Zyphra が Zamba2-VL を公開:ハイブリッド Mamba2–Transformer 型ビジョン言語モデルが初トークン生成時間を約 10 倍短縮
Zyphra は、Mamba2 と Transformer をハイブリッド化した「Zamba2-VL」を公開し、低遅延と高精度なビジョン言語モデルの新たな基準を示した。
キーポイント
ハイブリッドアーキテクチャの実装
計算効率の高い Mamba2(状態空間モデル)層に、コンテキスト保持能力を維持する Transformer 層を組み合わせることで、従来の純粋な SSM や Dense Transformer の欠点を補完した。
劇的な遅延短縮と性能
初回トークン生成までの時間を約 10 分の 1 に短縮することに成功し、DocVQA や ChartQA など複数のベンチマークで競合モデル(Molmo2, Qwen3-VL)に匹敵する高い精度を達成した。
高度なビジョンエンコーダーの採用
Qwen2.5-VL の Vision Transformer を採用し、2D 回転位置埋め込みとネイティブ動的解像度処理をサポートすることで、多画像理解やグラウンディング能力を強化している。
オープンソースモデルの拡大
1.2B、2.7B、7B の 3 つのサイズでリリースされ、リソース制約のある環境でも高性能なビジョン言語処理が可能になるよう設計されている。
推論速度の劇的な向上
Transformer の二次スケーリングに代わり線形時間処理を実現し、特に 32k トークンの事前計算において TTFT(初回トークンまでの時間)を約1桁短縮します。
特定タスクでの卓越した性能
PixMoCount や DocVQA などの数え上げやドキュメント理解タスクで競合モデルを大きく上回るスコアを記録し、エッジデバイス向けに最適化されています。
実装要件とインストール
Hugging Face で利用可能ですが、高速推論には Zyphra 製の transformers フォークと CUDA GPU 対応の Mamba2 カーネル(causal-conv1d, mamba-ssm)のインストールが必要です。
影響分析・編集コメントを表示
影響分析
この発表は、Vision-Language Models の分野において、計算コストと推論速度のトレードオフを解決する新たなアーキテクチャの可能性を示す重要なマイルストーンです。特に Mamba2 のような状態空間モデルの実用化が進む中、Transformer の長所を損なわずに効率性を高めるハイブリッドアプローチが、エッジデバイスやリアルタイムアプリケーションにおける VLM の普及を加速させる可能性があります。
編集コメント
Mamba2 の実用化において、Transformer とのハイブリッド化が「遅延短縮」と「推論能力維持」を両立させる鍵となることを示す好例です。今後のオープンソース VLM のアーキテクチャ設計に大きな影響を与えるでしょう。
Zyphra は、オープンソースのビジョン・ランゲージモデル(VLM)ファミリーである Zamba2-VL をリリースしました。このリリースには、1.2B、2.7B、7B パラメータの 3 つのサイズが含まれています。各モデルは、Zamba2 ハイブリッド SSM–Transformer ベースバックボーンの上に構築されています。
ビジョン・ランゲージモデル(VLM)は画像とテキストを同時に読み取り、チャート、ドキュメント、写真に関する質問に回答します。ほとんどのオープンソース VLM は言語モデルとして密な Transformer を使用していますが、Zamba2-VL はこれをハイブリッド状態空間設計に置き換えています。その目的は、より低いレイテンシで競争力のある精度を実現することです。
Zamba2-VL とは何か
Zamba2-VL は、現在標準となっている LLaVA スタイルの VLM テンプレートに従っています。事前学習されたビジョンエンコーダーが画像パッチを特徴量に変換します。軽量な MLP アダプターがこれらの特徴量を言語モデルの空間に投影します。その後、言語モデルはビジョントークンとテキストトークンの交互シーケンスを読み取ります。このモデル群は、単一画像および複数画像の理解とグラウンディングをサポートしています。
Zyphra は、各 Zamba2 ベースバックボーンに Qwen2.5-VL の Vision Transformer を組み合わせています。このエンコーダーが選ばれたのは、2 つの特定の特性によるものです。それは 2D 回転位置埋め込み(rotary position embeddings)とネイティブな動的解像度処理(dynamic-resolution processing)を使用している点です。2 層の MLP アダプターがエンコーダーとバックボーンを接続しています。
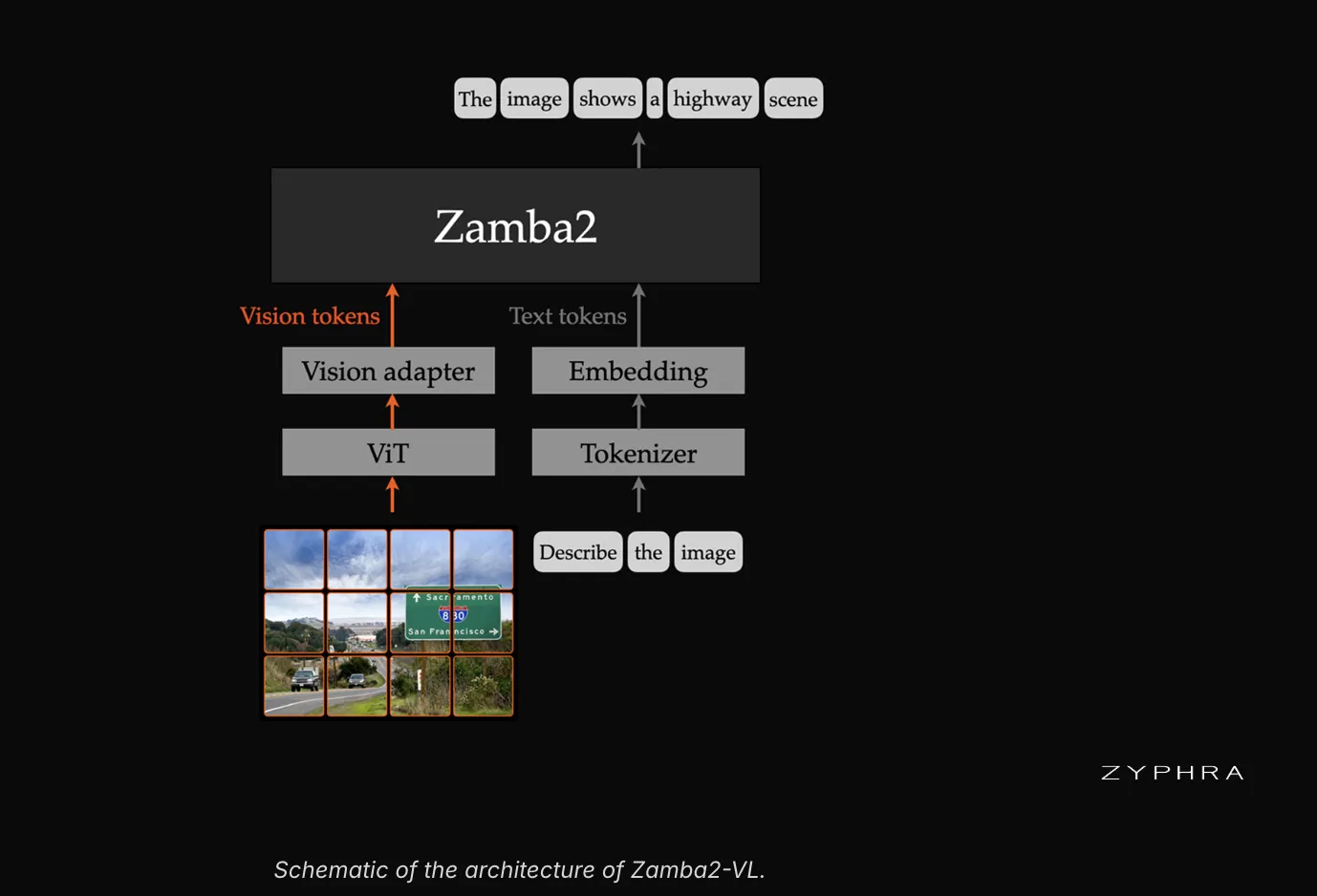 image https://www.zyphra.com/our-work/zamba2-vl
image https://www.zyphra.com/our-work/zamba2-vl
アーキテクチャ
Zamba2 のバックボーンは、一般的な VLM(ビジョン・ランゲージモデル)とは異なる設計の核心部分です。これは Mamba2 状態空間層と共有トランスフォーマーブロックを融合したハイブリッド構造となっています。Mamba2 層は固定サイズの状態で線形時間で動作し、その間に少数の共有アテンション層が交互に配置されています。各共有ブロックには、各層ごとに固有の LoRA アダプターが搭載されています。
Mamba2 層は計算の大部分を低コストで処理します。一方、共有アテンション層は、純粋な SSM(状態空間モデル)では放棄されるコンテキスト内検索機能を維持しています。このハイブリッド構造は、フルアテンションの表現力と状態空間の効率性の間でトレードオフを実現しています。
Zamba2-VL は Mistral v0.1 トークナイザーを採用しています。これは 100B トークンのビジョン・テキストデータおよび純粋なテキストデータでトレーニングされました。これらのデータはオープンウェブ上のデータセットから収集されたものです。
 imagehttps://www.zyphra.com/our-work/zamba2-vl
imagehttps://www.zyphra.com/our-work/zamba2-vl
モデル品質とベンチマーク
研究チームは、Zamba2-VL を 14 のベンチマークで評価しました。これらはチャート、図表、ドキュメントの理解を網羅しており、一般的な知覚、推論、視覚的数え上げも含まれています。すべてのスコアは、VLMEvalKit に基づく Zyphra の評価ハッチャーから得られたものです。このレポートでは、Molmo2、Qwen3-VL、InternVL3.5 ファミリーとの比較が行われています。
EvalZamba2-VL-2.7B InternVL3.5-2B Qwen3-VL-2B Molmo2-4B Qwen3-VL-4B
DocVQA (test) 90.9 89.4 93.3 87.8 95.3
ChartQA (test) 79.6 81.6 78.7 86.1 81.8
OCRBench 73.6 83.4 84.1 62.0 84.1
CountBenchQA 87.5 70.0 87.9 91.2 87.3
PixMoCount (test) 82.5 32.8 55.7 87.0 89.2
MMMU (val)37.749.940.948.851.4
MathVista (mini)51.061.451.856.563.6
InternVL3.5-2B と Qwen3-VL-2B はサイズが類似しています。Molmo2-4B と Qwen3-VL-4B はより大きいです。
このパターンは不均一であり、理解する価値があります。数え上げ(counting)が最も強力なカテゴリです。Zyphra によると、Zamba2-VL-1.2B の PixMoCount でのスコアは 62.5 です。これと比較すると、InternVL3.5-1B は 32.8、PerceptionLM-1B は 17.7 です。ドキュメント理解(document understanding)も健闘しており、2.7B モデルの DocVQA では 90.9 を記録しています。しかし、MMMU や MathVista のような知識依存型の推論では、より大きなベースラインモデルに遅れをとっています。
なぜ推論が高速なのか
推論において Zamba2-VL はその主な優位性を発揮します。トランスフォーマー(Transformer)のアテンションはシーケンス長に対して二次関数的にスケーリングします。マルチモーダル入力は非常に短い時間でシーケンスを長くします。1 枚の高解像度画像だけで数千のビジョントークンが追加され、短い動画クリップでは数万のトークンを生成することさえあります。
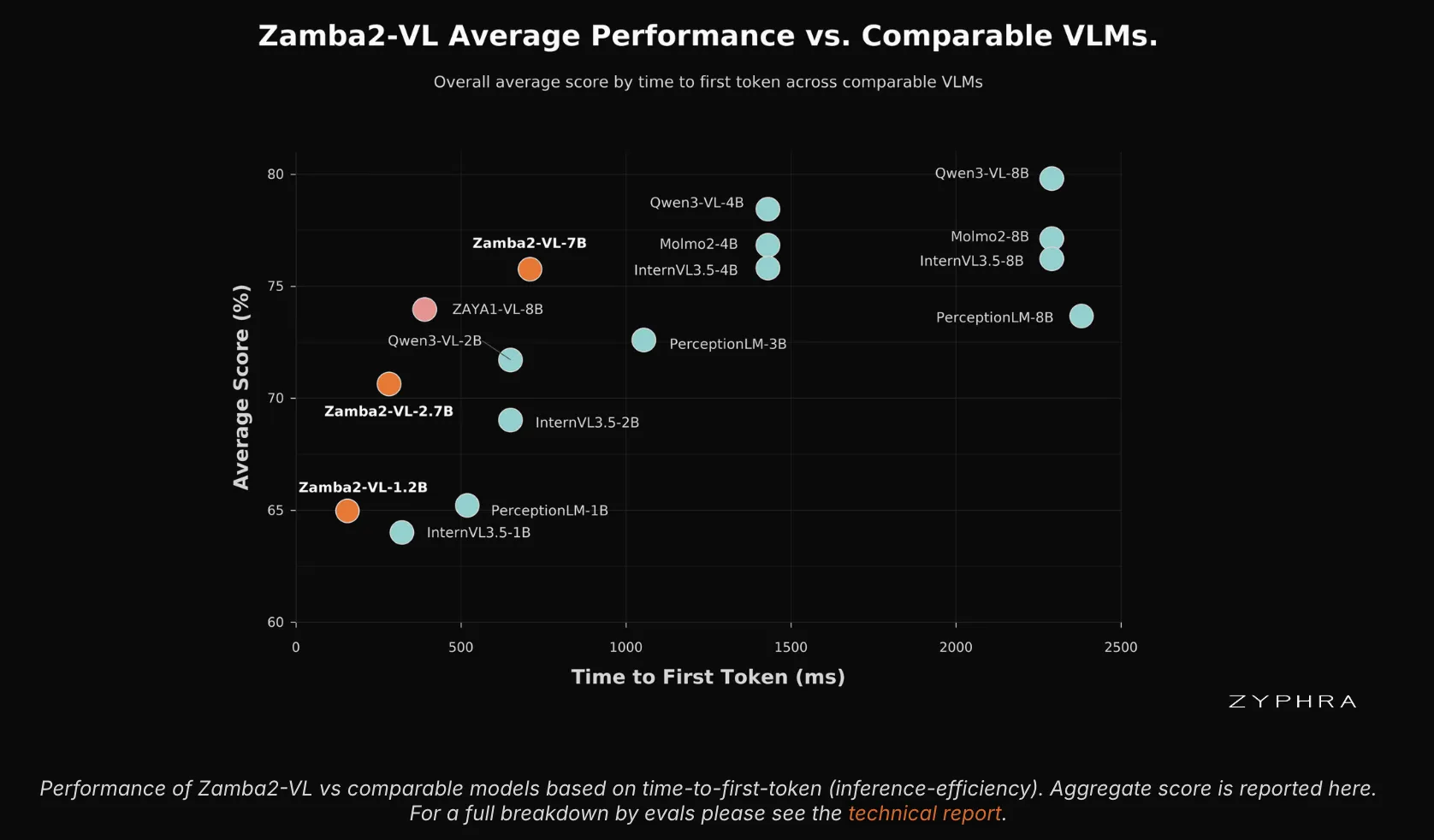
Zamba2-VL はアテンションに伴う KV キャッシュ(Key-Value Cache)の増大を回避します。ほぼ線形時間のプリフィル(prefill)と固定サイズの再帰状態(recurrent state)を受け継いでいます。32k トークンのプリフィルにおいて、スコア対 TTFT(Time To First Token)プロットで首位に立ちます。比較対象となったトランスフォーマーベースの VLM(Vision-Language Model)は、同程度のレイテンシでこのスコアに匹敵するものはありませんでした。そのレイテンシの差は少なくとも 1 桁(オーダー・オブ・マグニチュード)です。
効率性の優位性は、1.2B および 2.7B の規模において最も顕著です。これはオンデバイスやエッジでの展開をターゲットとした範囲です。
使用例と具体例
実用的な観点から、これがどこに位置するかを考えましょう。ドキュメントやフォームの抽出は、強力な DocVQA の結果から恩恵を受けます。スケーラブルな請求書解析や領収書のデジタル化を想定してください。小売業や在庫カウントは、PixMoCount と CountBenchQA の強みにマップされます。グラウンディング機能により、製品画像や UI 画像内のオブジェクトを指し示すことが可能になります。オンデバイス型アシスタントは、トークン生成までの時間短縮から恩恵を受けます。1.2B パラメータモデルはスマートフォンやエッジボックスを対象としています。多ページ PDF などの長い視覚的入力は、線形時間のプリフィル(prefill)によって最も大きな恩恵を受けます。
Getting Started
3 つのモデルは、Hugging Face 上の Zyphra Zamba2-VL コレクションに存在します。推論は、transformers v4.57.1 をベースとした Zyphra の transformers フォークを通じて実行されます。最適化された Mamba2 カーネルを使用するには、良好なレイテンシのために CUDA GPU が必要です。
フォークとそのコア依存関係をインストールしてください:
pip install "transformers @ git+https://github.com/Zyphra/transformers.git@zamba2-vl"
pip install qwen-vl-utils==0.0.2
pip install flash_attn
最適化された Mamba2 カーネルには、さらに 2 つのパッケージが必要です:
pip install --no-build-isolation "causal-conv1d @ git+https://github.com/Zyphra/z-causal-conv1d.git@zamba2-vl"
pip install --no-build-isolation "mamba-ssm @ git+https://github.com/Zyphra/mamba.git@zamba2-vl"
その後、モデルを読み込んで単一画像のクエリを実行します:
from transformers import Zamba2_VLForConditionalGeneration, Zamba2_VLProcessor
import torch
from PIL import Image
from qwen_vl_utils import process_vision_info
import requests
device = "cuda"
processor = Zamba2_VLProcessor.from_pretrained("Zyphra/Zamba2-VL-2.7B", temporal_patch_size=1)
model = Zamba2_VLForConditionalGeneration.from_pretrained(
"Zyphra/Zamba2-VL-2.7B",
device_map=device,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
question = "What do you see in the image? Give us some detail."
num_img_tokens = 3400
conversation = [
{"role": "user", "content": [
{"type": "image", "image": image,
"max_pixels": num_img_tokens * 28 * 28, "min_pixels": 10 * 28 * 28},
{"type": "text", "text": question},
]},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
images, _ = process_vision_info(conversation)
inputs = processor(text=prompt, images=images, add_special_tokens=True, return_tensors="pt")
inputs = {key: value.to(device) for key, value in inputs.items()}
outputs = model.generate(**inputs, max_new_tokens=100)
print(processor.tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
Swap the model ID for Zamba2-VL-1.2B or Zamba2-VL-7B to change scale.
Strengths and Weaknesses
Strengths:
Zyphra によると、これは完全にオープンなハイブリッド SSM–Transformer LLM 上で動作する最初のオープン VLM ファミリーです。
比較対象となる Transformer ベースラインと比較して、初回トークン生成までの時間が約 10 分の 1 に短縮されています。
視覚的な数え上げ能力が強く、文書理解においても競争力があります。
エッジ、ミドルレンジ、7B クラスのデプロイメントをカバーする 3 つのサイズバリエーションを用意しています。
Apache 2.0 ライセンスの下で、公開された重みと動作する推論コードが利用可能です。
弱点と課題:
研究用アーティファクトとしてリリースされています。
MMMU や MathVista などの知識推論においては、より大規模なモデルに劣ります。
同じサイズの Qwen3-VL や InternVL3.5 に比べて OCRBench のスコアは低いです。
最適化されたカーネルには CUDA GPU が必要であり、CPU パスは低速です。
デプロイには、リリースされたコードからのセルフホスティングが必要です。
主要なポイント
Zamba2-VL は、Apache 2.0 ライセンスの下で 1.2B、2.7B、7B パラメータのサイズで提供されています。
バックボーンは、Mamba2 の状態空間層と少数の共有 Transformer ブロックを組み合わせています。
比較対象となる Transformer VLM と比べて、初回トークン生成までの時間が約 10 分の 1 に短縮されます。
数え上げと文書理解が得意分野ですが、知識推論は劣ります。
重みと動作する推論コードは、Hugging Face および GitHub で公開されています。
Marktechpost のインタラクティブ解説
#mtp-zamba2vl-explainer *{box-sizing:border-box!important;margin:0;padding:0}
#mtp-zamba2vl-explainer hr,#mtp-zamba2vl-explainer p:empty,#mtp-zamba2vl-explainer del,#mtp-zamba2vl-explainer s{display:none!important}
#mtp-zamba2vl-explainer{
background:#0d0d0d!important;color:#e8e8e8!important;border:1px solid #232323!important;border-radius:14px!important;
font-family:-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,Helvetica,Arial,sans-serif!important;
max-width:880px;margin:24px auto;overflow:hidden;line-height:1.5;
}
#mtp-zamba2vl-explainer .z2-head{padding:26px 26px 18px;background:#0d0d0d!important;border-bottom:1px solid #1c1c1c!important}
#mtp-zamba2vl-explainer .z2-eyebrow{color:#76B900!important;font-size:11px;letter-spacing:.18em;font-weight:700;text-transform:uppercase}
#mtp-zamba2vl-explainer .z2-title{color:#fff!important;font-size:23px;font-weight:800;margin:10px 0 6px;line-height:1.25}
#mtp-zamba2vl-explainer .z2-sub{color:#9aa0a6!important;font-size:14.5px;max-width:680px}
#mtp-zamba2vl-explainer .z2-sizes{display:flex;gap:8px;margin-top:16px;flex-wrap:wrap}
#mtp-zamba2vl-explainer .z2-size{
background:#151515!important;color:#cfcfcf!important;border:1px solid #2a2a2a!important;border-radius:999px!important;
padding:7px 16px;font-size:13px;font-weight:700;cursor:pointer;font-family:inherit;transition:.15s
}
#mtp-zamba2vl-explainer .z2-size:hover{border-color:#3a3a3a!important}
#mtp-zamba2vl-explainer .z2-size.active{background:#76B900!important;color:#0d0d0d!important;border-color:#76B900!important}
#mtp-zamba2vl-explainer .z2-size-detail{
margin-top:14px;background:#121212!important;border:1px solid #222!important;border-left:3px solid #76B900!important;
border-radius:8px!important;padding:12px 14px;font-size:13.5px;color:#cdd0d3!important;min-height:44px
}
#mtp-zamba2vl-explainer .z2-tabs{display:flex;gap:4px;padding:14px 18px 0;background:#0d0d0d!important;flex-wrap:wrap}
#mtp-zamba2vl-explainer .z2-tab{
background:transparent!important;color:#9aa0a6!important;border:0!important;border-bottom:2px solid transparent!important;
padding:10px 14px;font-size:14px;font-weight:700;cursor:pointer;font-family:inherit
}
#mtp-zamba2vl-explainer .z2-tab:hover{color:#e8e8e8!important}
#mtp-zamba2vl-explainer .z2-tab.active{color:#76B900!important;border-bottom:2px solid #76B900!important}
#mtp-zamba2vl-explainer .z2-panel{display:none;padding:22px 26px 8px}
#mtp-zamba2vl-explainer .z2-panel.active{display:block}
#mtp-zamba2vl-explainer .z2-h{color:#fff!important;font-size:16px;font-weight:800;margin-bottom:4px}
#mtp-zamba2vl-explainer .z2-note{color:#8a9097!important;font-size:12.5px;margin-top:10px}
/* pipeline */
#mtp-zamba2vl-explainer .z2-pipe{display:flex;align-items:stretch;gap:0;margin:14px 0 4px;overflow-x:auto;padding-bottom:6px}
#mtp-zamba2vl-explainer .z2-stage{
background:#151515!important;color:#d6d6d6!important;border:1px solid #2a2a2a!important;border-radius:9px!important;
padding:11px 12px;font-size:12.5px;font-weight:700;cursor:pointer;white-space:nowrap;flex:0 0 auto;transition:.15s;text-align:center
}
#mtp-zamba2vl-explainer .z2-stage:hover{border-color:#3d3d3d!important}
#mtp-zamba2vl-explainer .z2-stage.active{border-color:#76B900!important;background:#16210a!important;color:#cde89a!important}
#mtp-zamba2vl-explainer .z2-arrow{display:flex;align-items:center;color:#3a3a3a!important;padding:0 6px;font-size:16px;flex:0 0 auto}
#mtp-zamba2vl-explainer .z2-stage-detail{
background:#121212!important;border:1px solid #222!important;border-radius:9px!important;padding:14px 16px;font-size:13.5px;color:#cdd0d3!important;margin-top:6px
}
#mtp-zamba2vl-explainer .z2-stage-detail b{color:#fff!important}
/* efficiency lab */
#mtp-zamba2vl-explainer .z2-lab{margin-top:6px}
#mtp-zamba2vl-explainer .z2-presets{display:flex;gap:7px;flex-wrap:wrap;margin:12px 0}
#mtp-zamba2vl-explainer .z2-preset{
background:#151515!important;color:#bdbdbd!important;border:1px solid #2a2a2a!important;border-radius:7px!important;
padding:6px 11px;font-size:12px;font-weight:600;cursor:pointer;font-family:inherit
}
#mtp-zamba2vl-explainer .z2-preset:hover{border-color:#76B900!important;color:#cde89a!important}
#mtp-zamba2vl-explainer .z2-slider{width:100%;margin:6px 0 2px;accent-color:#76B900;height:4px}
#mtp-zamba2vl-explainer .z2-tok{color:#fff!important;font-size:20px;font-weight:800;font-variant-numeric:tabular-nums}
#mtp-zamba2vl-explainer .z2-tok small{color:#8a9097!important;font-size:12.5px;font-weight:600;display:block;margin-top:2px}
#mtp-zamba2vl-explainer .z2-bars{margin-top:16px;display:flex;flex-direction:column;gap:14px}
#mtp-zamba2vl-explainer .z2-bar-row .z2-bl{display:flex;justify-content:space-between;font-size:12.5px;margin-bottom:5px}
#mtp-zamba2vl-explainer .z2-bl .z2-lbl{color:#cfcfcf!important;font-weight:700}
#mtp-zamba2vl-explainer .z2-bl .z2-val{color:#fff!important;font-weight:800;font-variant-numeric:tabular-nums}
#mtp-zamba2vl-explainer .z2-track{background:#1a1a1a!important;border:1px solid #242424!important;border-radius:6px!important;height:16px;overflow:hidden}
#mtp-zamba2vl-explainer .z2-fill{height:100%;width:0;border-radius:5px;transition:width .35s ease}
#mtp-zamba2vl-explainer .z2-fill.tf{background:#E0A050!important}
#mtp-zamba2vl-explainer .z2-fill.z2{background:#76B900!important}
#mtp-zamba2vl-explainer .z2-ratio{
margin-top:16px;background:#16210a!important;border:1px solid #2e4413!important;border-radius:9px!important;padding:12px 14px;
color:#cde89a!important;font-size:14px;font-weight:700;text-align:center
}
#mtp-zamba2vl-explainer .z2-ratio b{color:#76B900!important;font-size:18px}
#mtp-zamba2vl-explainer .z2-callout{
margin-top:14px;background:#101010!important;border:1px solid #222!important;border-radius:9px!important;padding:12px 14px;font-size:13px;color:#b9bdc2!important
}
#mtp-zamba2vl-explainer .z2-callout b{color:#fff!important}
/* ベンチマーク */
#mtp-zamba2vl-explainer .z2-bench-tabs{display:flex;gap:6px;flex-wrap:wrap;margin:12px 0 18px}
#mtp-zamba2vl-explainer .z2-bt{
background:#151515!important;color:#bdbdbd!important;border:1px solid #2a2a2a!important;border-radius:7px!important;
padding:6px 11px;font-size:12px;font-weight:700;cursor:pointer;font-family:inherit
}
#mtp-zamba2vl-explainer .z2-bt:hover{border-color:#3d3d3d!important}
#mtp-zamba2vl-explainer .z2-bt.active{background:#76B900!important;color:#0d0d0d!important;border-color:#76B900!important}
#mtp-zamba2vl-explainer .z2-brow{margin-bottom:11px}
#mtp-zamba2vl-explainer .z2-brow .z2-bl{display:flex;justify-content:space-between;font-size:12.5px;margin-bottom:4px}
#mtp-zamba2vl-explainer .z2-brow .z2-mname{color:#cfcfcf!important;font-weight:600}
#mtp-zamba2vl-explainer .z2-brow.lead .z2-mname{color:#cde89a!important;font-weight:800}
#mtp-zamba2vl-explainer .z2-brow .z2-score{color:#fff!important;font-weight:800;font-variant-numeric:tabular-nums}
#mtp-zamba2vl-explainer .z2-btrack{background:#1a1a1a!important;border:1px solid #242424!important;border-radius:5px!important;height:13px;overflow:hidden}
#mtp-zamba2vl-explainer .z2-bfill{height:100%;width:0;background:#3a3a3a!important;border-radius:4px;transition:width .45s ease}
#mtp-zamba2vl-explainer .z2-bfill.lead{background:#76B900!important}
/* footer / tagline */
#mtp-zamba2vl-explainer .z2-foot{
margin-top:14px;padding:18px 26px;background:#0a0a0a!important;border-top:1px solid #1c1c1c!important;
display:flex;align-items:center;gap:12px;flex-wrap:wrap;justify-content:space-between
}
#mtp-zamba2vl-explainer .z2-foot .z2-brand{font-size:13.5px;color:#9aa0a6!important}
#mtp-zamba2vl-explainer .z2-foot .z2-brand b{color:#76B900!important;font-weight:800}
#mtp-zamba2vl-explainer .z2-foot a{
color:#0d0d0d!important;background:#76B900!important;text-decoration:none!important;font-weight:800;font-size:12.5px;
padding:8px 15px;border-radius:7px!important;border:1px solid #76B900!important;white-space:nowrap
}
#mtp-zamba2vl-explainer .z2-line{height:1px!important;background:#1c1c1c!important;border:0!important;margin:8px 0}
@media (max-width:640px){
#mtp-zamba2vl-explainer .z2-head,#mtp-zamba2vl-explainer .z2-panel{padding-left:16px;padding-right:16px}
#mtp-zamba2vl-explainer .z2-tabs{padding-left:10px;padding-right:10px}
#mtp-zamba2vl-explainer .z2-title{font-size:19px}
#mtp-zamba2vl-explainer .z2-tab{padding:9px 9px;font-size:13px}
#mtp-zamba2vl-explainer .z2-foot{padding:16px;flex-direction:column;align-items:flex-start}
#mtp-zamba2vl-explainer .z2-pipe{padding-bottom:8px}
}
Interactive Explainer
Zamba2-VL: Hybrid SSM–Transformer Vision-Language Models
Open VLMs at 1.2B, 2.7B, and 7B that replace dense attention with a Mamba2 state-space + Transformer hybrid. Apache 2.0.
1.2B
2.7B
7B
仕組み
なぜ高速なのか
ベンチマーク
パイプライン(ステージをタップ)
Zamba2-VL は LLaVA スタイルのテンプレートに従います:ビジョンエンコーダー → アダプター → 言語モデル。
トークンスケーリングラボ
スライダーをドラッグするか、プリセットを選択してください。アテンションの事前計算(prefill)は O(n²) でスケーリングしますが、Mamba2 レイヤーは O(n) でスケーリングします。
1 枚の高解像度画像(約 3,400 トークン)
数枚の画像(約 12,000 トークン)
短い動画(約 24,000 トークン)
長いコンテキスト(約 32,000 トークン)
3,400 ビジョントークン
高解像度画像 1 枚分
Transformer アテンション — 事前計算コスト 1.0×
Zamba2-VL ハイブリッド — 事前計算コスト 1.0×
Transformer KV キャッシュ — コンテキスト用のメモリが増加
Zamba2-VL 再帰状態(recurrent state)— コンテキスト用のメモリが固定
この長さでは、ハイブリッドモデルは事前計算コストを約 1.0 倍削減します。
測定された主張:Zyphra はほぼ線形時間の事前計算と固定サイズの再帰状態を報告しています。32k トークンの事前計算において、最も近い Transformer ベースラインと比較して、最初のトークンまでの時間を約 1 桁(オーダー)短縮できると報告されています。
バーは測定されたレイテンシではなく、O(n²) と O(n) のスケーリング特性を示しています。
ベンチマークエクスプローラー — Zamba2-VL-2.7B vs ベースライン
評価項目を選択してください。緑色が Zamba2-VL-2.7B です。数値が高いほど優れています。
ソース:Zyphra評価ハッチ(VLMEvalKit)。InternVL3.5-2B と Qwen3-VL-2B はサイズが類似しており、Molmo2-4B と Qwen3-VL-4B はより大規模です。
Marktechpost によって公開 — エンジニアやデータサイエンティスト向けの AI/ML 研究、モデルリリース、開発者向けチュートリアル。
Marktechpost でさらに詳しく読む
(function(){
var root=document.getElementById("mtp-zamba2vl-explainer");
if(!root)return;
var $=function(s){return root.querySelector(s)};
var $all=function(s){return Array.prototype.slice.call(root.querySelectorAll(s))};
/* ---- size selector ---- */
var sizeInfo={
"1.2B":"エッジおよびオンデバイス層。相対的なトークン初出力までの時間の短縮において最大の利点を持つ。Zyphra の報告によると PixMoCount は 62.5 で、InternVL3.5-1B の 32.8 や PerceptionLM-1B の 17.7 を上回ります。",
"2.7B":"中規模の一般モデルで、Zamba2-2.7B LLM に基づいています。視覚的な数え上げやドキュメント理解に強く、知識依存型の推論(MMMU, MathVista)では大規模モデルには劣ります。",
"7B":"最大サイズのリリース版。Zyphra によると、ほぼすべてのカテゴリにおいて最も強力な 7〜8B オープンウェイト VLM と競合する性能を持ちます。"
};
function setSize(s){
$all(".z2-size").forEach(function(b){b.classList.toggle("active",b.getAttribute("data-size")===s)});
$("#z2-size-detail").textContent=sizeInfo[s];
}
$all(".z2-size").forEach(function(b){b.addEventListener("click",function(){setSize(b.getAttribute("data-size"))})});
setSize("1.2B");
/* ---- tabs ---- */
$all(".z2-tab").forEach(function(t){
t.addEventListener("click",function(){
var name=t.getAttribute("data-tab");
$all(".z2-tab").forEach(function(x){x.classList.toggle("active",x===t)});
$all(".z2-panel").forEach(functio
原文を表示
Zyphra has released Zamba2-VL, a family of open vision-language models. The release covers three sizes: 1.2B, 2.7B, and 7B parameters. Each model is built on the Zamba2 hybrid SSM–Transformer backbone.
Vision-language models (VLMs) read images and text together. They answer questions about charts, documents, and photos. Most open VLMs use a dense Transformer as the language model. Zamba2-VL replaces that with a hybrid state-space design. The goal is competitive accuracy at lower latency.
What is Zamba2-VL
Zamba2-VL follows the now-standard LLaVA-style VLM template. A pre-trained vision encoder turns image patches into features. A lightweight MLP adapter projects those features into the language model’s space. The language model then reads an interleaved sequence of vision and text tokens. The models support single and multi-image understanding and grounding.
Zyphra pairs each Zamba2 backbone with the Vision Transformer from Qwen2.5-VL. That encoder was chosen for two specific properties. It uses 2D rotary position embeddings and native dynamic-resolution processing. A two-layer MLP adapter connects the encoder to the backbone.
imagehttps://www.zyphra.com/our-work/zamba2-vl
The Architecture
The Zamba2’s backbone is where the design diverges from typical VLMs. It is a hybrid of Mamba2 state-space layers and shared transformer blocks. The Mamba2 layers run in linear time with a fixed-size state. A small number of shared attention layers are interleaved between them. Each shared block carries a unique LoRA adapter at each layer.
The Mamba2 layers carry the bulk of computation cheaply. The shared attention layers preserve in-context retrieval that pure-SSM models give up. The hybrid trades full-attention expressivity against state-space efficiency.
Zamba2-VL uses the Mistral v0.1 tokenizer. It was trained on 100B tokens of vision-text and pure-text data. That data was sourced from open web datasets.
imagehttps://www.zyphra.com/our-work/zamba2-vl
Model Quality and Benchmarks
The research team evaluated Zamba2-VL across 14 benchmarks. These span chart, diagram, and document understanding. They also cover general perception, reasoning, and visual counting. All scores come from Zyphra’s evaluation harness, which is based on VLMEvalKit. The report compares against the Molmo2, Qwen3-VL, and InternVL3.5 families.
EvalZamba2-VL-2.7BInternVL3.5-2BQwen3-VL-2BMolmo2-4BQwen3-VL-4B
DocVQA (test)90.989.493.387.895.3
ChartQA (test)79.681.678.786.181.8
OCRBench73.683.484.162.084.1
CountBenchQA87.570.087.991.287.3
PixMoCount (test)82.532.855.787.089.2
MMMU (val)37.749.940.948.851.4
MathVista (mini)51.061.451.856.563.6
InternVL3.5-2B and Qwen3-VL-2B are similar in size. Molmo2-4B and Qwen3-VL-4B are larger.
The pattern is uneven and worth understanding. Counting is the strongest category. Zyphra reports Zamba2-VL-1.2B at 62.5 on PixMoCount. That compares with 32.8 for InternVL3.5-1B and 17.7 for PerceptionLM-1B. Document understanding also holds up, with DocVQA at 90.9 for the 2.7B model. The model lags larger baselines on knowledge-heavy reasoning, such as MMMU and MathVista.
Why Inference is Faster
Inference is where Zamba2-VL shows its main advantage. Transformer attention scales quadratically with sequence length. Multimodal inputs make sequences long very quickly. A single high-resolution image can add several thousand vision tokens. A short video clip can produce tens of thousands of tokens.
Zamba2-VL avoids the growing KV cache of attention. It inherits near-linear-time prefill and a fixed-size recurrent state. On a 32k-token prefill, it leads on the score-versus-TTFT plot. No Transformer VLM in the comparison matched its score at similar latency. The latency gap is at least an order of magnitude.
The efficiency advantage is largest at the 1.2B and 2.7B scales. That is the range targeted for on-device and edge deployment.
Use Cases With Examples
The practical question is where this fits. Document and form extraction benefits from the strong DocVQA results. Think invoice parsing or receipt digitization at scale. Retail and inventory counting maps to the PixMoCount and CountBenchQA strengths. Grounding support enables pointing to objects in product or UI images. On-device assistants benefit from the low time-to-first-token. The 1.2B model targets phones and edge boxes. Long visual inputs, like multi-page PDFs, gain most from linear-time prefill.
Getting Started
The three models live in the Zyphra Zamba2-VL collection on Hugging Face. Inference runs through Zyphra’s transformers fork, based on transformers v4.57.1. The optimized Mamba2 kernels need a CUDA GPU for good latency.
Install the fork and its core dependencies:
Copy CodeCopiedUse a different Browser
pip install "transformers @ git+https://github.com/Zyphra/transformers.git@zamba2-vl"
pip install qwen-vl-utils==0.0.2
pip install flash_attn
Optimized Mamba2 kernels need two more packages:
Copy CodeCopiedUse a different Browser
pip install --no-build-isolation "causal-conv1d @ git+https://github.com/Zyphra/z-causal-conv1d.git@zamba2-vl"
pip install --no-build-isolation "mamba-ssm @ git+https://github.com/Zyphra/mamba.git@zamba2-vl"
Then load the model and run a single-image query:
Copy CodeCopiedUse a different Browser
from transformers import Zamba2_VLForConditionalGeneration, Zamba2_VLProcessor
import torch
from PIL import Image
from qwen_vl_utils import process_vision_info
import requests
device = "cuda"
processor = Zamba2_VLProcessor.from_pretrained("Zyphra/Zamba2-VL-2.7B", temporal_patch_size=1)
model = Zamba2_VLForConditionalGeneration.from_pretrained(
"Zyphra/Zamba2-VL-2.7B",
device_map=device,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
question = "What do you see in the image? Give us some detail."
num_img_tokens = 3400
conversation = [
{"role": "user", "content": [
{"type": "image", "image": image,
"max_pixels": num_img_tokens * 28 * 28, "min_pixels": 10 * 28 * 28},
{"type": "text", "text": question},
]},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
images, _ = process_vision_info(conversation)
inputs = processor(text=prompt, images=images, add_special_tokens=True, return_tensors="pt")
inputs = {key: value.to(device) for key, value in inputs.items()}
outputs = model.generate(**inputs, max_new_tokens=100)
print(processor.tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
Swap the model ID for Zamba2-VL-1.2B or Zamba2-VL-7B to change scale.
Strengths and Weaknesses
Strengths:
First open VLM family on a fully open hybrid SSM–Transformer LLM, per Zyphra.
About an order of magnitude lower time-to-first-token than comparable Transformer baselines.
Strong visual counting and competitive document understanding.
Three sizes cover edge, mid, and 7B-class deployment.
Apache 2.0 license with public weights and working inference code.
Weaknesses and Challenges:
Released as a research artifact.
Lags larger models on knowledge reasoning like MMMU and MathVista.
Lower OCRBench than same-size Qwen3-VL and InternVL3.5.
Optimized kernels need a CUDA GPU; CPU paths are slow.
Deployment requires self-hosting from the released code.
Key Takeaways
Zamba2-VL ships at 1.2B, 2.7B, and 7B parameters under Apache 2.0.
The backbone pairs Mamba2 state-space layers with a few shared transformer blocks.
Time-to-first-token drops about an order of magnitude versus comparable Transformer VLMs.
Counting and document understanding are strengths; knowledge reasoning lags.
Weights and working inference code are public on Hugging Face and GitHub.
Marktechpost’s Interactive Explainer
#mtp-zamba2vl-explainer *{box-sizing:border-box!important;margin:0;padding:0}
#mtp-zamba2vl-explainer hr,#mtp-zamba2vl-explainer p:empty,#mtp-zamba2vl-explainer del,#mtp-zamba2vl-explainer s{display:none!important}
#mtp-zamba2vl-explainer{
background:#0d0d0d!important;color:#e8e8e8!important;border:1px solid #232323!important;border-radius:14px!important;
font-family:-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,Helvetica,Arial,sans-serif!important;
max-width:880px;margin:24px auto;overflow:hidden;line-height:1.5;
}
#mtp-zamba2vl-explainer .z2-head{padding:26px 26px 18px;background:#0d0d0d!important;border-bottom:1px solid #1c1c1c!important}
#mtp-zamba2vl-explainer .z2-eyebrow{color:#76B900!important;font-size:11px;letter-spacing:.18em;font-weight:700;text-transform:uppercase}
#mtp-zamba2vl-explainer .z2-title{color:#fff!important;font-size:23px;font-weight:800;margin:10px 0 6px;line-height:1.25}
#mtp-zamba2vl-explainer .z2-sub{color:#9aa0a6!important;font-size:14.5px;max-width:680px}
#mtp-zamba2vl-explainer .z2-sizes{display:flex;gap:8px;margin-top:16px;flex-wrap:wrap}
#mtp-zamba2vl-explainer .z2-size{
background:#151515!important;color:#cfcfcf!important;border:1px solid #2a2a2a!important;border-radius:999px!important;
padding:7px 16px;font-size:13px;font-weight:700;cursor:pointer;font-family:inherit;transition:.15s
}
#mtp-zamba2vl-explainer .z2-size:hover{border-color:#3a3a3a!important}
#mtp-zamba2vl-explainer .z2-size.active{background:#76B900!important;color:#0d0d0d!important;border-color:#76B900!important}
#mtp-zamba2vl-explainer .z2-size-detail{
margin-top:14px;background:#121212!important;border:1px solid #222!important;border-left:3px solid #76B900!important;
border-radius:8px!important;padding:12px 14px;font-size:13.5px;color:#cdd0d3!important;min-height:44px
}
#mtp-zamba2vl-explainer .z2-tabs{display:flex;gap:4px;padding:14px 18px 0;background:#0d0d0d!important;flex-wrap:wrap}
#mtp-zamba2vl-explainer .z2-tab{
background:transparent!important;color:#9aa0a6!important;border:0!important;border-bottom:2px solid transparent!important;
padding:10px 14px;font-size:14px;font-weight:700;cursor:pointer;font-family:inherit
}
#mtp-zamba2vl-explainer .z2-tab:hover{color:#e8e8e8!important}
#mtp-zamba2vl-explainer .z2-tab.active{color:#76B900!important;border-bottom:2px solid #76B900!important}
#mtp-zamba2vl-explainer .z2-panel{display:none;padding:22px 26px 8px}
#mtp-zamba2vl-explainer .z2-panel.active{display:block}
#mtp-zamba2vl-explainer .z2-h{color:#fff!important;font-size:16px;font-weight:800;margin-bottom:4px}
#mtp-zamba2vl-explainer .z2-note{color:#8a9097!important;font-size:12.5px;margin-top:10px}
/* pipeline */
#mtp-zamba2vl-explainer .z2-pipe{display:flex;align-items:stretch;gap:0;margin:14px 0 4px;overflow-x:auto;padding-bottom:6px}
#mtp-zamba2vl-explainer .z2-stage{
background:#151515!important;color:#d6d6d6!important;border:1px solid #2a2a2a!important;border-radius:9px!important;
padding:11px 12px;font-size:12.5px;font-weight:700;cursor:pointer;white-space:nowrap;flex:0 0 auto;transition:.15s;text-align:center
}
#mtp-zamba2vl-explainer .z2-stage:hover{border-color:#3d3d3d!important}
#mtp-zamba2vl-explainer .z2-stage.active{border-color:#76B900!important;background:#16210a!important;color:#cde89a!important}
#mtp-zamba2vl-explainer .z2-arrow{display:flex;align-items:center;color:#3a3a3a!important;padding:0 6px;font-size:16px;flex:0 0 auto}
#mtp-zamba2vl-explainer .z2-stage-detail{
background:#121212!important;border:1px solid #222!important;border-radius:9px!important;padding:14px 16px;font-size:13.5px;color:#cdd0d3!important;margin-top:6px
}
#mtp-zamba2vl-explainer .z2-stage-detail b{color:#fff!important}
/* efficiency lab */
#mtp-zamba2vl-explainer .z2-lab{margin-top:6px}
#mtp-zamba2vl-explainer .z2-presets{display:flex;gap:7px;flex-wrap:wrap;margin:12px 0}
#mtp-zamba2vl-explainer .z2-preset{
background:#151515!important;color:#bdbdbd!important;border:1px solid #2a2a2a!important;border-radius:7px!important;
padding:6px 11px;font-size:12px;font-weight:600;cursor:pointer;font-family:inherit
}
#mtp-zamba2vl-explainer .z2-preset:hover{border-color:#76B900!important;color:#cde89a!important}
#mtp-zamba2vl-explainer .z2-slider{width:100%;margin:6px 0 2px;accent-color:#76B900;height:4px}
#mtp-zamba2vl-explainer .z2-tok{color:#fff!important;font-size:20px;font-weight:800;font-variant-numeric:tabular-nums}
#mtp-zamba2vl-explainer .z2-tok small{color:#8a9097!important;font-size:12.5px;font-weight:600;display:block;margin-top:2px}
#mtp-zamba2vl-explainer .z2-bars{margin-top:16px;display:flex;flex-direction:column;gap:14px}
#mtp-zamba2vl-explainer .z2-bar-row .z2-bl{display:flex;justify-content:space-between;font-size:12.5px;margin-bottom:5px}
#mtp-zamba2vl-explainer .z2-bl .z2-lbl{color:#cfcfcf!important;font-weight:700}
#mtp-zamba2vl-explainer .z2-bl .z2-val{color:#fff!important;font-weight:800;font-variant-numeric:tabular-nums}
#mtp-zamba2vl-explainer .z2-track{background:#1a1a1a!important;border:1px solid #242424!important;border-radius:6px!important;height:16px;overflow:hidden}
#mtp-zamba2vl-explainer .z2-fill{height:100%;width:0;border-radius:5px;transition:width .35s ease}
#mtp-zamba2vl-explainer .z2-fill.tf{background:#E0A050!important}
#mtp-zamba2vl-explainer .z2-fill.z2{background:#76B900!important}
#mtp-zamba2vl-explainer .z2-ratio{
margin-top:16px;background:#16210a!important;border:1px solid #2e4413!important;border-radius:9px!important;padding:12px 14px;
color:#cde89a!important;font-size:14px;font-weight:700;text-align:center
}
#mtp-zamba2vl-explainer .z2-ratio b{color:#76B900!important;font-size:18px}
#mtp-zamba2vl-explainer .z2-callout{
margin-top:14px;background:#101010!important;border:1px solid #222!important;border-radius:9px!important;padding:12px 14px;font-size:13px;color:#b9bdc2!important
}
#mtp-zamba2vl-explainer .z2-callout b{color:#fff!important}
/* benchmarks */
#mtp-zamba2vl-explainer .z2-bench-tabs{display:flex;gap:6px;flex-wrap:wrap;margin:12px 0 18px}
#mtp-zamba2vl-explainer .z2-bt{
background:#151515!important;color:#bdbdbd!important;border:1px solid #2a2a2a!important;border-radius:7px!important;
padding:6px 11px;font-size:12px;font-weight:700;cursor:pointer;font-family:inherit
}
#mtp-zamba2vl-explainer .z2-bt:hover{border-color:#3d3d3d!important}
#mtp-zamba2vl-explainer .z2-bt.active{background:#76B900!important;color:#0d0d0d!important;border-color:#76B900!important}
#mtp-zamba2vl-explainer .z2-brow{margin-bottom:11px}
#mtp-zamba2vl-explainer .z2-brow .z2-bl{display:flex;justify-content:space-between;font-size:12.5px;margin-bottom:4px}
#mtp-zamba2vl-explainer .z2-brow .z2-mname{color:#cfcfcf!important;font-weight:600}
#mtp-zamba2vl-explainer .z2-brow.lead .z2-mname{color:#cde89a!important;font-weight:800}
#mtp-zamba2vl-explainer .z2-brow .z2-score{color:#fff!important;font-weight:800;font-variant-numeric:tabular-nums}
#mtp-zamba2vl-explainer .z2-btrack{background:#1a1a1a!important;border:1px solid #242424!important;border-radius:5px!important;height:13px;overflow:hidden}
#mtp-zamba2vl-explainer .z2-bfill{height:100%;width:0;background:#3a3a3a!important;border-radius:4px;transition:width .45s ease}
#mtp-zamba2vl-explainer .z2-bfill.lead{background:#76B900!important}
/* footer / tagline */
#mtp-zamba2vl-explainer .z2-foot{
margin-top:14px;padding:18px 26px;background:#0a0a0a!important;border-top:1px solid #1c1c1c!important;
display:flex;align-items:center;gap:12px;flex-wrap:wrap;justify-content:space-between
}
#mtp-zamba2vl-explainer .z2-foot .z2-brand{font-size:13.5px;color:#9aa0a6!important}
#mtp-zamba2vl-explainer .z2-foot .z2-brand b{color:#76B900!important;font-weight:800}
#mtp-zamba2vl-explainer .z2-foot a{
color:#0d0d0d!important;background:#76B900!important;text-decoration:none!important;font-weight:800;font-size:12.5px;
padding:8px 15px;border-radius:7px!important;border:1px solid #76B900!important;white-space:nowrap
}
#mtp-zamba2vl-explainer .z2-line{height:1px!important;background:#1c1c1c!important;border:0!important;margin:8px 0}
@media (max-width:640px){
#mtp-zamba2vl-explainer .z2-head,#mtp-zamba2vl-explainer .z2-panel{padding-left:16px;padding-right:16px}
#mtp-zamba2vl-explainer .z2-tabs{padding-left:10px;padding-right:10px}
#mtp-zamba2vl-explainer .z2-title{font-size:19px}
#mtp-zamba2vl-explainer .z2-tab{padding:9px 9px;font-size:13px}
#mtp-zamba2vl-explainer .z2-foot{padding:16px;flex-direction:column;align-items:flex-start}
#mtp-zamba2vl-explainer .z2-pipe{padding-bottom:8px}
}
Interactive Explainer
Zamba2-VL: Hybrid SSM–Transformer Vision-Language Models
Open VLMs at 1.2B, 2.7B, and 7B that replace dense attention with a Mamba2 state-space + Transformer hybrid. Apache 2.0.
1.2B
2.7B
7B
How it works
Why it’s faster
Benchmarks
The pipeline (tap a stage)
Zamba2-VL follows the LLaVA-style template: vision encoder → adapter → language model.
Token-scaling lab
Drag the slider or pick a preset. Attention prefill scales O(n²); the Mamba2 layers scale O(n).
1 hi-res image (~3,400)
A few images (~12,000)
Short video (~24,000)
Long context (~32,000)
3,400 vision tokensabout one high-resolution image
Transformer attention — prefill compute1.0×
Zamba2-VL hybrid — prefill compute1.0×
Transformer KV cache — memory for contextgrows
Zamba2-VL recurrent state — memory for contextfixed
At this length, the hybrid uses about 1.0× less prefill compute
Measured claim: Zyphra reports near-linear-time prefill and a fixed-size recurrent state. On a 32k-token prefill, it reports roughly an order-of-magnitude lower time-to-first-token than the closest Transformer baseline.
Bars above illustrate O(n²) vs O(n) scaling, not measured latency.
Benchmark explorer — Zamba2-VL-2.7B vs baselines
Pick an eval. Green is Zamba2-VL-2.7B. Higher is better.
Source: Zyphra evaluation harness (VLMEvalKit). InternVL3.5-2B and Qwen3-VL-2B are similar in size; Molmo2-4B and Qwen3-VL-4B are larger.
Published by Marktechpost — AI/ML research, model releases, and developer tutorials for engineers and data scientists.
Read more on Marktechpost
(function(){
var root=document.getElementById("mtp-zamba2vl-explainer");
if(!root)return;
var $=function(s){return root.querySelector(s)};
var $all=function(s){return Array.prototype.slice.call(root.querySelectorAll(s))};
/* ---- size selector ---- */
var sizeInfo={
"1.2B":"Edge and on-device tier. Largest relative time-to-first-token advantage. Zyphra reports PixMoCount 62.5, versus 32.8 for InternVL3.5-1B and 17.7 for PerceptionLM-1B.",
"2.7B":"Mid-size generalist, based on the Zamba2-2.7B LLM. Strong visual counting and document understanding; lags larger models on knowledge-heavy reasoning (MMMU, MathVista).",
"7B":"Largest release. Zyphra reports it as competitive with the strongest 7\u20138B open-weight VLMs across nearly every category."
};
function setSize(s){
$all(".z2-size").forEach(function(b){b.classList.toggle("active",b.getAttribute("data-size")===s)});
$("#z2-size-detail").textContent=sizeInfo[s];
}
$all(".z2-size").forEach(function(b){b.addEventListener("click",function(){setSize(b.getAttribute("data-size"))})});
setSize("1.2B");
/* ---- tabs ---- */
$all(".z2-tab").forEach(function(t){
t.addEventListener("click",function(){
var name=t.getAttribute("data-tab");
$all(".z2-tab").forEach(function(x){x.classList.toggle("active",x===t)});
$all(".z2-panel").forEach(functio
関連記事
MIT の研究者が AI モデルにチャートの解釈を教示
MIT の研究者らは、市場の意思決定を加速するため、生成 AI モデルが視覚・数値・言語情報を統合してチャートを正確に解釈する技術を研究している。
Molmo が指差して行動する能力を習得
AI 研究チームは、視覚理解から視覚的行動へと拡張した「MolmoPoint」および「MolmoWeb」を発表し、モデルが世界を見ながら指差しやナビゲーション、対話を行えるようになり、研究者にオープンなツールを提供しました。
ファルコン・パーセプション
AI企業がFalcon Perceptionを発表した。この技術は高度な視覚認識システムであり、自律走行車や監視システムへの応用が期待される。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み