Mistral OCR 4:文書知能のための最先端 OCR ツール(9 分読了)
Mistral AI は、170 か国語に対応し、自己完結型デプロイと構造化データ抽出を可能にする「Mistral OCR 4」を発表し、エンタープライズ向け文書処理の新たな基準を示した。
キーポイント
SOTA な性能と構造化出力
独立評価において既存の主要 OCR システムを上回る 72% の勝率を記録し、テキスト抽出に加え、バウンディングボックス、ブロック分類(表、式など)、信頼度スコアを同時に提供。
完全なオンプレミス対応
単一コンテナで動作するコンパクトなモデル設計により、データ主権やコンプライアンスが求められる環境でも自己完結型でのデプロイが可能。
検索基盤との統合強化
Mistral Search Toolkit と連携し、構造化された出力を RAG(生成拡張)や企業検索パイプラインの ingestion 要素として直接活用できる。
影響分析・編集コメントを表示
影響分析
このリリースは、OCR技術を単なる文字認識から、RAGや検索システムに直接組み込める構造化データ生成へと進化させる重要な転換点です。特に、オンプレミス環境での高品質な処理が可能になることで、機密性の高い文書を取り扱う金融や法務分野などにおけるAI導入の障壁を大幅に低下させると予想されます。
編集コメント
単なる文字認識の精度向上だけでなく、バウンディングボックスやブロック分類といった構造化情報を出力できる点は、RAGシステムの実用性を飛躍的に高める要素です。特に「単一コンテナ」での動作保証は、セキュリティ要件が厳しい企業顧客にとって決定的なメリットとなります。
本日、Mistral OCR 4 をリリースいたします。本モデルは、抽出されたテキストに加え、バウンディングボックス、ブロック分類、インライン信頼度スコアを特徴としています。170 の言語(10 の言語グループに分類)に対応し、単一のコンテナで動作するため、完全なセルフホストデプロイメントが可能です。また、エンタープライズ検索、RAG(Retrieval-Augmented Generation)、ドメイン固有の検索パイプライン におけるインgestion コンポーネントとしても機能します。OCR 4 は小型で焦点を絞ったモデルであり、本記事では新機能、パブリックおよび内部ベンチマーク上でのパフォーマンス、これらのベンチマークが抱える既知の制限、そしてモデル API と Document AI の使い分けに関するガイダンスについて解説します。
ハイライト
- 画期的なパフォーマンス。独立した注釈付け者たちは、テストされたすべての主要 OCR およびドキュメント AI システムに対して OCR 4 を好んでおり、勝率は平均 72% に達しています。また、OlmOCRBench における総合スコアでもトップ(85.20)を獲得しました。詳細な手法と既知のスコアリング制限については、以下のベンチマークセクションをご覧ください。
- テキスト抽出だけでなく、セグメンテーションも提供します。OCR 4 は抽出されたテキストに加え、バウンディングボックス、タイプ別ブロック分類(タイトル、表、数式、署名など)、およびインライン信頼度スコアを返します。最も要望の多かった機能であるバウンディングボックスは、コンテキスト内でのハイライト処理や信頼性の高いデータパイプラインのためにテキストの位置特定を実現します。同時に、ブロックタイプと信頼度スコアは、ソースに根ざした引用、削除、および人間による検証(human-in-the-loop verification)を駆動します。
- Mistral Search Toolkit と統合されています(パブリックプレビュー)。OCR 4 は、AI Now Summit で発表された Mistral のオープンソースでコンポーザブルな検索フレームワークである Search Toolkit の取り込みコンポーネントです。その構造化出力は、RAG およびエンタープライズ検索のためのツールの取り込み、検索、評価ワークフローに、引用準備が整った入力データを供給します。
- 多言語対応。10 の言語グループにわたる 170 か国語をサポートしており、競合するいくつかのシステムで性能が低下する専門分野やリソースが少ない言語において、明確な改善が見られます。
- ご自身のインフラ上で実行可能。OCR 4 は単一のコンテナへのデプロイが可能になるほどコンパクトであり、ドキュメントデータをお客様の環境内に保持することで、データ所在地、主権、およびコンプライアンスを確保しつつ、コスト効率が高くスループットの高いバッチ処理をサポートします。自己管理型デプロイはエンタープライズ顧客向けに利用可能です。
オーバービュー
Mistral OCR 4 は、幅広い種類の文書からコンテンツを抽出し構造化します。以前の世代がページをクリーンなテキストと表に変換することに焦点を当てていたのに対し、OCR 4 は文書の構造的表現を返します。各ブロックはバウンディングボックスで位置特定され、タイプ別に分類され、ページ単位および単語単位でインラインの信頼度スコアが生成されます。したがって、後段システムは、文書が何を述べているかだけでなく、各要素がどこに存在し、どのような役割を果たし、モデルが各領域に対してどの程度自信を持っているかも利用可能になります。
この構造は、いくつかの後段ワークロードをサポートします:
- RAG 用のセマンティックチャンキング:分類されたクリーンなブロックがより優れた検索単位となります。
- エージェント用の構造的プリミティブ:エージェントは文書を読むことから、それらに対して行動する(フォーム入力、請求書処理、コンプライアンスチェック)へと進化します。
- コネクタ用の構造化コンテンツ:取り込みおよびインデックスパイプラインのための一貫性のある型付き出力です。
OCR 4 は、PDF、DOC、PPT、OpenDocument を含む一般的なエンタープライズフォーマットを受け入れ、多くのシステムが苦手とする専門的かつリソースが少ない言語を含む 10 の言語グループにわたる 170 か国語をサポートします。単一コンテナでデプロイ可能なコンパクトなモデルであるため、コスト敏感型および高ボリュームの展開の両方に適しています。完全にセルフホストで実行可能であり、データ主権要件を持つ組織が文書データを自社のインフラ内に保持することを可能にします。
開発者は API を通じてモデルを統合し、チームは Mistral Studio の Document AI を使用して、同じエンジンへのアプリケーションレベルのノーコードパスを実現できます。Mistral OCR 4 の API 利用料金は 1,000 ページあたり 4 ドルで、バッチ API 利用時に 50% オフとなり、コストは 1,000 ページあたり 2 ドルに削減されます。Document AI の料金は 1,000 ページあたり 5 ドルです。
ベンチマーク
**「Mistral OCR 4 を、チャートや図が密集した財務 QA データセット上で主要なエージェント型ドキュメントパーサーと比較ベンチマークした結果、約 8 分の 1 のコストと 17 分の 1 のレイテンシで同等の精度を達成しました。大規模な本番環境ユースケースにおいては、この差が急速に蓄積されます。」
*- Aidan Donohue, AI エンジニア、Rogo**
OCR 4 を評価するために、主要な AI ネイティブ OCR モデル、最先端の汎用モデル、エンタープライズドキュメントサービス、および自社製の Mistral OCR 3 と比較しました。
人間による選好評価
自動ベンチマークには上記のようなスコアリング上のアーティファクトが含まれる可能性があるため、実際の使用状況を反映するように選ばれたドキュメントを用いた直接比較の人間評価を補完として実施しました。12 以上の言語にわたる 600 ドキュメント以上を第三者ベンダーから収集し、実際の業界ユースケースを代表させるよう調整した上で、独立した注釈作成者に OCR 4 の出力と各競合他社の出力をドキュメントごとに盲検でランク付けしてもらいました。
アノテーターは、テストされたすべてのシステムにおいて、OCR 4 を大多数の文書で好んで選択しました。これらは固定された参照値との文字列比較ではなく、現実的な文書に対する人間の判断であるため、自動スコアリングに影響を与える注釈やフォーマットのノイズを多く回避しています。
image_15hPxB.webp?dpl=6a3bf6f893a80900098fee95)
全体パフォーマンス
「Mistral OCR は、ページあたり従来のプロバイダーよりも約 4 倍高速です。これは、顧客の知的財産権(IP)のタイムライン管理において速度が極めて重要な、高ボリュームのドケッティングワークフローにおいて、印象的な結果です。」
*- Ivan Mihailov, AI エンジニア、Anaqua*
人間の選好で第 1 位となったことに加え、OCR 4 は、公開されている OlmOCRBench(85.20))においてテストしたモデルの中で最高スコアを達成し、内部のCrawl Multilingual evaluation (.98)**でも AI ネイティブおよびエンタープライズ型ソリューションを上回って首位に立っています。
image_ZDpUIm.webp?dpl=6a3bf6f893a80900098fee95)On OmniDocBench, OCR 4 achieves a score of 93.07. We report this figure with a caveat: both OlmOCRBench and OmniDocBench have known limitations in how they score certain outputs, and a single aggregate number can both understate and overstate real-world performance.
When we audited the mismatches behind our scores, most were not model errors but artifacts of how the benchmarks compare output. The recurring categories:
- グランドトゥルース(正解データ)の誤り。一部の参照注釈自体に誤りがあり、テキストの欠落や余分な文字、隠された領域の転写ミス、あるいはタイプミス(例えば、参照資料で著者名が誤記されているが、モデルはページから正しく読み取っているケースなど)が含まれています。出力は原文書と一致しているにもかかわらず、誤りと判定されてしまいます。
- 等価な数式表記。同じようにレンダリングされる異なる LaTeX 形式も不一致としてカウントされます。レンダリングされた数式自体は正しいですが、文字列比較では一致しません。
- 数式のセグメンテーション。表現が単一の数式として出力されるか、複数のインライン断片に分割されるかは、レンダリング内容が同一であってもマッチングに影響します。これはマッチャーが各ピースを整合させることができないためです。
- 複数カラムの読み取り順序。カラム境界を跨いで分割された単語(例:"certifi-cates")や、カラム順序に関する仮定により、正しい抽出結果でも読み取り順序の失敗としてスコアリングされてしまいます。
- ブロックタイプの属性付け。ベンチマークでは出力にヘッダーやフッターは期待していません。これを解決するため、スコアリング前に出力からヘッダーとフッターを除去しています。しかし、そのテストでは、実際には存在すべきページタイトルである文字列も同時にチェックしており、誤って不正としてフラグを立ててしまいます。
これらのアーティファクトは数学的・科学的な文書や複数カラムの文書に集中しており、正しい出力に対してペナルティブを与えることが、間違った出力を報酬するよりも頻繁に起こります。したがって、集計スコアは決定論的なものではなく、方向性を示す指標として扱います。
これらのベンチマークは方向性を示すものです。すべての競合他社のスコアは内部での再現結果を反映しています。ご自身のドキュメントで評価を行うことを推奨します。
パフォーマンス詳細
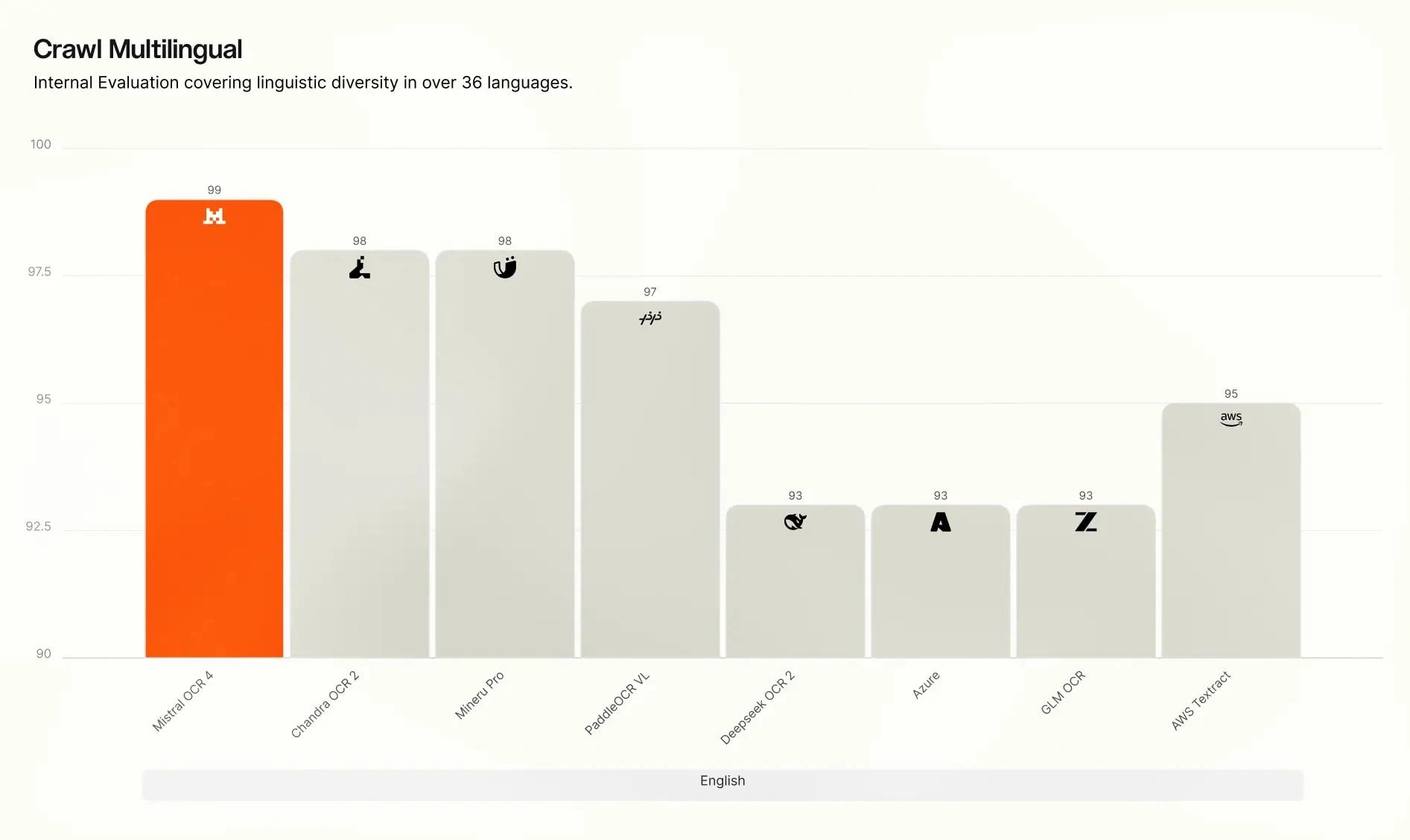
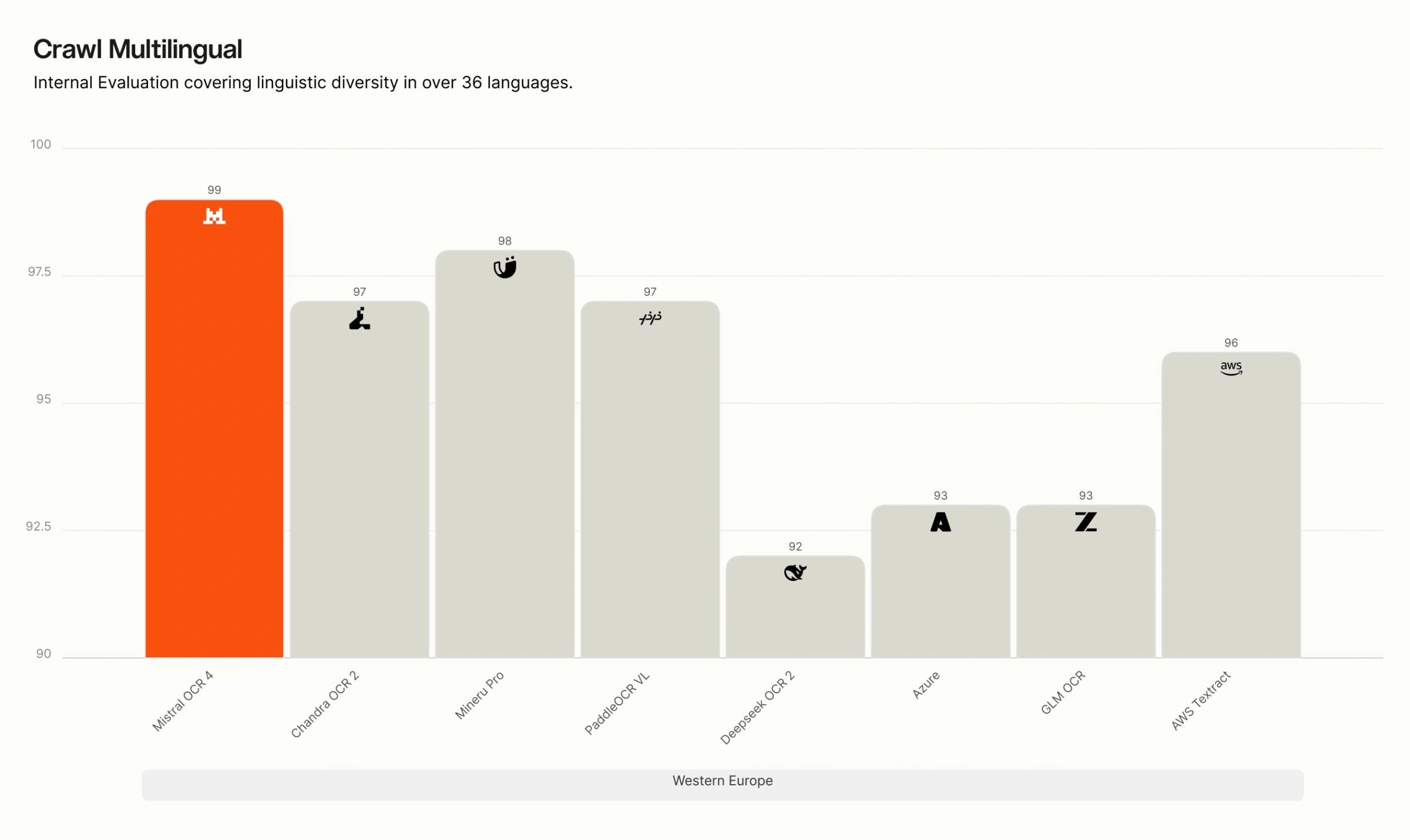
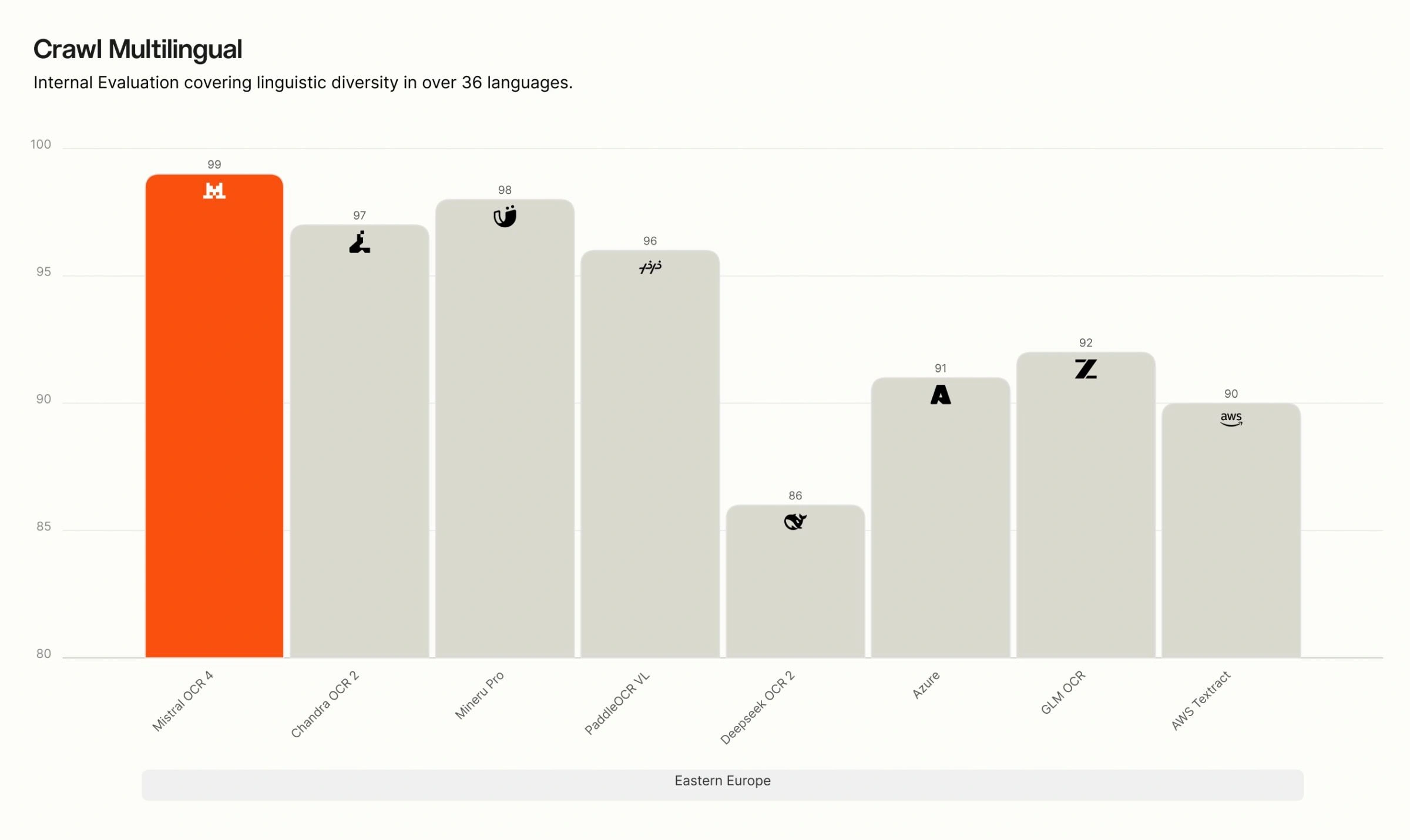
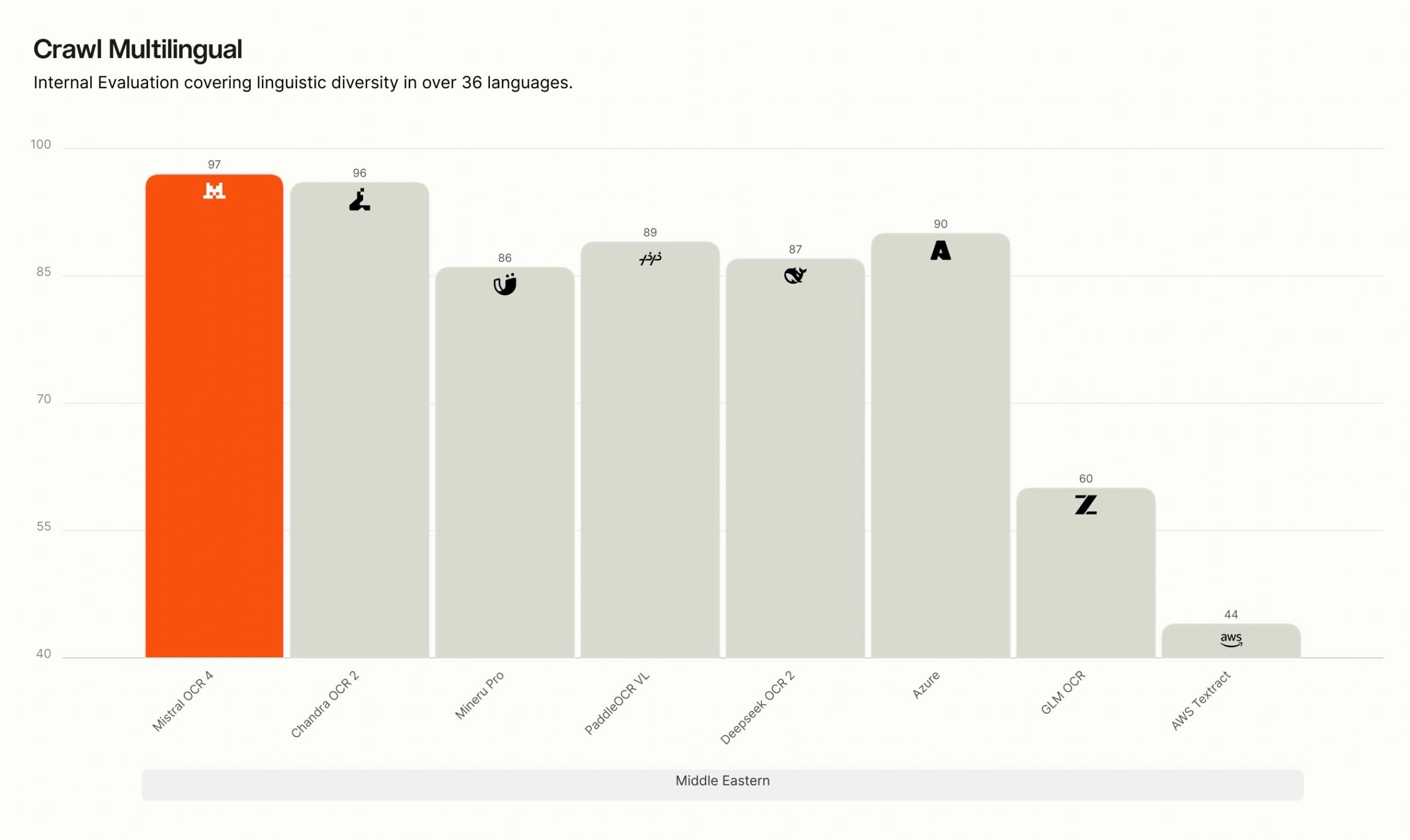
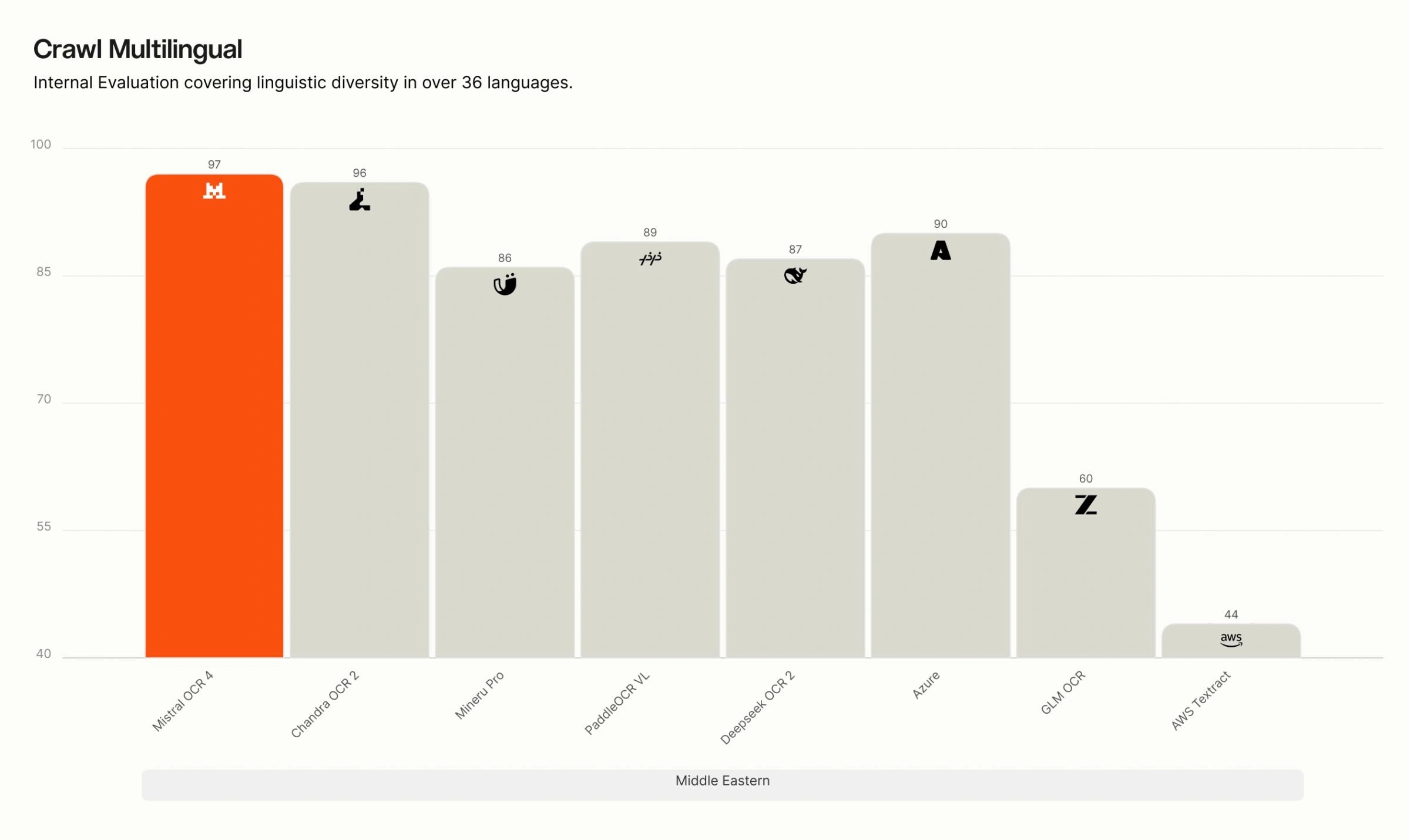
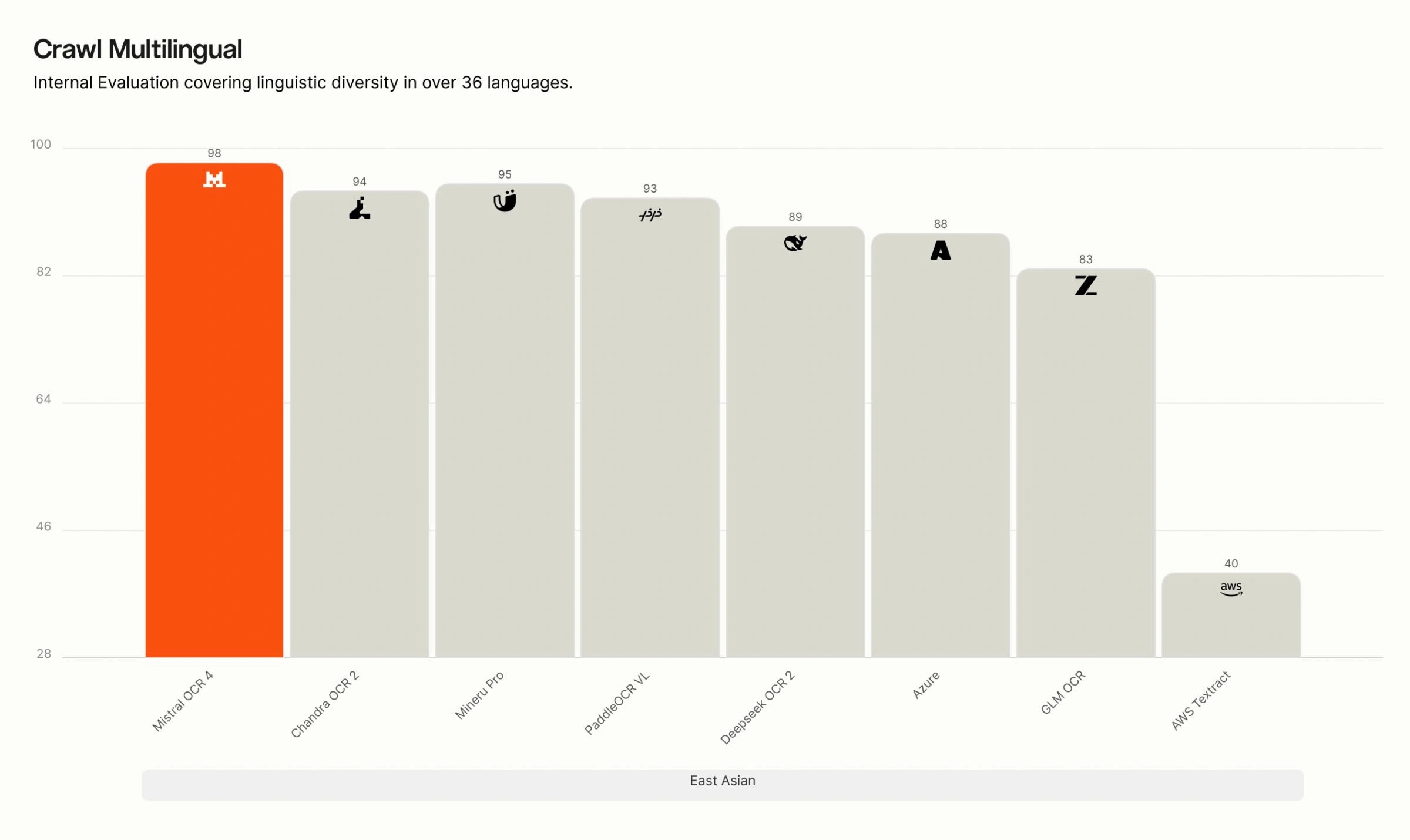
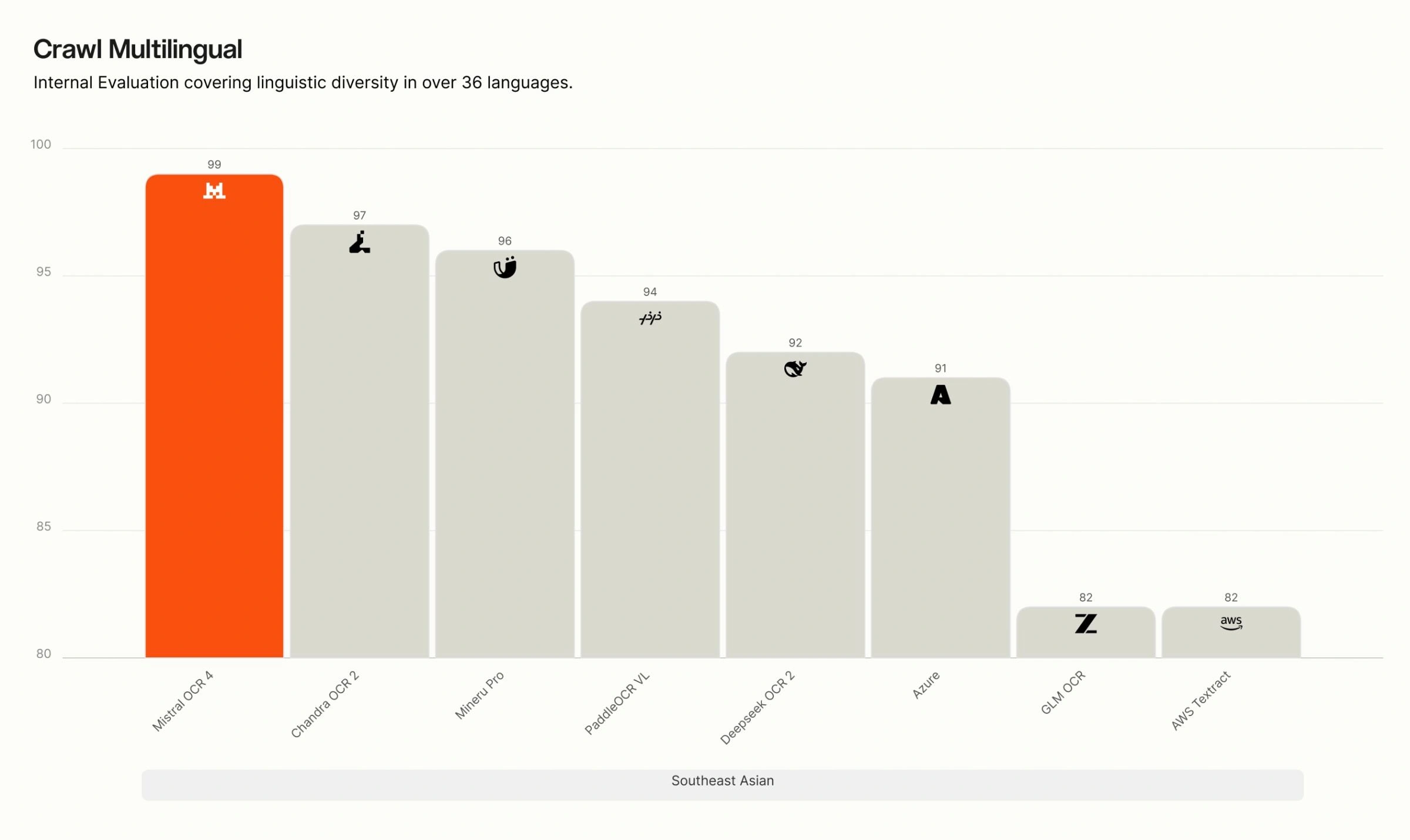
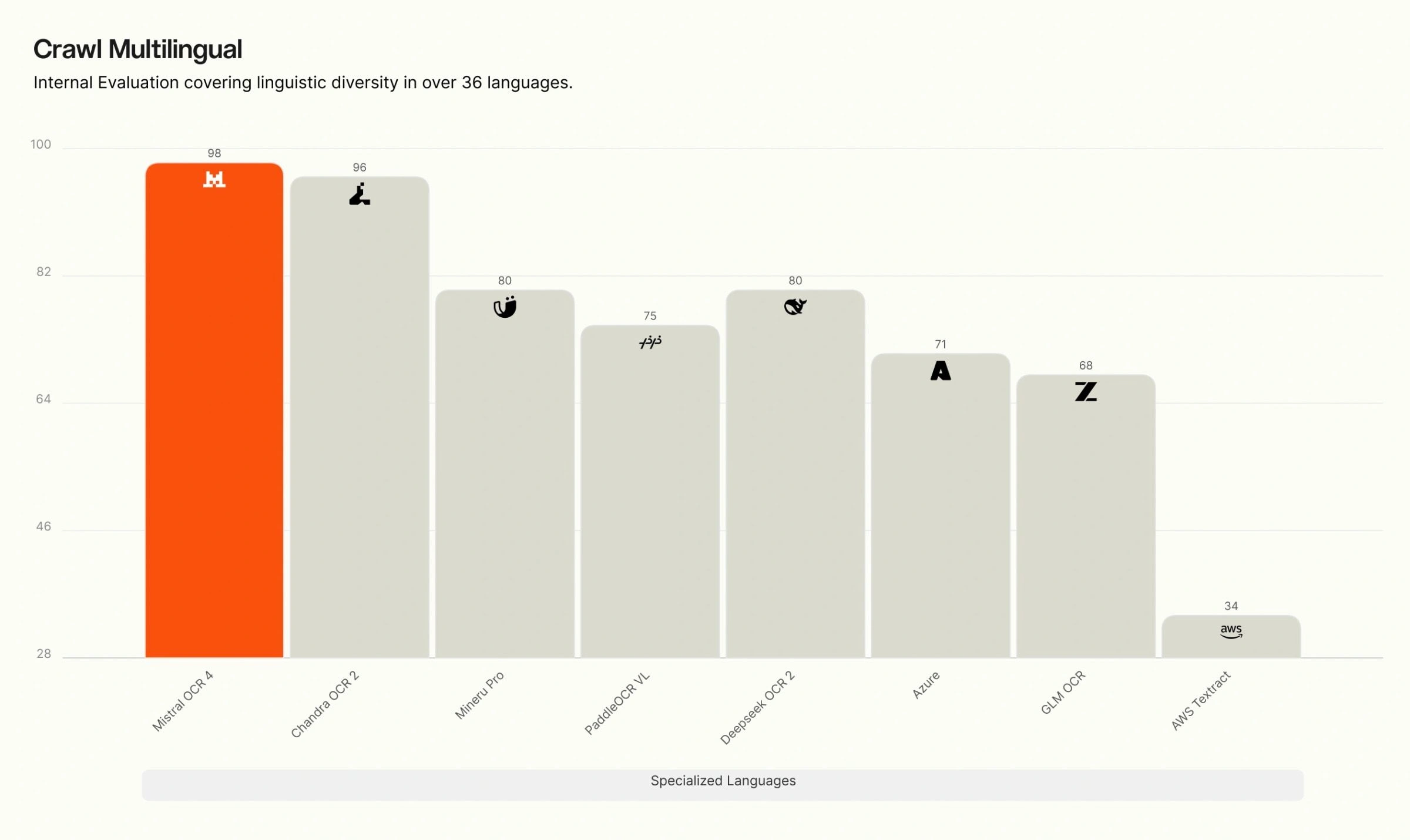
多言語別 Crawls の内訳。 当社の内部における多言語評価では、OCR 4 は英語、西欧諸国語、東欧諸国語、中東諸国語、中国語、東アジア諸国語、東南アジア諸国語、および専門言語(ヒンディー語、日本語、グルジア語、ベンガル語、アルメニア語、ヘブライ語、ギリシャ語、グジャラート語、タミル語、マラヤーラム語、カンナダ語、テルグ語)のすべての 8 つの言語グループにおいて首位を維持しています。特に専門的かつリソースが限られた言語においては、多くの競合システムが精度が大きく低下する一方で、OCR 4 は高い精度を維持しており、その差は最も顕著です。
推奨ユースケース
OCR 4 は、高ボリュームのパイプラインと対話型ドキュメントワークフローの両方をサポートしており、以下が含まれます:
- ドキュメントの解析および抽出:複雑な多言語ドキュメント。
- 検索拡張生成(RAG: Retrieval-Augmented Generation):意味的なチャンキングやソース根拠のある回答のための構造化され、分類され、引用準備が整ったコンテンツ。Search Toolkit を使用すれば、OCR 4 の出力を直接検索パイプラインに供給できます。
- エージェントワークフロー:フォーム入力、請求書処理、コンプライアンスチェックなどのタスクを完了するためにエージェントに構造的なプリミティブを提供します。特に法務、金融サービス、医療分野で有効です。
- 信頼度スコアを活用した構造化データパイプライン:効率的な人間による検証者(verifier)の活用を可能にするためのもの。フォーム/請求書の抽出、赤塗り処理、コンプライアンス駆動型プロセスが含まれます。
- エンタープライズ検索およびナレッジベース:カスタム取り込みやエンティティ抽出のためのデータソースコンポーネントとしての OCR。
初期ユーザーは、OCR 4 を活用して請求書を構造化されたフィールドに変換したり、企業のアーカイブをデジタル化したり、技術的・科学的レポートからクリーンなテキストを抽出したり、エンタープライズ検索を強化したりしています。
範囲外の利用に関する注意。 OCR 4 は文書理解モデルであり、意思決定者ではありません。医療診断、法的助言または判断、高リスクの金融決断、安全性が重要なシステム、リアルタイム/遅延敏感な処理、あるいは文書以外の入力(生音声、動画など)を目的としたものではありません。
OCR 4 API: オプションの理解
Mistral の OCR 4 は単一の API エンドポイントを通じて利用可能です。すべてのリクエストは同じ基盤となる OCR モデルを実行し、常に抽出されたコンテンツ、バウンディングボックス(囲み矩形)、ブロックタイプ、信頼度スコア、およびマークダウン構造化テキストを返します。異なるのは、その上にどの程度の機能を追加するかです。
純粋な抽出モードで OCR 4 を使用する場合は以下の場合に最適です:
- アプリケーション、エージェント、またはデータパイプラインに高速かつ正確な文書抽出を直接組み込む場合。
- カスタムな下流ロジックを実行するために、生レスポンス、バウンディングボックス、ブロックタイプ、信頼度スコアを直接操作する場合。
- バッチ API を通じてスループットとコストを完全に制御しながら、高ボリュームまたは一括インgestion(取り込み)を実行する場合。
- 厳格なデータプライバシー、主権、またはコンプライアンス要件のためにセルフホストする場合。
ドキュメント AI 機能を有効化するには(同じエンドポイントで追加パラメータを使用)
- あなたが定義したスキーマに従って構造化された JSON を返す — ドキュメントと一緒に JSON スキーマを渡すと、OCR 出力は mistral-small-2603 に供給され、あなたの仕様に沿った内容が生成されます。
- 画像注釈スキーマを渡すことで検出された画像に構造化 JSON で注釈を付け、画像ごとに追加のビジョン・ランゲージモデル呼び出しをトリガーします。
- カスタムプロンプトを JSON スキーマと共に使用して、ドキュメント全体の抽出コンテンツがどのように解釈または要約されるかを誘導します。
- 後段のパースロジックを書かずに、ビジネスユーザー、ソリューションチーム、あるいはパイロットプロジェクトが構造化された結果を生み出せるようにします。
実用的な意思決定ルール:生きた抽出コンテンツが必要であれば、OCR 4 をそのまま使用してください。出力を構造化形式に再整形し、ドメイン固有のフィールドで注釈付けを行うか、カスタム指示で処理する必要がある場合は、同じ呼び出しに Document AI パラメータを追加します。OCR 結果は常に取得されますが、Document AI はその上に構造化レイヤーを追加するだけです。
現在利用可能
「Microsoft Foundry における Mistral Document AI with OCR 4 の提供は、私たちのパートナーシップにおける重要なマイルストーンです。私たちは共に、Mistral の革新と Microsoft のエンタープライズプラットフォームを組み合わせることで、顧客が高度で構造化されたドキュメント理解を直接 AI ワークフローに組み込み、現実のビジネスニーズに対応するスケーラブルで信頼性の高いソリューションを提供できるようにしています。」
*-Kimmi Grewal, VP, AI Ecosystem Partnerships, Microsoft*
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等)は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
Mistral OCRv4 と Document AI(OCRv4 を基盤とする)は、Mistral Studio、Amazon SageMaker、Microsoft Foundry を通じて API で利用可能です。また、Snowflake Parse Document での提供も近日予定されています。厳格なデータプライバシー要件を満たす必要がある組織向けに、OCR 4 ではセルフホスティングオプションも用意されており、機密情報を自社のインフラ内に保持することが可能です。自己展開について詳しく知りたい場合は、お問い合わせください。
始め方
より早く学習し始めるためのいくつかの方法をご用意しています。
- OCR 4 をお試しください。新しくなった「OCR 4 との入門」クックブックでは、最初の抽出処理、バウンディングボックスの扱い、ブロック分類について解説します。
- OCR 4 ウェビナー。7 月 7 日午後 6 時(中欧夏時間)に、新機能やデモ、質疑応答を含む「OCR 4 in Production」ウェビナーを開催いたします。登録はこちらから。
- 詳細については営業担当までお問い合わせください。
 image
image
OCR 4
Premier
世界最高峰の文書抽出および理解モデル。
OCR
Multimodal
Text-to-text
OCR
$4 / 1000 ページ
Batch-API
$2 / 1000 ページ
Document AI
$5 / 1000 ページ
本番環境での OCR
OCR4 リリースの新機能と、ワークフローや検索ツールキット内でこれらを活用して本番グレードのインデックスを構築する方法についてご紹介します。
原文を表示
Today, we're releasing Mistral OCR 4, featuring bounding boxes, block classification, and inline confidence scores alongside extracted text. The model supports 170 languages across 10 language groups, runs in a single container for fully self-hosted deployments, and serves as an ingestion component for enterprise search, RAG, and domain-specific retrieval pipelines. OCR 4 is a small, focused model, and this post covers what's new, how it performs on public and internal benchmarks, the known limitations of those benchmarks, and guidance on when to use the model API versus Document AI.
Highlights
- Breakthrough performance. Independent annotators prefer OCR 4 over every leading OCR and document-AI system tested, with win rates averaging 72%, alongside the top overall score on OlmOCRBench (85.20). See Benchmarks below for methodology and known scoring limitations.
- Segmentation, not just text. Alongside the extracted text, OCR 4 returns bounding boxes, typed-block classification (titles, tables, equations, signatures, and more), and inline confidence scores. Bounding boxes, our most-requested capability, localize text for in-context highlighting and reliable data pipelines. At the same time, block types and confidence scores drive source-grounded citations, redactions, and human-in-the-loop verification.
- Integrated with Mistral Search Toolkit (public preview). OCR 4 is an ingestion component of Search Toolkit, Mistral's open-source, composable search framework, announced at the AI Now Summit. Its structured output supplies citation-ready inputs to the toolkit's ingestion, retrieval, and evaluation workflow for RAG and enterprise search.
- Multilingual coverage. Support for 170 languages across 10 language groups, with measurable gains on specialized and low-resource languages where several competing systems degrade.
- Run on your own infrastructure. OCR 4 is compact enough to deploy on a single container, keeping document data in your environment for residency, sovereignty, and compliance, while supporting cost-efficient, high-throughput batch processing. Self-managed deployment is available to enterprise customers.
Overview
Mistral OCR 4 extracts and structures content from a wide range of documents. Where previous generations focused on converting a page into clean text and tables, OCR 4 returns a structured representation of the document. Each block is localized with a bounding box, classified by type, and inline confidence scores are generated per-page and per-word. Downstream systems, therefore, have access not only to *what* the document says but also to *where* each element sits, *what role* it plays, and *how confident* the model is in each region.
This structure supports several downstream workloads:
- Semantic chunking for RAG: clean, classified blocks become better retrieval units.
- Structural primitives for agents: agents move from reading documents to acting on them (form filling, invoice processing, compliance checks).
- Structured content for connectors: consistent, typed output for ingestion and indexing pipelines.
OCR 4 accepts common enterprise formats, including PDF, DOC, PPT, and OpenDocument, and supports 170 languages across 10 language groups, including specialized and low-resource languages that many systems handle poorly. As a compact model deployable in a single container, it is suited to both cost-sensitive and high-volume deployments. It can run fully self-hosted, allowing organizations with data-sovereignty requirements to keep document data within their own infrastructure.
Developers integrate the model via API, and teams can use Document AI in Mistral Studio for an application-level, no-code path to the same engine. Mistral OCR 4 through the API is priced at $4 per 1,000 pages, with a 50% Batch-API discount, reducing the cost to $2 per 1,000 pages. Document AI is priced at $5 per 1,000 pages.
Benchmarks
“We benchmarked Mistral OCR 4 against the leading agentic document parsers across a chart and figure dense financial QA dataset and reached equivalent accuracy at roughly 8x lower cost and 17x lower latency. For production use cases at scale, that delta compounds fast." - Aidan Donohue, AI Engineer, Rogo
To evaluate OCR 4, we compared it against leading AI-native OCR models, frontier general-purpose models, enterprise document services, and our own Mistral OCR 3.
Human Preference Evaluations
Automated benchmarks carry the scoring artifacts described above, so we complemented them with a head-to-head human evaluation on documents chosen to reflect real usage. We assembled 600+ documents across 12+ languages, sourced from third-party vendors to represent real industry use cases, and asked independent annotators to blindly rank each competitor's output against OCR 4's, document by document.
Annotators preferred OCR 4 in the majority of documents across all systems tested. Because these are human judgments on realistic documents rather than string comparisons against fixed references, they sidestep much of the annotation and formatting noise that affects automated scores.
_15hPxB.webp?dpl=6a3bf6f893a80900098fee95)
Overall Performance
“Mistral OCR is roughly 4x faster per page than our incumbent provider, an impressive result for the high-volume docketing workflows where speed is critical to managing our customers' IP timelines.” - Ivan Mihailov, AI engineer, Anaqua
In addition to placing first in our human preferences, OCR 4 achieves the top overall score amongst the models we tested on the public OlmOCRBench (85.20) and leads our internal Crawl Multilingual evaluation (.98), ahead of both AI-native and enterprise solutions.
_ZDpUIm.webp?dpl=6a3bf6f893a80900098fee95)
On OmniDocBench, OCR 4 achieves a score of 93.07. We report this figure with a caveat: both OlmOCRBench and OmniDocBench have known limitations in how they score certain outputs, and a single aggregate number can both understate and overstate real-world performance.
When we audited the mismatches behind our scores, most were not model errors but artifacts of how the benchmarks compare output. The recurring categories:
- Ground-truth errors. Some reference annotations are themselves incorrect: missing or extra text, transcriptions of redacted regions, or typos (for example, a cited author's name misspelled in the reference but read correctly by the model from the page). The output matches the source document, yet it is still marked wrong.
- Equivalent math notation. Different LaTeX that renders identically is counted as a mismatch, The rendered equation is correct; the string comparison is not.
- Equation segmentation. Whether an expression is emitted as a single equation or split into several inline fragments affects the match, even when the rendered content is identical, because the matcher cannot align the pieces.
- Multi-column reading order. Words split across a column boundary (for example, "certifi-cates") and column-ordering assumptions cause correct extractions to be scored as reading-order failures.
- Block-type attribution. The benchmark does not expect headers/footers in the output. To resolve this we strip headers footers from our output before scoring. But the test then checks for a string that also happens to be the title of the page which should actually be present and flags it incorrectly.
These artifacts concentrate in mathematical, scientific, and multi-column documents, and they more often penalize correct output than reward incorrect output. We therefore treat the aggregate score as directional rather than definitive.
These benchmarks are directional. All competitor scores reflect internal reproductions. We recommend evaluating on your own documents.
Performance Details
Crawl Multilingual breakdown. On our internal multilingual evaluation, OCR 4 leads across all eight language groups — English, Western Europe, Eastern Europe, Middle Eastern, Chinese, East Asian, Southeast Asian, and specialized languages (Hindi, Japanese, Georgian, Bengali, Armenian, Hebrew, Greek, Gujarati, Tamil, Malayalam, Kannada, Telugu). The gap is widest for specialized and low-resource languages, where many competing systems degrade sharply, while OCR 4 maintains high accuracy.
Recommended use cases
OCR 4 supports both high-volume pipelines and interactive document workflows, including:
- Document parsing and extraction: complex, multilingual documents.
- Retrieval-Augmented Generation (RAG): structured, classified, citation-ready content for semantic chunking and source-grounded answers. With Search Toolkit, OCR 4 output can be fed directly into retrieval pipelines.
- Agentic workflows: providing agents with the structural primitives to complete tasks such as form filling, invoice processing, and compliance checks, especially in legal, financial services, and healthcare.
- Structured data pipelines using confidence scores to enable efficient use of human verifiers: form/invoice extraction, redactions, and compliance-driven processes.
- Enterprise search and knowledge bases: OCR as a data-source component for custom ingestion and entity extraction.
Early users are applying OCR 4 to turn invoices into structured fields, digitize company archives, extract clean text from technical and scientific reports, and power enterprise search.
A note on out-of-scope use. OCR 4 is a document-understanding model, not a decision-maker. It is not intended for medical diagnosis, legal advice or judgment, high-stakes financial decisions, safety-critical systems, real-time/latency-sensitive processing, or non-document inputs (raw audio, video, etc.).
OCR 4 API: Understanding Your Options
Mistral's OCR 4 is available through a single API endpoint. Every request runs the same underlying OCR model and always returns extracted content, bounding boxes, block types, confidence scores, and markdown-structured text. What varies is how much you layer on top.
Use OCR 4 in pure extraction mode when you want to:
- Embed fast, accurate document extraction directly into your application, agent, or data pipeline.
- Work directly with the raw response, bounding boxes, block types, and confidence scores to drive custom downstream logic.
- Run high-volume or batch ingestion with full control over throughput and cost via the Batch API.
- Self-host for strict data-privacy, sovereignty, or compliance requirements.
Activate Document AI capabilities (same endpoint, additional parameters) when you want to:
- Return structured JSON in a schema you define — pass a JSON schema alongside your document, and the OCR output is fed to mistral-small-2603 to generate content shaped to your spec.
- Annotate detected images with structured JSON by passing an image annotation schema, triggering an additional vision-language model call per image.
- Use a custom prompt alongside a JSON schema to guide how the extracted content of the full document is interpreted or summarized.
- Enable business users, solutions teams, or pilots to produce structured results without writing downstream parsing logic.
The practical decision rule: if you need raw extracted content, use OCR 4 as-is. If you need the output reshaped into a structured format, annotated with domain-specific fields, or processed with a custom instruction, add the Document AI parameters to the same call. You always get the OCR result regardless; Document AI simply adds structured layers on top of it.
Now available
“The availability of Mistral Document AI with OCR 4 in Microsoft Foundry marks an important milestone in our partnership. Together, we’re enabling customers to bring advanced, structured document understanding directly into their AI workflows, combining Mistral’s innovation with Microsoft’s enterprise platform to deliver scalable, trusted solutions for real-world business needs.”-Kimmi Grewal, VP, AI Ecosystem Partnerships, Microsoft
Both Mistral OCRv4 and Document AI (powered by OCRv4) are available via API through Mistral Studio, Amazon SageMaker, Microsoft Foundry, and coming soon Snowflake Parse Document. For organizations with stringent data-privacy requirements, OCR 4 also offers a self-hosting option so sensitive information stays within your own infrastructure. To explore self-deployment, let us know.
Get started
We offer a few ways to get started and learn more quickly.
- Try OCR 4. The new Getting Started with OCR 4 Cookbook walks through a first extraction, working with bounding boxes, and block classification.
- OCR 4 webinar. We'll cover what's new in OCR 4 with demos and Q&A on July 7th at 6:00 PM CET. Register for the OCR4 in Production webinar.
- Contact Sales for more information.
OCR 4
Premier
The world's best document extraction and understanding model.
OCR
Multimodal
Text-to-text
OCR
$4 / 1000 pages
Batch-API
$2 / 1000 pages
Document AI
$5 / 1000 pages
OCR in production.
Learn about the new features in the OCR4 release and how can they be used inside workflows and search toolkit to get production grade indexing.
関連記事
Unlimited OCR Works(GitHub リポジトリ)
DeepSeek OCR をベースに定数 KV キャッシュ設計を組み合わせ、人間の作業記憶を模倣する「Unlimited OCR」モデルが開発された。この技術により、32K の最大長制限下で数十ページの文書を単一の順次処理で転写可能となり、音声認識や翻訳タスクにも応用できる。
Mistral OCR 4 が引用対応の構造化出力を RAG、エージェント型、企業検索パイプラインに提供
Mistral AI は最新ドキュメント理解モデル「OCR 4」を発表し、抽出テキストに境界ボックスやブロック分類、信頼度スコアを追加した。このモデルは 170 か国語に対応し、自己完結型デプロイが可能で、企業検索や RAG パイプラインの ingestion コンポーネントとして機能する。
2026 年に AI エンジニアになるためのロードマップ
KDnuggets が、2026 年までに AI エンジニアとして活躍するための学習ロードマップを提示している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み