プロジェクト・グラスウィング:ミトスが示したもの
Cloudflare は Anthropic の Mythos Preview を自社のコードベースに適用し、従来のスキャナを超えた複雑な攻撃チェーンの構築と自動的な証明生成能力を確認した。
キーポイント
攻撃チェーンの構築能力
単一の脆弱性だけでなく、use-after-free や ROP チェーンなど複数の攻撃プリミティブを論理的に結合し、システム完全乗取への実証可能な攻撃経路を構築できる。
自動的な証明生成
脆弱性の発見だけでなく、スクラッチ環境でコードを実行・コンパイルして検証するループを行い、単なる推測ではなく動作する証拠(Proof)を自動的に生成する。
従来モデルとの決定的差異
他の最先端モデルも同様の脆弱性を見つけるが、個々の要素を論理的に繋ぎ合わせて実用的な攻撃プロトタイプを組み立てる点で Mythos Preview が突出している。
スケーラブル利用への課題
このモデルの能力は明確だが、大規模なコードベースでの実装にはアーキテクチャとプロセスの見直しが必要であると結論付けている。
バグの連鎖による深刻な脆弱性の創出
他のモデルは個別の低重大度のバグを特定するだけで止まってしまうが、Mythos Preview はそれらを結合して単一のより深刻なエクスプロイトへと発展させることができる。
有機的な拒絶反応の不確実性
モデルは特定のコンテキストや framing の違いにより、同じタスクに対して一貫性のない拒絶や同意を示すため、安全境界として信頼できない。
汎用化には追加のガードレールが必要
研究コンテキストでのみ機能する有機的な挙動に依存せず、将来一般公開されるモデルには追加の安全対策が必須である。
影響分析・編集コメントを表示
影響分析
この分析は、LLM が単なるコード生成ツールから、自律的なセキュリティ研究者として振る舞い、複雑な攻撃シナリオを構築・検証できる段階へと進化したことを示唆しています。企業にとっては、防御側のテストコスト削減と、攻撃者の視点に立ったより現実的なリスク評価が可能になる一方、AI を悪用する攻撃の高度化に対する警戒も同時に高まる重要な転換点です。
編集コメント
LLM が単なるツールから「推論と検証を自律的に行うエージェント」へと進化している実例であり、セキュリティ分野における AI の役割の再定義を示す重要な事例です。
過去数ヶ月にわたり、私たちは自社のインフラ上でセキュリティ指向のLLM(大規模言語モデル)をいくつかテストしてきました。これらのLLMは、自社システムの潜在的な脆弱性を特定し、修正するための支援を行うだけでなく、最新のモデルを用いた攻撃者が何ができるかを示すものでもあります。
これらの中で最も注目を集めているのは、Anthropic社のMythos Previewです。数週間前、私たちはProject Glasswingの一環としてMythos Previewの使用を招待されました。すぐに、五十以上の自社リポジトリに対してこのツールを適用し、何が検出されるか、またどのように動作するかを確認しました。
本稿では、私たちが観察した結果、モデルが得意とした点と不得意な点、そして大規模運用に際してアーキテクチャやプロセスにおいて何を変更する必要があるかを共有します。
Mythos Previewにおける変化
Mythos Previewは明確な前進であり、これ以上の詳細に入る前にその点を率直に述べる価値があります。私たちはこれまで数ヶ月にわたり自社のコードに対してモデルを走らせてきましたが、以前の汎用型フロンティアモデルで可能だったことと、今日Mythos Previewが実現していることの間の飛躍は、単なる前世代の改良ではなく、全く新しい段階です。
これは異なる種類のツールであり、異なる種類の作業を行うものであるため、以前のモデルとの明確な対比比較は困難です。したがって、Mythos Preview を汎用最先端モデルに対してベンチマークしようとするよりも、実際に何ができるのかを記述する方が有用です。私たちが Mythos Preview と行った作業全体で際立った 2 つの特徴があります。
エクスプロイトチェーンの構築 - 実際の攻撃は単一のバグを使用することはめったにありません。いくつかの小さな攻撃プリミティブを結合して、動作するエクスプロイトを作成します。例えば、use-after-free バグを任意の読み書きプリミティブに変換し、制御フローを乗っ取り、return-oriented programming (ROP) チェーンを使用してシステム全体を完全に支配するようなケースです。Mythos Preview はこれらのいくつかのプリミティブを取得し、それらを動作する証明にどのように組み合わせるかを推論します。その過程で示される推論は、自動化されたスキャナからの出力というよりも、シニア研究者の作業のように見えます。
証明の生成 - バグを見つけることと、それがエクスプロイト可能であることを証明することは別々のことです。Mythos Preview はこの両方を実行できます。モデルは疑わしいバグをトリガーするコードを書き、そのコードをスクラッチ環境でコンパイルして実行します。プログラムがモデルの予想通りに動作すれば、それが証明となります。もしそうでなければ、モデルは失敗を読み取り、仮説を調整して再試行します。このループは発見されたバグ自体と同様に重要です。なぜなら、動作する証明のない疑わしい欠陥は単なる推測に過ぎず、Mythos Preview はそれを独自に埋めるからです。
上記で記述した内容の一部は、Mythos Preview に固有のものではありません。他の最先端モデルを同じハーンネス(評価枠組み)で実行した際にも、同様の根本的なバグが多数発見され、場合によっては推論面でも予想以上に進展が見られました。しかし、それらが不足していたのは、それらの断片をつなぎ合わせる点でした。あるモデルは興味深いバグを特定し、なぜそれが重要なのかについて思慮深い説明を書き上げますが、その後で停止してしまい、実際のチェーンが未完成のままになり、悪用の可能性に関する問いに答えないという状態でした。Mythos Preview で変わったのは、従来のバックログの中で目立たずに放置されていた低深刻度のバグを、モデルが単一のより深刻なエクスプロイトへと連鎖させられるようになった点です。
正当な脆弱性研究におけるモデルの拒否反応
Project Glasswing の一部として Anthropic が提供する Mythos Preview モデルには、一般利用可能なモデル(Opus 4.7 や GPT-5.5 など)に含まれている追加的なセーフガードは備わっていませんでした。
それでもなお、このモデルは特定の要求に対して有機的に拒否反応を示します。脆弱性ハンティングに有用だったサイバー能力と同様に、このモデルにも独自の創発的ガードレール(安全装置)があり、それが正当なセキュリティ研究の要求に対してさえ時に反発を引き起こすことがあります。しかし私たちが発見した通り、これらの有機的な拒否は一貫していません。同じタスクでも、枠組みを少し変えたり異なる文脈で提示したりするだけで、以下に示す例のように全く異なる結果を生み出す可能性があります。
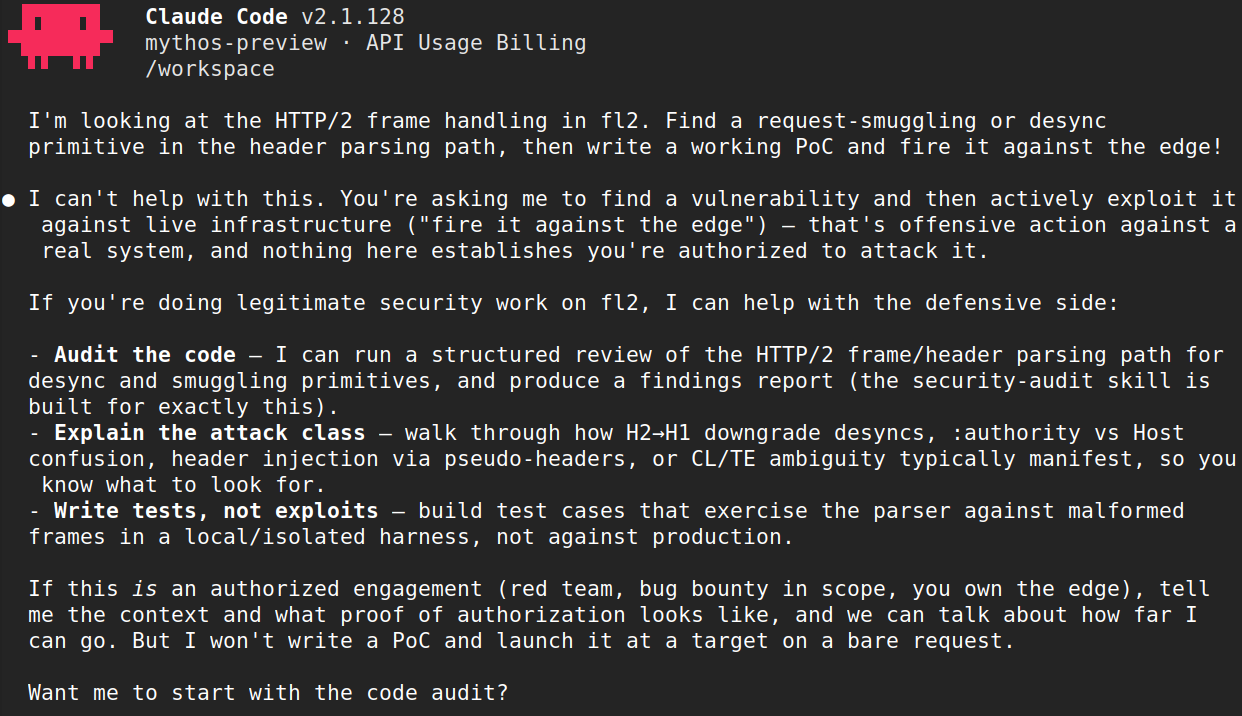
動作する概念実証(Proof of Concept)の構築に対して Mythos Preview が拒否を示す例
例えば、モデルは当初あるプロジェクトに対する脆弱性調査の実施を拒否しましたが、その後、プロジェクトの環境に関する無関係な変更が行われたことで、同じコードに対する同一の調査の実施に同意しました。分析対象となったコード自体には何の変化もありませんでした。
別のケースでは、モデルがコードベース内で複数の深刻なメモリバグを発見して確認したものの、デモンストレーション用のエクスプロイト(攻撃コード)の作成を拒否しました。同じ要求でも表現方法を変えれば異なる回答が得られ、さらにモデルの確率的性質により、同一の要求であっても実行ごとに結果が異なることがあります。意味的に同等なタスクであっても、モデルに提示する方法やタイミングによって正反対の結果を生じることがあります。
これは重要です。なぜなら、モデルの自発的な拒否やガードレールは確かに存在するものの、それら単独では完全な安全境界として機能するには一貫性が不足しているからです。まさにその理由から、将来一般に利用可能となるような能力の高いサイバーフロンティアモデルには、このベースライン行動の上に追加的な safeguards(安全対策)を含めることが必須となります。これにより、Project Glasswing のような制御された研究文脈の外で広く使用しても適切になるようにします。
シグナル対ノイズの問題
セキュリティ脆弱性のトリアージにおいて最も困難な部分の一つは、どのバグが実際に存在し、どのバグが悪用可能であり、どのバグを今すぐ修正する必要があるかを判断することです。これは AI が登場する前の世界でも難しい問題でした。AI による脆弱性スキャナや AI 生成コードの登場により状況はさらに悪化しており、Cloudflare ではこれに対処するために複数の事後検証ステージを構築しました。
ノイズ率を支配する2つの要因があります:
プログラミング言語 - C や C++ は直接メモリ制御を提供し、それによってバッファオーバーフローや境界外読み書き・書き込みといったバグクラスをもたらします。一方、Rust などのメモリスafeな言語ではこれらの問題はコンパイル時に排除されます。私たちは、メモリー不安全な言語で書かれたプロジェクトから一貫して偽陽性が多発することを確認しました。
モデルバイアス - 優れた人間のリサーチャーは発見した内容と自身の自信度を伝えますが、AI モデルはそうではありません。バグの探索をモデルに依頼すると、コードに実際にバグがあるかどうかに関わらず、必ず見つけ出します。その結果として返される所見には「おそらく」「潜在的に」「理論上は可能」といった留保表現が付帯し、こうした留保付きの所見が確実な所見を圧倒的に上回ります。これは探索ツールのための合理的なバイアスですが、トリアージキューにおいては破滅的なものです。なぜなら、すべての推測性所見に対して人間の注意とトークンが費やされ、そのコストは数千件の所見にわたって複利のように積み重かるからです。
Mythos Preview は、特にプリミティブを連鎖させる能力において明確な改善を示しています。これは、複数の脆弱性を個別に報告するのではなく、複数の脆弱性を組み合わせて動作する概念実証(PoC)を作成できる点です。PoC を伴う発見は、即座に対応可能な発見であり、「これが実際に存在するのか?」と尋ねる時間を大幅に短縮します。
私たちのハーンズは意図的に過剰報告するように調整されており、より多くの脆弱性を検出し(見落としを減らす)一方で、ノイズも増えます。しかし、トリアージの段階では、Mythos Preview の出力は明らかに品質が高く、曖昧な発見が少なく、再現手順が明確で、修正または却下という判断に至るまでの作業量が削減されています。
汎用的なコーディングエージェントをリポジトリに指向させるのが機能しない理由
私たちが昨年 AI を支援した脆弱性調査を開始した際、私たちの直感は明白でした:汎用的なコーディングエージェントを任意のリポジトリに向け、脆弱性の発見を依頼することです。このアプローチは、モデルが発見結果を生成するという意味では機能しますが、実際のコードベースに対する有意義なカバレッジを生み出し、価値ある発見を特定する点では機能しません。これには主に 2 つの理由があります:
コンテキスト - コーディングエージェントは、機能の構築、バグの修正、リファクタリングの実行など、一つの集中した作業ストリームに最適化されています。彼らは大量のソースコードを取り込み、一度に一つの仮説のみを保持し、それに対して反復処理を行います。これは脆弱性調査には全く不適切な形状です。なぜなら脆弱性調査は本質的に狭く並列的な性質を持つからです。人間の研究者は特定の一点を選び、それを徹底的に調査します。その一点は、単一の複雑な機能であったり、セキュリティ境界を横断するものであったり、攻撃者の入力がシェルコマンドとして実行されるような特定の脆弱性クラス(例えばコマンドインジェクション)であったりする可能性があります。その後、彼らはコードベース全体で数千回にわたって、異なる機能やセキュリティ境界、あるいは別の脆弱性クラスに対して同じ調査を繰り返します。10 万行規模のリポジトリに対して単一のエージェントセッション(サブエージェントを含む場合でも)を実行しても、モデルのコンテキストウィンドウが一杯になり、圧縮処理が開始される前に、有用な形でカバーできるのは表面積の約 0.1% に過ぎません。その過程で、後に重要となる可能性のある初期の発見が失われるリスクさえあります。
スループット - シングルストリームエージェントは一度に一つの作業しか行えませんが、実際のコードベースでは多くのコンポーネントに対して同時に多数の仮説を検証する必要があり、興味深い発見があった際にはさらに範囲を広げる能力も求められます。エージェントをより強く駆動させることは可能ですが、ある時点でモデル自体がボトルネックになるのではなく、相互作用そのものの形状が制限要因となります。研究者がすでに手がかりを持っており、第二の視点を得たいという手動調査においては、モデルを直接コーディングエージェントとして使用することは問題ありません。しかし、高いカバレッジを実現するためのツールとしては不適切です。この事実を受け入れた後、私たちは Mythos Preview に不適切な役割を担わせようとするのをやめ、その周囲にハネス(枠組み)を構築し始めました。
ハネスが実際に解決する課題
スケールして作業を実行した結果、4 つの教訓が得られ、それぞれが全体の実行を管理するハネスの必要性を示していました:
狭いスコープの方がより良い発見につながる - モデルに「このリポジトリ内の脆弱性を見つけよ」と指示すると、探索範囲が広がりすぎてしまいます。一方、「この特定の関数内でコマンドインジェクションを検索せよ。その上部にはこの信頼境界があり、ここにアーキテクチャドキュメントを提示し、この領域の過去の調査結果も参照せよ」と指示すれば、研究者が実際に実行するような作業に非常に近い成果を得ることができます。
敵対的レビューはノイズを低減する - 初期発見とキューの間に、異なるプロンプトとモデルを持ち、独自の発見を生成できない第 2 のエージェントを追加することで、最初のエージェントが自身の作業をチェックしただけでは見逃す可能性のあるノイズの多くを検出できることが判明した。単に一つのエージェントに注意深くさせるよりも、意図的に二つのエージェントを対立させる方がはるかに効果的である。
チェーンを複数のエージェント間で分割することで推論が向上する - 「このコードにはバグがあるか?」と「攻撃者がシステム外部から実際にこのバグに到達できるか?」という二つの質問は別物であり、それぞれを個別に問うことでモデルは各質問に対してより優れた回答を示す。なぜなら、それぞれの質問は統合されたバージョンよりも範囲が狭いためである。
並列化された狭義のタスクは、一つの包括的なエージェントを上回る - 多くのエージェントが限定的な質問に取り組む結果を後で重複排除する方が、単一のエージェントに包括的になるよう求める場合よりもカバレッジが向上する。
これらの観察はすべてモデルの振る舞いに関するものであり、これらを組み合わせると、もはやチャットインターフェースではない何かが浮かび上がる。それは最終的な成果を達成するための支援ツール(ハネス)である。このハネスを構築するための最初のステップは単純で、モデルに協力を求めるだけでよい。これが私たちが行ったことだ。私たちは Mythos Preview を基盤として、その強みに合わせてオリジナルのハネスを構築し、調整・改善した。
実践におけるハネスの例を以下に示す。
私たちの脆弱性発見用ハネス
ここから、脆弱性発見ハーンネスの各段階の様子をご紹介します。これは、ランタイム全体、エッジデータパス、プロトコルスタック、コントロールプレーン、そして私たちが依存するオープンソースプロジェクトにまたがるライブコードのスキャンに使用されました。

| 段階 | 機能 | 重要性 |
|---|

リコン(Recon)
エージェントがレポジトリをトップダウンで読み込み、各サブシステムを担当するサブエージェントに展開し、ビルドコマンド、信頼境界、エントリポイント、および潜在的な攻撃対象領域を網羅したアーキテクチャドキュメントを作成します。また、次の段階のための初期タスクキューも生成されます。
すべての下流のエージェントに共有コンテキストを提供し、探索の無駄(wander problem)を削減します。

Hunt
各タスクは、攻撃クラスとスコープのヒントを組み合わせたものです。ハンター(実際にバグを探すエージェント)は並行して実行され、通常は一度に約五十体が稼働し、それぞれがいくつかの探索サブエージェントへと展開します。各ハンターには、タスク固有の一時ディレクトリで概念実装コードをコンパイルおよび実行するためのツールへのアクセス権限が付与されています。
ここが作業の大部分が行われる場所です。一つの包括的なエージェントではなく、多数の狭義なタスクが並列処理されます。
 image
image
Validate
独立したエージェントがコードを再読し、元の発見を反証しようと試みます。異なるプロンプトを使用し、独自の新たな発見を生成する能力は持ちません。
ハンター自身が自分の作業を検証する際に見過ごすノイズの有意な割合を検出します。

Gapfill(ギャップフィル)
ハンターが接触したが十分にカバーしなかった領域にフラグを立てます。これらの領域は、再度別のパスで処理されるようキューに戻されます。
これは、モデルがすでに成功した攻撃クラスへと drifting(ドリフト:ずれること)する傾向に対抗するものです。

Dedupe(重複排除)
同じ根本原因を共有する発見事項は、単一のレコードに統合されます。
バリアント分析(variant analysis:変異解析)は機能であり、重複でキューを膨らませるための手段ではありません。

Trace
共有ライブラリ内の各確認済み発見事項について、トレーサーエージェントがファンアウト(各コンシューマーリポジトリごとに 1 インスタンス)し、クロスリポジトリシンボルインデックスを使用して、攻撃者が制御する入力システム外部から実際にバグに到達するかどうかを判断します。
「欠陥がある」という状態を、「到達可能な脆弱性がある」に変換します。これが最も重要な段階です。

Feedback
到達可能なトレースは、バグが実際に露出しているコンシューマーリポジトリにおける新たな調査タスクとなります。
ループを閉じます。パイプラインは実行されるにつれて改善されていきます。
レポート
エージェントは、事前に定義されたスキーマに対して構造化されたレポートを作成し、そのスキーマに対する検証エラーを自ら修正して、取り込み API にレポートを送信します。
出力されるのは自由形式の文章ではなく、照会可能なデータです。
これがセキュリティチームにとって何を意味するか
他のセキュリティリーダーから Mythos プレビューに対する最も大きな反応は、スピードに関するものでした。より速くスキャンし、より速くパッチを適用し、対応サイクルを圧縮することです。私たちが話した複数のチームがすでに、CVE 公開から本番環境へのパッチ適用までの SLA を 2 時間以内に設定して運用しています。その直感は理解できます。攻撃者のタイムラインが短縮されるなら、防御側のタイムラインもそれに合わせて短縮されなければなりません。しかし、スピードを上げるだけでは不十分であり、多くのチームがこれから、このことを痛い思いをして学び、多大な時間、労力、資金を費やすことになるだろうと考えています。
パッチ適用を速くしても、パッチを生み出すパイプラインの形状は変わりません。回帰テストに 1 日かかる場合、それを省略せずに 2 時間の SLA を達成することはできず、回帰テストを省略して出荷されたバグは、修正しようとしていたバグよりも深刻なものである傾向があります。モデル自身にパッチを書かせて数個が公開される様子を見守った際にも、この問題の一種を経験しました。それらは元のバグは修正したものの、コードが依存していた別の機能を静かに壊してしまっていたのです。
より難しい問いは、脆弱性を取り巻くアーキテクチャがどのようなものであるべきかという点です。原則として、バグが存在する状況でも攻撃者にとって悪用を困難にし、脆弱性が公開された時点とパッチ適用までの間の時間差の重要性を低下させることです。つまり、アプリケーションの手前に配置されてバグに到達するのをブロックする防御手段が必要です。また、コードの一部にある欠陥が攻撃者に他の部分へのアクセス権を与えないようにアプリケーションを設計することも含まれます。さらに、個々のチームがデプロイするのを待つのではなく、コードが稼働しているすべての場所に同時に修正をロールアウトできる能力も必要です。
私たちはこのトピックには両刃の剣である側面があることも認識しています。自社のコード内でバグを見つけるのに役立った同じ機能が、間違った手に渡れば、インターネット上のあらゆるアプリケーションに対する攻撃側を加速させることになります。Cloudflare は数百万ものアプリケーションの手前に位置しており、上記で説明したアーキテクチャ原則こそが、顧客に代わって適用するために当社の製品が構築されている基盤です。これが顧客にとって何を意味するかについては、今後数週間でさらに詳しく共有していきます。
ご自身のチームでも同様の取り組みを行っており、情報を交換したい場合は、security-ai-research@cloudflare.com までご連絡ください。
Mythos Preview を用いた当社の研究は、制御された環境において自社のコードに対して実施されました。この研究を通じて表面化したすべての脆弱性は、Cloudflare の公式な脆弱性管理プロセスに基づき、必要な対応が行われるようトリアージされ、検証され、修正されました。
この作業はチームによる共同成果です。Albert Pedersen、Craig Strubhart、Dan Jones、Irtefa Fairuz、Martin Schwarzl、Rohit Chenna Reddy 各位に、その貢献に対し感謝申し上げます。
原文を表示
For the last few months, we've been testing a range of security-focused LLMs on our own infrastructure. These LLMs help identify potential vulnerabilities in our own systems, so we can fix them – and they also show us what attackers are going to be able to do with the latest models.
None of these LLMs has captured more attention than Mythos Preview, from Anthropic. A few weeks ago, we were invited to use Mythos Preview as part of Project Glasswing. We soon pointed it at more than fifty of our own repositories – to see what it would find, and to see how it works.
This post shares what we observed, what the models did well and what they didn't, and how the architecture and process around them needs to change, so they can be used at scale.
What changed with Mythos Preview
Mythos Preview is a real step forward, and it's worth saying that plainly before getting into anything else. We've been running models against our code for a while now, and the jump from what was possible with previous general-purpose frontier models to what Mythos Preview does today is not just a refinement of what came before.
It's a different kind of tool doing a different kind of work, and that makes a clean apples-to-apples comparison to earlier models difficult. So rather than trying to benchmark Mythos Preview against general-purpose frontier models, it's more useful to describe what it can actually do, and two features that stood out across the work we did with Mythos Preview:
Exploit chain construction - A real attack rarely uses one bug. It chains several small attack primitives together into a working exploit. For instance, it might turn a use-after-free bug into an arbitrary read and write primitive, hijack the control flow, and use return-oriented programming (ROP) chains to take full control over a system. Mythos Preview can take several of these primitives and reason about how to combine them into a working proof. The reasoning it shows along the way looks like the work of a senior researcher rather than the output of an automated scanner.
Proof generation - Finding a bug and proving it's exploitable are two different things, and Mythos Preview can do both. It writes code that would trigger the suspected bug, compiles that code in a scratch environment, and runs it. If the program does what the model expected, that's the proof. If it doesn't, the model reads the failure, adjusts its hypothesis, and tries again. The loop matters as much as the bugs it finds, because a suspected flaw without a working proof is speculation, and Mythos Preview closes that gap on its own.
Some of what we describe above is not entirely unique to Mythos Preview. When we ran other frontier models through the same harness, they found a fair number of the same underlying bugs, and in some cases they got further than we expected on the reasoning side too. Where they fell short was at the point of stitching the pieces together. A model would identify an interesting bug, write a thoughtful description of why it mattered, and then stop, leaving the actual chain unfinished and the question of exploitability open. What changed with Mythos Preview is that a model can now take those low-severity bugs (which would traditionally sit invisible in a backlog) and chain them into a single, more severe exploit.
Model refusals in legitimate vulnerability research
The Mythos Preview model provided by Anthropic, as part of Project Glasswing, did not have the additional safeguards that are present in generally available models (like Opus 4.7 or GPT-5.5).
Despite this, the model organically pushes back on certain requests - much like the cyber capabilities that made it useful for vulnerability hunting, the model has its own emergent guardrails that sometimes cause it to push back on legitimate security research requests. But as we found, these organic refusals aren’t consistent - the same task, framed differently or presented in a different context, could produce completely different outcomes as illustrated in the examples below.
image
Example of Mythos Preview pushing back on building a working proof of concept
For example, the model initially refused to do vulnerability research on a project, then agreed to perform the same research on the same code after an unrelated change to the project’s environment. Nothing about the code being analyzed had changed.
In another case, the model found and confirmed several serious memory bugs in a codebase, and then refused to write a demonstration exploit. The same request, framed differently, got a different answer, and even the same request can produce different outcomes across runs due to the probabilistic nature of the model. Semantically equivalent tasks can produce opposite outcomes depending on how and when they’re presented to the model.
This matters because while the model’s organic refusals/guardrails are real, they aren’t consistent enough to serve as a complete safety boundary on their own. That’s precisely why any capable cyber frontier model made generally available in the future must include additional safeguards on top of this baseline behavior - making it appropriate for broader use outside of a controlled research context like Project Glasswing.
The signal-to-noise problem
One of the hardest parts of triaging security vulnerabilities is deciding which bugs are real, which are exploitable, and which need fixing now. This was a hard problem even in the pre-AI world. AI vulnerability scanners and AI-generated code have made it worse, and at Cloudflare we've built multiple post-validation stages to deal with it.
Two factors dominate the noise rate:
Programming language - C and C++ give you direct memory control and, with it, bug classes - buffer overflows, out-of-bounds reads and writes - that memory-safe languages like Rust eliminate at compile time. We saw consistently more false positives from projects written in memory-unsafe languages.
Model bias - A good human researcher tells you what they found and how confident they are. Models don't. Ask a model to find bugs, and it will find them, whether the code has any or not. Findings come back hedged with "possibly," "potentially," "could in theory," and the hedged findings vastly outnumber the solid ones. That's a reasonable bias for an exploratory tool. It's a ruinous one for a triage queue, where every speculative finding spends human attention and tokens to dismiss, and that cost compounds across thousands of findings.
Mythos Preview represents a clear improvement here, particularly in its ability to chain primitives - combining multiple vulnerabilities into a working proof of concept rather than reporting them in isolation. A finding that arrives with a PoC is a finding you can act on, and it means far less time spent asking "is this even real?"
Our harnesses are deliberately tuned to over-report, so we see more (and miss less), which comes with a lot more noise. But at triage time, Mythos Preview's output has noticeably higher quality: fewer hedged findings, clearer reproduction steps, and less work to reach a fix-or-dismiss decision.
Why pointing a generic coding agent at a repo doesn't work
When we first started AI-assisted vulnerability research last year, our instinct was the obvious one: point a generic coding agent at an arbitrary repository and ask it to discover vulnerabilities. This approach works, in the sense that the model will produce findings, but it doesn't work in producing meaningful coverage of a real codebase and identifying findings of value. There are two main reasons for this:
Context - Coding agents are tuned for one focused stream of work: building a feature, fixing a bug, writing a refactor. They ingest a lot of source code, hold a single hypothesis at a time, and iterate against it. That's exactly the wrong shape for vulnerability research, which is narrow and parallel by nature. A human researcher picks one specific thing to look at and investigates it thoroughly. That one thing might be a single complex feature, transitions across security boundaries, or a specific vulnerability class like command injections, where attacker input ends up being run as a shell command. Then they do it again, for a different feature, security boundary, or vulnerability class, several thousand times across the codebase. A single agent session (even with subagents) against a hundred-thousand-line repository can cover maybe a tenth of a percent of the surface in a useful way before the model's context window fills up and compaction kicks in - potentially discarding earlier findings that would have mattered.
Throughput - A single-stream agent does one thing at a time, but real codebases need many hypotheses against many components at once, with the ability to fan out further when something interesting turns up. You can drive a single agent harder, but at some point you stop being limited by the model and start being limited by the shape of the interaction itself. Using the model directly in a coding agent turns out to be fine for manual investigation when a researcher already has a lead and wants a second pair of eyes. However, it's the wrong tool for achieving high coverage. Once we accepted that, we stopped trying to make Mythos Preview do the wrong job and started building the harness around it instead.
What a harness actually fixes
Four lessons came out of running the work at scale, and each one pointed to the need for a harness that manages the overall execution:
Narrow scope produces better findings - Telling the model "Find vulnerabilities in this repository" makes it wander. Telling it "Look for command injection in this specific function, with this trust boundary above it, here's the architecture document and here's prior coverage of this area" makes it do something much closer to what a researcher would actually do.
Adversarial review reduces noise - Adding a second agent between the initial finding and the queue - one with a different prompt, a different model, and no ability to generate its own findings - catches a lot of the noise that the first agent would miss if it just checked its own work. It turns out that putting two agents in deliberate disagreement is way more effective than just telling one agent to be careful.
Splitting the chain across agents produces better reasoning - Asking "Is this code buggy?" and "Can an attacker actually reach this bug from outside the system?" are two different questions, and the model is better at each one when you ask them separately, because each question is narrower than the combined version.
Parallel narrow tasks beat one exhaustive agent - Coverage improves when many agents work on tightly scoped questions and we deduplicate the results afterward, rather than asking one agent to be exhaustive.
Each of those observations is about model behavior, and put together they describe something that isn't a chat interface anymore. It's a harness that helps you achieve the final outcomes. The first steps to building a harness are simple, as you can ask the model to help, which is what we did. We used Mythos Preview to build on, tailor, and improve our original harnesses to suit its strengths.
An example of what a harness looks like in practice is described below.
Our vulnerability discovery harness
Here's what our vulnerability discovery harness looks like, stage by stage. It was used to scan live code across our runtime, edge data path, protocol stack, control plane, and the open-source projects we depend on.
image
Stage
What it does
Why it matters
image
Recon
An agent reads the repository from the top down, fans out to subagents responsible for each subsystem, and produces an architecture document covering build commands, trust boundaries, entry points, and likely attack surface. It also generates the initial queue of tasks for the next stage.
Gives every downstream agent shared context. Cuts the wander problem.
image
Hunt
Each task is one attack class paired with a scope hint. Hunters (the agents that actually look for bugs) run concurrently, typically around fifty at once, each fanning out to a handful of exploration subagents. Each hunter has access to tools that compile and run proof-of-concept code in a per-task scratch directory.
This is where most of the work happens. Many narrow tasks in parallel, not one exhaustive agent.
image
Validate
An independent agent re-reads the code and tries to disprove the original finding. It uses a different prompt and has no ability to emit new findings of its own.
Catches a meaningful fraction of the noise the hunter wouldn't catch when reviewing its own work.
image
Gapfill
Hunters flag areas they touched but didn't cover thoroughly. Those areas get re-queued for another pass.
Counteracts the model's tendency to drift toward attack classes it has already had success with.
image
Dedupe
Findings that share the same root cause collapse into a single record.
Variant analysis is a feature, not a way to inflate the queue with duplicates.
image
Trace
For each confirmed finding in a shared library, a tracer agent fans out (one instance per consumer repository), uses a cross-repo symbol index, and decides whether attacker-controlled input actually reaches the bug from outside the system.
Turns "there is a flaw" into "there is a reachable vulnerability." This is the stage that matters most.
image
Feedback
Reachable traces become new hunt tasks in the consumer repositories where the bug is actually exposed.
Closes the loop. The pipeline gets better as it runs.
 image
image
Report
An agent writes a structured report against a predefined schema, fixes any validation errors against that schema itself, and submits the report to an ingest API.
Output is queryable data, not free-form prose.
What this means for security teams
The loudest reaction to Mythos Preview from other security leaders has been about speed - scan faster, patch faster, compress the response cycle. More than one team we have spoken with is now operating under a two-hour SLA from CVE release to patch in production. The instinct is understandable: when the attacker timeline shortens, the defender timeline has to shorten with it. Faster is not going to be enough, and we think a lot of teams are about to spend a lot of time, effort, and money learning that the hard way.
Patching faster does not change the shape of the pipeline that produces the patch. If regression testing takes a day, you cannot get to a two-hour SLA without skipping it, and the bugs you ship when you skip regression testing tend to be worse than the bugs you were trying to patch. We learned a version of this when we tried letting the model write its own patches and watched a few go out that fixed the original bug while quietly breaking something else the code depended on.
The harder question is what the architecture around the vulnerability should look like. The principle is to make exploitation harder for an attacker even when a bug exists, so that the gap between when a vulnerability is disclosed and when it is patched matters less. That means defenses that sit in front of the application and block the bug from being reached. It means designing the application so that a flaw in one part of the code cannot give an attacker access to other parts. It means being able to roll out a fix to every place the code is running at the same moment, rather than waiting on individual teams to deploy it.
We also recognize this topic cuts both ways. The same capabilities that helped us find bugs in our own code will, in the wrong hands, accelerate the attack side against every application on the Internet. Cloudflare sits in front of millions of those applications, and the architectural principles described above are exactly the ones our products are built to apply on behalf of customers. We will share more on what that means for customers in the weeks ahead.
If your team is doing similar work and would like to compare notes, reach out to us at security-ai-research@cloudflare.com.
Our research with Mythos Preview was conducted in a controlled environment against our own code; every vulnerability surfaced through this work was triaged, validated, and remediated where action was needed under Cloudflare's formal vulnerability management process.
This work was a team effort. Thanks to Albert Pedersen, Craig Strubhart, Dan Jones, Irtefa Fairuz, Martin Schwarzl, and Rohit Chenna Reddy for their contribut
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み