Anthropic 責任あるスケーリングポリシー v3:詳細の掘り下げ
Anthropicが安全ポリシー「Responsible Scaling Policy v3.0」を改定し、柔軟性と信頼を重視する方針を示したが、アナリストはこれを拘束力のある約束ではなく単なる行動計画として評価し、実質的なリスク管理の限界を指摘している。
キーポイント
RSP v3.0の設計原則:柔軟性と信頼
新ポリシーは厳格な拘束力よりも「強い議論」と柔軟性を重視しており、Anthropicがリスクを認識し安全を優先する限り、実際の行動は同社の判断に委ねられる。
具体的なコミットメントの再定義
重要な拘束事項は、定期的なリスクレポートの作成、フロンティアセキュリティロードマップの維持、および最高経営責任者や取締役会による進歩への拒否権(ベトポイント)の確立に限定される。
リスクレポートとASL-3対策の継続
3〜6ヶ月ごとの包括的なリスクレポートにより、モデルが絶対的リスクをもたらすかどうかに加えて、業界全体の文脈での相対的なマージナルリスクも開示する。また、ASL-3の緩和策は全モデルに適用され、内部脅威対策としてCEOレベルでのセキュリティ強化が推奨される。
アナリストによる批判的評価
記事の著者は、このポリシーが「強力なAI」、特に自動化された研究開発(R&D)領域における自身のリスク理解と一致していないとし、これは約束ではなく行動計画であるため、読者はこれに基づいて計画を立てる必要があると警告する。
自主規制のコミットメント欠如と「安全」の条件付き適用
Anthropicは他社が安全対策を講じない場合でも自社の開発ペースを追う方針を明文化し、リードしている場合にのみ安全基準を満たすという条件付きコミットメントに留まっている。
事前デプロイメント審査の欠如と物理的停止能力の喪失
モデルリリース前の審査ゲートが存在せず、物理的に開発を停止・制限する体制も整備されていないため、事実上安全規制の実行可能性が失われている。
ASLレベルの廃止と安全性評価の主観化
従来のASL(AI Safety Level)レベルが廃止され、安全性に関する分析と論証に委ねられることにより、評価基準の曖昧さと不確実性が生じている。
影響分析・編集コメントを表示
影響分析
このニュースは、AI開発企業における安全ガバナンスの「自主規制」モデルが、厳格な法的拘束力から「信頼と透明性」へシフトしていることを示唆しています。しかし、アナリストの指摘通り、このアプローチは実質的なリスク抑制効果に疑問を残すものであり、投資家や規制当局にとっては、企業の内部統制への依存度が高まるリスクとして捉える必要があります。業界全体としては、安全基準の定義が「結果」から「プロセスと開示」へ移行しつつある兆候と言えます。
編集コメント
Anthropicの新しい安全ポリシーは、厳格な制限よりも柔軟なプロセス重視を謳っていますが、アナリストはこれが実質的なリスク管理として不十分だと指摘しています。規制当局や投資家は、この「信頼」ベースの枠組みが実際にどのような安全基準を満たすのかを注視する必要があります。
先週の投稿では、Anthropic が RSP のバージョン 2.2 から 3.0 へ移行することの影響について取り上げました。これには、多くの人が重要な決定を下す際に依拠していた約束が破られたという点も含まれます。
今回の投稿では、新しい RSP v3.0 を新たな文書として扱い、それを評価します。
まず、RSP v3.0 が全体としてどのように機能するかを概観します。その後、ロードマップとリスクレポートの詳細に踏み込んでいきます。
RSP v3.0 の仕組みについて
通常であれば、私は新しい RSP の正確な記述内容により注意を払うはずです。
この場合でも、RSP が重要でないわけではありません。確かに、Anthropic が何を行うかに対して、RSP はある程度の影響力を持つと考えます。同様に、ロードマップやその結果として生じるリスクレポートも影響を与えるでしょう。
しかし、根本的な設計原則は柔軟性と「強力な論拠」であり、彼らはいつでも内容を変更できます。これはつまり、中心となる原則が信頼に依存していることを意味します。
私はこの内容を、「私たちが懸念し、実行する計画がある事項」として読み取っています。実務上、これは主に彼らが正しいと信じる行動をとることに帰着し、Anthropic がモデルの安全性を重視しており、関与するリスクを理解している限り、このマップ上にその行動を重要な拘束力を持つものとして機能させる要素は特に見当たりません。
実際に最も重要と思われるソフトな「コミットメント」として挙げられるのは、定期的な新リスクレポートの作成、フロンティア・セーフティ・ロードマップ(Frontier Safety Roadmap)の維持、および主要な能力向上に対する CSO(最高セキュリティ責任者)、CEO、取締役会、LTBT(上級経営チーム)との間で拒否権ポイント(veto points)を設けることです。
私は、ここに示されたコミットメントを、「強力な AI」、特に自動研究開発(R&D)の領域におけるリスクに関する私の理解を反映するものとして読み取ることはありません。
これはコミットメントのセットではなく、行動計画です。これに基づいて計画を立ててください。
この計画の一部には、さらなる計画を含むフロンティア・セーフティ・ロードマップ(Frontier Safety Roadmap)の維持が含まれますが、これらは完全に状況に応じて変更される可能性があります。ただし、より野心的な目標を後退させないよう努めます。
もう一つの要素は、定期的なリスク報告書です。これは過去の報告書に加えて、他で議論された通り、3〜6 ヶ月ごとに全体像を示すものです。重要な目的は、モデルが絶対的なリスクをもたらす場合でも(他の相手方から見て)追加的なリスクをあまり生じさせない場合であっても、包括的かつ率直に全体のリスク状況を報告することです。
これには、事実情報、脅威モデル、証拠、緩和策、リスク分析、過去の意思決定のレビュー、およびその他の関連情報が含まれます。
彼らは、これらの報告書について包括的な公開外部レビュー(external review)を求める慣行に向けて取り組んでいくとしています。
彼らは最初のリスク報告書を提示したので、これによって何を期待すべきかを判断できます。
ASL-3 の緩和策は、Anthropic のモデル全体に引き続き適用されるべきです。セキュリティは現在、内部者脅威(insider threats)からの保護を強化しており、業界に対しても CEO まで含めて同様の対策を講じるよう推奨しています。また、RAND SL4 を名指しで挙げています。良いことです。
彼らは今や、「自社で実施する内容」と「全員に義務付けてほしい内容」の両方を提示しています。
これら 2 つは確かに別々の概念ですが、この状況において、アンソロピックが少なくとも言うべきことを(それ以上を)一般に必要とされるものとして目指し、全力で取り組むべきではないとするなら、私は驚くでしょう。現在のフレームワークがそのような事態を引き起こすとは読み取れません。
枠組みは「業界全体レベルで安全を保つために必要なことはこれである」というものです。したがって、アンソロピックがそれ未満であれば、構造的に私たちを安全に保つには不十分であると推測されます。
他の組織がルールに従わない場合でも、アンソロピックがこれらのルールにどれだけ尽力して追随するかは曖昧です。彼らはそれにコミットしているわけではありませんが、RSP v3 のどこにもそのようなコミットメントはありません。
アンソロピックが、自らが先頭に立っている間、自分が呼びかけているグローバルなルールに追いつき、あるいはそれを超えることをしない場合、これはピーター・ウィルデフォードの言葉で言えば、彼らの自主的な自己規制実験がほぼ失敗したことを示す指標となります。これに加えて、アヤサの指摘は、アンソロピック自身が能力を正確に測定し、一時停止を引き起こす可能性のあるものを検知することに信頼を置けない場合、これも同様にそのような実験が失敗していることを示すという点です(ただし、アンソロピックが自らの失敗に気づくという、優雅な形での失敗です)。
他のラボに対するインセンティブ効果は良いものですが、それらなしで進むことによる圧力の方が、私は強いと考えます。実際には、これがコミットメントを弱めることを期待しています。
Anthropic が一時停止や制限を行う物理的能力を維持するための仕組みと原動力は失われた。私はこれが事実上、一時停止や制限が検討すらされないことを意味し、あるいは Anthropic がそれを行う準備もできていないことを意味すると懸念している。一時停止や制限を行う物理的能力を確実に備えるよう、強くコミットする必要がある。
ここでは事前展開ゲート機構が存在しない。単にものをリリースできる状態だ。これが最も欠けてはならない重要な要素である。
以前よりも明確に、安全でないようなリリースであっても競争のペースを維持すると説明しており、潜在的に安全でないモデルをリリースしないというコミットメントを取り消したと認めている。
彼らの言い訳:もしある AI 開発者が安全性対策の実装のために開発を一時停止し、他の開発者が強力な緩和策なしで AI システムの訓練と展開を進めた場合、それが結果としてより安全でない世界をもたらす可能性があるというものである。
しかし、Anthropic が先頭にいる場合、そしてその場合に限り、彼らは安全性にコミットする。ただし、再び考えを変えるまでである。
競合他社が強力な安全性対策を計画している場合、少なくともそれらに追いつくと約束する。
ただし、十分な努力を行い、それでも達成できなかった場合を除く。その場合は、それが遅延要因となることを許さない。
TIME がこれを「Anthropic が旗艦的な安全誓約を放棄した」と分類したのは正しいと思う。
ASL レベルは廃止され、「安全性に対する強力な根拠を示す分析と論証の要求」に置き換えられた。彼らはこれが「柔軟性を残す」ことを認め、またその意味について人々によって見解が分かれることも認めている。
ASL レベルの中心点は、外部者の視点から見れば、Anthropic の手を縛り、後から高価であることが証明されたとしても合意したことを実行せざるを得なくするか、少なくともそれをしなかったと認めさせようとする点にあった。
Holden が挙げた目標は、リスク緩和に対する強制機能を作り出し、実践やポリシーのためのテストベッドを構築し、リスクに関するコンセンサスと共通知識の形成を目指すことである。Holden は RSPv3 がこれらの目標を実質的に維持していると考えているが、私はそう思わない。
もしあなたがやるべきことが自己説得力のある安全ケースを作成することだけなら、それがあなたにとって十分に重要であれば、いつでもそれができるだろう。
「すべてのレッドラインが何であるかまだわからない」という主張には共感する。しかし、いかなるレッドラインも明確に説明できないのであれば、それは良い兆候ではない。
私はこの変更を以下のように読み取る:モデルリリースに関する決定について、現在の『コミットメント』さえ守ったとしても(それらは実際にはコミットメントではない)、私たちはほとんど意味のあるコミットメントを持っていないのだ。
彼らは良い議論を行うと約束する。そして、何が良い議論であるかを彼ら自身が決定する。
RSP は now、FSP(Frontier Safety Roadmap:フロンティア安全ロードマップ)の公開を義務付けている。略語が十分に混乱を招いていない場合のために、セキュリティ、アライメント、セーフガード、ポリシーにわたるリスク緩和について記述したものである。
なぜそれらを RSP に含めないのか?私は「頻繁に更新されるから」と思うだろう。
これらは『コミットメント』ではない『公開目標』である。コミットメントもまたコミットメントではないというのに。私たちは新しい言葉が必要だ。
原則として、ハードコミットと目標志向の両方を設けることは妥当に思えますが、それは実際にハードコミットが存在する場合に限られ、現状ではそのようなハードコミットは存在しません。あるのはソフトコミットと目標志向のみです。それでは、ソフトコミットに基づいて評価するのでしょうか?
これは、SB 53 や RAISE の違反を確実に防止したいという意図によるものなのでしょうか?
リスク報告書は、公開時に詳細な安全性情報を提供し、オンライン上で 3〜6 ヶ月ごとに公開されます。外部レビューは「特定の状況下」で必要とされます。これはモデルリリース時の能力評価やモデルカードの代替ではなく、それらに追加されるものです。
なぜ外部レビューを望まないのでしょうか?ホルデン氏は、外部レビューが高リスクかつ実験的であると述べていますが、私は、これがモデルリリースと連動しておらず、停止機能としても機能しないのであれば、単に行えばよいと考えます。
新しいモデルリリースと連動させない場合、どのようにして能力を意味ある形で評価できるのでしょうか?また、この頻度でリスク評価を行うにはどうすればよいのでしょうか?
答えは、新モデルのリリース時、または内部モデルにおいてそのような差分が必要であると認識してから 30 日以内に、旧リスク報告書との差分分析を実施することにコミットしている点にあります。
モデルリリースが 2 ヶ月ごとである中で、3〜6 ヶ月は非常に長い期間です。
「リスクとベネフィットの判断」は最終的に常にそうなるものですが、実務上ではリスクが妨げにならないようもう一歩進んだ措置のように見えます。
外部レビュー自体は良いことですが、やはり手遅れになる可能性が高いように思われます。
チェック対象が大幅に見直されています。
生物学的および化学的な安全対策は継続しており、次節を参照してください。
放射線および核に関する項目は完全に削除され、もはや関心を持たれていません。
自律性についてはチェックされていません。なぜならモデルはすでに完全な自律性を有しており、私たちはその前提で進めているからです。
サイバー作戦(Cyber Operations)の項目は完全に削除されました。おそらくすべてのテストを通過してしまうからでしょうか?これは OpenAI および Google にとって中核的なテストであるにもかかわらずです。
実効性のある計算リソースチェックポイントも削除されています。
全体として:ああ、あなたが引き上げる基準を。ああ、あなたが動かすゴールポストを。
評価が「雰囲気」ベースであり、それさえも本当のコミットメントがない場合、これを真剣に受け止めるのは難しいです。Anthropic は雰囲気をチェックし、安全かどうかを判断します。なぜ私が間違っているのか教えてください。
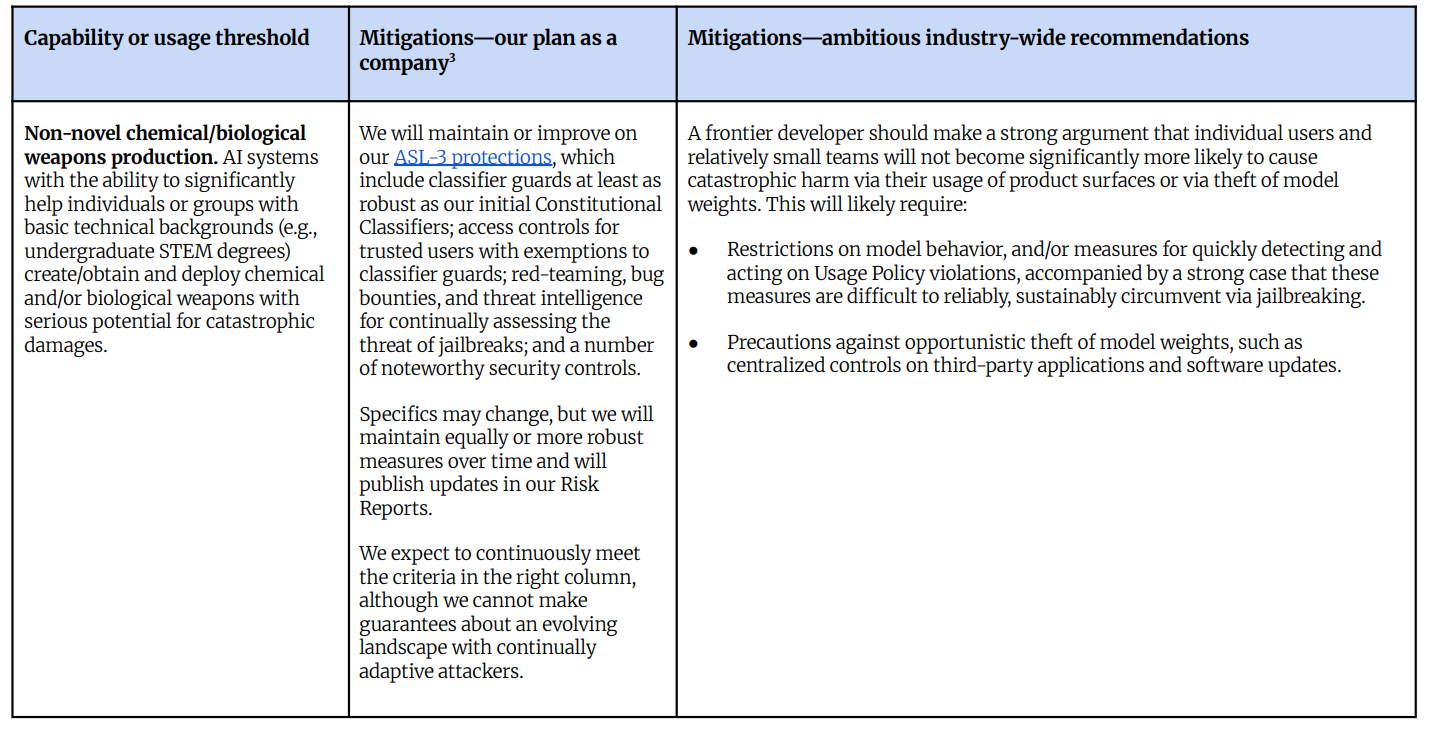
生物学的および化学的な安全対策。
非新規の化学兵器または生物兵器の生産が、新たな CBRN-3(Chemical, Biological, Radiological, and Nuclear - 3)となります。
これは今後ほぼすべてのモデルに対して ASL-3(Artificial Intelligence Safety Level - 3)保護を要求するものです。
彼らは明示的に業界全体の基準に達し、それを達成することを期待しています(ただし、これは、彼らがその基準に達すると述べていない箇所では、おそらく達するとも期待していないし、目指してもいないことを意味します)。
目標は、「小規模チームが壊滅的な危害を引き起こす可能性が著しく高くない」という「強力な論拠」を提示することであり、これはおそらくモデル重みの盗難に対する予防措置やモデル行動の監視を通じて達成されます。
オープンウェイトモデルがこの基準を満たすことは、おそらく不可能です。
新規の化学・生物兵器は、新たな CBRN-4(注:化学・生物・放射能・核兵器)となります。
「中程度の資源を有し専門家の支援を受けたチーム」が使用できる兵器は、「COVID-19 などの過去の壊滅的被害をはるかに超える壊滅的な損害をもたらす可能性」を伴わなければなりません。したがって、これは極めて高い基準であり、おそらくここでは「化学」という言葉は削除してよいでしょう。
これに対する追加の対応策として、「特定の脅威経路の早期検出のための政策提言を作成する」ことが挙げられています。
彼らが推奨する行動は再び、「一連の緩和措置が RAND SL4(注:RAND 研究所のリスクレベル分類レベル 4)に合致し、かつ使用監視も含まれる」という「強力な論拠」です。
「利用状況を監視する」という計画は、現在 Jailbreaking(注:セキュリティ制限を回避する攻撃手法)の状況を見ると、あまり良くないと思われます。
「高リスクの破壊工作の機会」は、AI 企業内のシステム、特に後継モデルに関するものに対する新たなカテゴリです。良いアイデアです。
サボタージュ(破壊工作)があることを喜ばしく思う一方で、AI が制御から逃れようとする、あるいは制御を乗っ取ろうとする、あるいはその他様々な行為を行うことへの懸念と比較すると、これは奇妙な枠組みまたは焦点と言えます。ここでは、私たちの機会を損なうあらゆる行動がどの程度該当するのかは明確ではなく、したがってそれらがすべて含まれるのか、含まれないのかも不明です。いずれにせよ、この枠組みは相当に混乱を招くものです。
彼らの「コミットメント」への回答は、システムの能力を詳細に説明するものです。また、彼らは自社のポリシー推奨要件を満たすことを期待しています。
その要件は再び、「モデルが『世界的な壊滅的な事態の不可逆的かつ大幅な増大をもたらすような』サボタージュを実行しない」という「強力な論拠」です。
これは、サボタージュがカウントされるための非常に高いハードルです。
彼らはこれが最終的には、AI モデルに対する過度なサボタージュの機会を防止するための内部コンパートメンタライゼーション(区画化)、制限、コードレビュー、能力評価、および内部的な行動と利用の監視および/または制限、そして傾向の欠如を示す証拠を含むことを期待しています。
これが具体的な要件のセットであれば、おそらく強力なものとなるでしょう。
しかし、「これは必要になるだろう」という表現では、それが何を意味するのかを知ることは難しくなります。
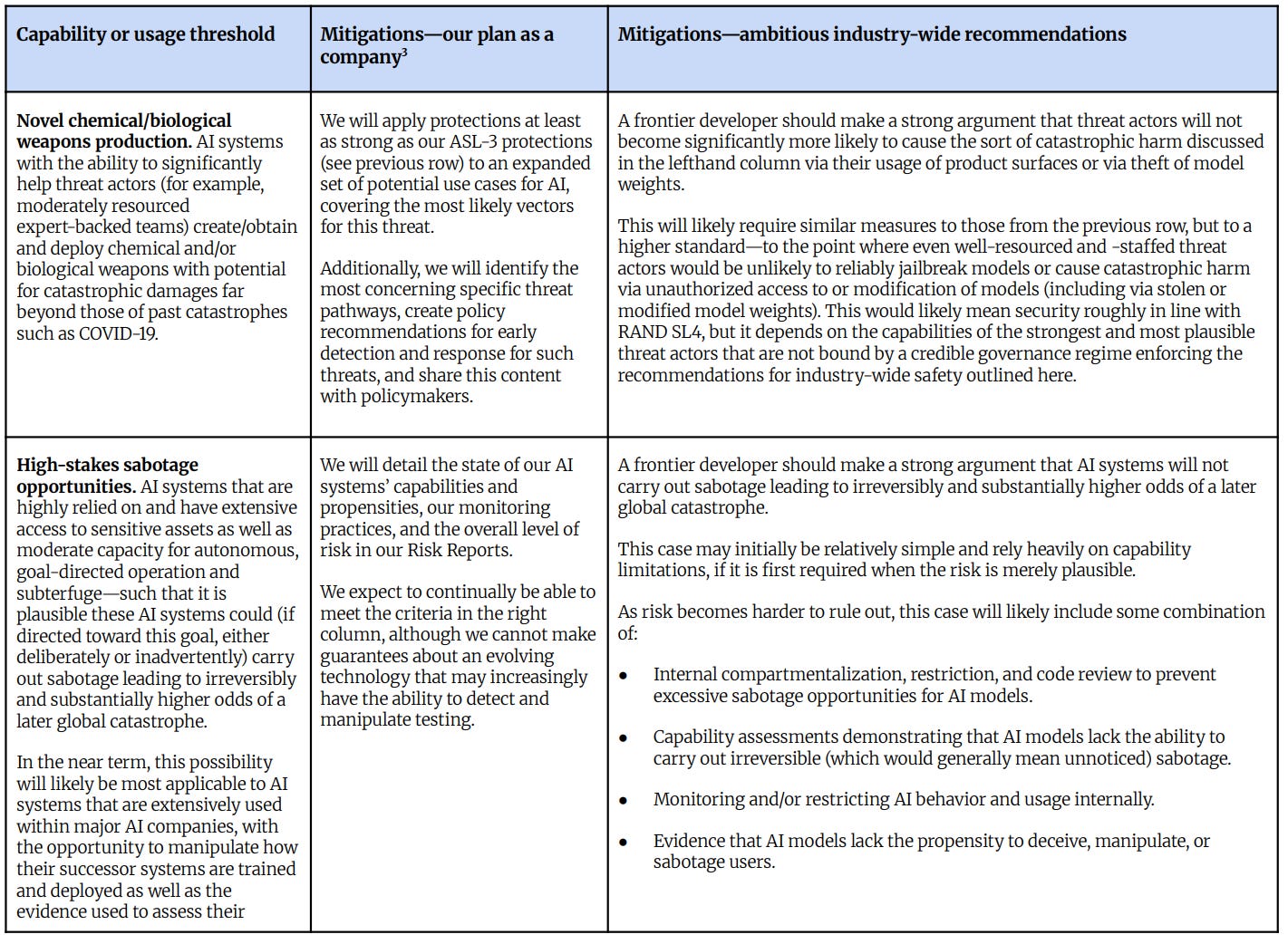
「主要分野における自動化された研究開発」は、新しい AI R&D-5 であり、最大の基準です。これは「2018 年から 2024 年の AI の進歩を 2 年分を 1 年に圧縮できる」という形で運用されており、速度が 100% 向上することを意味します。
彼らが指摘するように、これは高いハードルであり、現在、それより低い基準さえも達成できていません。
Claude Opus 4.6 は、約 9% の速度向上をもたらすだろうと推定しています。
GPT-5.4-Pro は約 30% の速度向上(思考プロセスでは 25% と算出)を推定しています。
私はこの数値が上回る可能性があると予想します。
また、「Claude Opus 4.6 が達成できること」と「特異点がまさに今始まる」の間に、追加の閾値を設けるべきだと考えます。
彼らが「主要分野における自動化された研究開発」に到達した場合、あるいはその時点で何を計画しているのでしょうか?
「リソースを投入し、セキュリティのための画期的な研究開発プロジェクトを完了させること。」
内部開発において「あらゆるものを監視する状態」を実現すること。
体系的なアライメント評価を実施すること。
外部のレッドチーム(攻撃シミュレーション)よりも優れた内部レッドチームを開発すること。
リスクレポートを公開すること。
他社より優れた取り組みを行うが、何事も保証はできない。
望ましい世界的な要請とは何か?これは「強力な論拠」であり、ここでは以下を対象としています:
この技術を用いて、ユーザーのどのチームも重大かつ壊滅的な被害を引き起こすことはない。最大限のアクセス権を持つ悪意のある従業員を含めて。
これはモデルの誤用防止と、モデル重み(weights)の保護を意味します。
モデルに危険な目標が訓練されておらず、あるいは他のモデルの性質として壊滅的な害を及ぼす傾向がないこと。
これらは良いセーフガードであり、確かに必要ですが、それらが中心にあるわけではありません。
これらの R&D 発動型セーフガードのいずれも、自動化された R&D の中心的な脅威モデル——すなわち、急速な能力向上や再帰的自己改善、そしてそれに伴うすべての「ユドコフスキー的」危険、アライメント問題、事実上の目標、手段的収束、急激な方向転換、そして突然あなたを凌駕すること——には対応していません。これは意図的な悪用や、十分な能力を獲得する以前の既存の悪い行動ではありません。上記の措置は、何かが誤る二次的な経路の一部を遮断しますが、それらの行為自体は完全に実行されます。しかし、私が上記の措置から、あなたがその最終局面(エンドゲーム)に進む準備ができているという確信を得られるとは到底思えません。
これは超知能を無視しているか、あるいは真剣に受け止めていないかのどちらかです。
新しい潜在的な能力に対する約束された対応は、それらが表すものの重大さを反映していないように見えます。野心高い目標さえも、野心深いようには見えません。
全体を通じて、正確な言語が曖昧な言語へと変容しています。
ガバナンスコミットメントに関する様々な変更があります。いくつかは削除され、いくつかは追加されました。特に「準備完了」と「通知」の項目が、代替案なしに消えているように見えます。
彼らは、これらすべてを処理する責任あるスケーリングオフィサー(Responsible Scaling Officer)を置くことにコミットしています。
取締役会とLTBT(上級技術責任者)は、追加の明示的な拒否権ポイントとして導入されました:「限界的リスク分析(前節参照)が前進に関する意思決定において主要な役割を果たす場合、CEOおよびRSOだけでなく、取締役会およびLTBTによるリスク報告書の明示的承認が必要となる」。
これは良いことですが、私はこれを条件付きのものではなく、確定的なものにしてほしいと思います。能力の大幅な向上には、取締役会、CEO、RSO、LTBTのすべての明確な承認が必要であると述べるのは妥当だと考えられます。
関連する技術スタッフの間にも拒否権ポイントが設けられることを望みます。
Yoav Tzfati氏が指摘するように、報告書の内容に関わらず、他の拒否権ポイントに制約される限り、CEOとRSOは自由に何でも決定できます。ロードマップ
ロードマップは主に非常に高レベルですが、いくつかの優れた詳細も含まれています。長期的なタイムラインにおける理想目標も含まれています。以下に例を示します。
2026年7月1日:政策立案者向けのロードマップ。まだありませんか?
2026年10月1日:Claudeの憲章(Claude's Constitution)の維持、最新状態の保ち、評価の実施。
2027年1月1日:世界クラスの内部レッドチーム演習(redteaming)。
2027年1月1日:完全自動化された攻撃調査。
2027年1月1日:「すべてのものを監視する」内部状態への移行。
2027年7月1日:セキュリティ全般における「レベルアップ」、多くの詳細を含む。
将来の重要なイベントは自動化された研究開発(R&D)であり、彼らはこれが早くも2027年初頭に実現可能であると予測しています。そのため、その時点で達成すべき目標を設けていると再確認しています:
その時点までに、上記の目標の多くを達成できていると予想しています。具体的には以下のような内容です。
リソースを投入し、「ムーンショット R&D セキュリティ」プロジェクトを完了させること。
世界クラスの内部レッドチーム(攻撃シミュレーション)および自動化された攻撃調査体制を開発すること。
政策立案者向けに、AI 開発の恩恵を不必要に制限したり、民主主義国の AI 開発が専制国家に対して遅れることがないよう配慮しつつ、業界全体の安全性を実現するためのロードマップを策定し、その推進を図ること。
内部での AI 開発において、「すべてのものを監視する」状態を確立すること。
Claude の憲章(Constitution)を維持するために、体系的なアライメント監査およびその他の措置を一貫して実施すること。
これにより、RSP(責任あるスケーリングポリシー)のいくつかの項目が具体化され、より明確になります。
あなたは議論のためにここに来たのです
Anthropic が企業に求める中心的なことは、「さまざまなリスクに対して対策を講じた」という「強力な主張」を行うことです。これは様々な行動を必要とするものですが、Anthropic はそれらの行動を義務付けるよう求めているわけではありません。
これは(推測するに)最大限の柔軟性という哲学に基づいています。しかし、最大限の柔軟性は、最大限の信頼を要求することを意味します。
誰が「強力な主張」を行ったかを決定するのでしょうか?
おそらく Anthropic が、Anthropic 自身が強力な主張を行ったかどうかを決定することになるでしょう。
Anthropic を信頼したとしても、OpenAI が OpenAI 自身が行ったかどうかを判断すると信頼できますか?Google は?Meta は?xAI は?私はそうは思いません。
公平な反論として「政府がその決定を下し、モデルのリリースに対して恣意的な拒否権を行使し、それを無限の交渉材料として利用することを望むのか」という問いがあります。確かに今月はこのアプローチにおける大きな危険性を私たちに示しました。
したがって、「強力な議論」スタイルの言語を使用したいのであれば、この問題に対する解決策が必要であり、現時点ではそのような解決策は存在しません。信頼できるプロセスを見つけるまでには、それよりも具体的である必要があり、そうでなければ実効性を持ちません。
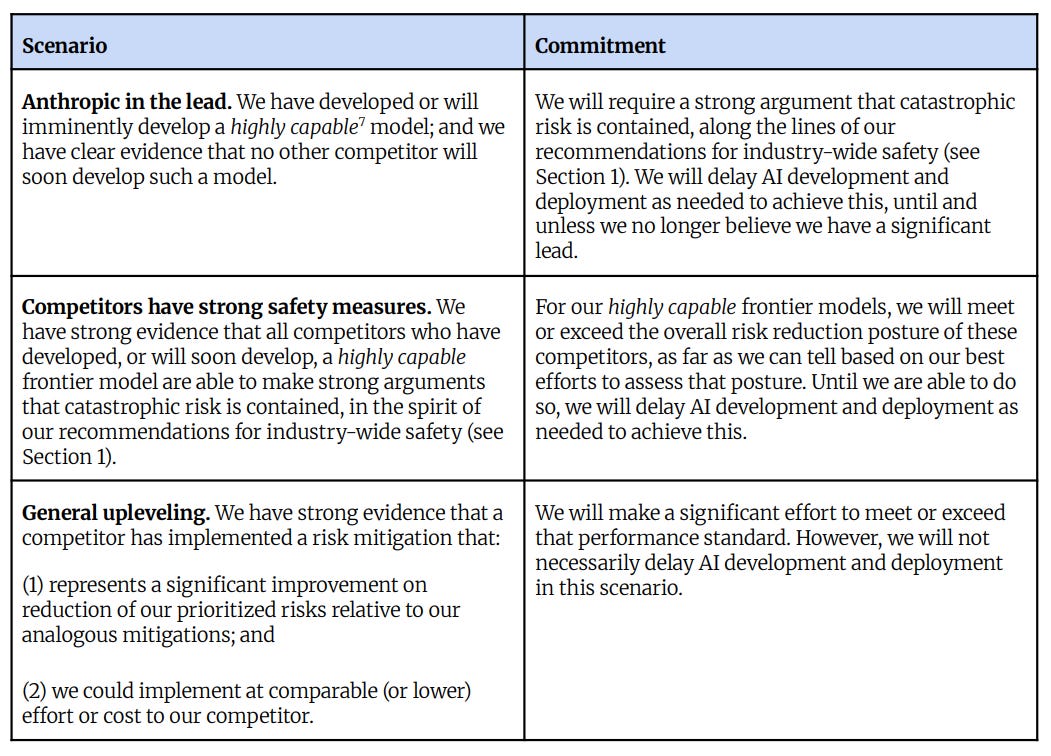
彼らが「コミットメント(約束)」という言葉を使うのは、Anthropic が主導権を握っている場合だけです。
強力な安全対策を持つ競合他社に直面した場合、彼らはその競合他社の基準を満たすか上回ることを約束するだけであり(この文脈における「コミットメント」の意味を思い出してください)。
競合他社が Anthropic の基準を上回る改善を行っている場合、彼らはより高い基準を満たそうとしますが、何らかの約束は行いません。
彼らは引き続きその言葉「コミットメント」を使い続けています。彼らが、後で必要に応じて変更できない真正な約束であることを明確に伝え、少なくともある程度の時間がかかる明確な手続きを要請するまで、私はこの言葉を引用符付きで使うのをやめません。
では、より安全対策が不十分な強力な競合他社が存在し、「顕著なリード」がない場合はどうなるでしょうか。これは上記のチャートには全く含まれておらず、最も可能性の高いシナリオです。実務上の答えは、Anthropic が自社の緩和策と確率が十分に高いと感じる限り、事業を継続すると推測されます。
原文を表示
Wednesday’s post talked about the implications of Anthropic changing from v2.2 to v3.0 of its RSP, including that this broke promises that many people relied upon when making important decisions.
Today’s post treats the new RSP v3.0 as a new document, and evaluates it.
First I’ll go over how the RSP v3.0 works at a high level. Then I’ll dive into the Roadmap and the Risk Report.
How RSP v3.0 Works
Normally I would pay closer attention to the exact written contents of the new RSP.
In this case, it’s not that the RSP doesn’t matter. I do think the RSP will have some influence on what Anthropic chooses to do, as will the road map, as will the resulting risk reports.
However, the fundamental design principle is flexibility and a ‘strong argument,’ and they can change the contents at any time, all of which means the central principle is trust.
I read the contents as ‘here are the things we are worried about and plan to do,’ which mostly in practice should amount to doing what they believe is right and I don’t see anything on this map that seems likely to importantly bind that given Anthropic generally cares about the safety of its models, as it understands the risks involved.
The actual soft ‘commitments’ that seem to matter most are the periodic new Risk Reports, maintaining a Frontier Safety Roadmap, and establishing veto points with the CSO, CEO, board and LTBT on big capabilities advances.
I don’t read the commitments here as reflecting my understanding of the risks involved in ‘powerful AI,’ especially in the realm of automated R&D.
This is a plan of action, not a set of commitments. Plan accordingly.
Part of the plan is to maintain a Frontier Safety Roadmap with further plans, which are fully subject to change, although they will strive to avoid making them less ambitious.
Another element are periodic Risk Reports, which are in addition to previous risk reports, giving an overall picture every 3-6 months, as discussed elsewhere. The key aim is to be fully candid about the overall risk picture, including when models pose absolute risk but don’t introduce much marginal risk (because you should see the other guy).
This is to include factual information, threat models, evidence, mitigations, risk analyses, reviews of past decisions and any other relevant information.
They will ‘work towards a practice of’ seeking comprehensive, public external review on these reports.
They give us the first Risk Report, so we can judge by that what to expect.
ASL-3 mitigations should continue to apply to Anthropic models across the board. Security most now protect against insider threats and they recommend the industry do so up to and including the CEO, and names RAND SL4. Good.
They now offer both a ‘this is what we will do on our own’ and ‘this is what we would like to have everyone be required to do.’
These two can indeed be distinct things, but in this situation I would find it surprising if Anthropic shouldn’t be aspiring and trying very hard to do at least what they say should be generally required, if not more. I don’t read the current framework as causing that to happen.
The framing is ‘this is what it would take at an industry wide level to keep things safe’ so anything less than that by Anthropic would presumably be, by construction, insufficient to keep us safe.
It is ambiguous the extent to which Anthropic will strive to match those rules even if others do not follow. They’re not committed to doing so, but then nothing in RSP v3 is a commitment.
If Anthropic doesn’t match or exceed the global rules it is calling for given what they are, at least while it is out in front, then this is, as Peter Wildeford put it, a marker that their voluntary self-governance experiment has largely failed. This is in addition to aysja’s point, which is that if Anthropic does not trust itself to accurately measure capabilities that might trigger a pause that this also indicates that such an experiment is a failure, albeit a graceful one in which Anthropic notices it has failed.
The incentive effect on other labs is good but the pressure of going without them was I think stronger. In practice I expect this to weaken commitments.
The machinery and impetus to ensure Anthropic retains physical ability to do a pause or restriction is gone. I worry this de facto means it won’t even be considered, or Anthropic won’t be prepared to do it. You need to hard commit to having the physical ability to pause or restrict.
There is no pre-deployment gate mechanism here. You can just release things. That’s the most important thing not to not have.
They explain more explicitly than before that they will keep pace in the race, even if such a release would be unsafe, and they are taking back their commitment to not release potentially unsafe models.
Their excuse: If one AI developer paused development to implement safety measures while others moved forward training and deploying AI systems without strong mitigations, that could result in a world that is less safe.”
However, if Anthropic is in the lead, then and only then they commit to safety, unless they change their minds again.
If competitors have strong safety measures they plan to at least match those.
Unless they made a considerable effort to do so, and couldn’t, in which case they’re not going to let that delay them.
I think it was correct for TIME to categorize this as ‘Anthropic drops flagship safety pledge.’
ASL-levels are deprecated in favor of ‘requiring analysis and arguments making a strong case for safety.’ They admit this ‘leaves flexibility,’ and that different people will disagree on what that means.
The central point of the ASL-levels, from an outsider perspective, was to tie Anthropic’s hands, so they would have to do the thing they agreed to do even if it later proved expensive, or otherwise at least have to admit they didn’t do it.
The goals Holden listed were to create a forcing function on risk mitigations, and create a testbed for practices and policies, and work towards consensus and common knowledge about risks. Holden thinks that RSPv3 effectively preserves these goals. I don’t think it does.
If all you have to do is make a self-convincing safety case, well, you can always do that if it’s sufficiently important to you to do that.
I am sympathetic to ‘we do not know what all the red lines will be.’ But if you cannot articulate any red lines, that is not a good sign.
I read this change as: We have almost no meaningful commitments at all around decisions about model releases, even if we keep to all of our current ‘commitments,’ which aren’t commitments.
They promise make a good argument. They decide what is a good argument.
The RSP now requires publishing an FSP, a Frontier Safety Roadmap, in case the acronyms were insufficiently confusing, describing risk mitigations across Security, Alignment, Safeguards and Policy.
Why not have those be in the RSP? I think ‘because they get updated a lot.’
These are ‘public goals’ but not ‘commitments,’ despite the commitments also not being commitments. We need new words for things.
In principle it seems fine to have both hard commits and aspirational goals, but that only works if there are any hard commits and there aren’t any. There are soft commits and aspirational goals. So, grade on the soft commits, then?
Is this because they want to ensure no violations of SB 53 or RAISE?
Risk Reports will provide detailed safety information at time of publication and be published online every 3-6 months. External review will be required ‘in certain circumstances.’ This is in addition to on-model-release capability assessments and model cards, not a replacement of them.
Why would you ever not want external review? Holden says external reviews are high-stakes and experimental, but I think given this isn’t lining up with a model release and doesn’t serve as a stopping function you can just do them.
How do you assess capabilities meaningfully if you don’t line up with new model releases? How do you do risk assessments on this cadence?
The answer is that they are committing to doing a diff with the old risk report upon release of a new model, or within 30 days of realizing they have an internal model that requires such a diff.
3-6 months is a lot when model releases are every 2 months.
‘Risk-benefit determination’ is how everything always works in the end, but seems like another step towards in practice not letting risks stop you.
External reviews are good but again they look like they’ll be too late?
What is being checked for is overhauled.
Biological and chemical safeguards continue, see next section.
Radiological and nuclear are fully gone, we don’t care anymore.
Autonomy isn’t checked because the models fully have autonomy, and we’re proceeding with that assumption.
Cyber Operations is fully gone. Perhaps because it would pass every test? This is despite it being a core test for both OpenAI and Google.
The effective compute checkpoints are gone.
Overall: Oh, the standards you’ll raise. Oh, the goalposts you’ll move.
It’s hard for me to take this seriously when the evaluations will be vibes-based and there are no real commitments even then. Anthropic is going to check the vibes, and decide if it seems safe or not. Tell me why I’m wrong.
Biological and chemical safeguards.
Non-novel chemical or biological weapons production is the new CBRN-3.
This calls for ASL-3 protections in essentially all models going forward.
They explicitly aim for and expect to hit the industry-wide standard (note that this implies that where they don’t say they expect or aim to hit that standard, it means they presumably don’t expect or aim to hit it).
The goal is a ‘strong argument’ that small teams won’t be significantly more likely to cause catastrophic harm, presumably via precautions against model weight theft and monitoring of model behaviors.
It is presumably impossible for open weights models to satisfy this.
Novel chemical and biological weapons are the new CBRN-4.
The weapon enabled in the hands of ‘moderately resourced expert-backed teams’ has to come ‘with potential for catastrophic damages far beyond those of past catastrophes such as COVID-19.’ So it’s a super high threshold, and presumably you can delete ‘chemical’ here.
The additional response here is ‘create policy recommendations’ for early detection of particular threat pathways.
Their recommended action is again ‘a strong argument’ for a set of mitigations, which here they anticipate matches RAND SL4, plus the usage monitoring.
The plan of ‘monitor usage’ seems not great given the state of jailbreaking.
High-stakes sabotage opportunities is a new category aimed at internal systems at AI companies, especially regarding successor models. Good idea.
While I’m happy to have sabotage, it is a strange framing or focus as opposed to worrying about AIs breaking free of control, or taking over control, or doing various other things. It’s not clear the extent to which any actions that hurt our chances count here, and thus they’re all included, versus not. Either way, this is reasonably confusing framing.
Their ‘commitment’ response is to detail the systems’ capabilities. They also expect to meet their policy recommendation requirements.
That requirement is again a ‘strong argument,’ here that the model will not carry out sabotage ‘leading to irreversibly and substantially higher odds of a global catastrophe.’
That’s a pretty high bar for sabotage to count.
They expect this to eventually involve internal compartmentalization, restriction, and code review to prevent excessive sabotage opportunities for AI models, capability assessments, monitoring and/or restricting behavior and usage internally and evidence of lack of propensity.
If that was a concrete set of requirements, it would probably be strong.
As a ‘we expect this will require,’ it’s harder to know if it means anything.
‘Automated R&D in key domains’ is the new AI R&D-5, the big kahuna, operationalized as ‘could compress two years of 2018-2024 AI progress into a single year’ which is a 100% speedup.
As they note, this is a high bar, and they are currently missing lower bars.
Claude Opus 4.6 estimates it would have provided about a 9% speedup.
GPT-5.4-Pro estimates about 30% speedup (Thinking said 25%).
I would take the over on that.
I would also want an additional threshold somewhere between ‘what Claude Opus 4.6 can do’ and ‘the singularity starts right about now.’
What do they plan to do if or by the time they hit ‘automated R&D in key domains’?
‘Resource and complete significant “moonshot R&D for security” projects.’
Achieve an ‘eyes on everything’ state for our internal development.
Perform systematic alignment assessments.
Develop internal red-teaming superior to external red-teaming efforts.
Publish Risk Reports.
Do better than the other guys, but they can’t guarantee anything.
What’s the desired global request? Another ‘strong argument,’ in this case for:
No team of users will cause substantial new catastrophic harm with this, including malicious employees with maximum access.
That’s misuse prevention and guarding of model weights.
A lack of dangerous goals trained into the models, or other model propensity to cause catastrophic harm.
These are good safeguards and you do need them, but they’re not central.
None of these R&D-triggered safeguards address the central threat model of automated R&D, which is rapid capability gain or recursive self-improvement, together with all the resulting Yudkowsky-style dangers, alignment issues and de facto goals, instrumental convergence and sharp left turns and suddenly outsmarting you, not intentional misuse or existing bad behaviors prior to achieving sufficient capabilities. The actions above cut off some secondary ways things can go wrong, totally do those things, but I don’t see how the above actions give you assurance that you are ready to go into that endgame, at all.
Either this is ignoring superintelligence, or not taking it seriously.
The responses promised for the new potential capabilities do not seem to reflect the gravity of what they represent. Even the ambitious goals don’t seem ambitious.
Precise language becomes vague language, throughout.
Various changes to governance commitments. Some are gone, some added. Readiness and notification in particular look gone without replacement.
They commit to having a Responsible Scaling Officer to handle all this.
The Board and LTBT are introduced as additional explicit veto points: “In the event that marginal risk analysis (see previous section) plays a major role in a decision to move forward, explicit approval of the Risk Report by the Board and LTBT (rather than just the CEO and RSO) will be required.”
This is good, but I’d like to see this not be a conditional. It seems reasonable to say that any substantial increase in capabilities should require the explicit approval of the Board, CEO, RSO and LTBT.
I would like to also see veto points among the associated technical staff.
As Yoav Tzfati points out, the CEO and RSO are free to decide whatever they want, no matter what the reports say, subject to other veto points. The Roadmap
The roadmap is mostly very high level, but does have some good details. It contains some aspirational goals on long timelines. Here are some examples.
July 1, 2026: Roadmap for policymakers. We don’t have one yet?
October 1, 2026: Upholding Claude’s Constitution, keeping it up to date, doing assessments.
January 1, 2027: World-class internal redteaming.
January 1, 2027: Fully automated attack investigations.
January 1, 2027: ‘Moving towards’ an “eyes on everything” internal state.
July 1, 2027: ‘Leveling up across the board’ on security, with many details.
The key future event is automated R&D, which they anticipate could arrive as soon as early 2027, which they reiterate is why they have these goals to get to by then:
By that point, we expect to have accomplished most of the goals listed above, including:
Resourcing and completing significant “moonshot R&D security” projects.
Developing world-class internal red-teaming and automated attack investigations.
Publishing and advocating for a roadmap for policymakers to achieve industry-wide safety without unnecessarily limiting the benefits from AI development or slowing the AI development of democracies relative to that of autocracies.
Achieving an “eyes on everything” state for our internal AI development.
Consistently implementing systematic alignment audits and other measures for upholding Claude’s Constitution.
This fleshes out some things from the RSP and makes them more concrete.
You Came Here For An Argument
The central thing Anthropic wants is for companies to have to ‘make a strong argument’ that they have guarded against various risks, which they anticipate would require various actions but they’re not asking to require those actions.
This stems (I presume) from the philosophy of maximum flexibility. But maximum flexibility means requiring maximum trust.
Who gets to decide whether you made a strong argument?
Presumably Anthropic decides whether Anthropic made a strong argument.
Even if you trust Anthropic, do you trust OpenAI to decide if OpenAI did so? Google? Meta? xAI? I don’t.
A fair retort is ‘do you want the government making that decision, giving it an arbitrary veto over model releases, that it could use as a point of limitless leverage?’ Certainly this month has shown us one big danger in that approach.
Thus I think if we want to use ‘strong argument’ style language, we need a solution to this problem, and right now we have no such solution. Until we can find some process that we can trust, it needs to be more concrete than that, or it won’t have teeth.
They only ‘commit’ to the strong argument when Anthropic is in the lead.
If they face competitors with strong safety measures, they only promise to meet or exceed the standards of those competitors (and remember what ‘commitment’ means in this context).
If the competitor is improving on Anthropic’s standards, they’ll try to meet the higher standard, but they don’t promise anything.
They keep using that word ‘commitment.’ I will stop putting it in air quotes if they give clear communication that something really is a commitment that they cannot modify later as needed, with at least some slower and clear procedure required.
What about if they have a strong competitor with worse safety measures, and lack a ‘significant lead’? That didn’t make the chart above at all, and is the most likely scenario. One presumes the answer in practice is that they will proceed, so long as Anthropic feels its mitigations and chances are sufficiently
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み