Amazon SageMaker AIとAmazon BedrockでvLLMを使用して数十のファインチューニングモデルを効率的に提供
vLLMでMixture of ExpertsモデルのマルチLoRA推論を実装し、カーネルレベルの最適化を行い、効率的なモデル提供方法を解説。GPT-OSS 20Bを例に使用。
キーポイント
vLLMとAWSが共同開発したMulti-LoRA推論技術により、複数のファインチューニング済みモデルを単一GPUで効率的にホスト可能に
Mixture of Experts(MoE)モデル向けに最適化され、GPT-OSS、Qwen3-MoE、DeepSeek、Llama MoEなどで動作
GPU利用率向上によりコスト削減効果が大きく、5つの10%利用率GPUを1つの効率的共有GPUに集約可能
Amazon SageMaker AIとAmazon Bedrockで最適化版を利用可能で、vLLM 0.15.0より19%高いOTPSと8%低いTTFTを実現
影響分析・編集コメントを表示
影響分析
この技術はAIモデル運用の経済性を大きく改善し、特に複数のカスタムモデルを運用する組織にとってGPUコスト削減とリソース効率化に貢献する。AWSプラットフォームでの最適化により、クラウドAIサービスの競争力を高め、オープンソースモデルの実用化を促進する可能性がある。
編集コメント
複数モデルの効率的ホスティングという実務的な課題に対する技術的解決策が提示されており、AI運用コストに悩む企業にとって注目すべき内容。AWSのプラットフォーム最適化が競争優位性を生んでいる点も重要。
Amazon SageMaker AI および Amazon Bedrock で vLLM を用いて、数十のファインチューニング済みモデルを効率的に提供
複数のカスタム AI モデル、特に最近の Mixture of Experts (MoE) モデルファミリーを実行している組織や個人は、個々のモデルが専用コンピューティングエンドポイントの容量を飽和させるのに十分なトラフィックを受けない場合に、アイドル状態の GPU 容量に対して支払いを行うという課題に直面することがあります。この問題を解決するため、私たちは vLLM コミュニティと連携し、GPT-OSS や Qwen などの人気のあるオープンソース MoE モデルに対する Multi-LoRA (Multi-Low-Rank Adaptation) 提供のための効率的なソリューションを開発しました。Multi-LoRA はモデルをファインチューニングするための一般的なアプローチです。モデルの重み全体を再トレーニングするのではなく、Multi-LoRA では元の重みを凍結したまま、モデルの層に小さく学習可能なアダプターを注入します。Multi-LoRA を用いると、推論時には複数のカスタムモデルが同じ GPU を共有し、リクエストごとにアダプターのみを入れ替えるだけで済みます。例えば、5 人の顧客それぞれが専用 GPU の 10% しか利用していない場合でも、Multi-LoRA を用いれば単一の GPU から提供でき、5 つの未活用 GPU を 1 つの効率的に共有される GPU に変換できます。
本記事では、vLLM における Mixture of Experts (MoE) モデル向けの Multi-LoRA 推論の実装方法について説明し、私たちが行ったカーネルレベルの最適化を紹介するとともに、この取り組みから得られるメリットをご紹介します。本記事全体を通じて、GPT-OSS 20B を主要な例として使用します。
これらの改善点は、バージョン 0.15.0 以降のローカル vLLM デプロイメントですぐに利用可能です。マルチ LoRA サービングは now、GPT-OSS、Qwen3-MoE、DeepSeek、Llama MoE を含む MoE モデルファミリーで動作します。また、私たちの最適化は、Llama3.3 70B や Qwen3 32B などの密型モデルに対するマルチ LoRA ホスティングの改善にも寄与しています。Amazon 固有の最適化により、vLLM 0.15.0 と比較して追加的なレイテンシ改善が実現され、例えば GPT-OSS 20B では、Output Tokens Per Second (OTPS)(モデルが出力を生成する速度)が 19%向上し、Time To First Token (TTFT)(モデルの出力生成開始までにかかる待ち時間)が 8%短縮されます。これらの最適化を活用するには、LoRA カスタマイズ済みモデルを Amazon SageMaker AI または Amazon Bedrock でホストしてください。
vLLM における MoE モデル向けのマルチ LoRA 推論の実装
vLLM における MoE モデル向けのマルチ LoRA 推論の初期実装について詳しく掘り下げる前に、最適化の根拠を理解するために重要な MoE モデルと LoRA ファインチューニングに関する背景情報を提供します。MoE モデルには、エキスパートと呼ばれる複数の専門化されたニューラルネットワークが含まれています。ルーターが各入力トークンを最も関連性の高いエキスパートに割り当て、その出力をその後集約します。このスパースアーキテクチャでは、1 トークンあたりにモデルの全パラメータの一部のみが活性化されるため、計算リソースを抑えながら大規模なモデルを処理できます。詳細な可視化については、以下の図 1 を参照してください。
各エキスパートは、トークンの隠れ状態を2段階で処理する小さなフィードフォワードネットワークです。まず、gate_up
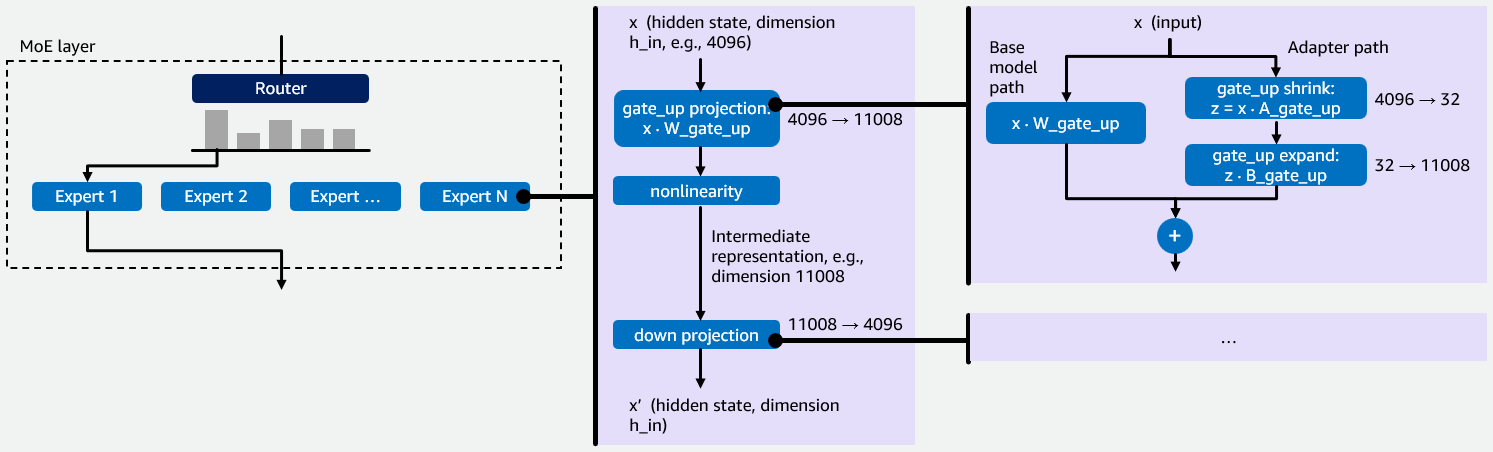
図 1: MoE-LoRA モデルの動作を、隠れ状態次元 4096、中間表現次元 11008、LoRA ランク r = 32 の例を用いて示したものです。
各エキスパートには 2 つの重み射影があります: gate_up
この実装を vLLM に統合することで、H200 GPU 上で GPT-OSS 20B を用いたマルチ LoRA サービングが可能となり、詩ベースのベンチマークである Sonnet データセットにおいて、入力長 1600、出力長 600、同時実行数 16 の条件下で、26 OTPS と 1053 ms の TTFT を達成しました。これらの結果を再現するには、vLLM GitHub リポジトリのリリース 0.11.1.rc3 にある PR をご確認ください。本ブログの後半では、これらのベースライン有効化数値からパフォーマンスをどのように最適化したかを示します。
vLLM におけるマルチ LoRA 推論性能の向上
初期実装を確定した後、NVIDIA Nsight Systems (Nsys) を用いてボトルネックを特定したところ、fused_moe_lora が問題であることが判明しました。
実行最適化
初期の実装では、マルチ LoRA の TTFT はベースモデルの TTFT(すなわち GPT-OSS 20B の公開リリース版)よりも 10 倍高く(悪く)ありました。プロファイリングの結果、Triton コンパイラが入力長に依存する変数をコンパイル時の定数として扱ってしまい、fused_moe_lora
cuModuleLoadData
do_not_specialize
Figure 2: Fused_moe_lora のプロファイリング結果
プロファイリングにより、fused_moe_lora についても明らかになりました。
シャープとエクスパンドカーネルは直列で実行されるため、初期の実装では 2 つのカーネル実行間にバブル(アイドル時間)が発生していました。カーネル実行をオーバーラップさせるために、Programmatic Dependent Launch (PDL) を実装しました。PDL を用いることで、依存するカーネルはメインのカーネルが完了する前に起動を開始でき、シャープカーネルが実行されている間にエクスパンドカーネルが重みを共有メモリと L2 キャッシュにプリフェッチできます。シャープカーネルが完了した時点で、エクスパンドカーネルはすでに重みを読み込んでおり、即座に計算を開始できます。
また、LoRA に対する CudaGraph を用いたスペキュレティブ・ディコーディング(推論)のサポートを追加し、ベースモデルとアダプターで異なる CudaGraph がキャプチャされてしまう vLLM の問題を修正しました。CudaGraph は GPU 演算シーケンスをキャプチャして GPU カーネルのオーバーヘッドを削減するために使用されるため、効率性に重要です(例:カーネルを単一ユニットとして扱う)。その結果、CPU オーバーヘッドとこれらのカーネル起動遅延を低減できます。当社の実行最適化により、OTP は推論なしで 50/100 から推論ありでも 50/100 に改善され、GPT-OSS 20B のデフォルト設定における TTFT(Time To First Token)は 150 ms に改善されました。本ブログの残りの部分では、スペキュレティブ・ディコーディングを有効にした状態での数値を報告します。
カーネル最適化
Split-K は、細い行列の負荷分散を改善するためのワーク分解戦略です。LoRA shrink では xA を計算します。
GPU スケジューラーは、複数のスレッドグループを同じ出力要素に割り当て、異なる出力要素のスレッドグループを同時に実行します。lora_shrink の場合も同様です。
また、shrink および expand LoRA カーネルから不要なマスク処理とドット積演算を削除しました。Triton カーネルは固定サイズのブロックでデータをロードしますが、行列の次元がこれらのブロックサイズに均等に割り切れない場合があります。例えば、BLOCK_SIZE_K が...
最後に、LoRA 重みの加算をベースモデルの重みとの結合を LoRA expand カーネルに統合しました。この最適化により、カーネル起動オーバーヘッドを削減できます。これらのカーネル最適化により、GPT-OSS 20B で 144 OTPS および 135 ms の TTFT を達成できました。
Amazon SageMaker AI および Amazon Bedrock 向けのカーネル設定のチューニング
Triton カーネルでは、ブロックサイズ(BLOCK_SIZE_M など)などのパラメータの調整が必要です。
デフォルト構成が標準的な融合 MoE に最適化されている MoE LoRA カーネルは、マルチ LoRA サービングにおいて性能が低いことが判明しました。これらのデフォルト設定には、LoRA インデックスに対応する追加グリッド次元や、複数のアダプターによる複合スパース性が考慮されていません。このボトルネックに対処するため、ユーザーがカスタムチューニング済み構成をフォルダパスの提供によりロードできるようにサポートを追加しました。詳細については、vLLM LoRA Tuning ドキュメントをご覧ください。私たちは 4 つの fused_moe_lora をチューニングしました。
結果と結論
vLLM コミュニティとの協力により、GPT-OSS、Qwen3 MoE、DeepSeek、Llama MoE などの MoE モデルに対するマルチ LoRA サービングを実装し、オープンソース化しました。その後、最適化を適用した結果、vLLM 0.15.0 における GPT-OSS 20B の OTPS(秒間出力トークン数)は vLLM 0.11.1rc3 と比較して 454% 向上し、TTFT(初回トークンまでの時間)は 87% 短縮されました。一部の最適化、特にカーネルチューニングや CTA スウィッシングは、Qwen3 32B の OTPS が 99% 改善されるなど、密結合モデルのパフォーマンスも向上させました。これらの成果をローカル環境でのデプロイメントで活用するには、vLLM 0.15.0 以降を使用してください。Amazon Bedrock および Amazon SageMaker AI で利用可能な Amazon 固有の最適化により、GPT-OSS 20B の場合、vLLM 0.15.0 と比較して OTPS が 19% 高速化され、TTFT が 8% 改善されるなど、モデル全体にわたって追加のレイテンシ削減を実現しています。Amazon 上でのカスタムモデルホスティングを開始するには、Amazon SageMaker AI のホスティングおよび Amazon Bedrock のドキュメントをご覧ください。
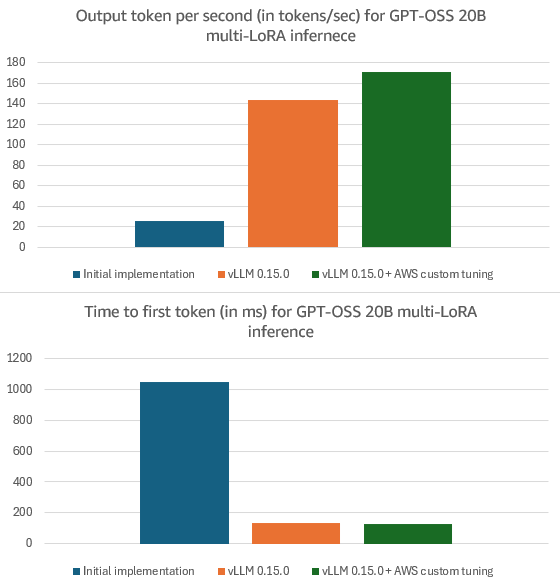
図 3: GPT-OSS 20B のマルチ LoRA 推論における秒間出力トークン数(OTPS)および初回トークンまでの時間(TTFT):1/vLLM 0.11.1rc3 での初期実装、2/vLLM 0.15.0 使用時、3/vLLM 0.15.0 に AWS カスタムカーネルチューニングを追加した場合。実験では、LoRA ランク 32 および並列ロードされた 8 個のアダプターを使用し、入力トークン数は 1600、出力トークン数は 600 としました。
謝辞
vLLM コミュニティの貢献者および協力者の皆様、Jee Li 氏、Chen Wu 氏、Varun Sundar Rabindranath 氏、Simon Mo 氏、Robert Shaw 氏ならびに、当チームメンバーの Xin Yang 氏、Sadaf Fardeen 氏、Ashish Khetan 氏、George Karypis 氏に対し、心より感謝申し上げます。
著者について
原文を表示
Efficiently serve dozens of fine-tuned models with vLLM on Amazon SageMaker AI and Amazon Bedrock
Organizations and individuals running multiple custom AI models, especially recent Mixture of Experts (MoE) model families, can face the challenge of paying for idle GPU capacity when the individual models don’t receive enough traffic to saturate a dedicated compute endpoint. To solve this problem, we have partnered with the vLLM community and developed an efficient solution for Multi-Low-Rank Adaptation (Multi-LoRA) serving of popular open-source MoE models like GPT-OSS or Qwen. Multi-LoRA is a popular approach to fine-tune models. Instead of retraining entire model weights, multi-LoRA keeps the original weights frozen and injects small, trainable adapters into the model’s layers. With multi-LoRA, at inference time, multiple custom models share the same GPU, with only the adapters swapped in and out per request. For example, five customers each utilizing only 10% of a dedicated GPU can be served from a single GPU with multi-LoRA, turning five underutilized GPUs into one efficiently shared GPU.
In this post, we explain how we implemented multi-LoRA inference for Mixture of Experts (MoE) models in vLLM, describe the kernel-level optimizations we performed, and show you how you can benefit from this work. We use GPT-OSS 20B as our primary example throughout this post.
You can use these improvements today in your local vLLM deployments with version 0.15.0 or later. Multi-LoRA serving now works for MoE model families including GPT-OSS, Qwen3-MoE, DeepSeek, and Llama MoE. Our optimizations also help improve multi-LoRA hosting for dense models, e.g., Llama3.3 70B or Qwen3 32B. Amazon-specific optimizations deliver additional latency improvements over vLLM 0.15.0, e.g., 19% higher Output Tokens Per Second (OTPS) (i.e., how fast the model generates output) and 8% lower Time To First Token (TTFT) (i.e., how long you have to wait before the model starts to generate output) for GPT-OSS 20B. To benefit from these optimizations, host your LoRA customized models on Amazon SageMaker AI or Amazon Bedrock.
Implementing multi-LoRA inference for MoE models in vLLM
Before we dive into our initial implementation of multi-LoRA inference for MoE models in vLLM, we want to provide some background information on MoE models and LoRA fine-tuning that is important for understanding the rationale behind our optimizations. MoE models contain multiple specialized neural networks called experts. A router directs each input token to the most relevant experts, whose outputs are then aggregated. This sparse architecture processes larger models with fewer computational resources because only a fraction of the model’s total parameters are activated per token, see Figure 1 below for a visualization.
Each expert is a small feed-forward network that processes a token’s hidden state in two stages. First, the gate_up
Figure 1: Illustration of how MoE-LoRA models work with an example hidden state dimension 4096, intermediate representation dimension 11008 and LoRA rank r = 32.
Each expert has two weight projections: gate_up
With this implementation merged into vLLM, we could run a multi-LoRA serving with GPT-OSS 20B on an H200 GPU, reaching 26 OTPS and 1053 ms TTFT on the Sonnet dataset (a poetry-based benchmark) with input length of 1600, output length of 600 and concurrency of 16. To reproduce these results, check out our PR in the release 0.11.1.rc3 from the vLLM GitHub repository. In the rest of this blog, we will show how we optimized the performance from these baseline enablement numbers.
Improving multi-LoRA inference performance in vLLM
After finalizing our initial implementation, we used NVIDIA Nsight Systems (Nsys) to identify bottlenecks and found the fused_moe_lora
Execution optimizations
With our initial implementation, the multi-LoRA TTFT was 10x higher (worse) than the base model TTFT (i.e., the public release version of GPT-OSS 20B). Our profiling revealed that the Triton compiler treated input-length-dependent variables as compile-time constants, causing the fused_moe_lora
cuModuleLoadData
do_not_specialize
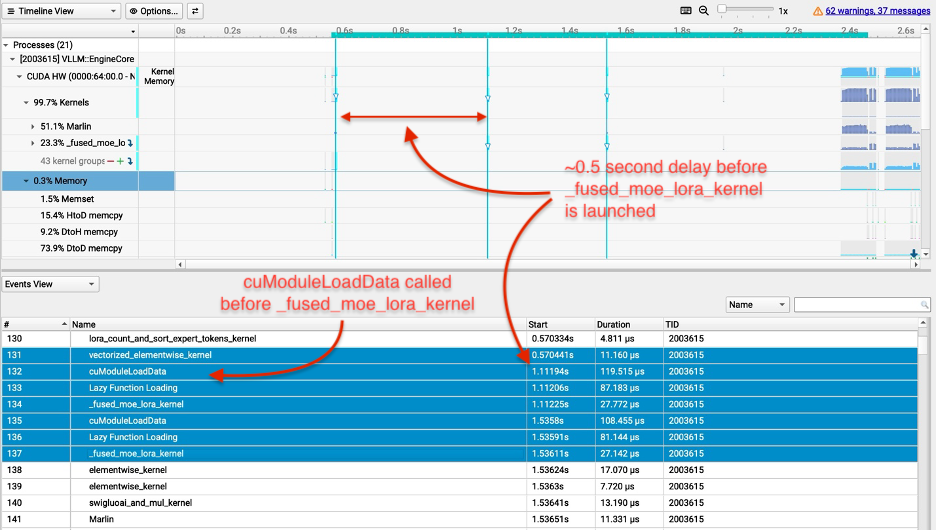
Figure 2: Profiling results for fused_moe_lora
Profiling also revealed that our fused_moe_lora
The shrink and expand kernels run serially, which created bubbles between executions of two kernels in our early implementation. To overlap the kernel execution, we implemented Programmatic Dependent Launch (PDL). With PDL, a dependent kernel can begin to launch before the primary kernel finishes, which lets the expand kernel pre-fetch weights into shared memory and L2 cache while the shrink kernel runs. When the shrink kernel completes, the expand kernel has already loaded its weights and can immediately begin computation.
We also added support for speculative decoding with CudaGraph for LoRA, fixing an issue in vLLM which would capture different CudaGraphs for the base model and adapter. CudaGraphs are important for efficiency since they are used to capture sequences of GPU operations to help reduce GPU kernel overhead, e.g., kernels as a single unit. As a result, CudaGraphs can reduce CPU overheads and these kernel launch latencies. With our execution optimizations, OTPS improved to 50/100 without/with speculative decoding and TTFT improved to 150 ms for GPT-OSS 20B using the default configuration. For the remainder of the blog, we report the numbers with speculative decoding on.
Kernel optimizations
Split-K is a work decomposition strategy that helps improve load balancing for skinny matrices. LoRA shrink computes xA
The GPU scheduler assigns multiple thread groups to the same output element and runs thread groups for different output elements at the same time. For lora_shrink
We also removed unnecessary masking and dot product operations from the shrink and expand LoRA kernels. Triton kernels load data in fixed-size blocks, but matrix dimensions may not divide evenly into these block sizes. For example, if BLOCK_SIZE_K
Lastly, we fused the addition of the LoRA weights with the base model weights into the LoRA expand kernel. This optimization helps reduce the kernel launch overhead. These kernel optimizations helped us reach 144 OTPS and 135 ms TTFT for GPT-OSS 20B.
Tuning kernel configurations for Amazon SageMaker AI and Amazon Bedrock
Triton kernels require tuning of parameters such as block sizes (BLOCK_SIZE_M
We found that the MoE LoRA kernels using default configurations optimized for standard fused MoE performed poorly for multi-LoRA serving. These defaults did not account for the additional grid dimension corresponding to the LoRA index and the compound sparsity from multiple adapters. To address this bottleneck, we added support for users to load custom tuned configurations by providing a folder path. For more information, see the vLLM LoRA Tuning documentation. We tuned the four fused_moe_lora
Results & Conclusion
Through our collaboration with the vLLM community, we implemented and open-sourced multi-LoRA serving for MoE models including GPT-OSS, Qwen3 MoE, DeepSeek, and Llama MoE. We then applied optimizations, e.g, yielding 454% OTPS improvements and 87% lower TTFT for GPT-OSS 20B in vLLM 0.15.0 vs vLLM 0.11.1rc3. Some optimizations, particularly kernel tuning and CTA swizzling, also improved performance for dense models, e.g., Qwen3 32B OTPS improved by 99%. To leverage this work in your local deployments, use vLLM 0.15.0 or later. Amazon-specific optimizations, available in Amazon Bedrock and Amazon SageMaker AI, help deliver additional latency improvements across models, e.g., 19% faster OTPS and 8% better TTFT vs vLLM 0.15.0 for GPT-OSS 20B. To get started with custom model hosting on Amazon, see the Amazon SageMaker AI hosting and Amazon Bedrock documentation.
Figure 3: Output tokens per second (OTPS) and time to first token (TTFT) for GPT-OSS 20B multi-LoRA inference: 1/ Initial implementation in vLLM 0.11.1rc3; 2/ with vLLM 0.15.0; 3/ with vLLM 0.15.0 and AWS custom kernel tuning. Experiments used 1600 input tokens and 600 output tokens with LoRA rank 32 and 8 adapters loaded in parallel.
Acknowledgments
We would like to acknowledge the contributors and collaborators from the vLLM community: Jee Li, Chen Wu, Varun Sundar Rabindranath, Simon Mo and Robert Shaw, and our team members: Xin Yang, Sadaf Fardeen, Ashish Khetan, and George Karypis.
About the authors
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み