The Pulse:AI 負荷により GitHub が機能不全に陥った理由と他社との違い
GitHub のデータ整合性インシデントと頻発する障害は、開発者コミュニティに深刻な信頼危機をもたらしており、AI エコシステムを含むソフトウェア開発基盤の脆弱性を浮き彫りにした。
キーポイント
致命的なデータ整合性の欠如
マージキューでのスクワッシュマージ機能にバグがあり、2,092 のプルリクエストでコミットが消失する事態が発生し、GitHub の信頼性を根底から揺るがした。
頻発するサービス障害と低可用性
先月の 90% から今月 86% へ可用性が低下し、データ消失に加えプルリクエストやイシューが消えるなどの障害が相次いでいる。
企業対応への批判と信頼喪失
GitHub の経営陣が影響範囲を過小評価する姿勢を見せたことに対し、顧客である Modal などのエンジニアから誠意に欠ける対応として激しい批判が殺到している。
手動復旧による開発者の負担
GitHub が公式サポートを提供せず、影響を受けた企業は自らの手で Git ヒストリを調査し、コミットを手動で復元する作業を強いられた。
Elasticsearch 障害による機能不全
バックエンドの Elasticsearch クラスター過負荷により、プルリクエストやイシューが消失したように見える状態が約6時間続いた。
著名な開発者の離脱と信頼性の低下
HashiCorp 創設者Mitchell Hashimoto氏が、頻発する障害により GitHub を「本格的な作業の場」として見限って離脱を表明した。
公式ステータスと実態の乖離
GitHub 公式ページの信頼性報告に対し、第三者による分析では過去90日間の稼働率が85.51%(ほぼゼロナイン)に過ぎないと指摘されている。
影響分析・編集コメントを表示
影響分析
この事件は、AI モデルの開発やトレーニングに不可欠なコード管理基盤である GitHub の信頼性が揺らぐことを示しており、開発者コミュニティ全体に「インフラ依存リスク」への警戒感を強める結果となった。特にデータ整合性の欠如は復旧コストが膨大になるため、企業は単なる可用性だけでなく、データの完全性を保証するサービス選定基準を見直す必要がある。
編集コメント
AI エコシステムが急成長する中、コード管理という最も基本的なインフラの信頼性が損なわれる事象は、開発者の生産性とセキュリティに直結する重大な警鐘です。
こんにちは、Pragmatic Engineer ニュースレターの特別無料号をお届けします。Gergely です。毎号、シニアエンジニアやエンジニアリングリーダーの視点から、ビッグテックとスタートアップを取り上げています。今回は先週の『The Pulse』で取り上げた 4 つのトピックのうちの一つをご紹介します。フルサブスクライバーには、7 日前に以下の記事をお送りしています。このメールを転送された方は、こちらから登録してください。
GitHub の信頼性は最近、許容できないレベルを超えています:先月、第三者による測定では「1 ナイン」(正確には 90%)と評価されました。今月は、第三者のトラッカーによると信頼性がさらに低下し、「ゼロナイン」すなわち 86% にまで落ち込みました。そして先週は事態がさらに悪化し、事実上恥をかくべきデータ整合性のインシデントが発生し、さらなる停止が続きました。GitHub は最終的に部分的な説明を行いました。
データ整合性インシデント
先週の木曜日(4 月 23 日)、以下のような出来事が起こりました:マージキューを通じてマージされたプルリクエストが、スクワッシュマージ方式を使用していた場合、マージグループに複数の PR が含まれていると、誤ったマージコミットが生成されました。その後のマージからコミットが取り消され、結果として、マージされたコード内でコミットが「消失」してしまったのです!
GitHub 自身が導入したバグにより、スクワッシュマージ(通常は複数の小さなコミットを意味のある単一のコミットに統合するために使用される手法)を使用した場合、プルリクエストが期待通りにマージされるという同社の整合性保証が破られました。これは大きな問題です:データ整合性の保証は、GitHub のようなサービスにおいて最も重要な保証の一つだからです。
合計 2,092 のプルリクエストに影響を受け、停止の影響を受けた企業には Modal や Zipline が含まれていました。実質的に GitHub は、影響を受けた顧客に多くの作業を押し付け、失われたコミットを手動で解きほぐして復旧する必要が生じましたが、GitHub 側はこれに対して何の支援も提供できませんでした。
顧客は手動で git の履歴を確認し、欠落したコードを復元しなければなりませんでした。手動での復旧手順(スクワッシュコミットの取り消しと、コミットを一つずつ再適用)に従った後、すべてのコミットが復元されるはずでした。
GitHub は後に影響を受けたコミットのリストを顧客へメールで送信しましたが、GitHub の経営陣がこの障害の性質を軽視しているように見えるのは奇妙です。結局のところ、データの整合性を損なう障害は、データが破損しない単なる可用性の低下よりもはるかに重大な問題です。
Modal のソフトウェアエンジニアである Can Duruk は、GitHub のこの障害に対する沈黙した対応に不満を抱いていました:
「COO が影響を小さく見せるために巨大な共通項を見つけようとするのは非常に不誠実であり、顧客への約束全体が無効化されたことについて真摯にお詫びすべきです。私たちは彼らのステータスページを調べるまで、単に私たちのリポジトリを軽く扱って壊してしまったことにさえ気づきませんでした。」
障害は止まらない
月曜日(4 月 27 日)、GitHub の Web UI からプルリクエストとイシューが消えました:
 image プルリクエストが行方不明になる。出典:Mario Zechner
image プルリクエストが行方不明になる。出典:Mario Zechner image イシューも検索できない。出典:David Cramer これは、GitHub のバックエンドで Elasticsearch(Elasticsearch)の停止が発生したことが原因でした。クラスターが過負荷となり、ダウンしました。そのため、プルリクエスト、イシュー、プロジェクトは完全に消えたわけではありませんが、6 時間にわたる停止の間は表示されませんでした。
image イシューも検索できない。出典:David Cramer これは、GitHub のバックエンドで Elasticsearch(Elasticsearch)の停止が発生したことが原因でした。クラスターが過負荷となり、ダウンしました。そのため、プルリクエスト、イシュー、プロジェクトは完全に消えたわけではありませんが、6 時間にわたる停止の間は表示されませんでした。
今週は他にも障害がありました:
一部のプルリクエストが表示されない(4 月 28 日火曜日)
一部の GitHub Actions に問題が発生(同日)
リポジトリ内の不完全なプルリクエスト(4 月 29 日水曜日)
また、火曜日(4 月 28 日)、セキュリティ企業 Wiz が重大なセキュリティ問題を公表しました。これは、悪意のあるアクターが git push コマンドを実行するだけで、GitHub および GitHub Enterprise サーバー上のすべてのリポジトリにアクセスできてしまうというものです。GitHub は GitHub.com 上の問題に対し 6 時間以内に修正を施しましたが、更新されていない GitHub Enterprise サーバーは依然として脆弱な状態にあります。
著名なオープンソースコントリビューターが挫折して GitHub を去る
火曜日、HashiCorp の創設者であり Ghostty の作者である Mitchell Hashimoto が、GitHub はプロフェッショナルな作業には適さないと発表し、自身の主たる焦点となっているオープンソースのターミナル「Ghostty」へ移行すると表明しました。Mitchell の理由は極めてシンプルです。GitHub にいることが彼の生産性を低下させているという点です(強調は私による):
「先月の間、私はGitHubの停止が私の作業能力に悪影響を及ぼした日付ごとに『X』をつけて日記をつけました。ほぼ毎日『X』がついています。この投稿を書いている今日も、GitHub Actions の停止により約 2 時間、PR(Pull Request)レビューを行うことができませんでした。もしこれが毎日数時間もの間、あなたを作業から遮断するのであれば、ここで真剣な仕事をする場所ではありません。
もうここは私にとって楽しい場所ではありません。私はそこにいたいのですが、そこは私がいることを望んでいません。私は仕事を終わらせたいのですが、そこは私が仕事を終えることを望んでいません。私はソフトウェアをリリースしたいのですが、そこは私がソフトウェアをリリースすることを望んでいません。
もっと良くなってほしいと願っていますが、同時にコードも書きたいのです。しかしもう GitHub ではコードが書けません。申し訳ありません。18 年の歳月を経て、私は去らなければなりません。いつか戻りたいとは思いますが、それは言葉や約束ではなく、実際の結果と改善に基づいて初めて可能になるでしょう。」
Mitchell の経験は、GitHub の公式ステータスページが彼のような重度のユーザーにとって不正確であることを示唆しています。サードパーティ製の「GitHub ステータスページ不在」の方がより現実的な推定値である可能性が高く、そこでは GitHub の信頼性はゼロ・ナイン(99.99% 以上の稼働率)に達しておらず、稼働率は 85.51% に留まっています。これは過去 90 日間にわたり、GitHub の一部が平均して毎日 2〜3 時間ダウンしていたことを意味します(!!)。
信頼性の問題:GitHub は「本格的な作業には適さない場所」。出典:存在しない GitHub ステータスページ
Mitchell の不満は非常に明快です。
プロのソフトウェアエンジニアとして、作業を遂行するためのツールが不可欠です。
数ヶ月にわたり、GitHub は一連の障害により、オープンソースプロジェクトでの彼の作業を妨げてきました。
本格的な業務には不適切な製品を使用する意味はありません。
GitHub に改善の兆しが見られない以上、単に動作する別のソリューションへ移行する価値があります。
CTO が AI エージェントによる負荷急増を指摘
GitHub の CTO である Vlad Fedorov は、数ヶ月にわたる信頼性の低下の原因について更新情報を共有しました。彼は、エージェントからの負荷が予想以上に大きかったことが原因であると特定しました。この状況を説明するグラフは GitHub から公開されています。
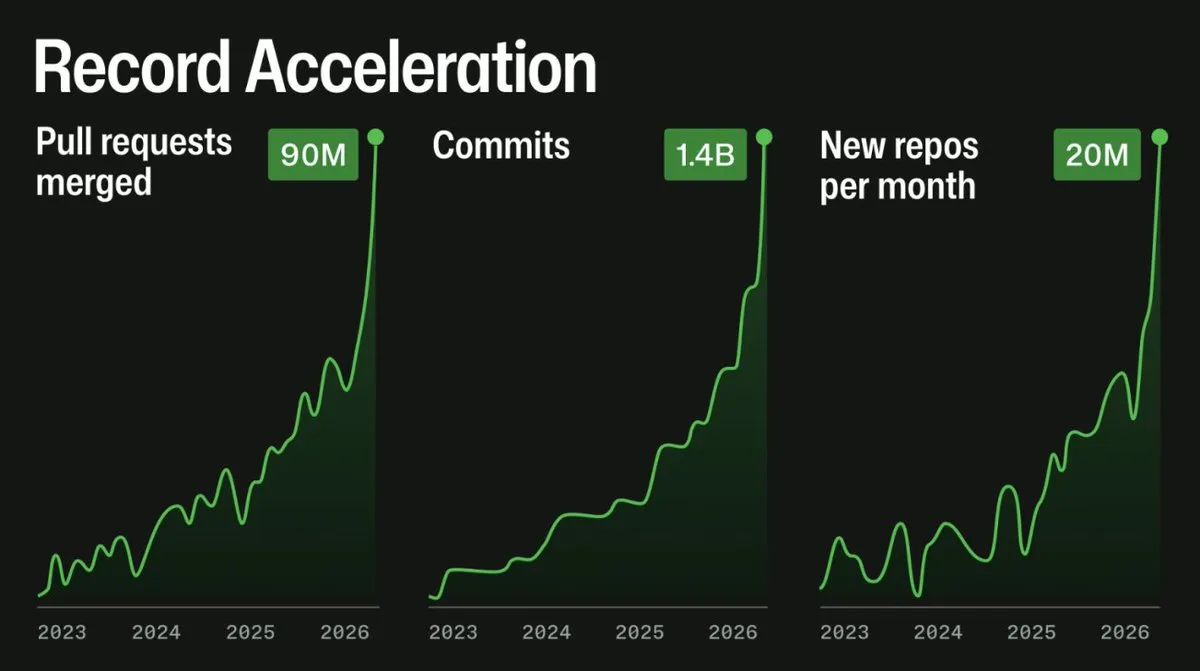
このグラフは目を引きますが、たった一つの小さな問題があります。Y 軸(縦軸)が存在しないのです!したがって、負荷がゆっくりと、そして非常に急速に増加しているという物語は語られていますが、その増加幅がどれほどであったかは示されていません。しかし、私は GitHub からデータを入手し、以下に過去 2 年間の実際の負荷増加を示すグラフを掲載します:
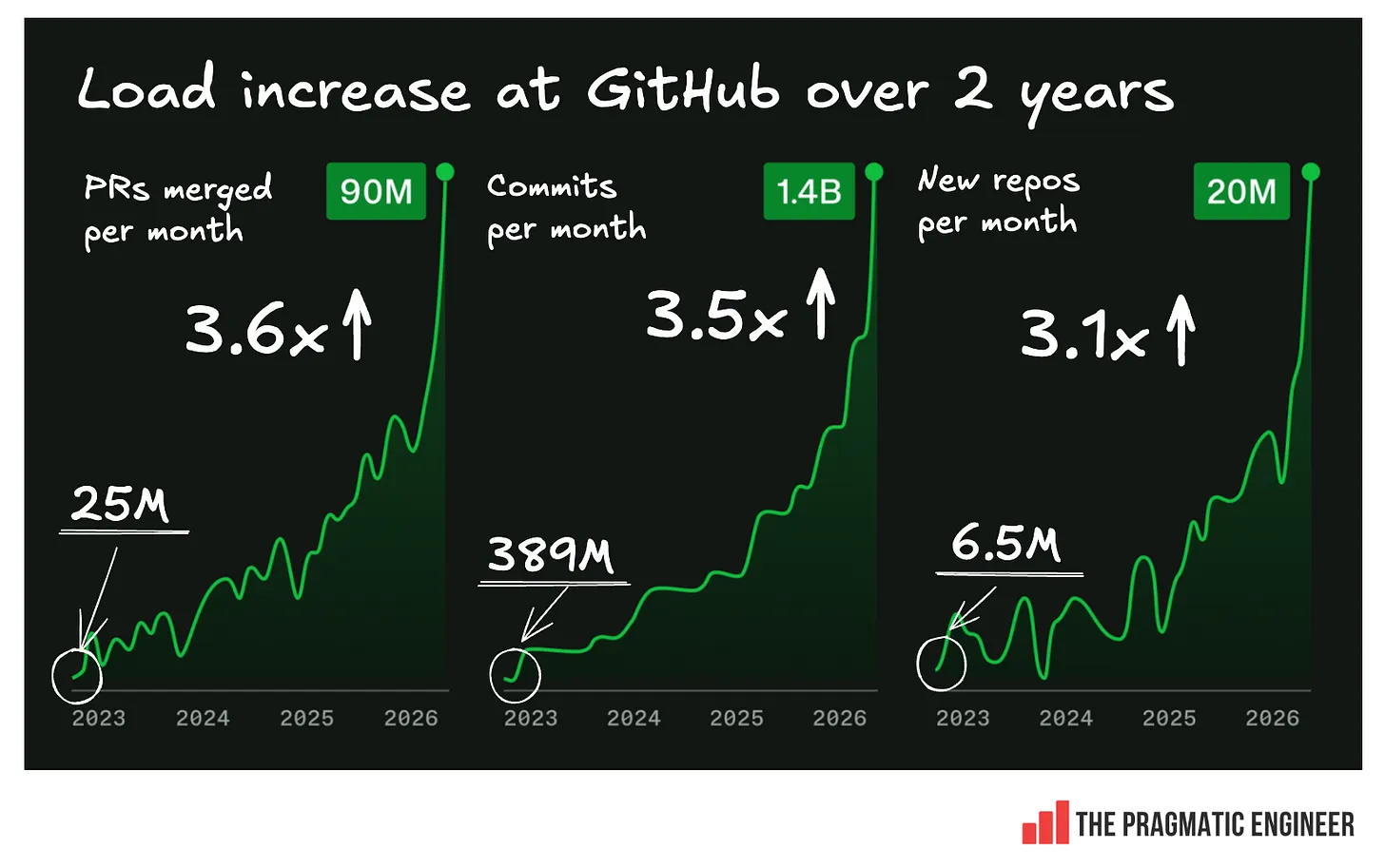 image 2 年間にわたって約 3.5 倍に増加した負荷は、一見するとそれほど過酷なものには見えません。これは 1 ヶ月で 10 倍になるような負荷増とは全く異なり、その多くが直近の数ヶ月に発生したものです。では、なぜ GitHub はこれに対応できないのでしょうか?ブログ記事の中で Fedorov は次のように述べています。
image 2 年間にわたって約 3.5 倍に増加した負荷は、一見するとそれほど過酷なものには見えません。これは 1 ヶ月で 10 倍になるような負荷増とは全く異なり、その多くが直近の数ヶ月に発生したものです。では、なぜ GitHub はこれに対応できないのでしょうか?ブログ記事の中で Fedorov は次のように述べています。
「プルリクエストは、Git ストレージ、マージ可能性チェック、ブランチ保護、GitHub Actions、検索、通知、権限、Web フック、API、バックグラウンドジョブ、キャッシュ、データベースにまで影響を及ぼします。大規模なスケールでは、小さな非効率性が積み重なり、キューが深くなり、キャッシュミスがデータベース負荷となり、インデックスが追いつかなくなり、リトライがトラフィックを増幅し、1 つの遅い依存関係が複数の製品体験に影響を与えます」
2023 年 1 月と現在の 1 秒あたりの負荷数値を比較すると以下のようになります。
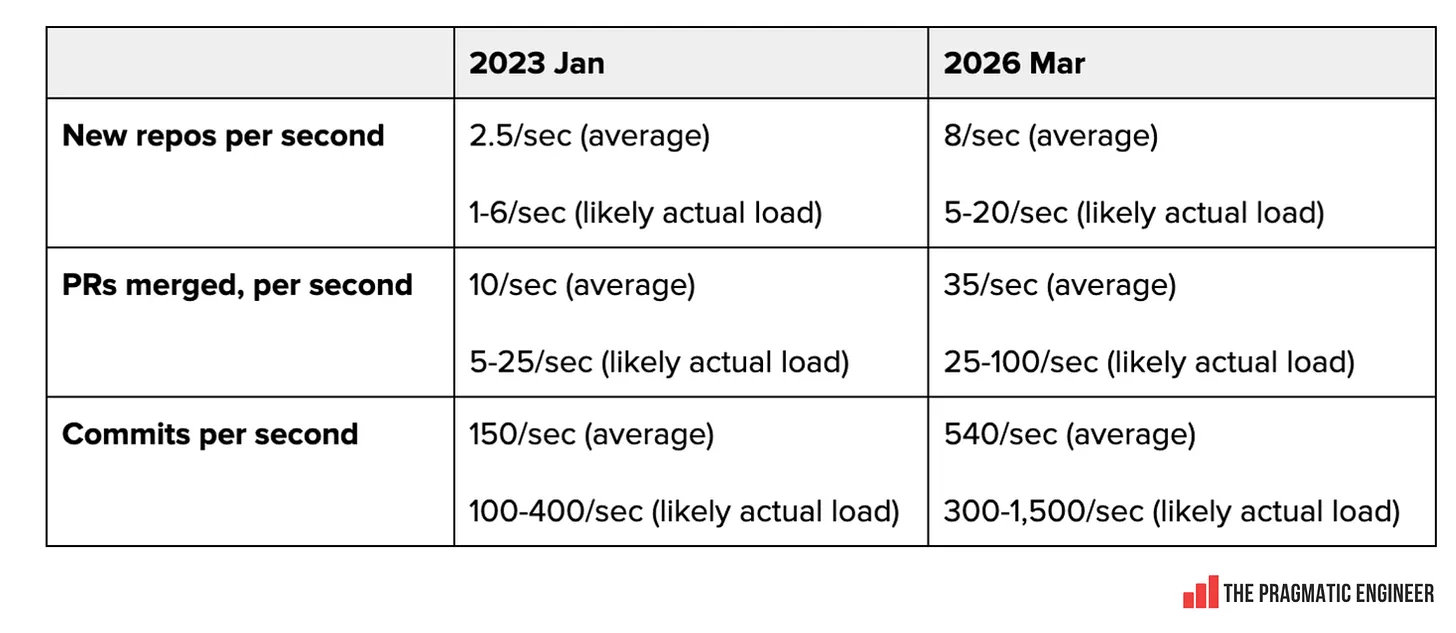 image GitHub は 2023 年の数値を達成するまでに 15 年を要しました。そして、将来も同様のペースで成長し続けると想定していたのかもしれません。もしそうであれば、長期的なインフラストラクチャの改善に関するいくつかのエンジニアリング上の判断は、AI エージェントの登場によって陳腐化してしまっていたはずです。
image GitHub は 2023 年の数値を達成するまでに 15 年を要しました。そして、将来も同様のペースで成長し続けると想定していたのかもしれません。もしそうであれば、長期的なインフラストラクチャの改善に関するいくつかのエンジニアリング上の判断は、AI エージェントの登場によって陳腐化してしまっていたはずです。
GitHub の課題にさらに拍車をかけるのは、同社が自社のデータセンターから Azure への移行を進行中であるという点です。昨年 10 月、GitHub はすでに自社のデータセンター容量に限界があったため、Azure への移転を開始しました。このプロジェクトは 12 ヶ月を要すると見込まれています。
サービスの負荷が比較的安定している場合でも、このような大規模なインフラ移行は十分困難です。何も壊れないように確認するだけで多大な労力が必要となります。しかし、負荷が急増している時期に移動を行うということは、バグがより目に見える障害を引き起こす可能性があることを意味します。もちろん、GitHub は今や何を予想すべきかを知っているため、Azure 上でさらに多くのコンピューティング容量を確保できるようになりました。
他の主要企業はインフラ負荷の10倍増加に備えて準備していましたが、なぜマイクロソフト/ GitHub はそうしなかったのでしょうか?一年前、私はビッグテック企業がビジネスへのAIの影響に対応するためにどのように準備しているかについて調査を行いました。Google は、負荷が10倍増えることを想定して内部システムを改善していました。先月『The Pragmatic Engineer』で取り上げた通り、昨年7月の記事では次のように記されていました。
「Google は、出荷されるコード量が10倍になることに備えています。元 Google サイト信頼性エンジニア(SRE)が私に語ったところによると:
「私が SRE の友人たちから聞いているのは、彼らが本番環境に投入されるコードの行数が10倍になることを想定して準備しているということです」
AI ツールの影響に関するデータを持っている可能性が高い企業といえば Google です。生成されるコード量が10倍になれば、おそらくコードレビュー、デプロイメント、機能フラグ、ソースコントロールのフットプリント、そして注意深く扱わなければバグや障害さえも10倍になるでしょう。」
業界内では膨大な負荷の増加が予測されていたことは秘密の知識ではありませんでしたが、GitHub はその潜在的な規模に対して無知だったようです。Vlad によると、GitHub は最終的に容量を 10 倍に増やす必要性を計画していましたが、それは 2025 年 10 月のことで、それから数ヶ月後の話でした。そして 2026 年 2 月には、同社はその見通しを 30 倍へと修正しています。彼はこう記述しました。
「私たちは 2025 年 10 月に GitHub の容量を 10 倍に増やす計画の実行を開始し、信頼性とフェイルオーバー(障害発生時の切り替え)の大幅な改善を目指していました。しかし 2026 年 2 月には、今日のスケーラビリティの 30 倍が必要となる未来のために設計する必要があることが明確になりました。」
また、GitHub が爆発的な負荷成長への準備に要した時間を過小評価していたのではないか、そして今年初めに予想よりも数ヶ月早くその成長が現実のものとなった際に驚かされたのではないかという疑問もあります。
GitHub が主要な負荷増加の準備を始めたのは 10 月だけであるため、現在の問題が予期せぬものではないことは当然です。GitHub のような規模では、各サービスを担当するチームが自社のサービスの負荷量を予測して 1 年前から計画を立てることは一般的であり、ストレージや VM(仮想マシン)、ネットワークなどのハードウェアリソースもそれに応じて割り当てられます。負荷計画は準備の最大半分を占めることもあり、現実が計画通りにいかない場合、一部のシステムではスケールアップに苦労することがあります。
まず、2年間で負荷が3.5倍に増加した事象は、多くのサービスにとってはそれほど大きな問題ではないはずです。特に状態(ステート)をあまり保持せず、新しいノードを追加するだけでスケーリングが実現できる水平方向への拡張が可能であればなおさらです。しかし、GitHub はプルリクエスト、ワークフロー、プロジェクトなどにおいて、おそらく非常に多くの状態情報を保持しています。これがデータベースやワークフローを実行するシステムにおけるスケーリングをより困難にしていると考えられます。
また、GitHub には18年にわたる技術的負債(tech debt)が蓄積しており、組織的なオーバーヘッドとして調整すべき数千名の従業員を抱えています。サービスの負荷が以前よりも急速に増加する中、これらの蓄積された「負債」のために対応はより困難になっています:
技術的負債:同社の多くのシステムは10年以上前に構築されたものであり、おそらくパッチ適用の積み重ねによって維持されているため、変更が難しく、リスクも高くなっています。
組織的負債:GitHub には約4,000人が勤務しており、そのうちエンジニアは1,000人です。チーム間には相互依存関係があり、一見単純な作業であっても、数十人のエンジニアが連携して取り組む必要がある場合があります。
顧客の期待:システムの変更をより迅速に行うことを意味するとしても、GitHub は顧客のワークフローを中断することはできません。
GitHub は「イノベーターのジレンマ」に直面しています。同社は AI 以前、開発者ワークフローを合理的に構築したことで成功を収め、サービス負荷の変化を正確に予測できる時代がありました。しかし現在、エンジニアリングチームのワークフローには AI エージェントが含まれるようになり、GitHub の独自のワークフローが必ずしも最適な適合とはならなくなりました。その結果、同社はサービスレベルの変化を予測することに失敗しました。
他のベンダーも AI 負荷で足元をすくわれたのか?実はそうでもない
この状況について納得できない点の一つは、おそらく同様の負荷スパイクを経験している他のベンダーが、GitHub のように信頼性の問題に苦しんでいないように見えることです。Vercel、Linear、Resend、Railway、Sentry、およびその他のインフラプロバイダーは AI によって記録的な成長を遂げていますが、負荷には対応し続けています。
はい、Anthropic、OpenAI、Cursor といった AI ベンダーにもいくつかの信頼性の問題はありますが、GitHub の規模に比べればはるかに小さいものです。GitHub の直接競合である GitLab や Bitbucket も同様に負荷が増加していると考えられますが、ダウンタイムが GitHubほど深刻ではありません。
明白な疑問として、GitHub の苦痛のうちどれほどが自業自得なのかという点があります。Microsoft がオーナーであるため、他社やスタートアップよりも多くのリソースを有していますが、負荷増加を予測できず、またスタートアップのような機敏さで対応するには大きすぎます。
大規模な負荷増加への対応は確かに困難な課題ですが、平均的なエンジニアリングチームと突出したチームとの差が如実に現れる瞬間でもあります。GitHub は世界クラスのエンジニア組織として振る舞っていません。
GitHub の代替手段は?
GitHub の常連ユーザーは、継続する障害の痛みを肌で感じています。開発者としては、マイクロソフトが最終的に信頼性を向上させることを期待するか、あるいは代替手段を探すかのどちらかです。前述した通り、ミッチェル氏は辞職を決め、現在 Ghostty をどこに移すかを検討中です。
明白な代替手段は、GitHub の最大の競合他社である GitLab と Bitbucket です。両者とも Git ホスティングを提供しており、GitHub が苦しんでいるような稼働率の問題はありません。
セルフホスト型ソリューションも選択肢の一つです。例えば、Git リポジトリを自分でホストするか、オープンソースでローカルファーストの GitHub 代替品である Forgejo などのセルフホスト型フォージを利用する方法があります。
また、近い将来、GitHub に似たコードホスティング機能を提供しつつ、より堅牢な稼働率を実現し、GitHub が将来的にサポートしたいと願う 30 倍規模以上のスケールに対応できるアーキテクチャで構築されたスタートアップが現れるのではないかと推測しています。
先週の『The Pulse』の完全版を読むか、今週の『The Pulse』をチェックしてください。今週の問題では以下を取り上げています:
Anthropic は容量不足により開発者に対して敵対的になったのか?
Amazon がついに Claude Code と Codex の利用を許可
Meta が人員削減前にエンジニアを強制的にデータラベリング業務へ割り当て
新しいトレンド:小規模な「AI フォワード」チーム
業界パルス:メタが従業員のコンピューター活動を追跡する理由、OpenAI が Datadog から移行を開始、Apple が Claude Code の使用を漏らして明かす、GitHub から Xbox への Microsoft 内での移管、Copilot が何もしなくても VS Code に「Copilot と共同作成」と表示される件、Coinbase の人員削減に関する分析
業界パルス:メタが従業員のコンピューター活動を追跡する理由、OpenAI が Datadog から移行を開始、Apple が Claude Code の使用を漏らして明かす、GitHub から Xbox への Microsoft 内での移管、Copilot が何もしなくても VS Code に「Copilot と共同作成」と表示される件、Coinbase の人員削減に関する分析
原文を表示
Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover Big Tech and startups through the lens of senior engineers and engineering leaders. Today, we cover one out of four topics from last week’s The Pulse issue. Full subscribers received the article below seven days ago. If you’ve been forwarded this email, you can subscribe here.
GitHub’s reliability has been beyond unacceptable recently: last month, third party measurements pinned it at one nine (right at 90%). This month, reliability has been down to zero nines – 86% – as per a third-party tracker, and last week, things got even worse: a frankly embarrassing data integrity incident, more outages, and a partial explanation from GitHub, eventually.
Data integrity incident
Last Thursday (23 April), this happened: PRs merged via the merge queue using the squash merge method produced incorrect merge commits, when the merge group contained more than one PR. Commits were reverted from subsequent merges: basically, commits were “lost” in the code that was merged!
Thanks to a bug GitHub introduced, the service broke its integrity promise that pull requests would be merged as expected when using squash merge, which is a technique typically used to merge multiple small commits into a single, meaningful commit. This is a big deal: as data integrity promises are some of the most important ones, for services like GitHub.
A total of 2,092 pull requests were impacted, and companies hit by the outage included Modal and Zipline. Effectively, GitHub pushed a bunch of work on affected customers who had to manually untangle and recover lost commits, which GitHub could offer zero assistance with.
Customers had to manually go through their git history and restore missing code. After following manual recovery steps (reverting the squash commit and re-applying commits one by one), all commits should have been recovered.
GitHub later emailed the list of affected commits to customers, but it’s odd that GitHub executives seemed to downplay the nature of this outage. After all, an outage that messes with data integrity is a much bigger deal than something like a fall in availability where no data is corrupted.
Can Duruk, software engineer at Modal, was unhappy about GitHub’s muted response to the outage:
“The COO going out of their way to find a huge denominator to make the impact appear small feels very dishonest; versus a sincere apology about how this invalidates their entire promise to their customers. We had to dig into their status page about this to even realize they just casually f***ed up our repo.”
Outages don’t stop
On Monday (27 April), pull requests and issues disappeared from GitHub’s web UI:
imagePull requests go missing. Source: Mario ZechnerimageIssues also not to be found. Source: David CramerThis had to do with an Elasticsearch outage on GitHub’s backend: the cluster became overloaded and went down. So, while pull requests, issues, and projects didn’t vanish altogether, they also didn’t show up during the 6-hour-long outage.
There were other outages this week:
Some pull requests not showing up (Tuesday, 28 April)
Problems with some GitHub Actions (the same day)
Incomplete pull requests in repositories (Wednesday, 29 April)
Also on Tuesday (28 April), security firm Wiz disclosed a critical security issue, where a bad actor could get access to all repositories on GitHub and GitHub Enterprise server by using only a git push command. GitHub fixed the issue on GitHub.com within six hours, but GitHub Enterprise servers that were not updated remain vulnerable.
Famous open source contributor quits GitHub in frustration
On Tuesday, Mitchell Hashimoto, founder of HashiCorp, creator of Ghostty, announced GitHub was unfit for professional work and that he was moving off to Ghostty, the open source terminal that’s his main focus. Mitchell’s reasoning was dead simple: being on GitHub makes him unproductive (emphasis mine:)
“The past month I’ve kept a journal where I put an “X” next to every date where a GitHub outage has negatively impacted my ability to work. Almost every day has an X. On the day I am writing this post, I’ve been unable to do any PR review for ~2 hours because there is a GitHub Actions outage. This is no longer a place for serious work if it just blocks you out for hours per day, every day.
It’s not a fun place for me to be anymore. I want to be there, but it doesn’t want me to be there. I want to get work done and it doesn’t want me to get work done. I want to ship software and it doesn’t want me to ship software.
I want it to be better, but I also want to code. And I can’t code with GitHub anymore. I’m sorry. After 18 years, I’ve got to go. I’d love to come back one day, but this will have to be predicated on real results and improvements, not words and promises.”
Mitchell’s experience suggests that GitHub’s official status page is inaccurate from the point of view of a heavy user like himself. The third-party “missing GitHub status page” is likely to be a better estimation: where GitHub’s reliability is at zero nines: at 85.51% uptime. That means that a part of GitHub was down for 2-3 hours, per day, on average, for the last 90 days (!!)
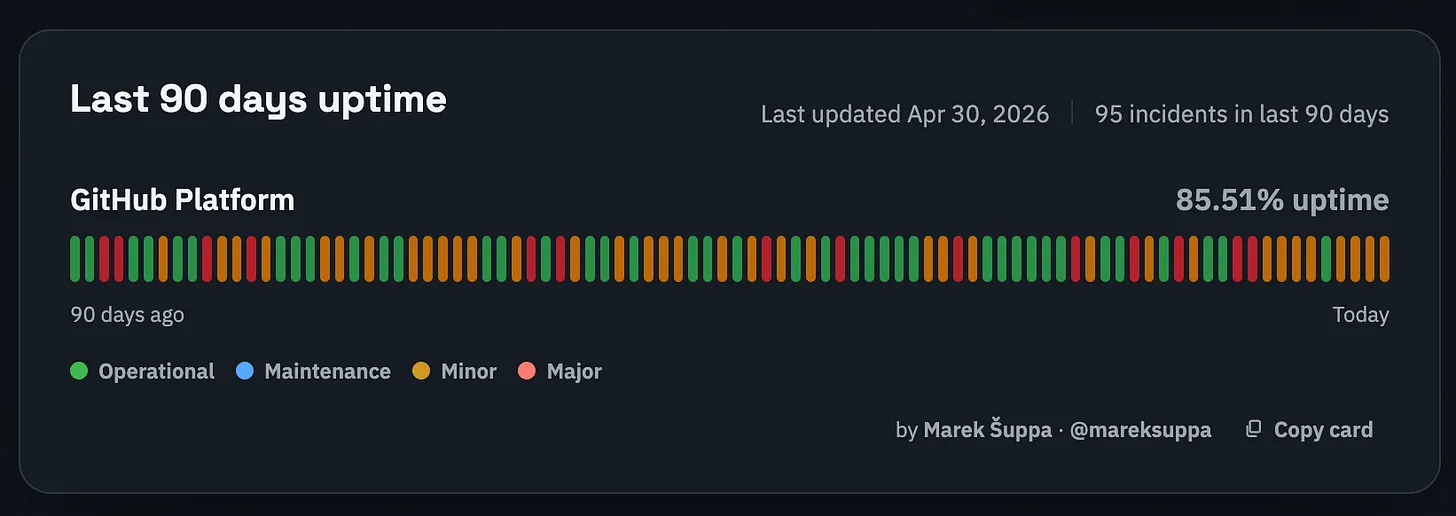 imageReliability woes: GitHub “not a place for serious work.” Source: The Missing GitHub Status PageMitchell’s complaint sounds straightforward:
imageReliability woes: GitHub “not a place for serious work.” Source: The Missing GitHub Status PageMitchell’s complaint sounds straightforward:
As a professional software engineer, it’s important to have tools that help you get work done
For months, GitHub has got in the way of his work on open source projects via a flood of outages
It makes no sense to use a product unfit for professional work.
As GitHub shows no signs of improvement, it’s worthwhile to move to a different solution which just works
CTO blames AI agent-fuelled load spike
GitHub CTO, Vlad Fedorov, shared an update on why reliability has been terrible for months at GitHub. He identified the load from agents being much bigger than expected as the culprit. Charts illustrating this were shared by GitHub:
imageThis chart looks eye-catching – but there’s just one tiny issue: no Y axis! So, while it tells the story of the load going up slowly and then very fast, we’re not told by how much. However, I managed to get data from GitHub, and below is the chart showing the actual load increase over two years:
imageA load increase of ~3.5x, spread across two years, doesn’t seem so brutal at first glance. It is nothing like a load increase of 10x in a month, and a good chunk of it occurred in recent months. So, why can’t GitHub handle it? In a blog post, Fedorov said:
“A pull request can touch Git storage, mergeability checks, branch protection, GitHub Actions, search, notifications, permissions, webhooks, APIs, background jobs, caches, and databases. At large scale, small inefficiencies compound: queues deepen, cache misses become database load, indexes fall behind, retries amplify traffic, and one slow dependency can affect several product experiences.”
Here’s how the per-second load numbers from January 2023 and today compare:
imageGitHub took 15 years to achieve the 2023 numbers, and maybe it expected to continue growing in a comparable way in the future. If so, some engineering decisions about long-term infrastructure improvements would have been made obsolete by the arrival of AI agents.
To add to GitHub’s challenges, the company is in the midst of a migration from its own data centers → Azure. In October last year, GitHub started to move over to Azure – a project expected to take 12 months – because it already had constraints on its own data center capacity.
Such large-scale infrastructure migrations are hard enough when the load on a service is relatively stable; just making sure nothing breaks takes a lot of effort. But moving at a time when load is spiking means that bugs can cause more visible outages. Of course, GitHub can secure a lot more compute capacity on Azure, now they know what to expect.
But other major companies prepared for a 10x increase in infra load, so why not Microsoft / GitHub? A year ago, I did research on how Big Tech was preparing to respond to the impact of AI on their business. Google was improving its internal systems to accommodate for a 10x increase in load. As we covered in The Pragmatic Engineer, in July last year:
“Google is preparing for 10x more code to be shipped. A former Google Site Reliability Engineer (SRE) told me:
“What I’m hearing from SRE friends is that they are preparing for 10x the lines of code making their way into production.”
If any company has data on the likely impact of AI tools, it’s Google. 10x as much code generated will likely also mean 10x more: code review, deployments, feature flags, source control footprint and, perhaps, even bugs and outages, if not handled with care.”
Predicted enormous load increases were not secret knowledge within the industry, yet it seems GitHub was blissfully ignorant of their potential size. According to Vlad, GitHub did eventually plan for a need to increase capacity by 10x, but this was in October 2025, months later. In February 2026, the company is now adjusting that expectation to 30x. He wrote:
“We started executing our plan to increase GitHub’s capacity by 10X in October 2025 with a goal of substantially improving reliability and failover. By February 2026, it was clear that we needed to design for a future that requires 30X today’s scale.”
There’s also the question of whether GitHub miscalculated how much time it had to prepare for explosive load growth, and whether it was caught off guard when that growth materialized months sooner than expected at the start of this year.
Given GitHub only started to prepare for a major load increase in October, its current problems are unsurprising. At the scale of GitHub, it’s common enough for each team owning a service to plan a year ahead on how much load their service will have, and hardware resources like storage, VMs, and networking are allocated accordingly. Load planning can account for up to half of the preparations, and when reality doesn’t conform to plans, some systems can struggle to scale up.
So, on one hand, dealing with a 3.5x increase in load over 2 years should not be such a big deal for most services; especially not ones which can be horizontally scaled (when there’s not much state, and scaling is achieved simply by adding new nodes.) But GitHub probably stores a lot more state with pull requests, workflows, projects, etc. This probably makes scaling more tricky when it comes to databases and systems running workflows.
GitHub also has 18 years of tech debt on its hands, and thousands of staff to align as “organizational overhead.” As its service load grows faster than before, responding is harder due to all that accumulated “debt”:
Tech debt: many systems at the company are 10+ years old and are likely patched up, making them more difficult and risky to change
Organizational debt: around 4,000 people work at GitHub, of whom 1,000 are engineers. Teams have dependencies with each other, and even seemingly simple work can require dozens of engineers to work together
Customer expectations: GitHub cannot break customer workflows, even if doing so would mean changes to systems happen faster
GitHub finds itself in the ‘innovator’s dilemma’: the company became successful because it built developer workflows that made sense, pre-AI, and it used to be able to accurately forecast service load changes. But now that engineering teams’ workflows include AI agents, GitHub’s own workflows are not necessarily the best fit, and the company failed to forecast service-level changes.
Other vendors floored by AI load? Not really
One thing that doesn’t add up about the situation is that other vendors who are presumably experiencing similar load spikes don’t appear to be suffering with reliability issues as much. Vercel, Linear, Resend, Railway, Sentry, and other infra providers see record-level growth thanks to AI, but keep up with the load.
Yes, it’s true that AI vendors like Anthropic, OpenAI, and Cursor have some reliability issues, but it’s not at the scale of GitHub’s. GitHub’s direct competitors, GitLab and Bitbucket, presumably see load going up similarly, but they’re not going down as much.
An obvious question is how much of GitHub’s pain is self-inflicted? With Microsoft as owner, it has more resources at its disposal than any competitor or startup, and yet failed to predict load increases and is too big to respond with the nimbleness of a startup.
It’s undeniable that solving for a major load increase is a hard challenge; it’s when the difference between average and standout engineering teams is apparent. GitHub hasn’t been responding like a world-class engineering org.
GitHub alternatives?
Every regular user of GitHub feels the pain of ongoing outages. As a dev, you can either hope Microsoft will eventually improve reliability, or seek alternatives. As covered above, Mitchell has chosen to quit and is currently deciding where to take Ghostty.
The obvious alternatives are GitHub’s biggest competitors, GitLab, and Bitbucket. Each offers Git hosting, and neither comes with the uptime woes that GitHub is suffering from.
Self-hosted solutions are also an option, like self-hosting your git repo, or going with a self-hosted forge like Forgejo, which is an open source, local-first GitHub alternative.
I also suspect that, soon enough, we’ll see startups offering GitHub-like code hosting capabilities, while offering more robust uptime and being architected to handle the 30x-or-more scale which GitHub hopes one day to support.
Read the full issue of last week’s The Pulse, or check out this week’s The Pulse. This week’s issue covers:
Did Anthropic turn hostile on devs because capacity was running low?
Amazon finally allows Claude Code and Codex usage
Meta forcefully assigns engineers to data labelling ahead of job cuts
New trend: small “AI-forward” teams
Industry Pulse: why Meta tracks employees’ computer activity, OpenAI starts to move off Datadog, Apple lets slip it uses Claude Code, GitHub → Xbox transfers at Microsoft, VS Code inserted “coathored by Copilot” even when Copilot did nothing, analysis of the Coinbase layoffs
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み