AIのボトルネック:高品質な人間によるデータ
Surge AI は、モデルの進化にデータ品質が追いついていない現状を指摘し、高品質な人間によるデータ作成プラットフォームの重要性を説いている。
キーポイント
AI 発展のボトルネックはデータ品質
ハードウェアやアルゴリズムの進化にもかかわらず、訓練データの欠陥が AI の実社会への浸透を阻んでいる。
エンゲージメント指標と品質のミスマッチ
クリック数やエンゲージメントといった安易なプロキシデータに依存することで、有害コンテンツの拡散や推薦精度の低下を招いている。
人間による高品質データの必要性
スパム混入や誤ラベルの多い既存データセットの問題に対し、Google や Facebook の元エンジニアらが構築した人間主導のプラットフォームが解決策として提示されている。
高品質なデータラベラーの必要性
複雑化するAIシステムには、問題の本質を理解し、偏見やヘイトスピーチを識別できる熟練した人間によるラベル付けが不可欠です。
MLチームとラベラー間の対話の重要性
データ作成はフィードバック駆動のプロセスであり、ラベラーが指摘する曖昧さや洞察を反映させるために両者の継続的なコミュニケーションが必要です。
人間価値観に合致した目的関数の設計
モデルの真の目標とデータセットの近似値との乖離を防ぎ、クリック数ではなく「時間の質」や社会的価値を最適化する必要があります。
AI の目的とデータセットの重要性
AI が人間の本質的なニーズを満たすためには、アルゴリズムよりも高品質なデータセットを構築するスキルが最も重要である。
影響分析・編集コメントを表示
影響分析
この記事は、AI 業界が「モデルの規模拡大」から「データの質的向上」へと焦点を移すべき重要な転換点を示唆しています。特に、エンゲージメント最大化アルゴリズムがもたらす社会的弊害(フェイクニュースや有害コンテンツ)への懸念をデータ構造の問題として浮き彫りにしており、企業にとってデータ戦略の再構築を迫る内容です。
編集コメント
モデルの性能向上が止まったように見える背景には、実は「データの質」がボトルネックになっているという本質的な指摘です。今後は生成 AI の活用だけでなく、データ収集・ラベリングプロセスそのものの見直しが競争力の源泉となるでしょう。
AIのボトルネック:高品質な人手によるデータ
理論上、AIは私たちの最も大胆な夢をはるかに超えて進化している。しかし現実には、Siriでさえ天気を教えてくれない。問題は何か?モデルの訓練と評価に使用する高品質なデータセットの作成は、依然として非常に困難なのである。Redditの分類器を訓練するための20,000件のラベルを1日で収集できるはずなのに、実際には3ヶ月待たされ、スパムだらけの訓練セットが返ってくる。Surge AIは、この問題を解決するために人間とAIのプラットフォームを構築しているGoogle、Facebook、Twitterのエンジニアと研究者のチームである。信頼できるデータセット構築の支援が必要ですか?あるいは、より高品質なMechanical Turkに興味がありますか?team@surgehq.ai(またはTwitterの@HelloSurgeAI)までご連絡ください!
4年前、AlphaGoは世界の囲碁のエキスパートを打ち負かし、ビッグテック企業は手に入る限りのMLスタートアップを買収し、ニューヨーク・タイムズは「機械学習はコンピューティングそのものを再発明しようとしている」と宣言した。
2016年、DeepMindはStarCraft IIに勝利するAIの構築を開始し、2019年末までにそのAlphaStar AIはグランドマスターレベルに到達した。https://www.youtube.com/watch?v=5iZlrBqDYPM
まるであと数年もすれば、Alexaが私たちの家を乗っ取り、Netflixが友達よりも優れた映画の提案をしてくれる世界が来るかのように感じられた。
👀 それ以来、何が起こったのか?
より高速なGPUにより、ニューラルネットワークの訓練コストは低下し、ますます大規模なモデルの訓練が可能になった。新しいツールにより、インフラストラクチャの作業ははるかに容易になった。
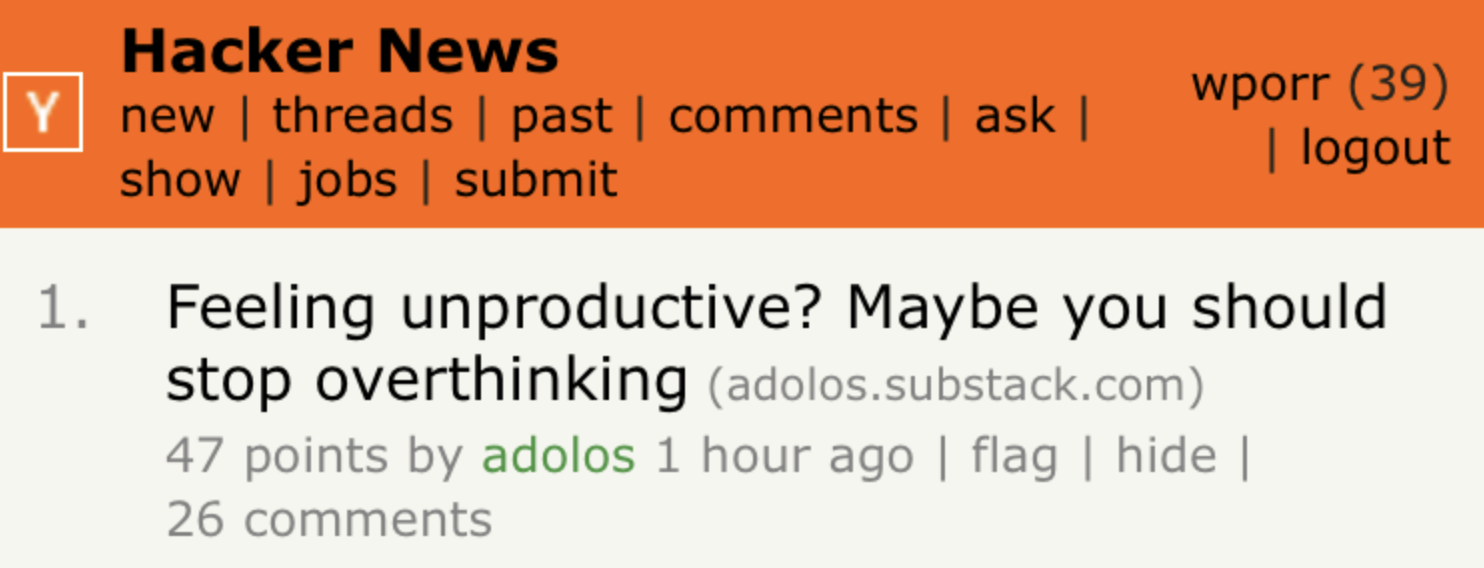
また、より主観的なタスクを実行することを学ぶ新しいニューラルネットワークアーキテクチャも開発された。例えば、TransformerはOpenAIのGPT-3モデルを支えており、この言語生成モデルはHacker Newsのトップに到達するブログ記事を書く。
Hacker Newsのトップに到達した、GPT-3が執筆した生産性に関するブログ記事。https://liamp.substack.com/p/my-gpt-3-blog-got-26-thousand-visitors
では、革命はどこにあるのか?
では、なぜAIは世界を支配していないのか?
🧯 なぜGPT-3でブログ記事を生成できるのに、ソーシャルメディア企業は私たちのフィードから扇動的なコンテンツを排除するのに苦労しているのか?
🥯 なぜ超人的なStarCraftアルゴリズムがあるのに、Eコマースストアは私に2台目のトースターを買うよう勧めてくるのか?
🎬 なぜ私たちのモデルはリアルな画像(そして映画!)を合成できるのに、顔の検出には失敗するのか?
簡単に言えば、私たちのモデルは向上したが、データは向上していない。私たちのモデルは、依然として誤りが多く、作成者が実際に望んでいるものと適切に一致していないデータセットで訓練され(評価もされている!)のだ。
今日のデータの何が問題なのか? ゴミを入れれば、ゴミが出てくる 🦝
場合によっては、モデルはクリックやユーザーエンゲージメントのような代理指標で訓練される。
例えば、ソーシャルメディアのフィードは、ユーザーに最高の体験を提供するように訓練されているわけではない。代わりに、利用可能な最も簡単なデータ源であるクリックとエンゲージメントを最大化するように訓練されている。
しかし、「いいね」は品質とは異なる。衝撃的な陰謀論は中毒性があるが、あなたは本当にそれを自分のフィードで見たいだろうか?この不一致は、クリックベイトの拡散、政治的な誤情報の拡散、憎悪的で扇動的なコンテンツの蔓延など、多くの意図しない副作用を引き起こしている。
他の場合では、モデルは、母国語で作業していない労働者や、低品質な結果が決して検出されないと知っている労働者によって構築されたデータセットで訓練される。
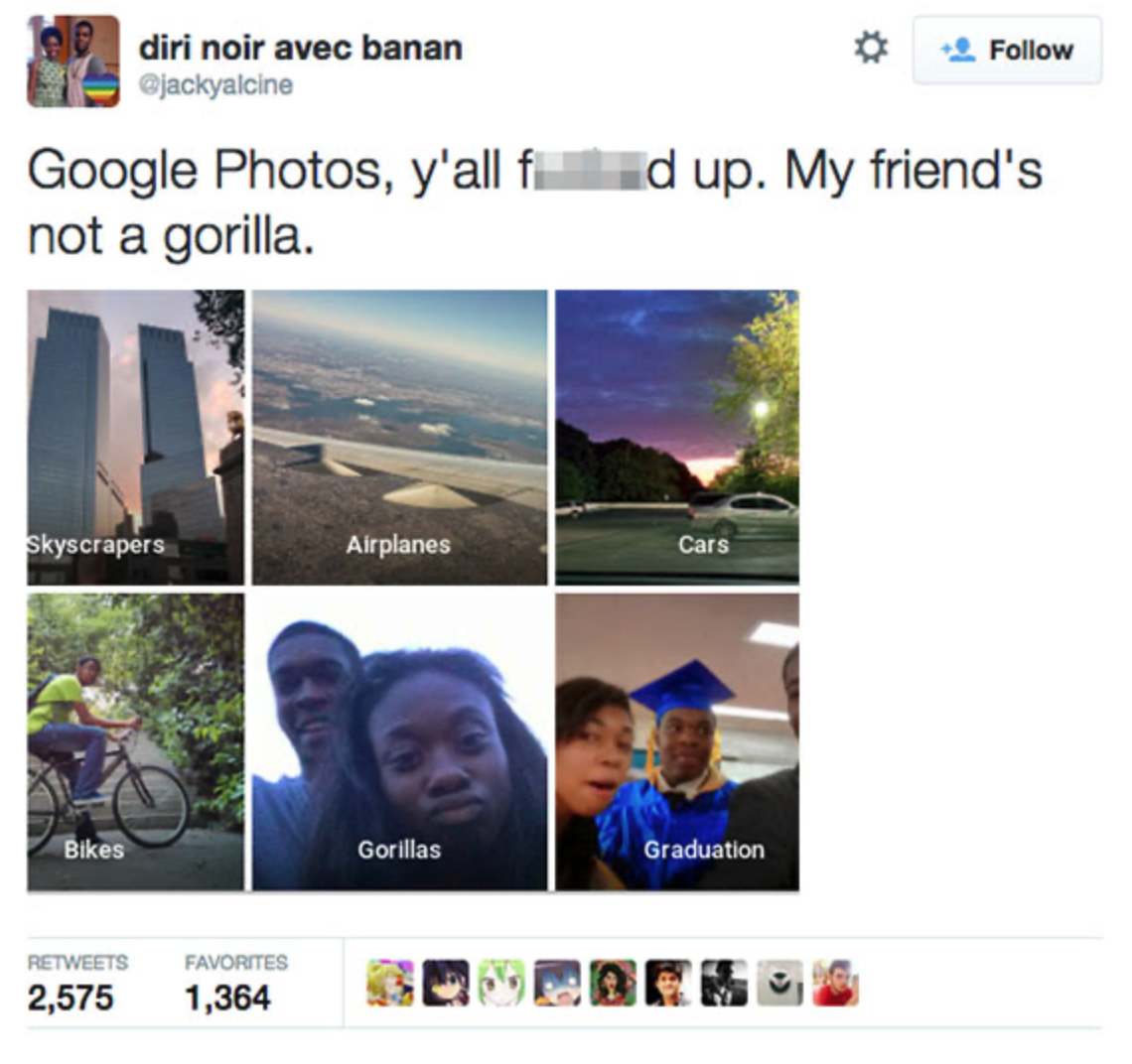
例えば、次のツイートを見てほしい。
典型的なラベラーは「bitches」、「fucking」、「shit」を見つけ、このツイートを有害とラベル付けするだろう。たとえその冒涜的な言葉が肯定的で励みになる意図で使われていてもだ。私たちはこのような問題に訓練セットで無数に遭遇してきた。
データがモデルを定義する。もしデータが誤ってラベル付けされたゴミであれば、どれだけMLの専門知識があっても、モデルが同様にゴミになることを防ぐことはできない。
🧗 私たちに必要な進歩は何か?
データセットの問題は、多くの問題を引き起こす。
パフォーマンスの低いモデルに直面したとき、エンジニアは数ヶ月をかけて機能や新しいアルゴリズムをいじくり回すが、問題がデータにあることに気づかない。友人や家族を結びつけることを意図したアルゴリズムが、激しい感情や怒りのコメントを駆り立てる結果になる。
どうすればこれらの問題を解決できるのか?次のAIの波を解き放つために不可欠だと私たちが信じる、一連の構成要素を以下に示す。
🎒 あなたが解決しようとしている問題を理解する、熟練した高品質なラベラー
AIシステムがより複雑になるにつれて、それらを教育し、そのパフォーマンスを測定するために、洗練された人間によるラベリングシステムが必要となる。誤解を招く情報を分類するのに十分な世界の知識を持つモデルや、クリックではなく「有意義に過ごした時間(Time Well Spent)」を増加させるアルゴリズムを考えてみてほしい。
このレベルの洗練さは、低スキルの労働者による多数決からは生み出せない。ヘイトスピーチについて機械に教え、アルゴリズムのバイアスを特定するためには、それらの問題自体を理解している高品質なラベリング要員が必要なのだ。
💃 MLチームとラベラーが交流する場
MLモデルは常に変化している。今日スパムメールと見なされるものが、明日はそうでないかもしれない。そして、ラベリングの指示書にすべてのエッジケースを網羅することは決してできない。
製品構築がユーザーとエンジニアの間のフィードバック駆動プロセスであるのと同様に、データセットの作成もそうあるべきだ。画像の中の顔を数えるとき、漫画のキャラクターは数えるのか?ヘイトスピーチをラベル付けするとき、引用文はどう扱うのか?ラベラーは何千もの例を処理した後、曖昧さや洞察を明らかにする。データ品質を最大化するためには、双方がコミュニケーションを取る必要がある。
人間の価値観に沿った目的関数
モデルは、多くの場合、真の目標の単なる近似に過ぎないデータセットで訓練されるため、意図しない乖離が生じる。
例えば、AI安全性の議論では、機械知能が世界を脅かす力を発達させることを人々は懸念している。他の人々は、これは遠い未来の問題だと反論する。しかし、今日の技術プラットフォームが直面する最大の問題を見ると、これはすでに起こっているのではないだろうか?
例えば、Facebookの使命は「いいね」を集めることではなく、私たちを友人や家族とつなぐことだ。しかし、「いいね」やインタラクションを増加させるようにモデルを訓練することで、それらは非常にエンゲージメントが高いが、同時に有害で誤った情報を含むコンテンツを拡散することを学んでしまう。
もしFacebookがその訓練目標に人間の価値観を注入できたらどうだろう?これは空想ではない。Google検索はすでに実験プロセスで人間による評価を使用しており、私たちが構築している人間-AIシステムも同じことを目指している。
🤖 人間の力によるAIの未来
機械学習の核心は、コンピュータに私たちが望む仕事を実行するように教えることにある。そして、私たちは正しい例を示すことでそれを実現する。
では、高品質なモデルを構築するためには、高品質なデータセットを構築し、それが手元の問題と一致していることを確認することが、MLエンジニアの最も重要なスキルであるべきではないだろうか?
結局のところ、私たちが気にかけるのは、AIが人工的なベンチマークを打ち負かすかどうかではなく、人間のニーズを解決するかどうかである。
もしあなたがコンテンツモデレーションに取り組んでいるなら、あなたのデータセットはヘイトスピーチだけでなく、肯定的で励みになる冒涜も捉えているだろうか?
もしあなたが次世代の検索システムやレコメンダーシステムを構築しているなら、あなたの訓練セットは関連性と品質をモデル化しているだろうか?それとも、中毒性のある誤情報とクリックをモデル化しているだろうか?
データセット作成は学校で教えられるものではなく、何年もアルゴリズムを研究してきたエンジニアがarXivの最も洗練されたモデルに固執するのは簡単だ。しかし、私たち自身の現実世界のニーズを解決するAIを望むなら、私たちのモデルを定義するデータセットについて深く考え、それらに人間の手を加える必要がある。
Surge AIは、Google、Facebook、Twitterのエンジニアからなるチームであり、高品質な教師ありデータの問題から始めて、次のAIの波を可能にするプラットフォームを構築している。これには人間と技術の協力が必要だ。私たちの高スキルなラベリング労働力は一連の厳格なテストを受け、私たちのプラットフォームは信頼できるデータ収集を簡単なものにする。私たちは協力して、トップ企業が誤情報、AIの公平性、創造的生成などのための大規模なデータセットを作成するのを支援してきた。低品質なデータセットにうんざりしていますか?あるいは、実際に機能するMechanical Turkに興味がありますか?ぜひお聞かせください。
原文を表示
The AI Bottleneck: High-Quality, Human-Powered Data
In theory, AI has blown past our wildest dreams; in practice, Siri can’t even tell us the weather. The problem? Creating high-quality datasets to train and measure our models is still incredibly difficult. We should be able to gather 20,000 labels for training a Reddit classifier in a single day, but instead, we wait 3 months and get back a training set full of spam. Surge AI is a team of Google, Facebook, and Twitter engineers and researchers building human-AI platforms to solve this. Need help building trustworthy datasets, or interested in a higher-quality Mechanical Turk? Reach out at team@surgehq.ai (or @HelloSurgeAI on Twitter)!
Four years ago, AlphaGo beat the world’s Go experts, big tech was acquihiring every ML startup they could get their hands on, and the New York Times declared that “machine learning is poised to reinvent computing itself”.
In 2016, DeepMind began building an AI to beat StarCraft II — and by the end of 2019, its AlphaStar AI reached GrandMasterlevel. https://www.youtube.com/watch?v=5iZlrBqDYPM
It felt like we were just a few years away from a world where Alexa would take over our homes, and Netflix would give us better movie suggestions than our friends.
👀 What’s happened since then?
Faster GPUs have dropped the cost of training neural networks and allowed for larger and larger models to be trained. New tools make the infrastructure work much easier.
We’ve also developed new neural network architectures that learn to perform more subjective tasks. Transformers, for example, power OpenAI’s GPT-3 model, a language generator that writes blog posts that reach the top of Hacker News.
A GPT-3-written blog post on productivity that reached the top of Hacker News. https://liamp.substack.com/p/my-gpt-3-blog-got-26-thousand-visitors
Then where’s the revolution?
So why hasn’t AI taken over the world?
🧯 Why can I generate a blog post with GPT-3 — but social media companies struggle to keep inflammatory content out of our feeds?
🥯 Why do we have superhuman Starcraft algorithm — while e-commerce stores still recommend I buy a second toaster?
🎬 Why can our models synthesize realistic images (and movies!) — but fail at detecting faces?
The short answer: our models have gotten better but our data hasn’t. Our models are trained on (and measured against!) datasets that remain error-ridden and poorly aligned with what creators actually want.
What’s wrong with today’s data? Garbage in, garbage out 🦝
In some cases, models are trained on proxies like clicks and user engagement.
Social media feeds, for example, aren’t trained to provide users the best experience; instead, they maximize clicks and engagement, the easiest sources of data available.
But likes are different from quality — shocking conspiracy theories are addictive, but do you really want to see them in your feed? — and this mismatch has led to a host of unintended side effects, including the proliferation of clickbait, the spread of political misinformation, and the pervasiveness of hateful, inflammatory content.
At other times, models are trained on datasets built by workers who don’t work in their native language or who know that low-quality results will never be detected.
Take, for example, the following tweet.
A typical labeler will spot “bitches”, “fucking”, and “shit”, and label this tweet as toxic, even though the profanity is intended in a positive, uplifting manner. We’ve run into issues like these in our training sets countless times.
Data defines the model. If the data is mislabeled garbage, no amount of ML expertise will prevent the model from being junk as well.
🧗 What advancements do we need?
Dataset issues cause a host of problems.
When faced with poorly performing models, engineers spend months tinkering with features and new algorithms, without realizing that the problem lies with their data. Algorithms intended to bring friends and family together drive red-hot emotions and angry comments instead.
How can we fix these problems? Here are a set of building blocks we believe are critical for unlocking the next wave of AI.
🎒Skilled, high-quality labelers who understand the problem you’re trying to solve
As AI systems become more complex, we need sophisticated human labeling systems to teach them and measure their performance. Think of models with enough knowledge of the world to classify misleading information, or algorithms that increase Time Well Spent instead of clicks.
This level of sophistication can’t be boosted from majority votes on low-skill workers. In order to teach our machines about hate speech and to identify algorithmic bias, we need high-quality labeling forces who understand those problems themselves.
💃 Spaces for ML teams and labelers to interact
ML models are constantly changing. What counts as a spammy email today may not tomorrow, and we’ll never capture every edge case in our labeling instructions.
Just as building products is an feedback-driven process between users and engineers, dataset creation should be as well. When counting faces in an image, do cartoon characters count? When labeling hate speech, where do quotes fall? Labelers uncover ambiguities and insights after going through thousands of examples, and to maximize data quality, we need both sides to communicate.
Objective functions aligned with human values
Models often train on datasets that are merely an approximation of their true goal, leading to unintended divergences.
In AI safety debates, for example, people worry about machine intelligences developing the power to threaten the world. Others counter that this is a problem for the far future — and yet, when we look at the largest issues facing tech platforms today, isn’t this already happening?
Facebook’s mission, for example, isn’t to garner likes, but to connect us with our friends and family. But by training its models to increase likes and interactions, they learn to spread content that’s highly engaging, but also toxic and misinformed.
What if Facebook could inject human values into its training objectives? This isn’t a fantasy: Google Search already uses human evaluation in its experimentation process, and the human-AI systems we’re building aim to do the same.
🤖 A human-powered AI future
At its core, machine learning is about teaching computers to perform the job we want — and we do that by showing them the right examples.
So in order to build high-quality models, shouldn’t building high-quality datasets, and making sure they match the problem at hand, be the most important skill of an ML engineer?
Ultimately, we care whether AI solves human needs, not whether it beats artificial benchmarks.
If you work on content moderation, are your datasets capturing hate speech — or positive, uplifting profanity too?
If you’re building the next generation of Search and Recommender Systems, are your training sets modeling relevance and quality — or addictive misinformation and clicks?
Dataset creation isn’t something taught in schools, and it’s easy for engineers who’ve spent years studying algorithms to fixate on the fanciest models in arXiv. But if we want AI that solves our own real-world needs, we need to think deeply about the datasets that define our models, and give them a human touch.
Surge AI is a team of Google, Facebook, and Twitter engineers building platforms to enable the next wave of AI — starting with the problem of high-quality supervised data. This requires humans and technology working together. Our high-skill labeling workforce undergoes a rigorous series of tests; our platform then makes trustworthy data collection a breeze. Together, we’ve helped top companies create massive datasets for misinformation, AI fairness, creative generation, and more. Tired of low-quality datasets, or interested in a Mechanical Turk that actually works? We’d love to hear from you.
Follow us onLinkedinXEnterpriseBench: CoreCraft – Measuring AI Agents in Chaotic, Enterprise RL EnvironmentsHemingway-bench Leaderboard: Because Good Writing Isn't a Checklist of VibesBuilding AdvancedIF: Evolving Instruction Following Beyond IFEval and “Avoid the Letter C”LMArena is a cancer on AIRL Environments and the Hierarchy of Agentic CapabilitiesHow do frontier models perform on real-world finance problems?A Product Take on Sonnet 4.5Is Sonnet 4.5 the best coding model in the world?The Human/AI Frontier: A Conversation with Bogdan GrechukSWE-Bench Failures: When Coding Agents Spiral Into 693 Lines of HallucinationsBenchmarks are brokenUnsexy AI Failures: The PDF That Broke ChatGPTBringing light to the GPT-4o vs. GPT-5 personality controversyDALL·E 3 and Midjourney Fail Astral Codex Ten's Image Generation BetHow Anthropic uses Surge AI to Train and Evaluate ClaudeWe Evaluated ChatGPT vs. Google on 500 Search QueriesAI Red Teams for Adversarial Training: How to Make ChatGPT and LLMs Adversarially RobustHellaSwag or HellaBad? 36% of this popular LLM benchmark contains errorsHow TikTok is Evolving the Next Generation of SearchEvaluating Generative AI: Did Astral Codex Ten Win His Bet on AI Progress?Why Instagram is Losing Gen Z: We Asked 100 Users to Compare TikTok vs. ReelsThe $250K Inverse Scaling Prize and Human-AI AlignmentSearch Behind-the-Scenes: How Neeva Uses Human Evaluation to Measure Search QualityHuman Evaluation of Large Language Models: How Good is Hugging Face’s BLOOM?30% of Google's Emotions Dataset is MislabeledAI Red Teams and Adversarial Data Labeling with Redwood ResearchHumans vs. Gary Marcus vs. Slate Star Codex: When is an AI failure actually a failure?How Surge AI Built OpenAI's GSM8K Dataset of 8,500 Math ProblemsWe asked 100 humans to draw the DALL·E promptsGoogle Search is Falling BehindMoving Beyond Engagement: Optimizing Facebook's Algorithms for Human ValuesHoly $#!t: Are popular toxicity models simply profanity detectors?Is Google Search Deteriorating? Measuring Google's Search Quality in 20225 Examples of the Importance of Context-Sensitivity in Data-Centric AIThe AI Bottleneck: High-Quality, Human-Powered DataFrom the frontier to your inbox
Subscription confirmed







![](https://cdn.prod.website-files.com/68dcd2ceb173c46fa0299
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み