メタがオープンウェイトから方針転換、製薬大手は AI に賭け、規制の複雑化と人間コホートのシミュレーション
AI ネイティブなソフトウェア開発チームにおけるコーディング速度の向上が、製品管理や法務などの周辺プロセスにボトルネックを生み出しており、エンジニアとプロダクトマネージャーの役割融合による組織変革が急務であると指摘している。
キーポイント
AI ネイティブチームの役割拡大
コーディングエージェントの活用によりエンジニアは製品管理やデザインなどの広範な役割を担うようになり、従来の狭義の開発者像から脱却している。
プロダクト管理ボトルネックの解消戦略
エンジニアとPM の比率を下げるだけでなく、双方が相手のスキルを理解し融合させることで、意思決定と実装間のコミュニケーションコストを削減する。
開発速度向上に伴う新たなボトルネック
コーディングが 10 倍〜100 倍速くなる一方で、マーケティングや法務審査などの周辺プロセスが遅れ、組織全体の「スウィベルチェア・ボトルネック」を発生させている。
AI ネイティブチームの役割拡大と「スワールチェア・ボトルネック」
コーディング速度が向上したことで、エンジニアは製品管理やデザインなどの広範な役割を担うようになり、従来の専門職中心のチーム構造から少人数の一般化されたチームへ移行している。
Meta の「Muse Spark」発表とオープンウェイト戦略からの転換
Meta は健康・マルチモーダル性能に特化したクローズドモデル「Muse Spark」を発表し、開発者コミュニティへの影響を懸念させる中、同社がオープンウェイト戦略から離脱したことを示している。
生成 AI を活用した薬物発見の加速と Eli Lilly の巨額投資
Eli Lilly が Insilico Medicine に最大 27.5 億ドルを拠出し、AI による創薬プロセスが従来の数年から約 18 ヶ月へと短縮される実証事例が出ている。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI がコード生成能力を飛躍的に高めた結果、ソフトウェア開発のボトルネックが「実装」から「意思決定」と「周辺プロセス(法務・マーケティング)」へシフトしたことを示唆しています。企業にとっては、単にツールを導入するだけでなく、エンジニアとプロダクトマネージャーの役割を融合させ、組織全体のワークフローを再設計することが、AI 時代の競争力を維持するために不可欠であると結論付けています。
編集コメント
AI ツールの導入が即座に生産性を高めるだけでなく、組織の構造や他部門との連携における新たな課題を浮き彫りにする重要な視点です。技術的な進化よりも、人間側の適応速度こそが今後の鍵となるでしょう。
親愛なる皆様、
AI ネイティブのソフトウェアエンジニアリングチームは、従来のチームとは非常に異なる方法で運営されています。明白な違いは、AI ネイティブチームがコーディングエージェントを使用して製品をはるかに迅速に構築できる点ですが、これにより私たちの運用方法には多くの他の変化が生じます。例えば、一部の優れたエンジニアはコードを書くことだけでなく、より広範な役割を果たすようになりました。彼らは部分的にプロダクトマネージャーやデザイナー、時にはマーケターでもあります。さらに、同じオフィスで働き、対面でコミュニケーションが取れる小規模チームは、驚くほど迅速に進めることができます。
現在、迅速に構築できるため、何を構築するかを決定する時間に多くの時間を割く必要があります。このプロジェクト管理のボトルネックに対処するため、一部のチームではエンジニアとプロダクトマネージャー(PM)の比率を、例えば 8:1 から最低 1:1 まで引き下げようとしています。しかし、さらに良い方法があります:何を構築するかを決める PM が一人おり、それを構築するエンジニアが一人いる場合、両者間のコミュニケーションがボトルネックとなります。これが私が目にする最も動きの速いチームには、プロダクト作業をある程度できるエンジニア(およびオプションで、エンジニアリング作業をある程度できる PM)がいる傾向がある理由です。ユーザーを理解し、何を構築するかを決定して直接構築できるエンジニアは、驚くほど迅速に実行できます。
私は、エンジニアが製品決定を行う役割を成功裏に拡大し、PM がソフトウェア構築の役割を拡大する様子を見てきました。テクノロジー業界には PM よりも多くのエンジニアが存在しますが、どちらも有望な道です。あなたがエンジニアであれば、いくつかのプロダクトマネジメントスキルを学ぶことが役立つでしょう。また、PM の方はぜひ構築方法を学んでください。
製品管理のボトルネックを超えて、私はデザイン、マーケティング、法的コンプライアンスなどにもボトルネックがあると考えています。コーディングを 10 倍や 100 倍に高速化すると、他のすべてのプロセスが相対的に遅く見えてしまいます。例えば、私のチームの一部は非常に迅速に優れた機能を構築しましたが、その結果、マーケティング組織がユーザーへの伝え方を慌てて検討することになり、これがマーケティングのボトルネックとなりました。あるいは、あるチームが 1 日でソフトウェアを構築できる一方で、法務部門がレビューに 1 週間を要する場合、それが法的コンプライアンスのボトルネックとなります。このように、エージェント型コーディングはソフトウェアエンジニアリングのワークフローを変えるだけでなく、その周囲にあるすべてのチームにも変化をもたらしています。
 image 規模が小さく AI を活用したチームであれば、より多くの成果を上げることができます。この場合、一般化された能力を持つ人材が特に優れています。従来の企業では、プロジェクトを実行し価値を生み出すために、エンジニアリング、プロダクトマネジメント、デザイン、マーケティング、法務など多様な専門分野から人々を集めなければなりません。その結果、専門職の大きなチームが形成され、互いに連携して働くことになります。しかし、2 人のチームで 5 つの異なる専門性を要する業務を遂行しなければならない場合、一部の個人は単一の専門分野に限定されない役割も果たさなければなりません。小規模なチームでは、個人が深い専門性を持つこともあります。例えば、一人は優れたエンジニアであり、もう一人は優れたプロダクトマネージャーであるかもしれません。しかし、プロジェクトを前進させるために必要な他の主要機能についても理解しており、必要に応じて他の種類の課題について思考し、対応することもできます。もちろん、AI ツールへの習熟度は大きな助けとなります。なぜなら、異なる役割が関わる問題について考えるのを助けてくれるからです。
image 規模が小さく AI を活用したチームであれば、より多くの成果を上げることができます。この場合、一般化された能力を持つ人材が特に優れています。従来の企業では、プロジェクトを実行し価値を生み出すために、エンジニアリング、プロダクトマネジメント、デザイン、マーケティング、法務など多様な専門分野から人々を集めなければなりません。その結果、専門職の大きなチームが形成され、互いに連携して働くことになります。しかし、2 人のチームで 5 つの異なる専門性を要する業務を遂行しなければならない場合、一部の個人は単一の専門分野に限定されない役割も果たさなければなりません。小規模なチームでは、個人が深い専門性を持つこともあります。例えば、一人は優れたエンジニアであり、もう一人は優れたプロダクトマネージャーであるかもしれません。しかし、プロジェクトを前進させるために必要な他の主要機能についても理解しており、必要に応じて他の種類の課題について思考し、対応することもできます。もちろん、AI ツールへの習熟度は大きな助けとなります。なぜなら、異なる役割が関わる問題について考えるのを助けてくれるからです。
2 人のチームであっても、迅速に進めるためにはコミュニケーションのボトルネックを最小限に抑える必要があります。そのため、私は同じ場所で働くチームを高く評価しています。リモートチームも良好な成果を出すことができますが、最も高い速度を実現するのは、全員が同じ部屋にいて、問題解決のために瞬時にコミュニケーションが取れる状態にあることです。
この手紙では、主に 2〜10 人程度の AI ネイティブなチームについて焦点を当てますが、すべてのことを小規模チームで完遂できるわけではありません。大規模チームの調整については、今後取り上げていきます。
これらの役割の変化を多くの人が navigating するのは難しいと感じていることを理解しています。同時に、関連するスキルを習得する意志を持つ個人や小規模チームが、以前よりもはるかに多くの成果を出せるようになったことに希望を抱いています。これは学習と構築の黄金期です!
作り続けましょう。
アンドリュー
DEEPLEARNING.AI からのメッセージ
「仕様駆動型開発」では、コーディングエージェントとの協働における規律あるワークフローを学びます。仕様に従い、実装を段階的に導きながら、構築するものをコントロールし続けてください!無料で参加はこちら
ニュース
Llama 後の時代
Meta はオープンウェイト戦略から転換し、クローズドな代替案を提供しました。
新情報: Meta は1年ぶりに最初の AI モデルを発表するとともに、9 ヶ月で設立されたスーパーインテリジェンス・ラボ(Superintelligence Labs)の初の製品を公開しました。Muse Spark は、ツール使用とマルチエージェントオーケストレーションをサポートするネイティブな多モーダル推論モデルです。一部の健康分野や多モーダルベンチマークでは首位を占めていますが、コーディングやエージェント作業においては不足が見られ、Meta はこれをアーキテクチャの再設計を検証するものとして位置づけており、同社はこれに基づいてより大規模なモデルを構築する計画を立てています。
- 入力/出力:テキスト、画像、音声(最大 262,000 トークン)を入力し、テキストを出力
- パフォーマンス:Artificial Analysis Intelligence Index で第4位
- 利用可能状況:meta.ai および Meta AI アプリを通じて無料提供;WhatsApp、Instagram、Facebook、Messenger、Ray-Ban Meta AI グラスにも順次展開;特定パートナー向け API プレビューも実施中
- 機能:3 つの推論モード(即時、思考、熟考)、ショッピングモード
- 非公開情報:パラメータ数、アーキテクチャ、トレーニングデータおよび手法、出力サイズ制限
仕組み: Meta は Muse Spark の技術詳細については限定的にしか開示していませんが、トレーニング効率の向上やマルチエージェントオーケストレーションの強化、さらにヘルスケア分野への専門的な投資を強調しました。
- 同社は事前学習のアプローチ、モデルアーキテクチャ、最適化手法、データ選定を再構築しました。Meta によると、Muse Spark は Llama 4 Maverick と同等の能力を持ちながら、トレーニングに割く処理量は桁違いに少なくて済みます。
- 事後学習では、チームが過度な推論トークンの使用に対してモデルにペナルティを与える強化学習(reinforcement learning)を実施しました。このプロセスは「思考圧縮(thought compression)」と呼ばれています。このペナルティの下で、モデルはまず推論時間を延ばして改善し、次に推論を圧縮する方法を学び、さらに推論を拡張してさらなる向上を図りました。
- 単一の思考連鎖(chain of thought)を処理するのではなく、「考査モード」では複数のエージェントが同時に起動し、解決策を提案し、それらを洗練させ、結果を集約します。Meta によれば、これにより比較可能なレイテンシでより高いパフォーマンスを実現しています。
- 健康分野の推論能力を向上させるため、Meta はより正確で包括的な健康回答を生み出すことを目的としたトレーニングデータの選定を支援するため、1,000 名以上の医師を起用しました。
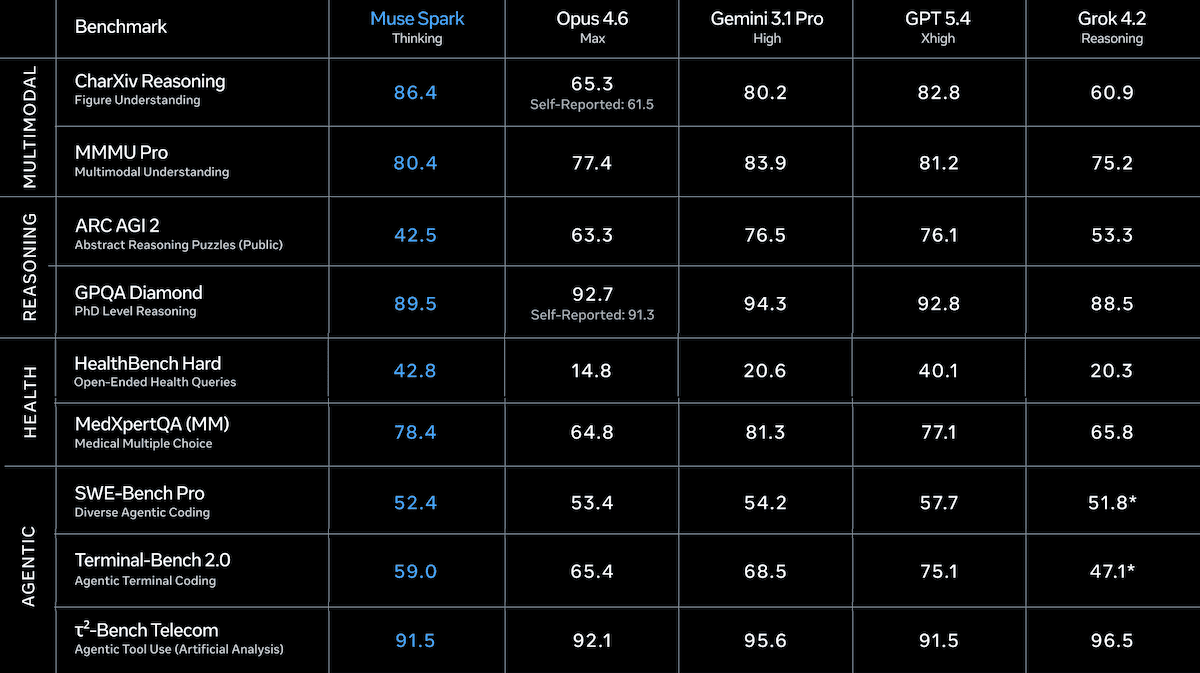
結果: Muse Spark のベンチマーク性能は全般的に競争力があり、特にトークン効率に優れています。Meta は、コーディング能力やエージェントとしてのパフォーマンスにおいて課題があることを認めています。
- Artificial Analysis のインテリジェンス指数(経済的に有用なタスクの 10 のベンチマークを複合化したもの)において、推論モードに設定された Muse Spark はスコア 52 で全体 4 位となりました。これは、高推論モードに設定された Gemini 3.1 Pro Preview と xhigh 推論モードに設定された GPT-5.4(ともに 57 で 3 位タイ)および最大推論モードに設定された Claude Opus 4.6(53)に次ぐ順位です。Muse Spark はこの指数を完了するために約 5900 万トークンを使用しましたが、Claude Opus 4.6 は約 1 億 5800 万トークン、GPT-5.4 は約 1 億 1600 万トークンを要しました。
- Muse Spark は少なくとも一つのマルチモーダルベンチマークで最高評価を獲得しています。Meta によると、チャートや図表の理解を問う CharXiv Reasoning では、Muse Spark(86.4%)は GPT-5.4(82.8%)および Gemini 3.1 Pro(80.2%)を上回りました。また、Artificial Analysis によると、多分野にわたる視覚的問題を解決する MMMU Pro では、Muse Spark(81%)が Gemini 3.1 Pro(82%)に次いで 2 位となりました。
- Artificial Analysis のコーディング指数(コーディングベンチマークの加重平均)では、Muse Spark(47)は GPT-5.4(57)、Gemini 3.1 Pro Preview(56)、および最大推論モードに設定された Claude Sonnet 4.6(51)に後れをとりました。
- Artificial Analysis が独立して測定したところ、ヒューマニティーズ・ラスト・エグザム(Humanity's Last Exam)の思考モードにおける Muse Spark のスコアは 39.9% で、Gemini 3.1 Pro Preview(44.7%)および GPT-5.4(41.6%)に次ぐ結果でした。しかし、Meta が報告するところでは、Muse Spark を検討モード(contemplating mode)で使用した場合のスコアは 58% です。
- Meta のテストでは、OpenAI のヘルスベンチマークの一部である HealthBench Hard において、Muse Spark は 42.8% で他のすべてのモデルを上回り、2 位の GPT-5.4(40.1%)をリードしました。また、エージェント型ブラウジング評価である DeepSearchQA でも Muse Spark が 74.8% で首位に立ち、Claude Opus 4.6 Max(73.7%)を抜きました。
ニュースの背景: Muse Spark は、Llama 4 のトレーニングデータがベンチマーク解答で汚染されているとの批判を受け AI ラボを再編した後の Meta にとって初の新モデルです。2025 年 6 月、Meta は Scale AI に 143 億ドルを投じて同社の 49% の株式を取得し、共同創設者のアレクサンダー・ワン氏を最高 AI 責任者(CAIO)に迎えると同時に、数億ドル規模の報酬パッケージを伴う大規模な採用活動を開始しました。この独自モデルのリリースは、オープンウェイトの Llama モデルを基盤としたプロジェクトを多数構築してきた開発者の間で懸念を招いています。
なぜ重要なのか: Meta は、その製品上の野望にとって最も重要な機能に投資しています。すなわち、カメラを搭載した数十億人のユーザー向けの多モーダル知覚、AI クエリの中で最も一般的なカテゴリの 1 つである健康推論、そして多段階タスクのためのマルチエージェント調整です。非公開 API のプレビューが進行中であり、OpenAI、Google、Anthropic と並んでビジネス顧客との競争に臨もうとしています。しかし、オープンウェイトの米国における主要な擁護者としての立場から転換することは、開発者コミュニティにとって大きな損失となります。
私たちが考えていること: Muse Spark の検討モードと Kimi K2.5 のエージェント群は、新たなパターンを示しています。より多くの研究所が、単一のモデルをさらに大きく訓練するのではなく、推論時に複数のエージェントを調整するようにモデルを訓練することで性能を拡張しようとしています。
 image生成 AI は、テキスト、画像、音声、動画、コードを生み出すことができることを証明しました。世界で最も価値のある製薬会社が、医薬品も生み出せるという確信のもとに数十億ドルを投じています。
image生成 AI は、テキスト、画像、音声、動画、コードを生み出すことができることを証明しました。世界で最も価値のある製薬会社が、医薬品も生み出せるという確信のもとに数十億ドルを投じています。
何が新しいか: 製薬大手のエリ・ Lilly は、創薬パイプライン全体に生成 AI を活用する香港のバイオテクノロジー企業である Insilico Medicine に最大 27.5 億ドルを提供することに合意しました。当初、Lilly は、まだ人間で試験されていない未公開の医薬品の開発および販売のための独占権を取得するために 1.15 億ドルを支払います。その後の支払いは、開発段階、規制承認、商業化などのマイルストーンに連動して行われます。これは『Fierce Biotech』が報じた内容です。これは、2023 年の AI ソフトウェアライセンス契約および 2025 年 11 月の 1 億ドルの研究協力に続く、両社間の 3 回目の合意となります。
AI を活用した創薬: 2014年に設立されたInsilicoは、AIを用いて28種類の候補薬剤を開発しており、そのうち約半数が臨床試験段階にあります。最も進んでいるのがRentosertibで、これは特発性肺線維症(IPF)を対象とした薬剤です。この疾患では瘢痕化が進行し、肺機能が徐々に低下します。第2a相試験(有効性を検証する初期の小規模テスト)は好結果を示しました。炎症性腸疾患の治療を目的とした第2の薬剤Garutadustatは、2026年1月に第2a相試験を開始しました。
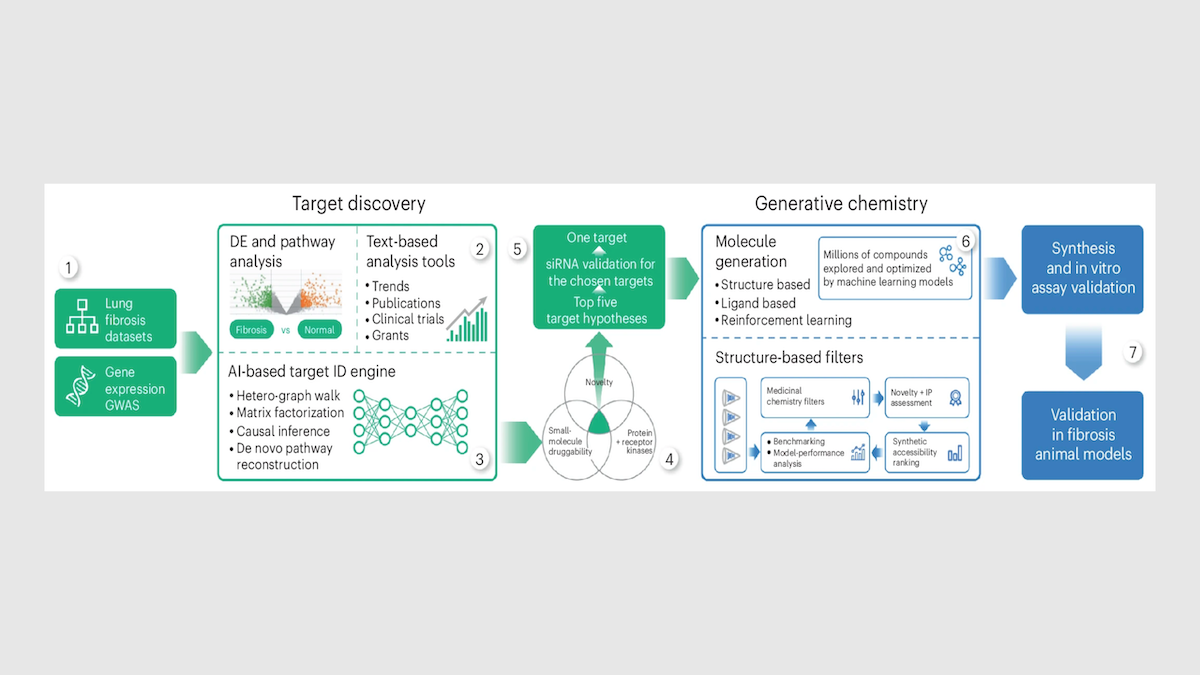
仕組み: 疾患を選択した後、Insilico は独自開発の生成モデルを用いて、創薬プロセスの2段階に適用します。1つ目は標的とするタンパク質を特定する段階、もう1つ目はそのタンパク質に作用する分子を設計する段階です。
- ターゲットを見つけるために、Insilico は PandaOmics というツールを使用して、生物学的データセット、公開研究、特許、臨床試験、助成金申請を分析します。ディープラーニングモデルは、疾患との関連性、薬物ターゲットとしての適格性、新規性の観点から候補ターゲットをランク付けします。IPF(特発性肺線維症)の場合、PandaOmics は IPF および関連疾患の特徴である瘢痕化に関与するタンパク質 TNIK を最有力候補として特定しました。TNIK をブロックすることで IPF を治療しようとした試みはこれまでありませんでした。
- TNIK をブロックする分子を設計するために、チームは Chemistry42 を使用しました。約 30 の生成モデルが並列で実行され、結合強度、毒性、溶解度、およびその他の特性に対して最適化された候補分子構造を生成しました。科学者たちは複数のラウンドにわたって出力を評価し、洗練させました。このプロセスにより、Insilico が 80 化合物未満を合成・試験した後にリード分子が得られました。従来の創薬では、チームは数百の候補を合成・試験する前に、既存の化合物 20 万から 100 万をスクリーニングすることが一般的です。
- ターゲットの特定から前臨床安全性試験に供する分子の合成に至るまでの期間は約 18 か月でした。これは典型的な 5 から 6 年と比較して劇的な短縮です。このペースは 2021 年から 2024 年の間に Insilico の 20 を超えるプログラム全体で安定しており、各プログラムでは前臨床候補を 1 つ見出すために約 60 から 200 の分子を合成・試験しました。
ニュースの背景: 新しい薬の開発には通常 10 から 15 年がかかり、コスト は 20 億ドルを超え、候補の約 86 パーセントが承認に至る前に失敗します。プロセスを加速させるために AI を適用する創薬開発者の数は増加しています。ピアレビューされた分析では、2025 年半ば時点で臨床段階にある AI 活用型薬物プログラム 173 件をカタログ 化しました。それでもなお、AI によって発見された薬物で規制承認を受けたものはまだありません。第 2 相に至る薬物候補の 70 パーセントは次の段階に進むことができません。これには BenevolentAI や Recursion Pharmaceuticals による AI 設計の薬物候補も含まれます。
なぜ重要なのか: Insilico のパイプラインは、生成 AI が科学における最も困難な問題の一つ——特定のタンパク質に結合し、体内で吸収され、毒性がなく、患者を助ける分子を見つけること——に取り組める可能性を示唆しています。Rentosertib の第 2a 相試験では、最高用量を投与された参加者の強制肺活量(肺機能の指標)が平均 98.4 ミリリットル増加した一方、プラセボ群は 20.3 ミリリットル減少しました。これは初期段階ですが、AI が生成した医薬品が患者を助けることができるという具体的な証拠です。
私たちが考えていること: AI は創薬開発を加速させていますが、従来の方法で開発された化合物よりも、これらの加速された化合物が臨床試験をより高い確率で通過するかどうかは、まだ見極められていません。
米国各州が AI 法を前進させる
米国の各州は、ドナルド・トランプ大統領が国家レベルの法律に代わる州ごとの立法を抑制しようとする努力にもかかわらず、AI を規制する法律の制定を続けています。
何が新しいか: 多くの州がこの一年間に AI の規制に動き出し、開発者が法的要件を満たす努力を複雑にする可能性のある、増え続ける立法の寄せ集め(パッチワーク)に貢献しています。*ニューヨーク・タイムズ*が報じたところによると、これら州は合わせて 1,500 件以上(ある集計による 集計)の法案を検討しているほか、若者によるチャットボットの利用を抑制するよう設計された 40 の州で既に施行されている 100 件以上の既存法(著作権のある素材に対する AI システムの学習に許可を要するものや、AI システムのセキュリティテストを義務付けるものなど)が存在します。
仕組み: カリフォルニア州知事のガビン・ニューサムは、トランプ政権による州ごとの AI 規制を阻止しようとする取り組みに対して最も目立つ反対者となっています。しかし、40 を超える州が現在、独自の法律を成立させる過程にあります。その中には以下が含まれます:
- カリフォルニア州。米国およびその先駆的な規制の指標となることが多いカリフォルニア州は、国内で最も包括的な AI 関連法を制定しています。3 月 30 日、ニューサム知事は、州政府が使用する AI ツールがプライバシーを保護し、市民権を支援し、バイアスを軽減することを義務付ける行政命令を発令しました。8 月から、大規模なテックプラットフォームおよび AI プロバイダーは、AI 生成出力に目に見えない透かし(watermark)を施す必要があります。これらの規定は、1 月に施行されたさまざまな法律に追加されるものです。例えば、高度な AI モデルの開発者は壊滅的なリスクを評価し、重大な安全インシデントを報告しなければなりません。大規模言語モデル(LLM: Large Language Model)プロバイダーは、チャットボットが自殺や未成年者との性的行為について議論することを防止し、AI と会話している際に定期的にユーザーに注意喚起する必要があります。
- コロラド州。2024 年、コロラド州は国内で最も厳格な規制の一部を含む包括的な AI 法を可決しました。7 月に施行予定のこの法律は、「高リスク AI システムの開発者および導入者」に対し、教育、雇用、金融、医療、住宅といった重要な分野で意思決定を行うシステムによるアルゴリズム差別から消費者を保護することを義務付けています。開発者はシステムの制限事項、トレーニングデータ、リスク軽減への取り組みを文書化しなければならず、モデルを導入する側は毎年その影響を評価し、AI が個人に影響を与える意思決定を行った際に消費者に警告する必要があります。しかし、企業やテック企業からの圧力により、一般会議(General Assembly)は年次影響評価の要件およびその他の負担を緩和することを検討しています。
- ミネソタ州。ミネソタ州は 2023 年初頭にディープフェイクによる選挙干渉を禁止する措置を早期に講じました。現在、立法府は、AI を使用して人々の写真から衣服を取り除いたり、個人の行動に基づいて価格を動的に設定したりすることを禁止する法案を検討しています。8 月には、健康保険会社が医師の審査なしに AI を用いて医療提供を拒否することを禁止する法律が施行されます。
- ニューヨーク州。この州は、ディープフェイクに対する早期保護から 2026 年のより広範な制限に至るまで、国内で最も厳格な AI 規制の一部を確立しています。2027 年 1 月からは、収益が 5 億ドルを超えるモデルメーカーは、ユーザーが生物兵器や自律型ハッキングツールを作成することをブロックするための厳格なプロトコルに従わなければなりません。これらの取り組みについては毎年監査し、インシデントを速やかに報告する必要があります。
- オハイオ州。3 月末に施行された法律により、許可なく他人の声や姿を複製して製品を販売したり、性的な画像を作成したりする目的での AI 使用が禁止されています。オハイオ州は現在、AI システムに配偶者、管理者、財産所有者としての役割において法的人格および法的権利を与えない法案を検討しています。また、競合他社間で小売価格や賃貸料の調整に AI を使用することを禁止する法案も検討中です。
- ユタ州。2026 年だけで、ユタ州立法府は同州の 2024 年人工知能政策法(Artificial Intelligence Policy Act)を精緻化する複数の法案を可決しました。例えば、今後数ヶ月以内に施行予定のある法案では、プラットフォーム企業が同意のない性的に露骨なディープフェイクを配布することを禁止しています。別の法案は、健康保険会社が医師の意見なしに AI を用いて医療提供を拒否することを禁止しています。同州では、規制当局の監督下で新技術をテストしている間、AI 企業から特定の規制からの一時的免除を申請することが認められています。
ニュースの背景: トランプ政権は、州ごとのバラバラな規制(patchwork)が米国の AI におけるリーダーシップを阻害する恐れが高まる中、国家レベルの規制を州法よりも推進し始めました。12 月、トランプ大統領は州レベルの立法を抑制することを意図した行政命令に署名しました。この命令は、イノベーションを阻害する法律や、政治的な偏向があると見なされる可能性のあるバイアス是正規制を対象としています。また、「過酷な」AI 法を制定または施行する州に対して連邦資金の供与を停止すると脅し、議会に対し州規制を阻止するよう促しています。3 月には、連邦立法のためのガイドラインが発表されました。このガイドラインは、子供たちの保護と、AI データセンターのエネルギー消費量の増加に伴う電気料金の値上げに対する統制を支持するものです。
なぜ重要なのか: AI をめぐる規制環境はますます複雑化しており、米国におけるコンプライアンスの潜在的な地雷原となり、世界中で焦点がぼやけ、矛盾した規制を生み出しています。ある特定の AI モデルは、コロラド州ではバイアス監査に合格し、カリフォルニア州では透かし埋め込みを提供し、ニューヨーク州では報告基準を満たす必要がある一方で、連邦政府はこれらの要件を無効化しようとしています。この管轄権をめぐる綱引きは、AI システムの構築コストを増大させ、新しいアプリケーションやサービスの展開における法的リスクを高め、連邦政府が過酷とみなす州の義務に準拠するために政府資金が差し止められる可能性さえ生み出します。
私たちが考えていること: 一部の現在の州レベルでの義務は妥当です。例えば、ユーザーは AI 企業がプライバシーを保護すると信頼できるべきであり、子供たちは大人向けに生成・利用される AI の粗悪なコンテンツから守られるべきです。しかし、そのような要件は国レベルで課されるべきです。私たちは議会に対し、より一貫性があり安定した規制環境の構築を呼びかけます。
多様な人間集団のシミュレーション
あなたの製品やサービスに対する一般大衆の反応を理解したい場合、大規模言語モデル(LLM)は、機能、特徴、プロモーション、または価格に関する質問に回答するユーザーをシミュレートするために使用できます。しかし、LLM は人間が示すような多様なバリエーションで応答するわけではありません。研究者たちは、LLM にカスタマイズ可能な多様な態度を持つペルソナ(役割)を演じさせる手法を開発しました。
最新動向: Google の Davide Paglieri 氏、Logan Cross 氏らによる研究チームが Persona Generators を提案しました。彼らのアプローチは、地図全体をカバーする 25 のペルソナに対するプロンプト(指示)を LLM に作成させるコードを生成します。
重要な洞察: LLM に人間のペルソナを演じさせることは、通常、効果的なプロンプト(例えば、「今日政治の文脈で答えてください。あなたは民主党員だと考えています……」など)を作成する問題です。しかし、このアプローチは、LLM が特定の人口統計学的特性を採用するように明示的に指示された場合でも、人間集団が示すような範囲を反映しない平均的な回答を引き出す傾向があります。代替案として、モデルにペルソナプロンプトをプログラムで変更させ、特定の意見・態度・懸念の範囲をカバーする出力を生み出すまで反復させる方法があります。ペルソナ人口の範囲(具体的には、同意から不同意までの度合いでランク付けされた態度)を定義するガイドラインに基づき、進化アルゴリズムを用いて、モデルがあらゆる種類の回答を引き出す一連のプロンプトを生成するように誘導することができます。
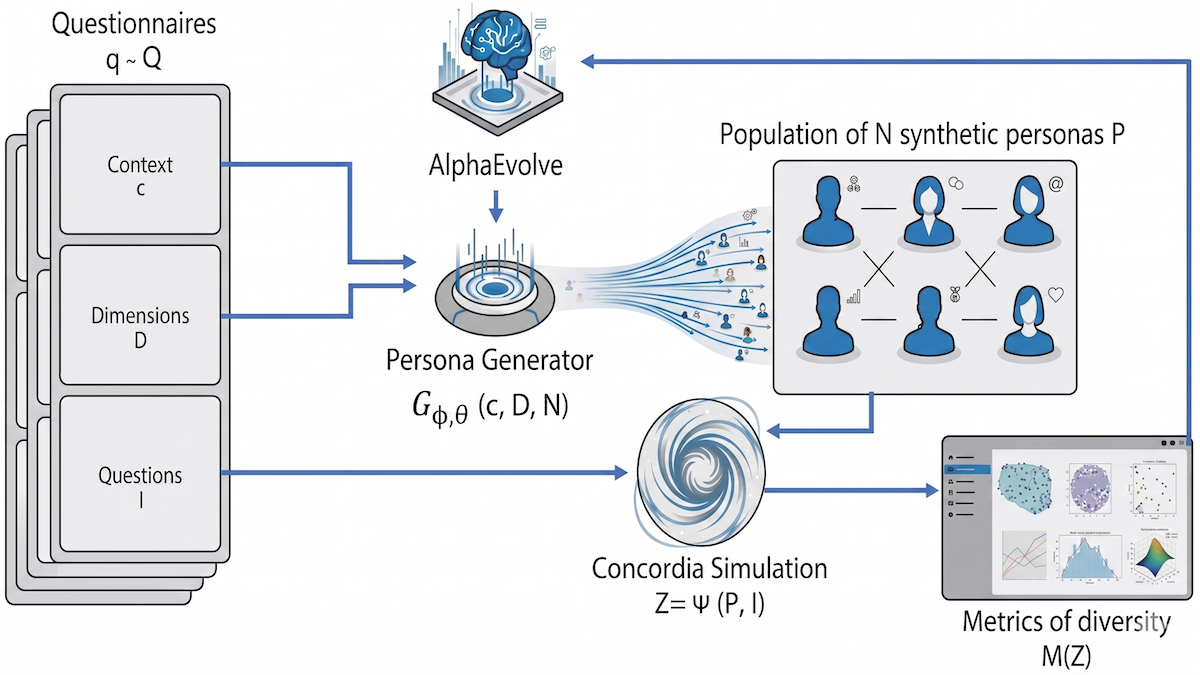
仕組み: 著者らは、進化的アプローチである AlphaEvolve を用いて、(i) ペルソナ向けの 25 のプロンプトを生成し、(ii) 一連の生成されたアンケートへの回答に基づき、それらの態度の多様性を最大化するコードを作成しました。
- 著者らはまず、Gemini 2.5 Pro を用いて、医療、金融リテラシー、陰謀論など多様な主題に関する 30 件のアンケートを生成しました。各アンケートには、トピックの説明という文脈(コンテキスト)、リスク許容度や制度への信頼といった「多様性の軸」のセット、そしてこれらの軸に関連し、1(強く同意)から 5(強く不同意)までのスケールで回答する質問が含まれていました。
- 著者らはコードを作成しました(当初は著者らが作成し、その後 AlphaEvolve によって反復的に更新されました)。このコードにより、各アンケートに対して 25 件のペルソナプロンプトを生成します。
- ペルソナの回答の生産を自動化するため、著者らはエージェントベースシミュレーション構築用のライブラリである Concordia を用いて Gemma 3-27B-IT にプロンプトを送信しました。この大規模言語モデル(LLM)は各ペルソナを順に引き受け、対応するアンケートに回答します。各ペルソナについて、その回答をベクトルに変換しました。
- 各アンケートに回答したペルソナ間の多様性を評価するため、任意の 2 つのベクトルの平均距離や、ペルソナ集団が可能なすべての回答をどの程度カバーしているかといった 6 つの指標を計算しました。
- AlphaEvolve はコードの 10 の異なるバージョンで並列に動作し、反復的に更新して全ペルソナにわたる多様性指標を最大化しました。500 回の反復後、著者らはすべての多様性指標の平均を最大化するコードを選択しました。
- 推論時には、文脈と多様性の軸のセットが与えられると、システムは 25 件の多様なペルソナを作成します。
結果: 新しい文脈と多様性の軸が与えられた場合、生成されたペルソナは、米国人口統計に基づいた大規模なペルソナプロンプトデータセットである Nemotron Personas や、幼年期から成年期までの生成された記憶に基づく Concordia メモリジェネレーター が生成したペルソナプロンプトの多様性指標を、一貫して上回りました。テスト用アンケートセットが与えられた場合、著者らのペルソナは可能な回答の 82 パーセントをカバーしましたが、Nemotron Personas は 76 パーセント、Concordia メモリジェネレーターは 46 パーセントでした。
なぜ重要なのか: 聴衆の拡大を目指す組織は、世論を広く反映する合成ペルソナから恩恵を受けることができます。また、実世界の聴衆に合わせるために合成ペルソナを作成した組織は、より多様な層からの洞察を得ることができます。この研究は、最も確率の高い出力を生み出しやすいトレーニングデータへの一致という目標から、すべての望ましい可能性を網羅するという目標へとシフトするものです。個々のペルソナではなく、ペルソナ生成器の最適化を行うことで、より広範なユーザー行動の可能性を表現できるようになります。
私たちが考えていること: 合成ペルソナは、LLM(大規模言語モデル)へのプロンプトで容易に構築できる状況において何を構築するかを決めるという製品管理のボトルネックを乗り越えるための魅力的な可能性を提供します。
原文を表示
Dear friends,
AI-native software engineering teams operate very differently than traditional teams. The obvious difference is that AI-native teams use coding agents to build products much faster, but this leads to many other changes in how we operate. For example, some great engineers now play broader roles than just writing code. They are partly product managers, designers, sometimes marketers. Further, small teams who work in the same office, where they can communicate face-to-face, can move incredibly quickly.
Because we can now build fast, a greater fraction of time must be spent deciding what to build. To deal with this project-management bottleneck, some teams are pushing engineer:product manager (PM) some teams are pushing engineer:product manager (PM) ratios downward from, say, 8:1 to as low as 1:1. But we can do even better: If we have one PM who decides what to build and one engineer who builds it, the communication between them becomes a bottleneck. This is why the fastest-moving teams I see tend to have engineers who know how to do some product work (and, optionally, some PMs who know how to do some engineering work). When an engineer understands users and can make decisions on what to build and build it directly, they can execute incredibly quickly.
I’ve seen engineers successfully expand their roles to including making product decisions, and PMs expand their roles to building software. The tech industry has more engineers than PMs, but both are promising paths. If you are an engineer, you’ll find it useful to learn some product management skills, and if you’re a PM, please learn to build!
Looking beyond the product-management bottleneck, I also see bottlenecks in design, marketing, legal compliance, and much more. When we speed up coding 10x or 100x, everything else becomes slow in comparison. For example, some of my teams have built great features so quickly that the marketing organization was left scrambling to figure out how to communicate them to users — a marketing bottleneck. Or when a team can build software in a day that the legal department needs a week to review, that’s a legal compliance bottleneck. In this way, agentic coding isn’t just changing the workflow of software engineering, it’s also changing all the teams around it.
When smaller, AI-enabled teams can get more done, generalists excel. Traditional companies need to pull together people from many specialties — engineering, product management, design, marketing, legal, etc. — to execute projects and create value. This has resulted in large teams of specialists who work together. But if a team of 2 persons is to get work done that require 5 different specialities, then some of those individuals must play roles outside a single speciality. In some small teams, individuals do have deep specializations. For example, one might be a great engineer and another a great PM. But they also understand the other key functions needed to move a project forward, and can jump into thinking through other kinds of problems as needed. Of course, proficiency with AI tools is a big help, since it helps us to think through problems that involve different roles.
Even in a two-person team, to move fast, communication bottlenecks also must be minimized. This is why I value teams that work in the same location. Remote teams can perform well too, but the highest speed is achieved by having everyone in the room, able to communicate instantaneously to solve problems.
This letter focuses on AI-native teams with around 2-10 persons, but not everything can be done by a small team. I'll address the coordination of larger teams in the future.
I realize these shifts to job roles are tough to navigate for many people. At the same time, I am encouraged that individuals and small teams who are willing to learn the relevant skills are now able to get far more done than was possible before. This is the golden age of learning and building!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI
In “Spec-Driven Development,” you will learn a disciplined workflow for working with coding agents. Write specs, guide implementation step by step, and stay in control of what you build! Join in for free
News
Life After Llama
Meta pivoted from its open-weights strategy to deliver a closed alternative.
What’s new: Meta introduced its first AI model in a year and the first product of its nine-month-old Superintelligence Labs. Muse Spark is a natively multimodal reasoning model with support for tool use and multi-agent orchestration. It leads in some health and multimodal benchmarks but falls short in coding and agentic work, which Meta frames as validating an architectural redesign on which the company plans to build larger models.
- Input/output: Text, image, speech in (up to 262,000 tokens), text out
- Performance: Fourth place on the Artificial Analysis Intelligence Index
- Availability: Free via meta.ai and Meta AI app; coming to WhatsApp, Instagram, Facebook, Messenger, and Ray-Ban Meta AI glasses; API preview for selected partners
- Features: Three reasoning modes (instant, thinking, contemplating), shopping mode
- Undisclosed: Parameter count, architecture, training data and methods, output size limit
How it works: Meta disclosed limited technical details about Muse Spark but highlighted gains in training efficiency and multi-agent orchestration plus a domain-specific investment in health.
- The company reworked its pretraining approach, model architecture, optimization, and data curation. Meta says Muse Spark matches Llama 4 Maverick’s capabilities with over an order of magnitude less processing devoted to training.
- Post-training involved reinforcement learning in which the team penalized the model for using excessive reasoning tokens, a process the team calls thought compression. Under this penalty, the model first improved by reasoning longer, then learned to compress its reasoning, and then extended its reasoning for further improvement.
- Rather than processing a single chain of thought, contemplating mode launches multiple agents that propose solutions, refine them, and aggregate the results in parallel. Meta says this achieves better performance while incurring comparable latency.
- To improve health reasoning, Meta enlisted more than 1,000 physicians to help curate training data aimed at producing more accurate and thorough health responses.
Results: Muse Spark’s benchmark performance is generally competitive and notably token-efficient. Meta acknowledged that it shows gaps in coding and agentic performance.
- On the Artificial Analysis Intelligence Index, a composite of 10 benchmarks of economically useful tasks, Muse Spark set to reasoning (52) places fourth overall behind the tied-for-third Gemini 3.1 Pro Preview set to high reasoning and GPT-5.4 set to xhigh reasoning (both 57), and Claude Opus 4.6 set to max reasoning (53). Muse Spark used around 59 million tokens to complete the index, compared to roughly 158 million tokens for Claude Opus 4.6 and 116 million tokens for GPT-5.4.
- Muse Spark earns top marks in at least one multimodal benchmark. On CharXiv Reasoning (understanding charts and figures), Muse Spark (86.4 percent) outperformed GPT-5.4 (82.8 percent) and Gemini 3.1 Pro (80.2 percent), according to Meta. On MMMU Pro (solving multidisciplinary visual problems), Muse Spark (81 percent) placed second behind Gemini 3.1 Pro (82 percent), according to Artificial Analysis.
- On Artificial Analysis’ Coding Index, a weighted average of coding benchmarks, Muse Spark (47) fell behind GPT-5.4 (57), Gemini 3.1 Pro Preview (56), and Claude Sonnet 4.6 set to max reasoning (51).
- Artificial Analysis independently measured Muse Spark in Thinking mode at 39.9 percent on Humanity’s Last Exam, trailing Gemini 3.1 Pro Preview (44.7 percent) and GPT-5.4 (41.6 percent). However, Meta reports 58 percent when Muse Spark used contemplating mode.
- In Meta’s tests, Muse Spark outperformed all models on HealthBench Hard, a subset of OpenAI’s health benchmark, at 42.8 percent, ahead of second-best GPT-5.4 (40.1 percent). Muse Spark also led DeepSearchQA, an agentic browsing evaluation, at 74.8 percent, ahead of Claude Opus 4.6 Max (73.7 percent).
Behind the news: Muse Spark is the Meta’s first new model since it reorganized its AI labs after critics alleged that the training data for Llama 4 been contaminated with benchmark answers. In June 2025, Meta spent $14.3 billion for a 49 percent stake in Scale AI, brought in cofounder Alexandr Wang as chief AI officer, and launched a hiring spree with pay packages worth hundreds of millions of dollars. The proprietary release has raised concerns among developers, many of whom have built projects on open-weights Llama models.
Why it matters: Meta is investing in the capabilities that matter most for its product ambitions: multimodal perception for billions of camera-equipped users, health reasoning for one of the most common categories of AI queries, and multi-agent coordination for multi-step tasks. With a private API preview in progress, it’s positioning itself to compete for business customers alongside OpenAI, Google, and Anthropic. However, its pivot away from being the leading U.S. champion of open weights is a significant loss for the developer community.
We’re thinking: Muse Spark’s contemplating mode and Kimi K2.5’s Agent Swarm point to an emerging pattern: More labs are scaling performance by training models to orchestrate multiple agents at inference time rather than training ever-larger single models.
Generative AI has proven that it can produce text, images, audio, video, and code. The world’s most valuable pharmaceutical company is betting billions that it can produce drugs as well.
What’s new: Pharma giant Eli Lilly agreed to give as much as $2.75 billion to Insilico Medicine, a Hong Kong-based biotechnology company that applies generative AI across its drug-discovery pipeline. Initially, Lilly will pay $115 million for exclusive rights to develop and sell undisclosed drugs that have not yet been tested in humans, while further payments will be tied to developmental, regulatory, and commercial milestones, *Fierce Biotech* reported. This is the third agreement between the companies following an AI software license in 2023 and a $100 million research collaboration in November 2025.
AI drug-discovery: Founded in 2014, Insilico has used AI to develop 28 candidate drugs, roughly half of which are in clinical trials. The most advanced one, Rentosertib, targets idiopathic pulmonary fibrosis (IPF), a disease in which scarring progressively reduces lung function. A Phase 2a trial (an early, small-scale test of efficacy) showed positive results. A second drug, Garutadustat, which is intended to treat inflammatory bowel disease, entered Phase 2a in January 2026.
How it works: After choosing a disease, Insilico applies proprietary generative models to two stages of drug discovery: identifying which protein to target and designing a molecule to act on that protein.
- To find targets, Insilico uses a tool called PandaOmics to analyze biological datasets, published research, patents, clinical trials, and grant applications. Deep learning models rank candidate targets by relevance to a disease, suitability as drug targets, and novelty. For IPF, PandaOmics identified TNIK, a protein involved in the scarring that characterizes IPF and related diseases, as the top candidate. No one had previously tried to treat IPF by blocking TNIK.
- To design a molecule to block TNIK, the team used Chemistry42. Roughly 30 generative models ran in parallel to produce candidate molecular structures, each one optimized for binding strength, toxicity, solubility, and other properties. Scientists evaluated and refined the output over multiple rounds. The process yielded a lead molecule after Insilico synthesized and tested fewer than 80 compounds. In conventional drug discovery, teams often screen 200,000 to 1 million existing compounds before synthesizing and testing hundreds of candidates.
- The time from identifying targets to synthesizing molecules that are ready for preclinical safety testing took roughly 18 months, compared to a typical five to six years. That pace held steady across more than 20 Insilico programs between 2021 and 2024, each of which synthesized and tested around 60 to 200 molecules to find one preclinical candidate.
Behind the news: Developing a new drug typically takes 10 to 15 years and costs more than $2 billion, and roughly 86 percent of candidates fail to reach approval. A growing number of drug developers apply AI to accelerate the process. A peer-reviewed analysis catalogued 173 AI-enabled drug programs across clinical stages as of mid-2025. Nonetheless, no AI-discovered drug has received regulatory approval. Of the drug candidates that reach Phase 2, 70 percent fail to reach the next phase, including AI-designed drugs from BenevolentAI and Recursion Pharmaceuticals.
Why it matters: Insilico’s pipeline suggests generative AI can tackle one of the hardest problems in science: finding a molecule that binds to a particular protein, is absorbed by the body, isn’t toxic, and helps patients. In Rentosertib’s Phase 2a trial, participants who took the highest dose gained an average of 98.4 milliliters in forced vital capacity (a measure of lung function), while those who took a placebo declined by 20.3 milliliters. That is early but concrete evidence that AI-generated drugs can help patients.
We’re thinking: AI is accelerating drug development, but it remains to be seen whether those accelerated compounds will pass clinical trials at a higher rate than those developed in traditional ways.
US States Move Forward With AI Laws
U.S. states are continuing to enact laws that regulate AI, despite President Trump’s efforts to discourage state-by-state legislation in favor of national laws.
What’s new: Many states have moved to regulate AI this year, contributing to a growing patchwork of legislation that stands to complicate developers’ efforts to meet legal requirements. Collectively, the states are considering numerous bills — more than 1,500, by one tally — in addition to more than 100 existing laws enacted by 40 states that are designed to discourage use of chatbots by young people, require permission to train AI systems on copyrighted material, or require security testing of AI systems, *The New York Times* reported.
How it works: California governor Gavin Newsom has been the most visible opponent of the Trump Administration’s effort to discourage state-by-state regulation of AI. But more than 40 states are in the process of passing their own laws. Among them are:
- California. Often a bellwether for regulation in the U.S. and beyond, California has established the nation’s most comprehensive AI laws. On March 30, Governor Newsom issued an executive order requiring that AI tools used by the state protect privacy, support civil rights, and mitigate bias. Starting in August, large tech platforms and AI providers must apply an invisible watermark to AI-generated output. These provisions add to a variety of laws that took effect in January. For instance, developers of advanced AI models must assess catastrophic risks and report serious safety incidents. LLM providers must prevent chatbots from discussing self-harm or sex with minors and remind users periodically when they are chatting with AI.
- Colorado. In 2024, Colorado passed a sweeping AI law with some of the most stringent regulations in the county. Scheduled to go into effect in July, it requires “developers and deployers of high-risk AI systems” to protect consumers from algorithmic discrimination by systems that are designed to make decisions in high-stakes fields such as education, employment, finance, healthcare, and housing. Developers must document system limitations, training data, and efforts to mitigate risks, while those who deploy models must assess their impact annually and alert consumers when AI makes a decision that affects them. However, pressure from businesses and tech companies has prompted the General Assembly to consider relaxing a requirement for annual impact assessments and other burdens.
- Minnesota. Minnesota moved early in 2023 by prohibiting deepfake election interference. Now the legislature is considering a bill that would ban use of AI to remove clothing from photos of people or set prices dynamically based on personal behavior. In August, a law will take effect that prohibits health insurance companies from using AI to deny care without a review by a relevant doctor.
- New York. This state has established some of the nation’s most stringent AI regulations, from early protections against deepfakes to broader restrictions in 2026. Starting in January 2027, model makers that have revenue of over $500 million must observe strict protocols to block users from creating bioweapons or autonomous hacking tools. They must audit these efforts annually and report incidents promptly.
- Ohio. A law that took effect in late March prohibits use of AI to replicate a person’s voice or likeness to sell a product or produce intimate images without permission. Ohio is considering a bill that would deny AI systems legal personhood and legal rights in the roles of spouse, manager, or property owner. It is also considering a ban on using AI to coordinate retail and rental prices among competitors.
- Utah. In 2026 alone, the Utah legislature passed several bills that refined the state’s 2024 Artificial Intelligence Policy Act. For instance, a bill that’s scheduled to take effect in coming months prohibits platform companies from distributing nonconsensual, sexually explicit deepfakes. Another prohibits health insurers from using AI to deny care without a doctor’s input. The state lets AI companies apply for temporary relief from certain regulations while they test new technology under regulatory supervision.
Behind the news: The Trump Administration started promoting national regulations over state laws as worries grew that a state-by-state patchwork could impede U.S. leadership in AI. In December, President Trump signed an executive order designed to discourage state-level legislation. The order targets laws that would stifle innovation as well as anti-bias regulations that could be perceived to have a political slant. It threatens to withhold federal funds from states that pass or enforce “onerous” AI laws and urges Congress to block state regulations. In March, it followed up with guidelines for federal legislation. The guidelines support protections for children and controls on electricity price hikes driven by AI data centers’ increasing consumption of energy.
Why it matters: An increasingly complex regulatory landscape around AI creates a potential minefield for compliance in the U.S. and contributes to unfocused, contradictory regulation worldwide. A given AI model may be required to pass a bias audit in Colorado, provide watermarking in California, and meet reporting thresholds in New York — all while the federal government moves to preempt these requirements. This jurisdictional tug-of-war increases the cost of building AI systems, adds to the legal risk of deploying new applications and services, and raises the possibility that government funding may be withheld for complying with state mandates the federal government considers onerous.
We’re thinking: Some current state-level mandates are sensible. Users should be able to rely on AI companies to preserve their privacy, for instance, and children should be protected from AI slop generated by and for adults. But such requirements should be imposed at the national level. We call on Congress to build a more cohesive, stable regulatory environment.
Simulating Diverse Human Cohorts
If you want to understand how the public will respond to your offerings, large language models can simulate users who answer questions about capabilities, features, promotions, or prices. However, LLMs don't respond with the range of variations that humans do. Researchers developed a method that prompts LLMs to take on personas with a customizable variety of attitudes.
What’s new: Davide Paglieri, Logan Cross, and colleagues at Google proposed Persona Generators. Their approach produces code that prompts an LLM to compose prompts for 25 personas that cover the map.
Key insight: Making an LLM take on a human persona typically is a matter of composing an effective prompt (for instance, “Answer the following question as if in politics today, you considered yourself a Democrat. . . .”). However, this approach tends to elicit average responses that don’t reflect the range that a human population would provide — even if the prompt explicitly directs the LLM to adopt specific demographic characteristics. An alternative is to direct a model to modify persona prompts programmatically until they produce output that covers a specific range of opinions, attitudes, or concerns. Given guidelines that define the scope of the persona population (specifically attitudes ranked by degrees of agreement to disagreement), an evolutionary algorithm can push the model to produce a set of prompts that elicit the full range of responses.
How it works: The authors used the evolutionary method AlphaEvolve to generate code that (i) generated 25 prompts for personas and (ii) maximized the diversity of their attitudes based on their answers to a set of generated questionnaires.
- The authors started by using Gemini 2.5 Pro to generate 30 questionnaires on a variety of subject matter such as health care, financial literacy, and conspiracy theories. Each questionnaire included a context (description of the topic), a set of “diversity axes" (such as tolerance of risk or trust in institutions), and questions related to the axes to be answered on a scale between 1 (strongly agree) to 5 (strongly disagree).
- They created code (initially written by the authors, then updated iteratively by AlphaEvolve) to produce 25 persona prompts per questionnaire.
- To automate production of the personas’ responses, the authors used Concordia, a library for building agent-based simulations, to prompt Gemma 3-27B-IT. The LLM adopted each persona in turn and responded to the corresponding questionnaire. For each persona, they converted its answers into a vector.
- To evaluate diversity among the personas that answered each questionnaire, they computed six metrics, such as average distance between any two vectors and the degree to which the population of personas covered all possible responses.
- AlphaEvolve worked in parallel on 10 different versions of the code, iteratively updating them to maximize the diversity metrics across all the personas. After 500 iterations, the authors chose the code that maximized the average of all diversity metrics.
- At inference, given a context and a set of diversity axes, the system created 25 diverse personas.
Results: Given a fresh context and diversity axes, the resulting personas consistently exceeded the diversity metrics of Nemotron Personas, a large dataset of persona prompts that are based on U.S. demographic statistics, and persona prompts produced by a Concordia memory generator based on generated memories from childhood to adulthood. Given a set of test questionnaires, the authors’ personas covered 82 percent of possible responses, while Nemotron Personas covered 76 percent and Concordia memory generator covered 46 percent.
Why it matters: Organizations that aim to expand their audiences can benefit from synthetic personas that broadly reflect public sentiment, and those that create synthetic personas to match their real-world audiences can gain insights from a more diverse crowd. This work shifts the objective from matching training data (which tends to generate the most probable outputs and not the outliers) to covering all desired possibilities. Optimizing the persona generator, rather than individual personas, unlocks a broader representation of likely user behavior.
We’re thinking: Synthetic personas offer an intriguing possibility for navigating the product-management bottleneck, the difficulty of deciding what to build when you can build easily by prompting an LLM.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み