NVIDIAがNemotron-Cascade 2をリリース:3Bの活性化パラメータを持つオープンな30B MoEモデルで、推論能力とエージェント機能を強化
NVIDIAは、30BパラメータのMixture-of-Expertsモデル「Nemotron-Cascade 2」を公開し、数学的推論やコーディングなどの特定領域で最先端性能を達成しながら、3Bの活性化パラメータのみで効率的な推論能力を実現した。
キーポイント
効率的な大規模モデルアーキテクチャ
30BパラメータのMixture-of-Expertsモデルでありながら、推論時には3Bパラメータのみを活性化することで、計算効率を高めつつ高度な推論能力を実現している。
特定領域での卓越した性能
数学的推論(AIME 2025、HMMT Feb25)、コーディング(LiveCodeBench v6、IOI 2025)、アライメントと指示追従(ArenaHard v2、IFBench)において、競合モデルを上回る性能を示している。
革新的なトレーニング手法
Cascade Reinforcement LearningとMulti-domain On-Policy Distillation(MOPD)を組み合わせたトレーニングパイプラインにより、複数領域での高性能を維持しながら破滅的忘却を防止している。
国際競技会での実績
2025年の国際数学オリンピック(IMO)、国際情報オリンピック(IOI)、ICPC世界決勝でゴールドメダルレベルの性能を達成した2番目のオープンウェイトLLMとなった。
影響分析・編集コメントを表示
影響分析
このリリースは、大規模モデルの効率化と専門化のトレンドを加速させる重要なマイルストーンである。計算リソースを抑えつつ特定領域で最高性能を発揮するモデル設計は、実用展開の障壁を下げ、より多くの開発者や企業が高度なAI機能を利用できる可能性を広げる。
編集コメント
特定領域に特化した高性能モデルのオープンリリースは、AI開発の民主化をさらに推進する重要な一歩。計算効率と性能のバランスが実用化の鍵となる中、このアプローチは業界の新たな標準となる可能性がある。
タイトル: NVIDIA、Nemotron-Cascade 2をリリース: 3Bの活性化パラメータを持つオープンウェイトの30B MoEモデルで、優れた推論能力と強力なエージェント機能を実現
NVIDIAは、3Bの活性化パラメータを持つオープンウェイトの30B Mixture-of-Experts(MoE)モデルであるNemotron-Cascade 2のリリースを発表しました。このモデルは「知能密度」の最大化に焦点を当て、最先端大規模モデルが用いるパラメータ規模の一部で、高度な推論能力を提供します。Nemotron-Cascade 2は、2025年の国際数学オリンピック(IMO)、国際情報オリンピック(IOI)、ICPCワールドファイナルにおいて金メダルレベルの性能を達成した、2番目のオープンウェイトLLMです。
 imagehttps://research.nvidia.com/labs/nemotron/files/Nemotron-Cascade-2.pdf
imagehttps://research.nvidia.com/labs/nemotron/files/Nemotron-Cascade-2.pdf
目標性能と戦略的トレードオフ
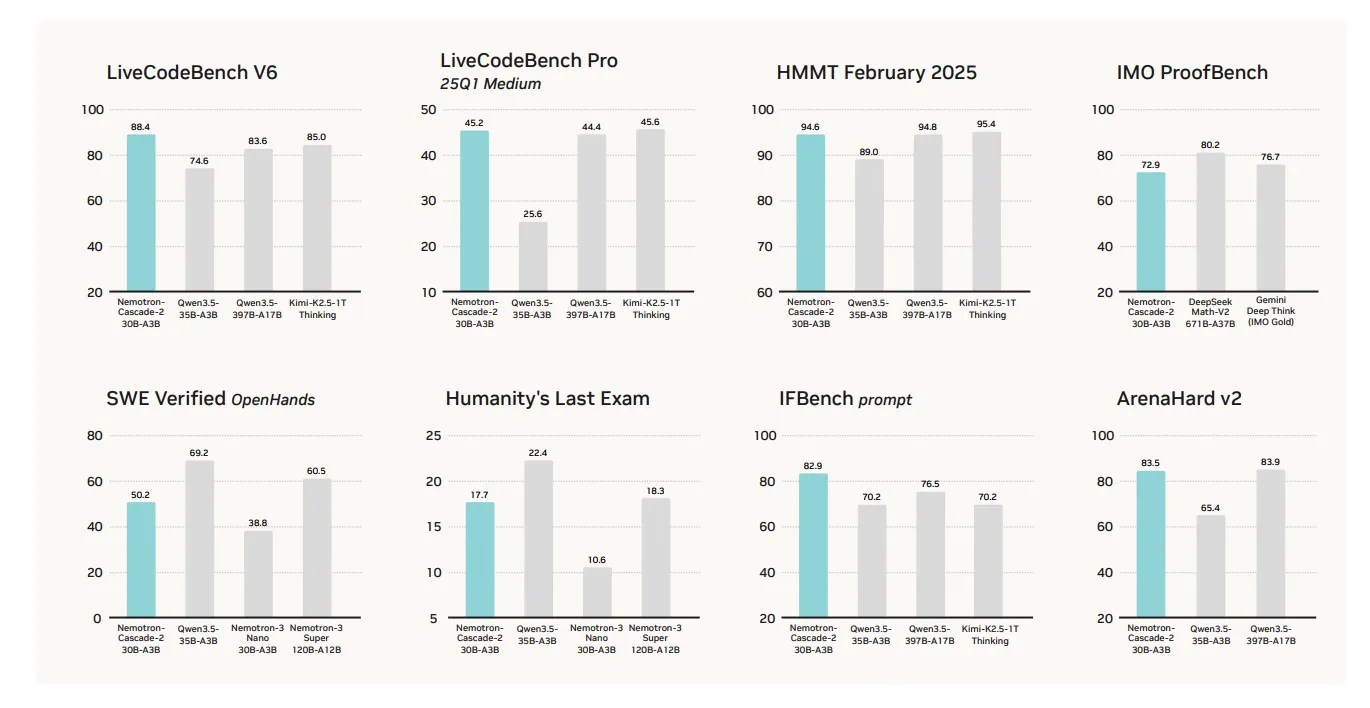
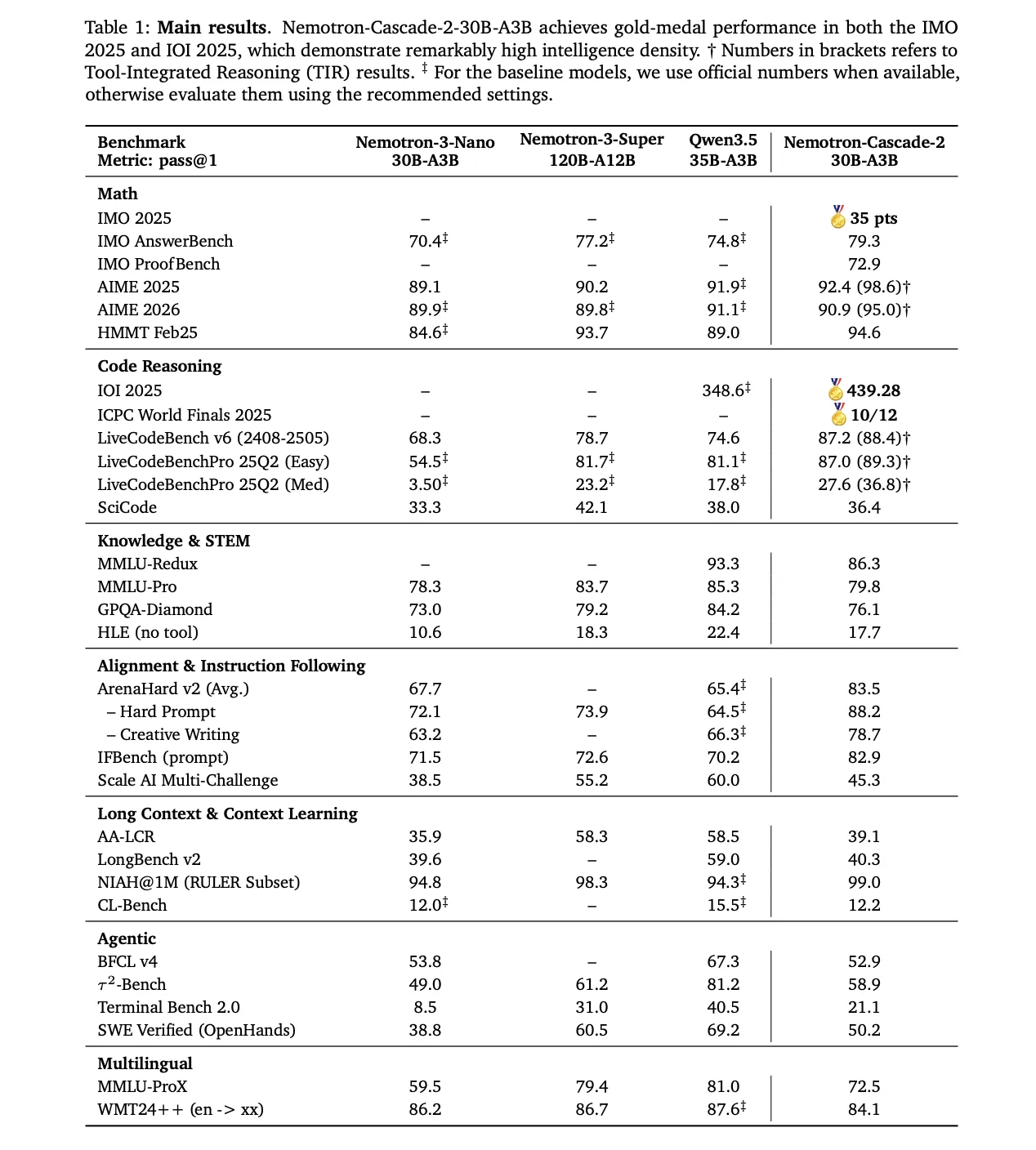
Nemotron-Cascade 2の主な価値提案は、数学的推論、コーディング、アライメント、指示追従における特化した性能です。これらの重要な推論集約型領域で最先端の結果を達成していますが、全てのベンチマークで「全面的に優れている」わけではありません。
このモデルの性能は、最近リリースされたQwen3.5-35B-A3B(2026年2月)および大規模なNemotron-3-Super-120B-A12Bと比較し、いくつかの特定カテゴリで優れています:
- 数学的推論: AIME 2025(92.4 対 91.9)およびHMMT Feb25(94.6 対 89.0)でQwen3.5-35B-A3Bを上回ります。
- コーディング: LiveCodeBench v6(87.2 対 74.6)およびIOI 2025(439.28 対 348.6+)でリードしています。
- アライメントと指示追従: ArenaHard v2(83.5 対 65.4+)およびIFBench(82.9 対 70.2)で顕著に高いスコアを記録しています。
 imagehttps://research.nvidia.com/labs/nemotron/files/Nemotron-Cascade-2.pdf
imagehttps://research.nvidia.com/labs/nemotron/files/Nemotron-Cascade-2.pdf
技術的アーキテクチャ: カスケード強化学習とマルチドメイン方策オン蒸留(MOPD)
このモデルの推論能力は、Nemotron-3-Nano-30B-A3B-Baseモデルを起点とする学習後調整パイプラインに由来します。
1. 教師ありファインチューニング(SFT)
SFTにおいて、NVIDIAの研究チームは、サンプルが最大256Kトークンのシーケンスにまとめられた、厳選されたデータセットを利用しました。このデータセットには以下が含まれます:
- 競技プログラミング向けの190万件のPython推論トレースと130万件のPythonツール呼び出しサンプル。
- 数学的自然言語証明向けの81万6千件のサンプル。
- 12万5千件のエージェント型サンプルと38万9千件の非エージェント型サンプルから構成される、特化したソフトウェアエンジニアリング(SWE)ブレンド。
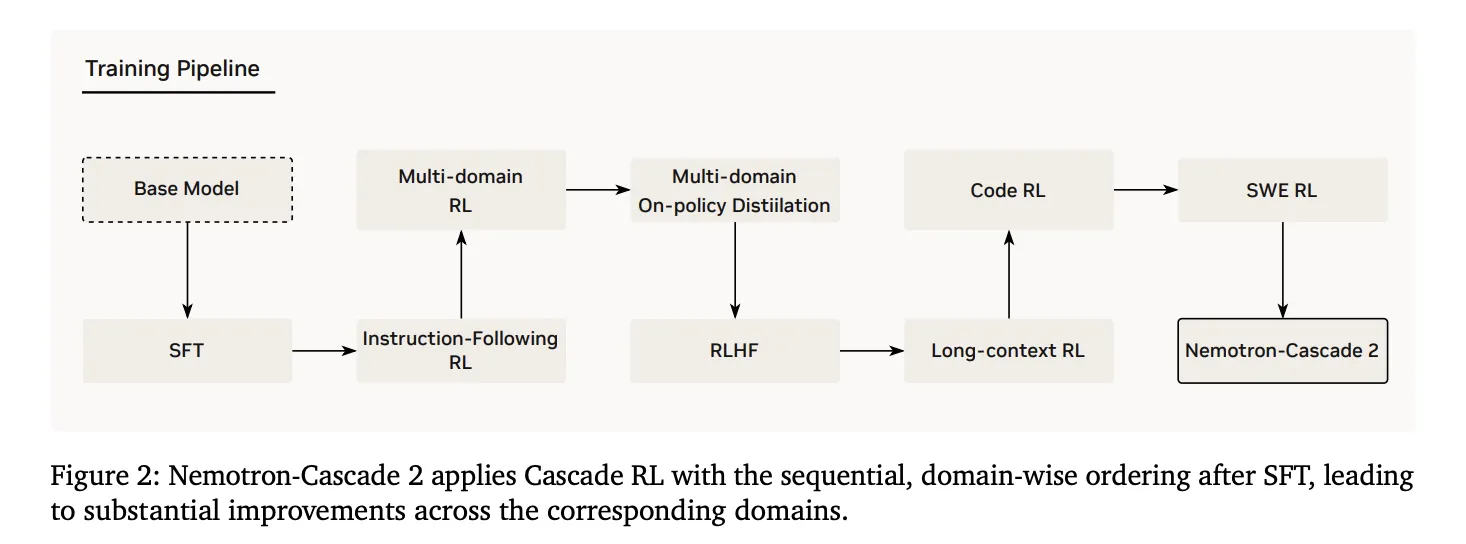
2. カスケード強化学習(Cascade RL)
SFTの後、モデルはカスケード強化学習を受けました。これは連続的かつドメインごとの訓練を適用するもので、他の領域を不安定化させることなく特定領域にハイパーパラメータを調整できるようにすることで、破滅的忘却を防ぎます。このパイプラインには、指示追従(IF-RL)、マルチドメインRL、RLHF、長文脈RL、および特化したコード・SWE RLの段階が含まれます。
 imagehttps://research.nvidia.com/labs/nemotron/files/Nemotron-Cascade-2.pdf
imagehttps://research.nvidia.com/labs/nemotron/files/Nemotron-Cascade-2.pdf
3. マルチドメイン方策オン蒸留(MOPD)
Nemotron-Cascade 2における重要な革新は、カスケードRLプロセス中にMOPDを統合した点です。MOPDアセンブリでは、同じSFT初期化から既に導出された最高性能の中間「教師」モデルを利用し、密なトークンレベルの蒸留の利点を提供します。この利点は数学的に次のように定義されます:
$$a_{t}^{MOPD}=log~\pi^{domain_{t}}(y_{t}|s_{t})-log~\pi^{train}(y_{t}|s_{t})$$
/*
研究チームは、MOPDがGroup Relative Policy Optimization(GRPO)のようなシーケンスレベル報酬アルゴリズムよりも、実質的にサンプル効率が高いことを発見しました。例えば、AIME25では、MOPDは30ステップ以内に教師モデルレベルの性能(92.0)に到達したのに対し、GRPOは同ステップ数を経ても91.0に留まりました。
推論機能とエージェント型インタラクション
Nemotron-Cascade 2は、そのチャットテンプレートを通じて2つの主要動作モードをサポートしています:
- 思考モード: 単一の
<think>トークンとそれに続く改行で開始します。これにより、複雑な数学およびコードタスクのための深い推論が活性化されます。 - 非思考モード: 空の
<think></think>ブロックを先頭に付けることで活性化され、より効率的で直接的な応答を可能にします。
エージェント型タスクでは、モデルはシステムプロンプト内で構造化されたツール呼び出しプロトコルを利用します。利用可能なツールは<tools>タグ内に列挙され、モデルは検証可能な実行フィードバックを確実にするため、<tool_call>タグで囲まれたツール呼び出しを実行するよう指示されます。
「知能密度」に焦点を当てることで、Nemotron-Cascade 2は、かつて超大型モデルにのみ可能と考えられていた特化した推論能力が、ドメイン固有の強化学習により300億パラメータ規模でも達成可能であることを示しています。
Paper and Model on HFをチェックしてください。また、Twitterで私たちをフォローし、12万人以上が参加するML SubRedditへの参加や、メールニュースレターの購読もお忘れなく。Telegramをご利用ですか? 今ならTelegramでもご参加いただけます。
この投稿「NVIDIA Releases Nemotron-Cascade 2: An Open 30B MoE with 3B Active Parameters, Delivering Better Reasoning and Strong Agentic Capabilities」は、MarkTechPostで最初に公開されました。
原文を表示
NVIDIA has announced the release of Nemotron-Cascade 2, an open-weight 30B Mixture-of-Experts (MoE) model with 3B activated parameters. The model focuses on maximizing ‘intelligence density,’ delivering advanced reasoning capabilities at a fraction of the parameter scale used by frontier models. Nemotron-Cascade 2 is the second open-weight LLM to achieve Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals.
imagehttps://research.nvidia.com/labs/nemotron/files/Nemotron-Cascade-2.pdf
Targeted Performance and Strategic Trade-offs
The primary value proposition of Nemotron-Cascade 2 is its specialized performance in mathematical reasoning, coding, alignment, and instruction following. While it achieves state-of-the-art results in these key reasoning-intensive domains, it is surely not a ‘blanket win’ across all benchmarks.
The model’s performance excels in several targeted categories compared to the recently released Qwen3.5-35B-A3B (February 2026) and the larger Nemotron-3-Super-120B-A12B:
Mathematical Reasoning: Outperforms Qwen3.5-35B-A3B on AIME 2025 (92.4 vs. 91.9) and HMMT Feb25 (94.6 vs. 89.0).
Coding: Leads on LiveCodeBench v6 (87.2 vs. 74.6) and IOI 2025 (439.28 vs. 348.6+).
Alignment and Instruction Following: Scores significantly higher on ArenaHard v2 (83.5 vs. 65.4+) and IFBench (82.9 vs. 70.2).
imagehttps://research.nvidia.com/labs/nemotron/files/Nemotron-Cascade-2.pdf
Technical Architecture: Cascade RL and Multi-domain On-Policy Distillation (MOPD)
The model’s reasoning capabilities stem from its post-training pipeline, starting from the Nemotron-3-Nano-30B-A3B-Base model.
- Supervised Fine-Tuning (SFT)
During SFT, NVIDIA research team utilized a meticulously curated dataset where samples were packed into sequences of up to 256K tokens. The dataset included:
1.9M Python reasoning traces and 1.3M Python tool-calling samples for competitive coding.
816K samples for mathematical natural language proofs.
A specialized Software Engineering (SWE) blend consisting of 125K agentic and 389K agentless samples.
- Cascade Reinforcement Learning
Following SFT, the model underwent Cascade RL, which applies sequential, domain-wise training. This prevents catastrophic forgetting by allowing hyperparameters to be tailored to specific domains without destabilizing others. The pipeline includes stages for instruction-following (IF-RL), multi-domain RL, RLHF, long-context RL, and specialized Code and SWE RL.
imagehttps://research.nvidia.com/labs/nemotron/files/Nemotron-Cascade-2.pdf
- Multi-Domain On-Policy Distillation (MOPD)
A critical innovation in Nemotron-Cascade 2 is the integration of MOPD during the Cascade RL process. MOPD assembly uses the best-performing intermediate ‘teacher’ models—already derived from the same SFT initialization—to provide a dense token-level distillation advantage. This advantage is defined mathematically as:
$$a_{t}^{MOPD}=log~\pi^{domain_{t}}(y_{t}|s_{t})-log~\pi^{train}(y_{t}|s_{t})$$
/*
The research team found that MOPD is substantially more sample-efficient than sequence-level reward algorithms like Group Relative Policy Optimization (GRPO). For instance, on AIME25, MOPD reached teacher-level performance (92.0) within 30 steps, while GRPO achieved only 91.0 after matching those steps.
Inference Features and Agentic Interaction
Nemotron-Cascade 2 supports two primary operating modes through its chat template:
Thinking Mode: Initiated by a single <think> token, followed by a newline. This activates deep reasoning for complex math and code tasks.
Non-Thinking Mode: Activated by prepending an empty <think></think> block for more efficient, direct responses.
For agentic tasks, the model utilizes a structured tool-calling protocol within the system prompt. Available tools are listed within <tools> tags, and the model is instructed to perform tool calls wrapped in <tool_call> tags to ensure verifiable execution feedback.
By focusing on ‘intelligence density,’ Nemotron-Cascade 2 demonstrates that specialized reasoning capabilities once thought to be the exclusive domain of frontier-scale models are achievable at a 30B scale through domain-specific reinforcement learning.
Check out Paper and Model on HF. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post NVIDIA Releases Nemotron-Cascade 2: An Open 30B MoE with 3B Active Parameters, Delivering Better Reasoning and Strong Agentic Capabilities appeared first on MarkTechPost.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み