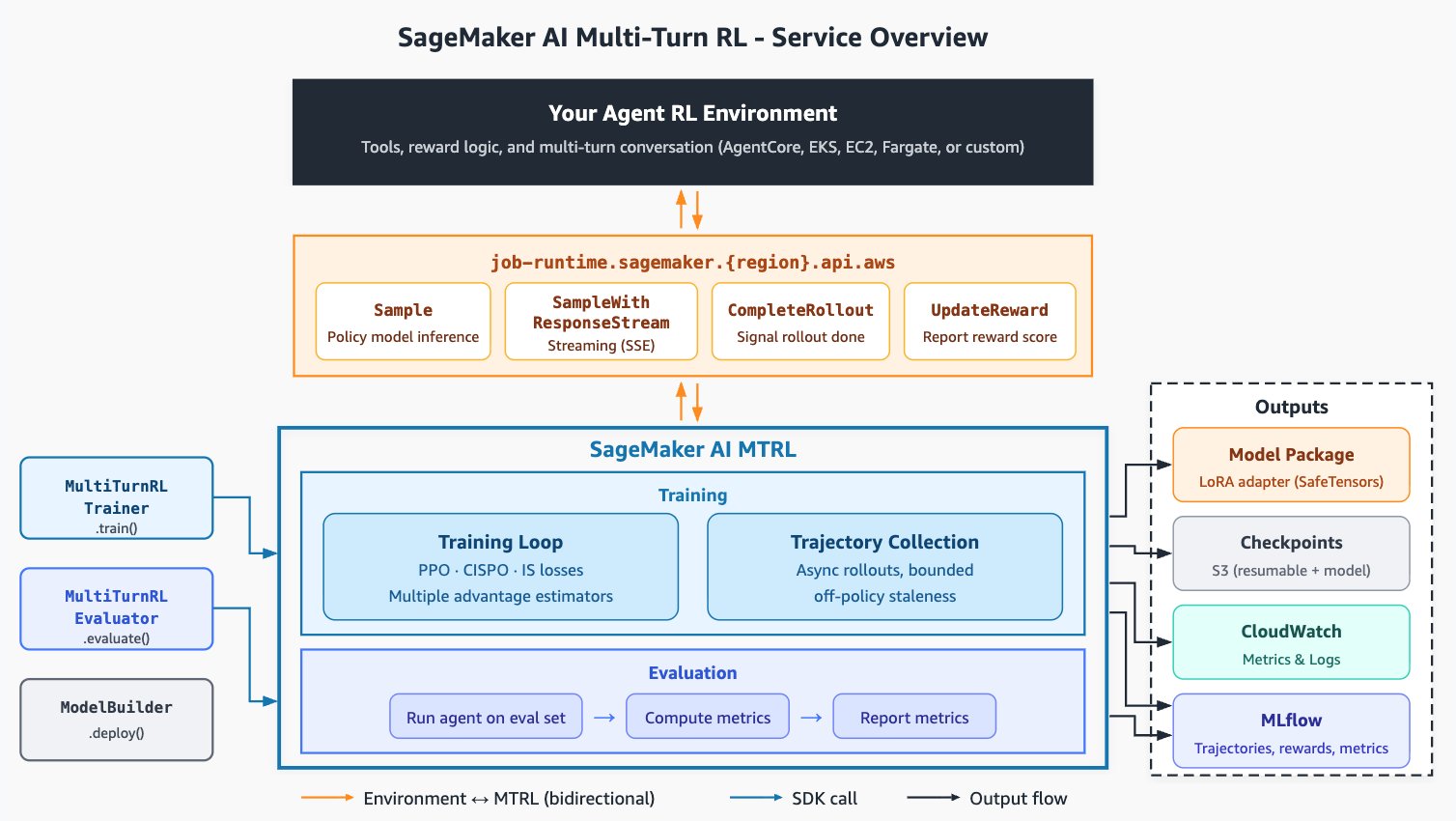
*図 1: SageMaker AI の多ターン RL サービスの概要*
安価で再現性があり、実環境を反映したトレーニング環境を構築する
シングルターンの RL(強化学習)にはプロンプトと報酬関数が必要です。一方、マルチターンの RL では、エージェントがターンを超えて行動するための環境、つまり呼び出されるツールやその背後にあるシステムが追加されます。この環境はトレーニングセットアップの一部であり、どのように構築するかによって、モデルが学習できる内容や、指標を信頼できるかが決定されます。
エージェントのトレーニングにおいては、本番環境と類似しているがライブトラフィックから隔離されたサンドボックス化またはシミュレーションされた環境を構築してください。ツールの呼び出しと応答は、同じスキーマとビジネスロジックを維持します。これらはライブ呼び出しではなく、記録された応答や隔離された状態によって駆動されます。
シミュレーション環境は推奨される出発点です。なぜなら、通常のランでは数千回のロールアウトが発生し、それぞれが複数のツール呼び出しを行うからです。例えば、バッチサイズを 128、グループサイズを 8 とすると、ステップあたり 1,024 回のロールアウトになります。このトラフィックを生きたシステムに直接流すと、顧客への影響が生じる可能性があります。シミュレーション環境がない場合、探索によって実際の副作用が発生する恐れがあります。例えば、試行錯誤を通じて学習するエージェントは、意図しないリファンドの発行、レコードの削除、またはワークフローのトリガーを引き起こすことになります。さらに、生データは常に変化しており、同じ軌道でもランごとにスコアが異なります。報酬を計算するには正しい結果を知る必要があり、ツール呼び出し先がどこであれ、固定されたラベル付きタセット(または信頼できる判定モデル)が必要です。
シミュレーション環境の構築方法は、ツールの機能に依存します。遭遇するユースケースのほとんどをカバーする 3 つのパターンがあります:
- リーダーツール:入力に応じて記録された応答をキーとして再生する。これらのツールは、エージェントがタスクに関連する情報を取得するのを支援します。例えば、SOP-Bench のカスタマーサービスタスクでは、10 個のモックツール(validateAccount, getAuthenticationDetails, createSessionAndOpenTicket など)が提供され、それぞれがツール呼び出し引数に基づいて CSV ファイルの特定の行など、固定データセットから決定論的な応答を返します。
- ステートフルツール:エピソードの期間中、状態を保持するシード付きサンドボックス。エージェントが何かを書き込み、それを再度読み取る場合、環境にはメモリが必要です。パターンは以下の通りです:ロールアウト開始時にエピソードごとのリソースを割り当て、エージェントが作成したすべてのものを登録します。エピソード終了時(ターミナルアクションに達した場合、最大ターン数に到達した場合、またはクラッシュした場合)には、try/finally ブロック内ですべてを破棄します。状態は次のロールアウトに漏れ出ません。
- 検証可能な結果:隔離されたシミュレーション環境における実際の実行。エージェントの出力がコード、SQL、または数学式である場合、それを隔離された環境で実行できます。コードには Docker exec を、SQL にはロールアウトごとのインメモリ SQLite を、数学には純粋な Python eval を使用します。実際の実行であり、インスタンスごとに決定論的です。同じ入力と同一のサンドボックス状態であれば、必ず同じ結果が得られます。例えば、AgentCore Code Interpreter はコード実行用の管理された隔離環境を提供しています。
いずれのパターンを採用する場合でも、以下の 2 つのプロパティを固定値として維持してください:
- 再現性:同じツールを同じ引数で呼び出すと常に同じ結果が返されるため、同一の軌跡に対する報酬が安定し、実行間での評価が可能になります。
- 代表性:モデルが学習する行動が生産環境へ転移できるように、実際のスキーマとデータ分布に基づいて環境を構築します。
トレーニングを開始する前に、環境が正しく設定されていることを確認してください:
- 同じ引数で呼び出されたツール呼び出しは同じ結果を返すこと。これは同一のインスタンスを 2 回実行し、ロールアウトメッセージを比較(diff)することで検証します。
- ロールアウトごとの状態は隔離されていること(別々の一時ディレクトリ、別々の ID、別々のデータベース接続)。
- 利用可能なツールと、そのツール呼び出し/レスポンスのスキーマが生産環境と一致していること。
トレーニング前に外部評価を設定する
環境が整い検証されたら、報酬関数を作成する前に成功を測定する方法を構築してください。この測定はあなたの最終目標を直接的に捉えるべきです。強化学習(RL)は報酬信号を文字通り最適化するため、報酬が唯一の指標となる場合、タスク上の進捗と報酬基準への適合という 2 つの進捗を分離して評価することはできません。報酬、環境のシード値、ハイパーパラメータの反復処理中に意思決定を導くために信頼できる外部評価が必要です。
⟦CODE_0⟧
パターン
デプロイ時に重視する成果を評価する、報酬とは独立して計算される保留評価(held-out evaluation)を用意してください。実際には、モデルを受け取り、固定されたテスト分割に対してロールアウトサーバーで実行し、単一のタスク成功率を返す小さなコード片です。誠実であれば、最小限の構成でも構いません。
SOP-Bench における評価は、最終的な JSON オブジェクト内の完全一致(exact-match)です。エージェントの出力にあるすべてのフィールドが、正解(ground-truth)のフィールドと完全に一致している必要があります。そうでなければロールアウトスコアはゼロとなります。報酬関数は部分的な加点や加重成分を計算できますが、評価機能はそうではありません。
トレーニングを開始する前に、ベースラインを設定してください。基本モデルと参照モデル(Amazon Bedrock でホストされた最先端モデルが適しています)を同じ評価プロセスに通します。これにより、2 つのことがわかります:基本モデルが到達すべき距離、およびこのタスクにおいて「良い状態」とはどのようなものかです。
アンチパターン
トレーニング報酬、またはそこから導き出された指標を成功の尺度として扱うことです。これは直感的に思えるかもしれませんが、報酬ハッキング(reward hacking)を検出するには外部評価が必要です。多ターンエージェントには特別な配慮が求められます:ツール呼び出しに対して報酬を支払う設計は、エージェントにできるだけ多くのツールを呼び出すよう学習させてしまいます。一方、ターン数に対するペナルティを与える設計は、必要な情報を得る前に回答を確定させるよう学習させてしまいます。いずれの場合も、トレーニング中の報酬は上昇しますが、タスクにおけるエージェントの実際の成功度は低下します。
トレーニングを開始する前に、評価が信頼できることを確認してください:
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等)は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "## パターン\n\nデプロイ時に重視する成果を評価する、報酬とは独立して計算される保留評価(held-out evaluation)を用意してください。実際には、モデルを受け取り、固定されたテスト分割に対してロールアウトサーバーで実行し、単一のタスク成功率を返す小さなコード片です。誠実であれば、最小限の構成でも構いません。\n\nSOP-Bench における評価は、最終的な JSON オブジェクト内の完全一致(exact-match)です。エージェントの出力にあるすべてのフィールドが、正解(ground-truth)のフィールドと完全に一致している必要があります。そうでなければロールアウトスコアはゼロとなります。報酬関数は部分的な加点や加重成分を計算できますが、評価機能はそうではありません。\n\nトレーニングを開始する前に、ベースラインを設定してください。基本モデルと参照モデル(Amazon Bedrock でホストされた最先端モデルが適しています)を同じ評価プロセスに通します。これにより、2 つのことがわかります:基本モデルが到達すべき距離、およびこのタスクにおいて「良い状態」とはどのようなものかです。\n\n## アンチパターン\n\nトレーニング報酬、またはそこから導き出された指標を成功の尺度として扱うことです。これは直感的に思えるかもしれませんが、報酬ハッキング(reward hacking)を検出するには外部評価が必要です。多ターンエージェントには特別な配慮が求められます:ツール呼び出しに対して報酬を支払う設計は、エージェントにできるだけ多くのツールを呼び出すよう学習させてしまいます。一方、ターン数に対するペナルティを与える設計は、必要な情報を得る前に回答を確定させるよう学習させてしまいます。いずれの場合も、トレーニング中の報酬は上昇しますが、タスクにおけるエージェントの実際の成功度は低下します。\n\nトレーニングを開始する前に、評価が信頼できることを確認してください:"}
- 評価は単一の関数、score(rollout) -> float であり、あなたが実際に提供するものを正確に採点するものです。
- ベースライン評価は、ファインチューニングを計画しているベースモデルに対してゼロではない値である必要があります(もしゼロであれば、次のセクションの「まずベースモデルが足場を持つことを確認する」を参照してください)。
- 比較対象となる高度なベースラインを得るために、フロンティアモデルに対して評価を実行してください。
多ターン強化学習のための適切な報酬関数の設計
報酬の設計は、強化学習における最も困難な未解決問題の一つです。エージェントが実際のタスクを解決できるという同じ柔軟性が、タスクを実行せずに報酬を満たす方法を見つけさせることにもなります。追加する各コンポーネント、調整する各報酬重み、付加する各フォーマットボーナスはすべて、タスクを解決せずにエージェントが登れる別の表面となります。モデルはあなたが意図したものを最適化するのではなく、あなたが記述したものを最適化します。デフォルトでは、トレーニングと評価に同じスコアリングルールを使用し、具体的な理由がある場合のみ例外として扱ってください。
翻訳全文
翻訳全文
ベンチマークスコアは、すべての項目が一致すれば1、そうでなければ0となります。トレーニングと評価では通常このスコアリングルールを共有し、観察対象となる情報の違いのみが生じます。トレーナーは各ロールアウトごとに1つの報酬(スカラー値またはスカラーのリスト)を受け取ります。評価は固定された分割データに対して低い頻度で実行されるため、より多くの指標を監視できます:項目ごとの精度、完了率(エージェントが出力を発行したか)、ツール呼び出しの分布、ターン予算の枯渇状況、フォーマット準拠性。
デフォルトのベンチマークスコアリングルールから逸脱する理由は2つあり、どちらもより密な報酬(denser reward)を必要とします。
第一にアルゴリズム的な側面です。RL(強化学習)は、各プロンプトに対して group_size 個のロールアウト群全体における分散から学習信号を計算し、グループベースのアバンテージ手法(advantage_method)を使用します。サービスのデフォルト設定では group_based は GRPO です。rloo や grpo_passk など他の多くのメソッドも利用可能です。完全なリストについては ドキュメント を参照してください。バイナリスコアはこの分散を圧縮してしまいます:グループ内のすべてのロールアウトが同じスコアを得た場合、相対的な信号はゼロとなり、そのグループは勾配に寄与しません。rollout/reward/valid_mean(非ゼロアバンテージを持つグループの平均)が rollout/reward/mean を下回って推移し、モデルが停止したとき、このギャップが症状として現れます。
2 つ目は収束速度です。グループの分散が健全であっても、密な報酬は、完全な成功を収めたロールアウトだけでなく、すべてのロールアウトにおいてモデルに部分的な進歩への勾配を与えます。6 つのフィールドのうち 5 つを正しく処理したロールアウトは、モデルに対して「より近い状態」がどのようなものかを教示します。一方、二値スコアではそのような情報は得られません。
SOP-Bench タスクにおける密な報酬は、各フィールドを独立して採点し、スカラーまたはスカラーのリスト(ターンごとの報酬)とメトリクス辞書を返します。
class SOPBenchReward:
"""SOP-Bench 航空機検査タスク向けのフィールドごとの密な報酬。
[0, 1] の範囲のスカラーと、MLflow で公開されるメトリクス辞書を返します。"""
ground_truth: dict[str, str]
format_coef: float = 0.1 # フォーマットは小さな形状付け項であり、目的関数ではないasync def __call__(self, history: list[Message]) -> tuple[float, dict[str, float]]:
fields = parse_final_output(last_assistant(history)) # JSON inside
emitted = float(fields is not None)
if fields is None: # no parseable answer
return self.format_coef * (emitted - 1), {"completion": 0.0, "field_acc": 0.0}
matched = sum(1 for k, v in self.ground_truth.items()
if str(fields.get(k)).strip().lower() == str(v).strip().lower())
field_acc = matched / len(self.ground_truth) # partial credit: 5/6 > 0
reward = field_acc + self.format_coef * (emitted - 1) # correctness dominates
return reward, {"completion": emitted, "field_acc": field_acc}
Your agent reports the reward through update_reward, and the metrics dictionary (completion, field_acc) appears in MLflow. To credit individual turns instead of the whole trajectory, update_reward also accepts a per-turn list, paired with the group_based_per_turn advantage method, so your reward function can also return one reward value per turn.
必ずJSON形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等)は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
- トレーニングを開始する前に、実際の出力に対する報酬を確認してください。評価よりも寛容な報酬パーサーは、それ自体が一種の報酬ハックとなります。SOP-Bench の実行例の一つでは、報酬側がベンチマークが採点した形式よりも緩い出力フォーマットを受け入れました:ベンチマークが
<tag>を必要とする一方で、単なるラッパータグのみでもクレジットが付与されました。トレーニングはまさに私たちが求めた通り機能しました:モデルはベンチマークが必要とするタグを削除することを学習し、報酬は上昇しましたが、外部評価は低下しました。
- まずベースモデルに一定の基盤があることを確認してください。強化学習(RL)は、ベースモデルがすでに時間のある割合で実行できている能力を向上させるものであり、ゼロから新たな能力を創出するものではありません。もしベースモデルがあなたのタスクにおいて成功した軌道(trajectories)を一度も生成しない場合、報酬信号が増幅する対象が存在せず、トレーニングは停止してしまいます。
SageMaker AI MTRL は、このようなベースラインを管理された評価ジョブとして実行できます。MultiTurnRLEvaluator は、保持されたプロンプトセットに対してエージェントを再生し、評価結果・報酬値および pass@k を報告します。すでにモデルをトレーニング済みの場合、evaluate_base_model=True を指定した単一の呼び出しで、ベースモデルとファインチューニング済みモデルを並列にスコアリングできます。pass@k は成功閾値(success_threshold)によって報酬を制限するため、success_threshold=1 を設定すると厳格な成功率が得られます:これは、完全な報酬を獲得したロールアウトの割合と平均値を示すものです。
from sagemaker.train.evaluate import MultiTurnRLEvaluatorBedrock AgentCore を使用して
evaluator_base = MultiTurnRLEvaluator(
model="openai-reasoning-gpt-oss-20b",
dataset="s3://my-bucket/eval-prompts.parquet",
agent_config="arn:aws:bedrock-agentcore:us-west-2:123456789012:runtime/my-agent",
s3_output_path="s3://my-bucket/eval-output/base/",
mlflow_resource_arn="arn:aws:sagemaker:us-west-2:123456789012:mlflow-tracking-server/my-mlflow",
role="arn:aws:iam::123456789012:role/SageMakerRole",
accept_eula=True,
)
execution = evaluator_base.evaluate()
execution.wait()
指定された s3_output_path には、評価の報告メトリクス(MLflow でも確認可能)と評価トラジェクトリが格納されます。ファインチューニング済みモデルおよびベースモデルに対する報酬ベースの評価については、Model evaluation のドキュメントを参照してください。
一つの区別を心に留めてください:評価ジョブは、エージェント自身の報酬関数を用いてロールアウトにスコアを付けます。つまり、これは保持された一般化能力(held-out generalization)を測定するものであり、報酬からの独立性を測定するものではありません。緩やかな報酬パーサーはここで健全に見えるでしょう。なぜなら指標自体が報酬だからです。報酬パーサーのバグを検出する独立したチェックは別に行います:同じロールアウトを、より厳格で独立したパーサー(SOP-Bench の場合、ベンチマークの完全一致スコアラー)を用いてスコア付けし、比較します。さらに、MultiTurnRLEvaluator を報酬が独立指標であるエージェントに指向させることで、その厳格なスコアラーを独自の評価ジョブとして実行することも可能です。
報酬設計の詳細、スパース報酬と密報酬の違い、ジャッジモデル(judge models)、多目的形状付け(multi-objective shaping)、およびそれらの間のトレードオフについては、SageMaker AI 報酬設計ベストプラクティスをご覧ください。
報酬を信頼する前に確認してください:
- トレーニング用報酬と評価用報酬は、異なる理由が測定され文書化されていない限り、同じ基盤となるスコアリングルールを共有する必要があります。
- 報酬は [0, 1] の浮動小数点数(負の回帰項を許容する場合は [-1, 1])を返す必要があります。
報酬は 100 ベースラインロールアウトに対して分散を持ちます(
原文を表示
Training a multi-turn agent in Amazon SageMaker AI to resolve support tickets or moderate content means handling a sequence of dependent steps, not a single response. These agents read instructions, make tool calls, read the results, decide the next action, and recover from a mistake before committing to an answer. That flexibility is also what makes agentic reinforcement learning (RL) challenging. More ways to act mean more ways to satisfy the reward without doing the task, and the environment the agent trains against can quietly corrupt the training signal.
In this post, we share best practices for reliable multi-turn RL training. We cover how to build a training environment you can trust, set up an external evaluation, design a reward aligned with the end task, manage what changes once the agent runs for multiple turns, and monitor the metrics that tell you when to iterate. We draw our examples from the SOP-Bench dataset, an Amazon Science benchmark that evaluates agents’ ability to resolve tasks based on complex Standard Operating Procedures (SOP) across 12 business domains.
SageMaker AI multi-turn reinforcement learning
Amazon SageMaker AI multi-turn RL (SageMaker AI MTRL) provides the training loop for agentic tasks. Your agent can run on Amazon Bedrock AgentCore, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Compute Cloud (Amazon EC2), AWS Fargate, or infrastructure of your choice. You connect it through a small adapter that exposes your tool surface to the rollout server, and SageMaker AI MTRL handles the rest:
- A modular agent-environment interface that keeps integration low-code while giving you full algorithmic control. Custom rewards, custom tool loops, and multi-turn conversation shapes are all yours to define.
- Serverless execution that simplifies infrastructure concerns, so you get production-scale agentic RL at per-token pricing without provisioning or managing GPU clusters.
- Asynchronous rollout and trajectory collection with bounded off-policy staleness. Generation and gradient updates run in parallel without drifting too far from the current policy, which speeds up training.
- A native algorithm library spanning Proximal Policy Optimization (PPO), Clipped Importance Sampling Policy Optimization (CISPO), and importance-sampling (IS) losses, paired with multiple group-based advantage estimators (GRPO, GRPO pass@k, RLOO, and more). These cover the choices most relevant to multi-turn agentic RL.
- Sequence-extension training to keep wall-clock down on long multi-turn trajectories.
- Trajectory and reward observability in MLflow managed by Amazon SageMaker AI, so you can read what your agent did turn by turn, and across training steps.
- Evaluation jobs report reward, pass@k, trajectory metrics, and more before you deploy to a SageMaker AI endpoint or Amazon Bedrock.
The service provides the training loop, hardware, and orchestration. The choices that decide whether you get a reliable agent are yours. You build the environment the agent trains against, measure success outside the reward, design the reward itself, and decide how to iterate when the curve stalls.
*Figure 1: Overview of the SageMaker AI multi-turn RL service*
Build a training environment that is cheap, reproducible, and representative
Single-turn RL needs a prompt and a reward function. Multi-turn RL adds an environment for the agent to act in across turns: the tools it calls and the systems behind them. That environment is part of your training setup, and the way you build it shapes both what the model can learn and whether you can trust your metrics.
When training an agent, build a sandboxed or simulated environment that resembles production but stays isolated from live traffic. Tool calls and responses keep the same schemas and business logic. They are driven by recorded responses or isolated state instead of live calls.
Simulated environments are the recommended starting point because a typical run produces many thousands of rollouts, each making several tool calls. As an example, a batch size of 128 with group size 8 is 1,024 rollouts per step. Pointing that traffic at live systems can lead to customer impact. Without a simulated environment, exploration can produce real side effects. For example, an agent learning by trial and error will issue refunds, delete records, or trigger workflows that you didn’t intend. Additionally, live data shifts under you, so the same trajectory scores differently across runs. You must know the correct outcome to compute a reward, which means a fixed, labeled set of tasks (or a trustworthy judge model) regardless of where the tool calls go.
How you build the simulated environment depends on what your tools do. Three patterns cover most use-cases you will encounter:
- Read-only tools: Replay recorded responses keyed by their inputs. These tools help the agent retrieve information relevant to a task. For example, in SOP-Bench the customer service task provides ten mocked tools (validateAccount, getAuthenticationDetails, createSessionAndOpenTicket, and so on), each returning a deterministic response from a fixture, such as a specific row from a CSV file based on the tool call arguments.
- Stateful tools: Seeded sandboxes that hold state for the length of an episode. When the agent writes something and reads it back, the environment needs memory. The pattern: allocate per-episode resources at the start of the rollout, and register everything the agent creates. Tear it all down in a try/finally block when the episode ends, whether by reaching a terminal action, hitting max_turns, or crashing. No state leaks into the next rollout.
- Verifiable outcomes: Genuine execution in an isolated simulation environment. When the agent’s output is code, SQL, or math, you can run it in an isolated environment. Use a Docker exec for code, an in-memory SQLite per rollout for SQL, a pure Python eval for math. Real execution, deterministic per-instance, same input plus same sandbox state equals same result. For example, AgentCore Code Interpreter provides managed isolated environments for code execution.
Whichever pattern fits, hold two properties fixed:
- Reproducibility: the same tool called with the same arguments returns the same result, so the reward for an identical trajectory is stable and your evaluation is comparable across runs.
- Representativeness: build the environment from your real schemas and data distributions so the behavior the model learns transfers to production.
Before you start training, confirm your environment is configured correctly:
- Tool calls with the same arguments give the same result, verified by running the same instance twice and diffing the rollout messages.
- Per-rollout state is isolated (separate temp directory, separate IDs, separate DB connection).
- Available tools match your production environment, along with tool request/response schemas.
Set up an external evaluation before you train
After your environment is in place and verified, build a way to measure success before you write a reward function. That measure should capture your end goal directly. RL optimizes the reward signal literally, so if the reward is the only number you watch, you cannot separate progress on the task from progress on satisfying the reward criteria. You need an external evaluation you can trust to guide your decisions while you iterate on rewards, environment seeding, and hyperparameters.
Pattern
Stand up a held-out evaluation that scores the outcome you care about at deployment, computed independently of the reward. In practice this is a small piece of code that takes a model, runs it through the rollout server on a fixed test split, and returns a single task-success rate. It can be minimal, as long as it is honest.
For SOP-Bench, the evaluation is exact-match on the final JSON object inside ``: every field in the agent’s output has to match the ground-truth field, or the rollout scores zero. The reward function can compute partial credit and weighted components. The evaluation doesn’t.
Before any training, establish a baseline. Run the base model and a reference model (a frontier model hosted on Amazon Bedrock is a good fit) through the same evaluation. This tells you two things: how far the base model has to go, and what *good* looks like on this task.
Anti-pattern
Treating the training reward, or a metric derived from it, as your measure of success. This might seem intuitive, but to capture reward hacking, you need external evaluation. Multi-turn agents need special consideration: a reward that pays out for tool calls teaches the agent to call as many tools as it can. A reward that penalizes turn count teaches the agent to commit to an answer before it has the information it needs. Either way, the training reward rises but the agent’s real success at its task falls.
Before you start training, confirm your evaluation is trustworthy:
- The evaluation is one function, score(rollout) -> float, scoring exactly what you ship.
- Baseline evaluation is non-zero on the base model you plan to fine-tune (if it’s zero, see Make sure the base model has a foothold first in the next section).
- Run your evaluation against a frontier model so you have an advanced baseline to compare against.
Design a good multi-turn RL reward function
Reward design is one of the more challenging open problems in RL. The same flexibility that lets the agent solve a real task lets it find ways to satisfy the reward without doing the task. Every component you add, every reward weight you tune, every formatting bonus you layer in is another surface where the agent can climb without solving the task. The model optimizes what you wrote down, not what you meant. By default use the same scoring rule for training and evaluation, and only deviate when you have a concrete reason.
Take SOP-Bench. The benchmark expects the answer as a JSON object inside `` tags:
{
"aircraft_ready": "true",
"mechanical_inspection_result": "success",
"electrical_inspection_result": "success",
"component_incident_response": "success",
"component_mismatch_response": "success",
"cross_check_reporting_response": "success"
}The benchmark scores 1 if every field matches and 0 otherwise. Training and evaluation usually share this scoring rule and differ only in what you observe around it. The trainer consumes one reward (scalar or list of scalars) per rollout. Evaluation runs at lower frequency on a fixed split, so you can monitor more metrics: per-field accuracy, completion rate (did the agent emit `` at all), tool-call distribution, turn budget exhaustion, format compliance.
There are two real reasons to deviate from the default benchmark scoring rule, and both call for a denser reward.
The first is algorithmic. RL computes the learning signal from variance across a group of group_size rollouts per prompt, using a group-based advantage method (advantage_method). The service default group_based is GRPO. Many other methods like rloo and grpo_passk are also available. See the documentation for a full list. A binary score can collapse that variance: when every rollout in a group scores the same, the relative signal is zero and the group contributes no gradient. When rollout/reward/valid_mean (the mean over non-zero-advantage groups) drifts below rollout/reward/mean and the model stalls, that gap is the symptom.
The second is convergence speed. Even when group variance is healthy, a dense reward gives the model gradient toward partial progress on every rollout, not only the ones that fully succeed. A rollout that gets five of six fields right teaches the model what *closer* looks like. A binary score teaches it nothing about that.
A dense reward for the SOP-Bench task scores each field independently and returns a reward scalar or list of scalars (per-turn rewards) plus a metrics dictionary.
class SOPBenchReward:
"""Dense per-field reward for the SOP-Bench aircraft-inspection task.
Returns a scalar in [0, 1] plus a metrics dict surfaced in MLflow."""
ground_truth: dict[str, str]
format_coef: float = 0.1 # format is a small shaping term, not the objective
async def __call__(self, history: list[Message]) -> tuple[float, dict[str, float]]:
fields = parse_final_output(last_assistant(history)) # JSON inside
emitted = float(fields is not None)
if fields is None: # no parseable answer
return self.format_coef * (emitted - 1), {"completion": 0.0, "field_acc": 0.0}
matched = sum(1 for k, v in self.ground_truth.items()
if str(fields.get(k)).strip().lower() == str(v).strip().lower())
field_acc = matched / len(self.ground_truth) # partial credit: 5/6 > 0
reward = field_acc + self.format_coef * (emitted - 1) # correctness dominates
return reward, {"completion": emitted, "field_acc": field_acc}Your agent reports the reward through update_reward, and the metrics dictionary (completion, field_acc) appears in MLflow. To credit individual turns instead of the whole trajectory, update_reward also accepts a per-turn list, paired with the group_based_per_turn advantage method, so your reward function can also return one reward value per turn.
- Verify the reward on real outputs before you train on it. A reward parser more forgiving than your evaluation is its own kind of reward hack. In one of our SOP-Bench runs the reward accepted a looser output format than the benchmark scored: a bare wrapper earned credit even though the benchmark only reads . Training did exactly what we asked: the model learned to drop the tag the benchmark needed, the reward climbed, but the external evaluation fell.
- Make sure the base model has a foothold first. RL improves what the base model can already do some fraction of the time. It doesn’t invent capability from nothing. If the base model produces zero successful trajectories on your task, the reward signal has nothing to amplify and training stalls.
SageMaker AI MTRL can run such a baseline as a managed evaluation job. MultiTurnRLEvaluator replays your agent over a held-out prompt set and reports eval/reward and pass@k. If you have already trained a model, a single call with evaluate_base_model=True scores the base and fine-tuned model side by side. Because pass@k thresholds the reward at success_threshold, setting success_threshold=1 gives you a strict success rate: the fraction of rollouts that scored a perfect reward alongside the mean.
from sagemaker.train.evaluate import MultiTurnRLEvaluator
# With Bedrock AgentCore
evaluator_base = MultiTurnRLEvaluator(
model="openai-reasoning-gpt-oss-20b",
dataset="s3://my-bucket/eval-prompts.parquet",
agent_config="arn:aws:bedrock-agentcore:us-west-2:123456789012:runtime/my-agent",
s3_output_path="s3://my-bucket/eval-output/base/",
mlflow_resource_arn="arn:aws:sagemaker:us-west-2:123456789012:mlflow-tracking-server/my-mlflow",
role="arn:aws:iam::123456789012:role/SageMakerRole",
accept_eula=True,
)
execution = evaluator_base.evaluate()
execution.wait()In the specified s3_output_path, you will find the reported metrics of the evaluation which you can also review in MLflow, along with evaluation trajectories. For reward-based evaluation of fine-tuned and base models, see the documentation on Model evaluation.
Keep one distinction in mind: the evaluation job scores rollouts with your agent’s own reward function, so it measures held-out generalization, *not independence from the reward*. A lenient reward parser would look healthy here, because the metric is the reward itself. The independent check that catches reward-parser bugs stays separate: score the same rollouts with a stricter, independent parser (for SOP-Bench, the benchmark’s exact-match scorer) and compare. You can even run that strict scorer as its own evaluation job by pointing MultiTurnRLEvaluator at an agent whose reward is the independent metric.
For a deeper treatment of reward design, sparse vs. dense rewards, judge models, multi-objective shaping, and the trade-offs between them, see the SageMaker AI reward design best practices.
Before you trust your reward, confirm:
- Training reward and evaluation share the same underlying scoring rule unless you have a measured reason to diverge (and that reason is documented).
- Reward returns a float in [0, 1] (or [-1, 1] if you allow negative regression terms).
Reward over 100 baseline rollouts has variance (not
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み