今さらながらDeepSeek-R1の論文を読んでみた
ABEJA の技術者が DeepSeek-R1 の論文を詳細に分析し、CoT ファインチューニングと GRPO による強化学習という具体的な手法により、高品質な推論能力を持つ軽量 LLM が実現されたプロセスを解説している。
キーポイント
DeepSeek-R1 のアーキテクチャとベースモデル
内部ネットワーク構造の改善ではなく、既存の DeepSeek-V3-Base をそのまま使用し、学習手法の変更によって性能を向上させている。
CoT データセットによるファインチューニング
数千件レベルの独自収集された Chain-of-Thought(思考プロセス付き)データを用いて、モデルに段階的な推論能力を習得させる最初のステップ。
GRPO とルールベース報酬による強化学習
生成したデータセットと V3 用データでファインチューニングした後、GRPO(Group Relative Policy Optimization)を用いた強化学習とルールベースの報酬システムで最終的なリファインメントを行う。
推論プロセスの構造化フォーマット
<reasoning_process> と <summary> を特殊トークンで区切る形式を学習させることで、複雑な問題への回答精度と可読性を同時に向上させている。
強化学習前のファインチューニングによる学習安定化
数千件のCoTデータでベースモデルをファインチューニングし、強化学習初期における無意味な出力や不安定化を防ぎ、人間が望む基本的な出力構造を教え込む。
計算コスト削減と報酬ハッキング回避のためのGRPO採用
評価用LLM(クリティックモデル)を不要とするGRPOを採用し計算リソースを節約するとともに、Reward Model によるスコア付けではなくルールベースの報酬を用いて「報酬ハッキング」を防ぐ。
明確なタスクに特化した3つのルールベース報酬
数学・コーディング等の明確な回答が得られるタスクに限定し、最終回答形式の指定([xxx])、CoT構造の強制、およびコード実行によるテストケースパスの有無を報酬判定基準とする。
影響分析・編集コメントを表示
影響分析
この記事は、DeepSeek-R1 が単なる「蒸留」ではなく、CoT データと GRPO といった先進的な強化学習手法を組み合わせることで、高品質な推論能力を獲得したことを明確に示しています。これにより、超高価な GPU に依存せずとも高度な推論タスクが実行可能になるという実用性の根拠が強化され、業界全体における軽量 LLM の開発トレンドと技術的基盤の理解を深める重要な役割を果たします。
編集コメント
ABEJA の技術者が論文を深く読み込み、具体的な学習フロー(CoT→ファインチューニング→GRPO)を整理した非常に質の高い解説記事です。実装や導入を検討するエンジニアにとっての重要な指針となります。

こんにちは!ABEJA で ABEJA Platform の開発や AI 関連の研究開発業務を行っている坂井(@Yagami360)です。こちらは ABEJA アドベントカレンダー 2025 の 24 日目の記事です。
今年のはじめ頃、中国の DeepSeek 社から非常に軽量かつ品質の高い大規模言語モデル(LLM: Large Language Model)が公開され、H100 や A100 などの超高価な NVIDIA 製 GPU がなくとも動かせるということで、株価への影響等を含めて話題になりました。
この記事を書く前の話になりますが、自分としては蒸留(ディストillation)を使って軽量化した LLM というイメージしかもっておらず、とはいえ蒸留という手法は昔から使われてきた手法であり、既存手法の延長線上にも見えるため、DeepSeek が米国大手ビックテックに先んじて蒸留で大幅軽量化した高品質な LLM を発表したのは意外だなあ程度の認識しか持っていませんでした。
かなり今更にはなりますが、幸い論文が公開されているようなので、ここらへんの実体を正確に把握しておきたいと思い、DeepSeek-R1 の論文を読んでみました。
DeepSeek-R1 の論文は、以下で公開されています。
DeepSeek-R1 ベースモデル
Chain of Thought(CoT)データセットでのファインチューニング
GRPO による強化学習とルールベースの報酬システム
学習済みモデルで生成したデータセットと DeepSeek-V3 用データセットでのファインチューニング
最終的なリファインメントのための強化学習
DeepSeek-R1 の蒸留モデル
DeepSeek-R1 の論文で述べられている各モデルや手法の流れを図示すると、以下のようになります。
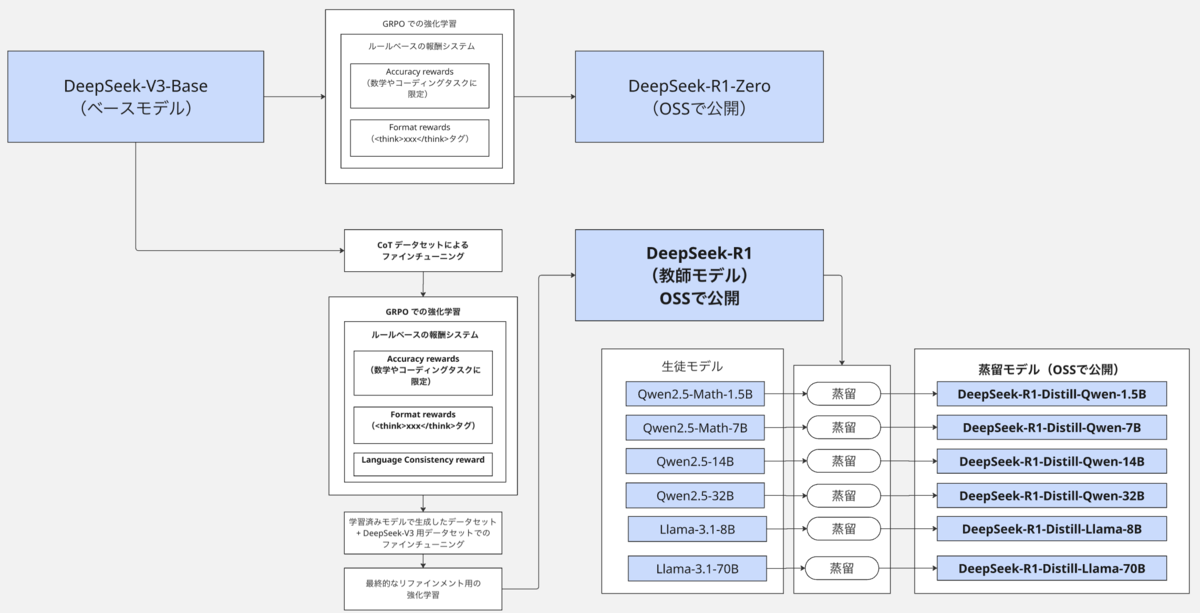
太字で示している箇所が、特に重要な箇所になります。
DeepSeek-R1 の論文で述べられているモデルとしては、DeepSeek-R1-Zero と DeepSeek-R1、及び DeepSeek-R1 の蒸留モデル群があります。
このうち DeepSeek-R1-Zero に関しては、出力されるテキストの可読性の低さ(同じ文章を繰り返すなど)や異なる言語で回答してしまう(日本語と中国語が入るなど)といった課題があり、それを追加の手法で解決したのが DeepSeek-R1 になるため、このブログでは DeepSeek-R1 のみ解説し、説明の煩雑さを省きたいと思います。
前提として DeepSeek-R1 は、モデル内部のネットワーク構造の改善を行ったモデルではありません。内部のネットワーク構造としては、同じく DeepSeek 社が開発した「DeepSeek-V3-Base」をそのまま使用しています(ベースモデルとして利用しています)
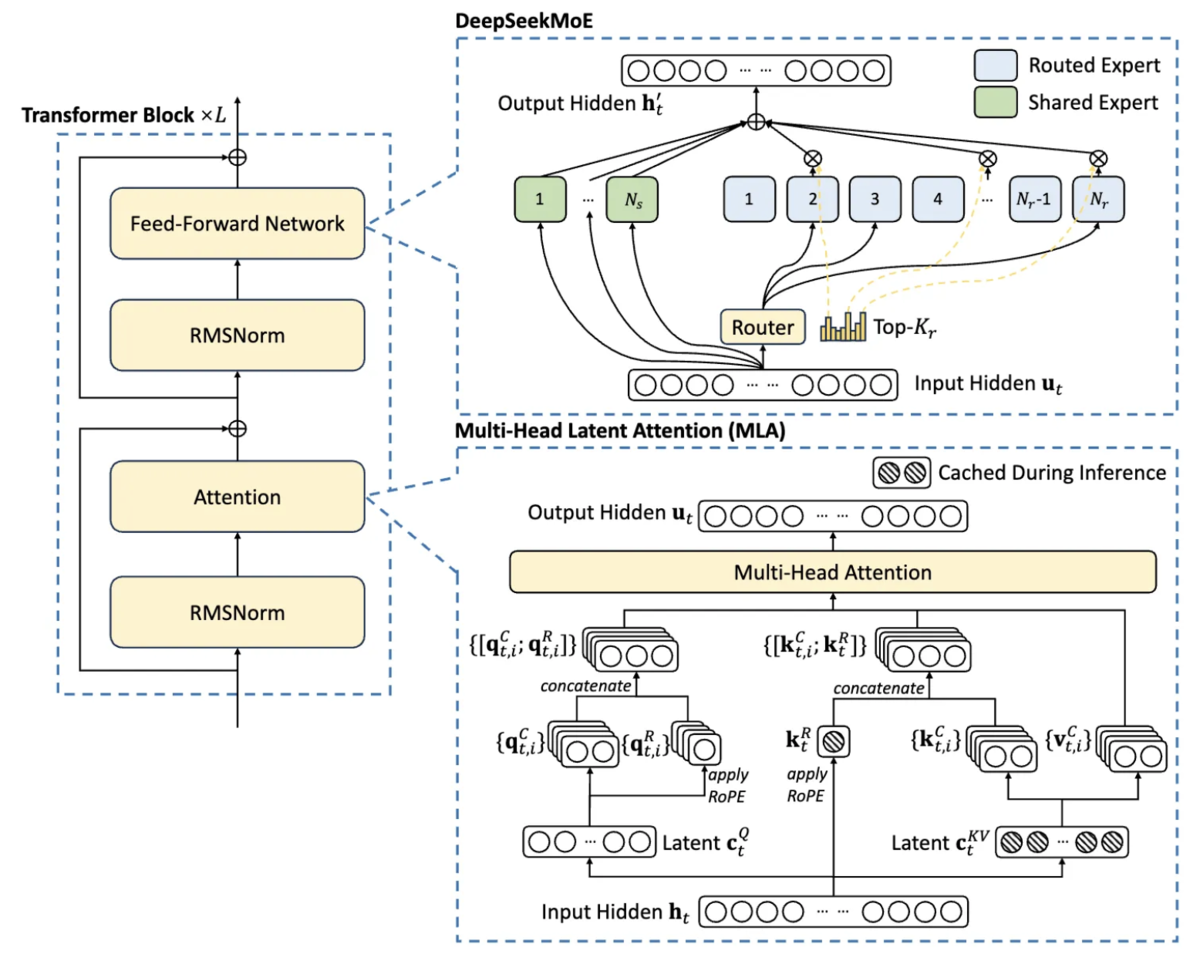 論文「DeepSeek-V3 Technical Report」より引用
論文「DeepSeek-V3 Technical Report」より引用
Chain of Thought(CoT)データセットでのファインチューニング
DeepSeek-R1 ではまず、独自に収集した少数(数千個レベル)の CoT [Chain-of-Thought] 付きの教師ありファインチューニング用データセットで上記ベースモデル(DeepSeek-V3-Base)をファインチューニングします。
CoT [Chain-of-Thought] とは、プロンプト技術の 1 つで、LLM に対して最終的な答えだけでなくその答えに至るまでの思考プロセスを段階的に説明するようにプロンプトで指示することで、複雑な問題に対する回答精度を向上させる手法のことです。
具体的には、以下のようなイメージです。(あくまでただのプロンプト技術の 1 つです)
ロジャーはテニスボールを 5 個持っています。彼はさらにテニスボールの缶を 2 つ買いました。それぞれの缶にはテニスボールが 3 個入っています。彼は今、テニスボールを何個持っていますか?
答えは 10 個です。(※内部で計算過程を持たないため、文脈によっては「2+3+5=10」などの単純ミスをすることがある)
Zero-shot CoT(CoT 指示だけで例はなし)
ロジャーはテニスボールを 5 個持っています。彼はさらにテニスボールの缶を 2 つ買いました。それぞれの缶にはテニスボールが 3 個入っています。彼は今、テニスボールを何個持っていますか?ステップバイステップで考えて回答してください。
ロジャーは最初に 5 個のボールを持っていました。1 缶に 3 個入っている缶を 2 つ買いました。つまり、新しく増えたボールは 3 × 2 = 6 個です。最初持っていた 5 個に、新しい 6 個を足します。5 + 6 = 11。答えは 11 個です。
Few-shot CoT(思考の例あり)
【例題 1】問題:私は鉛筆を 2 本持っています。5 本入りのパックを 3 つ買いました。鉛筆は何本ですか?思考:まず 3 x 5 = 15 本。次に 2 + 15 = 17 本。答え:17 本です。
ロジャーはテニスボールを 5 個持っています。彼はさらにテニスボールの缶を 2 つ買いました。それぞれの缶にはテニスボールが 3 個入っています。彼は今、テニスボールを何個持っていますか?ステップバイステップで考えて回答してください。
ロジャーは最初に 5 個のボールを持っていました。1 缶に 3 個入っている缶を 2 つ買いました。つまり、新しく増えたボールは 3 × 2 = 6 個です。最初持っていた 5 個に、新しい 6 個を足します。5 + 6 = 11。答えは 11 個です。
DeepSeek-R1 においては、入力プロンプトに対する出力文(正解データ)を以下のフォーマットにします。
|special_token||special_token|
...
具体的なデータ例のイメージとしては、以下のようになります。
出力文(正解データ)
「日本の伝統的な『おもてなし』の概念を詳細に説明し、それを英語に翻訳してください。」
[SEP]
[SEP]
このようなフォーマットにして学習することで、LLM が「複雑な概念(入力プロンプト)は、まず詳細なステップで思考を深め(CoT)、最後に簡潔にまとめて回答しなければならない(summary)」という制約を学習できるようになります。
回答の最後に要約を含められているので、DeepSeek-R1-Zero で問題のあった回答の可読性の低さ(同じ文章を繰り返すなど)や言語混合(日本語と中国語がまじるなど)も改善します。
また、DeepSeek-R1 では、後段のステップで強化学習を行うのですが、初期状態のベースモデルのままから強化学習で報酬を最大化しようとすると、すぐに最適でない出力(例:無意味なテキスト出力を大量に生成する、ランダムに長いテキストを生成する)に陥りやすく、学習が不安定化したり loss 収束に非常に長い時間がかかったりする問題があります。
そのため、上記のような独自に収集した少数(数千個レベル)の CoT [Chain of Thought] での教師ありのファインチューニング用データセットで DeepSeek-V3-Base をファインチューニングすることで、後段で行う強化学習における学習初期の不安定性を防ぎ、モデルに人間が望む基本的な出力を教え込みことができるようです。
GRPO [Group Relative Policy Optimization] での強化学習とルールベースの報酬システム
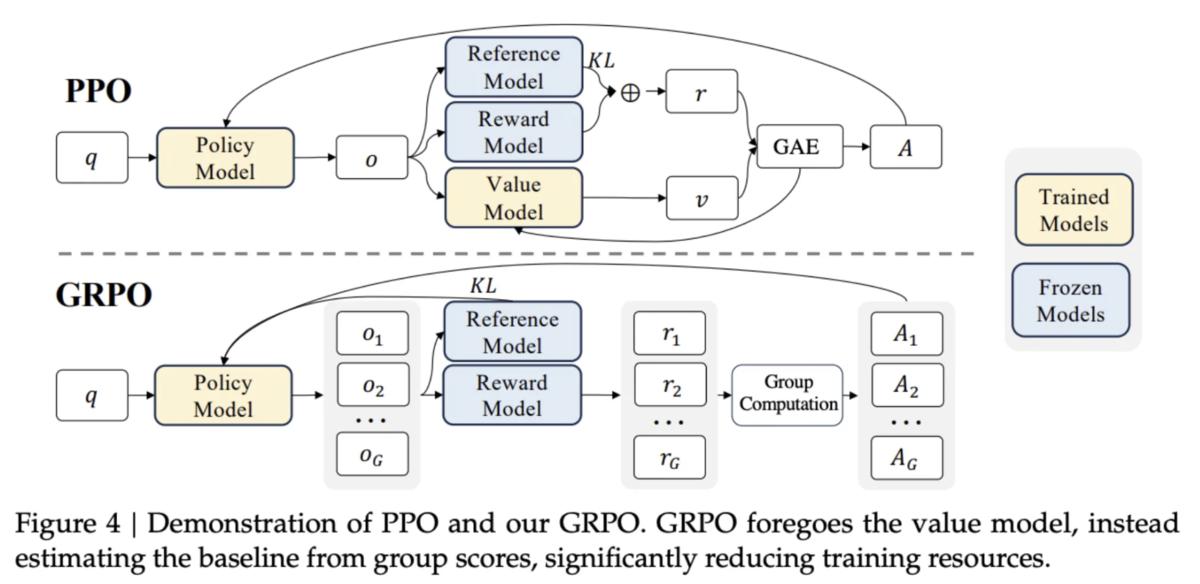 論文「DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models」から引用
論文「DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models」から引用
強化学習手法としては、GPT 等で使用されている PPO [Proximal Policy Optimization Algorithms] ではなく、GRPO [Group Relative Policy Optimization] を使用します。
一般的に、アクター・クリティック手法での強化学習では方策モデル(学習したい LLM)とクリティックモデル(評価用 LLM)の両方が必要ですが、GRPO ではクリティックモデル(評価用 LLM)を不要とすることでモデル学習時の計算コスト(GPU メモリや学習時間)を軽減した手法になります。
具体例には、以下の手順で学習を行います
上記ステップでのファインチューニングモデル(Policy Model)から複数の回答候補(o1, o2, …)を取得
各回答候補の報酬(r1, r2, …)を Reward Model でそれぞれ計算する 但し、DeepSeek-R1 ではこの部分の Reward Model での報酬計算は、評価用 LLM での報酬計算ではなく、後述のルールベースの報酬になります
各報酬(r1, r2, …)の平均値をベースラインとして採用し、各回答のアドバンテージ(A1, A2, …)を計算 アドバンテージとは、グループ内の平均(ベースライン)と比べてどれだけ優れているかを表す指標スコアのようなものです
ファインチューニングモデル(Policy Model)からの回答の確率分布と元のモデル(Reference Model)からの回答の確率分布との間で KL ダイバージェンスを計算 KL ダイバージェンスとは、2 つの確率分布間の距離指標です。KL ダイバージェンスによる制約により、学習後のモデルが学習前から大きく変化しすぎないように抑制をかけながら学習します
アドバンテージと KL ダイバージェンスから最終的な損失関数を計算して学習
数式で書くと以下のようになります。
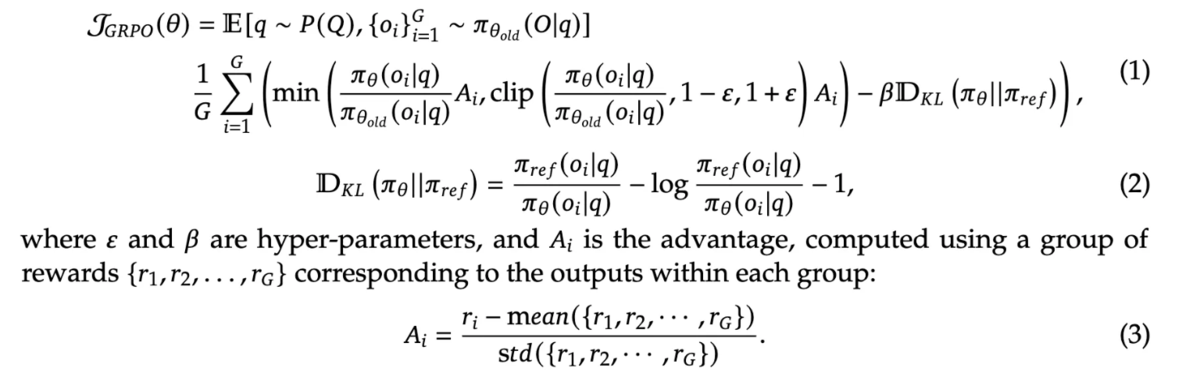 論文「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」からの引用
論文「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」からの引用
さて、大規模言語モデル(LLM)における強化学習では、以下の記事のように、生成された文章の良し悪しをスコア化する別の LLM が Reward Model と呼ばれて使用されてきました。そしてこの Reward Model から得られる報酬が最大化されるようにモデルが学習されてきました。
tech-blog.abeja.asia
しかしながらこの方法では、そもそもの Reward Model が、上記ブログで述べているように人間による好み・有用性・無害性でアノテーションした学習用データセットで学習したモデルであるため、「不自然だが(学習用データセットにある)人間による好み・有用性・無害性の観点で高評価を得られる出力」を生成するようになるといった、いわゆる「報酬ハッキング」が起こりやすくなるといった問題があります。
そのため DeepSeek-R1 では、Reward Model による報酬ではなく、ルールベースで決めた報酬を使用します。より詳細には、以下の 3 つのルールベースの報酬を使用します。(GRPO での強化学習というより、このルールベースでの報酬システムがより重要なポイントになります。)
Accuracy rewards(精度報酬)
ルールベースで報酬を決定するには、回答が明確で確定的であることが必要になってくるため、数学やコーディング問題といった回答が明確なタスクに限定します。数学やコーディングタスクに限定しても、LLM の根幹的な論理構造を強化するため、他の一般的な質疑応答タスクの汎化性能も向上させることができます。
最終回答が指定形式(例:ボックス内 [xxx])であること。
x2 - 5x + 6 = 0 の解のうち、最大のものはいくつですか?途中の計算も示してください。
この二次方程式を解くために、因数分解を行います。(x-2)(x-3) = 0 となります。よって、解は x=2 と x=3 です。最大の解は 3 です。最終回答: [3]
CoT(Chain-of-Thought:思考の連鎖)も含む回答テキスト全体から、[xxx] の形式で抽出された最終回答が一致しているかを確認します。
コーディングタスクの場合は、モデルが生成したコードをコンパイラで実行し、事前定義されたテストケースをすべてパスするかどうかを検証し報酬を決めます。
モデルに CoT(Chain-of-Thought:思考の連鎖)ありでの望ましい構造で出力させることを目的とした報酬です。具体的には、以下のようにモデルが思考プロセス(CoT)を「
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
ユーザーとアシスタントの会話。ユーザーが質問をし、アシスタントがそれを解決します。アシスタントはまず頭の中で推論プロセスについて考え、その後ユーザーに答えを提供します。推論プロセスと答えはそれぞれ
Language Consistency reward
DeepSeek-R1-Zero でも Accuracy rewards と Format rewards のルールベース報酬とする GRPO での強化学習は行っていますが、DeepSeek-R1-Zero では言語混同(日本語と中国語が入るなど)の問題がありました。
そのため、DeepSeek-R1 では追加で Language Consistency Reward という言語混同を軽減させるためのルールベースの報酬も追加しています。具体的には、出力テキストの CoT 部分のテキストに関して、出力したい言語(日本語など)になっている単語の割合として報酬を計算します。
最近では、このように検証可能な報酬ルールに基づく強化学習(RL)のことを、RLVR [RL with Verifiable Rewards] といったりします
学習済みモデルで生成したデータセットと DeepSeek-V3 用データセットでのファインチューニング
次に、上記の強化学習での学習済みモデルから高品質なデータセット(約60万件)を生成(推論)し、これに DeepSeek-V3 用のデータセット(約20万件の汎用タスク用データ)を加えたデータセットで追加の大規模ファインチューニングを実行し、更に品質を向上させます。
この追加の大規模ファインチューニングにより、上記の CoT データセットのファインチューニングやルールベースの強化学習によりモデルが失った可能性のある DeepSeek-V3 データセット由来の汎用的な振る舞い(文章作成、ロールプレイ、JSON 出力など)の品質を改善します。
最終的なリファインメントの強化学習
最後に、より人間の好む回答(有用性・無害性など)になるようにモデルを最終調整する強化学習を行います
学習済みモデルで生成したデータの場合
上記ルールベースの報酬で強化学習
DeepSeek-V3 用データの場合
報酬モデル(DeepSeek-V3 のモデル?)から取得した報酬で強化学習
DeepSeek-R1 の蒸留モデル
DeepSeek-R1 は、GPU メモリを多く必要とする大規模 LLM になるのですが、より軽量な環境でも動かせるように、DeepSeek-R1 を教師モデルとし、OSS のモデルである Qwen と Llama のモデル(具体的には、Qwen2.5-Math-1.5B
Qwen2.5-Math-7B
Llama-3.3-70B-Instruct
ここでの蒸留では、DeepSeek-R1(教師モデル)から生成した推論データ(80万件)で生徒モデル(Qwen と Llama)をファインチューニングし知識転移するのみで、強化学習等は行っていません。
なお蒸留という手法は、DeepSeek とかで一躍有名になったかもしれませんが、この手法自体は昔(10年くらい前)から存在する手法で、LLM 以外でも広く活用されてきた技術です。
LLM の文脈におけるこの手法とは、高性能な教師モデル(今回の場合は DeepSeek-R1)を用いて入力プロンプトに対する回答(正解データ)を生成・推論し、そのデータでより軽量な生徒モデル(今回の場合、Qwen や Llama)を学習させることで、教師モデルが持つ知識を生徒モデルへ転移させ、軽量な生徒モデルの品質を向上させるアプローチです。
この際の損失関数としては、最も一般的なロジット蒸留の場合、KL ダイバージェンス(Kullback-Leibler divergence:2 つの確率分布間の距離を示す指標)を用いた損失関数などで学習が行われます。蒸留の文脈では、教師モデルが出力する回答の確率分布と生徒モデルが出力する回答の確率分布という 2 つの確率分布間の距離を最小化するように学習されるため、結果として生徒モデルが教師モデルの回答に近づくように訓練されます。
教師モデルで推論を行いながら正解データを生成するため、アノテーション(注釈)済みの学習用データセットが存在しなくても、モデルを学習することが可能です。
ただし当然のことながら、教師モデルから生成されるデータが正確でなければ誤ったデータで学習されてしまうため、教師モデルの品質が極めて重要となります。
DeepSeek-R1 蒸留モデルには、それぞれ以下のようなものがあります。
DeepSeek-R1-Distill-Qwen-1.5B
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Llama-8B
DeepSeek-R1-Distill-Llama-70B
なお、ABEJA においても蒸留技術を活用した軽量 LLM の開発を行っております。是非こちらの記事もご覧ください。
tech-blog.abeja.asia
tech-blog.abeja.asia
DeepSeek-R1 の品質比較
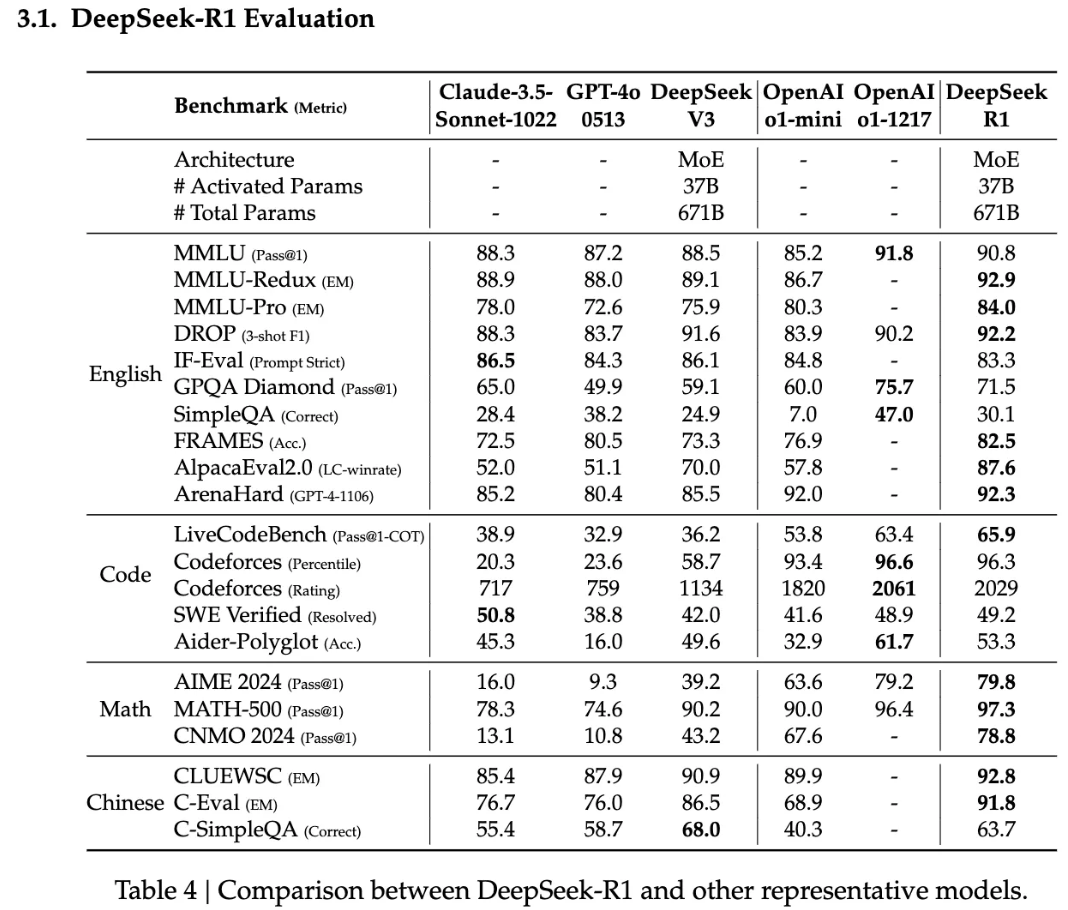 論文「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」より引用
論文「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」より引用
数学タスクのベンチマーク(AIME 2024, MATH-500 など)において、論文発表当時の米国大手 IT 企業の中規模系モデル(OpenAI-o1-mini, Claude-3.5-Sonnet-1022 など)と比較して、英語や中国語での各種ベンチマーク(MMLU の大学レベルの知識や専門知識を問うベンチマークなど)においても、DeepSeek-R1 のほうが全体的に高い品質スコアを実現している傾向が見られます。
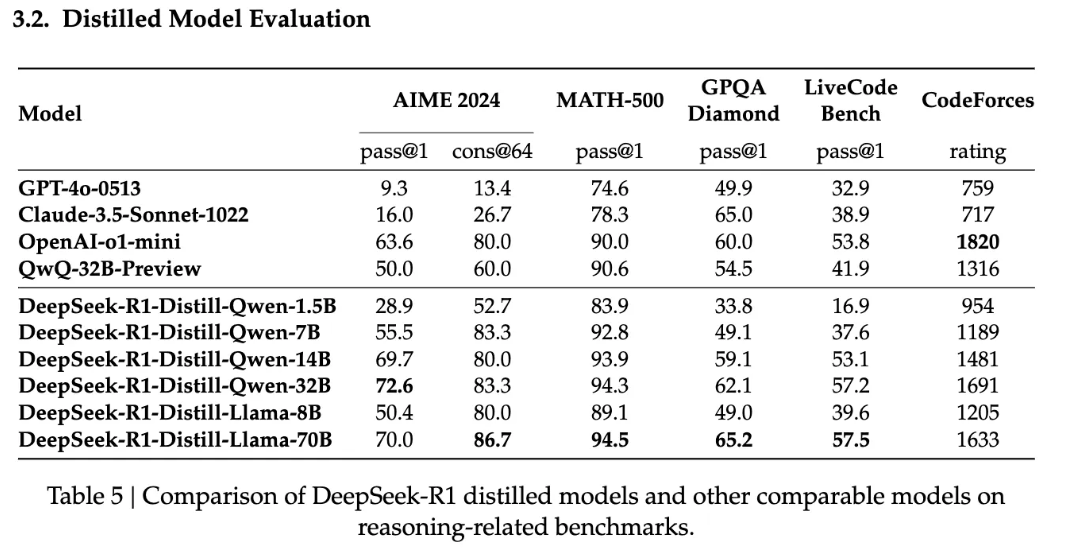 論文「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」より引用
論文「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」より引用
数学タスクのベンチマーク(AIME 2024, MATH-500)において、Qwen の中規模系モデル(QwQ-32B-Preview など)や Claude-3.5-Sonnet-1022 と比較した結果です。
論文を読む前は、DeepSeek-R1 は蒸留(ディストillation)を用いて軽量化しただしの LLM と認識していましたが、蒸留は機械学習において昔から使われている手法であり、蒸留×LLM だけなら誰でも考えつくことだし、他にもやっている人がいるのではと思っていました。論文を読んでみると、単に蒸留モデルを開発しただけではなく、様々な工夫を凝らして学習コストや品質の改善を図った大規模教師モデルも開発していることがわかりました。
LLM モデルは次々と新しいものが発表されるので内部の仕組みを詳しく見る必要性は正直あまりないのですが、個人的な動機として、中国発の LLM モデルをまだ一度も詳しく見たことがなく、有名なモデルを一度詳細レベルで調査することで、中国の技術レベルや将来性を把握しておきたかったというのがあります。今回 DeepSeek-R1 について正確に把握できて良かったです。
ABEJA は、テクノロジーの社会実装に取り組んでいます。技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください!(新卒の方やインターンシップのエントリーもお待ちしております!)careers.abejainc.com
特に下記ポジションの募集を強化しています!ぜひ御覧ください!
トランスフォーメーション領域:データサイエンティスト
トランスフォーメーション領域:データサイエンティスト(ミドル)
トランスフォーメーション領域:データサイエンティスト(シニア)
原文を表示
こんにちは!ABEJA で ABEJA Platform 開発や AI 関連の研究開発業務を行っている坂井(@Yagami360)です。 こちらはABEJAアドベントカレンダー2025の24日目の記事です。
今年のはじめ頃、中国の DeepSeek 社から非常に軽量かつ品質の高い LLM が公開され、H100, A100 などの超高価な NVIDIA 製 GPU がなくとも動かせるということで、株価への影響等含めて話題になりました。
この記事書く前の話になりますが、自分としては蒸留使って軽量化した LLM というイメージしかもってなく、とはいえ蒸留って手法は昔から使われてきた手法であり、既存手法の延長線上にも見えるため DeepSeek が米国大手ビックテックに先んじて蒸留で大幅軽量化した高品質な LLM を発表したのは意外だなあ程度の認識しかもってませんでした。
かなり今更にはなりますが、幸い論文が公開されているようなので、ここらへんの実体を正確に把握しておきたいと思い、DeepSeek-R1 の論文を読んでみました。
DeepSeek-R1 の論文は、以下で公開されています。
DeepSeek-R1 ベースモデル
CoT データセットでのファインチューニング
GRPO での強化学習とルールベースの報酬システム
学習済みモデルで生成したデータセットと DeepSeek-V3 用データセットでのファインチューニング
最終的なリファインメントの強化学習
DeepSeek-R1 の蒸留モデル
DeepSeek-R1 の論文で述べられている各モデルや手法の流れを図示すると、以下のようになります。
太字で示している箇所が、特に重要な箇所になります。
DeepSeek-R1 の論文で述べられているモデルとしては、DeepSeek-R1-Zero と DeepSeek-R1、及び DeepSeek-R1 の蒸留モデル群があります。
このうち DeepSeek-R1-Zero に関しては、出力されるテキストの可読性の低さ(同じ文章を繰り返すなど)や異なる言語で回答してしまう(日本語と中国語が入るなど)といった課題があり、それを追加の手法で解決したのが DeepSeek-R1 になるため、このブログでは DeepSeek-R1 のみ解説し、説明の煩雑さを省きたいと思います。
前提として DeepSeek-R1 は、モデル内部のネットワーク構造の改善を行ったモデルではないです。 内部のネットワーク構造としては、同じく DeepSeek 社が開発した「DeepSeek-V3-Base」をそのまま使用しています(ベースモデルとして利用しています)
論文「DeepSeek-V3 Technical Report」より引用
CoT データセットでのファインチューニング
DeepSeek-R1 ではまず、独自に収集した少数(数千個レベル)のCoT [Chain-of-Thought] 付きの教師ありファインチューニング用データセットで上記ベースモデル(DeepSeek-V3-Base)をファインチューニングします。
CoT [Chain-of-Thought] というのは、プロンプト技術の1つで、LLM に対して最終的な答えだけでなくその答えに至るまでの思考プロセスを段階的に説明するようにプロンプトで指示することで、複雑な問題に対しての回答精度を向上させる手法のことです。
具体的には、以下のようなイメージです。(あくまでただのプロンプト技術の1つです)
ロジャーはテニスボールを5個持っています。彼はさらにテニスボールの缶を2つ買いました。それぞれの缶にはテニスボールが3個入っています。彼は今、テニスボールを何個持っていますか?
答えは 10個です。(※内部で計算過程を持たないため、文脈によっては「2+3+5=10」などの単純ミスをすることがある)
Zero-shot CoT(CoT 指示だけで例はなし)
ロジャーはテニスボールを5個持っています。彼はさらにテニスボールの缶を2つ買いました。それぞれの缶にはテニスボールが3個入っています。彼は今、テニスボールを何個持っていますか? ステップバイステップで考えて回答してください。
ロジャーは最初に5個のボールを持っていました。1缶に3個入っている缶を2つ買いました。つまり、新しく増えたボールは 3 × 2 = 6個 です。最初持っていた5個に、新しい6個を足します。5 + 6 = 11。 答えは11個です。
Few-shot CoT(思考の例あり)
【例題1】 問題:私は鉛筆を2本持っています。5本入りのパックを3つ買いました。鉛筆は何本ですか?思考:まず 3 x 5 = 15 本。次に 2 + 15 = 17 本。答え:17本です。 ロジャーはテニスボールを5個持っています。彼はさらにテニスボールの缶を2つ買いました。それぞれの缶にはテニスボールが3個入っています。彼は今、テニスボールを何個持っていますか? ステップバイステップで考えて回答してください。
ロジャーは最初に5個のボールを持っていました。1缶に3個入っている缶を2つ買いました。つまり、新しく増えたボールは 3 × 2 = 6個 です。最初持っていた5個に、新しい6個を足します。5 + 6 = 11。 答えは11個です。
DeepSeek-R1 においては、入力プロンプトに対する出力文(正解データ)を以下のフォーマットにします。
|special_token|<reasoning_process>|special_token|<summary>
<reasoning_process>
<think>...</think>
具体的なデータ例のイメージとしては、以下のようになります。
出力文(正解データ) <special_token><reasoning_process><special_token><summary>
「日本の伝統的な『おもてなし』の概念を詳細に説明し、それを英語に翻訳してください。」
[SEP]<reasoning_process>
</reasoning_process>[SEP]<summary>
このようなフォーマットにして学習することで、LLM が「複雑な概念(入力プロンプト)は、まず詳細なステップで思考を深め(CoT)、最後に簡潔にまとめて回答しなければならない(summary)」という制約を学習できるようになります。
回答の最後に要約を含められているので、DeepSeek-R1-Zero で問題のあった回答の可読性の低さ(同じ文章を繰り返すなど)や言語混合(日本語と中国語がまじるなど)も改善します。
また、DeepSeek-R1 では、後段のステップで強化学習を行うのですが、初期状態のベースモデルのままから強化学習で報酬を最大化しようとすると、すぐに最適でない出力(例:無意味なテキスト出力を大量に生成する、ランダムに長いテキストを生成する)に陥りやすく、学習が不安定化したり loss 収束に非常に長い時間がかかったりする問題があります。
そのため、上記のような独自に収集した少数(数千個レベル)のCoT での教師ありのファインチューニング用データセットで DeepSeek-V3-Base をファインチューニングすることで、後段で行う強化学習における学習初期の不安定性を防ぎ、モデルに人間が望む基本的な出力を教え込みことができるようです。
GRPO での強化学習とルールベースの報酬システム
論文「DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models」から引用
強化学習手法としては、GPT 等で使用されている PPO [Proximal Policy Optimization Algorithms] ではなく、GRPO [Group Relative Policy Optimization] を使用します。
一般的に、アクター・クリティック手法での強化学習では方策モデル(学習したいLLM)とクリティックモデル(評価用LLM)の両方が必要ですが、GRPO ではクリティックモデル(評価用LLM)を不要とすることでモデル学習時の計算コスト(GPUメモリや学習時間)を軽減した手法になります。
具体例には、以下の手順で学習を行います
上記ステップでのファインチューニングモデル(Policy Model)から複数の回答候補(o1, o2, …)を取得
各回答候補の報酬(r1, r2, …)を Reward Model でそれぞれ計算する 但し、DeepSeek-R1 ではこの部分の Reward Model での報酬計算は、評価用 LLM での報酬計算ではなく、後述のルールベースの報酬になります
各報酬(r1, r2, …)の平均値をベースラインとして採用し、各回答のアドバンテージ(A1, A2, …)を計算 アドバンテージとは、グループ内の平均(ベースライン)と比べてどれだけ優れているかを表す指標スコアのようなものです
ファインチューニングモデル(Policy Model)からの回答の確率分布と元のモデル(Reference Model)からの回答の確率分布との間で KL ダイバージェンスを計算 KLダイバージェンスとは、2つの確率分布間の距離指標です。KL ダイバージェンスによる制約により、学習後のモデルが学習前から大きく変化しすぎないように抑制をかけながら学習します
アドバンテージと KL ダイバージェンスから最終的な損失関数を計算して学習
数式で書くと以下のようになります。
論文「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」から引用
さて、LLM における強化学習では、以下の記事のように、Reward Model と呼ばれる生成したモデルの文章の良し悪しをスコア化する別の LLM が使用されてきました。そしてこの Reward Model から得られる報酬が最大化されるようにモデルが学習されてきました。
tech-blog.abeja.asia
しかしながらこの方法では、そもそもの Reward Model が、上記ブログで述べているように人間による好み・有用性・無害性でアノテーションした学習用データセットで学習したモデルであるため、「不自然だが(学習用データセットにある)人間による好み・有用性・無害性で意味で高評価を得られる出力」を生成するようになるといった所謂「報酬ハッキング」が起こりやすくなるといった問題があります。
そのため DeepSeek-R1 では、Reward Model による報酬ではなく、ルールベースで決めた報酬を使用します。 より詳細には、以下の3つのルールベースの報酬を使用します。 (GRPO での強化学習というより、このルールベースでの報酬システムがより重要なポイントになります。)
Accuracy rewards
ルールベースで報酬決めるには、回答が明確で確定的であることが必要になってくるため、数学やコーディング問題といった回答が明確なタスクに限定します。 数学やコーディングタスクに限定しても、LLM の根幹的な論理構造を強化するため、他の一般的な質疑応答タスクの汎化性能も向上させることができます。
最終回答が指定形式(例:ボックス内 [xxx]
x2 - 5x + 6 = 0 の解のうち、最大のものはいくつですか?途中の計算も示してください。
この二次方程式を解くために、因数分解を行います。(x-2)(x-3) = 0 となります。よって、解は x=2 と x=3 です。最大の解は3です。最終回答: [3]
CoT も含む回答テキスト全体から、[xxx]
コーディングタスクの場合は、モデルが生成したコードをコンパイラで実行し、事前定義されたテストケースをすべてパスするかどうかを検証し報酬を決めます。
モデルに CoT [Chain-of-Thought] ありでの望ましい構造で出力させることを目的とした報酬です。 具体的には、以下のようにモデルが思考プロセス(CoT)を「<think>
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think>
ユーザーとアシスタントの会話。ユーザーが質問をし、アシスタントがそれを解決します。アシスタントはまず頭の中で推論プロセスについて考え、その後ユーザーに答えを提供します。推論プロセスと答えはそれぞれ <think>
Language Consistency reward
DeepSeek-R1-Zero でも Accuracy rewards と Format rewards のルールベース報酬とする GRPO での強化学習は行っていますが、DeepSeek-R1-Zero では言語混同(日本語と中国語が入るなど)の問題がありました。
そのため、DeepSeek-R1 では追加で Language Consistency Reward という言語混同を軽減させるためのルールベースの報酬も追加しています。 具体的には、出力テキストの CoT 部分のテキストに関して、出力したい言語(日本語など)になっている単語の割合として報酬を計算します。
最近では、このように検証可能な報酬ルールに基づく強化学習(RL)のことを、RLVR [RL with Verifiable Rewards] といったりします
学習済みモデルで生成したデータセットと DeepSeek-V3 用データセットでのファインチューニング
次に、上記の強化学習での学習済みモデルから高品質なデータセット(約60万件)を生成(推論)し、これに DeepSeek-V3 用のデータセット(約20万件の汎用タスク用データ)を加えたデータセットで追加の大規模ファインチューニングを実行し、更に品質を向上させます。
この追加の大規模ファインチューニングにより、上記の CoT データセットのファインチューニングやルールベースの強化学習によりモデルが失った可能性のある DeepSeek-V3 データセット由来の汎用的な振る舞い(文章作成、ロールプレイ、JSON 出力など)の品質を改善します。
最終的なリファインメントの強化学習
最後に、より人間の好む回答(有用性・無害性など)になるようにモデルを最終調整する強化学習を行います
学習済みモデルで生成したデータの場合
上記ルールベースの報酬で強化学習
DeepSeek-V3 用データの場合
報酬モデル(DeepSeek-V3 のモデル?)から取得した報酬で強化学習
DeepSeek-R1 の蒸留モデル
DeepSeek-R1 は、GPU メモリを多く必要とする大規模 LLM になるのですが、より軽量な環境でも動かせるように、DeepSeek-R1 を教師モデルとし、OSS のモデルである Qwen と Llama のモデル(具体的には、Qwen2.5-Math-1.5B
Qwen2.5-Math-7B
Llama-3.3-70B-Instruct
ここでの蒸留では、DeepSeek-R1(教師モデル)から生成した推論データ(80万件)で生徒モデル(Qwen と Llama)をファインチューニングし知識転移するのみで、強化学習等は行っていません。
なお蒸留という手法は、DeepSeek とかで一躍有名になったかもしれませんが、この手法自体は昔(10年くらい前)から存在する手法で、LLM 以外でも広く活用されてきた技術です。
LLM の文脈でいうと、高性能な教師モデル(今回の場合は DeepSeek-R1)で入力プロンプトに対する回答(正解データ)を生成(推論)し、そのデータでより軽量な生徒モデル(今回の場合、Qwen や Llama)を学習することで、教師モデルのもつ知識を生徒モデルに知識転移し、軽量生徒モデルの品質を改善する手法になります。
この際の損失関数としては、最も一般的なロジット蒸留の場合で、KL ダイバージェンスの損失関数などで学習します。(KLダイバージェンスとは、2つの確率分布間の距離指標です。蒸留の文脈では、教師モデルが出力する回答の確率分布と生徒モデルが出力する回答の確率分布という2つの確率分布間の距離を最小化されるように学習されるので、生徒モデルが教師モデルの回答に近くなるように学習されます)
教師モデルで推論しながら正解データを生成するので、正解データがアノテーションされている学習用データセットがなくともモデルを学習することができます。
ただし当然ですが、教師モデルから生成するデータが正しくなければ誤ったデータで学習されてしまうので、教師モデルの品質が重要になります。
DeepSeek-R1 蒸留モデルは、それぞれ DeepSeek-R1-Distill-Qwen-1.5B
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Llama-8B
DeepSeek-R1-Distill-Llama-70B
尚、ABEJA においても蒸留を使用した軽量 LLM の開発を行っております。是非こちらの記事を見てもらえればと思います
tech-blog.abeja.asia
tech-blog.abeja.asia
DeepSeek-R1 の品質比較
論文「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」より引用
数学タスクのベンチマーク(AIME 2024, MATH-500 など)において、論文発表当時の米国大手 IT の中規模系モデル(OpenAI-o1-mini
Claude-3.5-Sonnet-1022
英語や中国語での各種ベンチマーク(MMLU の大学レベルの知識や専門知識のベンチマークなど)においても、DeepSeek-R1 のほうが全体的に高い傾向の品質スコアを実現しているようです。
論文「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」より引用
数学タスクのベンチマーク(AIME 2024, MATH-500)において、Qwen の中規模系モデル(QwQ-32B-Preview
Claude-3.5-Sonnet-1022
論文読む前は、DeepSeek-R1 は蒸留使って軽量化しただけの LLM という認識で、でも蒸留って機械学習で昔から使われている手法であるし、蒸留 x LLM だけなら誰でも考えつくし他にもやっている人いるのではと思っていました。論文読んでみると、単に蒸留モデル開発しただけではなく、様々な工夫で学習して学習コストや品質改善した大規模教師モデルも開発していることがわかりました。
LLM モデルは次々と新しいモデルが発表されるので内部の仕組みを詳しくみる必要性は正直あまりないのですが、個人的な動機として、中国発のLLMモデルをまだ一度も詳しく見たことがなく、有名なモデルを一度詳細レベルで調査することで、中国の技術レベルとか将来性を把握しておきたかったというのがあります。今回 DeepSeek-R1 について正確に把握できて良かったです。
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!) careers.abejainc.com
特に下記ポジションの募集を強化しています!ぜひ御覧ください!
トランスフォーメーション領域:データサイエンティスト
トランスフォーメーション領域:データサイエンティスト(ミドル)
トランスフォーメーション領域:データサイエンティスト(シニア)
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み