決済プラットフォームに常駐する自律型 AI エージェントの設計と運用
メルペイは決済プラットフォームに常駐する自律型 AI エージェント「pcp-agent」を実運用しており、セキュリティと計測の仕組みを公開した。
キーポイント
自律型 Ambient Agent の実装
人間が AI を起動する従来のモデルではなく、トリガーベースで常駐し自律実行する「Ambient Agent」として設計され、決済プラットフォームの運用を肩代わりしている。
厳格なセキュリティと権限管理
Docker コンテナ内の copy-on-write ファイルシステムでセッションを隔離し、GitHub トークンのスコープ制限や Hook による事前検査で書き込み権限を厳密に制御している。
Claude Code を核とした拡張性
汎用 LLM エージェントである Claude Code をベースとし、CLAUDE.md や Plugin、Hook でドメイン固有のスキルを追加することで、特定の運用担当として振る舞わせている。
再利用可能な基盤としての展開
単一ボットではなく「remote-claude」というラッパーを介して SRE や n8n など複数ドメインへ展開可能なエージェント基盤として設計されており、冷間起動とウォームアップの速度差も最適化されている。
セキュリティと計測の設計思想の対比
セキュリティ層(PreToolUse)は失敗時にブロックする「fail-closed」を採用し、計測層(PostToolUse)はエージェント動作を妨げないよう常に正常終了とする「fail-open」で設計している。
ナレッジの自律的メンテナンスと記憶管理
Slack 会話や対応履歴から自動でドメイン知識を抽出・更新する LangMem ベースの仕組みを導入し、RAG 検索だけでなく「記憶そのもの」の手入れを行うことで情報の鮮度を維持している。
汎用プラットフォームとしての基盤設計
個別のエージェントではなく、Slack 統合・セッション隔離・セキュリティフックなどを共通化する「remote-claude」という基盤を構築し、新規エージェントの立ち上げコストを最小化して横展開を実現している。
影響分析・編集コメントを表示
影響分析
この記事は、LLM エージェントを実環境のミッションクリティカルなシステム(決済)で安全に運用するための具体的なアーキテクチャとセキュリティ対策を示しており、業界全体の自律型 AI 導入におけるベストプラクティスとして大きな影響を与える。特に「常駐型」かつ「自律実行」を実現しつつ、厳格な権限管理を両立させる手法は、他の企業においても即座に参照・応用可能な重要な知見である。
編集コメント
決済という極めて厳格なセキュリティ要件を持つドメインで、自律 AI を安全に運用するための具体的な技術的解決策が示されており、実務者にとって非常に参考になる内容です。
こんにちは。メルペイのディレクター、@abcdefuji です。この記事は「Merpay & Mercoin Tech Openness Month 2026」の20日目の記事です。
はじめに
私たちは、決済プラットフォームチームに Slack メンションで起動し Google Compute Engine(GCE)上に常駐する AI エージェント pcp-agent を作り、本番運用しています。狙いは「人間が AI をキックする」ツールではなく、トリガーベースで自律実行する Ambient Agent(環境常在型エージェント)を作ることでした。
本記事では、この取り組みで本当に難しかった2点、決済ドメインで自律エージェントを安全に動かすセキュリティと、その効果を計測する仕組みについて実コードと図で解説します。さらに、これが単一のボットではなく、SRE や n8n など複数ドメインへ展開する再利用可能なエージェント基盤(remote-claude)であることも紹介します。
背景:なぜ「常駐エージェント」なのか
PCP(Payment & Customer Platform、決済・顧客プラットフォーム)は数十のマイクロサービスを抱え、社内の大量のユースケースを支えています。障害調査、アラートのトリアージ、システム間の金額検証、問い合わせ対応。これらはいずれも「決まった手順だが人手を食う」作業です。私たちはこうした運用を AI に肩代わりさせたいと考えました。
掲げたビジョンはシンプルです。AI があらゆるオペレーションをトリガーベースで自律実行し、人間のアクションを必要としない Platform 体制を構築する、というものです。「人間が AI をキックする」世界観は前提から外しました。
だからこそ私たちは、チャット UI に個人が質問を投げるツールではなく、チームに常駐し、トリガーで自律的に動く Ambient Agent(環境常在型エージェント)として pcp-agent を位置づけました。人で言えば「決済プラットフォームチームに運用担当が常駐している」イメージです。
全体アーキテクチャ
pcp-agent は Slack 統合型の Claude Code ボットで、隔離された Docker コンテナ内で動きます。セッションごとに copy-on-write ファイルシステム(書き込み時コピー方式ファイルシステム)で独立したコンテナが立ち上がり、影響範囲をセッション単位に閉じ込めます。共通インフラ(server / scheduler / auth-proxy)が Slack メンションやスケジューラーからの起動を受け、コンテナを起動します。

エージェントの権限管理については、決定的な層を導入しています。書き込み可能なリポジトリは、社内の集中管理された ACL と、そこから発行されるスコープを絞った短命の GitHub トークンによって、リポジトリ単位で機械的に制限されています。それ以外はすべて読み取り専用(調査・参照用)です。CLAUDE.md には書き込み可能なリポジトリを明示してエージェントの振る舞いを誘導しますが、強制するのは上記の決定的な層です。リスクが高い領域への書き込みはエージェントに許さないという境界をまず引きました。
仕組み:Claude Code を核に remote-claude で包む
中身を一段掘り下げます。pcp-agent の心臓部は Claude Code そのものです。私たちは Claude Code を「コマンドラインで動くエージェントランタイム」として使い、その周りを remote-claude という薄いラッパーで包んでいます。remote-claude は Slack やスケジューラーからのトリガーを受け取り、セッションごとに Docker コンテナを立て、その中で Claude Code を起動し、標準出力を Slack に橋渡しする役割を担います。
Claude Code は単体では汎用のコーディングエージェントです。これを「決済プラットフォームドメインの運用担当」に仕立てているのは、ワークスペースに置いた .claude ディレクトリの中身です。ここには振る舞いを決める CLAUDE.md、ドメイン知識と手順をコード化したスキル/プラグイン、そして実行のたびに介入するフックが含まれます。能力を増やしたいときはモデルを差し替えるのではなく、スキルやルールを追加し、「プロンプトとファイル」で拡張するのが設計の基本方針です。
一回の実行(セッション)の流れはこうです。トリガーが来ると remote-claude が新しいコンテナをコピーオンライト方式で起動し、その中の Claude Code が Slack メッセージやスケジュールされたプロンプトを入力として受け取ります。エージェントがツールを呼ぶたびに、まず PreToolUse フックがセキュリティ検査をかけて危険なら止め、ツール実行後に PostToolUse フックが開発者体験の計測プラットフォームである DX へ利用イベントを送ります。同じセッション(Slack スレッド)への追加リクエストは、起動中の Claude Code プロセスを再利用するため高速で、コールドスタートは約 30 秒に対してウォームスタートは約 2〜3 秒です。セッションはアイドル状態が約 30 分続くとクライアントを切断し、約 1 週間(session_ttl)で破棄します。各セッションはコピーオンライト方式で独立したワークスペースを持つので、影響範囲をセッション単位に閉じ込めつつ再現性を確保できます。

設計上の要点は「LLM を信用しすぎない」ことです。エージェントの判断(自然言語)は本質的に非決定的なので、安全性や監査が要る部分は決定的なフック、ネットワークレベルの認証プロキシ(auth-proxy)、コンテナ隔離、IaC 管理におけるシークレットなど、LLM の外側に寄せています。LLM には「何をやりたいか」を任せ、「やってよいか」「どう繋ぐか」はコードと基盤で固める、という責務分離です。
認証設計:auth-proxy でクレデンシャル注入を一点集中
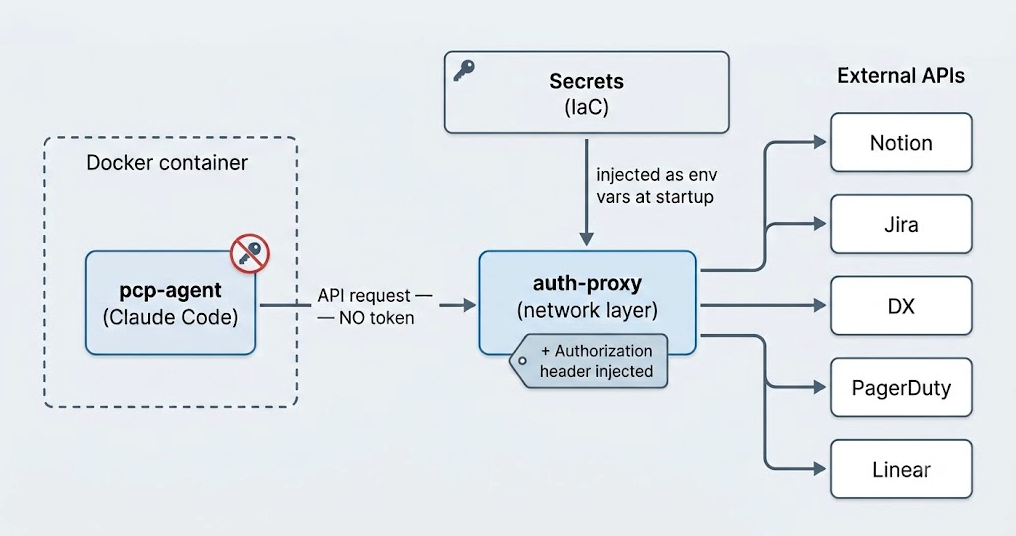
エージェントは Notion / Jira / DX / PagerDuty / Datadog / Slack など多数の外部 API を横断します。認証方式はサービスごとにバラバラで、これを LLM に直接持たせるのは危険です。そこで私たちは auth-proxy をネットワークレベル(iptables DNAT)に置き、宛先ごとに適切な認証情報を自動注入する構成にしました。注入するヘッダや取得方法はサービスごとに異なり(環境変数、keyless な GitHub トークン、GCP サービスアカウントのインパーソネーションなど)、その差異を auth-proxy が吸収します。エージェント側の curl はトークンを一切知りません。
この設計のもう一つの利点は、シークレットをエージェントのコードから完全に分離できることです。実トークンはすべて IaC(microservices-terraform)で管理し、auth-proxy 側にだけ環境変数として渡します。ランナー(エージェント実行コンテナ)に埋め込まれるのは非機能のダミー値だけで、万が一漏れても無効です。エージェントのワークスペースにクレデンシャルは存在しません。
セキュリティ:決済ドメインで自律エージェントを動かすための多層防御
決済ドメインで本番権限を持つ自律エージェントは、最高レベルの安全要求を満たす必要があります。pcp-agent は deny rules(拒否ルール)、PreToolUse hook(ツール使用前フック)、behavioral rules(行動規則)、auth-proxy、コンテナ隔離の 5 層で防御しています。重要なのは、単一の層に依存しないことです。どれか一つが破られても、別の層が止める設計にしています。
主防御線に据えたのは PreToolUse hook です。個々のツールごとの許可・拒否設定に頼り切るのではなく、どのツール経由でも危険な操作を止められる決定的なフックを最終的な強制層に置く方が確実だと考えたからです。後述するように、このフックは想定外の終了コードで落ちた場合に「黙って許可」ではなく「ブロック」を返す fail-closed 設計にしてあります。フックがクラッシュした隙にコマンドが通る事故を防ぐためです。
シークレットファイルの検出には現実的な難しさがあります。jq のフィールドアクセスをして issue key を取得するような正当な操作と、秘密ファイルの読み取りを区別しなければなりません。私たちのパターンはファイルパスとして現れる鍵ファイルのみを止め、クエリ構文は通すよう練られています。
この手の防御は「イタチごっこ」です。セキュリティレビューを重ねるたびに想定外の抜け道が見つかり、その都度検出パターンを強化してきました。正当な操作は通しつつ、秘密情報の読み取りだけを確実に止める。その考え方を、次の小節でコード例とともに示します。
設計判断(ADR)も明文化しています。たとえば WebSearch と WebFetch はドメイン許可リストの対象外としました。許可リストは「LLM が Bash コマンドで URL をハルシネートする」ことを防ぐためのもので、Web 閲覧(読み取り)とは脅威モデルが異なるからです。ただし取得 URL は秘密パターンをスキャンし、クエリ経由のデータ漏洩を防いでいます。また Codex MCP は本エージェントでは有効化していません。Codex は独自のシェル実行エンジンを持ち Claude Code の deny rule を迂回するため、human-in-the-loop のない Slack bot では受け入れ不可と判断し、フックでブロックしています。
PreToolUse hook:fail-closed の安全網
#!/usr/bin/env bash
PreToolUse security hook — deterministic enforcement layer
Exit codes: 0 = allow, 2 = block
set -euo pipefail
0=allow / 2=block 以外で落ちたら block を返す(クラッシュ時に許可しない)
trap 'ec=$?; if [[ $ec -ne 0 && $ec -ne 2 ]]; then
echo "{ decision: block, reason: hook failed (exit $ec) — blocking for safety }"
exit 2
fi' EXIT
**
注:上記の echo は可読性のため簡略表記にしています。実装では decision / reason を含む JSON を出力します。
シークレットファイル検出のパターン**
正当な jq フィールドアクセスは通しつつ、鍵ファイルの読み取りだけを止めます(一部のパスは可読性のため簡略表記)。
secret_file_patterns=(
'.env(boundary)'
'.env.'
'.pem(boundary)'
'.key(boundary)'
'credentials.*.json'
'/proc//environ'
)
.env.example / process.env.X / jq の .fields.parent.key は許可(ファイル読みではない)
ポイントは boundary(境界)と pathchar(パス文字)の条件で「ファイルパスとして現れる鍵ファイル」だけを対象にし、{ key: .key } のようなオブジェクトアクセスを誤検知しないことです。
計測:PostToolUse hook × DX で効果を測る
「導入したが効果は?」に答えられなければ本番運用は続きません。私たちは、エージェントのツール実行を PostToolUse hook で捕捉し、DX にイベント送信しています。これにより「どのスキルやツールが、誰に、どれだけ使われたか」を継続的に計測できます。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "この手の防御は「イタチごっこ」です。セキュリティレビューを重ねるたびに想定外の抜け道が見つかり、その都度検出パターンを強化してきました。正当な操作は通しつつ、秘密情報の読み取りだけを確実に止める。その考え方を、次の小節でコード例とともに示します。
設計判断(ADR)も明文化しています。たとえば WebSearch と WebFetch はドメイン許可リストの対象外としました。許可リストは「LLM が Bash コマンドで URL をハルシネートする」ことを防ぐためのもので、Web 閲覧(読み取り)とは脅威モデルが異なるからです。ただし取得 URL は秘密パターンをスキャンし、クエリ経由のデータ漏洩を防いでいます。また Codex MCP は本エージェントでは有効化していません。Codex は独自のシェル実行エンジンを持ち Claude Code の deny rule を迂回するため、human-in-the-loop のない Slack bot では受け入れ不可と判断し、フックでブロックしています。
PreToolUse hook:fail-closed の安全網
#!/usr/bin/env bash
PreToolUse security hook — deterministic enforcement layer
Exit codes: 0 = allow, 2 = block
set -euo pipefail
0=allow / 2=block 以外で落ちたら block を返す(クラッシュ時に許可しない)
trap 'ec=$?; if [[ $ec -ne 0 && $ec -ne 2 ]]; then
echo "{ decision: block, reason: hook failed (exit $ec) — blocking for safety }"
exit 2
fi' EXIT
**
注:上記の echo は可読性のため簡略表記にしています。実装では decision / reason を含む JSON を出力します。
シークレットファイル検出のパターン**
正当な jq フィールドアクセスは通しつつ、鍵ファイルの読み取りだけを止めます(一部のパスは可読性のため簡略表記)。
secret_file_patterns=(
'.env(boundary)'
'.env.'
'.pem(boundary)'
'.key(boundary)'
'credentials.*.json'
'/proc//environ'
)
.env.example / process.env.X / jq の .fields.parent.key は許可(ファイル読みではない)
ポイントは boundary(境界)と pathchar(パス文字)の条件で「ファイルパスとして現れる鍵ファイル」だけを対象にし、{ key: .key } のようなオブジェクトアクセスを誤検知しないことです。
計測:PostToolUse hook × DX で効果を測る
「導入したが効果は?」に答えられなければ本番運用は続きません。私たちは、エージェントのツール実行を PostToolUse hook で捕捉し、DX にイベント送信しています。これにより「どのスキルやツールが、誰に、どれだけ使われたか」を継続的に計測できます。"}
設計には三つのポイントがあります。第一に fail-open です。計測はエージェントの動作を妨げてはいけないので、どんなエラーでも黙って正常終了します。セキュリティの PreToolUse が fail-closed なのとちょうど対照的で、層ごとに設計思想を逆にしているのが要点です。第二にセッション内重複排除で、同じイベント型は1セッションに1回だけ送ります。第三にメール解決で、Slack コンテキストからユーザーを特定し、bot やスケジュール実行ではフォールバックの共通アドレスに振り替えます。
興味深いのは、送信するだけでなくエージェント自身が DX のメトリクスを読むことです。チームスコアは MCP 経由で直接クエリし、Core4(Effectiveness / Impact / Quality / Speed)や sentiment を参照します。これにより、エージェントが自分の置かれたチームの開発者体験データを踏まえて振る舞える素地ができます。なお、コメント API は個人のメールを含むため、リポジトリに保存せず Slack にも出さず、必要時にオンデマンドで取得して 1on1 準備などの参照にのみ使う、という PII 取り扱いを徹底しています。
フロー:PostToolUse hook の処理

これによりダッシュボード側でスキル別・ツール別の利用状況を集計できます。
エージェントに「記憶」を持たせる:ナレッジの自動メンテナンス

ドメイン知識は Slack と Notion に散在し、放置すればエージェントは古い情報で答えてしまいます。私たちはこれをスケジュールジョブで継続的に更新しています。日次のチャンネルナレッジ抽出ジョブ(対象チャンネルの整備後に本格有効化予定)は、前日の人間同士の会話を読み、ドメインに関わる知識をスキルやナレッジとして抽出・提案します。
さらに、エージェントが対応した Slack スレッドを見直して有用な知識を登録し、既存エントリの更新・削除を整理する LangMem ベースの自動メンテナンスも回しています。RAG で都度検索するだけでなく、記憶そのものを継続的に手入れする発想です。
加えて「AI が読みやすいドキュメント構造」への投資も行いました。リポジトリ一覧や監視チャンネル一覧を機械可読な形で同期し、エージェントが参照しやすくしています。PCP にはリポジトリだけで約50個ほどあるのでこのような情報を整理することがスタートでした。知識の鮮度・ノイズ・ハルシネーションは依然として課題ですが、人手の更新に頼らない仕組みを基盤として持てたことが大きな前進でした。
自律スケジューラー:何が毎日・毎週動いているか

必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
pcp-agent は Slack メンションでの起動だけでなく、cron ベースのスケジューラー(scheduled task)でも自律的に動作します。これが「トリガーベースで人間のアクションを必要としない」というビジョンの実装そのものです。週次のダッシュボード要約やアラートダイジェストは、誰かが依頼しなくても毎週決まった時刻に投稿されます。
ジョブ定義は宣言的な YAML で、タイムゾーン・タイムアウト(active_deadline_seconds)・リトライ(backoff_limit)・多重起動抑止(concurrency_policy: forbid)・出力先 Slack チャンネルを指定できます。中心は「PCP Daily Schedule」で、平日毎朝 9 時 (JST) に 4 つのルーティンを順番に実行し、各完了後に中間結果を Slack に投稿、最後に「本日のまとめ」を出します。当初は別々のジョブだったものを、一つの統合ワークフローに集約しました。このループを回すこと自体で、日々の会話からナレッジが溜まり、スキルも更新されていく、そうした自己更新的なループとして設計しています。
スケジュール例:
ジョブ
スケジュール
内容
pcp-daily-schedule
平日 9:00
4 タスク統合:①リリースノート生成 ②対象リポジトリ追跡(新スキル取込提案)③既存スキル改善提案 ④LangMem ナレッジ前日分メンテ
xxxx-weekly-dashboard-summary
毎週月 10:30
各チームダッシュボードの週次サマリ
yyyy-weekly-alert-digest
毎週月 11:00
各チームアラートの週次ダイジェスト
- name: xxxx-weekly-alert-digest
enabled: true
cron: "0 11 * * 1" # Every Monday 11:00 (JST)
prompt_file: "config/prompts/xxxx-weekly-alert-digest.md"
timezone: "Asia/Tokyo"
active_deadline_seconds: 600 # 10 分でタイムアウト
backoff_limit: 1 # 失敗時に 1 回リトライ
concurrency_policy: forbid # 前回実行中ならスキップ
ポイントは、スケジューラーが単なる cron 以上であることです。タイムアウト、リトライ、多重起動抑止といったジョブ制御を持たせることで、自律実行を本番で安全に回せるようにしています。
実際のユースケース
pcp-agent の能力はスキルとしてファイル化され、実運用で次のようなユースケースに使われています。いずれも「決まった手順だが人手を食う」調査・集計・トリアージ作業です。
ユースケース
スキル
内容
障害・アラート調査
investigate-alert
アラートを起点に関連ログ・メトリクスをたどり一次切り分け
日次トリアージ
xxxx-daily-triage
XXXX チームの毎日の異常検知とトリアージ
問い合わせ調査
investigate-inquiry
問い合わせをドメイン知識付きで調査
週次サマリ
yyyy-weekly-alert-digest
各チームのアラート・ダッシュボードの週次要約
PR 監視・イシュー起票
watch-pr / issue / jira
レビュー補助と起票
この中でも最初のわかりやすいユースケースは調査のユースケースでした。
参考例として、Alert(トリガー) → Datadog(データ集約) → Slack / Notion 等 (データ可視化・レポート) という流れです。すでに多くのエンジニアのローカル環境にはデータ調査スキルが存在すると思います。そのスキルをリモートに持ってきてトリガーさせるだけで一定の時間削減が実現でき、そしてローカルに存在するスキル(属人性)をリモートに持ってくることで誰でも同じ体験を実現することができます。
そして、これらのユースケースが「実際にどれだけ使われているか」を DX で可視化しています。どのユースケース(スキル)が、どのチームで、どれくらい使われたかをダッシュボードで追跡できます。エージェントの価値を「何ができるか(能力)」ではなく「何に使われているか(採用)」で測るのが狙いです。
プラットフォームとしての強み:1 つの bot ではなく、エージェント基盤
ここまで pcp-agent という 1 つのエージェントを見てきましたが、本当の狙いは個別の bot を作ることではありません。私たちが作ったのは remote-claude という再利用可能なプラットフォームで、pcp-agent はその上で動く 1 テナントにすぎません。同じ基盤の上に、SRE 向けの remote-claude-sre、ワークフロー自動化 (n8n) 向けの remote-claude-n8n が並んで動いており、data platform 領域へも展開しています。

プラットフォームと各エージェントの責務は明確に分かれています。共有基盤 (remote-claude) が提供するのは、Slack 統合、セッション隔離 (copy-on-write)、cron スケジューラー、auth-proxy、PreToolUse/PostToolUse フックの仕組み、PII リダクション、ランナーのリソース制限 (メモリ・PID・CPU) といった「どのエージェントにも共通して必要な土台」です。各テナントが持つのは、自分のドメインに固有の workspace/.claude、つまり CLAUDE.md、スキル、ルールだけです。
この設計の効きどころは、新しいエージェントを立ち上げるコストの小ささです。共有設定は base.yaml に集約され、各エージェントは差分だけを上書きします。テンプレート (remote-claude/template) をコピーし、ドメイン知識をスキルとして足せば、Slack 起動・隔離・スケジューラー・セキュリティ・計測がすべて最初から揃った状態で新しいテナントが立ち上がります。「決済の常駐エージェント」で作った仕組みが、そのまま他のチームにも転用できるわけです。
remote-claude/config/base.yaml(全エージェント共通、各エージェントが上書き)
default_model: sonnet
use_proxy_network: true # ランナーに権限を与えずオーバーレイで経路制御
session_policy:
session_ttl_minutes: 10080 # 7 days
runner_memory_limit: "4g"
runner_pids_limit: 256
runner_idle_timeout_minutes: 30
slack_output_redaction: false # PII リダクションをデプロイ単位で ON にできる
セキュリティや計測のような「外側で固める」部分をプラットフォーム側に持たせることで、各チームはドメイン知識の記述に集中でき、かつ全社的に一貫した安全性・可観測性を担保できます。これがエージェントを「点」ではなく「基盤」として広げる強みです。ちなみに remote-claude はもともと SRE 向け(cc-sre)に生まれ、そこから複数ドメインをホストする汎用プラットフォームへと一般化されていきました。
まとめ
半年運用して、いくつか確かな手応えがありました。まずスキル化は効きます。ドメイン知識を SKILL.md としてコード管理すると、エージェントの振る舞いが再現可能になり、レビューやテストの対象にできます。エージェント自身に新しいスキルを作らせるループも回り始めました。
もっとも、正直なところ最大の課題はユースケースの深掘りだと感じています。問い合わせのための調査のように、各所のパーツは AI に代替できる部分が出てきましたが、まだ人間がトリガーしている場面が多く、真に AI を軸に置いたフローになっているとは言えません。エージェントが受け取れるトリガーをさらに増やし、ユースケース全体を「AI 前提」のプロセスへ置き換えていきたいと考えています。
今後は、このエージェントを一つに統合するか、ドメインごとに分散させるかをユースケース次第で見極めていきます。LLM のコンテキストは有限なので、独自のワークフローが必要なユースケースが増えれば分散させる方針です。
加えて、社内でこうしたエージェントが増えていくほど、個々の精度以上に「フリート全体をどう統治し、どう観測するか」が重要になります。エージェントごとに権限・ポリシー・監査がバラバラだと、事故も非効率も増えていきます。そこで、ガバナンスと各エージェントの振る舞い・コスト・利用状況などを横断的に把握する仕組みを、今後プラットフォーム側で整えていきたいと考えています。
「AI エージェントを作ってみた」記事は数多くありますが、決済ドメインの本番チームに常駐させ、セキュリティを多層で固め、効果を計測しながら回すところまでやると、考えるべきことは一気に増えます。私たちが半年で取り組んだのは、その「面倒な部分」を実コードで埋めてきた記録です。そして、その面倒な部分を共有基盤(remote-claude)に寄せたことで、決済で作った仕組みを SRE や n8n へ横展開できる「エージェント基盤」に育ちつつあります。これから業務にエージェントを組み込む方にとって、安全性と計測をプラットフォーム側でどう設計するかの一例になれば幸いです。
原文を表示
こんにちは。メルペイ Director の @abcdefuji です。この記事は「Merpay & Mercoin Tech Openness Month 2026」の 20日目の記事です。
はじめに
私たちは、決済プラットフォームチームに Slack メンションで起動し Google Compute Engine(GCE) 上に常駐する AI エージェント pcp-agent を作り、本番運用しています。狙いは「人間が AI をキックする」ツールではなく、トリガーベースで自律実行する Ambient Agent を作ることでした。
本記事では、この取り組みで本当に難しかった2点、決済ドメインで自律エージェントを安全に動かすセキュリティと、その効果を計測する仕組みについて実コードと図で解説します。さらに、これが単一のbotではなく、SREやn8nなど複数ドメインへ展開する再利用可能なエージェント基盤(remote-claude)であることも紹介します。
背景:なぜ「常駐エージェント」なのか
PCP(Payment & Customer Platform)は数十のマイクロサービスを抱え、社内の大量のユースケースを支えています。障害調査、アラートのトリアージ、システム間の金額検証、問い合わせ対応。これらはいずれも「決まった手順だが人手を食う」作業です。私たちはこうした運用を AI に肩代わりさせたいと考えました。
掲げたビジョンはシンプルです。AI があらゆるオペレーションをトリガーベースで自律実行し、人間のアクションを必要としない Platform 体制を構築する、というものです。「人間が AI をキックする」世界観は前提から外しました。
だからこそ私たちは、チャット UI に個人が質問を投げるツールではなく、チームに常駐し、トリガーで自律的に動く Ambient Agent として pcp-agent を位置づけました。人で言えば「決済プラットフォームチームに運用担当が常駐している」イメージです。
全体アーキテクチャ
pcp-agent は Slack 統合型の Claude Code bot で、隔離された Docker コンテナ内で動きます。セッションごとに copy-on-write ファイルシステムで独立したコンテナが立ち上がり、影響範囲をセッション単位に閉じ込めます。共通インフラ(server / scheduler / auth-proxy)が Slack メンションやスケジューラーからの起動を受け、コンテナを起動します。
エージェントの権限管理関しては、決定的な層を導入しています。書き込み可能なリポジトリは、社内の集中管理された ACL と、そこから発行される scope を絞った短命の GitHub token によって リポジトリ単位で機械的に制限しています。それ以外はすべて read-only(調査・参照用)です。CLAUDE.md には writable repo を明示してエージェントの振る舞いを誘導しますが、強制するのは上記の決定的な層です。リスクが高い領域への書き込みはエージェントに許さない、という境界をまず引きました。
仕組み:Claude Code を核に remote-claude で包む
中身を一段掘り下げます。pcp-agent の心臓部は Claude Code そのものです。私たちは Claude Code を「コマンドラインで動くエージェントランタイム」として使い、その周りを remote-claude という薄いラッパーで包んでいます。remote-claude は Slack やスケジューラーからのトリガーを受け取り、セッションごとに Docker コンテナを立て、その中で Claude Code を起動し、標準出力を Slack に橋渡しする役割を担います。
Claude Code は単体では汎用のコーディングエージェントです。これを「決済プラットフォームドメインの運用担当」に仕立てているのは、ワークスペースに置いた .claude ディレクトリの中身です。ここには振る舞いを決める CLAUDE.md、ドメイン知識と手順をコード化した Skill / Plugin、そして実行のたびに介入する Hook が含まれます。能力を増やしたいときはモデルを差し替えるのではなく、スキルやルールを足す、つまり「プロンプトとファイル」で拡張するのが設計の基本方針です。
一回の実行(セッション)の流れはこうです。トリガーが来ると remote-claude が新しいコンテナを copy-on-write で起こし、その中の Claude Code が Slack メッセージやスケジュールされたプロンプトを入力として受け取ります。エージェントがツールを呼ぶたびに、まず PreToolUse hook がセキュリティ検査をかけて危険なら止め、ツール実行後に PostToolUse hook が 開発者体験の計測プラットフォームであるDX へ利用イベントを送ります。同じセッション(Slack スレッド)への追加リクエストは、起動中の Claude Code プロセスを再利用するため高速で、コールドスタート約30秒に対してウォームは約2〜3秒です。セッションはアイドルが約30分続くとクライアントを切断し、約1週間(session_ttl)で破棄します。各セッションは copy-on-write で独立した workspace を持つので、影響範囲をセッション単位に閉じ込めつつ再現性を確保できます。
設計上の要点は「LLM を信用しすぎない」ことです。エージェントの判断(自然言語)は本質的に非決定的なので、安全性や監査が要る部分は決定的な Hook、ネットワークレベルの auth-proxy、コンテナ隔離、IaC 管理のシークレットなど、LLMの外側に寄せています。LLM には「何をやりたいか」を任せ、「やってよいか」「どう繋ぐか」はコードと基盤で固める、という責務分離です。
認証設計:auth-proxy でクレデンシャル注入を一点集中
エージェントは Notion / Jira / DX / PagerDuty / Datadog / Slack など多数の外部 API を横断します。認証方式はサービスごとにバラバラで、これを LLM に直接持たせるのは危険です。そこで私たちは auth-proxy をネットワークレベル(iptables DNAT)に置き、宛先ごとに適切な認証情報を自動注入する構成にしました。注入するヘッダや取得方法はサービスごとに異なり(環境変数、keyless な GitHub トークン、GCP サービスアカウントのインパーソネーションなど)、その差異を auth-proxy が吸収します。エージェント側の curl はトークンを一切知りません。
この設計のもう一つの利点は、シークレットをエージェントのコードから完全に分離できることです。実トークンはすべて IaC(microservices-terraform)で管理し、auth-proxy 側にだけ環境変数として渡します。ランナー(エージェント実行コンテナ)に埋め込まれるのは非機能のダミー値だけで、万が一漏れても無効です。エージェントのワークスペースにクレデンシャルは存在しません。
セキュリティ:決済ドメインで自律エージェントを動かすための多層防御
決済ドメインで本番権限を持つ自律エージェントは、最高レベルの安全要求を満たす必要があります。pcp-agent はdeny rules、PreToolUse hook、behavioral rules、auth-proxy、コンテナ隔離の5層で防御しています。重要なのは、単一の層に依存しないことです。どれか一つが破られても、別の層が止める設計にしています。
主防御線に据えたのは PreToolUse hook です。個々のツールごとの許可・拒否設定に頬り切るのではなく、どのツール経由でも危険な操作を止められる決定的なフックを最終的な強制層に置く方が確実だと考えたからです。後述するように、このフックは想定外の終了コードで落ちた場合に「黙って許可」ではなく「ブロック」を返す fail-closed 設計にしてあります。フックがクラッシュした隙にコマンドが通る事故を防ぐためです。
シークレットファイルの検出には現実的な難しさがあります。jq のフィールドアクセスをしてissue key を取得するような正当な操作と、秘密ファイルの読み取りを区別しなければなりません。私たちのパターンはファイルパスとして現れる鍵ファイルのみを止め、クエリ構文は通すよう練られています。
この手の防御は「イタチごっこ」です。セキュリティレビューを重ねるたびに想定外の抜け道が見つかり、その都度検出パターンを強化してきました。正当な操作は通しつつ、秘密情報の読み取りだけを確実に止める。その考え方を、次の小節でコード例とともに示します。
設計判断(ADR)も明文化しています。たとえば WebSearch と WebFetch はドメイン許可リストの対象外としました。許可リストは「LLM が Bash コマンドで URL をハルシネートする」ことを防ぐためのもので、Web 閲覧(読み取り)とは脅威モデルが異なるからです。ただし取得 URL は秘密パターンをスキャンし、クエリ経由のデータ漏洩を防いでいます。また Codex MCP は本エージェントでは有効化していません。Codex は独自のシェル実行エンジンを持ち Claude Code の deny rule を迂回するため、human-in-the-loop のない Slack bot では受け入れ不可と判断し、フックでブロックしています。
PreToolUse hook:fail-closed の安全網
#!/usr/bin/env bash
# PreToolUse security hook — deterministic enforcement layer
# Exit codes: 0 = allow, 2 = block
set -euo pipefail
# 0=allow / 2=block 以外で落ちたら block を返す(クラッシュ時に許可しない)
trap 'ec=$?; if [[ $ec -ne 0 && $ec -ne 2 ]]; then
echo "{ decision: block, reason: hook failed (exit $ec) — blocking for safety }"
exit 2
fi' EXIT注:上記の echo は可読性のため簡略表記にしています。実装では decision / reason を含む JSON を出力します。
シークレットファイル検出のパターン
正当な jq フィールドアクセスは通しつつ、鍵ファイルの読み取りだけを止めます(一部のパスは可読性のため簡略表記)。
secret_file_patterns=(
'.env(boundary)'
'.env.'
'.pem(boundary)'
'.key(boundary)'
'credentials.*.json'
'/proc//environ'
)
# .env.example / process.env.X / jq の .fields.parent.key は許可(ファイル読みではない)ポイントは boundary(境界)と pathchar(パス文字)の条件で「ファイルパスとして現れる鍵ファイル」だけを対象にし、{ key: .key } のようなオブジェクトアクセスを誤検知しないことです。
計測:PostToolUse hook × DX で効果を測る
「導入したが効果は?」に答えられなければ本番運用は続きません。私たちは、エージェントのツール実行を PostToolUse hook で捕捉し、DX にイベント送信しています。これにより「どのスキルやツールが、誰に、どれだけ使われたか」を継続的に計測できます。
設計には三つのポイントがあります。第一に fail-open です。計測はエージェントの動作を妨げてはいけないので、どんなエラーでも黙って正常終了します。セキュリティの PreToolUse が fail-closed なのとちょうど対照的で、層ごとに設計思想を逆にしているのが要点です。第二にセッション内重複排除で、同じイベント型は1セッションに1回だけ送ります。第三にメール解決で、Slack コンテキストからユーザーを特定し、bot やスケジュール実行ではフォールバックの共通アドレスに振り替えます。
興味深いのは、送信するだけでなくエージェント自身が DX のメトリクスを読むことです。チームスコアは MCP 経由で直接クエリし、Core4(Effectiveness / Impact / Quality / Speed)や sentiment を参照します。これにより、エージェントが自分の置かれたチームの開発者体験データを踏まえて振る舞える素地ができます。なお、コメント API は個人のメールを含むため、リポジトリに保存せず Slack にも出さず、必要時にオンデマンドで取得して 1on1 準備などの参照にのみ使う、という PII 取り扱いを徹底しています。
フロー:PostToolUse hook の処理
これによりダッシュボード側でスキル別・ツール別の利用状況を集計できます。
エージェントに「記憶」を持たせる:ナレッジの自動メンテナンス
ドメイン知識は Slack と Notion に散在し、放置すればエージェントは古い情報で答えてしまいます。私たちはこれをスケジュールジョブで継続的に更新しています。日次のチャンネルナレッジ抽出ジョブ(対象チャンネルの整備後に本格有効化予定)は、前日の人間同士の会話を読み、ドメインに関わる知識をスキルやナレッジとして抽出・提案します。
さらに、エージェントが対応した Slack スレッドを見直して有用な知識を登録し、既存エントリの更新・削除を整理する LangMem ベースの自動メンテナンスも回しています。RAG で都度検索するだけでなく、記憶そのものを継続的に手入れする発想です。
加えて「AI が読みやすいドキュメント構造」への投資も行いました。リポジトリ一覧や監視チャンネル一覧を機械可読な形で同期し、エージェントが参照しやすくしています。PCPにはリポジトリだけで約50個ほどあるのでこのような情報を整理することがスタートでした。知識の鮮度・ノイズ・ハルシネーションは依然として課題ですが、人手の更新に頼らない仕組みを基盤として持てたことが大きな前進でした。
自律スケジューラー:何が毎日・毎週動いているか
pcp-agent は Slack メンションでの起動だけでなく、cron ベースのスケジューラーで自律的にも動きます。これが「トリガーベースで人間のアクションを必要としない」というビジョンの実装そのものです。週次のダッシュボード要約やアラートダイジェストは、誰かが依頼しなくても毎週決まった時刻に投稿されます。
ジョブ定義は宣言的な YAML で、タイムゾーン・タイムアウト(active_deadline_seconds)・リトライ(backoff_limit)・多重起動抑止(concurrency_policy: forbid)・出力先 Slack チャンネルを指定できます。中心は「PCP Daily Schedule」で、平日毎朝9時(JST)に4つのルーティンを順番に実行し、各完了後に中間結果を Slack に投稿、最後に「本日のまとめ」を出します。当初は別々のジョブだったものを、一つの統合ワークフローに集約しました。このループを回すこと自体で、日々の会話からナレッジが溜まり、スキルも更新されていく、そうした自己更新的なループとして設計しています。
スケジュール例:
ジョブ
スケジュール
内容
pcp-daily-schedule
平日 9:00
4タスク統合:①リリースノート生成 ②対象リポジトリ追跡(新スキル取込提案)③既存スキル改善提案 ④LangMem ナレッジ前日分メンテ
xxxx-weekly-dashboard-summary
毎週月 10:30
各チームダッシュボードの週次サマリ
yyyy-weekly-alert-digest
毎週月 11:00
各チームアラートの週次ダイジェスト
- name: xxxx-weekly-alert-digest
enabled: true
cron: "0 11 * * 1" # Every Monday 11:00 (JST)
prompt_file: "config/prompts/xxxx-weekly-alert-digest.md"
timezone: "Asia/Tokyo"
active_deadline_seconds: 600 # 10分でタイムアウト
backoff_limit: 1 # 失敗時に1回リトライ
concurrency_policy: forbid # 前回実行中ならスキップポイントは、スケジューラーが単なる cron 以上であることです。タイムアウト、リトライ、多重起動抑止といったジョブ制御を持たせることで、自律実行を本番で安全に回せるようにしています。
実際のユースケース
pcp-agent の能力はスキルとしてファイル化され、実運用で次のようなユースケースに使われています。いずれも「決まった手順だが人手を食う」調査・集計・トリアージ作業です。
ユースケース
スキル
内容
障害・アラート調査
investigate-alert
アラートを起点に関連ログ・メトリクスをたどり一次切り分け
日次トリアージ
xxxx-daily-triage
XXXXチームの毎日の異常検知とトリアージ
問い合わせ調査
investigate-inquiry
問い合わせをドメイン知識付きで調査
週次サマリ
yyyy-weekly-alert-digest
各チームのアラート・ダッシュボードの週次要約
PR監視・Issue起票
watch-pr / issue / jira
レビュー補助と起票
この中でも最初のわかりやすいユースケースは調査のユースケースでした。
参考例として、Alert(トリガー) → Datadog(データ集約) → Slack / Notion等 (データ可視化・レポート) という流れです。すでに多くのエンジニアのローカル環境にはデータ調査スキルが存在すると思います。そのスキルをリモートに持ってきてトリガーさせるだけで一定の時間削減が実現でき、そしてローカルに存在するスキル(属人性)をリモートに持ってくることで誰でも同じ体験を実現することができます。
そして、これらのユースケースが「実際にどれだけ使われているか」を DX で可視化しています。どのユースケース(スキル)が、どのチームで、どれくらい使われたかをダッシュボードで追跡できます。エージェントの価値を「何ができるか(能力)」ではなく「何に使われているか(採用)」で測るのが狙いです。
プラットフォームとしての強み:1つのbotではなく、エージェント基盤
ここまで pcp-agent という1つのエージェントを見てきましたが、本当の狙いは個別のbotを作ることではありません。私たちが作ったのは remote-claude という再利用可能なプラットフォームで、pcp-agent はその上で動く1テナントにすぎません。同じ基盤の上に、SRE 向けの remote-claude-sre、ワークフロー自動化(n8n)向けの remote-claude-n8n が並んで動いており、data platform 領域へも展開しています。
プラットフォームと各エージェントの責務は明確に分かれています。共有基盤(remote-claude)が提供するのは、Slack統合、セッション隔離(copy-on-write)、cronスケジューラー、auth-proxy、PreToolUse/PostToolUseフックの仕組み、PIIリダクション、ランナーのリソース制限(メモリ・PID・CPU)といった「どのエージェントにも共通して必要な土台」です。各テナントが持つのは、自分のドメインに固有の workspace/.claude、つまりCLAUDE.md、スキル、ルールだけです。
この設計の効きどころは、新しいエージェントを立ち上げるコストの小ささです。共有設定は base.yaml に集約され、各エージェントは差分だけを上書きします。テンプレート(remote-claude/template)をコピーし、ドメイン知識をスキルとして足せば、Slack起動・隔離・スケジューラー・セキュリティ・計測がすべて最初から揃った状態で新しいテナントが立ち上がります。「決済の常駐エージェント」で作った仕組みが、そのまま他のチームにも転用できるわけです。
# remote-claude/config/base.yaml (全エージェント共通、各エージェントが上書き)
default_model: sonnet
use_proxy_network: true # ランナーに権限を与えずオーバーレイで経路制御
session_policy:
session_ttl_minutes: 10080 # 7 days
runner_memory_limit: "4g"
runner_pids_limit: 256
runner_idle_timeout_minutes: 30
slack_output_redaction: false # PIIリダクションをデプロイ単位でONにできるセキュリティや計測のような「外側で固める」部分をプラットフォーム側に持たせることで、各チームはドメイン知識の記述に集中でき、かつ全社的に一貫した安全性・可観測性を担保できます。これがエージェントを「点」ではなく「基盤」として広げる強みです。ちなみに remote-claude はもともと SRE 向け(cc-sre)に生まれ、そこから複数ドメインをホストする汎用プラットフォームへと一般化されていきました。
まとめ
半年運用して、いくつか確かな手応えがありました。まずスキル化は効きます。ドメイン知識を SKILL.md としてコード管理すると、エージェントの振る舞いが再現可能になり、レビューやテストの対象にできます。エージェント自身に新しいスキルを作らせるループも回り始めました。
もっとも、正直なところ最大の課題はユースケースの深掘りだと感じています。問い合わせのための調査のように、各所のパーツは AI に代替できる部分が出てきましたが、まだ人間がトリガーしている場面が多く、真に AI を軸に置いたフローになっているとは言えません。エージェントが受け取れるトリガーをさらに増やし、ユースケース全体を「AI 前提」のプロセスへ置き換えていきたいと考えています。
今後は、このエージェントを一つに統合するか、ドメインごとに分散させるかをユースケース次第で見極めていきます。LLM のコンテキストは有限なので、独自のワークフローが必要なユースケースが増えれば分散させる方針です。
加えて、社内でこうしたエージェントが増えていくほど、個々の精度以上に「フリート全体をどう統治し、どう観測するか」が重要になります。エージェントごとに権限・ポリシー・監査がバラバラだと、事故も非効率も増えていきます。そこで、ガバナンスと各エージェントの振る舞い・コスト・利用状況などを横断的に把握する仕組みを、今後プラットフォーム側で整えていきたいと考えています。
「AI エージェントを作ってみた」記事は数多くありますが、決済ドメインの本番チームに常駐させ、セキュリティを多層で固め、効果を計測しながら回すところまでやると、考えるべきことは一気に増えます。私たちが半年で取り組んだのは、その「面倒な部分」を実コードで埋めてきた記録です。そして、その面倒な部分を共有基盤(remote-claude)に寄せたことで、決済で作った仕組みを SRE や n8n へ横展開できる「エージェント基盤」に育ちつつあります。これから業務にエージェントを組み込む方にとって、安全性と計測をプラットフォーム側でどう設計するかの一例になれば幸いです。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み