LangSmithにおける再利用可能な評価器とテンプレート
LangSmithが評価テンプレート30種以上と再利用可能な中央ハブを提供し、プロジェクト間での評価器の共有を可能にして開発効率を向上させた。
キーポイント
評価テンプレートの拡充
LangSmith Evaluationにおいて、30種類以上の事前構築された評価テンプレートが利用可能となり、ゼロから評価ロジックを設計する手間が削減された。
中央ハブによる再利用
評価器(Evaluator)をプロジェクト間で共有・再利用できる中央ハブ機能が導入され、チーム全体での標準化と効率化が促進されている。
開発サイクルの高速化
既存のリソースを活用できるため、より高品質な評価を迅速に実装でき、LLMアプリケーションのリリースサイクルが加速する。
影響分析・編集コメントを表示
影響分析
このアップデートは、LangChainユーザーにとって評価作業のボトルネックを解消する実用的な改善であり、LLMアプリケーション開発における品質保証プロセスの標準化に寄与します。ただし、これは既存プラットフォームの機能強化であり、業界構造や技術パラダイムを根本から変革するものではないため、中程度の重要性を持ちます。
編集コメント
LangSmithのこの機能強化は、LLM開発現場における「評価」の重要性を再認識させると同時に、チーム協業時のワークフロー効率化に直結する有益なアップデートです。

主要なポイント
- エバリュア・テンプレート(Evaluator templates)でスタートダッシュを切りましょう。LangSmith には、安全性、応答品質、軌跡(Trajectory)、ユーザー行動、マルチモーダル評価をカバーする 30 以上のテンプレートが用意されています。そのまま使用するかカスタマイズして、オンラインモニタリングとオフラインのテスト実行の両方で活用できます。
- 1 つのエバリュエータ(Evaluator)を作成し、あらゆる場所で適用します。新しく追加された「Evaluators」タブにより、ワークスペース内のすべてのエバリュエータが一元的に管理されます。既存のエバリュエータを新しいトレーシングプロジェクト(Tracing project)に数秒でアタッチできるため、組織全体で重複したコピーを維持することなく、セキュリティチェックと品質指標の一貫性を保つことができます。
- 優れた評価には多層的なカバレッジが必要です。最終回答のみをチェックする単一のエバリュエータでは、検索エージェント(Retrieval agent)が適切なドキュメントを取得したか、計画立案エージェント(Planning agent)が適切に委任を行ったかどうかは検出できません。効果的なエージェントの評価とは、トレース(Trace)内の個々のステップ、完全な軌跡、マルチターン会話、および特定のツール呼び出しをテストすることを意味します。
本日、LangSmith Evaluation において再利用可能なエバリュエータ(Reusable evaluators)とエバリュエータテンプレートライブラリ(Evaluator template library)の 2 つのアップデートをリリースします。
再利用可能なエバリュエータにより、複数のトレーシングプロジェクトにわたってエバリュエータを一元的に表示、管理、適用できます。エバリュエータテンプレートにより、チームはゼロから構築することなく、エージェントのテストとモニタリングを迅速に開始できます。
評価が停滞する場所
エージェント構築において「良い」とは何かを定義することは、最も困難な課題の一つです。あなたのエージェントは適切なツールを呼び出しても、レスポンスのフォーマットが不十分である可能性があります。単一ターンの対話には対応できても、マルチターン会話では破綻してしまうかもしれません。また、最終回答のみをチェックする単一の評価器(evaluator)では、検索エージェントが正しいドキュメントを取得したのか、あるいは計画エージェントが適切なサブエージェントに委任を選択したのかを判断できません。個々のステップ、完全なトランジェクトリ(trace)、全体としての会話、さらには特定のトレース内のツール呼び出しといった異なるレベルで評価を行う必要があります。
これらの各レベルにわたる評価器の構築には、数週間かかることがあります。プロンプトを作成し、実際のデータに対してスコアを確認し、調整し、これを繰り返します。この反復プロセスは重要ですが、毎回ゼロから始めるとなると、エージェントの改善に費やすべき時間が基礎作業に奪われてしまいます。さらに、優れた評価器を一度構築したら、別々のコピーを維持することなく、トレースプロジェクト全体でそれを適用したいと考えるはずです。
LangSmithでは、openevalsのEvaluator FrameworkからEvaluator Calibration、マルチモーダル・Evaluatorのサポートに至るまで、1年以上にわたって評価ツールの構築を行ってきました。今回のリリースでは、最も多くのリクエストがあった2つの特徴を追加しました。
Evaluator Templates
私たちは、本番環境でエージェントを実行している多くのチームと協力してきましたが、同じような評価に関する質問が常に持ち上がっています。エージェントは安全か? 応答は実際に良いのか? それに至るために適切な手順を踏んだか?
テンプレートは、私たちが最も頻繁に目にするカテゴリをカバーしています:
- 安全性とセキュリティ:プロンプトインジェクションの検出、PIIチェック、バイアスおよび毒性
- 応答品質:正確性、有用性、トーン
- トランジェクトリ(行動軌跡):エージェントは適切な手順を踏んだか?
- ユーザー行動分析:言語分布、満足度のシグナル
- マルチモーダル:音声および画像レビュー
これらは、利用可能な30以上のEvaluatorテンプレートの一部です。テンプレートには、調整されたプロンプトを持つLLM-as-judge(大規模言語モデルによる判定者)Evaluatorと、ルールベースのコードEvaluatorが含まれています。これらをそのまま使用するか、または自社のエージェントに合わせてカスタマイズしてください。
これらはオンライン評価とオフライン評価の両方で機能します。オンライン評価では、テンプレートは生産トラフィックを分類するのに役立ちます:プロンプトインジェクションの検出、予期しないユーザー行動のフラグ付け、または人間のレビューが必要なトレースの表面化などです。あなたの修正を使用して評価者プロンプトを調整し、次回により良いパフォーマンスを発揮させることができます。
オフライン評価では、テンプレートはデータセット全体で実験を実行するための出発点を提供します。評価者を実行し、スコアを確認し、失敗にフィルタリングし、何が間違っていたかを理解します。
これらのテンプレートは、本日リリースされたopenevals v0.2.0でも利用可能で、音声や画像の出力を評価するための新しいマルチモーダルサポートが追加されています。コード内またはLangSmith UIを通じて直接使用できます。
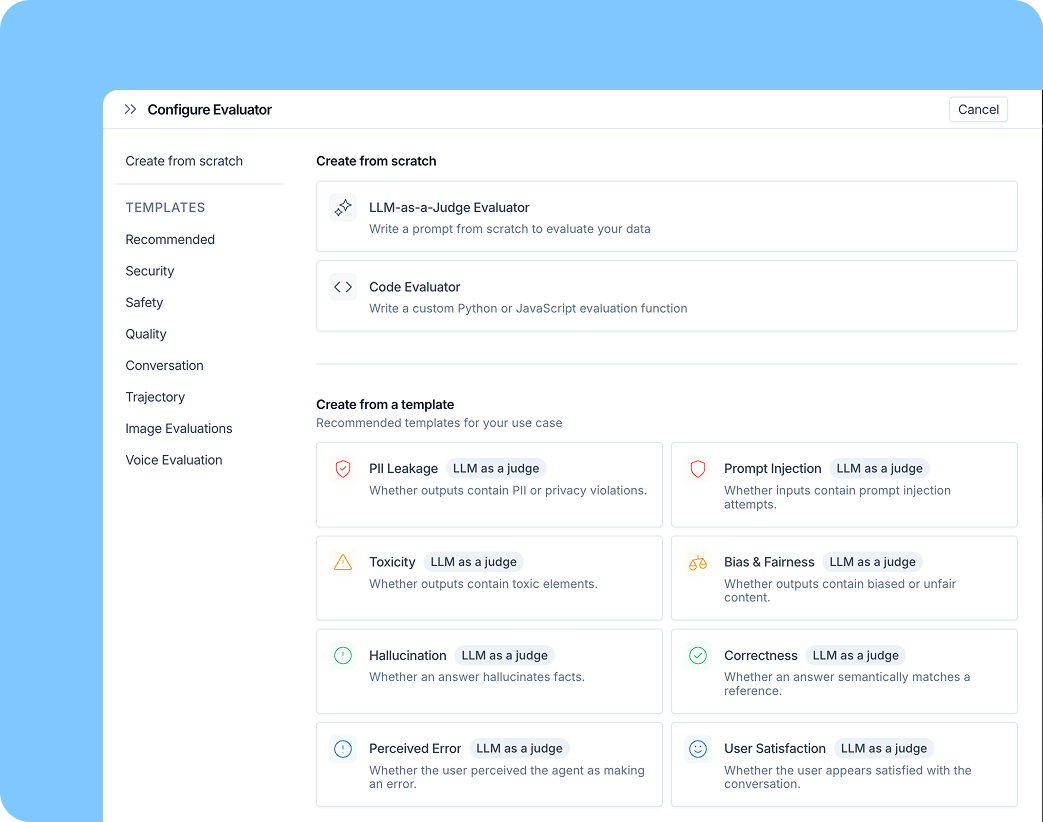
再利用可能な評価者
一度優れた評価者を作成したら、それらを中央で管理する方法が必要です。新しいEvaluatorsタブは、どのプロジェクトにアタッチされているかに関係なく、ワークスペース内のすべての評価者を表示します。トレースプロジェクトでフィルタリングでき、既存の評価者を数秒で新しいプロジェクトにアタッチできます。
組織全体で評価の品質を管理するチーム(安全性チェックの定義、品質指標の標準化など)の場合、評価者を一度作成してどこにでも適用できます。すべてのトレースプロジェクトで同じ安全性評価者の別々のコピーを維持する必要はありません。
特定のトレーシングプロジェクトで作業する個人エンジニアにとって、体験はシンプルに保たれます:トレーシングビューからプロジェクトスコープのevaluatorを迅速に追加および構成できます。
例として、テンプレートからプロンプトインジェクションevaluatorを構築するとします。プロンプトを調整し、サンプルデータに対して検証し、良好に動作することを確認します。再利用可能なevaluatorを使用すると、1つの場所からすべての本番トレーシングプロジェクトにこれをアタッチできます。プロンプトを改善した場合、その更新はすべての場所に適用されます。
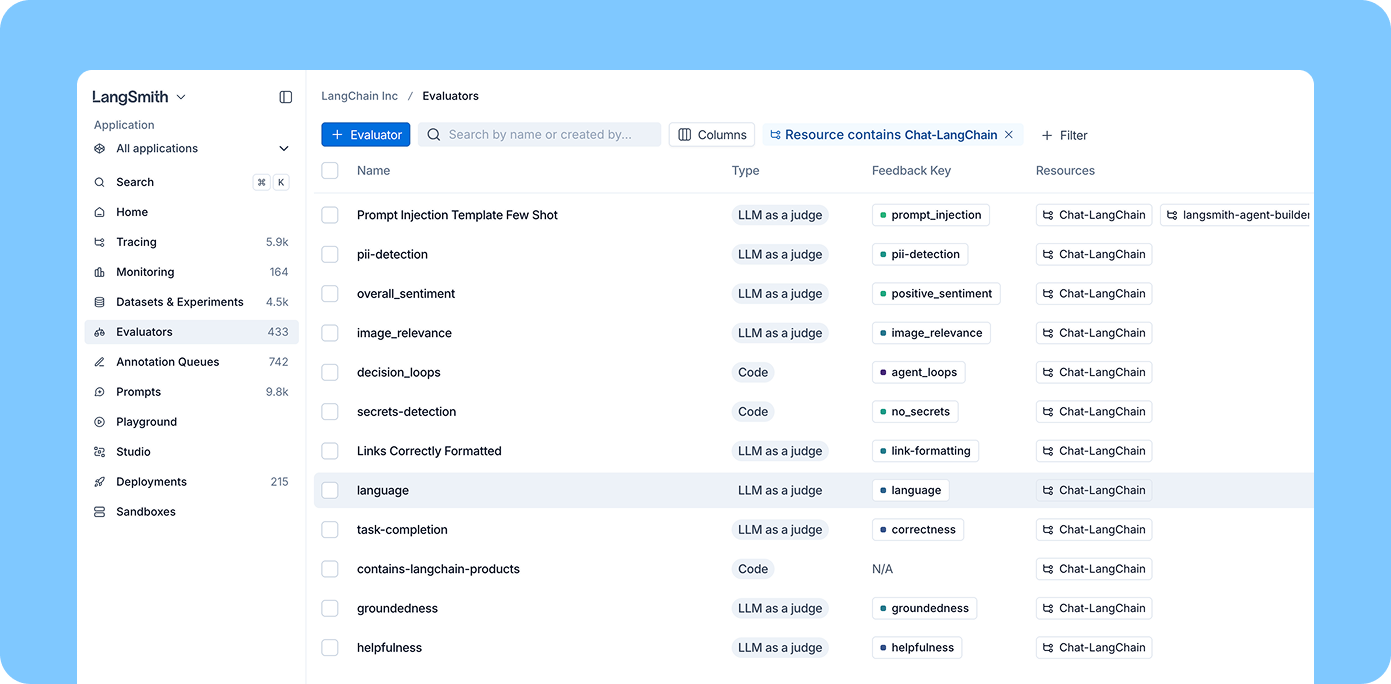
今後の予定
新しい機能をお試しの場合、どのように機能しているかお知らせください。次は、評価のコストを追跡し、それに応じて予算を設定できるようにする「支出の可視化(spend visibility)」を追加します。
関連コンテンツ

ケーススタディ
LangSmith
How Credit Genie used Insights Agent to improve their AI financial assistant




D. Li,
J. Ngai,
G. Lozano Palacio,
C. Yuan
2026年4月20日
5分

LangSmith
観測可能性と評価(Observability & Evals)
エージェント改善ループにおける人間の判断

Rahul Verma
2026年4月9日
11分

観測可能性と評価(Observability & Evals)
より良いHarness:Evalsを用いたHarnessのヒルクライミングのためのレシピ

Vivek Trivedy
2026年4月8日
8分

エージェントの実際の動作を可視化する
LangSmithは、当社のエージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの意思決定をデバッグし、評価(eval)の変更を確認し、ワンクリックでデプロイすることを支援します。
原文を表示
Key Takeaways
- Evaluator templates give you a running start. LangSmith now includes 30+ templates covering safety, response quality, trajectory, user behavior, and multimodal evaluation. Use them as-is or customize them — they work for both online monitoring and offline experiment runs.
- Build an evaluator once, apply it everywhere. A new Evaluators tab centralizes every evaluator in your workspace. You can attach an existing evaluator to a new tracing project in seconds, so your safety checks and quality metrics stay consistent across the org without maintaining duplicate copies.
- Good evals require coverage at multiple levels. A single evaluator checking the final answer won't catch whether your retrieval agent pulled the right documents or your planning agent delegated correctly. Effective agent evaluation means testing individual steps, full trajectories, multi-turn conversations, and specific tool calls within a trace.
Today, we're releasing two updates to LangSmith Evaluation: reusable evaluators and an evaluator template library.
Reusable evaluators give you a single place to view, manage, and apply evaluators across multiple tracing projects. Evaluator templates give teams a running start on testing and monitoring agents without building everything from scratch.
Where evaluations get stuck
Figuring out what "good" looks like is one of the hardest problems when building agents. Your agent might call the right tool but format the response poorly. It might handle single-turn interactions well but fall apart over a multi-turn conversation. And a single evaluator that checks the final answer won't tell you whether your retrieval agent pulled the right documents or whether your planning agent chose the right subagent to delegate to. You need evals at different levels: individual steps, full trajectories, entire conversations, and sometimes specific tool calls within a trace.
Building evaluators across those levels can take weeks. You write a prompt, check the scores against real data, tune it, and repeat. That iteration is important, but when you're starting from scratch every time, it's time spent on the basics instead of improving your agent. And once you've built a good evaluator, you’ll want to apply it across tracing projects without maintaining separate copies.
We've been building evaluation tooling in LangSmith for over a year, from openevals evaluator framework to Align Evals for evaluator calibration to multimodal evaluator support. Today's release adds two features we've heard the most demand for.
Evaluator templates
We've worked with a lot of teams running agents in production, and the same evaluation questions keep coming up: is the agent safe? Is the response actually good? Did it take the right steps to get there?
Templates cover the categories we see come up most often:
- Safety and security: prompt injection detection, PII checks, bias and toxicity
- Response quality: correctness, helpfulness, tone
- Trajectory: did the agent take the right steps?
- User behavior analysis: language distribution, satisfaction signals
- Multimodal: voice and image review
These are a few of the 30+ evaluator templates available. Templates include LLM-as-judge evaluators with tuned prompts and rule-based code evaluators. Use them as-is or customize for your agent.
They work for both online and offline evaluation. For online evaluation, templates help you categorize production traffic: detecting prompt injections, flagging unexpected user behavior, or surfacing traces that need human review. You can use your corrections to tune the evaluator prompt so it performs better next time
For offline evaluation, templates give you a starting point for running experiments across your datasets. Run the evaluator, check scores, filter down to failures, and understand what went wrong.
These templates are also available in openevals v0.2.0, released today, with new multimodal support for evaluating voice and image outputs. You can use them directly in code or through the LangSmith UI.
Reusable evaluators
Once you've built evaluators that work well, you need a way to manage them centrally. A new Evaluators tab surfaces every evaluator in your workspace, regardless of which project it's attached to. You can filter by tracing project and attach an existing evaluator to a new project in seconds.
If your team owns evaluation quality across the org (defining safety checks, standardizing quality metrics), you can build evaluators once and apply them everywhere. No more maintaining separate copies of the same safety evaluator across every tracing project.
For individual engineers working in a specific tracing project, the experience stays simple: you can quickly add and configure evaluators scoped to your project from the tracing view.
As an example, say you build a prompt injection evaluator from a template. You tune the prompt, validate it against sample data, and it works well. With reusable evaluators, you attach it to every production tracing project from one place. When you improve the prompt, the update applies everywhere.
What's coming next
If you try out the new features, let us know how they're working for you. Next up, we're adding spend visibility so you can track what evaluations are costing you and set budgets accordingly.
Related content
Case Studies
LangSmith
How Credit Genie used Insights Agent to improve their AI financial assistant
D. Li,
J. Ngai,
G. Lozano Palacio,
C. Yuan
April 20, 2026
5
min
LangSmith
Observability & Evals
Human judgment in the agent improvement loop
Rahul Verma
April 9, 2026
11
min
Observability & Evals
Better Harness: A Recipe for Harness Hill-Climbing with Evals
Vivek Trivedy
April 8, 2026
8
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
本番環境におけるディープエージェントのランタイム基盤
長期動作するエージェントの本番デプロイには専用インフラが必要である。本ガイドは、耐久性のある実行、メモリ管理、人間による監督(HITL)、観測可能性について解説し、「deepagents」がこれらを本番環境に展開する方法を示す。
AI エージェントに専用コンピューターを付与する
LangChain は、数百万のタスクを実行する AI エージェントが安全かつ効率的に動作するために、各エージェントに個別のファイルシステムやシェル環境を持つ仮想コンピューターを提供するインフラシフトの必要性を提唱している。
Google Colab CLI の紹介
Google は、開発者や AI エージェントがローカル端末からリモート Colab ランタイムに接続し、高機能 GPU を要求して Python スクリプトをシームレスに実行できる新ツール「Google Colab CLI」を発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み