GuideslyがAWS上でアウトドアガイド向けAI生成旅行レポートを構築した方法
Guidesly社は、AWS上でサーバーレスに構築した「Jack AI」を活用し、アウトドアガイドの旅行データ・写真・動画を自動的にマーケティング用コンテンツに変換するエンドツーエンドの自動化システムを開発し、ガイドの業務負荷を軽減している。
キーポイント
業界課題の解決
アウトドアガイドはマーケティングやコンテンツ作成に多大な時間を費やしており、発見されにくさと業務負荷が成長の障壁となっていた。
Jack AIの自律的動作
汎用AIツールとは異なり、Jack AIは旅行後に自動的に起動し、生データを処理してウェブサイト、SNS、メール向けの完成されたコンテンツを生成する。
AWSを基盤とした技術アーキテクチャ
AWS Lambda、Step Functions、S3、RDS、SageMaker、Bedrockなどのサービスを組み合わせ、メディアの取り込み、文脈付与、コンピュータビジョン、生成AIの適用、マルチチャネル公開を実現している。
垂直統合型AI SaaSとしての価値
Guideslyは単なる予約プラットフォームを超え、予約、決済、ウェブサイト、顧客管理、マーケティングを一つのシステムで提供する垂直統合型AI SaaSに進化した。
重要な引用
Guidesly is reshaping how outdoor recreation is booked, run, and experienced.
Unlike general-purpose AI tools that require constant prompting and oversight, Jack AI works in the background on its own.
It activates automatically after each trip, transforming raw data, photos, and videos into polished, ready-to-publish content across websites, social media, and email.
Running serverless on AWS, it scales automatically to deliver consistent content at speed, allowing guides to focus on their trips rather than administrative work.
影響分析・編集コメントを表示
影響分析
この記事は、生成AIが特定業界の具体的な業務課題を解決する実用的な応用例を示しており、AIの産業実装における成熟度の高まりを反映している。AWSを基盤としたサーバーレスアーキテクチャの採用は、中小企業やスタートアップでもスケーラブルなAIシステムを構築できる可能性を示唆しており、業界全体のAI導入を加速させる可能性がある。
編集コメント
業界特化型の生成AI応用例として非常に示唆に富む。AWSサービスを効果的に組み合わせた実装詳細は、同様の課題を抱える他業界への応用可能性も感じさせる。
これは、GuideslyのDavid Lord、Taylor Lord、Shiva Prasad、Anup Banasavalli Hiriyanagowda、Nikhil Chandraによるゲスト投稿です。
Guideslyは、アウトドアレクリエーションの予約、運営、体験の方法を再構築しています。 2019年に設立されたGuideslyは、釣り愛好家、ハンター、ダイバー、アウトドアレクリエーションの愛好家を、信頼できるガイド、ダイショップ、チャーター手配業者と結びつける方法として始まりました。その後、業界全体をカバーする垂直分野特化型のAIソフトウェア・アズ・ア・サービス(SaaS: Software as a Service)システムへと成長しました。Guidesly Proを利用することで、アウトドアのプロフェッショナルは、予約、決済、ウェブサイト、クライアント管理、マーケティングなど、事業のあらゆる側面を単一のシステムで支えるビジネスソリューションを手に入れることができます。
多くのガイドにとって、最も困難な課題は、オンライン上で存在を認知され、雑音の中で目立つことです。何をすべきかを知っている人でも、ウェブサイトの更新、ソーシャルメディアへの投稿、メールキャンペーンの実行に1日最大8時間を費やすことがあります。これらのチャネルで一貫した実行が行われない場合、可視性は低下し、小規模な事業者はマーケティングチームを持つ競合他社に遅れを取り、成長と予約に直接影響する機会を逃すリスクがあります。
この課題に対応するために生み出されたのが Jack AI です。当初から Guidesly は、AI を単なるツールとしてではなく、ガイドたちが日々直面する情報孤立(サイロ)を解消し、予約、データ、コンテンツ、クライアントとの関わり、マーケティングを一つのインテリジェントなフローに統合する手段として捉えていました。このビジョンは自動化を超えたものでした。それは、ガイドたちが時間を割けない重い作業を静かに処理し、共に働く真のパートナーを生み出すことでした。
text 常なるプロンプトや監視を必要とする汎用 AI ツールとは異なり、Jack AI はバックグラウンドで自律的に動作します。各トリップ終了後に自動的に起動し、生データや写真、動画から、ウェブサイト、ソーシャルメディア、メール向けに公開準備が整った洗練されたコンテンツへと変換します。AWS 上でサーバーレスで稼働し、自動的にスケーリングして高速かつ一貫性のあるコンテンツ配信を実現するため、ガイドは行政業務ではなくトリップそのものに集中できます。
text この記事では、このエンドツーエンドの自動化を可能にする Jack AI の AWS 上での構築方法について解説します。AWS Lambda、AWS Step Functions、Amazon Simple Storage Service (Amazon S3)、Amazon Relational Database Service (Amazon RDS)、Amazon SageMaker AI、そして Amazon Bedrock といったサービスが、トリップメディアの取り込み、コンテキストによるエンリッチメント、コンピュータビジョンおよび生成 AI の適用、そして複数のチャネルへのマーケティング対応コンテンツの公開を、安全かつ信頼性高く、大規模にどのように実現しているかを探ります。
課題:ガイドをマーケティング業務から解放する
アウトドアガイドにとっての真の目標は、本当に記憶に残る体験を提供することですが、魅力的なコンテンツを作成することは依然として重要かつ時間のかかる作業です。各ツアーで数十枚の写真やストーリーが生まれますが、それらを魅力的なマーケティング素材に変換するのは難しい課題です。
- 種の同定と旅行の詳細の特定 – ガイドは数えきれないほどの写真を撮影しますが、種、サイズ、技術、場所を手動でタグ付けするのは骨の折れる作業です。詳細が欠けていると、投稿は情報量が不足し、潜在的な顧客にとって魅力的ではなくなります。
- 適切なトーンの捕捉 – すべてのガイドには、地域の専門用語、独自のストーリーテリング、そして水上や野外での長年の経験によって形作られたユニークなスタイルがあります。一般的でなく、ズレていないように感じられる、本物らしいコンテンツを書くことは、スケーラビリティを考えるとほぼ不可能です。
- SEO(検索エンジン最適化)への対応 – キーワードを豊富に含み、地域に最適化されたコンテンツを一貫して作成することは、プロのマーケターにとっても困難です。忙しいガイドにとって、SEO の機会を逃すことは、発見可能性の低下と予約数の減少を意味します。
- 複数のチャネルの管理 – 旅行報告書のページ、ブログ、Instagram のキャプション、Facebook の投稿、そしてメールニュースレターなど、すべてに注意を払う必要がありました。これらのリソースを手動で更新することは、毎週何時間も執筆、編集、フォーマティングにかかることを意味しました。
- 水上での時間の犠牲 – ラップトップに向かう時間は、顧客へのガイド業務から奪われる時間です。小規模なビジネスにとって、このトレードオフは収益と顧客体験の両方に影響を与えます。
ガイドが最善を尽くしても、手動のプロセスは正確でも速くもなく、顧客の需要、現代のマーケティングニーズ、そしてメールを通じて顧客とつながり続けるという重要な必要性に対応するには至りませんでした。そこで登場するのが Guidesly の Jack AI です – コンテンツ作成、SEO 最適化、メールマーケティング、マルチチャネル配信を自動化し、ガイドが彼らが愛することに集中できるようにします:忘れられないアウトドア体験の提供。
ソリューションの概要:Jack AI
Jack AI を実現するために、Guidesly は AWS 上で完全に自動化されたサーバーレスの AI 駆動型マーケティングワークフローを実装しました。このシステムは、生のトリップデータを公開可能なコンテンツへと変換するよう設計されています。これにより、ガイドは卓越したアウトドア体験の提供に集中しながら、ウェブサイト、ソーシャルメディア、メールキャンペーン across で一貫性のある本格的なデジタルプレゼンスを維持できます。
以下の図は、当社のパイプラインを示しています:
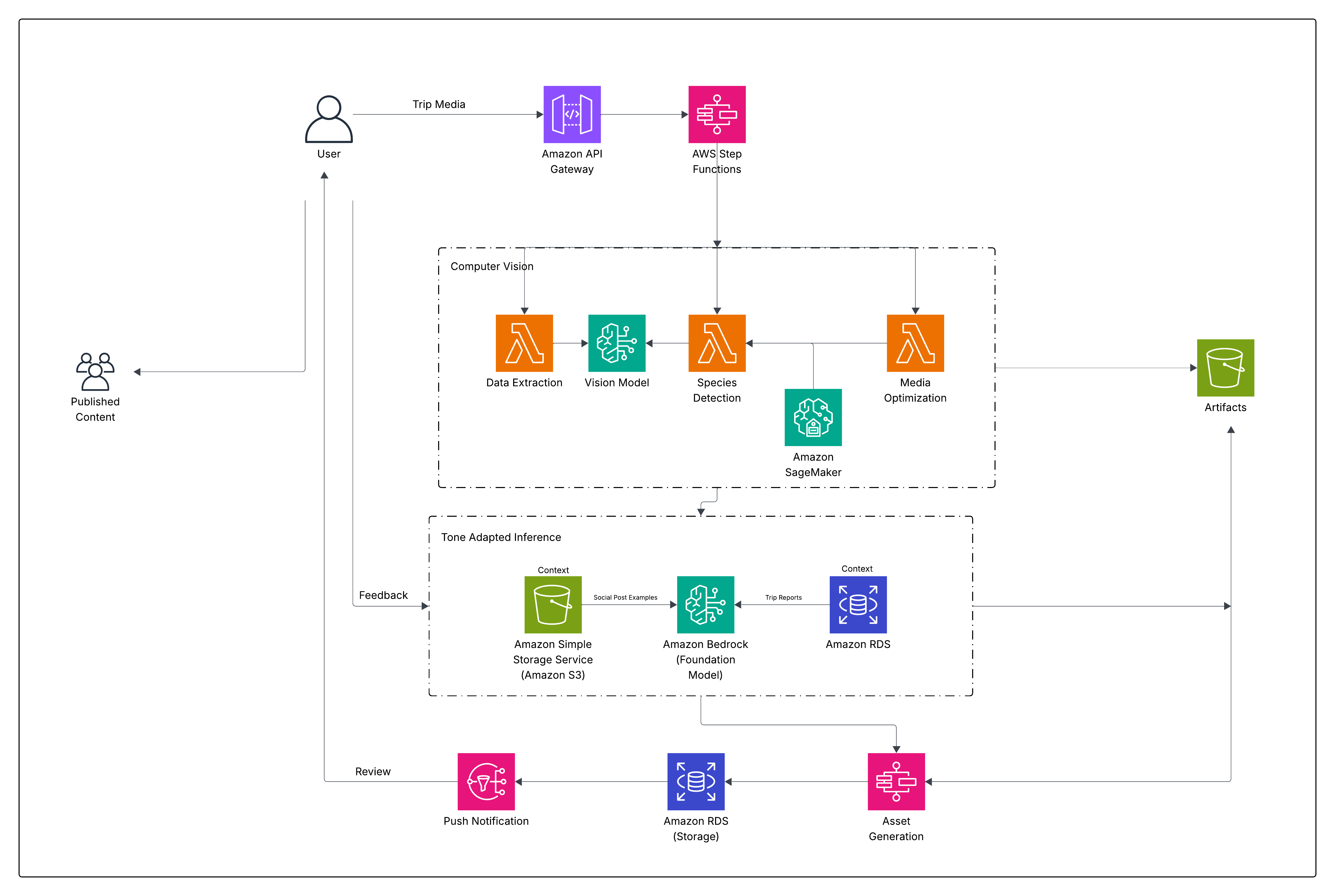
トリップメディアの取り込み – Amazon API Gateway:
- 自動トリガー:ガイドがアップロードしたトリップの写真や動画は Amazon API Gateway を通じてシステムに入力され、即座にオーケストレーションパイプラインを起動します。
- 新鮮なコンテンツの配信:メディアはアップロードされた直後に処理されるため、トリップが記憶に新しいうちに、ソーシャル投稿やメールキャンペーンが視聴者に届きます。
パイプラインのオーケストレーション
AWS Step Functions がワークフローを管理し、データ抽出や魚の検出からメディアの改善、コンテンツ生成、公開に至る各段階で AWS Lambda 関数を呼び出します。
- メディアからのデータ抽出
自動メタデータキャプチャ:ガイドが写真や動画をアップロードすると、システムはGPS座標、タイムスタンプ、デバイス設定などを含む埋め込まれたEXIFメタデータ(EXIF Metadata)を抽出します。
- 文脈の強化:抽出された地理空間情報は、同じ時刻と場所に関連する気象および水質条件のデータと組み合わせられます。これにより、潮位、水温、風速、雲量などの詳細——それ以外では失われてしまう可能性のあるコンテキスト——が捉えられます。
- 豊かなストーリーテリング:各トリップを、撮影された内容だけでなく実際の環境条件に基づけることで、ガイドの追加努力を必要とせず、よりパーソナライズされ、真実味があり、魅力的なコンテンツが生成されます。
- スケーラブルな一貫性:単一の画像から数百枚の画像まで処理する場合、自動化によりすべてのメディアアーティファクトが高品質なコンテキストデータで強化され、下流プロセスに対する信頼性の高い入力が提供されます。
- コンピュータビジョンを用いた魚種の検出
魚種の識別は、Jack AIシステムの主要な機能の一つです。課題は、現実世界の画像で魚を検出することだけでなく、ボート、ドック、湖、沖合など、非常に多様な環境にわたる数百の種を正確に分類することです。
これに対処するため、私たちはカスタムトレーニング済みのコンピュータビジョンモデルと、AWS サービスを通じて利用可能なファウンデーションビジョンモデルを組み合わせたマルチレイヤーコンピュータビジョンパイプラインを設計しました。
実験とモデル開発
私たちのモデル開発ワークフローは、実験環境としてJupyterLabを使用するAmazon SageMaker AI内で主に実行されます。
この構成により、以下が可能になります:
- 新しいコンピュータビジョンアーキテクチャの迅速なプロトタイピング
- GPU搭載インスタンスでの大規模トレーニングジョンの実行
- 複数の魚類分類ベンチマークにおけるモデルの評価
- モデルの改善と本番環境へのデプロイメント間の迅速な反復
SageMaker AI環境は、データセット、トレーニングスクリプト、モデル実験を管理する中核ハブとして機能します。
データセットとトレーニングの課題
魚種の識別は、多数の種が存在しデータ分布が偏っているため、ユニークな機械学習(ML)の課題となります。私たちのシステムは現在、以下の組み合わせから収集された400以上の魚種クラスをサポートしています:
- Guideslyシステムからの独自漁業レポート画像
- ユーザー提出の釣り写真
- パートナーソースから収集されたキュレーション済みデータセット
人気のある種には数千のトレーニング例がありますが、多くの種はラベル付き画像が限られており、従来の教師あり学習アプローチを困難にしています。
この不均衡に対処するため、私たちはハイブリッドトレーニング戦略を使用します:
- 大量のデータセットを持つ種に対する標準的な教師あり学習
- トレーニングデータの限られた希少種に対するワンショットおよびフューショット学習技術
これにより、すべての種に対して大規模なデータセットを必要とすることなく、分類のカバレッジを拡張することができます。
多層ビジョンパイプライン
単一のモデルに依存するのではなく、物体検出と種の分類を分離する二段階のビジョンアーキテクチャを実装しました。
検出レイヤー
第一段階では、釣り画像内の関連する物体を識別するように訓練されたYOLOベースの物体検出モデルを使用します。対象となるのは以下です:
- 魚
- 釣り具
- 人物
- 船および環境の文脈
検出モデルは各物体の境界ボックスを特定します。次のステージに画像全体を渡すのではなく、検出された魚の領域のみを切り抜きます。このアプローチは、分類モデルを混乱させる可能性のある無関係な背景要素を除去するため、分類精度を大幅に向上させます。
分類レイヤー
切り抜かれた各魚の画像は、その後、専門的な分類モデルに渡されます。開発過程において、私たちは以下のいくつかのアーキテクチャを試験しました:
- 畳み込みニューラルネットワーク(Convolutional Neural Networks: CNNs)
- 強力なベースライン分類のためのResNetベースモデル
- 長尾種の認識におけるワンショットおよびフューショット学習モデル
これらのアーキテクチャの組み合わせにより、数百種のクラス全体で精度、推論速度、トレーニング効率のバランスを取ることができます。
ハイブリッドビジョン+ファウンデーションモデルアプローチ
カスタムトレーニング済みモデルに加え、Amazon Bedrockを通じて利用可能なマルチモーダルファウンデーションモデル(Foundation Models: FMs)を統合し、追加の推論と文脈的理解を提供しています。
しかし、生のビジョンモデルは時としてハルシネーションを起こしたり、視覚シーンを誤解したりすることがあります。このリスクを軽減するため、画像をファウンデーションモデルに送信する前に、いくつかの前処理ステップを適用しています:
- 画像前処理
検出された魚の領域の切り抜き
- 画像寸法の正規化
- 不要な背景の除去
- コンテキストの強化
メディアメタデータ(場所、水域、時間)
- 既知の種分布
- 検出モデルの出力
- 構造化されたシステムプロンプト
画像に関する文脈情報をモデルに提供
- 可能な種の予測を制限
このハイブリッドアプローチにより、ドメイン固有の分類器の精度と大規模ビジョンモデルの推論能力を組み合わせることができます。
研究から本番環境へ
モデルの検証が完了した後、Amazon SageMaker AI上の管理されたエンドポイントを使用してデプロイします。これにより、以下のことが可能になります:
- アップロードされた画像に対するリアルタイム推論
- 大量のメディアに対する自動スケーリング
- モデルの継続的な監視と更新
その結果、Guidesly のシステム全体で数千枚の釣り画像を処理できるスケーラブルなビジョンシステムが構築され、複雑な現実世界の条件においても信頼性の高い魚種の検出を実現しています。
- 迅速な Web 向け公開のためのメディア最適化
魚種の検出と文脈情報の付与が完了した後、Jack AI は実際の公開に向けてメディアの準備に注力します。ガイドによってアップロードされた高解像度の写真や動画は、ウェブサイト、ソーシャルネットワーク、メールキャンペーン across で使用されることを目的とした最適化された Web 対応アセットに自動的に処理されます。この最適化パイプラインは、圧縮、リサイズ、フォーマット変換をバックグラウンドで処理します。これにより、視覚的な品質を損なうことなくメディアファイルの軽量化が保証されます。ワークフローの初期段階でアセットを標準化することで、手動での画像編集の必要性を排除し、デバイスやシステム間で一貫したプレゼンテーションを維持しています。
改善されたメディアは、Amazon S3 バケット内でバージョン管理されたアーティファクトとして保存され、タグ付けによって容易な検索と再利用が可能になっています。これらのアセットは、SEO 用のページ、旅行レポート、ニュースレター、ソーシャルメディア投稿など、複数の場所で再処理することなく繰り返し表示できるため、公開パイプラインの高速化と効率化が実現します。パフォーマンス向上に加え、このステップは SEO 目標にも貢献しています。読み込み速度の速い画像は検索順位を向上させ、ユーザー体験を強化し、ガイドウェブサイトの直帰率を低下させる効果があります。
- トーン改善
生成された旅行レポートが、釣りガイドの自然な声に合致し、真実味のあるものになるよう保証するために、コンテンツ生成パイプライン内に「トーン改善レイヤー」が導入されました。このシステムは、ファインチューニングを通じて基盤となる言語モデル自体を変更するのではなく、コンテキスト入力と構造化されたプロンプトを通じてトーンを改善します。これにより、ガイドたちが用いる独自のストーリーテリングスタイルを維持しつつ、スケーラビリティと運用の簡素性を確保しています。
このアプローチの基盤はコンテキストインジェクションです。構造化された旅行メタデータがモデルのプロンプトに直接埋め込まれ、正確で関連性の高い物語を生成するために必要な grounding context(根拠となる文脈)を提供します。これに加えて、過去の旅行報告書やガイド固有の表現パターンが検索され、参照例として含まれます。これにより、モデルはガイドが自然に旅行記録に持ち込む語彙、リズム、描写スタイルを模倣することができます。カスタムモデルのトレーニングではなく、注意深く設計されたプロンプトによって、基盤モデルが期待されるトーンを反映した出力へと導かれます。これにより、ファインチューニングされたモデルの維持に伴う運用オーバーヘッドなしで、書き方のスタイルを動的に調整することが可能になります。捏造された詳細を避けるため、生成プロセスは提供されたメタデータとコンテキスト入力に厳密に制限されます。モデルには、ソースデータにない追加の種、技術、天気、または場所といった欠落情報を推論しないよう指示されており、すべての報告書が実際の旅行記録と一貫していることが保証されます。
生成処理自体は Amazon Bedrock の大規模言語モデル(FMs)を使用して実行され、コンテキスト入力と構造化されたプロンプトを処理して、大規模かつ一貫性のあるドメイン固有のレポートを生成します。モデルの再学習ではなくコンテキストプロンプティングに依存することで、このシステムはトレーニングインフラを不要とし、運用オーバーヘッドを削減し、新しいガイドレポートやドメインパターンが登場しても迅速な反復が可能になります。このアプローチは、システムが必要としていたバランス、つまり信頼性、コスト効率、そしてシステムの拡大に伴うスケーラビリティを備えた本格的なガイドスタイルのトリップレポートを提供するという点で、最適な選択でした。
公開パイプライン
コンテンツが生成され、トーンが改善・調整された後、公開パイプラインはすべての要素を統合して、各チャネル向けにマーケティング準備が完了したアセットを提供します。この段階は、最小限の手動作業でエンドツーエンドで実行されるように設計されており、自動化が裏側で処理を実行する一方で、ガイドは常に最新情報を把握できることを保証しています。
アセットの生成は、複数の AWS Lambda 実行を調整する「Assets Generation Step Function(アセット生成ステップ関数)」を通じて処理されます。これらの関数は、各トリップの S3 バケットに保存された成果物からマーケティング用成果物を生成します。これには、SEO 対応のトリップレポート、新鮮なウェブサイトコンテンツ、ソーシャルメディア投稿、パーソナライズされたメールキャンペーンが含まれます。出力はシステムに自動的に保存され、後続の公開ワークフローと統合されるため、手動でのドラフト作成、コピーライティング、またはフォーマットの必要性が軽減されます。アセットの準備が整うと、ガイドにはレビュー用のプッシュ通知が届き、不要な運用オーバーヘッドなしで情報を把握し続けることができます。
処理された成果物(改善されたメディア、抽出されたトリップの詳細、生成されたマーケティングアセット)は、Amazon RDS と Amazon S3 を使用して中央に保存されます。Amazon S3 はメディアと生成コンテンツに対して耐久性が高くコスト効果の高いストレージを提供し、Amazon RDS は後続のワークフローやレポートのために構造化されたトリップおよびガイドデータを可能にします。これらのサービスは、追加の処理を必要とせずに、ウェブサイト、ソーシャルチャネル、メールキャンペーン across でアセットがすぐに再利用可能であることを保証します。
公開制御は、AI 駆動の自動化を通じて柔軟に維持されます。ガイドは生成されたコンテンツを確認・承認したり、改良を要求したり、または完全な自動化のためにビルトインの自動公開スイッチを使用したりすることができます。この柔軟性により、各ガイドは必要に応じて手動で品質管理を行いながら効率性を確保するか、あるいは「設定して放置」のアプローチを選択するというバランスを取ることができます。裏側では、AWS Step Functions が複数の AWS Lambda 関数の実行をオーケストレーションし、最小限のインフラストラクチャ管理で数百人のガイドに対応できるよう自動的にスケーリングします。
コストの考慮事項
アーキテクチャは自動的にスケーリングするように設計されていますが、生成された旅行報告書あたりのコストは比較的小さなままです。典型的なシナリオでは、メディア処理、コンピュータビジョン推論、コンテンツ生成を含む完全な報告書の生成には、報告書あたり約 0.10 ドルから 0.50 ドルのコストがかかります。最終的なコストは、処理される画像の数、動画メディアの有無、AI 推論リクエストの量などの要因によって異なります。ワークフローはサーバーレスかつイベント駆動であるため、ガイドは報告書が生成された場合にのみコストが発生し、利用が増加しても単体経済性は予測可能に保たれます。
アウトドアレクリエーションマーケティングへの影響
Jack AIがAWS上でエンドツーエンドで稼働することで、その影響は自動化を超え、アウトドアレクリエーションマーケティングが日常的にどのように実行されるかという点にも及びます。AI駆動の自動化とAWSサービスを組み合わせることで、マーケティングコンテンツの生成、推敲、公開のプロセスが、単一の反復可能なワークフローに集約されました。アウトドアレクリエーションのガイドはもはや、トリップレポートの下書き作成や画像のフォーマット、ソーシャルメディア投稿のスケジュール調整に数時間を費やす必要はありません。代わりにこれらのタスクは自動的に処理され、ガイドは最も重要なことに集中できるようになります:すなわち、クライアントおよびアウトドア体験そのものです。
結果
その成果は、ウェブサイト、ソーシャルメディア、メールキャンペーン全体で一貫性のある高品質なデジタルプレゼンスです。ガイドは専用のマーケティングスタッフを必要とせずとも、可視性を高め、検索順位を強化し、より効果的に顧客とエンゲージメントを深めることができます。
原文を表示
*This is guest post by David Lord, Taylor Lord, Shiva Prasad, Anup Banasavalli Hiriyanagowda, Nikhil Chandra from Guidesly.*
Guidesly is reshaping how outdoor recreation is booked, run, and experienced. Founded in 2019, it began as a way to connect anglers, hunters, divers, and outdoor recreation enthusiasts with trusted guides, dive shops, and charters. It has since grown into a vertical AI software as a service (SaaS) system serving the entire industry. With Guidesly Pro, outdoor professionals gain a business solution that powers every part of their operation—bookings, payments, websites, client management, and marketing—all from a single system.
For many guides, the toughest challenge is getting discovered and cutting through the noise online. Even those who know what must be done can spend up to eight hours a day updating websites, posting on social media, and running email campaigns. Without consistent execution across these channels, visibility drops, and smaller operators risk falling behind competitors with full marketing team-missed opportunities that directly impact growth and bookings.
It was addressing this problem that Jack AI was born. From the start, Guidesly saw AI not only as a tool, but as a way to connect the silos that guides face every day—uniting bookings, data, content, client engagement, and marketing into one intelligent flow. The vision went beyond automation. It was about creating a true partner that works alongside guides, quietly handling the heavy lifting they don’t have time for.
Unlike general-purpose AI tools that require constant prompting and oversight, Jack AI works in the background on its own. It activates automatically after each trip, transforming raw data, photos, and videos into polished, ready-to-publish content across websites, social media, and email. Running serverless on AWS, it scales automatically to deliver consistent content at speed, allowing guides to focus on their trips rather than administrative work.
In this post, we walk through how Jack AI is built on AWS to power this end-to-end automation. We explore how services such as AWS Lambda, AWS Step Functions, Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), Amazon SageMaker AI, and Amazon Bedrock come together to ingest trip media, enrich it with context, apply computer vision and generative AI, and publish marketing-ready content across multiple channels—securely, reliably, and at scale.
The challenge: Freeing guides from marketing operations
For outdoor guides, the real goal is delivering truly memorable experiences, but creating engaging content remains a critical and time-consuming task. Each trip produces dozens of photos and stories, yet turning them into compelling marketing is a challenge:
- Identifying species and trip details – Guides capture countless photos, but manually tagging species, sizes, techniques, and locations is painstaking. Missing details can make posts less informative and less engaging for potential clients.
- Capturing the right voice – Every guide has a unique style shaped by local jargon, personal storytelling, and years on the water or in the field. Writing content that feels authentic—without sounding generic or mismatched—is nearly impossible to scale.
- Keeping up with SEO – Consistently producing keyword-rich, locally improved content is challenging even for professional marketers. For busy guides, missed SEO opportunities mean lower discoverability and fewer bookings.
- Managing multiple channels – Trip report pages, blogs, Instagram captions, Facebook posts, and email newsletters all demanded attention. Updating these resources manually meant hours of writing, editing, and formatting every week.
- Sacrificing time on the water – Every hour spent at a laptop is an hour taken away from guiding clients. For small businesses, this tradeoff impacts both revenue and customer experience.
Even with guides doing their best, manual processes weren’t accurate or fast enough to keep pace with client demand, modern marketing needs, and the critical need to stay connected with customers via email. That’s where Guidesly’s Jack AI steps in—automating content creation, SEO optimization, email marketing, and multi-channel distribution, so guides can focus on what they love: delivering unforgettable outdoor experiences.
Overview of the solution: Jack AI
To bring Jack AI to life, Guidesly implemented a fully automated, serverless, AI-driven marketing workflow on AWS, designed to transform raw trip data into ready-to-publish content. This system allows guides to focus on delivering exceptional outdoor experiences while maintaining a consistent, authentic digital presence across websites, social media, and email campaigns.
The following diagram illustrates our pipeline:
Trip media ingestion – Amazon API Gateway:
- Automatic trigger: Trip photos and videos uploaded by guides to enter the system through Amazon API Gateway, which immediately triggers the orchestration pipeline.
- Fresh content delivery: Media is processed as soon as it’s uploaded, enabling social posts and email campaigns to reach audiences while trips are still top of mind.
Pipeline orchestration
AWS Step Functions manage the workflow, invoking AWS Lambda functions for each stage—from data extraction and fish detection to media improvement, content generation, and publishing.
- Data extraction from media
Automatic metadata capture: As soon as guides upload photos and videos, the system extracts embedded EXIF Metadata, including GPS coordinates, timestamps, and device settings.
- Contextual enrichment: The extracted geospatial information is then combined with relevant weather and water condition data for the same time and location. This captures details such as tide levels, water temperature, wind speed, and cloud cover—context that would otherwise be lost.
- Richer storytelling: By grounding each trip in the actual environmental conditions alongside what was caught, the system produces content that is more personalized, authentic, and engaging, without requiring additional effort from the guide.
- Scalable consistency: Whether processing a single image or hundreds, automation makes sure that every media artifact is enriched with high-quality contextual data, providing reliable inputs for downstream processes.
- Fish species detection using computer vision
Fish species identification is one of the core capabilities of the Jack AI system. The challenge is not only detecting fish in real-world images but also accurately classifying hundreds of species across highly variable environments such as boats, docks, lakes, and offshore locations.
To address this, we designed a multilayer computer vision pipeline that combines custom-trained computer vision models with foundation vision models available through AWS services.
Experimentation and model development
Our model development workflow runs primarily inside Amazon SageMaker AI using JupyterLab as the experimentation environment.
With this setup, we can:
- Rapidly prototype new computer vision architectures
- Run large-scale training jobs on GPU-backed instances
- Evaluate models across multiple fish classification benchmarks
- Iterate quickly between model improvements and production deployment
The SageMaker AI environment acts as the central hub where datasets, training scripts, and model experiments are managed.
Dataset and training challenges
Fish identification presents a unique machine learning (ML) challenge due to the large number of species and uneven data distribution. Our system currently supports over 400 fish species classes, collected from a combination of:
- Proprietary fishing report imagery from the Guidesly system
- User-submitted catch photos
- Curated datasets gathered from partner sources
While some popular species have thousands of training examples, many species have limited labeled images, which makes traditional supervised learning approaches difficult.
To address this imbalance, we use a hybrid training strategy:
- Standard supervised learning for species with large datasets
- One-shot and few-shot learning techniques for rare species where training data is limited
This allows the system to expand classification coverage without requiring large datasets for every species.
Multi-layer vision pipeline
Rather than relying on a single model, we implemented a two-stage vision architecture that separates object detection from species classification.
Detection Layer
The first stage uses YOLO-based object detection models trained to identify relevant objects within fishing images, including:
- Fish
- Fishing gear
- People
- Boats and environmental context
The detection models identify bounding boxes for each object. Instead of passing the entire image to the next stage, we crop only the detected fish regions.This approach significantly improves classification accuracy because it removes unrelated background elements that can confuse classification models.
Classification Layer
Each cropped fish image is then passed into a specialized classification model.Over the course of development, we experimented with several architectures including:
- Convolutional neural networks (CNNs)
- ResNet-based models for strong baseline classification
- One-shot and few-shot models for long-tail species recognition
The combination of architectures allows us to balance accuracy, inference speed, and training efficiency across hundreds of species classes.
Hybrid vision + foundation model approach
In addition to our custom-trained models, we integrate multimodal foundation models (FMs) available through Amazon Bedrock to provide additional reasoning and contextual understanding.
However, raw vision models can sometimes hallucinate or misinterpret visual scenes. To reduce this risk, we apply several preprocessing steps before sending images to foundation models:
- Image preprocessing
Cropping detected fish regions
- Normalizing image dimensions
- Removing unnecessary background
- Context enrichment
Media metadata (location, water body, time)
- Known species distribution
- Detection model outputs
- Structured system prompts
Provide the model with contextual information about the image
- Constrain possible species predictions
With this hybrid approach, we can combine the precision of domain-specific classifiers with the reasoning capabilities of large vision models.
From research to production
After the models are validated, we deploy them using managed endpoints on Amazon SageMaker AI. This enables:
- Real-time inference on uploaded images
- Automatic scaling for large volumes of media
- Continuous monitoring and model updates
The result is a scalable vision system capable of processing thousands of fishing images across Guidesly’s system, delivering reliable fish species detection even in complex real-world conditions.
- Media improvement for faster, web-ready publishing
After fish detection and contextual enrichment are complete, Jack AI focuses on preparing media for real-world publishing. High-resolution photos and videos uploaded by guides are automatically processed into optimized, web-ready assets designed for use across websites, social networks, and email campaigns. This improvement pipeline handles compression, resizing, and format conversion behind the scenes. This makes sure that media files remain lightweight without sacrificing visual quality. By standardizing assets early in the workflow, Jack AI removes the need for manual image editing and maintains consistent presentation across devices and systems.
Improved media is stored as versioned artifacts in an Amazon S3 bucket and tagged for straightforward retrieval and reuse. These assets can be surfaced repeatedly across SEO pages, trip reports, newsletters, and social posts without reprocessing, keeping the publishing pipeline fast and efficient. Beyond performance, this step also supports SEO goals—fast-loading images to improve search rankings, enhance user experience, and reduce bounce rates on guide websites.
- Tone improvement
To make sure that generated trip reports feel authentic and aligned with the natural voice of fishing guides, a *Tone Improvement layer* was introduced within the content generation pipeline. Rather than modifying the underlying language model through fine-tuning, the system improves tone through contextual inputs and structured prompting. This preserves the distinctive storytelling style guides use while maintaining scalability and operational simplicity.
The foundation of this approach is context injection. Structured trip metadata is embedded directly into the model prompt, giving the model the grounded context it needs to generate accurate and relevant narratives. Alongside this, historical trip reports and guide-specific phrasing patterns are retrieved and included as reference examples. This helps the model mirror the vocabulary, pacing, and descriptive style that guides naturally bring to documenting their trips. Rather than training a custom model, carefully designed prompts guide the foundation model toward outputs that reflect the expected tone. This allows for dynamic adjustments to writing style without the operational overhead of maintaining fine-tuned models. To avoid fabricated details, the generation process is constrained strictly to the provided metadata and contextual inputs. The model is instructed not to infer missing information like additional species, techniques, weather, or locations absent from the source data, so every report remains consistent with the actual trip record.
Generation itself is executed using Amazon Bedrock FMs, which process the contextual inputs and structured prompts to produce coherent, domain-appropriate reports at scale. By relying on contextual prompting rather than model re-training, the system avoids training infrastructure, reduces operational overhead, and enables rapid iteration as new guide reports and domain patterns emerge. This approach struck the balance that the system needed: authentic, guide-style trip reports delivered with reliability, cost efficiency, and the scalability to grow as the system expands.
Publishing pipeline
After the content is generated, improved, and refined for tone, the publishing pipeline brings everything together to deliver marketing-ready assets across channels. This stage is designed to run end-to-end with minimal manual effort, making sure that guides stay informed while automation handles execution behind the scenes.
Asset generation is handled through an *Assets Generation Step Function* that orchestrates multiple AWS Lambda runs. These functions generate marketing deliverables from the artifacts stored in the S3 bucket for each trip. This includes SEO-friendly trip reports, fresh website content, social media posts, and personalized email campaigns. The outputs are automatically stored in the system and integrated into downstream publishing workflows, reducing the need for manual drafting, copywriting, or formatting. After the assets are ready, guides receive push notifications for review, so they can stay informed without unnecessary operational overhead.
Processed artifacts—including improved media, extracted trip details, and generated marketing assets—are stored centrally using Amazon RDS and Amazon S3. Amazon S3 provides durable, cost-effective storage for media and generated content, while Amazon RDS makes structured trips and guide data available for downstream workflows and reporting. Together, these services make sure that assets are immediately reusable across websites, social channels, and email campaigns without requiring additional processing.
Publishing controls remain flexible through AI-driven automation. Guides can review and approve generated content, request refinements, or rely on a built-in auto-publish toggle for full automation. With this flexibility, each guide can balance quality control with efficiency—remaining hands-on when needed or opting for a *set-and-forget* approach. Behind the scenes, AWS Step Functions orchestrate multiple AWS Lambda function runs, scaling automatically to accommodate hundreds of guides with minimal infrastructure management.
Cost considerations
While the architecture is designed to scale automatically, the cost per generated trip report remains relatively small. In typical scenarios, generating a full report—including media processing, computer vision inference, and content generation—costs approximately $0.10 to $0.50 per report. The final cost varies depending on factors such as the number of images processed, the presence of video media, and the volume of AI inference requests. Because the workflow is serverless and event-driven, guides only incur costs when reports are generated, keeping the unit economics predictable as usage grows.
Impact on outdoor recreation marketing
With Jack AI operating end-to-end on AWS, the impact extends beyond automation and into how outdoor recreation marketing is executed day-to-day. By combining AI-driven automation with AWS services, the process of generating, refining, and publishing marketing content has been reduced to a single, repeatable workflow. Outdoor recreation guides no longer need to spend hours drafting trip reports, formatting images, or scheduling social posts. Instead, these tasks are handled automatically, relieving guides to focus on what matters most: their clients and the outdoor experience itself.
The outcome is a consistent, high-quality digital presence across websites, social media, and email campaigns. Guides improve visibility, strengthen search rankings, and engage customers more effectively without the need for dedicated marketing staff.
Results
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み