知識労働向けコデックス、創造的作業向けクロード:エージェントの多様化
OpenAI の Codex がコーディングから知識労働へ、Anthropic の Claude がクリエイティブツールおよびセキュリティ機能へとそれぞれ領域を拡大し、エージェントの汎用化が加速している。
キーポイント
Codex の知識労働への拡張
OpenAI の Codex が「Coding for Work」から「Knowledge Work」へ戦略を転換し、Microsoft/Google/Salesforce 連携や Office ファイル編集機能を実装して非エンジニア層にも開放された。
Claude のクリエイティブ・セキュリティ統合
Anthropic の Claude が Blender や Adobe Creative Cloud などのクリエイティブツールへのサポートを強化し、同時にコードレビューツール「Claude Security」を発表してセキュリティ脆弱性対策に注力した。
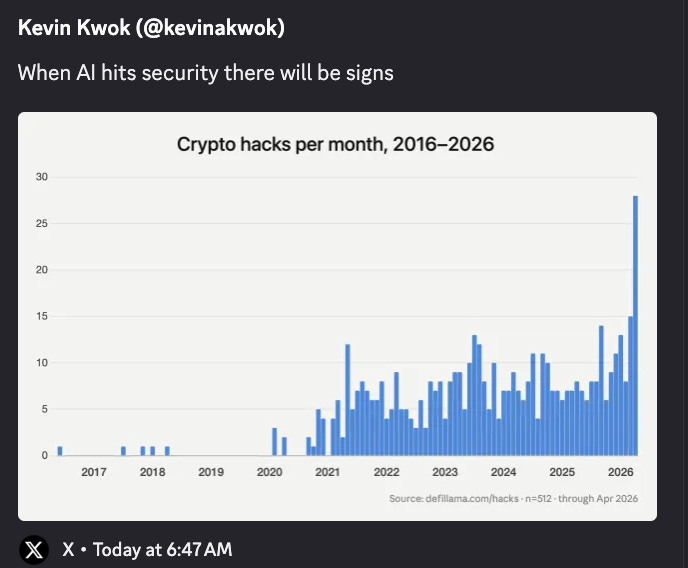
GPT-5.5 のサイバー攻撃シミュレーション達成
UK AI Security Institute の評価により、OpenAI の GPT-5.5 が多段階のサイバー攻撃シミュレーションを完了するモデルとなり、Claude と同レベルの実力を示した。
GPT-5.5 のサイバー攻撃シミュレーション能力向上
UK AI Security Institute の評価により、GPT-5.5 は複数ステップのサイバー攻撃シミュレーションを完了するモデルとして Claude とほぼ同等のパフォーマンスを示し、Anthropic の独占的優位性が揺らいだ。
Codex の汎用コンピューター作業への拡張
OpenAI は Codex をコード作成からドキュメントやスプレッドシートを含む一般的なコンピューター作業へ拡大し、更新により処理速度が最大 42% 向上した。
Qwen3.6 のオープンウェイトモデルとしての台頭
150B パラメータ未満のモデルで知能指数トップとなり、単一の H100 GPU で動作可能だが、推論コストは Gemma 4 よりも約 21 倍高いというトレードオフがある。
Tencent Hy3-preview の性能と特長
Intelligence Index で 42 を記録し Qwen3.6 などに劣るが、科学推論の CritPt では GLM-5.1 と同等の 4.6% を達成した。
影響分析・編集コメントを表示
影響分析
このニュースは、AI エージェントが特定のタスク(コーディング)に限定されず、あらゆるデジタル作業を代行する「スーパーアプリ」へと進化していることを示唆しています。特に非技術者向けの UI/UX 改善と既存ビジネスツールの統合が進むことで、企業現場での実装スピードが加速し、ホワイトカラー業務の再定義が現実味を帯びてきます。
編集コメント
今週は OpenAI と Anthropic の両社が、それぞれ「知識労働」と「クリエイティブ/セキュリティ」を主戦場としてエージェントの領域を広げており、業界全体が「コーディング支援」から「全業務自動化」へとフェーズ移行していることが明確になりました。
非教師あり学習ポッドキャストでは、「コーディングエージェントが制約を破っている」という仮説について言及しましたが、その議論は本日ライブで公開されました。
いくつかの発表は個別のものですが、他方は時間をかけて積み上がっていきます。Claude と Codex の両方とも非常に大きな一週間を送りましたが、Claude はここ数ヶ月続いている通り、インプレッション数の戦いで概ね勝利しています。
Codex
今日の Codex の大きなアップデートは「仕事のための Codex」で、基本的にはコーディングだけでなく知識労働のための Codex を訴求するランディングページです。これは先週、Codex を presumptive な OpenAI の「スーパーアプリ」へと転換させる動きの始まりに続くものです。しかし、単なるランディングページの更新にとどまりません。最新の Codex では CUA が 42% 高速化され、レスポンシブブラウザ、/chronicle、/goal(私たちが提唱する Ralph ループ)、そしてオンボーディングでは Microsoft/Google/Salesforce のスイートへの接続を促すようになり、エージェントには興味深いほど Cowork に似た計画 UI が備わり、MS Office ファイル用のアプリ内ファイルエディタも表示されます。
要するに、Tibo 氏が言うように「Codex は非コーディング者にも利用可能」、Greg 氏は「Codex は誰でも、コンピュータを使うあらゆるタスクのためにある」とし、Sam 氏は「コーディング以外のコンピュータ作業でも試してみてください」と述べています。お分かりいただけるでしょう。
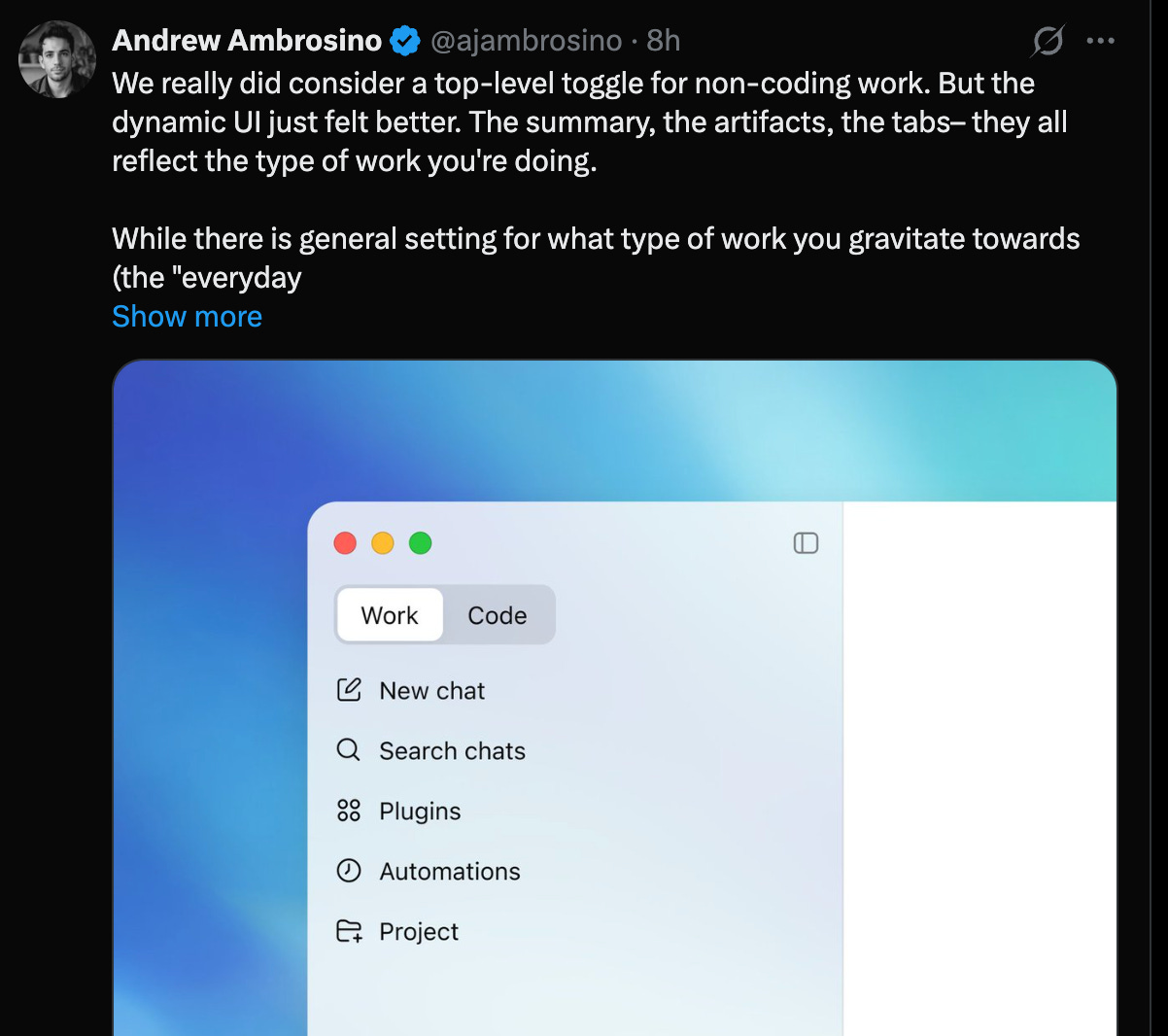
「動的 UI」は興味深い選択です。チームは明示的に Claude の Cowork に似たトグルを拒否し、代わりにエージェントが UI 体験をルーティングする道を選びました。
source
Claude
セキュリティ脆弱性が増加し、ミソス(Mythos)に関するメタ神話も広がる中、Anthropic はコードレビューツールである Claude Security を発表しました。
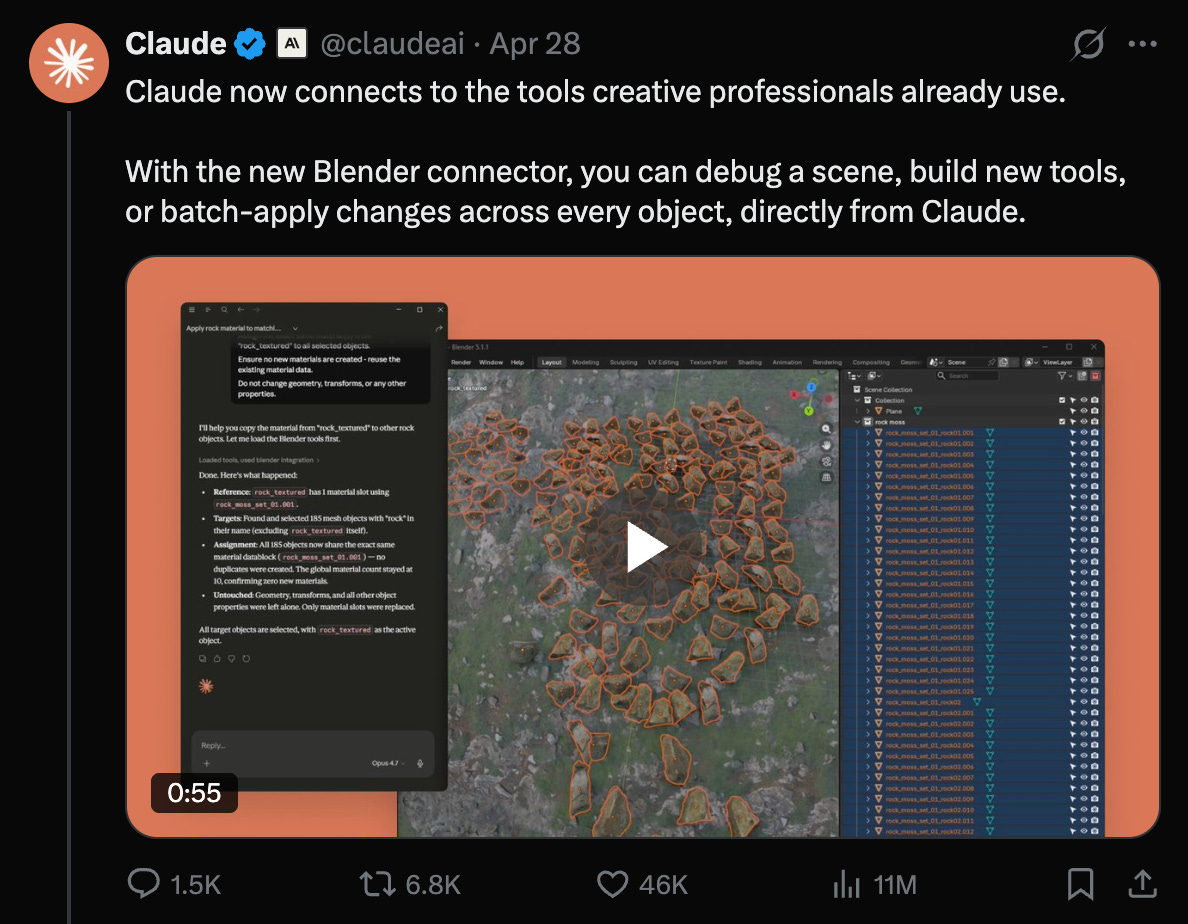
しかし、おそらく今週のより大きなニュースは、Blender、Autodesk、Adobe Creative Cloud、Ableton、Splice、Canva Affinity などのクリエイティブツールのサポートです。
2026 年 4 月 29 日〜30 日の AI ニュース。私たちは 12 のサブレッド、544 の Twitter(X)投稿を確認し、Discord は確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のため、AINews は現在 Latent Space の一部となっています。メールの頻度を選択的にオン/オフにできます!
AI Twitter リキャップ
OpenAI の GPT-5.5、Codex の拡張、およびサイバー能力評価
GPT-5.5 は、長期にわたるサイバータスクにおいてすでにトップティアのモデルとして確固たる地位を築いています。英国 AI セキュリティ研究所(UK AI Security Institute)は、GPT-5.5 が同機関が実施する多段階のサイバー攻撃シミュレーションをエンドツーエンドで完了した 2 つ目のモデルであると報告しました。また、複数の続報では、この評価において Claude Mythos Preview とほぼ同等のパフォーマンスを示したことが強調されました。@scaling01 は、GPT-5.5 の平均パス率が 71.4% であるのに対し、Mythos は 68.6% であると引用しました。一方、@cryps1s は、GPT-5.5 が TLO チェーンを 10 回の試行のうち 2 回で解決したのに対し、Mythos は 3 回であったと指摘しています。@polynoamial は、推論予算が 1 億トークンを超えてもパフォーマンスは依然として向上しており、明らかな飽和状態はまだ見られないと強調しました。これは、攻撃的なサイバー自動化において Anthropic が独自のリードを持っていたという以前の認識を根本的に変えるものです。OpenAI もまた、このタイミングに合わせて製品側のセキュリティリリースを発表しました。ChatGPT 向けの「高度なアカウントセキュリティ(Advanced Account Security)」が追加され、フィッシング耐性のあるサインイン機能や強化された回復機能が導入されました。
Codex はコーディングを超えて一般的なコンピュータ作業へと展開しています:OpenAI は「すべての人向け、コンピュータで行うあらゆるタスク向け」と明確に位置づけた大規模な Codex アップデートをリリースし、主な発表では役割ベースのオンボーディング、アプリ接続、ドキュメント、スライド、表計算、リサーチ、計画にわたるワークフローが強調されました。@ajambrosino はこのアップデートを動的なタスク固有 UI、20% 高速化されたコンピュータ/ブラウザ利用、スライドや表の扱いの改善、そしてよりスムーズな引き継ぎとして要約しました。一方、@AriX はアップデート後に Computer Use の実行速度が 42% 向上した点を指摘しています。Sam Altman も「今日 Codex に大規模アップグレード!コーディング以外のコンピュータ作業で試してください」と投稿し、その発表を後押ししました。より広い文脈として、OpenAI は単なるモデル能力ではなく、「Computer Use エージェント」の UX を製品化しているというパターンが見られます。
ベンチマークにおける差分は漸進的ですが経済的に意味があります:Artificial Analysis によると、GPT-5.5 Pro は CritPt において GPT-5.4 Pro よりわずかに新しい SOTA(State of the Art)となりましたが、興味深い点は単なるスコアの向上ではなく、その最先端科学評価において約 60% のコストとトークン使用量を削減しながらこの向上を達成したことです。これは、GPT-5.5 ファミリーが劇的な知能の断絶よりも、高価値なワークフローにおけるより高い信頼性と優れた効率性に関する議論と一致しています。
オープンウェイトモデルの動き:Qwen3.6、Tencent Hy3-preview、Grok 4.3、および Ling 2.6 1T
Qwen3.6 27B は、本日発表された最も重要なオープンウェイトモデルのようです。Artificial Analysis により、知能指数スコア46で150B パラメータ未満のオープンウェイトリーダーにランクされ、Gemma 4 31B や以前の Qwen バリアントを上回りました。主要な詳細は以下の通りです:Apache 2.0 ライセンス、262K のコンテキスト長、ネイティブ多モーダル入力対応、および単一の H100 GPU に収まる BF16(ブレッド・フォーマット)重み。 companion モデルである 35B A3B MoE(Mixture of Experts:専門家混合モデル)はスコア43を獲得し、約3B のアクティブパラメータを持つオープンモデルの中で最強となりました。ただし、出力トークンあたりの推論コストが高いというトレードオフがあります。AA の試算によると、Qwen3.6 27B はテストスイートで約1億4400万トーンの出力トークンを消費しており、Gemma 4 31B を同環境で実行する際の約21倍のコストがかかります。それでも、サイズあたりの能力という観点では、注目すべき一歩であると考えられます。
Tencent の Hy3-preview は競争力がありますが、クラスをリードするレベルではありません。Artificial Analysis は Hy3-preview を、総パラメータ数295B、アクティブパラメータ21B の MoE(Mixture of Experts:専門家混合モデル)として記述し、コンテキスト長は 256K、コミュニティライセンスでは商用利用が制限されています。AA の知能指数スコアは42で、直近のオープン競合モデルである Qwen3.6 27B、DeepSeek V4 Flash、GLM-5.1 に後れをとっています。最も興味深い明るい点は CritPt(科学的推論テスト)で、GLM-5.1 と同率の 4.6% を記録しており、全体の位置づけと比較して平均以上の科学推論能力を示唆しています。
xAI の Grok 4.3 は、エージェントベンチマークにおいて劇的に改善し、かつコストも低下しました。Artificial Analysis による測定では、Grok 4.3 のインテリジェンス指数は 53 で、Grok 4.20 v2 より 4 ポイント上昇しており、GDPval-AA では 1500 Elo と大幅な飛躍を遂げました。また、AA は前バージョンと比較して入力価格が約 40%、出力価格が約 60% 低下したと報告しています。リリース時点では GDPval-AA において GPT-5.5 に大きな差で後れを取っていますが、これは微細な改訂ではなく、システム全体およびポストトレーニングにおける本格的な改善であるように見えます。
Ant Group の Ling 2.6 1T は、最先端性能よりもコスト効率性を重視したモデルです。Artificial Analysis は、Ling 2.6 1T を推論機能を持たない 1 トリオンパラメータの非推論モデルとして位置づけ、スコアは 34 と評価しました。GPQA や HLE の数値も妥当であり、特にベンチマーク実行コストが約 95 ドルと極めて低いことが特徴です。ただし信頼性には注意が必要です。AA は AA-Omniscience におけるハルシネーション(幻覚)発生率が 92% に達すると報告しています。
DeepSeek のマルチモーダル・ビジョン技術、GUI エージェント、およびトレーニング規模に関する推測
DeepSeek のマルチモーダル方向性は、コンピューター使用エージェントと密接に連動しているように見えます。@nrehiew_ は、DeepSeek が V4-Flash へのビジョン学習において、推論中にモデルが直接バウンディングボックスやポイント座標を出力させることで行っていると指摘し、これを汎用的な VLM(Vision Language Model)の取り組みではなく、コンピューター使用指向の設計と解釈しています。もう一つの投稿では、論文における「ビジュアルプリミティブ」タスクは、広範なマルチモーダル理解ではなく、ブラウザやコンピューターの直接使用に直接対応するものであると主張されています(リンク)。この枠組みは、@teortaxesTex による並行する観察とも一致しており、DeepSeek が別個の「V4-Flash-Vision」としてリリースするのではなく、ビジョン重みをメインの V4 ラインに統合している可能性があります。
リポジトリの消失自体が一つの物語となりました:公開後、@teortaxesTex や @arjunkocher を含む複数の観察者が、DeepSeek の「Thinking with Visual Primitives」リポジトリが消滅したことに気づきました。これらのツイートにおいて明確な説明は出てきませんでしたが、この作業が視覚的推論や GUI グラウンディングのための具体的なレシピを示唆していたため、削除によりさらに注目を集めました。
スケーリングにおける会話の増加は、最先端事前学習における非常に大きなトークン数を示唆している:@teortaxesTex は、100T トークンを超える数がもはや最先端モデルでは珍しくないとし、仮想的な 100T トークンの DeepSeek V4 を「V4 にさらに 2 エポック分追加した」と評価した。一方、@nrehiew_ は、約 100B のアクティブパラメータを持つモデルに対して、概算で約 150T トークンと約 9e25 の事前学習 FLOPs(浮動小数点演算)を試算し、保守的な MFU(モデルフロップス利用率)において OpenAI スケールの 100K GB200 クラスター上で約 14 日程度で実行可能であることを示唆した。これらは推測に基づく見解ではあるが、「最先端規模」が実務上何を意味するのかを調整するための指標として有用である。
エージェントインフラ、ハネスエンジニアリング、および協調型エージェントシステム
モデル中心の自慢からハネス中心のエンジニアリングへと明確な転換が見られる:Cursor は、ランタイム、評価(evals)、劣化修復、モデル固有のカスタマイズに焦点を当て、汎用的なベンチマーク主張ではなく、どのようにエージェントハネスを検証・調整しているかについて強力なノートを発表した。@Vtrivedy10 は、Cursor の記述がエージェント構築者間で収束する設計パターンと明確に結びついていると指摘した:モデルごとの専用プロンプト/ツール、オフラインとオンラインを組み合わせた評価(evals)、社内での実利用(dogfooding)、そしてコンテキストウィンドウを主要な計算リソースの境界として扱うことである。
LangChain は引き続き、展開とマルチテナント型エージェントインフラのパッケージ化を継続しています。@hwchase17 が導入した DeepAgents deploy は、deepagents.toml を介した設定駆動型のクラウド展開フローであり、エージェント、サンドボックス、認証、フロントエンドの各セクションをカバーします。LangChain スタッフによる関連投稿では、データ分離、委任された資格情報、マルチユーザー展開における RBAC(ロールベースアクセス制御)のためのエージェントサーバーパターンが詳細に説明されています(例)。これは、デモを企業向けソフトウェアへと転換する、地味だが重要なレイヤーとしてますます重要視されています。
協調型マルチエージェントワークスペースはより具体化されつつあります。@cmpatino_ が導入した Agent Collabs は、Hugging Face のバケットと Spaces を組み合わせて、多様なエージェントの群れがメッセージ、成果物、進捗状況を交換するための共有バックエンドとして機能します。注目すべき点は単に「エージェント同士の協力」にあるのではなく、リソースの少ないエージェントが有用な検証作業に参加し、リソース豊富なエージェントが高コストな実験を処理できるようにする、軽量な調整プリミティブにあります。
セキュリティ、サプライチェーン、アカウント強化
オープンソースパッケージの侵害は依然として深刻な運用リスクです。Socket によると、人気の高い PyPI パッケージ「lightning」のバージョン 2.6.2 と 2.6.3 で侵害が発生し、インポート時に悪意のあるコードが実行され、Bun をダウンロードして、認証情報の窃取を目的とした 11 MB の難読化された JavaScript ペイロードを実行しました。@theo はこの事案を npm 上の「intercom-client」の侵害や Linux のゼロデイ脆弱性といった追加のパッケージ侵害と関連付け、ソフトウェアサプライチェーン攻撃のテンポが増加しているとの見解を示しています。
セキュリティスキャナが第一級の AI プロダクトへと進化しています:Anthropic は Claude Security をリリースしました。@kimmonismus 氏やその後 @_catwu 氏が説明したこの製品は、Opus 4.7 を基盤としたリポジトリ脆弱性スキャナで、発見された問題を検証し修正を提案する機能を備えています。一方、Cursor も Cursor Security Review という並行する提供を開始しました。これは常時オン状態の PR(プルリクエスト)レビューと、スケジュール実行可能なコードベーススキャンを含むものです。これは、モデルベンダーが確立された DevSecOps カテゴリに直接参入した最も明確な事例の一つです。
主要なツイート(エンゲージメント順)
OpenAI Codex が一般知識作業へと領域を拡大:OpenAI の Codex 発表と Sam Altman 氏の続報が、当日最大の製品関連投稿となりました。これは「コーディングエージェント」から「コンピュータ操作エージェント」への戦略的転換を示すものです。
GPT-5.5 のサイバー評価結果の重要性:UK AISI(英国 AI セキュリティ研究所)のスレッドは、エンゲージメントの高い技術系投稿の一つであり、Anthropic の Mythos との比較を再構築するものとなりました。
Qwen はモデルだけでなく解釈性ツールも提供:Qwen モデル向けのスパースオートエンコーダからなるオープンなスイート「Qwen-Scope」が注目されました。これは生モデル重みではなく、機能制御(feature steering)、デバッグ、データ合成、評価に焦点を当てた稀なリリースです。
Anthropic が大規模なガイダンス/同調性研究を発表:100 万件の Claude 会話に関する分析により、行動研究が Opus 4.7 や Mythos Preview のトレーニング変更と直接結びつけられました。これは、ポストトレーニングループがよりプロダクト化され、データ駆動型になりつつある重要な兆候です。
AI Reddit まとめ
/r/LocalLlama + /r/localLLM まとめ
- AMD Ryzen 395 Box と Halo Box の発売
続きを読む
あらゆる作業のためのエージェント:知識労働には Codex、創造的作業には Claude(続き 11/11)
AI エージェントは、単なるチャットボットの枠を超え、複雑なタスクを自律的に実行する能力へと進化しています。知識労働の領域では、Codex がコード生成やデータ分析においてその真価を発揮し、開発者の生産性を劇的に向上させます。一方、創造的作業においては、Claude が文章作成やデザイン提案を通じて、人間の想像力を補完・拡張するパートナーとして機能します。
両者の役割分担は明確です。Codex は構造化された情報処理と論理的推論に特化し、Claude は文脈の理解と創造的な発想に優れています。このように、タスクの種類に応じて最適な AI エージェントを選択することが、現代のワークフローを効率化する鍵となります。
今後の展開では、これらのエージェントが相互に連携し、より高度な複合タスクを処理するエコシステムの構築が進むことが予想されます。知識労働と創造的作業の境界はさらに曖昧になり、AI が人間の能力を最大限に引き出す時代が到来します。
原文を表示
We mentioned on the Unsupervised Learning pod about the thesis that “coding agents are breaking containment”, and that talk is published live today.
Some launches are discrete; others roll up over time. Both Claude and Codex had very big weeks, with Claude generally winning the impression count war as has been happening for a while now.
Codex
Today’s big Codex update was “Codex for Work”, basically a landing page that pitches Codex for Knowledge Work (not just coding), following on from last week’s beginnings of turning Codex into the presumptive OpenAI “SuperApp”. But it’s not just a landing page update; the latest Codex now has 42% faster CUA, responsive browser, /chronicle, /goal (“our take on the Ralph loop), and the onboarding now encourages you to plug into the Microsoft/Google/Salesforce suite and the agent now has a curiously Cowork-like planning UI and shows an in-app file editor for MS Office files.
Basically, as Tibo says, “Codex now available for non-coders”, Greg “Codex is for everyone, for any task done with a computer”, and Sam “try it for non-coding computer work.” You get the picture.
The “dynamic UI” is an interesting choice - the team explicitly rejects the Claude Cowork-like toggle, choosing instead to let the agent route the UI experience.
source
Claude
Against the backdrop of increasing security vulnerabilities, and a meta mythos around Mythos, Anthropic launched Claude Security, a code review tool.
But probably the bigger news this week was the support of creative tools like Blender, Autodesk, Adobe Creative Cloud, Ableton, Splice, Canva Affinity, and more.
AI News for 4/29/2026-4/30/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI’s GPT-5.5, Codex expansion, and cyber capability evaluations
GPT-5.5 is now credibly in the top tier for long-horizon cyber tasks: the UK AI Security Institute reported that GPT-5.5 became the second model to complete one of its multi-step cyber-attack simulations end-to-end, and multiple follow-on posts highlighted rough parity with Claude Mythos Preview on this eval: @scaling01 cited 71.4% average pass rate for GPT-5.5 vs 68.6% for Mythos, while @cryps1s noted GPT-5.5 solved the TLO chain in 2/10 attempts vs Mythos’ 3/10. @polynoamial emphasized that performance was still improving past 100M tokens of inference budget, suggesting no obvious saturation yet. This materially changes the earlier narrative that Anthropic had a unique lead in offensive cyber automation. OpenAI also paired this moment with a product-side security release: Advanced Account Security for ChatGPT, adding phishing-resistant sign-in and hardened recovery.
Codex is moving beyond coding into general computer work: OpenAI shipped a substantial Codex update framed explicitly as “for everyone, for any task done with a computer,” with the main announcement highlighting role-based onboarding, app connections, and workflows spanning docs, slides, spreadsheets, research, and planning. @ajambrosino summarized the update as dynamic task-specific UI, 20% faster computer/browser use, better slide/sheet handling, and less clunky handoffs, while @AriX called out that Computer Use runs 42% faster after the update. Sam Altman amplified the launch with “big upgrade for codex today! try it for non-coding computer work.” The broader pattern: OpenAI is productizing “computer-use agent” UX, not just model capability.
Benchmark deltas were incremental but economically meaningful: Artificial Analysis reported GPT-5.5 Pro as a slight new SOTA on CritPt over GPT-5.4 Pro, but the interesting point was not raw score—it achieved the bump with ~60% lower cost and token use on that frontier-science eval. That lines up with broader chatter that the GPT-5.5 family is less about a dramatic intelligence discontinuity than about stronger reliability and better efficiency in high-value workflows.
Open-weight model movement: Qwen3.6, Tencent Hy3-preview, Grok 4.3, and Ling 2.6 1T
Qwen3.6 27B looks like the most important open-weight release of the day: Artificial Analysis ranked Qwen3.6 27B as the new open-weights leader under 150B parameters with an Intelligence Index score of 46, ahead of Gemma 4 31B and prior Qwen variants. Key details: Apache 2.0, 262K context, native multimodal input, and BF16 weights small enough to fit on a single H100. The companion 35B A3B MoE scored 43, making it the strongest open model around 3B active parameters. The tradeoff is expensive inference-by-output-token: AA estimates Qwen3.6 27B used ~144M output tokens on the suite and is roughly 21× the cost of Gemma 4 31B to run there. Still, on capability-per-size it appears to be a notable step.
Tencent’s Hy3-preview is competitive but not class-leading: Artificial Analysis described Hy3-preview as a 295B total / 21B active MoE with 256K context and a restricted-commercial-use community license. It scored 42 on AA’s Intelligence Index, trailing recent open peers like Qwen3.6 27B, DeepSeek V4 Flash, and GLM-5.1. The most interesting bright spot was CritPt, where it matched GLM-5.1 at 4.6%, suggesting better-than-average scientific reasoning relative to its overall position.
xAI’s Grok 4.3 improved sharply on agentic benchmarks while getting cheaper: Artificial Analysis measured Grok 4.3 at 53 on the Intelligence Index, up four points from Grok 4.20 v2, with a major jump on GDPval-AA to 1500 Elo. AA also reported approximately 40% lower input price and 60% lower output price than the prior version. The release still trails GPT-5.5 on GDPval-AA by a wide margin, but it looks like a real systems-and-post-training improvement rather than a minor rev.
Ant Group’s Ling 2.6 1T targets cost-efficiency rather than frontier status: Artificial Analysis positioned Ling 2.6 1T as a 1T-parameter non-reasoning model scoring 34, with decent GPQA/HLE numbers and notably low benchmark-run cost at roughly $95. The caveat is reliability: AA reported a 92% hallucination rate on AA-Omniscience.
DeepSeek multimodal/vision work, GUI agents, and training scale speculation
DeepSeek’s multimodal direction appears tightly coupled to computer-use agents: @nrehiew_ highlighted that DeepSeek trains vision into V4-Flash by having the model directly output bounding boxes and point coordinates during reasoning, interpreting this as a computer-use-oriented design rather than generic VLM work. A second post argues the paper’s “visual primitives” tasks map directly to browser/computer use rather than broad multimodal understanding (link). That framing matches parallel observations from @teortaxesTex that DeepSeek may be integrating vision weights back into the main V4 line rather than releasing a separate “V4-Flash-Vision”.
The repo disappearance became a story of its own: after release, several observers noted that DeepSeek’s “Thinking with Visual Primitives” repo vanished, including @teortaxesTex and @arjunkocher. No clear explanation emerged in these tweets, but the deletion drew more attention because the work suggested a concrete recipe for visual reasoning and GUI grounding.
Scaling chatter points to very large token counts for frontier pretraining: @teortaxesTex argued that >100T tokens is no longer unusual for frontier models and estimated a hypothetical 100T-token DeepSeek V4 as “V4 + 2 more epochs,” while @nrehiew_ back-of-the-enveloped ~150T tokens and ~9e25 pretraining FLOPs for a ~100B active model, suggesting a run feasible in roughly 14 days on an OpenAI-scale 100K GB200 cluster at conservative MFU. These are speculative takes, but useful as calibration for what “frontier-scale” now means in practice.
Agent infrastructure, harness engineering, and collaborative agent systems
There is a clear shift from model-centric bragging to harness-centric engineering: Cursor published a strong note on how it tests and tunes its agent harness, focusing on runtime, evals, degradation repair, and model-specific customization rather than generic benchmark claims. @Vtrivedy10 explicitly connected Cursor’s writeup to design patterns converging across agent builders: bespoke prompts/tools per model, mixed offline+online evals, dogfooding, and treating the context window as the primary compute boundary.
LangChain continues to package deployment and multi-tenant agent infra: @hwchase17 introduced DeepAgents deploy, a config-driven cloud deployment flow via deepagents.toml, covering agent, sandbox, auth, and frontend sections. Related posts from LangChain staff detailed agent-server patterns for data isolation, delegated credentials, and RBAC in multi-user deployments (example). This is increasingly the boring-but-important layer turning demos into enterprise software.
Collaborative multi-agent workspaces are getting more concrete: @cmpatino_ introduced Agent Collabs, using Hugging Face buckets plus Spaces as a shared backend for swarms of heterogeneous agents to exchange messages, artifacts, and progress. The noteworthy idea is not just “agents collaborating,” but lightweight coordination primitives that let weaker agents contribute useful validation work while better-resourced agents handle expensive experiments.
Security, supply chain, and account hardening
Open-source package compromise remains an acute operational risk: Socket reported that the popular PyPI package lightning was compromised in versions 2.6.2 and 2.6.3, with malicious code executing on import, downloading Bun, and running an 11 MB obfuscated JavaScript payload aimed at credential theft. @theo connected that incident with additional package compromises (intercom-client on npm) and a Linux zero day, arguing the tempo of software supply-chain attacks is increasing.
Security scanners are becoming first-class AI products: Anthropic rolled out Claude Security, described by @kimmonismus and later @_catwu as a repo vulnerability scanner that validates findings and suggests fixes, powered by Opus 4.7. Cursor shipped a parallel offering with Cursor Security Review, including always-on PR review and scheduled codebase scans. This is one of the clearest examples of model vendors moving directly into established devsecops categories.
Top tweets (by engagement)
OpenAI Codex broadens into general knowledge work: OpenAI’s Codex announcement and Sam Altman’s follow-up were the day’s biggest product posts, signaling a strategic push from “coding agent” to “computer-use agent”.
GPT-5.5’s cyber eval result mattered: UK AISI’s thread was one of the highest-engagement technical posts and reshaped comparisons with Anthropic’s Mythos.
Qwen shipped interpretability tooling, not just models: Qwen-Scope, an open suite of sparse autoencoders for Qwen models, stood out as a rare release focused on feature steering, debugging, data synthesis, and evaluation rather than raw model weights.
Anthropic published a large-scale guidance/sycophancy study: their analysis of 1M Claude conversations tied behavioral research directly to training changes for Opus 4.7 and Mythos Preview, an important sign that post-training loops are becoming more productized and data-informed.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
- AMD Ryzen 395 Box and Halo Box Launch
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み