[AINews] セレブラスの 600 億ドル IPO:ゆっくり、そして一気に
Cerebras が 600 億ドル規模の IPO を成功させ、OpenAI の大規模モデルを含むトリリオンパラメータモデルへの対応能力を実証し、推論インフラにおける重要な転換点を示した。
キーポイント
Cerebras の IPO と市場評価
1 つの S-1 撤回と OpenAI との巨大な提携を経て、Cerebras は時価総額 600 億ドルで IPO を達成し、大規模チップへの投資が正当化された。
OpenAI モデルとの提携と能力実証
CFO の Bob Komin 氏は、同社が OpenAI の内部モデル(5.4 および 5.5)を含むトリリオンパラメータ規模のモデルを処理可能であり、サイズに制限がないと明言した。
推論インフラの転換点としての IPO
投資家や業界関係者は、この IPO を単なる資本市場イベントではなく、計算資源の希少性と推論需要の高まりを背景としたインフラサイクルの重要な転換点と捉えている。
長期的な対抗馬としての地位確立
当初は懐疑的だった投資家も、Cerebras の持続的な実行力と「優れたチップ」の構築により、同社が最終的に正しかったことを認めるようになった。
推論・サービングへの戦略的転換
Cerebras は単なる学習用アクセラレーターではなく、トリリオンパラメータ規模のモデルを低遅延で処理する「推論(inference)およびサービング」プラットフォームとして市場に位置づけられています。
主要顧客と具体的なワークロード
同社は現在、OpenAI の内部モデル(5.4 および 5.5 版など)を含む大規模なフロントティア・ワークロードを処理しており、計算資源の希少性と推論需要の高まりに対応しています。
非 NVIDIA アーキテクチャの評価転換
以前は「実現不可能」と見なされていた独自のアプローチが、市場が学習から推論経済へとシフトする中で、「市場が必要とする差別化されたサービングスタック」として再評価されつつあります。
影響分析・編集コメントを表示
影響分析
この記事は、AI ハードウェア市場において推論(Inference)が新たな成長の中心となりつつあり、特に大規模モデルの処理能力を持つ企業が資本市場で高く評価される時代に入ったことを示しています。Cerebras の成功は、NVIDIA 以外の選択肢が確立され、OpenAI とのような大手テック企業との緊密な連携が競争優位性の鍵となることを意味しており、今後のインフラ投資の方向性を決定づける重要なシグナルです。
編集コメント
Cerebras の IPO は、AI ハードウェア業界が「推論」フェーズへと移行し、大規模モデルを効率的に処理できる企業が資本市場で評価される新たな基準を示しています。特に OpenAI との提携内容から、技術的実力が即座にビジネス価値として認識されている現状が浮き彫りになりました。
通常は技術的な話題に焦点を当てていますが、稀に大規模な資金調達はそれ自体が注目すべき出来事であり、今週の Cerebras の IPO(S-1 を一度撤回し、750MW という素晴らしいパートナーシップと OpenAI に対して 100億〜200億ドルの株式/取引を締結した後)は、NVIDIA が Groq を 200億ドルで買収したという衝撃的な人事からわずか 6 ヶ月後にインフランス・インフレクション(推論の転換点)を支える成長するテーマとして確かに位置づけられます。
本日は終値が 280 ドル、時価総額 600億ドルで終了し、これはビッグチップ(Big Chip)とその信奉者たちに対する驚くべき検証となりました。
Amir Efrati によるこの画像は、Cerebras の 10 年を要約しています:
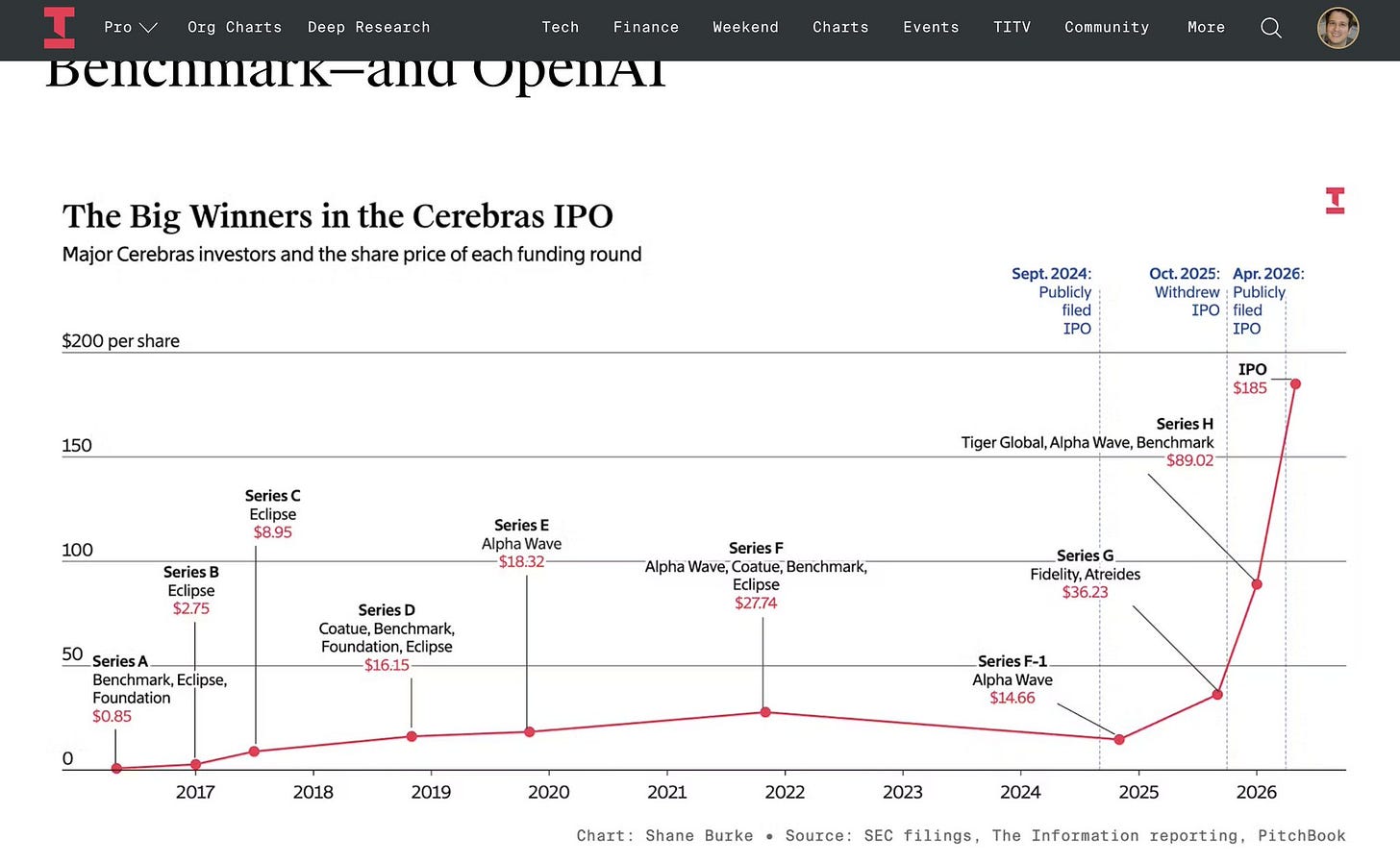
Cerebras の財務諸表はすでに完全に公開されていますが、議論の焦点は供給能力にあります。
詳細は後述しますが、Cerebras のヘッド・リサーチ・サイエンティスト(Head Research Scientist)は、本日午後 AIE Singapore でライブストリームにて講演します。
2026 年 5 月 14 日〜15 日の AI ニュース。私たちは 12 のサブレッド、544 の Twitter投稿を確認し、Discord では新たな情報は見つかりませんでした。AINews のウェブサイトでは過去のすべての号を検索できます。念のためにお知らせしますが、AINews は現在 Latent Space の一部となっています。メールの配信頻度を選択・解除することができます!
ヘッドラインストーリー:Cerebras IPO の振り返り、技術詳細、そして企業の歩み
Cerebras が IPO ストーリーとしてタイムラインに再び登場し、投資家や関連するインフラ関係者が同社を、ついに正当化されたように見える長期的な逆張りハードウェアの賭けとして捉えています。最も直接的に関連するツイートは、投資家の Ishan N. Taneja によるもので、彼は「初期の Cerebras の主張には信じていなかった」と述べた上で、「懐疑派だった自分が完全に正しかった」と結論付け、Cerebras の粘り強さ、実行力、そして「素晴らしいチップを構築した」ことを称賛しました。また、これが Hanabi の最初の IPO である @ishanit5 とも指摘しています。
2 つ目の Cerebras に特化したデータポイントは、CNBC の Deirdre Bosa が引用したもので、Cerebras の CFO Bob Komin が「小規模モデルのみ」というナラティブ(物語・見解)に反論している内容です。Komin は、Cerebras はあらゆるサイズのモデルに対応しており、対応可能なモデルサイズには「制限がない」と述べました。さらに、現在 Cerebras はトリリオンパラメータのモデルも扱っており、その中には内部の OpenAI モデルも含まれると具体名を挙げて「OpenAI 5.4 および 5.5」@dee_bosa と言及しています。
近くにある Apoorv Vyas の文脈を示すツイートでは、「Cerebras の IPO」が計算資源の希少性、推論需要、ルーティング、オープンソースに関するスタンフォード大学の議論と明示的に結びつけられており、この IPO が一般的な資本市場イベントとしてではなく、推論インフラサイクルの一部として解釈されていることを示唆しています @apoorv03。
事実 vs 意見
ツイートに直接記載された事実
Cerebras は IPO の文脈で議論されています @ishanit5, @apoorv03。
Cerebras の CFO Bob Komin は次のように述べています:
Cerebras はあらゆるサイズのモデルに対応する。
対応可能なモデルサイズには「制限がない」。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等)は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
Cerebras はトリリオンパラメータモデルの提供を行っています。
同社は内部の OpenAI モデル、具体的には OpenAI 5.4 および 5.5 を提供しています @dee_bosa。
意見・解釈
「Cerebras は正しい理由で物議を醸す行動をとった」「チームは素晴らしい」「彼らは傑出したチップを開発した」といった投資家の評価は、独立して検証された事実ではなく、投資家による見解です @ishanit5。
IPO が Cerebras の長期戦略に対する妥当性の証明であるという示唆は、これらのツイートにおける公式な主張ではなく、投資家のトーンや周辺インフラに関する議論から生じた解釈です。
CFO によるモデルサイズに「上限はない」という発言は、事実を枠組み化する側面とマーケティング用語の側面の両方を含んでおり、エンジニアはこれを「同社は提供アーキテクチャが現在の最先端ワークロードに対してスケーラブルであると信じている」と解釈すべきであり、計算リソースが文字通り無制限であるという意味で受け取るべきではありません。
議論中に明らかになった技術詳細と数値
ツイート群には歴史的な仕様に関する記述は少ないものの、Cerebras の技術的ポジショニングに関連するいくつかの注目すべき運用上の主張が含まれています:
トリリオンパラメータモデルの提供:Cerebras の CFO は、同社が現在トリリオンパラメータモデルを提供していると述べています @dee_bosa。
顧客名・ワークロード:Komin 氏は、これらには内部の OpenAI 5.4 および 5.5 が含まれると具体的に言及しています @dee_bosa。
戦略的楔(くさび):枠組みは明らかにトレーニングだけでなく、推論/提供に焦点を当てています。Apoorv は IPO の議論を「計算資源の不足」「推論需要の高まり」「モデルルーティング」と結びつけています @apoorv03。
これらのツイートは、Cerebras が市場において広く知られているポジショニングと一致しています。すなわち、ウェーハスケールのハードウェア、極端に高いオンチップメモリ帯域幅、そして低遅延で大規模モデルをサービス提供する際に生じるボトルネックを削減するために最適化されたシステムアーキテクチャです。これらの具体的なチップ仕様はツイートセットに含まれていませんが、CFO の「トリリオンパラメータ」という発言は技術的に意味深であり、同社が中規模のオープンモデル向けのニッチなアクセラレーターではなく、フロンティアスケールのモデルに対する本格的なサービスプラットフォームとして認識されたいと考えていることを示唆しているからです。
Cerebras の歩み:なぜこの IPO が共感を呼んだのか
Cerebras は長年、「野心的だが論争の的となる」カテゴリに属する AI ハードウェア企業でした。投資家のコメントは、その核心的な物語の弧をよく捉えています。同社は多くの人が非現実的または商業的に疑わしいと見なした道を選びましたが、それを粘り強く実行し、複数の計算サイクルを通じて生き残るだけの成果を上げました @ishanit5。
この称賛の裏にある含意は、ハードウェアエンジニアにとって重要です。
Cerebras は長年、NVIDIA 以外のアーキテクチャ的仮説(thesis)を象徴してきました。
その戦略は、従来のアクセラレータ経済学で競うのではなく、異なる物理的およびシステム設計哲学を用いてスケーリング問題に挑むことにあります。
そのため、市場が特定のワークロードで勝利しない限り独自アーキテクチャを割安とみなす傾向があるため、本質的に論争の的となりました。
IPO の振り返りに関する議論は、企業のストーリーが「このアーキテクチャは生き残れるのか?」から「市場が今必要としているのはまさにこのような差別化された推論サービススタックか?」へとシフトしたことを示唆しています。
このシフトは、AI インフラ市場自体も変化しているためです:
純粋なトレーニングの威信から、推論の経済性へ。
ベンチマークのスナップショットから、本番環境で巨大モデルをサービス提供することへ。
GPU の豊富さという前提から、計算資源の希少性とルーティングの規律へと。@apoorv03
そのような環境において、トリリオンパラメータ規模の内部フロンティアモデルを信頼性を持ってサービス提供できると主張できる企業は、数年前とは全く異なる反応を得ることになります @dee_bosa。
異なる視点
支持・楽観的見方
最も楽観的な見方は投資家のイシャーン・N・タネジャによるものです。懐疑心から敬意へと変わり、持続性、実行力、そして成功した逆張りチップへの賭けが強調されています @ishanit5。
ボブ・コミンの引用も戦略的に楽観的です。これは Cerebras を単なる脇役ではなく、フロンティア規模の推論のためのプラットフォームとして再定義するものです @dee_bosa。
アポールのコメントは、Cerebras を計算資源の希少性と上昇する推論需要という生きたシステムの問いの中心に位置づけます。ここでこそ、差別化されたサービスアーキテクチャが最も重要となる可能性があります @apoorv03。
中立的・分析的見方
中立的な読み解きでは、Cerebras の IPO は公的市場における出来事としてよりも、投資家がフロンティアスタックにおいて GPU デフォルト以外のインフラ企業にも余地があると信じているというシグナルとして重要であると考えられます。
もう一つの中立的な教訓:Cerebras に真の技術的差別化が存在したとしても、重要な問いは「チップがエレガントか」ではなく、「既存のエコシステムを中心に再編される市場において、稼働率、ソフトウェア互換性、そして商業的な採用を維持できるか」という点です。
懐疑的・暗黙の反論
提供されたセット内のツイートに Cerebras の IPO を直接攻撃するものはありません。しかし、専門家層が依然として慎重であるべきには、以下のような暗黙の理由があります:
「モデルサイズに制限なし」という主張は経営陣の常套句であり、実際にはメモリ階層、バッチ処理とレイテンシのトレードオフ、相互接続の挙動、ソフトウェアの使いやすさ、そしてワークロードの混合比において制限が生じます。
内部の OpenAI 向けワークロードへの対応は強力な主張ですが、トラフィックシェア、レイテンシティア、コスト/トークン、稼働率、あるいは正確なデプロイメント役割に関する詳細がなければ、これが広範な戦略的依存を反映しているのか、それとも限定的なターゲット利用に過ぎないのかを知ることは困難です。
AI ハードウェアの歴史には、技術的に印象的なアーキテクチャでありながら、ソフトウェア、開発者の採用、あるいはエコシステムの重力によって純粋なハードウェアの優位性が上回られ、商業的に失敗した事例が数多くあります。
なぜ今これが重要なのか
Cerebras の IPO に関する物語は、AI インフラストラクチャがいくつかの明確な真実を基に再評価されているタイミングで展開されています。これらの真実は、提供されたツイートセットの他の部分でも目に見えるものです:
推論(Inference)が主要な計算市場へと成長しています。Pearl、Together、および他社も、推論経済とトークンコストについて明確に言及しており、@prlnet や @simran_s_arora などがその議論を主導しています。
巨大モデルの提供はもはや実験室での自慢話ではなく、製品としての必須要件となっています。複数のツイートでは、トリリオン規模のモデルや大規模モデルの更新サイクル、そして @scaling01 や @kimmonismus による急速な RL(強化学習)/ポストトレーニング駆動型の改善について議論されています。
資本集約度に対する scrutiny が行われています。Kimmonismus は、ハイパースケイラーの設備投資が 6000 億ドルを超え、AI インフラへの支出と AI 収益との間に大きな格差があることを指摘し、市場がインフラ経済性を注視している警告を発しています @kimmonismus。
そのような文脈において、Cerebras が重要となるのは—そして唯一—、非標準的なアーキテクチャが、エコシステム移行コストを正当化できるほど先端的な推論の経済性やレイテンシプロファイルを改善できると確固たる根拠を示せる場合に限られます。
より広い文脈:公式主張と独立した検証
公式には、このツイート群における最も強力な主張は CFO の Bob Komin によるものです。Cerebras はすでにトリリオンパラメータの OpenAI 内部モデルを提供しているとのことです @dee_bosa。
しかし、このツイート群から欠けているのは、ベンチマーク形式の独立した検証です:
- トークンあたりのコスト比較がない
- レイテンシのパーセンタイルデータがない
- スループット数値がない
- コンテキスト長の具体的な数値がない
- ソフトウェア互換性の詳細がない
- 利用率の数値がない
したがって、適切な技術的な姿勢は以下の通りです:
- OpenAI を提供しているという主張を、注目すべきかつ信頼性のあるものとして捉えること;
- しかし、広範な優位性を完全に証明したものと過剰に解釈しないこと。
つまり、IPO の振り返りは「Cerebras が勝利した」というよりも、「Cerebras は市場が自社の仮説により有利になるまで生き残るのに十分な時間を持てた」という方が適切です。
AI Twitter Recap
Codex、GitHub Copilot アプリ、そして新たなコーディング・エージェントの表面領域
OpenAI の Codex モバイル/アプリ展開が製品に関する話題を支配しました。ユーザーたちはバーからウェブサイトを構築したり、iPhone から Mac を制御したり、常時稼働する Mac mini がバックグラウンドでセッションを実行している間、ラップトップを「衛星デバイス」として扱うといったことを報告しています @flavioAd, @nickbaumann_, @PaulSolt, @rileybrown。
Codex は急速にマルチ・サーフェス型エージェントプラットフォームへと進化しています:今回のサイクルにおけるツイートは、コーディング・エージェントが実行される場所と方法の有意義な拡大を示唆しています。Codex Mobile のウォークスルーを通じたモバイルファーストワークフロー、@npew による iPad/VPS セッション管理、@itsclivetime による Telegram/ホームサーバー遠隔セットアップ、そして @kimmonismus からのマシンがロックされている間の Mac 制御における「使用制限」の兆候などです。OpenAI の開発チームはまた、@etnshow を通じて採用数値を共有しました:週次アクティブユーザー数が 400 万人以上、ユーザーあたりのメッセージ数が 5 倍増加し、初週のアプリダウンロード数が 100 万件を超えています。
周辺エコシステムも、アプリ層での競合のみではなく、Codex に接続する動きを急速に進めています:Ollama はローカル/オープンモデルの起動パスとクラウドモデルの推奨機能を含む Codex アプリサポートを追加しました。Zed はエージェント内で ChatGPT サブスクリプションアクセスをサポートし、Codex と同じサブスクリプション/レート制限モデルを維持しています。また、MagicPath を Codex 内のネイティブキャンバスとして提供するものや、@secemp9 によって MCP/スラッシュコマンド形式に抽出されたポータブルな /goal コマンドなど、サードパーティ製拡張機能も登場しています。ロンドン、ポルトガル、パリでのミートアップ報告から、コミュニティの勢いが確認できました。
GitHub は、モデルだけでなくコード実行基盤(コーディング・ハーネス)にも並行して賭けを打っています。@code と @pierceboggan によって共有された社内ポストにおいて、VS Code/Copilot チームは、ユーザー体験がベースモデル単体よりも、コード実行基盤—文脈の組み立て、ツールの利用、実行ループ、メモリ—によってより強く形成されると強調しました。今週注目された製品機能には、@davidfowl によるエージェント統合と、@code によるコマンドに対する AI 解説付きのターミナルリスク評価バッジが含まれます。より広範なトレンドは明確です:競争の最前線が「最良のモデル」から「最良の基盤+UX+統合」へとシフトしていることです。
エージェント・ハーネス、検索、評価、および信頼性エンジニアリング
コーディング・エージェントに関する検索は、埋め込みベクトルではなくプリミティブを中心に再考されています。ここでの最も強力な主張は、「ベクトルデータベース上での grep/テキスト検索」です。@omarsar0 は、適切なエージェント・ハーネスに包まれた grep 形式のテキスト検索が、コーディング・エージェントタスクにおいて埋め込みベースの検索と同等かそれ以上の性能を発揮できることを示す論文を紹介しました。@dair_ai もこの結論を支持しています。関連して、@lintool は「エージェント型検索のための 2 パラメータモデル」は BM25 であり、もしかするとゼロパラメータ版は grep だと冗談めかして述べています。これは Cloudflare に隣接する実験とも一致します:@YoniBraslaver は monday.com の GraphQL API において SDK と MCP を比較し、SDK では 1 ステップ/15,000 トークンであるのに対し、本格的な MCP サーバーでは 4 ステップ/158,000 トークンが必要であることを発見しました。これは同じ出力に対して 8.4 倍のトークンコストがかかることを意味します。
エージェントの評価と観測可能性は、もはや主要なインフラ課題となっています。複数の投稿で共通のテーマが指摘されており、自律システムに対する評価は、エージェントがより長期的な視野を持ち、利用可能なツールが増えるにつれて、むしろ難しくなっているという点です。@palashshah は、現代の評価設計における難しさを指摘しました。一方、@cwolferesearch は、Terminal-Bench、Tau-Bench、GAIA、WorkArena、OSWorld、MLE-Bench、PaperBench、GDPval などを含む広範なベンチマークマップをまとめました。
新たなベンチマーク提案として、FutureSim が紹介されました。これは、Codex や Claude Code などのネイティブ環境において、継続的な更新や予測能力を試すために、現実世界の出来事を時間軸に沿って再生するものです。また、@nikhilchandak29 からは、予測においてもテスト時の計算リソースが滑らかにスケールするという追跡コメントがありました。
信頼性に関する懸念は、ハルシネーションからシステムレベルの故障モードへと移行しています:@random_walker は、ブラックボックス型の「ジェニー」インターフェースが推論トレース、ツール使用、メモリ、中間状態をユーザーが見ることができないため検証負担を増大させると主張しました。一方、@mitchellh はより鋭いインフラの比喩を示し、企業は AI 生成ソフトウェアに対して「MTTR がすべてである」という思考様式に drifting(傾斜)しつつあり、局所的な指標は良好に見える一方でグローバルなシステムの理解可能性が衰退する、回復力のある災厄マシンを創り出している可能性があると指摘しました。ツールリングの側では、LangChain は LangSmith Engine、SmithDB、管理された Deep Agents、サンドボックス、ゲートウェイ、コンテキストハブをカバーする Interrupt 発表で反対方向へ進み、@ankush_gola11 はエージェントの観測性(observability)に対する実用的要件として、トレース取り込みにおけるサブ秒単位の中央値書き込み遅延を強調しました。
トレーニング、最適化、推論効率
最適化器の研究は再び Adam ファミリーを超えて広がっています:@zacharynado は時流を簡潔に要約し、「sloptimizer(スロプタイザー)」分野は、Adam 派生型の墓場を経て、Shampoo や Muon-gen スタイルの手法でようやく始まったばかりだと述べました。2 つの具体的な更新が発表されました:1 つ目は SODA で、これは追加ハイパーパラメータを持たず、重み減衰(weight-decay)の調整を不要とし、ベース最適化器を改善するラッパーです。注目すべき点は、Muon がチューニングされた重み減衰スweep を実行した場合でも、SODA[Muon] が Muon よりも優位であると主張していることです。2 つ目は、返信や参照から見える Muon/Shampoo に対する一般的な継続的な関心です。
高速/低速学習および教育的監督は、今期の注目すべきトレーニングアイデアでした:@agarwl_氏は「Learning, Fast and Slow(速くそして遅く)」を説明し、重みにおける低速学習を強化学習 (RL) で組み合わせつつ、文脈やプロンプトにおける高速学習("fast weights")を GEPA を用いて最適化することで、強化学習単独よりも優れたデータ効率性、適応性、および忘却の減少を実現すると主張しました。監督側では、Pedagogical RL と Late Interaction の説明者が、正解出力からの学習だけでなく、正しく教示可能なロールアウト分布からの学習を提唱しており、@bradenjhancock 氏は生徒が追従できない飛躍を行う教師モデルに対してペナルティを与える関連研究を要約しました。
推論最適化はシステムレベルとモデルレベルの両方で依然として非常に活発です:@ariG23498 氏は連続バッチ処理 (continuous batching) について深く掘り下げるよう推奨し、動的なバッチ処理体制においてアイドル状態の GPU を回避するために、CUDA ストリーム、イベント、同期、および CPU/GPU の分離を理解する必要性を特に強調しました。Meta の研究者らは、モデルが永続キャッシュに保持すべきキー/値を学習することで KV キャッシュサイズを削減し、デコード速度を向上させる「Self-Pruned KV attention(自己剪定型 KV アテンション)」を提案しました。ローカル推論の側面では、@danielhanchen 氏は、新しい llama.cpp の予測的デコーディングパラメータのおかげで、Qwen の小規模モデル MTP GGUF が前日の 1.4 倍から 1.8 倍に高速化されたと報告しました。
オープンモデル、サービングスタック、およびエージェントツールチェーン
オープン/ローカルエージェントスタックは、Hermes、Ollama、およびポータブルランタイムを中心に緊密化しています。ClawRouter による Hermes Agent の統合、Teknium がトークン量で OpenClaw を上回ったとの主張、そして SuperGrok サブスクリプションを介した Hermes Agent における Grok サポートはすべて、相互運用可能なエージェントシェルを中心とした継続的な集約を示唆しています。NVIDIA は、Ollama を経由して DGX Spark 上で Hermes Agent をローカルで実行するための実用的なデプロイパスを発表しました。@onusoz もまた、主要なユーザビリティのギャップを指摘しました。需要が高まっているにもかかわらず、エンドユーザー向けのワンクリックモデルローカルデプロイは依然として存在しないということです。
オープンなマルチモーダルおよび科学モデルを取り巻くサービングインフラストラクチャは成熟し続けています。vLLM は、Baseten が vLLM-Omni の本番環境でのデプロイを強調しました。これは、従来はクローズド API によって支配されることが多かった多段階オーディオ、ストリーミングマルチモーダル、リアルタイム TTS(Text-to-Speech:テキスト読み上げ)ワークロード向けです。また、Intern-S2-Preview の day-0 サポートも提供されました。これは、物質結晶構造生成の初期能力を備えたオープンソースの科学マルチモーダル基盤モデルとして説明されています。追加的なツールリングの更新には、kernels プロジェクトにおけるアジェンティックカーネル開発への Hugging Face による呼びかけと、OpenAPI スペックを Cloudflare サービスバインディングに変換する Capa が含まれます。Capa は Stripe、GitHub、Slack、Twilio、Kubernetes などのプラットフォームで 5,852 の生成済みメソッドを提供します。
ドキュメント/検索インフラにおいても具体的な製品開発が進みました:Weaviate v1.37 では、プロパティごとのアクセント折りたたみ機能、プロパティごとのストップワードプリセット、および BM25 トークン化のデバッグ用の /v1/tokenize エンドポイントが追加されました。Cohere は、視覚解析と検索埋め込みを組み合わせて困難なドキュメントに対する検索を行うためのスタックとして Compass を推進しています。ベンチマーク分野では、ParseBench のリーダーである Infinity-Parser2-Pro (35B) と Flash (2B) が、ドキュメント/要素/チャート解析タスクにわたる 500 万件以上の合成パースサンプルと共同強化学習アルゴリズムにより評価されました。
Anthropic, OpenAI, xAI および競争動態
最も顕著な競争シグナルはベンチマーク圧力だけでなく、開発者向け製品の圧力に関するものでした:@Yuchenj_UW は、xAI の GPU 容量を獲得した後の Anthropic の最近の動きを「Codex のプレイブックを実行している」と表現し、最も目に見えるユーザー facing な変更は、Anthropic がすべての人の 5 時間および週次 Claude レートリミットをリセットしたことでした。これは @kimmonismus によって競争への対応および/または計算資源の利用可能性向上によるものとして強調されました。@kimmonismus からの別の報告では、FT の数値に基づき Anthropic の企業価値が 5 月末までに 9000 億ドル、年間収益(ARR)が 450 億ドルに達するとされており、以前のチェックポイントから大幅に上昇しています。
モデルの認識に関するいくつかのツイートは、ドメイン特化型の専門化とフロンティアギャップの拡大を指摘しています。Epoch AI のドメイン固有の ECI は、Claude が自身の一般能力指数と比較してソフトウェアエンジニアリングにおいて優位性を持つ一方で、数学では劣っていることを示唆しています。同時に、複数の投稿者が Claude/Mythos レベルの能力飛躍に感銘を受けました。@scaling01 は Mythos を「狂気じみている」と呼び、@teortaxesTex は少なくとも一部の用途において Mythos が GPT-5.5 よりも有意に強力であると述べています。xAI 側における次の推測されるステップはさらに大規模なスケールです。@scaling01 はまもなく新しい 1.5T の xAI モデルを期待しています。
OpenAI は「ChatGPT をパーソナルエージェントとして」という仮説を金融分野に拡大しました。ChatGPT は米国向けのプロユーザーに対して、安全な金融口座接続、支出分析、およびユーザーの許可されたデータに基づく根拠のある Q&A を備えた個人向け金融体験を発表しました。@fidjissimo はこれを健康記録との統合と同じパターンに関連付けました。つまり、構造化された個人的な文脈がエージェントに流れ込むというパターンです。@kimmonismus はこれによりフィンテックアシスタント層の一部が圧縮される可能性があると主張し、GPT-5.5 Thinking が複雑な個人向け金融タスクで 79/100、GPT-5.5 Pro が 82.5/100 を記録した内部の金融ベンチマークを引用しました。
エンゲージメント上位のツイート(エンゲージメント順)
Codex/エージェントの採用:ChatGPT の個人向け金融プレビューが、直接 AI に起因する最も高いエンゲージメントを獲得しました
原文を表示
We normally focus on technical stories, but occasional large fundraisings are noteworthy in themselves, and the Cerebras IPO (after one pulled S-1 and a fantastic 750MW partnership and $10-$20B stake/deal with OpenAI) this week, certainly qualifies as a growing theme supporting the Inference Inflection, just 6 months after the shock execuhire of Groq by NVIDIA for $20B. ended today at $280, a market cap of $60 billion, which is tremendous validation for Big Chip and their believers.
This image from Amir Efrati summarizes the Decade of Cerebras:
Cerebras’ financials are now fully public, but the focus of discussions center around the supply:
More details below, and the Head Research Scientist of Cerebras speaks at AIE Singapore later today on the livestream:
AI News for 5/14/2026-5/15/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Headline Story: Cerebras IPO recap, technical details, and company journey
Cerebras returned to the timeline as an IPO story, with investors and adjacent infra voices framing the company as a long-running contrarian hardware bet that finally looks vindicated. The most directly relevant tweet is from investor Ishan N. Taneja, who said he “didn’t believe” early Cerebras claims, then concluded the skeptic he doubted “was totally right,” praising Cerebras for persistence, execution, and for having “built a banger chip,” while noting this was Hanabi’s first IPO @ishanit5. A second Cerebras-specific datapoint came from CNBC’s Deirdre Bosa quoting Cerebras CFO Bob Komin pushing back on the “small models only” narrative: Komin said Cerebras serves models of all sizes, that there is “no limit” to the size of models it can serve, and that Cerebras is currently serving trillion-parameter models, including internal OpenAI models, specifically naming “OpenAI 5.4 and 5.5” @dee_bosa. A nearby contextual tweet from Apoorv Vyas explicitly linked “the Cerebras IPO” to a Stanford discussion on compute scarcity, inference demand, routing, and open source, suggesting the IPO was being interpreted not as a generic capital-markets event but as part of the inference infrastructure cycle @apoorv03.
Facts vs. opinions
Facts directly stated in tweets
Cerebras is being discussed in the context of an IPO @ishanit5, @apoorv03.
Cerebras CFO Bob Komin said:
Cerebras serves all model sizes.
There is “no limit” to model size it can serve.
Cerebras is serving trillion-parameter models.
It is serving internal OpenAI models, specifically OpenAI 5.4 and 5.5 @dee_bosa.
Opinions / interpretations
Cerebras “did controversial things for the right reasons,” “the team slaps,” and “they built a banger chip” are investor judgments, not independently verified facts @ishanit5.
The implication that the IPO is a validation of Cerebras’s long-term strategy is an interpretation emerging from the investor tone and surrounding infra discourse, not a formal claim from the company in these tweets.
The CFO’s claim that there is “no limit” to model size is partly factual framing and partly marketing language; engineers should read it as “the company believes its serving architecture scales to current frontier workloads,” not literally unbounded compute.
Technical details and numbers surfaced in the discussion
The tweet corpus is light on historical specs, but it does contain several notable operational claims relevant to Cerebras’s technical positioning:
Trillion-parameter model serving: Cerebras CFO says the company is currently serving trillion-parameter models @dee_bosa.
Named customers/workloads: Komin specifically says these include internal OpenAI 5.4 and 5.5 @dee_bosa.
Strategic wedge: The framing is clearly inference/serving, not just training. Apoorv ties the IPO discussion to “compute scarcity,” “rising inference demand,” and “model routing” @apoorv03.
Those tweets align with Cerebras’s broader known positioning in the market: wafer-scale hardware, extreme on-chip memory bandwidth, and system architectures optimized to reduce the bottlenecks that appear when serving large models with low latency. Even though those specific chip specs are not in the tweet set, the CFO’s “trillion-parameter” comment is technically meaningful because it implies the company wants to be understood as a serious serving platform for frontier-scale models, not a niche accelerator for mid-sized open models.
Cerebras’s journey: why this IPO resonated
Cerebras has spent years in the “ambitious but contentious” bucket in AI hardware. The investor comment captures the core narrative arc well: the company took a path that many found implausible or commercially dubious, but did so with persistence and enough execution to stay alive through multiple compute cycles @ishanit5.
The subtext of that praise is important for hardware engineers:
Cerebras has long represented a non-NVIDIA architectural thesis.
Its strategy has been to attack the scaling problem with a different physical and system design philosophy, rather than merely competing on conventional accelerator economics.
That made it inherently controversial, because the market often discounts bespoke architectures unless they win a very specific workload.
The IPO recap chatter suggests the company’s story has shifted from “can this architecture survive?” to “is this exactly the kind of differentiated serving stack the market now needs?”
That shift is happening because the AI infra market has also shifted:
From pure training prestige toward inference economics.
From benchmark snapshots toward serving giant models in production.
From GPU abundance assumptions toward compute scarcity and routing discipline @apoorv03.
In that environment, a company that can credibly say it serves trillion-parameter internal frontier models gets a very different hearing than it would have a few years ago @dee_bosa.
Different perspectives
Supportive / bullish
The most bullish take is from investor Ishan N. Taneja: skepticism gave way to admiration, with emphasis on persistence, execution, and a successful contrarian chip bet @ishanit5.
Bob Komin’s quote is also strategically bullish: it reframes Cerebras as a platform for frontier-scale inference, not a side player @dee_bosa.
Apoorv’s comment places Cerebras in the center of a live systems question—compute scarcity amid rising inference demand—which is where a differentiated serving architecture could matter most @apoorv03.
Neutral / analytical
A neutral read is that Cerebras’s IPO matters less as a public-markets event than as a signal that investors believe there is room for non-GPU-default infra companies in the frontier stack.
Another neutral takeaway: even if Cerebras has genuine technical differentiation, the important question is not “is the chip elegant?” but “can it sustain utilization, software compatibility, and commercial adoption in a market increasingly organized around incumbent ecosystems?”
Skeptical / implicit counterpoints
No tweet in the supplied set directly attacks the Cerebras IPO. But there are implicit reasons an expert audience would remain cautious:
“No limit to model size” is standard executive rhetoric; in practice, limits show up in memory hierarchy, batch/latency tradeoffs, interconnect behavior, software ergonomics, and workload mix.
Serving internal OpenAI workloads is a strong claim, but without details on share of traffic, latency tier, cost/token, utilization, or exact deployment role, it is hard to know whether this reflects broad strategic reliance or narrower targeted usage.
The history of AI hardware is full of technically impressive architectures that failed commercially because software, developer adoption, or ecosystem gravity overwhelmed raw hardware merit.
Why it matters now
The Cerebras IPO story lands at a moment when AI infra is being repriced around a few hard truths visible elsewhere in the tweet set:
Inference is becoming the dominant compute market. Pearl, Together, and others are explicitly talking about inference economics and token costs @prlnet, @simran_s_arora.
Serving giant models is now a product requirement, not just a lab flex. Multiple tweets discuss trillion-scale models, large-model cadence, and rapid RL/post-training-driven improvements @scaling01, @kimmonismus.
Capital intensity is under scrutiny. Kimmonismus notes hyperscaler capex crossing $600B and a large gap between AI infra spending and AI revenue, warning that the market is watching infra economics closely @kimmonismus.
In that context, Cerebras matters if—and only if—it can make a durable case that a nonstandard architecture can improve the economics or latency profile of frontier inference enough to justify ecosystem switching costs.
Broader context: official claims vs independent validation
Officially, the strongest claim in the tweet set is from CFO Bob Komin: Cerebras already serves trillion-parameter OpenAI internal models @dee_bosa.
What is missing from the tweet set is independent benchmark-style validation:
no cost-per-token comparison,
no latency percentile data,
no throughput numbers,
no context-length specifics,
no software compatibility details,
no utilization figures.
So the right technical posture is:
treat the OpenAI-serving claim as important and credible enough to watch;
do not overread it as full proof of broad superiority.
The IPO recap, then, is less “Cerebras won” and more “Cerebras stayed alive long enough for the market to become more favorable to its thesis.”
AI Twitter Recap
Codex, GitHub Copilot App, and the New Coding-Agent Surface Area
OpenAI’s Codex mobile/app rollout dominated product chatter. Users described building websites from a bar, controlling Macs from iPhone, and treating laptops as “satellite devices” while an always-on Mac mini runs sessions in the background @flavioAd, @nickbaumann_, @PaulSolt, @rileybrown.
Codex is rapidly becoming a multi-surface agent platform: tweets this cycle point to a meaningful broadening of where and how coding agents run: mobile-first workflows via Codex Mobile walkthroughs, iPad/VPS session management from @npew, Telegram/home-server remote setups from @itsclivetime, and hints of “locked use” for Mac control while the machine is locked from @kimmonismus. OpenAI’s dev team also shared adoption figures via @etnshow: 4M+ weekly active users, 5x more messages per user, and 1M+ app downloads in the first week.
The surrounding ecosystem is moving quickly to plug into Codex rather than compete only at the app layer: Ollama added Codex app support with local/open-model launch paths and cloud model recommendations; Zed now supports ChatGPT subscription access in its agent, preserving the same subscription/rate-limit model as Codex; and third-party extensions are appearing, including MagicPath as a native canvas inside Codex and a portable /goal command extracted into MCP/slash-command form by @secemp9. Community momentum was visible in meetup reports from London, Portugal, and Paris planning.
GitHub is making a parallel bet on the coding harness, not just the model: the VS Code/Copilot team emphasized that the user experience is shaped by the coding harness—context assembly, tool use, execution loops, memory—more than by the base model alone in their behind-the-scenes post shared by @code and @pierceboggan. Product features highlighted this week include agent merge from @davidfowl, and terminal risk assessment badges with AI explanations for commands from @code. The broader trend is clear: the competitive frontier is shifting from “best model” toward best harness + UX + integrations.
Agent Harnesses, Search, Evaluation, and Reliability Engineering
Search for coding agents is being rethought around primitives, not embeddings: the strongest thread here is the “grep/search over vector DBs” argument. @omarsar0 highlighted a paper showing grep-style text search, wrapped in the right agent harness, can match or beat embedding-based retrieval on coding-agent tasks; @dair_ai echoed the takeaway. Relatedly, @lintool joked that the “two-parameter model” for agentic search is BM25, and maybe the zero-parameter version is grep. This aligns with Cloudflare-adjacent experimentation too: @YoniBraslaver compared SDK vs MCP on monday.com’s GraphQL API, finding 1 step / 15k tokens for SDK versus 4 steps / 158k tokens for a real MCP server—8.4x token cost for the same output.
Agent evals and observability are becoming first-class infra problems: several posts converged on the same theme that evals for autonomous systems are harder, not easier, as agents get longer-horizon and more tool-rich. @palashshah called out the difficulty of modern eval design; @cwolferesearch compiled a broad benchmark map spanning Terminal-Bench, Tau-Bench, GAIA, WorkArena, OSWorld, MLE-Bench, PaperBench, GDPval, and others. New benchmark proposals included FutureSim, which replays real-world events temporally to test continual updating and forecasting in native harnesses like Codex/Claude Code, and follow-up commentary from @nikhilchandak29 arguing that test-time compute scales gracefully in forecasting too.
Reliability concerns are shifting from hallucinations to system-level failure modes: @random_walker argued that black-box “genie” interfaces increase the verification burden because users can’t see reasoning traces, tool use, memory, or intermediate state. @mitchellh made the sharper infra analogy: companies may be drifting into an “MTTR is all you need” mindset for AI-generated software, creating resilient catastrophe machines where local metrics look fine while global system comprehensibility decays. On the tooling side, LangChain pushed the other direction with Interrupt announcements covering LangSmith Engine, SmithDB, managed Deep Agents, sandboxes, gateway, and context hub, while @ankush_gola11 emphasized sub-second median write latency for trace ingestion as a practical requirement for agent observability.
Training, Optimization, and Inference Efficiency
Optimizer work is broadening beyond the Adam family again: @zacharynado summarized the zeitgeist succinctly: the “sloptimizer” field is just getting started with Shampoo and Muon-gen style methods after the graveyard of Adam variants. Two concrete updates landed: SODA, a wrapper that adds no hyperparameters, removes weight-decay tuning, and improves a base optimizer, with the notable claim that SODA[Muon] beats Muon even when Muon gets a tuned weight-decay sweep; and general continued interest in Muon/Shampoo from replies and references.
Fast/slow learning and pedagogical supervision were notable training ideas this cycle: @agarwl_ described “Learning, Fast and Slow”, combining slow learning in weights via RL with fast learning in context/prompt (“fast weights”) optimized with GEPA, claiming better data efficiency, adaptability, and less forgetting than RL alone. On the supervision side, Pedagogical RL and Late Interaction’s explainer argue for learning not merely from correct outputs but from correct, teachable rollout distributions, while @bradenjhancock summarized related work on teacher models that are penalized for taking leaps students can’t follow.
Inference optimization remains highly active at both systems and model levels: @ariG23498 recommended a deep dive on continuous batching, specifically the need to understand CUDA streams, events, synchronization, and CPU/GPU decoupling to avoid idle GPUs in dynamic batching regimes. Meta researchers proposed Self-Pruned KV attention, where the model learns which keys/values to keep in persistent cache to reduce KV cache size and improve decoding speed. On the local inference side, @danielhanchen reported that Qwen small-model MTP GGUFs now run 1.8x faster, up from 1.4x two days prior, thanks to new llama.cpp speculative-decoding parameters.
Open Models, Serving Stacks, and the Agent Toolchain
Open/local agent stacks are tightening around Hermes, Ollama, and portable runtimes: ClawRouter integrating Hermes Agent, Teknium’s claims of surpassing OpenClaw in token volume, and Grok support in Hermes Agent via SuperGrok subscriptions all point to continued consolidation around interoperable agent shells. NVIDIA published a practical deployment path to run Hermes Agent locally on DGX Spark via Ollama. @onusoz also highlighted a major usability gap: one-click local model deployment for end users still doesn’t really exist, despite increasing demand.
Serving infrastructure around open multimodal and scientific models continues to mature: vLLM highlighted Baseten’s production deployment of vLLM-Omni for multi-stage audio, streaming multimodal, and real-time TTS workloads often dominated by closed APIs. They also shipped day-0 support for Intern-S2-Preview, described as an open-source scientific multimodal foundation model with an early capability in material crystal structure generation. Additional tooling updates included Hugging Face’s call for agentic kernel development in the kernels project, and Capa, which turns OpenAPI specs into Cloudflare service bindings with 5,852 generated methods across platforms like Stripe, GitHub, Slack, Twilio, and Kubernetes.
Document/search infra also saw concrete product work: Weaviate v1.37 added per-property accent folding, per-property stopword presets, and a /v1/tokenize endpoint for debugging BM25 tokenization. Cohere pushed Compass as a stack for retrieval over difficult documents using visual parsing plus search embeddings. On the benchmarking side, ParseBench leaders Infinity-Parser2-Pro (35B) and Flash (2B) were credited with 5M+ synthetic parsing samples and a joint RL algorithm across document/element/chart parsing tasks.
Anthropic, OpenAI, xAI, and Competitive Dynamics
The strongest competitive signal was around developer-product pressure, not just benchmark pressure: @Yuchenj_UW framed Anthropic’s recent moves as “running the Codex playbook” after getting xAI GPU capacity, and the most visible user-facing change was Anthropic resetting everyone’s 5-hour and weekly Claude rate limits, amplified by @kimmonismus as a likely response to competition and/or increased compute availability. Separate reports from @kimmonismus cited FT numbers putting Anthropic valuation at $900B and ARR at $45B by end of May, up sharply from earlier checkpoints.
On model perception, several tweets point to widening domain specialization and frontier gaps: Epoch AI’s domain-specific ECI suggests Claude has a software-engineering advantage relative to its own general capability index, but under-indexes in math. At the same time, multiple posters were impressed by Claude/Mythos-level capability jumps: @scaling01 called Mythos “insane,” while @teortaxesTex said Mythos appears meaningfully stronger than GPT-5.5 in at least some use. The speculative next step on the xAI side is larger scale still: @scaling01 expects a new 1.5T xAI model soon.
OpenAI expanded the “ChatGPT as personal agent” thesis into finance: ChatGPT announced a personal finance experience for Pro users in the U.S., with secure financial-account connections, spending analysis, and grounded Q&A over user-authorized data. @fidjissimo tied it to the same pattern as health-record integrations: more structured personal context flowing into the agent. @kimmonismus argued this could compress parts of the fintech assistant layer, citing internal finance benchmarks where GPT-5.5 Thinking scored 79/100 and GPT-5.5 Pro 82.5/100 on complex personal-finance tasks.
Top tweets (by engagement)
Codex/agent adoption: ChatGPT personal finance preview was the highest-engagement directly AI-r
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み