AI エージェントに記憶機能を実装する方法
LangChain Blog は、AI エージェントの信頼性と複雑なタスク遂行能力を向上させるために、短期・長期記憶を統合する具体的なアーキテクチャと実装手法を詳述している。
キーポイント
記憶の階層化アーキテクチャ
エージェントがタスクを遂行するために必要な情報を、短期記憶(コンテキストウィンドウ内)と長期記憶(ベクトルデータベース等)に明確に分離・管理する設計思想。
メモリ管理の自動化手法
LLM を活用して情報の重要度を自動評価し、不要なデータを圧縮または削除することで、コストとコンテキスト制限を最適化する具体的なアルゴリズム。
実装パターンとツール連携
LangChain の既存コンポーネントや外部ストレージとの連携方法を提示し、開発者がすぐに適用可能なコード例や設計パターンの提供。
影響分析・編集コメントを表示
影響分析
本記事は、単なるチャットボットから自律的なタスク実行型エージェントへの移行において、最も欠落していた「継続的な文脈保持」の解決策を示すものであり、実用レベルの AI エージェント開発における標準的なベストプラクティスとして定着する可能性が高い。特に、メモリ管理の自動化手法は、大規模なエンタープライズ利用におけるコストと性能のバランスを改善する重要な指針となる。
編集コメント
AI エージェントの実用化において「記憶」は次なるボトルネックであり、このアーキテクチャ解説は開発者にとって即戦力となる重要な指針です。
エージェントに記憶機能を与える方法

エージェントが過去の行動から学習できるように ループ を構築することで、ユーザーと共に学習する心地よいエージェント体験を作成できます。これは通常記憶と呼ばれます。記憶があるかどうかは、ユーザーが毎回同じ修正を繰り返さなければならないのか、それとも一度指示されたことを正しく実行する方法をエージェントが覚えていられるのかという違いを生む要因となります。
実装はまだ進化途上にありますが、その抽象化はシンプルです。記憶を実装するには、エージェントがミスを犯した箇所や新しい情報を学習できた可能性のある場所を探し出し、その情報を抽出・一般化してデータ構造に格納するプロセスをバックグラウンドで実行する必要があります。そこにはまだ解明すべき詳細な点が多くあります。本稿では、このプロセスの具体的な実装例を追跡します。ここでは以下の技術を使用します:
- トレースストアとして LangSmith Observability を使用
- トレースを分析するプロセスとして LangSmith Engine を使用
- メモリストアとして LangSmith Context Hub を使用
記憶とは何か?
記憶とは、エージェントが実行を跨いで取得可能な永続的な文脈のことです。これには事実、好み、過去の対話、指示、スキル、例、学習されたパターンなどが含まれる可能性があります。
トレース、トランスクリプト、またはログは、何が起こったかを示す有用な証拠となります。しかし、それらが記憶となるのは、関連する教訓がエージェントが後で実行時に検索し、行動を変更するために使用できるコンテキストに変換された時だけです。
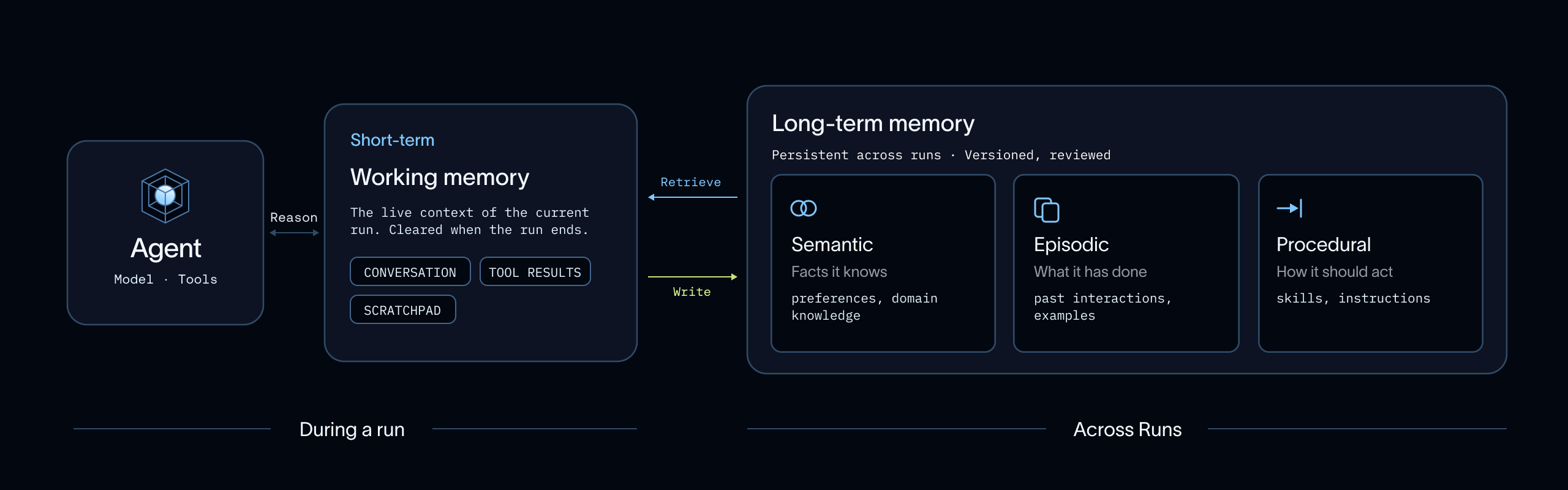
何をどこに配置するかを決定するには、記憶を2つのスコープに分けることが役立ちます:短期(または「ワーキング」)メモリと長期メモリです。
短期メモリは、エージェントが目の前のタスクを実行している間に利用可能なコンテキストを指します。これには、現在のスレッド、直近のメッセージ、ツール実行結果、取得されたドキュメント、中間的な推論アーティファクト、および現在のジョブを完了するために必要な一時的なファイルや状態が含まれます。
長期メモリは、現在の実行を超えて永続するコンテキストです。これには、後で利用可能となり、時間の経過とともにエージェントの行動を形成すべき事実、好み、例、ワークフロー、ポリシー、指示、およびスキルが含まれます。
両者の関係は読み書きのサイクルです。実行中、ハネスが関連するコンテキストを利用可能にすると、エージェントは長期記憶から恩恵を受けます。これはプロンプトの組み立て、ストアからの検索、ツールへのアクセス、ファイル、ランタイムの状態、またはその他のコンテキスト読み込みメカニズムを通じて行われる可能性があります。実行が進むにつれて作業メモリは変化します。実行後、トレースは発生したことの証拠を提供します。その証拠の多くは履歴として残すべきですが、一部には有用なシグナルが含まれているかもしれません:エージェントが記憶すべき嗜好、明確化する必要がある指示、ルールとなるべきツール使用パターン、または更新されるべきスキルなどです。
長期記憶を考える際の実用的な方法は、それを意味記憶、エピソード記憶、手続き的記憶に分離して考えることです。これは認知科学から借用された分類法 [arxiv.org/abs/2309.02427] であり、言語エージェントシステムによくマッピングされています。
- 意味記憶とは、エージェントが知っていること:事実、嗜好、一般的な知識です。
- エピソード記憶とは、エージェントが経験したこと:過去の相互作用、例、行動、結果です。
- 手続き的記憶とは、エージェントがどのように振る舞うべきか:指示、ワークフロー、ポリシー、スキル、ツール使用ルールです。
エージェントの振る舞いにおける最も目に見える改善の多くは、*手続き的*メモリから生じます。エージェントが繰り返し回答を誤ってフォーマットしたり、ツールの呼び出し順序を間違えたり、不適切なサブエージェントに委任したり、トーンルールを無視したりする場合、その修正は往々にして手続き的なものになります:ルールをより明確にする、エージェントが従う手順を変更する、あるいはそのタスクを担当するより具体的なスキルへと振る舞いを移すことです。
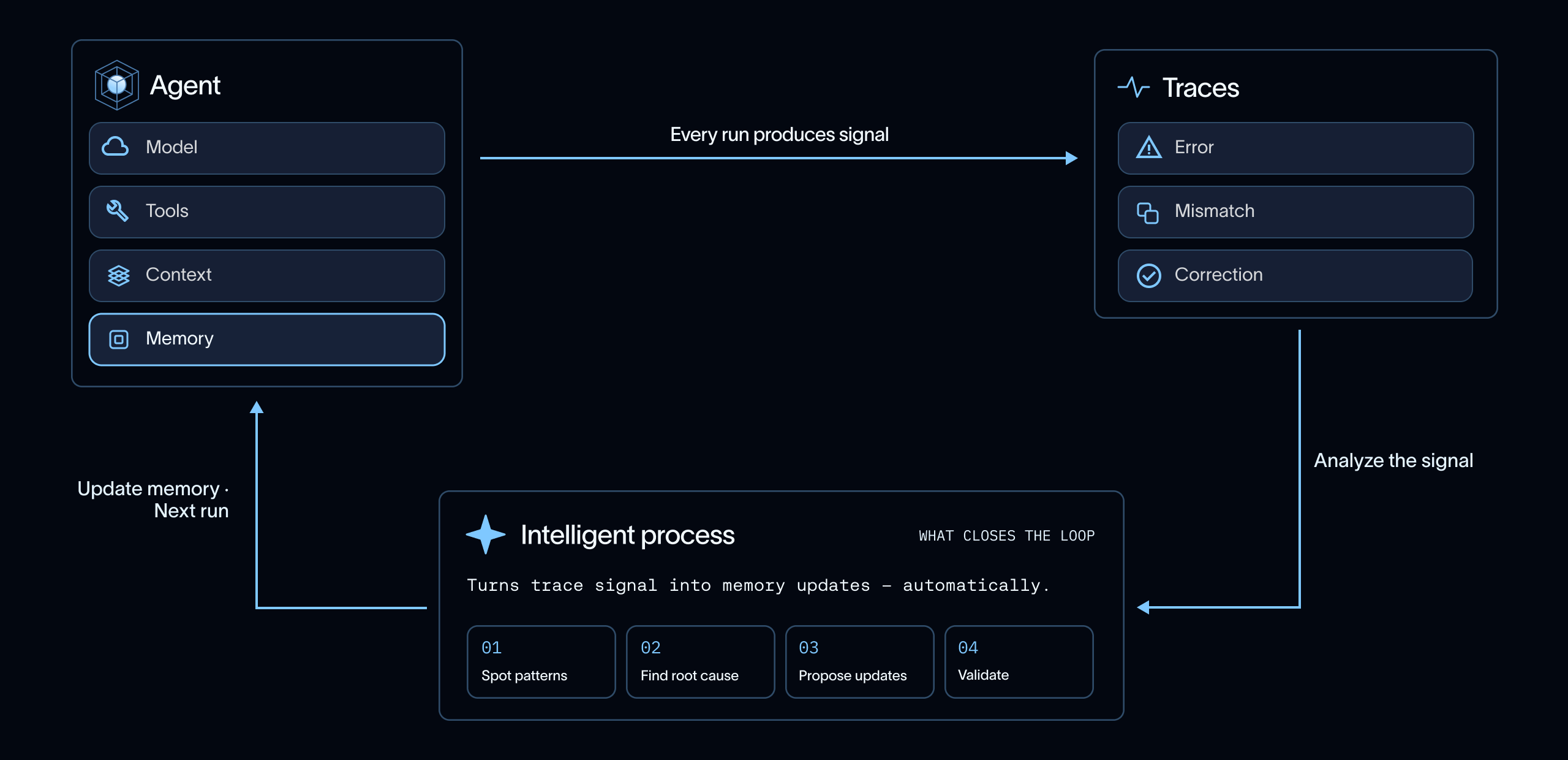
高レベルなメモリプロセス
高レベルで見れば、適切に機能するエージェントのメモリループには3つの部分があります:トレースのキャプチャ、トレースの分析、そしてメモリの更新です。
1. トレースのキャプチャ
トレースは証拠層です。十分に計測されたトレースは、タスクを遂行する際にエージェントがたどった経路を記録します:ユーザー入力、モデル呼び出し、ツールの入出力、取得したドキュメント、ルーティング決定、レイテンシ、エラー、そして多くの場合ユーザーフィードバックが含まれます。
これは重要です。なぜなら、従来の決定論的ソフトウェアとは異なり、エージェントの軌跡を検査するまで、その振る舞いがどうだったかを知らないことが多々あるからです。予期せぬ振る舞いは、弱いプロンプト、欠落しているツール、混乱を招くツールのスキーマ、不適切な検索、古くなったコンテキスト、過度に広範な指示、あるいは静かに作業を誤った場所に送ってしまったルーティング決定などが原因である可能性があります。トレースを検査することで、これらの原因を特定することができます。
2. トレースの分析
トレースをキャプチャした後、次のステップは有用なシグナルを見つけることです。一部のシグナルは明示的なフィードバックや評価失敗から得られます。また、一部は反復するパターンから得られます:同じ悪い出力、同じ無効なツール呼び出し、同じルーティングミス、または同じ無視された指示です。
厄介なのは診断の部分です。同じ症状が異なる修正策を指し示すことがあります。エージェントがトーンルールを無視する場合、そのルールは曖昧すぎるか、場所が間違っているか、関連するスキルから欠落しているか、あるいは別の指示と矛盾している可能性があります。
3. メモリの更新
シグナルを理解したら、システムは将来のコンテキストを変更する必要があるかどうかを決定すべきです。これには、指示を明確にするやルーティングルールを変更するなど、問題の修正が含まれる場合がありますが、ユーザーの好み、成功した例、またはエージェントが後で再利用すべきパターンなど、有用な何かを記憶することを含めることもあります。
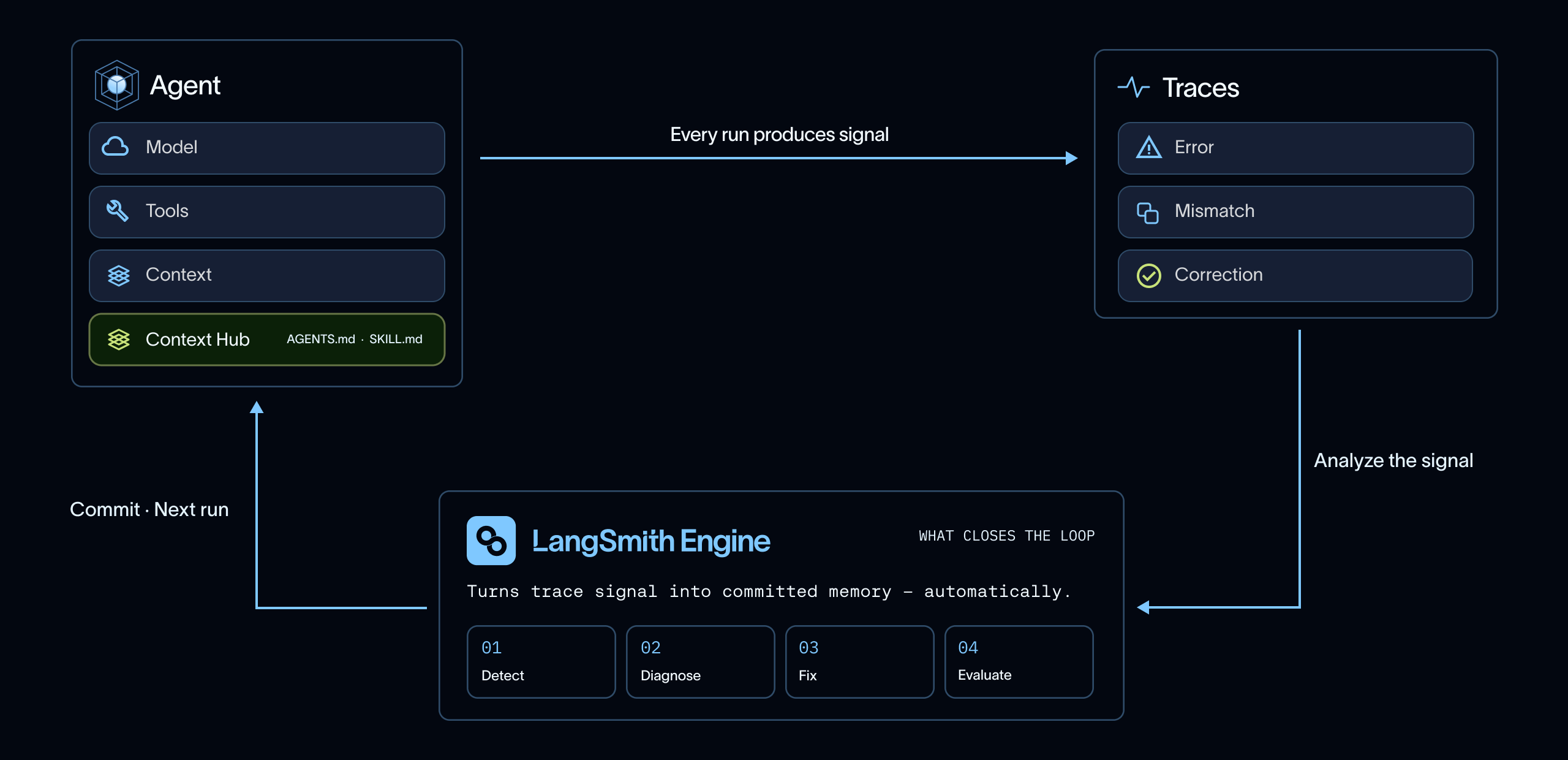
LangSmith でこれを行う方法
LangSmith を使って、このエージェントメモリループ全体を実行できます:
- トレースのキャプチャ: LangSmith Observability
- トレースの分析: LangSmith Engine
- メモリの更新: LangSmith Context Hub
LangSmith では、トレーシングがキャプチャステップを提供します。トレーシングプロジェクトは、エージェントがどのような経路をたどったかという豊富な記録を提供し、なぜそのように振る舞ったのかを検査・理解できるようにします。
LangSmith Engine は、これらのトレースを改善のシグナルに変換するバックグラウンドプロセスです。すべての実行を手動で検査する必要はなく、Engine は反復的な問題についてトレースを分析し、考えられる根本原因を診断し、将来の動作を改善するための具体的な変更点を提示します。具体的には、ルールの追加、関連ワークフローに近づけるための指示の移動、新しい例の作成、スキルの更新、またはルーティングポリシーの変更などが含まれます。
Context Hub は、これらの変更が永続的なエージェントコンテキストとなる場所です。エージェントが使用する指示、ツール、スキルをバージョン管理された場所で管理できるため、メモリはアプリケーションコード内に置かれた一時的なプロンプト編集に留まりません。
一度コンテキストが更新されると、将来の実行ではそれが再びエージェントに読み込まれます。これでループが閉じます。つまり、トレースがキャプチャされ、Engine が改善のシグナルを抽出し、Context Hub がメモリを保存し、次の実行は更新されたコンテキストから始まります。
有用なメモリのための設計原則(経験から)
このループを信頼性のあるものにするためのいくつかの原則があります:
- メモリ更新にすべきことはすべてではありません。トレースデータの多くは履歴として残すべきです。一部はデータセットの例、評価用テスト、コード変更、またはツールスキーマの修正になるべきです。永続的なコンテキストとなるのはごく一部のサブセットのみであるべきです。
- 将来の実行で実際に更新内容が読み込まれるようにしてください!ランタイムがプロンプト、ツール、スキルをキャッシュしている場合、メモリコミットにはリフレッシュパスが必要です。そうでなければ、システムは正しい更新内容を保存しながらも、古いコンテキストのまま実行し続ける可能性があります。
- 重要な振る舞いは評価(evals)で保護してください。将来の振る舞いを形作るほどに重要であるメモリ更新であれば、その振る舞いが後退したことを検出する方法を持つ価値があるのが通常です。
謝辞
Sydney Runkle と Harrison Chase の、考え抜かれたレビューとフィードバックに感謝します。

エージェントが実際に何をしているかを確認する
LangSmith は、エージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの決定をデバッグし、変更の評価を行い、ワンクリックでデプロイできるよう支援します。
原文を表示
How To Give Your Agent Memory
Building a loop so that your agent can learn from previous actions allows you to create delightful agentic experiences that learn with the user. This is often called memory. Memory can be the difference between your users having to constantly repeat corrections instead of the agent remembering how to do something correctly after the first time it is told.
The implementations are still evolving, but the abstractions are simple. In order to implement memory, you’ll want to run some process in the background that looks for places the agent made a mistake or could have learned new information, and extract/generalize that information into a data structure. There are a lot of details yet to be figured out there. This post walks through a concrete implementation of this process. It will use:
- LangSmith Observability as a trace store
- LangSmith Engine as a process that analyzes traces
- LangSmith Context Hub as a memory store
What is memory?
Memory is durable context that an agent can retrieve across runs to guide its behavior. It may include facts, preferences, past interactions, instructions, skills, examples, and learned patterns.
A trace, transcript, or log is useful evidence of what happened. It becomes memory only when the relevant lesson is converted into context the agent can retrieve on a later run and use to change its behavior.
To decide what belongs where, it helps to separate memory into two scopes: short-term (or ‘working’) memory and long-term memory.
Short-term memory is the context available while the agent is doing the task in front of it: the current thread, recent messages, tool results, retrieved documents, intermediate reasoning artifacts, and temporary files or state the agent needs to finish the current job.
Long-term memory is context that persists beyond the current run: facts, preferences, examples, workflows, policies, instructions, and skills that should be available later to shape the agent’s behavior over time.
The relationship between the two is a read-and-write cycle. During a run, the agent benefits from long-term memory once the harness makes the relevant context available. That might happen through prompt assembly, retrieval from a store, tool access, files, runtime state, or some other context-loading mechanism. As the run unfolds, working memory changes. After the run, the trace gives us evidence of what happened. Most of that evidence should remain history, but some of it may contain useful signal: a preference the agent should remember, an instruction that needs to be clarified, a tool-use pattern that should become a rule, or a skill that should be updated.
A useful way to think about long-term memory is to separate it into semantic, episodic, and procedural memory, a taxonomy borrowed from cognitive science and commonly mapped onto language-agent systems.
- Semantic memory is what the agent knows: facts, preferences, and general knowledge.
- Episodic memory is what the agent has experienced: past interactions, examples, actions, and outcomes.
- Procedural memory is how the agent should behave: instructions, workflows, policies, skills, and tool-use rules.
Many of the most visible improvements in agent behavior come from *procedural* memory. When an agent repeatedly formats answers incorrectly, calls tools in the wrong order, delegates to the wrong subagent, or ignores a tone rule, the fix is often procedural: make the rule clearer, change the steps the agent follows, or move the behavior into a more specific skill that owns that task.
The high-level memory process
At a high level, a well-functioning agent memory loop has three parts: capture traces, analyze traces, and update memory.
1. Capture traces
Traces are the evidence layer. A well-instrumented trace records the path an agent took through a task: the user input, model calls, tool inputs and outputs, retrieved documents, routing decisions, latency, errors, and often user feedback.
This is important because, unlike traditional deterministic software, you often do not know how an agent behaved until you inspect its trajectory. Unexpected behavior might be caused by a weak prompt, a missing tool, a confusing tool schema, poor retrieval, stale context, an overly broad instruction, or a routing decision that quietly sent the work to the wrong place. Inspecting a trace allows you to isolate these causes.
2. Analyze traces
Once traces are captured, the next step is to find useful signal. Some signal comes from explicit feedback or eval failures. Some comes from recurring patterns: the same bad output, the same invalid tool call, the same routing mistake, or the same ignored instruction.
The tricky part is diagnosis. The same symptom can point to different fixes. If the agent ignores a tone rule, the rule might be too vague, in the wrong place, missing from the relevant skill, or contradicted by another instruction.
3. Update memory
Once the signal is understood, the system should decide whether future context needs to change. That might mean fixing an issue, like clarifying an instruction or changing a routing rule, but it can also mean remembering something useful, like a user preference, a successful example, or a pattern the agent should reuse later.
How to do this with LangSmith
You can do this whole agent memory loop with LangSmith:
- Capture traces: LangSmith Observability
- Analyze traces: LangSmith Engine
- Update Memory: LangSmith Context Hub
In LangSmith, tracing gives you the capture step. Tracing projects give you a rich store of the trajectories that your agent took so that you can inspect and understand why the agent behaved the way it did.
LangSmith Engine is the background process that turns those traces into improvement signal. Instead of requiring you to inspect every run manually, Engine analyzes traces for recurring issues, diagnoses likely root causes, and surfaces concrete changes that could improve future behavior - it might add a rule, move an instruction closer to the relevant workflow, create a new example, update a skill or change a routing policy.
Context Hub is where those changes can become durable agent context. It gives you a versioned place to manage the instructions, tools, and skills your agents use, so memory is not just an ad hoc prompt edit sitting in application code.
Once the context is updated, future runs load it back into the agent. That closes the loop - traces are captured, Engine extracts improvement signal, Context Hub stores the memory, and the next run starts with updated context.
Design principles for useful memory (from experience)
A few principles to help make this loop reliable:
- Not everything should be a memory update. Most trace data should remain history. Some should become dataset examples, evals, code changes, or tool-schema fixes. Only a small subset should become durable context.
- Make sure future runs actually read the update! If the runtime caches prompts, tools, or skills, memory commits need a refresh path. Otherwise the system may store the right update while continuing to run with stale context.
- Protect important behavior with evals. If a memory update matters enough to shape future behavior, it is usually worth having a way to detect when that behavior regresses.
Acknowledgements
Thanks to Sydney Runkle and Harrison Chase for their thoughtful review and feedback.
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
2026 年に AI エンジニアになるためのロードマップ
KDnuggets が、2026 年までに AI エンジニアとして活躍するための学習ロードマップを提示している。
Klarna の AI アシスタントが 8500 万人のユーザー向けに大規模カスタマーサポートを再定義した方法
決済大手 Klarna は、8500 万人のアクティブユーザーを対象とした顧客サポートにおいて、AI アシスタントを導入することで業務効率と対応品質を劇的に向上させました。
Nous Research、Hermes エージェントのスキルシステムに「/learn」機能を追加、手書きなしでワークフローをスラッシュコマンドとして記録可能に
Nous Research はオープンソースの自己改善型エージェント「Hermes Agent」のスキルシステムを拡張し、「/learn」という新コマンドを追加した。これにより、ユーザーはドキュメントやコードなどの資料を指定するだけで、エージェントが自動的に再利用可能なスキル定義ファイル(SKILL.md)を作成できるようになった。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み