マルチモーダル知識グラフ「RAG-Anything」を用いた複雑な実世界ドキュメントの理解
LayerX は、複雑な実世界ドキュメントにおける視覚情報の欠落という課題に対し、マルチモーダル知識グラフを活用した「RAG-Anything」フレームワークを提案し、LLM の解析精度向上への道筋を示しました。
キーポイント
既存 RAG の構造的限界
従来のテキストベースの RAG は、PDF 内のグラフや図表といった視覚的情報を抽出する際に失敗し、複雑なドキュメントの正確な理解が困難であるという課題を指摘しています。
RAG-Anything のアプローチ
マルチモーダル知識グラフを構築することで、テキストだけでなく視覚的要素も構造化された情報として統合し、LLM への入力精度を高めるフレームワークです。
エンタープライズ業務への応用
LayerX の製品「Ai Workforce」において、複雑なレイアウトや図表を含むビジネスドキュメントの解析品質を向上させるための具体的な解決策として提案されています。
技術的実装と公開
関連する論文(arXiv)および GitHub リポジトリが公開されており、オープンな形で技術検証や応用開発が可能となっています。
散在する情報への対応の難しさ
根拠となる記述がドキュメント内の複数ページに散在している場合、一般的なアプローチでは抽出の難易度が急激に高まり、多段階推論におけるシステム制御が困難になる。
回答根拠の不透明さとハルシネーション
AIの回答根拠を明示する際、LLMが指示を省略したり事実と異なる情報を生成するハルシネーションリスクがあり、根拠出力を強制すると抽出性能そのものが低下する懸念がある。
知識グラフによる課題解決
従来の「視覚情報の欠落」「散在情報の整理」「根拠の不透明さ」という3つの壁に対し、LLMと融合させた知識グラフの活用が根本的な解決策として注目されている。
影響分析・編集コメントを表示
影響分析
この記事は、LLM がテキスト情報だけでなく視覚情報を正しく理解する必要性を浮き彫りにし、従来の RAG アプローチの限界を超えるための具体的な技術的解決策(マルチモーダル知識グラフ)を提示しています。エンタープライズ領域におけるドキュメント解析の精度向上に寄与し、実務での AI 導入障壁を下げる重要な知見を提供するものです。
編集コメント
実務で頻出する複雑なドキュメント解析における「視覚情報の欠落」という本質的な課題に対し、知識グラフを組み合わせることで解決を図るアプローチは非常に示唆に富んでいます。
※本記事は、2026年5月までLayerXのAi Workforce事業部でR&Dインターンとして活躍してくれたkemotoさんによる執筆です。本人のインターン期間終了に伴い、LayerX の koichi(こいち)が代理で投稿いたします。最先端のAI協業の現場で得られたリアルな学びを、ぜひご覧ください!
--
こんにちは。LayerX AiWorkforce 事業部 R&D チームでインターンしております竹本(@kemotohuman)です。
当事業部では、エンタープライズのお客さま向けに『Ai Workforce』というプロダクトを提供しています。Ai Workforce では、エンタープライズの業務に用いる複雑なドキュメントを「AIの力でいかに正確に処理・分析するか」というテーマに日々向き合っています。
しかし、実務で扱われるドキュメントの解析は一筋縄ではいきません。複雑なグラフや図表、緻密なレイアウトが施されたPDF資料を最新のAIに読み込ませ、「この内容を正確に分析してほしい」と依頼したとき、期待外れの回答にガッカリした経験はないでしょうか。現在のLLM(大規模言語モデル)技術は飛躍的に進化しましたが、依然として「実世界のドキュメント」を真に理解しているとは言い難いのが現状です。
今回は、このような課題を解決するために提案されたフレームワーク「RAG-Anything」について、そのアプローチと仕組み、そして実務への応用可能性を解説します。
- 元論文:https://arxiv.org/abs/2510.12323
- GitHub:https://github.com/hkuds/rag-anything
一般的な情報抽出が抱える課題
複雑なビジネスドキュメントからAIを用いて情報を抽出する際、従来の一般的なシステム(テキストベースのRAGなど)では、主に3つの構造的な壁に直面します。
1. 視覚的・マルチモーダルな情報の欠落
一般的にドキュメントをAIに処理させる場合、まずは一度「テキストデータに変換(文字起こし)」してからLLMに入力するアプローチが広く使われています。しかし、この方法ではグラフの推移やフロー図のように、「視覚的な理解が必要な要素」から情報を正確に抽出することが極めて困難になります。

テキストデータへの変換が情報抽出に悪影響を及ぼす例
ページ全体をそのまま画像としてマルチモーダルLLMに入力するという手段もありますが、レイアウトが緻密で複雑なドキュメントほどノイズが増えてしまい、ピンポイントでの情報抽出において精度が出ないというジレンマを抱えています。
2. 散在する情報や多段階推論への弱さ
回答の根拠となる記述がドキュメント内の1箇所にまとまっていれば良いのですが、根拠が複数かつ離れたページに散在している場合、一般的なアプローチでは抽出の難易度が急激に上がります。
ドキュメント全体の内容を俯瞰し、離れた位置にある複数の要素を整理しながら、多段階で答えを導き出すような高度なタスクにおいて、ナイーブな処理の場合 LLM の純粋な処理能力(モデルの賢さ)まかせになってしまい、システム側での制御が難しいという弱点があります。
3. 回答根拠の不透明さとハルシネーション
実務で AI を活用する上で、「AI の回答が、ドキュメントのどの部分に基づいているか」をユーザーに明示することは、信頼性の観点から不可欠です。一般的な情報抽出では「LLM に回答と同時に参照元のテキストも出力させる」という手法がよく取られます。
この場合、LLM がプロンプトの指示を途中で省略してしまったり、実際にはドキュメントにないテキストを出力してしまうハルシネーション(幻覚)のリスクが常に伴います。また、「根拠を正確に出力する」という余分なタスクをモデルに強いることで、本来の情報抽出性能そのものが低下してしまう懸念も存在します。
このように、従来のやり方では「視覚情報の欠落」「散在する情報の整理」「根拠の不透明さ」という 3 つの壁にぶつかってしまいます。
これらの課題、特に「散在する情報の整理」や「複雑な関係性の欠落」を根本から解決するためのアプローチとして、近年大きな注目を集めているのが「知識グラフ(Knowledge Graph)」の活用です。
次のセクションでは、まずこの知識グラフと LLM を融合させることで何が可能になるのかを詳しく説明します。
知識グラフと LLM の融合
前セクションで触れた「情報の散在」や「複雑な関係性の欠落」といった従来の RAG(Retrieval-Augmented Generation:検索拡張生成)の限界を突破するための鍵となるのが、「知識グラフ(Knowledge Graph)」と LLM の融合です。
1. 知識グラフとは?
知識グラフとは、実世界に存在する人・場所・組織・概念などの「エンティティ」と、それらの間にある「エッジ(関係性)」を用いて、情報をネットワーク構造で記述したものです。

例えば上の例だと、「Karl と Fred は友達(FRIEND)同士で、2 人とも東京(Tokyo)に住んでいる(LIVES_IN)」という情報を、それぞれの人物や場所をノード(丸)で表し、それらの関係を矢印(エッジ)で繋いで構造化して表現しています。
こうしたデータは Neo4j などの専用のグラフデータベースで管理され、Cypher などのクエリ言語を使って操作されます。
知識グラフは情報同士の複雑なつながりや暗黙的な関係性を明示的かつ正確に表現できる一方で、データの構築や運用のハードルが高い点が長年の課題でした。
2. LLM との統合
近年の LLM(大規模言語モデル)の発展は、知識グラフの構築や活用のあり方にも大きな変化をもたらしています。
まず大きな変化として挙げられるのが、LLMによって知識グラフの構築が圧倒的に容易になった点です。従来、テキストからエンティティやエッジを抽出してグラフデータを構築するには、固有表現認識(NER)をはじめとする複雑な自然言語処理の技術をいくつも組み合わせる必要があり、開発や運用のハードルが非常に高いものでした。しかし現在では、LLMに対してプロンプトで「この文章から要素と関係性を抽出して」と指示するだけで、柔軟かつ制御しやすい形でデータをパースできるようになり、構築のコストが大幅に下がっています。
一方で、こうして構築した知識グラフを、今度はLLMのコンテキストとして与えて活用するアプローチも進化しています。これが、近年検索拡張生成の発展形として注目されている「GraphRAG」です。LLMに構造化された知識グラフを組み合わせることで、従来のテキストを細切れにして検索するだけの方法では解けなかった、ドキュメント内の離れた情報を跨いで整理するような、高度で複雑な多段階推論が可能になります。
3. 従来の RAG と GraphRAG の違い

ドキュメントの検索において、一般的なテキストベースの従来の RAG(Naive RAG)と、知識グラフを活用した GraphRAG には決定的なアプローチの差があります。
- Naive RAG の限界:ドキュメントを一定の長さでチャンク化し、質問文とのベクトルの類似度(セマンティック検索)で関連箇所を探します。しかし、この方法では情報同士の暗黙的な関係性が削ぎ落とされてしまい、適切な回答を導き出せないケースが多発します。
- GraphRAG の強み:ドキュメント内の要素をインデックス化する際、あらかじめ要素間の関係性をネットワーク構造として保持します。そのため、質問に対して関連するグラフ構造を辿る検索を行うことができ、離れたページに散在している情報や暗黙的な関係性も取りこぼさずに網羅して抽出することができます。
このように、LLM にドキュメントの構造や関係性を教え込むアプローチとして、GraphRAG は極めて強力なソリューションです。しかし、一般的な GraphRAG は依然としてテキストデータをベースにグラフを構築するものが大半です。PDF 資料にあるような「グラフや図表、複雑なレイアウトそのものが持つ視覚的な意味」までを知識グラフに融合させることは、容易ではありません。
RAG-Anything は、テキスト、画像、表、数式といった異なるモダリティ(データの種類)の情報を、すべて「相互に繋がりを持つ知識エンティティ」として再定義し、包括的に検索・生成を行うオールインワンのマルチモーダル RAG フレームワークです。
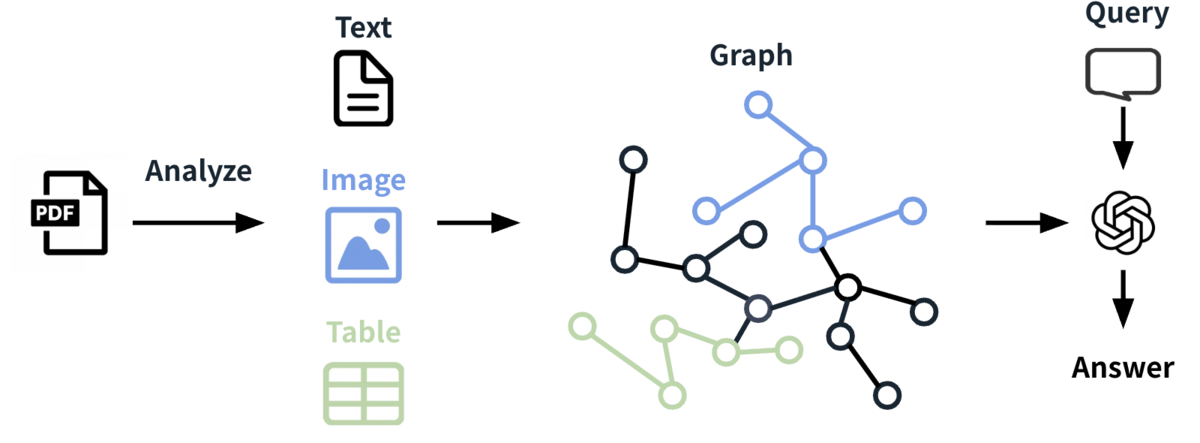
RAG-Anything の概要
1. インデックスの作成

RAG-Anything におけるマルチモーダルなインデックス作成(元論文より抜粋)
まず、入力された PDF 資料を高度なレイアウト解析パーサー(オープンソースの「MinerU」など)を用いて、テキスト、画像、表、数式などのコンポーネントに分離・抽出します。
このとき、単にデータを細切れ(チャンク化)にするのではなく、「図とそのキャプション」「数式とその定義文」「表とその説明テキスト」といった、ドキュメント内で密接に関わっている周囲の文脈を保持したまま、知識単位に分解するのが大きな特徴です。
次に、分解された知識単位から、役割の異なる 2 つの独立した知識グラフを並行して構築します。
- クロスモーダル知識グラフ(Cross-Modal Knowledge Graph)画像や表、数式などの非テキスト情報を VLM(視覚言語モデル)に入力し、検索用の「詳細な説明文」と、グラフ用の「エンティティ要約」の 2 つのテキスト表現を出力させます。これらを起点(アンカー)として、周囲のテキストチャンクと「belongs_to(〜に属する)」などのエッジ(矢印)で結び、ビジュアル要素をドキュメントの文脈構造の中に正しく位置づけます。
- テキストベース知識グラフ(Text-based Knowledge Graph)ドキュメント内の純粋なテキスト部分に対しては、従来の GraphRAG の手法を用い、固有表現抽出や関係性抽出を行って文字ベースの知識ネットワークを構築します。
こうしてできた 2 つのグラフを、同一の概念や単語のマッチングによって 1 つの包括的な知識グラフへと融合させます。同時に、高速なセマンティック検索を可能にするため、すべてのノードや関係性を高次元のベクトルに変換したベクトルデータベースも裏側で構築されます。
2. クロスモーダル検索と回答生成

RAG-Anything における情報検索と回答生成の流れ
ユーザーから質問(クエリ)が投げかけられると、RAG-Anything はまずクエリを分析し、文中に「図」「グラフ」「表」といった、特定のモダリティを指し示す語彙が含まれているかを識別します。
その上で、以下の 2 つの経路を組み合わせたハイブリッド検索を実行します。
- 構造的ナビゲーション(Structural Knowledge Navigation):融合された知識グラフを探索し、キーワードが直接ヒットした要素だけでなく、グラフの繋がりを辿ることで、離れたページに散在している「暗黙的な関係性」を持つ関連要素まで取りこぼさずに抽出します。
- 意味的類似度マッチング(Semantic Similarity Matching):クエリのベクトルを用いて、ベクトルデータベースから意味の近いチャンクやエンティティをピンポイントで検索します。
こうして両方の経路から集められた候補は、グラフ構造上の重要度、ベクトルの類似度、クエリから推測されたモダリティの優先度などを統合したスコアリングによって再ランキングされ、本当に必要なコンテキストだけが厳選されます。
従来の検索システムであれば、検索にヒットした「テキストによる説明」だけを LLM に渡して終わりでした。しかし RAG-Anything は、検索結果に画像や図表由来のノードが含まれていた場合、元のドキュメントから該当する「生の画像データ」をピンポイントで取得します。**
そして、厳選された構造化されたテキストコンテキストと、取得された生の画像の両方を VLM に同時に入力し、最終的な回答を生成します。これにより、テキストの文脈理解と、画像そのものが持つ生の情報を掛け合わせて回答を生成できます。回答の根拠となる図表が元データに直接ひも付くため、「どの視覚情報に基づいた回答なのか」を追跡しやすくなり、根拠なき出力(ハルシネーション)の混入を検知・抑制しやすい**という利点があります。
3. 精度評価
RAG-Anythingの有効性を検証するため、論文ではマルチモーダルなドキュメント QA のベンチマークである「DocBench」および「MMLongBench」を用いた性能評価が行われています。比較対象として、ネイティブマルチモーダル LLM への直接入力(GPT-4o-mini)や、テキスト中心の GraphRAG 手法(LightRAG)、画像要素のみをグラフ化する手法(MMGraphRAG)などが選定されました。

実験の結果、RAG-Anything は各種ベースラインと比較して、特にドキュメントのページ数が多くなる長文コンテキストにおいて良好なパフォーマンスを示す傾向が確認されています。例えば DocBench データセットにおける 100 ページを超える長大なドキュメントの検証では、DocBench の正答率〔Accuracy, %〕で MMGraphRAG に対して 13 ポイント以上の精度向上が見られました。また、MMLongBench においても同様の傾向が見られ、情報が複数ページに分散している状況での優位性が示されています。
さらに、どのコンポーネントが精度向上に寄与しているかを分析するアブレーション研究も行われており、RAG-Anything における性能のコアは、単なるリランカー等の工夫ではなく、デュアルグラフの構築によってドキュメント内の構造や要素間の関係性を保持できている点にあることが示唆されています。
実際に使ってみた
本フレームワークの挙動を確認するため、RAG-Anything に簡易的な UI を組み合わせ、インデックス構築と QA の検証を行いました。
1. 情報の整理と可視化
検証として、マルチモーダルな技術論文(DeepSeek-OCR 2)の PDF を入力し、RAG-Anything でグラフインデックスを構築しました。グラフインデックスが視覚的に把握できるよう、今回は UI 上でノードを要素ごとに色分けして表示できるように一部改変を加えました。

RAG-Anything によるグラフ構築例
上の例を見ると、各モダリティが文脈に応じてネットワーク状に密接に結びついており、RAG-Anything が PDF に含まれるテキスト・画像・表・数式などの要素を抽出し、それらの関係性を適切にグラフ構造へと落とし込んでいることがわかると思います。
2. 根拠を明示した情報抽出と QA
構築したインデックスに対し、実際に図表の理解が必要な質問を投げました。
原文を表示
※本記事は、2026年5月までLayerXのAi Workforce事業部でR&Dインターンとして活躍してくれた kemotoさんによる執筆です。本人のインターン期間終了に伴い、LayerX の koichi(こいち)が代理で投稿いたします。最先端のAI協業の現場で得られたリアルな学びを、ぜひご覧ください!
--
こんにちは。LayerX AiWorkforce 事業部 R&D チームでインターンしております竹本(@kemotohuman)です。
当事業部では、エンタープライズのお客さま向けに『Ai Workforce』というプロダクトを提供しています。Ai Workforce では、エンタープライズの業務に用いる複雑なドキュメントを「AIの力でいかに正確に処理・分析するか」というテーマに日々向き合っています。
しかし、実務で扱われるドキュメントの解析は一筋縄ではいきません。複雑なグラフや図表、緻密なレイアウトが施されたPDF資料を最新のAIに読み込ませ、「この内容を正確に分析してほしい」と依頼したとき、期待外れの回答にガッカリした経験はないでしょうか。現在のLLM(大規模言語モデル)技術は飛躍的に進化しましたが、依然として「実世界のドキュメント」を真に理解しているとは言い難いのが現状です。
今回は、このような課題を解決するために提案されたフレームワーク「RAG-Anything」について、そのアプローチと仕組み、そして実務への応用可能性を解説します。
- 元論文:https://arxiv.org/abs/2510.12323
- GitHub:https://github.com/hkuds/rag-anything
一般的な情報抽出が抱える課題
複雑なビジネスドキュメントからAIを用いて情報を抽出する際、従来の一般的なシステム(テキストベースのRAGなど)では、主に3つの構造的な壁に直面します。
1. 視覚的・マルチモーダルな情報の欠落
一般的にドキュメントをAIに処理させる場合、まずは一度「テキストデータに変換(文字起こし)」してからLLMに入力するアプローチが広く使われています。しかし、この方法ではグラフの推移やフロー図のように、「視覚的な理解が必要な要素」から情報を正確に抽出することが極めて困難になります。
テキストデータへの変換が情報抽出に悪影響を及ぼす例
ページ全体をそのまま画像としてマルチモーダルLLMに入力するという手段もありますが、レイアウトが緻密で複雑なドキュメントほどノイズが増えてしまい、ピンポイントでの情報抽出において精度が出ないというジレンマを抱えています。
2. 散在する情報や多段階推論への弱さ
回答の根拠となる記述がドキュメント内の1箇所にまとまっていれば良いのですが、根拠が複数かつ離れたページに散在している場合、一般的なアプローチでは抽出の難易度が急激に上がります。
ドキュメント全体の内容を俯瞰し、離れた位置にある複数の要素を整理しながら、多段階で答えを導き出すような高度なタスクにおいて、ナイーブな処理の場合LLMの純粋な処理能力(モデルの賢さ)まかせになってしまい、システム側での制御が難しいという弱点があります。
3. 回答根拠の不透明さとハルシネーション
実務でAIを活用する上で、「AIの回答が、ドキュメントのどの部分に基づいているか」をユーザーに明示することは、信頼性の観点から不可欠です。一般的な情報抽出では「LLMに回答と同時に参照元のテキストも出力させる」という手法がよく取られます。
この場合、LLMがプロンプトの指示を途中で省略してしまったり、実際にはドキュメントにないテキストを出力してしまうハルシネーションのリスクが常に伴います。また、「根拠を正確に出力する」という余分なタスクをモデルに強いることで、本来の情報抽出性能そのものが低下してしまう懸念も存在します。
このように、従来のやり方では「視覚情報の欠落」「散在する情報の整理」「根拠の不透明さ」という3つの壁にぶつかってしまいます。
これらの課題、特に「散在する情報の整理」や「複雑な関係性の欠落」を根本から解決するためのアプローチとして、近年大きな注目を集めているのが「知識グラフ(Knowledge Graph)」の活用です。
次のセクションでは、まずこの知識グラフとLLMを融合させることで何が可能になるのかを詳しく説明します。
知識グラフとLLMの融合
前セクションで触れた「情報の散在」や「複雑な関係性の欠落」といった従来のRAGの限界を突破するための鍵となるのが、「知識グラフ(Knowledge Graph)」とLLMの融合です 。
1. 知識グラフとは?
知識グラフとは、実世界に存在する人・場所・組織・概念などの「エンティティ」と、それらの間にある「エッジ(関係性)」を用いて、情報をネットワーク構造で記述したものです 。
例えば上の例だと、「KarlとFredは友達(FRIEND)同士で、2人とも東京(Tokyo)に住んでいる(LIVES_IN)」という情報を、それぞれの人物や場所をノード(丸)で表し、それらの関係を矢印(エッジ)で繋いで構造化して表現しています。
こうしたデータはNeo4jなどの専用のグラフデータベースで管理され、Cypherなどのクエリ言語を使って操作されます。
知識グラフは情報同士の複雑なつながりや暗黙的な関係性を明示的かつ正確に表現できる一方で、データの構築や運用のハードルが高い点が長年の課題でした。
2. LLMとの統合
近年のLLM(大規模言語モデル)の発展は、知識グラフの構築や活用のあり方にも大きな変化をもたらしています。
まず大きな変化として挙げられるのが、LLMによって知識グラフの構築が圧倒的に容易になった点です。従来、テキストからエンティティやエッジを抽出してグラフデータを構築するには、固有表現認識(NER)をはじめとする複雑な自然言語処理の技術をいくつも組み合わせる必要があり、開発や運用のハードルが非常に高いものでした。しかし現在では、LLMに対してプロンプトで「この文章から要素と関係性を抽出して」と指示するだけで、柔軟かつ制御しやすい形でデータをパースできるようになり、構築のコストが大幅に下がっています 。
一方で、こうして構築した知識グラフを、今度はLLMのコンテキストとして与えて活用するアプローチも進化しています。これが、近年検索拡張生成の発展形として注目されている「GraphRAG」です 。LLMに構造化された知識グラフを組み合わせることで、従来のテキストを細切れにして検索するだけの方法では解けなかった、ドキュメント内の離れた情報を跨いで整理するような、高度で複雑な多段階推論が可能になります 。
3. 従来のRAGとGraphRAGの違い
ドキュメントの検索において、一般的なテキストベースの従来のRAG(Naive RAG)と、知識グラフを活用したGraphRAGには決定的なアプローチの差があります 。
- Naive RAGの限界 :ドキュメントを一定の長さでチャンク化し、質問文とのベクトルの類似度(セマンティック検索)で関連箇所を探します 。しかし、この方法では情報同士の暗黙的な関係性が削ぎ落とされてしまい、適切な回答を導き出せないケースが多発します。
- GraphRAGの強み:ドキュメント内の要素をインデックス化する際、あらかじめ要素間の関係性をネットワーク構造として保持します 。そのため、質問に対して関連するグラフ構造を辿る検索を行うことができ、離れたページに散在している情報や暗黙的な関係性も取りこぼさずに網羅して抽出することができます 。
このように、LLMにドキュメントの構造や関係性を教え込むアプローチとして、GraphRAGは極めて強力なソリューションです 。
しかし、一般的なGraphRAGは依然としてテキストデータをベースにグラフを構築するものが大半です。PDF資料にあるような「グラフや図表、複雑なレイアウトそのものが持つ視覚的な意味」までを知識グラフに融合させることは、容易ではありません。
RAG-Anythingは、テキスト、画像、表、数式といった異なるモダリティ(データの種類)の情報を、すべて「相互に繋がりを持つ知識エンティティ」として再定義し、包括的に検索・生成を行うオールインワンのマルチモーダルRAGフレームワークです。
RAG-Anythingの概要
1. インデックスの作成
RAG-Anythingにおけるマルチモーダルなインデックス作成(元論文より抜粋)
まず、入力されたPDF資料を高度なレイアウト解析パーサー(オープンソースの「MinerU」など)を用いて、テキスト、画像、表、数式などのコンポーネントに分離・抽出します。
このとき、単にデータを細切れ(チャンク化)にするのではなく、「図とそのキャプション」「数式とその定義文」「表とその説明テキスト」といった、ドキュメント内で密接に関わっている周囲の文脈を保持したまま、知識単位に分解するのが大きな特徴です。
次に、分解された知識単位から、役割の異なる2つの独立した知識グラフを並行して構築します。
- クロスモーダル知識グラフ(Cross-Modal Knowledge Graph)画像や表、数式などの非テキスト情報をVLM(視覚言語モデル)に入力し、検索用の「詳細な説明文」と、グラフ用の「エンティティ要約」の2つのテキスト表現を出力させます。これらを起点(アンカー)として、周囲のテキストチャンクと「belongs_to(〜に属する)」などのエッジ(矢印)で結び、ビジュアル要素をドキュメントの文脈構造の中に正しく位置づけます。
- テキストベース知識グラフ(Text-based Knowledge Graph)ドキュメント内の純粋なテキスト部分に対しては、従来のGraphRAGの手法を用い、固有表現抽出や関係性抽出を行って文字ベースの知識ネットワークを構築します。
こうしてできた2つのグラフを、同一の概念や単語のマッチングによって1つの包括的な知識グラフへと融合させます。同時に、高速なセマンティック検索を可能にするため、すべてのノードや関係性を高次元のベクトルに変換したベクトルデータベースも裏側で構築されます。
2. クロスモーダル検索と回答生成
RAG-Anythingにおける情報検索と回答生成の流れ
ユーザーから質問(クエリ)が投げかけられると、RAG-Anythingはまずクエリを分析し、文中に「図」「グラフ」「表」といった、特定のモダリティを指し示す語彙が含まれているかを識別します。
その上で、以下の2つの経路を組み合わせたハイブリッド検索を実行します。
- 構造的ナビゲーション(Structural Knowledge Navigation):融合された知識グラフを探索し、キーワードが直接ヒットした要素だけでなく、グラフの繋がりを辿ることで、離れたページに散在している「暗黙的な関係性」を持つ関連要素まで取りこぼさずに抽出します。
- 意味的類似度マッチング(Semantic Similarity Matching):クエリのベクトルを用いて、ベクトルデータベースから意味の近いチャンクやエンティティをピンポイントで検索します。
こうして両方の経路から集められた候補は、グラフ構造上の重要度、ベクトルの類似度、クエリから推測されたモダリティの優先度などを統合したスコアリングによって再ランキングされ、本当に必要なコンテキストだけが厳選されます。
従来の検索システムであれば、検索にヒットした「テキストによる説明」だけをLLMに渡して終わりでした。しかしRAG-Anythingは、検索結果に画像や図表由来のノードが含まれていた場合、元のドキュメントから該当する「生の画像データ」をピンポイントで取得します。**
そして、厳選された構造化されたテキストコンテキストと、取得された生の画像の両方をVLMに同時に入力し、最終的な回答を生成します。これにより、テキストの文脈理解と、画像そのものが持つ生の情報を掛け合わせて回答を生成できます。回答の根拠となる図表が元データに直接ひも付くため、「どの視覚情報に基づいた回答なのか」を追跡しやすくなり、根拠なき出力(ハルシネーション)の混入を検知・抑制しやすい**という利点があります。
3. 精度評価
RAG-Anythingの有効性を検証するため、論文ではマルチモーダルなドキュメントQAのベンチマークである「DocBench」および「MMLongBench」を用いた性能評価が行われています 。比較対象として、ネイティブマルチモーダルLLMへの直接入力(GPT-4o-mini)や、テキスト中心のGraphRAG手法(LightRAG)、画像要素のみをグラフ化する手法(MMGraphRAG)などが選定されました 。
実験の結果、RAG-Anything は各種ベースラインと比較して、特にドキュメントのページ数が多くなる長文コンテキストにおいて良好なパフォーマンスを示す傾向が確認されています 。例えば DocBenchデータセットにおける100ページを超える長大なドキュメントの検証では、DocBench の正答率〔Accuracy, %〕で MMGraphRAG に対して13ポイント以上の精度向上が見られました。また、MMLongBenchにおいても同様の傾向が見られ、情報が複数ページに分散している状況での優位性が示されています 。
さらに、どのコンポーネントが精度向上に寄与しているかを分析するアブレーション研究も行われており、RAG-Anything における性能のコアは、単なるリランカー等の工夫ではなく、デュアルグラフの構築によってドキュメント内の構造や要素間の関係性を保持できている点にあることが示唆されています 。
実際に使ってみた
本フレームワークの挙動を確認するため、RAG-Anything に簡易的なUIを組み合わせ、インデックス構築とQAの検証を行いました。
1. 情報の整理と可視化
検証として、マルチモーダルな技術論文(DeepSeek-OCR 2)の PDF を入力し、RAG-Anything でグラフインデックスを構築しました。グラフインデックスが視覚的に把握できるよう、今回は UI 上でノードを要素ごとに色分けして表示できるように一部改変を加えました。
RAG-Anythingによるグラフ構築例
上の例を見ると、各モダリティが文脈に応じてネットワーク状に密接に結びついており、RAG-AnythingがPDFに含まれるテキスト・画像・表・数式などの要素を抽出し、それらの関係性を適切にグラフ構造へと落とし込んでいることがわかると思います。
2. 根拠を明示した情報抽出とQA
構築したインデックスに対し、実際に図表の理解が必要な質問を投げました。
関連記事
Gemma 4 12B:開発者ガイド
Google が、消費者向けデバイスでの高性能なローカル AI 実行を目的とした高密度マルチモーダルモデル「Gemma 4 12B」を発表し、従来の視覚・音声エンコーダーを不要とする新アーキテクチャを採用した開発者向けのガイドを提供した。
NVIDIA、ドキュメント・音声・動画エージェント向け長文脈マルチモーダルモデル「Nemotron 3 Nano Omni」を発表
NVIDIA は、ドキュメントや音声、動画の分析に特化した新モデル「Nemotron 3 Nano Omni」を発表した。同社はハイブリッドアーキテクチャを採用し、長文脈処理における精度と推論速度を大幅に向上させた。
画像・テキスト・動画を統合!オープンソースフレームワークで全モダリティ知識ベースを実現
通義実験室が、画像・テキスト・動画などの複数モダリティを統合的に処理できるオープンソースフレームワーク「VimRAG」を発表した。企業の多様な知識資産を一元的に扱い、大規模言語モデルの回答精度向上を目指す。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み