2種類のS3バケットをナレッジDBとして活用する
AI Shift Tech Blog は、Amazon S3 の新機能である「S3 Vectors」と「S3 Tables」を組み合わせることで、高コストなマネージドナレッジDBに依存せず、低価格でスケーラブルなチャットシステムを構築する具体的な手法と構成を実証した。
キーポイント
S3 ベースのハイブリッドナレッジアーキテクチャ
非構造化データ(PDF)は S3 Vectors でベクトル検索可能にし、構造化データ(CSV)は S3 Tables で Apache Iceberg 形式として保存・クエリする、コスト効率の高い 2 層構成を提案している。
S3 Vectors と S3 Tables の最新 GA 活用
2025 年 12 月に東京リージョンで一般提供された両サービスを活用し、ベクトルインデックスの自動最適化や Athena/Redshift 連携などの新機能を即座に実装可能であることを示している。
Bedrock Knowledge Bases とのネイティブ統合
生成したベクトルデータを直接 Amazon Bedrock Knowledge Bases に接続し、外部クローラー不要で S3 内のデータのみを対象とした RAG システムを構築する実装フローを解説している。
具体的なコスト削減と運用効率化
汎用バケットやディレクトリバケットではなく、用途特化型の S3 Vectors と Tables を採用することで、データ増加に伴うコスト増を抑えつつ、低レイテンシ検索を実現する戦略を提示している。
S3 ベクトルインデックスと Knowledge Bases の連携制限
Amazon Bedrock の Knowledge Bases では S3 に保持されたデータのみが対象であり、Web クローリングは非対応。また、メタデータに元のテキストを含めないと検索結果でテキストを取得できないため必須である。
S3 Tables を介した構造化データの Athena 活用
Iceberg フォーマットによる S3 テーブルバケットとネームスペースを作成し、Athena で SQL クエリを実行することで財務データなどの構造化データをナレッジとして扱える。
LLM による自動プランニングで検索経路を分岐
ユーザーのクエリに対して LLM が「SQL 検索(S3 Tables)」か「ベクトル検索(S3 Vectors)」かを判断し、それぞれの処理フローを実行して回答を生成するシンプルなアーキテクチャを採用している。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI アプリケーション開発におけるナレッジ検索のインフラ選定において、高価な専用マネージドサービスへの依存から、AWS S3 の新機能を駆使したカスタムアーキテクチャへの移行を示唆する重要な指針となる。特にコスト最適化が求められる実運用環境において、S3 Vectors と Tables を組み合わせたアプローチは、開発者にとって即座に適用可能な現実的な解決策として大きな影響を与えるだろう。
編集コメント
S3 の新機能である Vectors と Tables を組み合わせた具体的な実装例は、コスト意識の高い開発者にとって非常に参考になる内容です。特に Bedrock Knowledge Bases との連携フローが明確に示されており、RAG システム構築の次のステップとして注目すべき記事と言えます。
2種類のS3バケットをナレッジDBとして活用する
こんにちは、AIチームの干飯(@hosimesi11_)です。 この記事はAI Shift Advent Calendar 17日目の記事になります。今回は、ナレッジDBとして使用して2種類のS3バケットを使用し、高コスパなチャットシステムを作成しました。本記事で扱ったコードはこちらで公開しています。
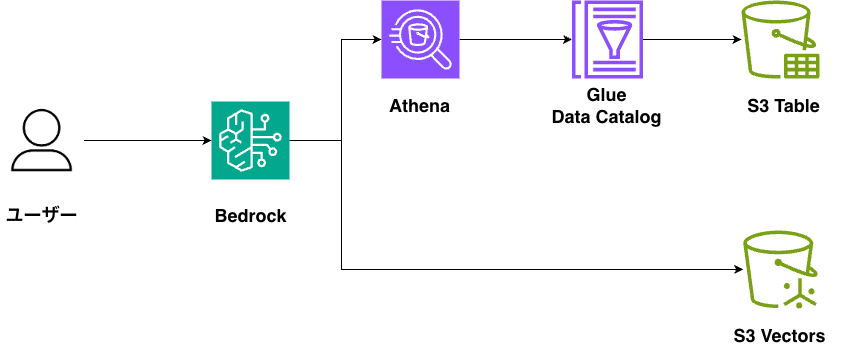
生成AIのプロダクトへの組み込みが増えるにつれて、検索システムの重要性も高まっています。さまざまなマネージドなナレッジDBが増え、ユーザーがインフラを意識せずに運用できるようにもなってきています。しかし、一般的に本番運用を始めるとナレッジDB内のデータは増え続けるため、コストが大きな課題になります。今回は、最近GAされたばかりのS3 VectorsとS3 Tablesを使って、比較的高コスパなナレッジ検索システムを作りたいと思います。 本日作るシステムの構成図は以下の通りになります。簡易的にするため、UIは作らず標準入力でユーザーからのクエリを受け付けます。
現在、S3バケットには以下の4種類が存在しています。
汎用バケット あらゆるユースケースに対応した一番スタンダードなバケットです。あらゆるデータ形式のファイルを保存することができ、フラットなストレージ構造を持っています。
ディレクトリバケット 低レイテンシーかつ、データレジデンシーを必要とするユースケース向けに最適化されています。汎用バケットとは違い、オブジェクトを階層的に整理します。
テーブルバケット 構造化データ用のバケットであり、表形式データの保存に適しています。分析や機械学習のユースケースに最適化され、表形式データをApache Iceberg 形式で保存します。
ベクトルバケット 一番最新のバケットタイプで、ベクトル検索のユースケースに最適化されています。埋め込みモデルによって作成されたベクトルデータをベクトルインデックスを効率的に保存し、検索できるようにします。
この中でも今回は特にテーブルバケットとベクトルバケットを使いたいと思います。
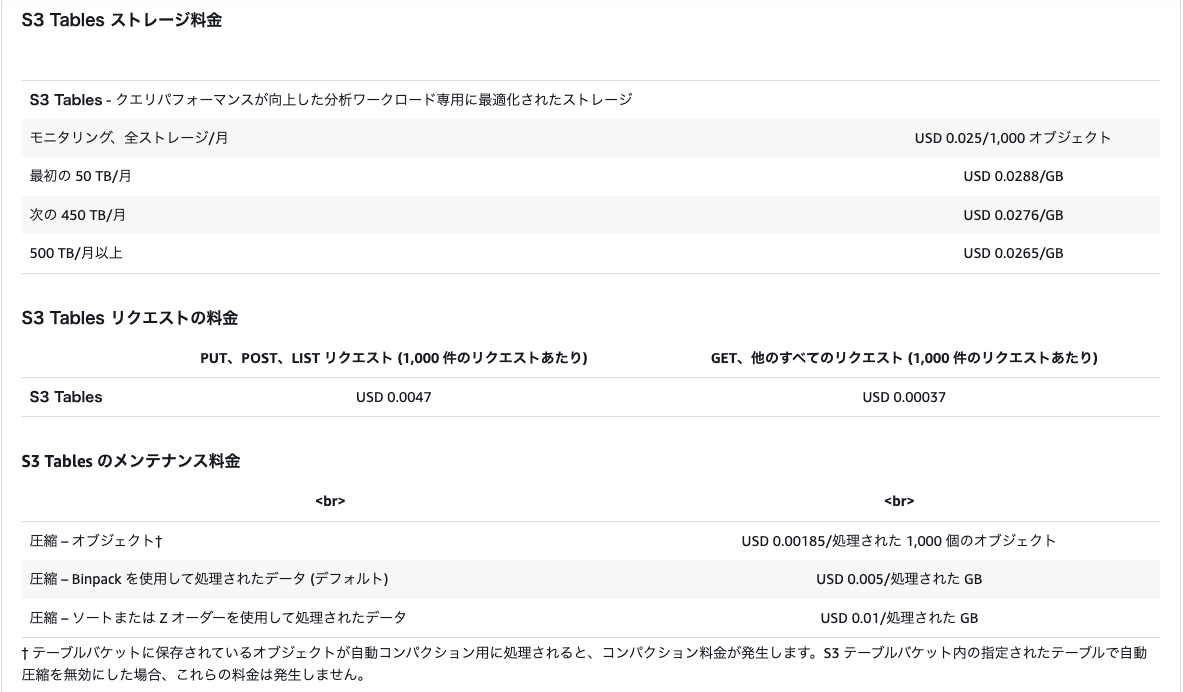
テーブルバケットは、東京リージョンでは2025年1月にGAされました。構造化データをApache Iceberg形式でS3上に保存し、Amazon Athena、Amazon Redshift、Apache Spark などとネイティブ統合されているため、一般的なクエリエンジンを使用してクエリを実行できます。データ増加に対して自動でのテーブル最適化やスナップショットなどを備えており、Iceberg形式データに対する分析はS3 Tablesで完結が可能になります。 2025年12月現在の東京リージョンの料金体系は以下の通りです。
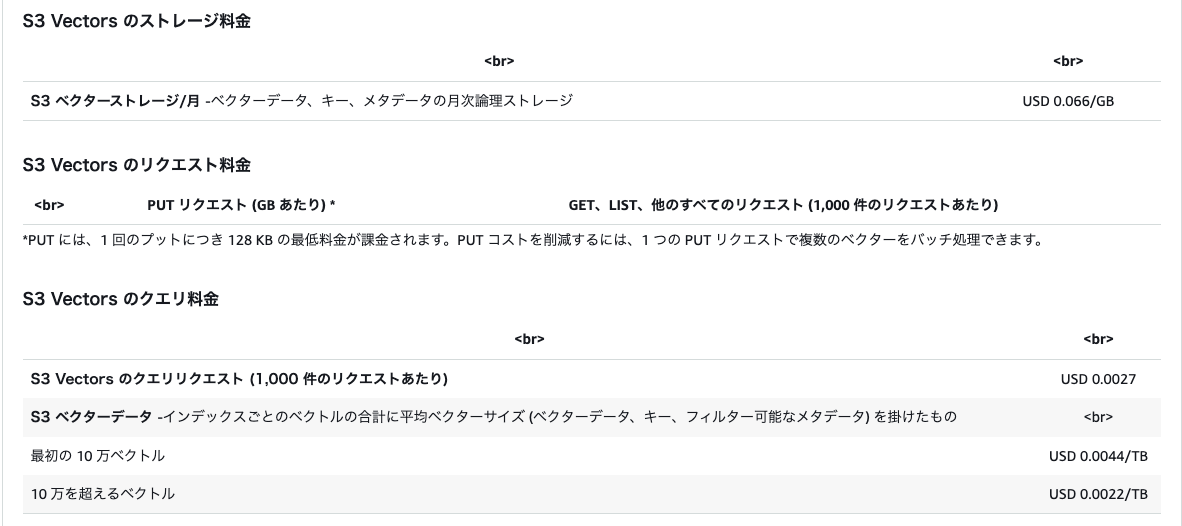
S3 Vectorsは2025年7月15日にベータリリースされ、つい先日の2025年12月15日にGAされました。埋め込みモデルにより作成されたベクトルをベクトルインデックス内に整理して検索ができるようになります。現在は距離関数として、コサイン類似度とユークリッド距離が使うことができます。S3 Tablesと同様にデータ増に対しても自動的に最適化も行われます。また、Amazon SageMaker Unified Studioや、Amazon Bedrock Knowledge Bases ともネイティブに統合されており、それらからの検索も可能になります。また、Amazon OpenSearch Serviceともネイティブ統合されているため、低レイテンシが求められる検索はAmazon OpenSearch Serviceに、コールドデータはAmazon S3 Vectorsに保存するといった用途にも使うことができます。 2025年12月現在の東京リージョンの料金体系は以下の通りです。
実際に2つのS3バケットをナレッジDBとして使用するための前準備を行います。
uvを使用して環境を構築します。AWSのリソースを操作するため、boto3も追加します。
また、データ処理などに必要になるライブラリ群もインストールしておきます。
uv add pypdf pydantic ruff ty python-dotenv
今回、非構造化データとして、サイバーエージェントが公開しているAI/Data Technology MapのPDFを使用します。こちらは各プロダクトのAI/Data領域の技術を紹介する資料で、面白いのでぜひご覧ください。構造化データとしては、直近のサイバーエージェントの売り上げデータをCSVファイルで用意します。
非構造化データの元となるPDFファイルを保存するために、まずS3の汎用バケットを用意します。
aws s3 mb s3://ais-advent-calendar-2025-standard --region ap-northeast-1
次に、ダウンロードしておいたPDFファイルをアップロードします。
aws s3 cp AIDataTechnologyMap.pdf s3://ais-advent-calendar-2025-standard/
続いて、ベクトルデータを保存するためのベクトルバケットを作成します。
aws s3vectors create-vector-bucket --vector-bucket-name ais-advent-calendar-2025-vector
その後、インデックスを作成していきます。インデックス作成時には、ベクトルの次元数やデータタイプ、距離関数を設定します。ここでの設定値は、使用する埋め込みモデルによって異なるため、利用するモデルに合わせて設定してください。今回はAmazon BedrockのTitan Text Embeddings V2を使用するため、ベクトルの次元数は1024に設定します。
aws s3vectors create-index --vector-bucket-name ais-advent-calendar-2025-vector --index-name ais-advent-calendar-2025-vector-index --data-type float32 --dimension 1024 --distance-metric cosine
今回は、Bedrockでベクトルを生成したものを直接S3 Vectorsに入れていきます。PDFファイルをベクトル化する手法は様々ありますが、今回はpypdfを使って以下のステップで簡易的に行います。詳細は実装を参照ください。
PDFファイルからテキストの抽出
Embeddingモデルでのベクトル化
ここで作成したベクトルインデックスをAmazon BedrockのKnowledge Basesと統合し、ベクトルデータベースとして扱う方法もあります。2025年12月現在、Knowledge Bases経由で扱うにはS3に保持されているデータに限られ、Webのクローリングデータは非対応です。 注意点として、S3 Vectorsのメタデータに元のテキストを入れないと、検索結果としてテキストを取得できないため、必ず含める必要があります。
次に、S3 テーブルバケットを作成します。
aws s3tables create-table-bucket --name ais-advent-calendar-2025-table
続いて、Amazon Athena経由でアクセスするためのネームスペースを作ります。ネームスペースにはハイフンが使えない点に注意が必要です。
aws s3tables create-namespace --table-bucket-arn "your-arn-name" --namespace ais_advent_calendar_2025_table_namespace
次に、上記のCSVデータに対応するテーブルスキーマを定義します。
aws s3tables create-table --table-bucket-arn "<your-arn-name>" --namespace ais_advent_calendar_2025_table_namespace --name ca_sales_table --format 'ICEBERG' --metadata '{"iceberg": {"schema": {"fields": [{"name": "period", "type": "string", "required": true},{"name": "net_sales", "type": "int", "required": false},{"name": "operating_income", "type": "int", "required": false},{"name": "non_operating_income", "type": "int", "required": false},{"name": "non_operating_expenses", "type": "int", "required": false},{"name": "ordinary_income", "type": "int", "required": false},{"name": "extraordinary_gains", "type": "int", "required": false},{"name": "extraordinary_losses", "type": "int", "required": false},{"name": "income_before_taxes", "type": "int", "required": false},{"name": "net_income", "type": "int", "required": false},{"name": "net_income_non_controlling_interests", "type": "int", "required": false},{"name": "net_income_attributable_to_owners", "type": "int", "required": false}]}}}'
Amazon Athenaに初めてクエリを投げる際は、クエリ結果を出力するS3バケットを設定する必要があるため、S3バケットを作成し、設定を行います。
aws s3 mb s3://ais-advent-calendar-2025-athena-ouput --region ap-northeast-1
aws athena update-work-group --work-group primary --configuration-updates '{"ResultConfigurationUpdates": {"OutputLocation": "s3://<your-result-bucket-name>/athena-query-results/","RemoveAclConfiguration": false,"RemoveEncryptionConfiguration": false}}'
ここまでの準備が完了したら、Athena経由でデータを追加します。
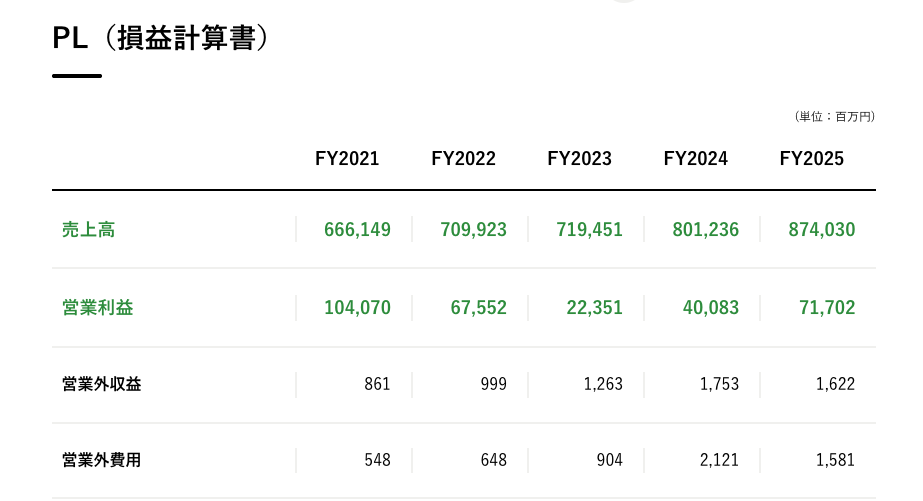
INSERT INTO ca_sales_table VALUES -- FY2021 ('FY2021', 666149, 104070, 861, 548, 104382, 2201, 6173, 100410, 66359, 25117, 41242), -- FY2022 ('FY2022', 709923, 67552, 999, 648, 67902, 1633, 8299, 61236, 38096, 15194, 22901), -- FY2023 ('FY2023', 719451, 22351, 1263, 904, 22710, 1470, 3854, 20326, 9151, 5611, 3540), -- FY2024 ('FY2024', 801236, 40083, 1753, 2121, 39715, 313, 8815, 31213, 20376, 4398, 15977), -- FY2025 ('FY2025', 874030, 71702, 1622, 1581, 71743, 2319, 7835, 66227, 41964, 10296, 31667);
今回は手動でデータを追加しましたが、本番運用においてはAWS Glue Jobなどを使用して自動でデータ追加を行うのが一般的です。
先ほど作成した2つのS3バケットに格納されたナレッジに対して検索ができるアプリケーションを実装していきます。
全体の流れとしては以下のような処理を実装します。実装は割とシンプルになっています。
LLMで「SQL検索(S3 Tables)か / ベクトル検索(S3 Vectors)か」をプランニングする
各処理を行う S3 Tablesの場合:AthenaでSQL実行 → 結果をコンテキスト化 → LLMで回答生成
S3 Vectorsの場合:埋め込み生成 → 類似検索 → 結果をコンテキスト化 → LLMで回答生成
各ステップの中身を要約しながら見ていきます。詳細はGitHubのコードを確認してください。 1. ユーザー入力を受け取る 標準入力からクエリを受け付け、plan_query_with_sql
def main() try: while True: try: # ユーザーからの入力を受け取る query = input("\nquery> ").strip() except EOFError: # EOF (Ctrl+D / Ctrl+Z) での終了処理 logger.info("終了") return if not query: continue # ユーザーからの質問(query)をプランニング関数に渡す plan = plan_query_with_sql( query=query, bedrock_runtime_client=bedrock_runtime_client, model_id=BEDROCK_CHAT_MODEL_ID, ) # ... (以降、プランに基づいてAthenaまたはVector検索を実行) ... except KeyboardInterrupt: # Ctrl+C での終了処理 logger.info("終了") return
- LLMで「SQL検索(S3 Tables)か / ベクトル検索(S3 Vectors)か」をプランニングする クエリ内容に基づいて、S3 TablesかS3 Vectorsかを選択し、S3 Tablesの場合は実行するSQLを生成します。
def plan_query_with_sql( query: str, bedrock_runtime_client, model_id: str, ) -> QueryPlan: # 1. LLMに渡すスキーマとルールの設定(system_textを構築) # 2. Bedrock LLMの呼び出し resp = bedrock_runtime_client.converse( modelId=model_id, system=[{"text": system_text}], messages=[{"role": "user", "content": [{"text": f"ユーザーの質問: {query}"}]}], ) # 3. LLMの応答からJSONを抽出 raw = resp.get("output", {}).get("message", {}).get("content", [])[0]["text"] json_text = _extract_first_json_object(raw) data = json.loads(json_text) # 4. データソースとSQLの抽出 source = data.get("source", "s3vectors") sql = data.get("sql", "") reason = data.get("reason", "") # 5. プランの確定 if source == "s3table" and _is_safe_sql(sql): # ユーザーが指定した期間をSQLに補正・反映 periods = _period_candidates(query) if periods: p = periods[0] # SQLの後処理 # sql = re.sub(...) return QueryPlan(source="s3table", sql=sql, reason=reason) # SQLが無効 or またはs3vectorsが指定された場合 return QueryPlan(source="s3vectors", sql="", reason=reason)
3-1. S3 Tablesの場合:AthenaでSQL実行 → 結果をコンテキスト化 → LLMで回答生成 LLMがS3 Tablesを選択してSQLを生成した場合はAthena経由でSQLを実行します。取得した結果をコンテキストにつめて、LLMによって回答を生成します。
def main() ... if plan.source == "s3table" and plan.sql: ... try: rows = run_athena_query(sql=plan.sql, athena_client=athena_client) except Exception as e: use_table = False athena_error = str(e) logger.exception(f"athena query failed: {e}") logger.info("fallback to s3vectors (athena failed)") rows = [] if plan.source == "s3table": ... context = "\n".join(lines) ... answer = generate_answer_from_context( query=query, context=context, bedrock_runtime_client=bedrock_runtime_client, model_id=BEDROCK_CHAT_MODEL_ID, citation_hint="(table, period) もしくは (table, columns)", ) print("\nanswer>\n" +
原文を表示
2種類のS3バケットをナレッジDBとして活用する
こんにちは、AIチームの干飯(@hosimesi11_)です。 この記事はAI Shift Advent Calendar 17日目の記事になります。今回は、ナレッジDBとして使用して2種類のS3バケットを使用し、高コスパなチャットシステムを作成しました。本記事で扱ったコードはこちらで公開しています。
生成AIのプロダクトへの組み込みが増えるにつれて、検索システムの重要性も高まっています。さまざまなマネージドなナレッジDBが増え、ユーザーがインフラを意識せずに運用できるようにもなってきています。しかし、一般的に本番運用を始めるとナレッジDB内のデータは増え続けるため、コストが大きな課題になります。今回は、最近GAされたばかりのS3 VectorsとS3 Tablesを使って、比較的高コスパなナレッジ検索システムを作りたいと思います。 本日作るシステムの構成図は以下の通りになります。簡易的にするため、UIは作らず標準入力でユーザーからのクエリを受け付けます。
現在、S3バケットには以下の4種類が存在しています。
汎用バケット あらゆるユースケースに対応した一番スタンダードなバケットです。あらゆるデータ形式のファイルを保存することができ、フラットなストレージ構造を持っています。
ディレクトリバケット 低レイテンシーかつ、データレジデンシーを必要とするユースケース向けに最適化されています。汎用バケットとは違い、オブジェクトを階層的に整理します。
テーブルバケット 構造化データ用のバケットであり、表形式データの保存に適しています。分析や機械学習のユースケースに最適化され、表形式データをApache Iceberg 形式で保存します。
ベクトルバケット 一番最新のバケットタイプで、ベクトル検索のユースケースに最適化されています。埋め込みモデルによって作成されたベクトルデータをベクトルインデックスを効率的に保存し、検索できるようにします。
この中でも今回は特にテーブルバケットとベクトルバケットを使いたいと思います。
テーブルバケットは、東京リージョンでは2025年1月にGAされました。構造化データをApache Iceberg形式でS3上に保存し、Amazon Athena、Amazon Redshift、Apache Spark などとネイティブ統合されているため、一般的なクエリエンジンを使用してクエリを実行できます。データ増加に対して自動でのテーブル最適化やスナップショットなどを備えており、Iceberg形式データに対する分析はS3 Tablesで完結が可能になります。 2025年12月現在の東京リージョンの料金体系は以下の通りです。
S3 Vectorsは2025年7月15日にベータリリースされ、つい先日の2025年12月15日にGAされました。埋め込みモデルにより作成されたベクトルをベクトルインデックス内に整理して検索ができるようになります。現在は距離関数として、コサイン類似度とユークリッド距離が使うことができます。S3 Tablesと同様にデータ増に対しても自動的に最適化も行われます。また、Amazon SageMaker Unified Studioや、Amazon Bedrock Knowledge Bases ともネイティブに統合されており、それらからの検索も可能になります。また、Amazon OpenSearch Serviceともネイティブ統合されているため、低レイテンシが求められる検索はAmazon OpenSearch Serviceに、コールドデータはAmazon S3 Vectorsに保存するといった用途にも使うことができます。 2025年12月現在の東京リージョンの料金体系は以下の通りです。
実際に2つのS3バケットをナレッジDBとして使用するための前準備を行います。
uvを使用して環境を構築します。AWSのリソースを操作するため、boto3も追加します。
また、データ処理などに必要になるライブラリ群もインストールしておきます。
uv add pypdf pydantic ruff ty python-dotenv
今回、非構造化データとして、サイバーエージェントが公開しているAI/Data Technology MapのPDFを使用します。こちらは各プロダクトのAI/Data領域の技術を紹介する資料で、面白いのでぜひご覧ください。構造化データとしては、直近のサイバーエージェントの売り上げデータをCSVファイルで用意します。
非構造化データの元となるPDFファイルを保存するために、まずS3の汎用バケットを用意します。
aws s3 mb s3://ais-advent-calendar-2025-standard --region ap-northeast-1
次に、ダウンロードしておいたPDFファイルをアップロードします。
aws s3 cp AIDataTechnologyMap.pdf s3://ais-advent-calendar-2025-standard/
続いて、ベクトルデータを保存するためのベクトルバケットを作成します。
aws s3vectors create-vector-bucket --vector-bucket-name ais-advent-calendar-2025-vector
その後、インデックスを作成していきます。インデックス作成時には、ベクトルの次元数やデータタイプ、距離関数を設定します。ここでの設定値は、使用する埋め込みモデルによって異なるため、利用するモデルに合わせて設定してください。今回はAmazon BedrockのTitan Text Embeddings V2を使用するため、ベクトルの次元数は1024に設定します。
aws s3vectors create-index --vector-bucket-name ais-advent-calendar-2025-vector --index-name ais-advent-calendar-2025-vector-index --data-type float32 --dimension 1024 --distance-metric cosine
今回は、Bedrockでベクトルを生成したものを直接S3 Vectorsに入れていきます。PDFファイルをベクトル化する手法は様々ありますが、今回はpypdfを使って以下のステップで簡易的に行います。詳細は実装を参照ください。
PDFファイルからテキストの抽出
Embeddingモデルでのベクトル化
ここで作成したベクトルインデックスをAmazon BedrockのKnowledge Basesと統合し、ベクトルデータベースとして扱う方法もあります。2025年12月現在、Knowledge Bases経由で扱うにはS3に保持されているデータに限られ、Webのクローリングデータは非対応です。 注意点として、S3 Vectorsのメタデータに元のテキストを入れないと、検索結果としてテキストを取得できないため、必ず含める必要があります。
次に、S3 テーブルバケットを作成します。
aws s3tables create-table-bucket --name ais-advent-calendar-2025-table
続いて、Amazon Athena経由でアクセスするためのネームスペースを作ります。ネームスペースにはハイフンが使えない点に注意が必要です。
aws s3tables create-namespace --table-bucket-arn "your-arn-name" --namespace ais_advent_calendar_2025_table_namespace
次に、上記のCSVデータに対応するテーブルスキーマを定義します。
aws s3tables create-table --table-bucket-arn "<your-arn-name>" --namespace ais_advent_calendar_2025_table_namespace --name ca_sales_table --format 'ICEBERG' --metadata '{"iceberg": {"schema": {"fields": [{"name": "period", "type": "string", "required": true},{"name": "net_sales", "type": "int", "required": false},{"name": "operating_income", "type": "int", "required": false},{"name": "non_operating_income", "type": "int", "required": false},{"name": "non_operating_expenses", "type": "int", "required": false},{"name": "ordinary_income", "type": "int", "required": false},{"name": "extraordinary_gains", "type": "int", "required": false},{"name": "extraordinary_losses", "type": "int", "required": false},{"name": "income_before_taxes", "type": "int", "required": false},{"name": "net_income", "type": "int", "required": false},{"name": "net_income_non_controlling_interests", "type": "int", "required": false},{"name": "net_income_attributable_to_owners", "type": "int", "required": false}]}}}'
Amazon Athenaに初めてクエリを投げる際は、クエリ結果を出力するS3バケットを設定する必要があるため、S3バケットを作成し、設定を行います。
aws s3 mb s3://ais-advent-calendar-2025-athena-ouput --region ap-northeast-1
aws athena update-work-group --work-group primary --configuration-updates '{"ResultConfigurationUpdates": {"OutputLocation": "s3://<your-result-bucket-name>/athena-query-results/","RemoveAclConfiguration": false,"RemoveEncryptionConfiguration": false}}'
ここまでの準備が完了したら、Athena経由でデータを追加します。
INSERT INTO ca_sales_table VALUES -- FY2021 ('FY2021', 666149, 104070, 861, 548, 104382, 2201, 6173, 100410, 66359, 25117, 41242), -- FY2022 ('FY2022', 709923, 67552, 999, 648, 67902, 1633, 8299, 61236, 38096, 15194, 22901), -- FY2023 ('FY2023', 719451, 22351, 1263, 904, 22710, 1470, 3854, 20326, 9151, 5611, 3540), -- FY2024 ('FY2024', 801236, 40083, 1753, 2121, 39715, 313, 8815, 31213, 20376, 4398, 15977), -- FY2025 ('FY2025', 874030, 71702, 1622, 1581, 71743, 2319, 7835, 66227, 41964, 10296, 31667);
今回は手動でデータを追加しましたが、本番運用においてはAWS Glue Jobなどを使用して自動でデータ追加を行うのが一般的です。
先ほど作成した2つのS3バケットに格納されたナレッジに対して検索ができるアプリケーションを実装していきます。
全体の流れとしては以下のような処理を実装します。実装は割とシンプルになっています。
LLMで「SQL検索(S3 Tables)か / ベクトル検索(S3 Vectors)か」をプランニングする
各処理を行う S3 Tablesの場合:AthenaでSQL実行 → 結果をコンテキスト化 → LLMで回答生成
S3 Vectorsの場合:埋め込み生成 → 類似検索 → 結果をコンテキスト化 → LLMで回答生成
各ステップの中身を要約しながら見ていきます。詳細はGitHubのコードを確認してください。 1. ユーザー入力を受け取る 標準入力からクエリを受け付け、plan_query_with_sql
def main() try: while True: try: # ユーザーからの入力を受け取る query = input("\nquery> ").strip() except EOFError: # EOF (Ctrl+D / Ctrl+Z) での終了処理 logger.info("終了") return if not query: continue # ユーザーからの質問(query)をプランニング関数に渡す plan = plan_query_with_sql( query=query, bedrock_runtime_client=bedrock_runtime_client, model_id=BEDROCK_CHAT_MODEL_ID, ) # ... (以降、プランに基づいてAthenaまたはVector検索を実行) ... except KeyboardInterrupt: # Ctrl+C での終了処理 logger.info("終了") return
- LLMで「SQL検索(S3 Tables)か / ベクトル検索(S3 Vectors)か」をプランニングする クエリ内容に基づいて、S3 TablesかS3 Vectorsかを選択し、S3 Tablesの場合は実行するSQLを生成します。
def plan_query_with_sql( query: str, bedrock_runtime_client, model_id: str, ) -> QueryPlan: # 1. LLMに渡すスキーマとルールの設定(system_textを構築) # 2. Bedrock LLMの呼び出し resp = bedrock_runtime_client.converse( modelId=model_id, system=[{"text": system_text}], messages=[{"role": "user", "content": [{"text": f"ユーザーの質問: {query}"}]}], ) # 3. LLMの応答からJSONを抽出 raw = resp.get("output", {}).get("message", {}).get("content", [])[0]["text"] json_text = _extract_first_json_object(raw) data = json.loads(json_text) # 4. データソースとSQLの抽出 source = data.get("source", "s3vectors") sql = data.get("sql", "") reason = data.get("reason", "") # 5. プランの確定 if source == "s3table" and _is_safe_sql(sql): # ユーザーが指定した期間をSQLに補正・反映 periods = _period_candidates(query) if periods: p = periods[0] # SQLの後処理 # sql = re.sub(...) return QueryPlan(source="s3table", sql=sql, reason=reason) # SQLが無効 or またはs3vectorsが指定された場合 return QueryPlan(source="s3vectors", sql="", reason=reason)
3-1. S3 Tablesの場合:AthenaでSQL実行 → 結果をコンテキスト化 → LLMで回答生成 LLMがS3 Tablesを選択してSQLを生成した場合はAthena経由でSQLを実行します。取得した結果をコンテキストにつめて、LLMによって回答を生成します。
def main() ... if plan.source == "s3table" and plan.sql: ... try: rows = run_athena_query(sql=plan.sql, athena_client=athena_client) except Exception as e: use_table = False athena_error = str(e) logger.exception(f"athena query failed: {e}") logger.info("fallback to s3vectors (athena failed)") rows = [] if plan.source == "s3table": ... context = "\n".join(lines) ... answer = generate_answer_from_context( query=query, context=context, bedrock_runtime_client=bedrock_runtime_client, model_id=BEDROCK_CHAT_MODEL_ID, citation_hint="(table, period) もしくは (table, columns)", ) print("\nanswer>\n" + answer + "\n") continue
3-2. S3 Vectorsの場合:埋め込み生成 → 類似検索 → 結果をコンテキスト化 → LLMで回答生成 S3 Vectorsが選択された場合は、埋め込みモデルでベクトルデータを生成し、S3 Vectorsに対して検索を行います。取得した結果をコンテキストにつめて、LLMによって回答を生成します。
def main() ... hits = search_vector_index( query=query, bedrock_runtime_client=bedrock_runtime_client, s3vectors_client=s3vectors_client, ) ... answer = generate_answer( query=query, hits=hits, bedrock_runtime_client=bedrock_runtime_client, model_id=BEDROCK_CHAT_MODEL_ID, ) print("\nanswer>\n" + answer + "\n")
作った検索システムを使用してみます。NL2SQL(自然言語からSQL生成)の部分は、簡易的な実装のため、本番運用時には改善の余地がありますが、意図した通りに検索できていそうです。
uv run src/main.py inference
【実行例 1:ベクトル検索(S3 Vectors)】
query> voice botの技術タグは? 2025-12-14 01:01:44,447 INFO __main__: route=s3vectors reason=voice botの技術タグに関する一般的なナレッジ検索であり、S3ベクター検索が適切です。数値集計や期間による絞り込みは不要です。 2025-12-14 01:01:45,101 INFO __main__: hits: distance=0.505279 AIDataTechnologyMap.pdf_50-51 source_file=AIDataTechnologyMap.pdf page=50 distance=0.658780 AIDataTechnologyMap.pdf_82-83 source_file=AIDataTechnologyMap.pdf page=82 distance=0.668686 AIDataTechnologyMap.pdf_126-127 source_file=AIDataTechnologyMap.pdf page=126 distance=0.677485 AIDataTechnologyMap.pdf_48-49 source_file=AIDataTechnologyMap.pdf page=48 distance=0.679986 AIDataTechnologyMap.pdf_78-79 source_file=AIDataTechnologyMap.pdf page=78 answer># Voice botの技術タグ Voice botの技術タグは以下の通りです: 自然言語処理、音声認識 (source_file=AIDataTechnologyMap.pdf, page=50)
【実行例 2:SQL検索(S3 Tables)】
query> 2025の売り上げは? 2025-12-14 01:01:56,438 INFO __main__: route=s3table catalog=s3tablescatalog/ais-advent-calendar-2025-table db=ais_advent_calendar_2025_table_namespace table=ca_sales_table 2025-12-14 01:01:56,438 INFO __main__: sql: SELECT period, net_sales FROM ais_advent_calendar_2025_table_namespace.ca_sales_table WHERE period = 'FY2025' LIMIT 200 2025-12-14 01:01:58,508 INFO __main__: athena rows: 1 answer> 2025年の売上は 874,030百万円 です。 (参照: ca_sales_table, period=FY2025のnet_sales)
最後に、このシステムのストレージコストを試算します。Embeddingや回答生成の部分はどの場合でもかかるので、ストレージコストのみを計算してみます。例として、構造化データ100GBと非構造化データ(ベクトルデータ化済み)1TBがあり、月間10,000リクエストがあると仮定します。※ 1ドルを160円として計算します。
2種類のS3バケットを使用した場合
料金計算式(ストレージ + リクエスト)
160円 * (0.028$ * 100GB + 0.000378$ * 10 (千Req))
448円 + 最適化費用 (概算)
160円 * (0.066$ * 1024GB + 0.0027$ * 10 (千Req))
一般的なツールの場合(最小構成)
料金計算式(ストレージ + リクエスト or コンピュート)
160 円 * (0.442$ * 100GB)
160円 * (0.026$ * 1024GB +0.334$ * 1 OCU * 730h)
2種類のS3バケットを使用した場合、ストレージ料金とクエリ料金のみですが、諸々入れても1万円前後あれば運用できそうです。一般的なツールの最小構成と比較しても安いのが分かります。もちろんAthenaやGlue、Embeddingや回答生成にも料金はかかりますが、適切なパーティショニングなどをしてスキャン量を減らすことができれば、社内利用などのレイテンシの許容が大きいワークロードには有効な選択肢になると思います。
AI Shiftではエンジニアの採用に力を入れています! 少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか? (オンライン・19時以降の面談も可能です!)
【面談フォームはこちら】 https://hrmos.co/pages/cyberagent-group/jobs/1826557091831955459
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/Welcome.html#BasicsBucket https://dev.classmethod.jp/articles/schema-definition-s3tables-createtable-with-awscli/

関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み