「TD学習を用いない強化学習」
Berkeley AI Research は、長期課題におけるエラー蓄積という従来の TD 学習の弱点を克服し、分割統治法に基づく新しい RL アルゴリズムの導入を発表した。
キーポイント
TD 学習の限界と代替案
従来の時差学習(TD)は長期課題において誤差が蓄積するスケーラビリティ問題を抱えており、本稿ではこれを「分割統治」アプローチで解決する新しいパラダイムを提案している。
オフポリシー RL の重要性
ロボット工学や医療などデータ収集コストが高い領域において、過去の経験や人間デモを活用できるオフポリシー RL は不可欠であり、そのスケーラブルな手法の確立が待望されていた。
モンテカルロ法との比較
誤差蓄積を緩和するために TD とモンテカルロ(MC)を組み合わせた n-ステップ学習などが試みられているが、根本的な解決には至らず、本手法はこれに代わる新たなアプローチとして位置づけられる。
Divide and Conquer パラダイムの提案
n ステップ TD 学習の欠点を克服し、ベルマン再帰回数を対数的に削減することで、任意の長期タスクへのスケーリングを可能にする新しい価値学習のパラダイムである。
ハイパーパラメータ不要と高分散の回避
この手法は n ステップ TD のようなハイパーパラメータ $n$ の調整を必要とせず、かつ高い分散や最適性の低下に陥るリスクも伴わない。
ゴール条件付き RL における実装可能性
決定論的ダイナミクスを持つゴール条件付き RL において、最短経路の三角不等式を利用した「推移的な」ベルマン更新則を適用することで、この理論を実際のアルゴリズムとして実現可能である。
実用的なサブゴール選択手法
連続環境における最適サブゴール探索の課題に対し、データセット内の状態に限定し、期待値回帰(expectile regression)を用いた「ソフトなargmax」を計算する手法を提案した。
影響分析・編集コメントを表示
影響分析
この研究は、強化学習の根幹である価値関数学習のパラダイムシフトを示しており、特にロボット制御や複雑な意思決定タスクなど、長期にわたる計画が必要な分野での実用化への道を開く可能性があります。TD 学習の根本的な欠陥を解決する試みとして、業界全体のアルゴリズム開発の方向性に大きな影響を与える重要な一歩です。
編集コメント
TD 学習の限界を打破する新たなアプローチは、実世界での AI アクション適用におけるボトルネック解消に寄与する極めて重要な知見です。
この記事では、「分割統治」という「代替的」なパラダイムに基づく強化学習(RL)アルゴリズムを紹介します。従来の手法とは異なり、このアルゴリズムは時間差分(TD)学習(スケーラビリティに課題がある)に基づいておらず、長期的なタスクにもうまくスケールします。
 時間差分(TD)学習の代わりに、分割統治に基づいて強化学習(RL)を行うことができます。
時間差分(TD)学習の代わりに、分割統治に基づいて強化学習(RL)を行うことができます。
問題設定: オフポリシー強化学習
我々の問題設定はオフポリシー強化学習です。これが何を意味するか、簡単に復習しましょう。
強化学習には、オン・ポリシーRLとオフ・ポリシーRLという2つのクラスのアルゴリズムがあります。オン・ポリシーRLとは、現在の方策によって収集された新しいデータのみを使用できることを意味します。言い換えれば、方策を更新するたびに古いデータを捨てなければなりません。PPOやGRPO(および一般的な方策勾配法)などのアルゴリズムがこのカテゴリーに属します。
オフ・ポリシーRLとは、この制限がないことを意味します:古い経験、人間のデモンストレーション、インターネットデータなど、あらゆる種類のデータを使用できます。したがって、オフ・ポリシーRLはオン・ポリシーRLよりも一般的で柔軟です(そしてもちろん、より難しいです!)。Q学習は最もよく知られたオフ・ポリシーRLアルゴリズムです。データ収集が高価な領域(ロボティクス、対話システム、医療など)では、オフ・ポリシーRLを使用せざるを得ないことが多いです。それが、これが非常に重要な問題である理由です。
2025年現在、オン・ポリシーRL(PPO、GRPOおよびその変種など)をスケールアップするためのレシピは、かなり良いものが得られていると思います。しかし、複雑で長期的なタスクにうまくスケールする「スケーラブルな」オフ・ポリシーRLアルゴリズムは、まだ見つかっていません。その理由を簡単に説明させてください。
価値学習における二つのパラダイム: 時間差分(TD)とモンテカルロ(MC)
オフ・ポリシーRLでは、通常、以下のベルマン更新則を用いた時間差分(TD)学習(すなわちQ学習)によって価値関数を訓練します:
問題はこれです:次の価値 $Q(s', a')$ の誤差はブートストラップを通じて現在の価値 $Q(s, a)$ に伝播し、これらの誤差は時間軸全体にわたって蓄積します。これが基本的に、TD学習が長期的なタスクへのスケーリングに苦労する原因です(詳細に興味があれば、この記事を参照してください)。
この問題を緩和するために、人々はTD学習とモンテカルロ(MC)リターンを混合してきました。例えば、$n$ステップTD学習(TD-$n$)を行うことができます:
ここでは、最初の$n$ステップについては(データセットからの)実際のモンテカルロ・リターンを使用し、残りの時間軸についてはブートストラップされた価値を使用します。この方法で、ベルマン再帰の回数を$n$分の1に減らすことができるので、誤差の蓄積が少なくなります。$n = \infty$という極端な場合には、純粋なモンテカルロ価値学習に戻ります。
これは合理的な解決策であり(そしてしばしばうまく機能しますが)、非常に不満足なものです。第一に、誤差蓄積問題を根本的に解決するものではなく、ベルマン再帰の回数を定数倍($n$)で減らすだけです。第二に、$n$が大きくなるにつれて、高い分散と次善性に悩まされます。したがって、$n$を単純に大きな値に設定することはできず、各タスクごとに慎重に調整する必要があります。
この問題を解決する根本的に異なる方法はあるのでしょうか?
「第三の」パラダイム: 分割統治
私の主張は、価値学習における第三のパラダイムである分割統治が、任意に長期的なタスクにスケールするオフ・ポリシーRLの理想的な解決策を提供するかもしれない、ということです。
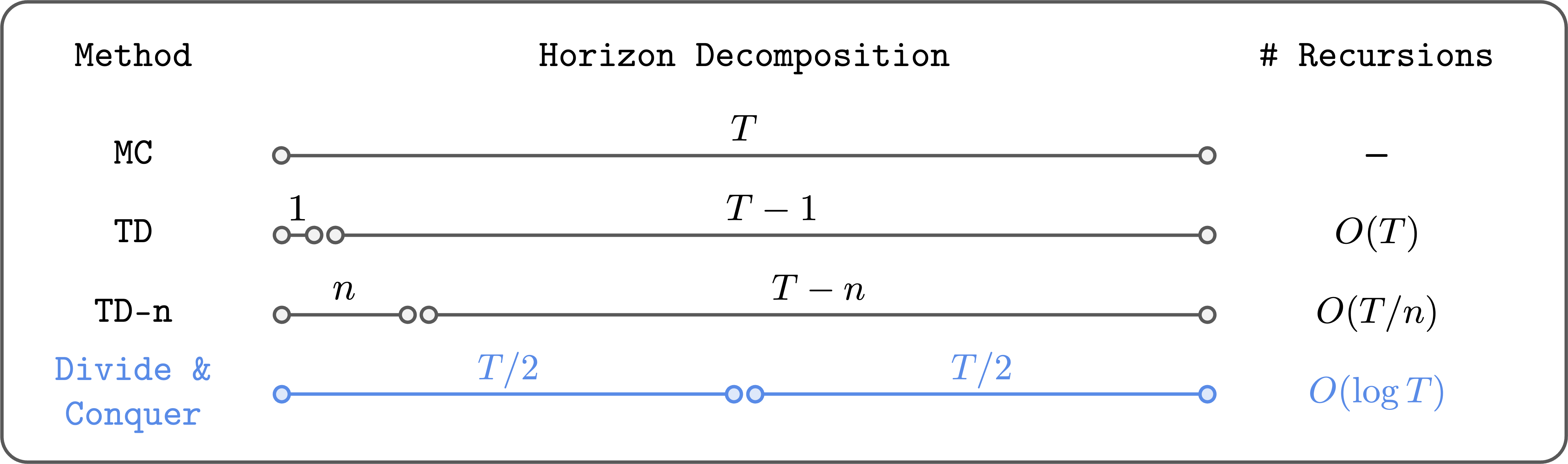 分割統治は、ベルマン再帰の回数を対数的に減らします。
分割統治は、ベルマン再帰の回数を対数的に減らします。
分割統治の重要なアイデアは、軌跡を二つの等しい長さのセグメントに分割し、それらの価値を組み合わせて完全な軌跡の価値を更新するというものです。この方法により、(理論的には)ベルマン再帰の回数を線形的ではなく対数的に減らすことができます。さらに、$n$ステップTD学習とは異なり、$n$のようなハイパーパラメータを選択する必要がなく、必ずしも高い分散や次善性に悩まされるわけではありません。
概念的には、分割統治は価値学習において我々が望むすべての良い特性を本当に備えています。そのため、私はこの高レベルのアイデアに長い間興奮してきました。問題は、実際にこれをどのように実践するかが明確ではなかったことです…最近まで。
実用的なアルゴリズム
Adityaと共同で主導した最近の研究で、我々はこのアイデアを実現しスケールアップする方向で意味のある進歩を遂げました。具体的には、少なくとも強化学習問題の重要な一クラスである、ゴール条件付き強化学習において、分割統治価値学習を非常に複雑なタスクにまでスケールアップすることができました(私の知る限り、これは最初のそのような研究です!)。ゴール条件付き強化学習は、任意の状態から任意の状態に到達できる方策を学習することを目的としています。これは自然な分割統治構造を提供します。これを説明しましょう。
構造は以下の通りです。まず、ダイナミクスが決定的であると仮定し、二つの状態$s$と$g$の間の最短経路距離(「時間的距離」)を$d^*(s, g)$と表記します。すると、これは三角不等式を満たします:
すべての $s, g, w \in \mathcal{S}$ に対して。
価値の観点では、この三角不等式を以下の「推移的」ベルマン更新則と等価に変換できます:
ここで、$\mathcal{E}$ は環境の遷移グラフにおける辺の集合、$V$ はスパース報酬 $r(s, g) = 1(s = g)$ に関連付けられた価値関数です。直感的には、これは、$w$ が最短経路上の最適な「中点」(サブゴール)である場合、二つの「より小さな」価値 $V(s, w)$ と $V(w, g)$ を使用して $V(s, g)$ の価値を更新できることを意味します。これはまさに我々が探していた分割統治価値更新則です!
しかし、ここに一つの問題があります。問題は、実際に最適なサブゴール $w$ をどのように選択するかが不明確だということです。表形式の設定では、単純にすべての状態を列挙して最適な $w$ を見つけることができます(これは本質的にFloyd-Warshall最短経路アルゴリズムです)。しかし、大きな状態空間を持つ連続環境では、これはできません。基本的に、このアイデアが数十年間存在していたにもかかわらず(実際、Kaelbling (1993) によるゴール条件付き強化学習の最初の研究にまで遡ります – 関連研究のさらなる議論については我々の論文を参照)、これが以前の研究が分割統治価値学習をスケールアップすることに苦労してきた理由です。我々の研究の主な貢献は、この問題に対する実用的な解決策です。
我々の重要なアイデアはこれです:$w$ の探索空間を、データセット内に出現する状態、具体的にはデータセットの軌跡において $s$ と $g$ の間にある状態に制限します。また、最適な $\text{argmax}_w$ を探索する代わりに、期待値回帰を使用して「ソフトな」$\text{argmax}$ を計算します。すなわち、以下の損失を最小化します:
ここで、$\bar{V}$ はターゲット価値ネットワーク、$\ell^2_\kappa$ は期待値 $\kappa$ を持つ期待値損失、そして期待値は、ランダムにサンプリングされたデータセット軌跡内のすべての $i \leq k \leq j$ となるタプル $(s_i, s_k, s_j)$ に対して取られます。
これには二つの利点があります。第一に、状態空間全体を探索する必要がありません。第二に、$\max$ 演算子による価値の過大評価を防ぐために、代わりに「よりソフトな」期待値回帰を使用します。我々はこのアルゴリズムを推移的強化学習(TRL)と呼びます。詳細とさらなる議論については、我々の論文をチェックしてください!
うまく機能するのか?
我々の手法が複雑なタスクにうまくスケールするかどうかを確認するために、オフラインゴール条件付き強化学習のベンチマークであるOGBenchの最も挑戦的なタスクのいくつかで、TRLを直接評価しました。主に、大規模な10億規模のデータセットを持つ、humanoidmazeとpuzzleタスクの最も難しいバージョンを使用しました。これらのタスクは非常に困難です:最大3,000環境ステップにわたって組み合わせ的に複雑なスキルを実行する必要があります。
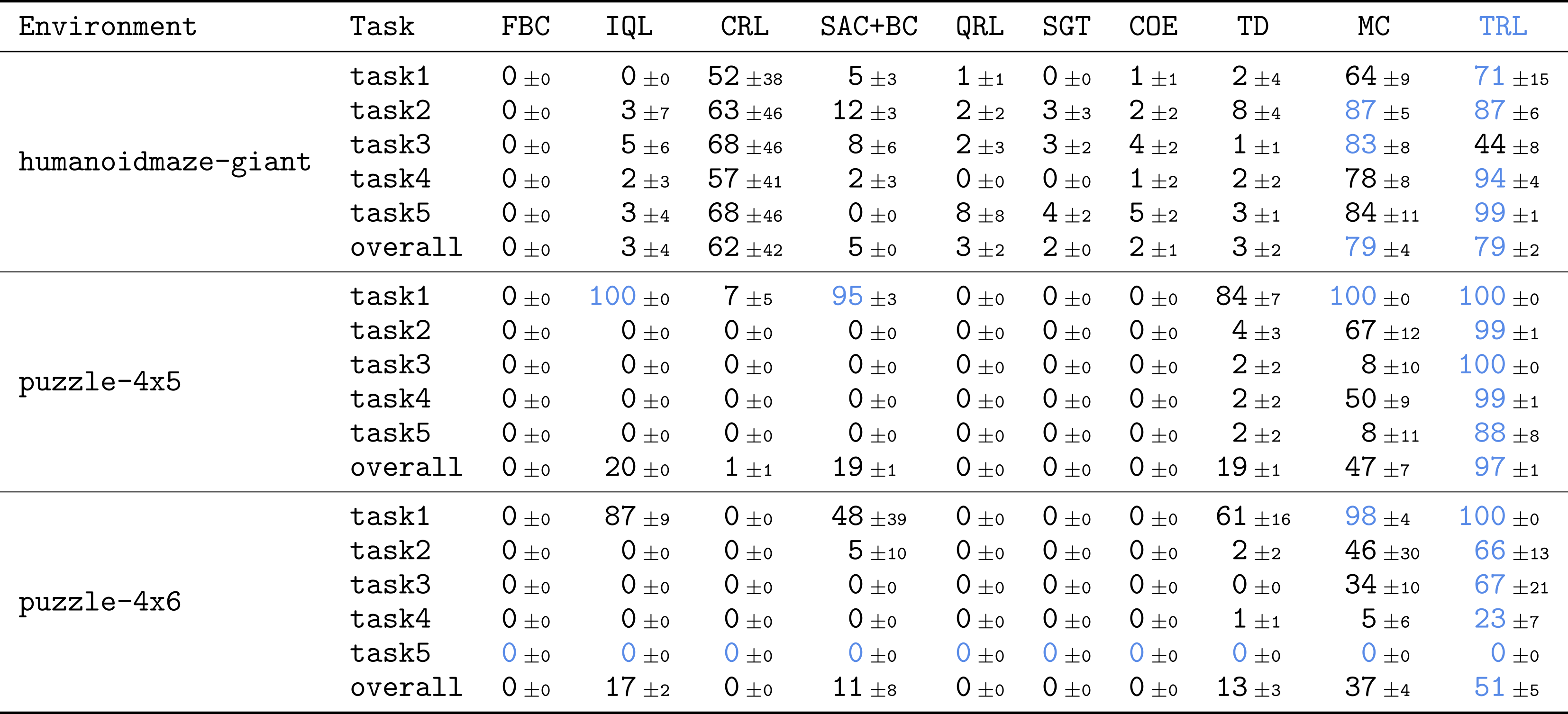 TRLは、非常に困難で長期的なタスクにおいて最高の性能を達成します。
TRLは、非常に困難で長期的なタスクにおいて最高の性能を達成します。
結果は非常に刺激的です!異なるカテゴリー(TD、MC、準距離学習など)の多くの強力なベースラインと比較して、TRLはほとんどのタスクで最高の性能を達成します。

原文を表示
In this post, I’ll introduce a reinforcement learning (RL) algorithm based on an “alternative” paradigm: divide and conquer. Unlike traditional methods, this algorithm is not based on temporal difference (TD) learning (which has scalability challenges), and scales well to long-horizon tasks.
We can do Reinforcement Learning (RL) based on divide and conquer, instead of temporal difference (TD) learning.
Problem setting: off-policy RL
Our problem setting is off-policy RL. Let’s briefly review what this means.
There are two classes of algorithms in RL: on-policy RL and off-policy RL. On-policy RL means we can only use fresh data collected by the current policy. In other words, we have to throw away old data each time we update the policy. Algorithms like PPO and GRPO (and policy gradient methods in general) belong to this category.
Off-policy RL means we don’t have this restriction: we can use any kind of data, including old experience, human demonstrations, Internet data, and so on. So off-policy RL is more general and flexible than on-policy RL (and of course harder!). Q-learning is the most well-known off-policy RL algorithm. In domains where data collection is expensive (e.g., robotics, dialogue systems, healthcare, etc.), we often have no choice but to use off-policy RL. That’s why it’s such an important problem.
As of 2025, I think we have reasonably good recipes for scaling up on-policy RL (e.g., PPO, GRPO, and their variants). However, we still haven’t found a “scalable” off-policy RL algorithm that scales well to complex, long-horizon tasks. Let me briefly explain why.
Two paradigms in value learning: Temporal Difference (TD) and Monte Carlo (MC)
In off-policy RL, we typically train a value function using temporal difference (TD) learning (i.e., Q-learning), with the following Bellman update rule:
The problem is this: the error in the next value $Q(s’, a’)$ propagates to the current value $Q(s, a)$ through bootstrapping, and these errors accumulate over the entire horizon. This is basically what makes TD learning struggle to scale to long-horizon tasks (see this post if you’re interested in more details).
To mitigate this problem, people have mixed TD learning with Monte Carlo (MC) returns. For example, we can do $n$-step TD learning (TD-$n$):
Here, we use the actual Monte Carlo return (from the dataset) for the first $n$ steps, and then use the bootstrapped value for the rest of the horizon. This way, we can reduce the number of Bellman recursions by $n$ times, so errors accumulate less. In the extreme case of $n = \infty$, we recover pure Monte Carlo value learning.
While this is a reasonable solution (and often works well), it is highly unsatisfactory. First, it doesn’t fundamentally solve the error accumulation problem; it only reduces the number of Bellman recursions by a constant factor ($n$). Second, as $n$ grows, we suffer from high variance and suboptimality. So we can’t just set $n$ to a large value, and need to carefully tune it for each task.
Is there a fundamentally different way to solve this problem?
The “Third” Paradigm: Divide and Conquer
My claim is that a third paradigm in value learning, divide and conquer, may provide an ideal solution to off-policy RL that scales to arbitrarily long-horizon tasks.
Divide and conquer reduces the number of Bellman recursions logarithmically.
The key idea of divide and conquer is to divide a trajectory into two equal-length segments, and combine their values to update the value of the full trajectory. This way, we can (in theory) reduce the number of Bellman recursions logarithmically (not linearly!). Moreover, it doesn’t require choosing a hyperparameter like $n$, and it doesn’t necessarily suffer from high variance or suboptimality, unlike $n$-step TD learning.
Conceptually, divide and conquer really has all the nice properties we want in value learning. So I’ve long been excited about this high-level idea. The problem was that it wasn’t clear how to actually do this in practice… until recently.
A practical algorithm
In a recent work co-led with Aditya, we made meaningful progress toward realizing and scaling up this idea. Specifically, we were able to scale up divide-and-conquer value learning to highly complex tasks (as far as I know, this is the first such work!) at least in one important class of RL problems, goal-conditioned RL. Goal-conditioned RL aims to learn a policy that can reach any state from any other state. This provides a natural divide-and-conquer structure. Let me explain this.
The structure is as follows. Let’s first assume that the dynamics is deterministic, and denote the shortest path distance (“temporal distance”) between two states $s$ and $g$ as $d^*(s, g)$. Then, it satisfies the triangle inequality:
for all $s, g, w \in \mathcal{S}$.
In terms of values, we can equivalently translate this triangle inequality to the following “transitive” Bellman update rule:
where $\mathcal{E}$ is the set of edges in the environment’s transition graph, and $V$ is the value function associated with the sparse reward $r(s, g) = 1(s = g)$. Intuitively, this means that we can update the value of $V(s, g)$ using two “smaller” values: $V(s, w)$ and $V(w, g)$, provided that $w$ is the optimal “midpoint” (subgoal) on the shortest path. This is exactly the divide-and-conquer value update rule that we were looking for!
However, there’s one problem here. The issue is that it’s unclear how to choose the optimal subgoal $w$ in practice. In tabular settings, we can simply enumerate all states to find the optimal $w$ (this is essentially the Floyd-Warshall shortest path algorithm). But in continuous environments with large state spaces, we can’t do this. Basically, this is why previous works have struggled to scale up divide-and-conquer value learning, even though this idea has been around for decades (in fact, it dates back to the very first work in goal-conditioned RL by Kaelbling (1993) – see our paper for a further discussion of related works). The main contribution of our work is a practical solution to this issue.
Here’s our key idea: we restrict the search space of $w$ to the states that appear in the dataset, specifically, those that lie between $s$ and $g$ in the dataset trajectory. Also, instead of searching for the optimal $\text{argmax}_w$, we compute a “soft” $\text{argmax}$ using expectile regression. Namely, we minimize the following loss:
where $\bar{V}$ is the target value network, $\ell^2_\kappa$ is the expectile loss with an expectile $\kappa$, and the expectation is taken over all $(s_i, s_k, s_j)$ tuples with $i \leq k \leq j$ in a randomly sampled dataset trajectory.
This has two benefits. First, we don’t need to search over the entire state space. Second, we prevent value overestimation from the $\max$ operator by instead using the “softer” expectile regression. We call this algorithm Transitive RL (TRL). Check out our paper for more details and further discussions!
Does it work well?
To see whether our method scales well to complex tasks, we directly evaluated TRL on some of the most challenging tasks in OGBench, a benchmark for offline goal-conditioned RL. We mainly used the hardest versions of humanoidmaze and puzzle tasks with large, 1B-sized datasets. These tasks are highly challenging: they require performing combinatorially complex skills across up to 3,000 environment steps.
TRL achieves the best performance on highly challenging, long-horizon tasks.
The results are quite exciting! Compared to many strong baselines across different categories (TD, MC, quasimetric learning, etc.), TRL achieves the best performance on most tasks.
TRL matches the best, individually tuned TD-$n$, without needing to set $\boldsymbol{n}$.
This is my favorite plot. We compared TRL with $n$-step TD learning with different values of $n$, from $1$ (pure TD) to $\infty$ (pure MC). The result is really nice. TRL matches the best TD-$n$ on all tasks, without needing to set $\boldsymbol{n}$! This is exactly what we wanted from the divide-and-conquer paradigm. By recursively splitting a trajectory into smaller ones, it can naturally handle long horizons, without having to arbitrarily choose the length of trajectory chunks.
The paper has a lot of additional experiments, analyses, and ablations. If you’re interested, check out our paper!
In this post, I shared some promising results from our new divide-and-conquer value learning algorithm, Transitive RL. This is just the beginning of the journey. There are many open questions and exciting directions to explore:
Perhaps the most important question is how to extend TRL to regular, reward-based RL tasks beyond goal-conditioned RL. Would regular RL have a similar divide-and-conquer structure that we can exploit? I’m quite optimistic about this, given that it is possible to convert any reward-based RL task to a goal-conditioned one at least in theory (see page 40 of this book).
Another important challenge is to deal with stochastic environments. The current version of TRL assumes deterministic dynamics, but many real-world environments are stochastic, mainly due to partial observability. For this, “stochastic” triangle inequalities might provide some hints.
Practically, I think there is still a lot of room to further improve TRL. For example, we can find better ways to choose subgoal candidates (beyond the ones from the same trajectory), further reduce hyperparameters, further stabilize training, and simplify the algorithm even more.
In general, I’m really excited about the potential of the divide-and-conquer paradigm. I still think one of the most important problems in RL (and even in machine learning) is to find a scalable off-policy RL algorithm. I don’t know what the final solution will look like, but I do think divide and conquer, or recursive decision-making in general, is one of the strongest candidates toward this holy grail (by the way, I think the other strong contenders are (1) model-based RL and (2) TD learning with some “magic” tricks). Indeed, several recent works in other fields have shown the promise of recursion and divide-and-conquer strategies, such as shortcut models, log-linear attention, and recursive language models (and of course, classic algorithms like quicksort, segment trees, FFT, and so on). I hope to see more exciting progress in scalable off-policy RL in the near future!
Acknowledgments
I’d like to thank Kevin and Sergey for their helpful feedback on this post.
This post originally appeared on Seohong Park’s blog.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み