DeepReinforce が Ornith-1.0 オープンソースコーディングモデルをリリース
DeepReinforce が、Gemma 4 と Qwen 3.5 を基盤とし、エッジから最前線まで対応する自己改善型コーディングモデル「Ornith-1.0」をオープンソース化して発表した。
キーポイント
広範なモデルサイズラインナップ
9B のコンパクト版から 397B の大規模 MoE モデルまで、エッジデバイスから最先端のワークロードまでをカバーするバリエーションを提供している。
高品質な基盤モデルの活用
各バリアントは、Gemma 4 と Qwen 3.5 という強力な事前学習済みモデルの上にトレーニングされており、高い基礎性能を確保している。
エージェント型コーディングへの特化
単なるコード補完ではなく、自律的に改善を行う「自己改善型」のアーキテクチャを採用し、複雑なコーディングタスクにおけるエージェント能力を強化している。
自己構築型スキャフォールディング
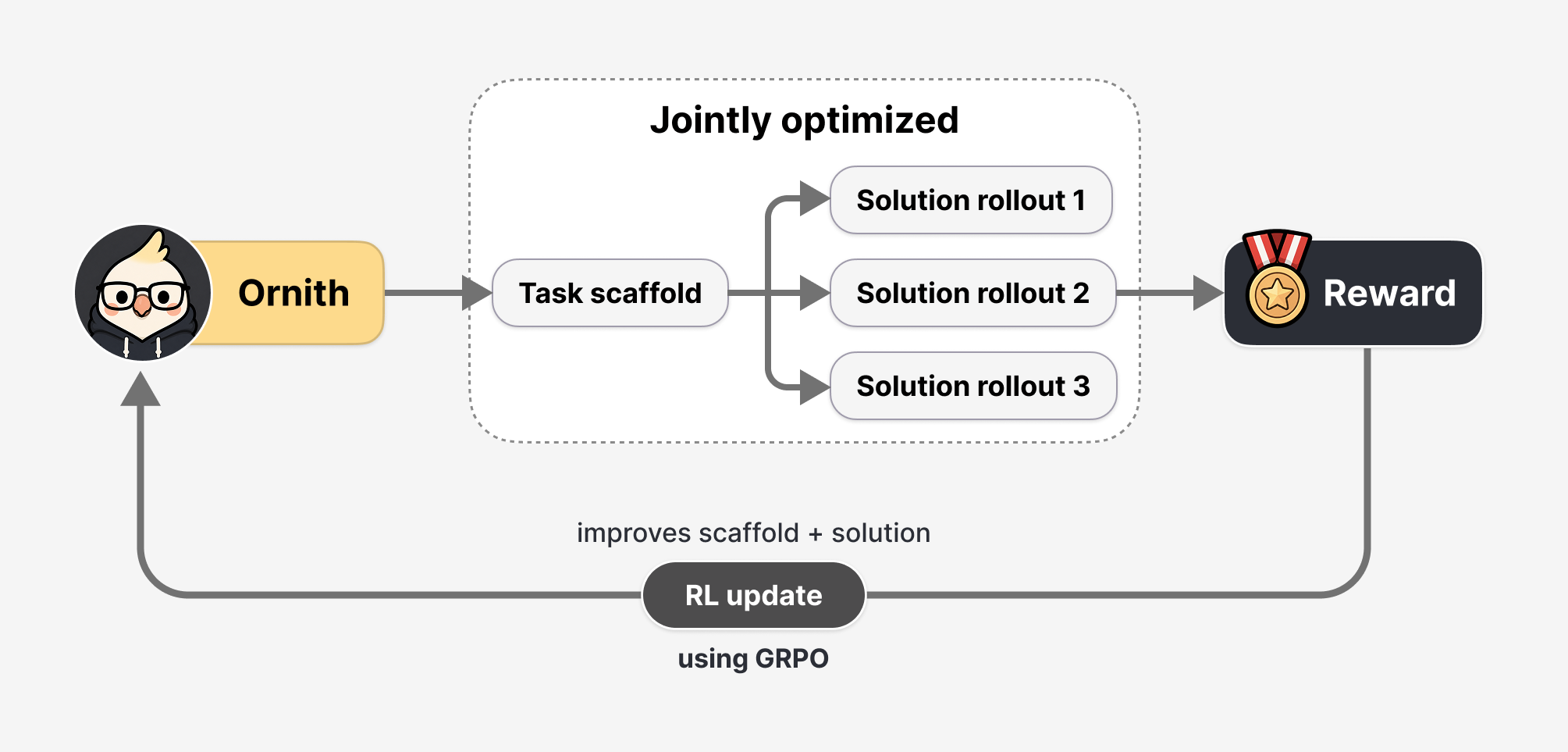
モデルが人間設計のハッチャーに依存せず、タスク解決のための「スキャフォールド(骨組み)」自体を生成・最適化する独自の強化学習アプローチを採用している。
報酬ハッキング防止の3層防御
環境の隔離、検出可能な監視機能、およびツール表面内でのゲーム化を検知する凍結されたLLM判事という3段階の対策により、検証を欺くリスクを防いでいる。
広範なサイズバリエーションと高性能
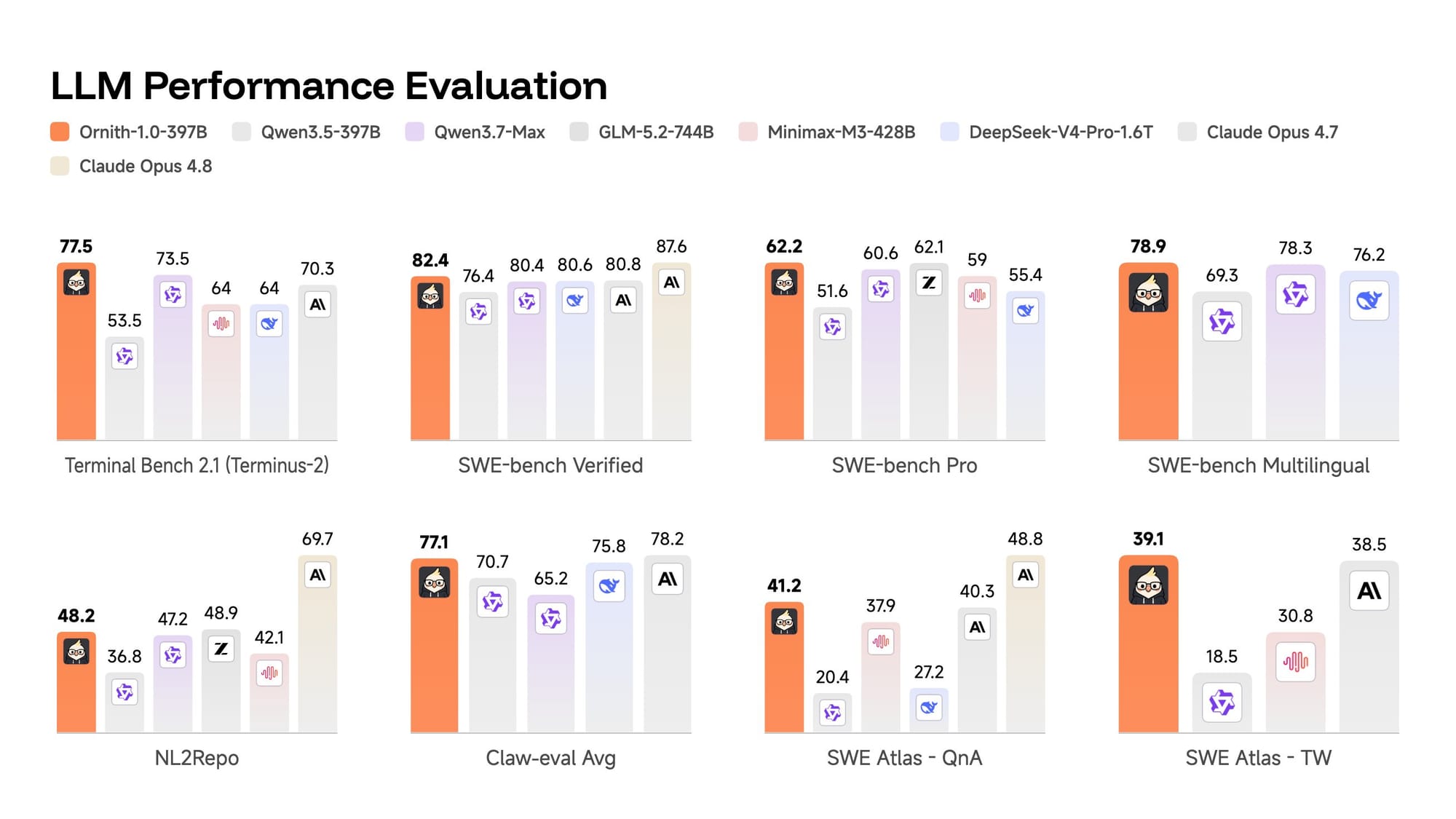
9Bから397Bまでのモデルが提供され、最大規模版はClaude Opus 4.7に匹敵する性能を、小規模版(9B)はリソース制限のある環境でも大規模モデル並みのコーディング能力を発揮する。
影響分析・編集コメントを表示
影響分析
このリリースは、大規模な計算リソースを持たない組織や個人でも、最先端のコーディングエージェント技術を試せる環境を提供し、オープンソースコミュニティにおける AI エージェント技術の普及を加速させるだろう。特に、異なるサイズバリエーションを用意することで、用途に応じた柔軟な導入が可能となり、実世界での適用範囲が広がる。
編集コメント
Gemma や Qwen のような既存の強力な基盤モデルを土台としつつ、特定のタスク(コーディング)に特化した「自己改善型」アプローチを採用した点は非常に興味深いです。エッジからクラウドまで幅広いサイズ展開は、実装のハードルを下げる重要な一歩と言えます。
DeepReinforce は、エージェント型コーディング用に構築された自己改善型のモデルファミリー Ornith-1.0 をオープンソース化しました。このリリースは、エッジ展開向けのコンパクトな 9B Dense バージョンから、最先端規模の作業を対象とした 397B MoE モデルまでを網羅しており、その間には 31B Dense と 35B MoE のオプションも含まれています。各バリアントは、事前学習済みである Gemma 4 および Qwen 3.5 を基盤としてトレーニングされています。
OpenSource
 imageOrnith-1.0
imageOrnith-1.0
Ornith-1.0 をほとんどの強化学習設定と区別する点は、そのスキャフォールド(足場)の扱い方です。人間の設計したハネスに依存して解決策の生成を誘導するのではなく、このモデルは解決策のロールアウト自体と、それを案内するタスク固有のスキャフォールドの両方を生成することを学習します。各強化学習ステップは 2 つの段階で実行されます。タスクと直前に使用されたスキャフォールドを条件として、モデルは洗練されたスキャフォールドを提案し、そのスキャフォールドを条件に解決策を生成します。ロールアウトからの報酬は両方の段階にフィードバックされ、モデルは回答だけでなくオーケストレーション(調整・指揮)の作成も学習するようにトレーニングされます。トレーニングを通じて繰り返し行われることで、スキャフォールドはより高い報酬をもたらす軌道を生み出す方向へと変異・選択され、手作業で設計されたハネスなしにタスク固有の戦略が自然に浮上します。
モデル自身にスキャフォールドを書かせることは、検証器を満たすためにスキャフォールドを生成するだけで実際のタスクを実行しない「報酬ハッキング」への道を開く可能性があります。DeepReinforce はこれに対する 3 層の防御策を説明しています:
- モデルの到達範囲を超えて環境とテストを隔離する、固定された外部信頼境界。
- 保留中のパスへの読み取りや検証スクリプトの変更を試みる試みを検出する、決定論的なモニター。
- 許可されたツール表面内でゲーム行為が発生した場合に検証者を拒否する、凍結された LLM 判事。
 imageOrnith-1.0
imageOrnith-1.0
パフォーマンス面では、DeepReinforce は Ornith-1.0 を同等規模の オープンソース モデルの中で最先端と位置付けています。同社によると、397B のフラッグシップモデルは Terminal-Bench 2.1 で 77.5、SWE-Bench Verified で 82.4 を達成しており、これは Claude Opus 4.7 や MiniMax M3、DeepSeek-V4-Pro といったトップクラスのオープンソース競合と同等の数字であると述べています。また、35B モデルは同規模の Qwen や Gemma のビルドを凌駕し、9B バージョンは Terminal-Bench 2.1 で 43.1、SWE-Bench Verified で 69.4 を達成し、Gemma 4-31B のようなはるかに大規模なモデルと同等の性能を発揮するとされています。これにより、リソースが限られたハードウェアでも高機能なコーディングが可能になります。
DeepReinforce はこのリリースを主導した AI ラボであり、CUDA-L1(CUDA-L1)などの先行研究やコードエージェント向けの IterX 最適化ループ(IterX optimization loop)を提供するチームです。Ornith-1.0 は、スキャフォールド構築(scaffold construction)をトレーニングプロセス自体に組み込むことで、この方向性をさらに推し進めています。重みと技術報告書は、モデルを直接実行または研究したいチーム向けに Hugging Face で公開されています。
原文を表示
DeepReinforce has open-sourced Ornith-1.0, a self-improving family of models built for agentic coding. The release spans the full range, from a compact 9B Dense version meant for edge deployment up to a 397B MoE model aimed at frontier-scale work, with 31B Dense and 35B MoE options in between. Each variant is trained on top of pretrained Gemma 4 and Qwen 3.5 foundations.
OpenSource
What sets Ornith-1.0 apart from most reinforcement learning setups is how it handles the scaffold. Rather than depending on human-designed harnesses to steer solution generation, the model learns to produce both the solution rollouts and the task-specific scaffolds that guide them. Each RL step runs in two stages. Conditioned on a task and the scaffold last used for it, the model proposes a refined scaffold, then generates a solution conditioned on that scaffold. Reward from the rollout flows back to both stages, so the model is trained to author the orchestration as well as the answer. Repeated across training, scaffolds get mutated and selected toward those that produce higher-reward trajectories, and per-task strategies surface on their own without hand-engineered harness design.
Letting a model write its own scaffold opens a path to reward hacking, where a scaffold satisfies the verifier without doing the task. DeepReinforce describes a three-layer defense:
- A fixed outer trust boundary that keeps the environment and test isolation beyond the model's reach.
- A deterministic monitor that flags attempts to read withheld paths or alter verification scripts.
- A frozen LLM judge that vetoes the verifier when gaming happens inside the allowed tool surface.
On performance, DeepReinforce positions Ornith-1.0 as state of the art among open-source models of comparable size. The company reports the 397B flagship reaching 77.5 on Terminal-Bench 2.1 and 82.4 on SWE-Bench Verified, figures it says match Claude Opus 4.7 and top open peers such as MiniMax M3 and DeepSeek-V4-Pro. The 35B model is reported to clear similarly sized Qwen and Gemma builds, while the 9B version is said to hit 43.1 on Terminal-Bench 2.1 and 69.4 on SWE-Bench Verified and match far larger models like Gemma 4-31B, which puts capable coding within reach of resource-limited hardware.
DeepReinforce is the AI lab behind the release, a team that publishes reinforcement learning research in the open, including prior work such as CUDA-L1, and that shipped the IterX optimization loop for code agents. Ornith-1.0 carries that direction further by folding scaffold construction into the training process itself. The weights and a technical report are released on Hugging Face for teams that want to run or study the models directly.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み