AWS TrainiumとvLLMを用いた推測的デコードによるデコード負荷の高いLLM推論の高速化
AWSはvLLMとKubernetesを用いたAWS Trainium2上でのspeculative decodingにより、Qwen3モデルのデコード段階を最大3倍高速化し、生成コストとレイテンシを削減する実証ベンチマークと運用ガイドを提供した。
キーポイント
speculative decodingの動作原理とコスト削減効果
ドラフトモデルが複数のトークンを提案し、ターゲットモデルが一度に検証する仕組みにより、逐次デコードのボトルネックを解消し、ハードウェア利用率とスループットを向上させる。
実運用における最適化パラメータ
ドラフトモデルの選択と `num_speculative_tokens`(speculative token window size)の調整が、ワークロードに応じたパフォーマンス最適化の主要な制御ノブとなる。
ベンチマーク手法とQwen3再現手順
測定環境、評価指標、およびQwen3モデルを用いた結果再現のためのステップバイステップ手順を公開し、実証可能性と透明性を確保している。
デコード集中型ワークロードへの適用
生成トークン数が消費数を大幅に上回るチャットボットやコーディングエージェントなど、デコード段階が推論コストの大部分を占めるアプリケーションに特に有効である。
影響分析・編集コメントを表示
影響分析
AWSの専用ハードウェアTrainium2とオープンソースエコシステム(vLLM, Qwen)を統合し、推論コスト削減の実用的な手法を提示した。これにより、大規模言語モデルの商用展開における経済的ハードルが下がり、特にデコード負荷の高い生成AIアプリケーションの普及を加速させる可能性がある。
編集コメント
編集者視点の一言コメント。AWS固有のハードウェアに限定されるものの、speculative decodingの実装パターンとチューニング指針は業界標準となりつつあり、実務者には即戦力となる技術記事である。
*Qwen3モデルをvLLM、Kubernetes、AWS AIチップでデプロイする際、トークン間レイテンシが短縮されることを示す実用的なベンチマーク。*
AWS Trainiumでのスペキュラティブ・ディコーディングは、デコード処理が中心となるワークロードにおいてトークン生成を最大3倍高速化し、出力トークンあたりのコスト削減と、出力品質を損なうことなくスループット向上を実現します。AIライティングアシスタント、コーディングエージェント、その他の生成AIアプリケーションを構築する場合、ワークロードは消費するトークンよりも大幅に多くのトークンを生成するため、デコード段階が推論コストの大部分を占めることになります。自己回帰的デコーディング(autoregressive decoding)ではトークンが逐次生成されるため、ハードウェアアクセラレータはメモリ帯域幅の制約を受け、十分に活用されません。これにより生成トークンあたりのコストが上昇します。スペキュラティブ・ディコーディングは、小さなドラフトモデル(draft model)が複数のトークンを一度に提案し、ターゲットモデルがそれらを単一の順伝播(forward pass)で検証することで、このボトルネックを解決します。シリアルなデコードステップが減ることでレイテンシが低下し、ハードウェア利用率が向上するため、推論コストの削減に寄与します。
本記事では以下の内容を学びます:
- AWS Trainium2においてスペキュラティブ・ディコーディングがどのように機能し、生成トークンあたりのコスト削減にどう役立つか
- Trainium上でvLLMを用いてスペキュラティブ・ディコーディングを有効にする方法
- パフォーマンス評価に使用したベンチマーク手法
- ワークロード向けにドラフトモデルの選択とスペキュラティブ・トークンウィンドウサイズを調整する方法
- Qwen3を使用して結果を再現するためのステップバイステップの手順
推論の高速化とは何か?
speculative decoding(投機的デコーディング)は、2つのモデルを用いて自己回帰的生成を高速化する手法です。
- ドラフトモデルは、n 個の候補トークンを迅速に提案します。
- ターゲットモデルは、これらを1回の順伝播(フォワードパス)で検証します。
トークンの受け入れや拒否、EAGLEベースの推論、および一般的な speculative decoding の概念を含む詳細なメカニクスについては、AWS Inferentia2 に関するブログ記事 Inferentia2、SageMaker EAGLE のチュートリアル、および この入門記事 を参照してください。ここでは、実際に制御可能な2つのパラメータ、すなわちドラフトモデルと num_speculative_tokens に焦点を当てます。
ドラフトモデルとターゲットモデルは、同じトークナイザーと語彙を共有する必要があります。これは、スペキュラティブ・ディコーディングがターゲットモデルによって直接検証されるトークンID上で動作するためです。同じアーキテクチャ・ファミリーからモデルを選択することをお勧めします。これにより、次のトークンの予測がより頻繁に一致するようになります。異なるアーキテクチャのモデルをペアリングすることも可能ですが、それらが同じトークナイザーを共有している場合に限られます。ただし、ドラフトモデルとターゲットモデル間の一致度が低下すると、受け入れ率が下がり、パフォーマンスの向上効果がほとんど失われます。
ターゲットモデルがドラフト・トークンを受け入れると、それらはシーケンシャルなデコードステップの全コストを発生させることなくコミットされます。あなたが制御できる主要なパラメータは num_speculative_tokens で、これはドラフトモデルが一度に提案するトークンの数を設定します。この値を増やすと、検証パスごとにスキップできるシリアル・デコードステップの数が増え、受け入れ率が高い場合にトークン間レイテンシ(inter-token latency)を直接削減できます。
このパフォーマンス向上は、2つの効果によるものです。まず、スペキュラティブ・ディコーディング(speculative decoding)はターゲットモデルのデコードステップ数を削減し、KVキャッシュ(KV cache:過去トークンのキーおよびバテンソルを格納するメモリ領域)へのアクセス回数を減らします。各デコードステップはメモリからキャッシュ全体を読み取るため、デコード処理はメモリアクセスがボトルネックとなります。第二に、スペキュラティブ・ディコーディングはデコード時のハードウェア利用率を向上させます。標準的な自己回帰型デコーディングでは、各ステップで1つの新しいトークンしか生成されず、アクセラレータは高コストな行列乗算カーネルを起動して1トークン分の処理を行うため、プロセッシングエレメントエンジンが大半unusedのままになります。一方、検証フェーズではターゲットモデルが一度にn個のトークンを処理するため、メモリアクセスのコストを分散させ、小さく非効率な単一トークン計算のシーケンスを、より計算密度の高いワークロードに変換します。num_speculative_tokens(スペキュラティブトークン数)を低すぎると、速度向上が制限されます。
逆に、この値が高すぎると早期拒否の確率が増加し、ドラフト計算のリソースが無駄になり、ターゲットモデルの検証コストが上昇します。この値は、観測された受容率に基づき、ドラフト計算と検証コストのバランスを取ることによって調整します。
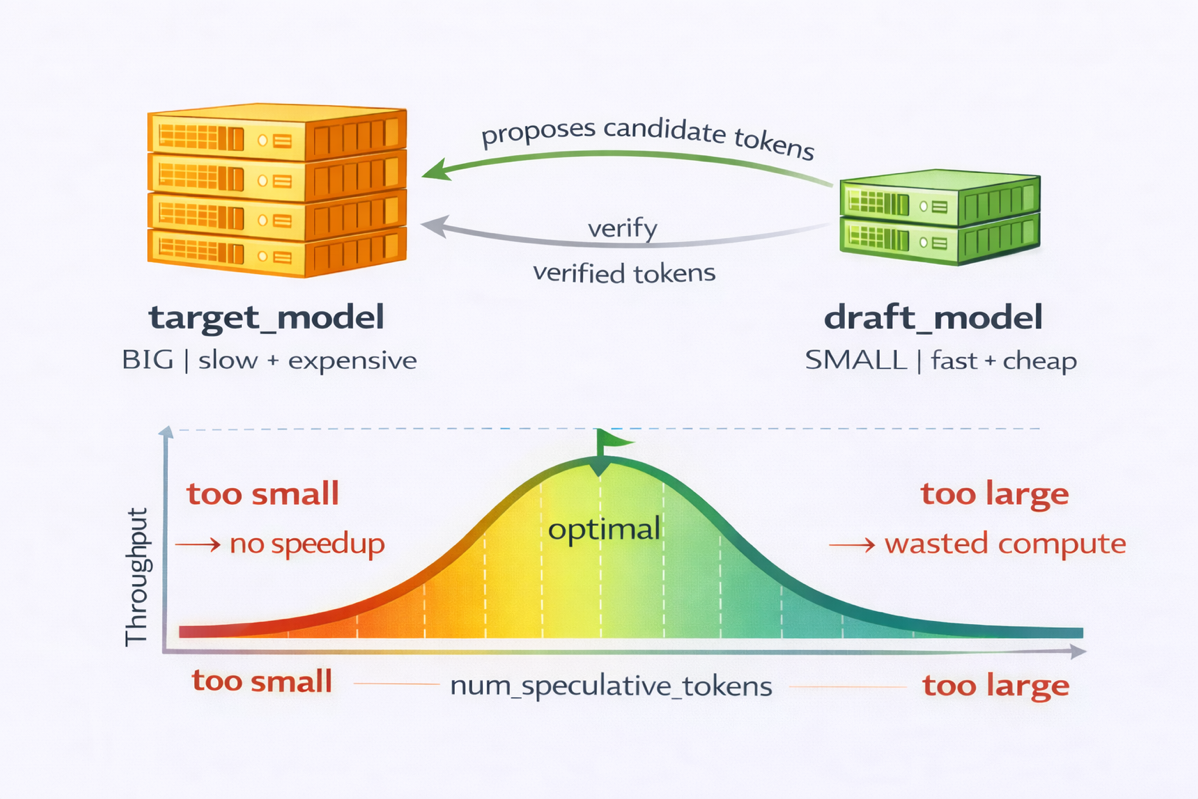
図1 スペキュラティブ・ディコーディング設定のトレードオフ
これらのトレードオフを例示するため、Qwen3-0.6BおよびQwen3-1.7Bのドラフトモデルを比較しました。より小さい0.6Bモデルは実行速度が速かったものの、受容率が約60%低く、計算コストの削減分を相殺するほどでした。Qwen3-1.7Bは、速度と受容率のバランスがより優れていました。
num_speculative_tokens(推論用トークン数)については、5から15の値を評価しました。小さな設定(例えば5)では速度向上が限定的でした。大きなウィンドウ(例えば15)は拒否率を増加させ、パフォーマンスを低下させました。最適な構成はプロンプトの構造に大きく依存しました。私たちは、構造化されたプロンプト(繰り返し、数値シーケンス、単純なコードなど)と自由形式の自然言語の両方をテストしました。最適なバランスは、Qwen3-1.7Bに7つの推論用トークンを設定した場合でした。完全なチューニングの詳細は「得られた教訓」セクションをご覧ください。
NeuronX Distributed Inference (NxD Inference) のサポート機能
AWS Neuron は、AWS AI チップ向けの SDK です。NeuronX Distributed Inference (NxDI) は、Trainium および Inferentia 上でスケーラブルで高パフォーマンスな大規模言語モデル(LLM)推論を実現するためのライブラリです。NxDI は、Trainium 上で4つのモードにおけるスペキュラティブ・ディコーディング(speculative decoding)のネイティブサポートを提供しています。
- 標準的な推論特化デコーディング(Speculative Decoding)— ドラフトモデルとターゲットモデルを独立してコンパイルする。最もシンプルな導入方法です。
- 融合推論特化デコーディング(Fused Speculation)— パフォーマンス向上のため、ドラフトモデルとターゲットモデルをまとめてコンパイルします。本記事で使用するモードです。
- EAGLE 推論特化デコーディング — ドラフトモデルがターゲットモデルの隠れ状態(Hidden State)コンテキストを活用し、トークン受容率を向上させます。
- Medusa 推論特化デコーディング — 複数の小さな予測ヘッドを並列実行してトークンを提案し、ドラフトモデルのオーバーヘッドを削減します。
完全なドキュメントについては、Speculative Decoding ガイド および EAGLE Speculative Decoding ガイド を参照してください。本記事では、Neuron 上で最適なパフォーマンスを得るため、ドラフトモデル(Qwen3-1.7B)とターゲットモデル(Qwen3-32B)を enable_fused_speculation=true でまとめてコンパイルする融合推論特化デコーディング(Fused Speculation)を使用しています。
AWS Trainiumでのスペキュラティブ・ディコーディングの始め方
Amazon Elastic Kubernetes Service (Amazon EKS) クラスター内で2つのvLLM推論サービスをデプロイし、デコーディング方式を除くすべての設定を同一に保ち、パフォーマンスへの影響を単独で評価します。ベースラインサービス(qwen-vllm)は、標準的なデコーディング方式でQwen3-32Bモデルを提供します。スペキュラティブ・ディコーディングサービス(qwen-sd-vllm)は、同じQwen3-32Bのターゲットモデルに加え、num_speculative_tokens=7の設定でQwen3-1.7Bのドラフトモデルを追加して提供します。
両方のサービスは、Trn2(trn2.48xlarge)上で同一の構成を実行しており、アクセラレータのアロケーション、テンソル並列化(大規模モデルを収めるために複数のNeuronCoreにモデルの重みを分散させる技術)、シーケンス長、バッチング制限、Neuron DLCイメージはすべて同一です。唯一の違いは、スペキュラティブ・ディコーディングサービスにQwen3-1.7Bのドラフトモデルとnum_speculative_tokens=7が追加されている点です。完全なセットアップの詳細は図2をご覧ください。
同一の負荷条件下で両方の構成を比較するため、llmperfを使用して、両エンドポイントに対して同一のトラフィックパターンを生成しました。Amazon CloudWatch Container Insightsを用いてインフラストラクチャのテレメトリデータを収集し、リクエストレベルのカスタムメトリクス(TTFT、トークン間レイテンシ、エンドツーエンドのレイテンシ)をCloudWatchダッシュボードに公開し、並列分析を行いました。
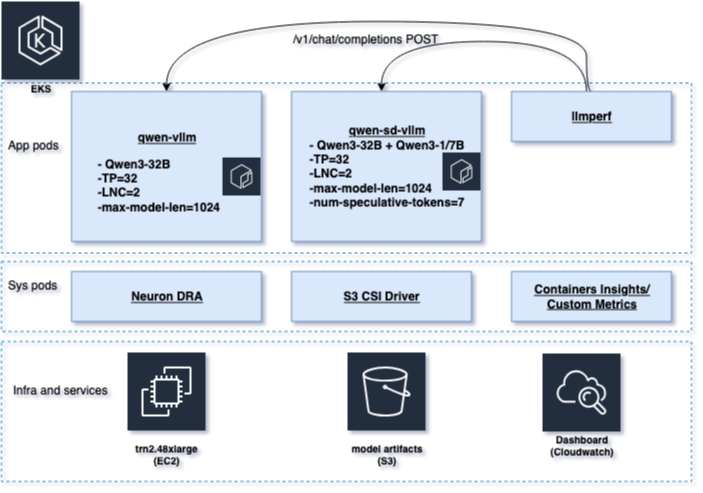
図 2 システムアーキテクチャ
ベンチマーク設定
私たちは、ベースラインおよび推論加速(speculative decoding)デプロイメントの両方に対して、構造化されたデコード集中型のテストケースを実行するために LLMPerf を使用しました。ベンチマークは Kubernetes ポッド内で実行され、qwen-llmperf-pod.yaml によって両方のエンドポイントに並列リクエストを発行し、トークンレベルのレイテンシ指標をログ記録しました。私たちのテストケースは、高度に構造化されたプロンプト(反復シーケンス、数値継続、単純なコードパターン)からオープンエンドの自然言語補完まで多岐にわたり、推論加速における最良ケースおよび最悪ケースの動作をカバーしています。完全なプロンプトセットは サンプルリポジトリ で利用可能です。
明確にするために、分析は2つの代表的なプロンプトタイプに焦点を当てています。1つは高度に構造化された決定論的なプロンプト(反復テキスト生成)、もう1つはオープンエンドのプロンプトです。これら2つのケースは、推論加速の最良ケースおよび最悪ケースの動作を示しています。
Podは、llmperfを制御された入力および出力の長さ、temperature=0.0で実行し、決定論的なデコーディングパスに負荷をかけました。私たちは、トークン間レイテンシ、TTFT(Time To First Token)、スループット、エンドツーエンドのレイテンシなどのメトリクスをログに記録し、CloudWatchに公開しました。
結果
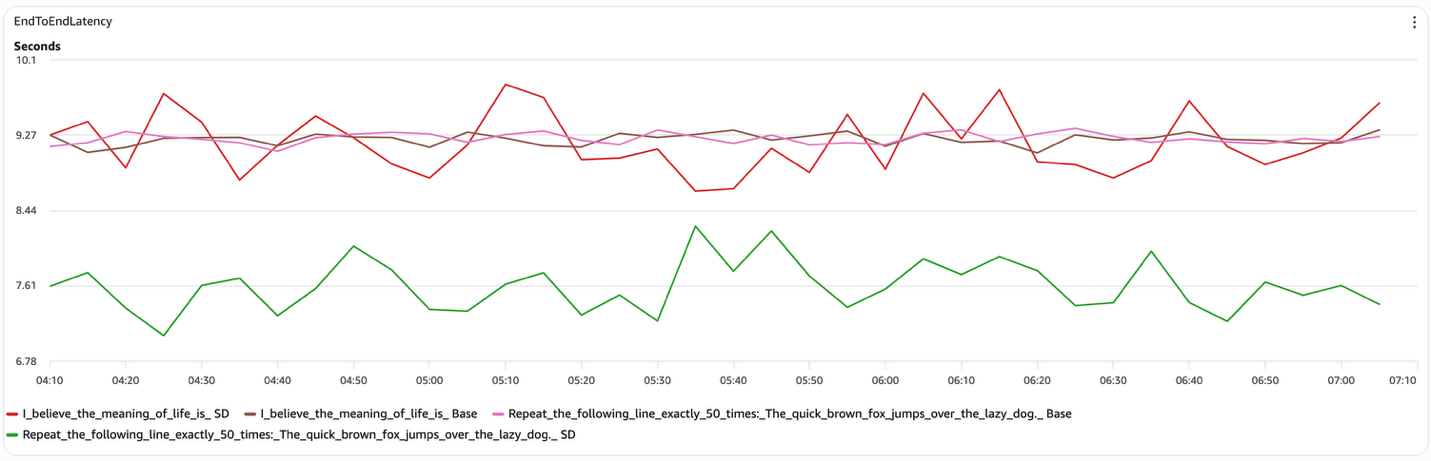
図 3 推論デコーディングのエンドツーエンドレイテンシ
推論デコーディングは選択的にレイテンシを削減します。その効果性はプロンプトの構造に強く依存しており、この依存関係は測定されたすべてのメトリクスで一貫して確認できます。以下に、各プロンプトタイプで期待される結果を示します:
- 構造化されたプロンプト(例:「以下の行を正確に50回繰り返してください」)。推測デコーディングは、エンドツーエンドのレイテンシを測定可能な範囲で削減します。ドラフトモデルがターゲットモデルによって生成される内容を確実に予測できる場合、システムはターゲットモデルのデコードステップの大幅な部分をスキップします。私たちのテストでは、トークン間レイテンシは約15ms/トークンに低下し(オープンエンドのプロンプトでは約45ms)、推測デコーディングのカーブは実行全体を通じてベースラインを一貫して下回りました。
- オープンエンドのプロンプト(例:「人生の意味は~だと信じています」)。推測デコーディングは一貫した恩恵を提供しません。ドラフトモデルはターゲットモデルと頻繁に乖離し、トークンの拒否が発生して、潜在的な利益が相殺されます。推測デコーディングとベースラインのエンドツーエンドのレイテンシカーブはほぼ重なり、両方の構成においてトークン間レイテンシは約45ms/トークンのままです。
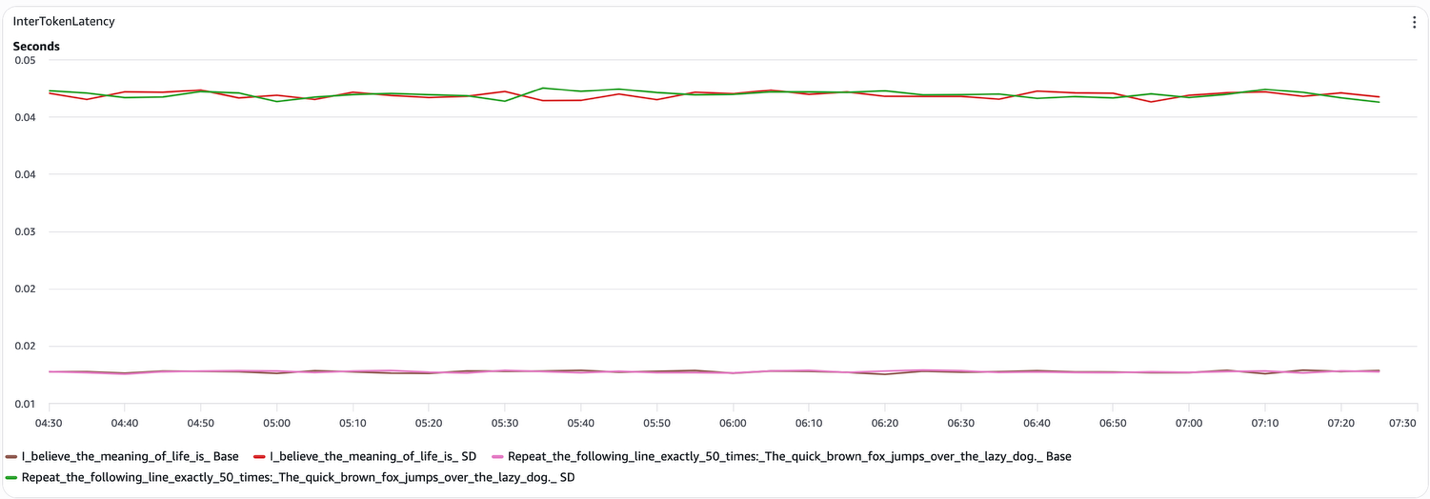
図4 推測デコーディングのトークン間レイテンシ(デコードフェーズ)
TTFT(Time to First Token:最初のトークンまでの時間)は、すべての構成で実質的に変化しません(図5)。TTFTは、モデルが入力コンテキストをエンコードするプレフィルフェーズによって支配されます。推測デコーディングはこの段階を変更しないため、プレフィルレイテンシは改善も悪化もしません。
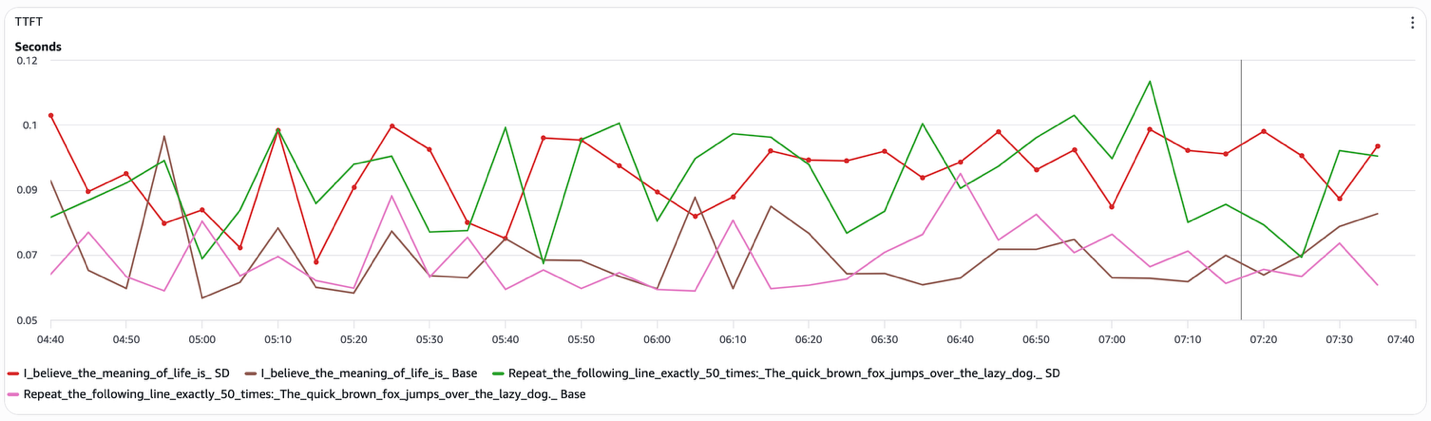
Figure 5 Speculative decoding TTFT (Prefill)
これらの結果を総合すると、speculative decoding(投機的デコーディング)は、ターゲットモデルのdecodeステップ(デコード処理)自体やprefillステージを加速させるのではなく、実行されるターゲットモデルのdecodeステップ数を削減することで、全体のレイテンシ(応答遅延)を改善していることがわかります。これが、構造化されたプロンプトではエンドツーエンドのレイテンシに改善が見られるものの、インタートークンレイテンシやTTFT(Time To First Token:最初のトークン生成までの時間)には改善が見られず、自由なテキスト生成ではspeculative decodingがベースラインの挙動に戻る理由を説明しています。
Reproducing the results
我々は、エンドツーエンドのコードサンプルとKubernetes構成ファイルをAWS Neuron EKS samples repositoryで提供しています。このリポジトリには以下の内容が含まれています:
- Trn2上でベースラインのvLLMおよびspeculative decoding vLLMサービスを展開するためのKubernetesマニフェスト
- 融合speculative decodingを有効にするためのvLLM設定フラグの例
- 負荷を生成しメトリクスを収集するために使用されるサンプルllmperfベンチマークスクリプト
- S3 CSI Driverを通じてモデルチェックポイントとコンパイル済みアーティファクトをマウントするための手順
- Neuron DRA、テンソル並列処理(Tensor Parallelism)、およびNeuronCore配置の設定に関するガイダンス
これらのサンプルにより、モデルのデプロイからベンチマーク実行およびメトリクス収集に至るまで、本記事で使用されたのと同じ実験環境を再現することができます。
結論
デコード処理が重い大規模言語モデル(LLM)のワークロードは、自己回帰的生成の逐次処理という性質によって制約されています。AWS Trainium2 上でのスペキュラティブ・デコーディング(speculative decoding)は、完全な出力を生成するために必要なターゲットモデルのデコードステップ数を削減することで、このボトルネックを打破し、1回のフォワードパスあたりに生成されるトークン数を効果的に増加させます。コード生成、構造化データ抽出、テンプレートベースのレポート生成、または設定ファイルの合成など、出力空間が予測可能なワークロードでは、品質を犠牲にすることなく、出力トークンあたりのコスト削減とスループットの向上という直接的なメリットをもたらします。スペキュラティブ・デコーディングは万能の最適化手法ではありません。その効果はプロンプトの構造、ドラフトモデルの品質、およびスペキュラティブパラメータのチューニングに依存します。適切なワークロードに適用された場合、Trainium ベースの推論システムにおいて有意義なレイテンシとコストの改善を実現します。
次のステップ
AWS Trainium 上でスペキュラティブ・デコーディングを開始するには、以下のリソースを参照してください:
- AWS Trainium の製品ページ — Trainium インスタンスの種類、機能、価格についてご確認ください。
- NeuronX Distributed Inference 開発者ガイド — 投機デコーディングの構成オプションを含む、NxDI の完全なドキュメント。
- NxDI 投機デコーディング機能ガイド — バニラ、融合、EAGLE、Medusa の各推論モードを有効にするためのリファレンス。
- vLLM ドキュメント — 本番環境での大規模言語モデル(LLM)サービングのために vLLM を構成する方法を学習してください。
- Amazon EKS ドキュメント — AWS 上で推論サービスを展開およびスケールするための Kubernetes の使用方法を習得してください。
- AWS Neuron EKS サンプルリポジトリ — 本記事のベンチマークを再現するためのエンドツーエンドのコードサンプル。
- Amazon CloudWatch ドキュメント — 推論エンドポイントを監視するためのダッシュボードとカスタムメトリクスを設定してください。
著者について
 image
image
Yahav Biran は、大規模な AI ワークロードに焦点を当てているアマゾンのシニアアーキテクトです。オープンソースプロジェクトへの貢献や、AWS ブログおよび学術雑誌(AWS コンピューティングおよび AI ブログ、Journal of Systems Engineering など)への寄稿を行っています。技術プレゼンテーションを頻繁に実施し、顧客と協力してクラウドアプリケーションの設計を行っています。Yahav はコロラド州立大学からシステムエンジニアリングの博士号を取得しています。

Truong Pham は、Amazon の Annapurna Labs に所属するソフトウェアエンジニアです。彼は大規模言語モデルの推論(inference)のパイ
原文を表示
*Practical benchmarks showing faster inter-token latency when deploying Qwen3 models with vLLM, Kubernetes, and AWS AI Chips.*
Speculative decoding on AWS Trainium can accelerate token generation by up to 3x for decode-heavy workloads, helping reduce the cost per output token and improving throughput without sacrificing output quality. If you build AI writing assistants, coding agents, or other generative AI applications, your workloads likely produce far more tokens than they consume, making the decode stage the dominant cost of inference. During autoregressive decoding, tokens are generated sequentially, leaving hardware accelerators memory-bandwidth-bound and underutilized. This drives up the cost per generated token. Speculative decoding addresses this bottleneck by letting a small draft model propose multiple tokens at once, which the target model verifies in a single forward pass. Fewer serial decode steps means lower latency and higher hardware utilization, helping to reduce your inference costs.
In this post, you will learn:
- How speculative decoding works and why it helps reduce cost per generated token on AWS Trainium2
- How to enable speculative decoding with vLLM on Trainium
- The benchmarking methodology we used to evaluate performance
- How to tune draft model selection and the speculative token window size for your workloads
- Step-by-step instructions to reproduce the results using Qwen3
What is speculative decoding?
Speculative decoding speeds up autoregressive generation by using two models:
- A draft model proposes n candidate tokens quickly.
- A target model verifies them in one forward pass.
For a deeper look at the underlying mechanics, including token acceptance and rejection, EAGLE-based speculation, and general speculative decoding concepts, see blog post Inferentia2this SageMaker EAGLE walkthrough on AWS Inferentia2, this SageMaker EAGLE walkthrough, and this primer. Here, we focus on the two knobs you control in practice: the draft model and num_speculative_tokens.
The draft and target models must share the same tokenizer and vocabulary, because speculative decoding operates on token IDs verified directly by the target model. We recommend choosing models from the same architectural family because their next-token predictions agree more often. You can pair models with different architectures if they share a tokenizer, but lower agreement between the draft and target models reduces acceptance rates and removes most of the performance gain.
When the target model accepts the draft tokens, they are committed without incurring the full cost of sequential decode steps. The primary parameter you control is num_speculative_tokens, which sets how many tokens the draft model proposes at once. Increasing this value lets you skip more serial decode steps per verification pass, directly reducing inter-token latency when acceptance rates are high.
The performance gain comes from two effects. First, speculative decoding reduces the number of target-model decode steps, which lowers the number of KV-cache memory round trips. (The KV cache stores previously computed key and value tensors so the model does not recompute attention for past tokens. Each decode step reads the full cache from memory, making decode memory-bandwidth-bound.) Second, speculative decoding improves hardware utilization during decoding. In standard autoregressive decoding, each decode step produces only a single new token: the accelerator launches expensive matrix-multiply kernels to produce just one token of work, leaving the processing-element engine largely underutilized. During verification, the target model instead processes n tokens at once, amortizing memory access and turning a sequence of small, inefficient single-token computations into a more compute-dense workload. Setting num_speculative_tokens too low limits speed gains.
Setting it too high increases the likelihood of early rejections, wasting draft compute and raising target-model verification cost. You tune this value by balancing draft compute against verification cost based on your observed acceptance rate.
Figure 1 Speculative decoding config tradeoffs
To illustrate these tradeoffs, we compared Qwen3-0.6B and Qwen3-1.7B draft models. The smaller 0.6B model was faster to run, but its acceptance rate was roughly 60% lower, enough to cancel out the compute savings. Qwen3-1.7B struck a better balance between speed and acceptance.
For num_speculative_tokens, we evaluated values from 5 to 15. Smaller settings (for example, 5) offered limited speedup. Larger windows (for example, 15) increased rejections and degraded performance. The best configuration depended heavily on prompt structure. We tested both structured prompts (such as repetition, numeric sequences, and simple code) and open-ended natural language. The best balance came from Qwen3-1.7B with 7 speculative tokens. See the Lessons learned section for full tuning details.
What NeuronX Distributed Inference (NxD Inference) supports
AWS Neuron is the SDK for AWS AI chips. NeuronX Distributed Inference (NxDI) is its library for scalable, high-performance LLM inference on Trainium and Inferentia. NxDI provides native support for speculative decoding on Trainium across four modes:
- Vanilla speculative decoding — Separate draft and target models compiled independently. The simplest way to get started.
- Fused speculation — Draft and target models compiled together for improved performance. This is the mode we use in this post.
- EAGLE speculation — The draft model leverages hidden-state context from the target model to improve acceptance rates.
- Medusa speculation — Multiple small prediction heads run in parallel to propose tokens, reducing draft-model overhead.
For complete documentation, see the Speculative Decoding guide and the EAGLE Speculative Decoding guide. This post uses fused speculation, where the draft model (Qwen3-1.7B) and target model (Qwen3-32B) are compiled together with enable_fused_speculation=true for optimal performance on Neuron.
Getting started with speculative decoding on AWS Trainium
We deploy two vLLM inference services on Trainium instances in the same Amazon Elastic Kubernetes Service (Amazon EKS) cluster, keeping everything identical except the decoding method to isolate the performance impact. The baseline service (qwen-vllm) serves Qwen3-32B with standard decoding. The speculative service (qwen-sd-vllm) serves the same Qwen3-32B target model, adding a Qwen3-1.7B draft model with num_speculative_tokens=7.
Both services run identical configurations on Trn2 (trn2.48xlarge), the same accelerator allocation, tensor parallelism (which distributes model weights across multiple NeuronCores to fit large models), sequence length, batching limits, and Neuron DLC image. The only difference is the addition of the Qwen3-1.7B draft model and num_speculative_tokens=7 for the speculative service. See Figure 2 for full setup details.
To compare the two configurations under identical load, we used llmperf to generate the same traffic patterns against both endpoints. We captured infrastructure telemetry with CloudWatch Container Insights and published request-level custom metrics (TTFT, inter-token latency, and end-to-end latency) to CloudWatch dashboards for side-by-side analysis.
Figure 2 System architecture
Benchmarking setup
We used LLMPerf to run structured, decode-heavy test cases against both the baseline and speculative decoding deployments. The benchmarks ran inside a Kubernetes pod, qwen-llmperf-pod.yaml, issuing concurrent requests to both endpoints and logging token-level latency metrics. Our test cases ranged from highly structured prompts (repetitive sequences, numeric continuations, simple code patterns) to open-ended natural language completions, covering both best-case and worst-case behavior for speculative decoding. The full prompt set is available in the samples repository.
For clarity, we focus the analysis on two representative prompt types: a highly structured, deterministic prompt (repetitive text generation) and an open-ended prompt. These two cases illustrate both the best-case and worst-case behavior of speculative decoding.
The pod ran llmperf with controlled input and output lengths and temperature=0.0 to stress deterministic decoding paths. We logged and published metrics including inter-token latency, TTFT, throughput, and end-to-end latency to CloudWatch.
Results
Figure 3 Speculative decoding E2E latency
Speculative decoding reduces latency selectively: its effectiveness depends strongly on prompt structure, and this dependency appears consistently across the measured metrics. Here is what you can expect for each prompt type:
- Structured prompts (for example, “Repeat the following line exactly 50 times”). Speculative decoding delivers a measurable reduction in end-to-end latency. When the draft model reliably predicts what the target model would generate, the system skips a substantial fraction of target-model decode steps. In our tests, inter-token latency dropped to roughly 15 ms per token (compared to approximately 45 ms for open-ended prompts), and the speculative decoding curve remained consistently below the baseline throughout the run.
- Open-ended prompts (for example, “I believe the meaning of life is”). Speculative decoding provides no consistent benefit. The draft model frequently diverges from the target model, causing token rejections that negate the potential gains. The speculative and baseline end-to-end latency curves largely overlap, and inter-token latency stays near 45 ms per token for both configurations.
Figure 4 Speculative decoding inter-token latency (Decode)
TTFT (Time to First Token) remains effectively unchanged across the configurations (Figure 5). TTFT is dominated by the prefill phase, where the model encodes the input context. Speculative decoding does not alter this stage, so prefill latency is neither improved nor degraded.
Figure 5 Speculative decoding TTFT (Prefill)
Taken together, these results show that speculative decoding improves total latency by reducing the number of target-model decode steps executed, not by accelerating the decode step itself or the prefill stage. This explains why gains appear in end-to-end latency for structured prompts, but are absent in inter-token latency and TTFT, and why speculative decoding returns to baseline behavior for open-ended generation.
Reproducing the results
We provide end-to-end code samples and Kubernetes configurations in the AWS Neuron EKS samples repository. The repository includes:
- Kubernetes manifests for deploying baseline vLLM and speculative decoding vLLM services on Trn2
- Example vLLM configuration flags for enabling fused speculative decoding
- Sample llmperf benchmarking scripts used to generate load and collect metrics
- Instructions for mounting model checkpoints and compiled artifacts through the S3 CSI Driver
- Guidance on configuring Neuron DRA, tensor parallelism, and NeuronCore placement
These samples let you recreate the same experimental setup used in this post, from model deployment through benchmarking and metrics collection.
Conclusion
Decode-heavy LLM workloads are constrained by the sequential nature of autoregressive generation. Speculative decoding breaks this bottleneck on AWS Trainium2 by reducing the number of target-model decode steps needed to produce the full output, effectively increasing the tokens generated per forward pass. For workloads where the output space is predictable, such as code generation, structured data extraction, templated report generation, or configuration file synthesis, this can translate directly to lower cost per output token and higher throughput, without sacrificing quality. Speculative decoding is not a universal optimization. Its effectiveness depends on prompt structure, draft-model quality, and speculative parameter tuning. When applied to the right workloads, it delivers meaningful latency and cost improvements on Trainium-based inference systems.
Next steps
To get started with speculative decoding on AWS Trainium, explore these resources:
- AWS Trainium product page — Learn about Trainium instance types, capabilities, and pricing.
- NeuronX Distributed Inference developer guide — Full documentation for NxDI, including speculative decoding configuration options.
- NxDI Speculative Decoding feature guide — Reference for enabling vanilla, fused, EAGLE, and Medusa speculation modes.
- vLLM documentation — Learn how to configure vLLM for production LLM serving.
- Amazon EKS documentation — Get started with Kubernetes on AWS for deploying and scaling inference services.
- AWS Neuron EKS samples repository — End-to-end code samples to reproduce the benchmarks in this post.
- Amazon CloudWatch documentation — Set up dashboards and custom metrics for monitoring your inference endpoints.
About the authors
Yahav Biran is a Principal Architect at Amazon, focusing on large-scale AI workloads. He contributes to open-source projects and publishes in AWS blogs and academic journals, including the AWS compute and AI blogs and the Journal of Systems Engineering. He frequently delivers technical presentations and collaborates with customers to design Cloud applications. Yahav holds a Ph.D. in Systems Engineering from Colorado State University.
Truong Pham is a software engineer at Annapurna Labs, Amazon. He specializes in optimizing large language model inference p
関連記事
AWSがS3 Filesを導入、S3バケットへのファイルシステムアクセスを実現
AWSはS3 Filesを発表し、ユーザーがAmazon S3バケットをマウントして標準ファイルシステムインターフェースでデータにアクセスできるようにした。アプリケーションは標準ファイル操作で読み書きでき、システムが自動的にS3リクエストに変換するため、コンピュートサービスがS3に保存されたデータを直接扱える。
AWSが自動インシデント調査のためのDevOpsエージェントを一般提供開始
AWSは、開発者と運用者がAWS環境での問題のトラブルシューティング、デプロイメントの分析、運用タスクの自動化を支援する生成AI搭載アシスタント「DevOps Agent」の一般提供を開始した。
Amazon Bedrockの詳細なコスト帰属機能の導入
AWSがAmazon Bedrockの推論コストをIAMプリンシパルごとに自動的に帰属する機能を発表した。これにより、コストの内訳把握、コスト最適化、財務計画が容易になる。