"アイドル"状態ではない:Linux カーネルの最適化が QUIC のバグに
Cloudflare は、Linux カーネルの CUBIC 実装最適化が QUIC プロトコルの quiche 実装において重大なバグを引き起こし、輻輳制御ウィンドウが最小値から回復不能になる事象を特定し、解決した。
キーポイント
CUBIC と QUIC の連携におけるバグの発生源
RFC 9438 に基づく Linux カーネルの CUBIC 実装最適化(app-limited exclusion)が、Cloudflare のオープンソース QUIC 実装である quiche に移植された際、予期せぬ動作を引き起こした。
深刻な症状:輻輳ウィンドウの永久固定
接続初期に重度のパケットロスが発生すると、CUBIC の輻輳ウィンドウ(cwnd)が最小値に固定され、その後回復できなくなる現象が発生し、テストで 61% の確率で失敗した。
原因分析と解決策
TCP と QUIC の実装間の微妙な差異が原因であったが、Cloudflare はほぼ一行のコード修正によってこの循環的なバグを解消し、安定性を回復させた。
Congestion Collapse Recovery Failure
CUBIC アルゴリズムは通常、パケットロス停止後に輻輳ウィンドウを回復させるが、このバグでは最小値に固定され成長しない。
Invisible Bugs in Steady-State Tests
通常のテストは定常状態や成長フェーズを検証するため、最小 cwnd での回復失敗という稀なレジームのバグは見逃されやすい。
CUBIC の異常な振動と cwnd の固定
分析により、CUBIC アルゴリズムが約 6.7 秒間で 999 回の状態遷移を繰り返す急速な振動を起こし、cwnd が最小値(2700 バイト)にロックされていることが判明した。
ACK クロックとの同期による誤判定
約 14ms の遷移周期は RTT と一致しており、クライアントからの ACK がサーバー側の CUBIC 状態マシンをトリガーし、bytes_in_flight がゼロになるたびに誤って回復フェーズへ移行している。
影響分析・編集コメントを表示
影響分析
この事象は、主要なインターネットインフラを支えるプロトコル実装(Linux カーネルと QUIC)間の微妙な相互作用が、大規模なサービス障害やパフォーマンス低下を招くリスクを浮き彫りにしました。特に、標準化された最適化が異なる環境で適用される際のテスト不足の危険性を示しており、開発者にとって相互運用性の検証の重要性を再認識させる内容です。
編集コメント
Linux カーネルの標準的な最適化が、特定の QUIC 実装において重大なバグを引き起こした事例は、ネットワークスタックの複雑さと相互依存性を如実に示しています。Cloudflare の迅速な対応と分析は、インフラエンジニアにとって非常に参考になるケーススタディです。
RFC 9438 で標準化された CUBIC は Linux のデフォルトの輻輳制御器であり、その結果、パブリックインターネット上のほとんどの TCP および QUIC 接続が利用可能な帯域幅をプローブし、損失を検知した際にバックオフし、その後回復する方法を支配しています。Cloudflare では、QUIC のオープンソース実装である quiche が CUBIC をデフォルトの輻輳制御器として使用しており、这意味着このコードは私たちが提供するトラフィックの大きな割合においてクリティカルパス上に存在します。
本稿では、CUBIC の輻輳ウィンドウ(cwnd)が最小値に永久に固定され、輻輳崩壊イベントから回復しないというバグの物語を語ります。
この物語は、RFC 9438 §4.2-12 で記述されているアプリケーション制限除外(app-limited exclusion)に合わせて CUBIC を整列させることを目的とした Linux カーネルの変更から始まります。これは TCP における実際の問題に対する修正ですが、これを QUIC の実装に移植したところ、quiche で予期せぬ動作が表面化しました。結末はハッピーエンドで、サイクルを断ち切るエレガントな(ほぼ)一行の修正です。
CUBIC のロジックを一言で言えば
コアの問題に深入りする前に、CCAs(輻輳制御アルゴリズム)に関する簡単な復習が状況を理解する助けになるかもしれません。
CCA が調整する中心的なノブは、輻輳ウィンドウ(cwnd)です。これは、任意の瞬間に転送中(送信済みだがまだ確認されていない)となるバイト数の送信側における上限を指します。cwnd を大きくすると、1 ラウンドトリップあたりにより多くのデータを転送できるようになります。逆に cwnd を小さくすると、データ転送が制限されます。損失検知型 CCA のすべて、CUBIC も含め、最終的にはネットワークが健全なときに cwnd をどのように増やすか、健全でないときにどのように減らすかというポリシーです。
本質的に、CCA はネットワークの「利用可能な帯域幅」を推定することでデータ転送を最大化することを目指します。なぜなら、誰も 1 Gbps の契約料金を支払いながらその一部しか使用したくないからです。CUBIC が属する損失検知型アルゴリズムのファミリーは、以下の基本的な前提に基づいて動作します。(1) パケットロスが発生しない場合は送信レートを上げる(つまり帯域幅利用率を高める)、(2) ロスが発生した場合、ネットワークの容量を超えたとみなし、送信側はバックオフする(つまり帯域幅利用率を下げる)。
 image
image
このロジックは、長年にわたり再検討されてきたいくつかの仮定に基づいています。ただし、その議論については別の機会に譲ります。
症状:61% の確率で失敗するテスト
私たちの調査は、イングレスプロキシの統合テストパイプラインにおける予期せぬ障害の報告から始まりました。この不安定な動作は、接続の初期段階で大量のパケットロスが発生するシナリオにおいて CUBIC が評価されたテストで現れました。
輻輳崩壊後の回復は稀な状態ですが、まさに輻輳制御アルゴリズムが存在して対処すべき領域です。ほとんどの輻輳制御テストは、アルゴリズムの定常状態と成長フェーズを扱いますが、接続が極限まで押し下げられた後の最小 cwnd(ウィンドウサイズ)での挙動を検証するものは極めて少ないです。この状態空間の隅にあるバグはスループットダッシュボードでは見えず、静的レビューでも検出できず、CCA(輻輳制御アルゴリズム)を意図的にその領域に駆動し、そこから回復できるかどうかを観察したときに初めて表面化します — これがまさに今回のテストが行ったことです。
シミュレーションされたテスト設定には以下の詳細が含まれます:

ローカル(localhost)で実行される Quiche HTTP/3 クライアントとサーバー
RTT = 10ms(設定ファイルで指定)
HTTP/3 を介した 10 MB ファイルのダウンロード
CUBIC 輻輳制御の使用
最初の 2 秒間に 30% のランダムなパケットロスを注入
2 秒後、ロスが完全に停止
このテストにはダウンロード完了のための寛容な 10 秒間のタイムアウトが設定されており、通常は 4〜5 秒で完了するはずですが、実際にはそうなりません。
期待される動作は単純明快です:CUBIC は損失フェーズ中にいくつかの打撃を受け、輻輳ウィンドウを縮小し、損失が止まれば着実に増加させ、タイムアウト内で十分にダウンロードを完了させるはずです。しかし、私たちは 100 回の反復テストで複数のケースを観測しました:約 60% のテストでは、寛容な 10 秒のタイムアウト内にダウンロードを完了できませんでした。
異常現象:損失ゼロで 999 回の状態遷移
輻輳制御器内部で何が起きているかを理解するため、quiche の qlog 出力にパケット損失イベントを計測し、可視化を行いました:
 image
image
失敗したテストの接続概要。T=2 秒以降、パケット損失は完全に停止しますが、cwnd(輻輳ウィンドウ)は最小値に固定されたままとなり、輻輳回避状態と回復状態が約 14 ミリ秒ごとに振動し続けています。
2 秒(2000 ミリ秒)の時点以降、パケット損失は完全に停止します。しかし、飛行中のバイト数は横ばいのままであり、これは CUBIC アルゴリズムのコアロジックと矛盾しています:損失がない場合は、より多くのガス(私たちの世界ではより多くのバイト)を投入してスロットルを増やすべきです。これにより疑問が生じます:ネットワークがもはやパケットをドロップしていないのに、なぜ輻輳ウィンドウが増大しないのでしょうか?
その領域にズームインして分析すると、CUBIC が輻輳回避状態(運用レジームフェーズ)と回復状態(パケット損失回復状態)の間で急速な振動を起こすことが示されました。これはプロットでは拡張された回復フェーズとして描かれています。約 6.7 秒間に 999 回の遷移が発生しており、これは約 14ms に一度の割合です。これは接続の RTT(10ms)と疑わしくも近い値です。この期間全体を通じて、cwnd は最小フロアである 2700 バイト、つまり 2 つのフルサイズのパケットに固定されています。
明らかに CUBIC のロジック内の何かが接続の状態を誤解釈しています。鍵となる手がかりは振動周期で、約 14ms という値が RTT と一致します。回復と回避の切り替えを引き起こしているものは、ラウンドトリップごとに一度、つまり接続の ACK クロックと同期して発生しています。これはクライアントからの各ラウンドトリップの ACK がサーバーの次の送信をトリガーする自己クロッキングリズムです。今回はダウンロード(サーバーからクライアント)であるため、問題となる ACK はクライアントからサーバーへ移動し、CUBIC の状態機械はサーバー側で動作します。これらの ACK が入力されるたびに bytes_in_flight がゼロになり、サーバーが次の 2 パケットバーストを送信しますが、これがバグを引き起こす原因となります。
この挙動が CUBIC に固有であることを確認するため、同じテストを Reno でも実行しました。Reno は損失ベースのファミリーのもう一つのメンバーですが、成長率が異なります。結果は決定的で、100% の合格率を示し、Reno は損失フェーズ後にきれいに回復したことがわかりました。これにより、この問題は CUBIC に起因するバグであることが明らかになりました。

Reno は T=2 秒で損失フェーズが終了した後、きれいに回復し、約 5 秒までにダウンロードを完了します
根本原因の追跡
損失ベースアルゴリズムには「ガス(加速)」と「ブレーキ(減速)」という二つのペダルがあり、その加速方法に違いがあります。もちろん、CUBIC はいくつかの追加機能も備えています。ここでは特に bytes_in_flight == 0 の状況に焦点を当てます。
IDLE 状態後の TCP CUBIC (Linux, 2017)
このバグを理解するには、まずそのバグの元となった最適化について理解する必要があります。2017 年、Linux カーネルの CUBIC 実装に問題が発見されました。コミットメッセージには以下のように説明されています。
エポックは初期設定時および損失が発生した時のみ更新またはリセットされます。アプリケーションがアイドル状態になった後、現在時刻とエポック開始時点との差分「t」は任意に大きくなり得ます。同様に bic_target も同様です。その結果、傾斜(ca->cnt の逆数)は非常に大きくなり、最終的に ca->cnt は遅延 ACK のスロースタート動作を確保するために 2 に下限値が設定されます。
これは slow_start_after_idle が無効化されている場合に特に顕著に現れ、数秒間のアイドル時間の後に危険な cwnd の膨張(1.5 倍 RTT)が発生します。
エポックは、CUBIC が成長曲線の基準点として使用する参照タイムスタンプです。W_cubic(delta_t) は delta_t = now - epoch_start によってパラメータ化されており、CUBIC が成長関数を再開始するたびに(特に損失イベントにより cwnd が減少した直後など)、エポックはリセットされます。リセット間隔中、delta_t は壁時計時間とともに単調に増加します。
アプリケーションが一時的にアイドル状態(送信停止)となり、その後再開した場合、CUBIC の成長関数 W_cubic(delta_t) は、図に示すように delta_t を now - epoch_start として計算します。エポックはアイドル期間中に更新されていないため、delta_t は非常に大きな値となり、結果として膨大なターゲットウィンドウが生成されます。これにより、CUBIC は直ちに cwnd を不合理な値まで膨張させようとしてしまいます。
 image
image
Jana Iyengar による初期の修正は、アプリケーションが送信を再開した際に epoch_start をリセットするというものでした。しかし Neal Cardwell はこのアプローチに欠陥があることを指摘しました。
…それは CUBIC アルゴリズムに対して、cwnd が現在ある地点から再び急激に上昇するように曲線を再計算させることになります(これは損失直後の CUBIC の動作と同じです)。理想的には、cwnd の成長曲線の形状は同じままとし、アイドル期間の長さだけ時間軸上で後方にシフトさせた形が望ましいのです。
Eric Dumazet、Yuchung Cheng、Neal Cardwell が執筆したエレガントな解決策は、エポックをリセットするのではなく、アイドル期間分だけ前方へシフトすることでした。これにより CUBIC 成長曲線の形状が保たれ、単に時間軸上でスライドさせることで、アルゴリズムが中断された地点から再開できるようになります。
quiche への移植(2020 年)
CUBIC が quiche に初めて実装された際、このアイドル期間調整も移植されました。しかし、ユーザー空間で動作する QUIC は、TCP のカーネルレベルの CA_EVENT_TX_START コールバックを持っていません。代わりに、quiche の実装では on_packet_sent() 内でアイドル状態をチェックします。
// cubic.rs — on_packet_sent()(簡略化版)
/// パケット送信時の状態を更新する。
fn on_packet_sent(&mut self, bytes_in_flight: usize, now: Instant, ...) {
// 送信バーストが再開された場合(つまり、この送信前に bytes_in_flight がゼロだった場合)、
// 送信のギャップを考慮して、輻輳回復開始時間を調整する。
if bytes_in_flight == 0 {
let delta = now - self.last_sent_time;
self.congestion_recovery_start_time += delta;
}
// この送信イベントの時刻を記録する。
self.last_sent_time = now;
}
どこで破綻するか:QUIC の違い
quiche に移植された修正には、カーネルの CUBIC モジュールに対する後続の修正(約 1 週間後に適用)によって是正された、元のカーネル変更におけるバグが含まれていました。2 つ目の修正に関するコミットメッセージは次のように説明しています:
tcp_cubic: 未来に epoch_start を設定しない
bictcp_cwnd_event() におけるアイドル時間の追跡は不正確である。なぜなら、epoch_start は通常、送信時ではなく ACK 処理時に設定されるからである。
適切な修正を行うには追加の状態変数を導入する必要があるが、Jana 氏によって指摘されるまで CUBIC バグが長年存在し続けていたことを考慮すれば、その手間をかける価値はなさそうだ。
したがって、単に未来に epoch_start を設定しないようにしよう。そうしなければ、bictcp_update() がオーバーフローしてしまい、CUBIC が再び cwnd を速すぎると成長させてしまう恐れがある。
コミットメッセージで言及されている通り、回復開始時刻は ACK 処理時に設定されるが、送信時刻に基づく調整計算により、その回復開始時刻が未来に押しやられてしまうことがある。これがテストで見られた回復と輻輳回避の間での振動現象を説明するものである。この罠が確実に作動するのは、到着するすべての ACK が bytes_in_flight をゼロまで引き下げる場合に限られる。実際には、これは cwnd が最小値(2 パケット)に崩壊し、アプリケーションが ACK の到着と同時に次のウィンドウ分のデータをすぐに送信できる状態にあることを意味する。この状況以外では、各送信時に bytes_in_flight == 0 が成立することは稀であり、バグをトリガーする可能性も低くなる。
⟦CODE_0⟧
なぜ接続開始時にも同様の現象が起こらないのでしょうか?このバグは、接続がスロースタートから脱出して輻輳回避(congestion avoidance)モードに切り替わった際にのみトリガーされます。スロースタートを抜ける前には congestion_recovery_start_time が設定されていないため、on_packet_sent 内のバグのある分岐には進化する回復境界が存在しません。
スロースタート中、CUBIC の cwnd(送信ウィンドウサイズ)は、すべての損失ベースの CCAs(輻輳制御アルゴリズム)が共有する Reno スタイルの ACK ベースのルールに従って増加します。CUBIC 曲線やその congestion_recovery_start_time に対する感度が関与するのは、接続が輻輳回避モードに入った後だけです。つまり、この罠には同時に三つの条件が必要です:回復境界を設定するための実際の損失イベント、実行中の輻輳回避、そして cwnd が 2 パケットの下限まで縮小することです。
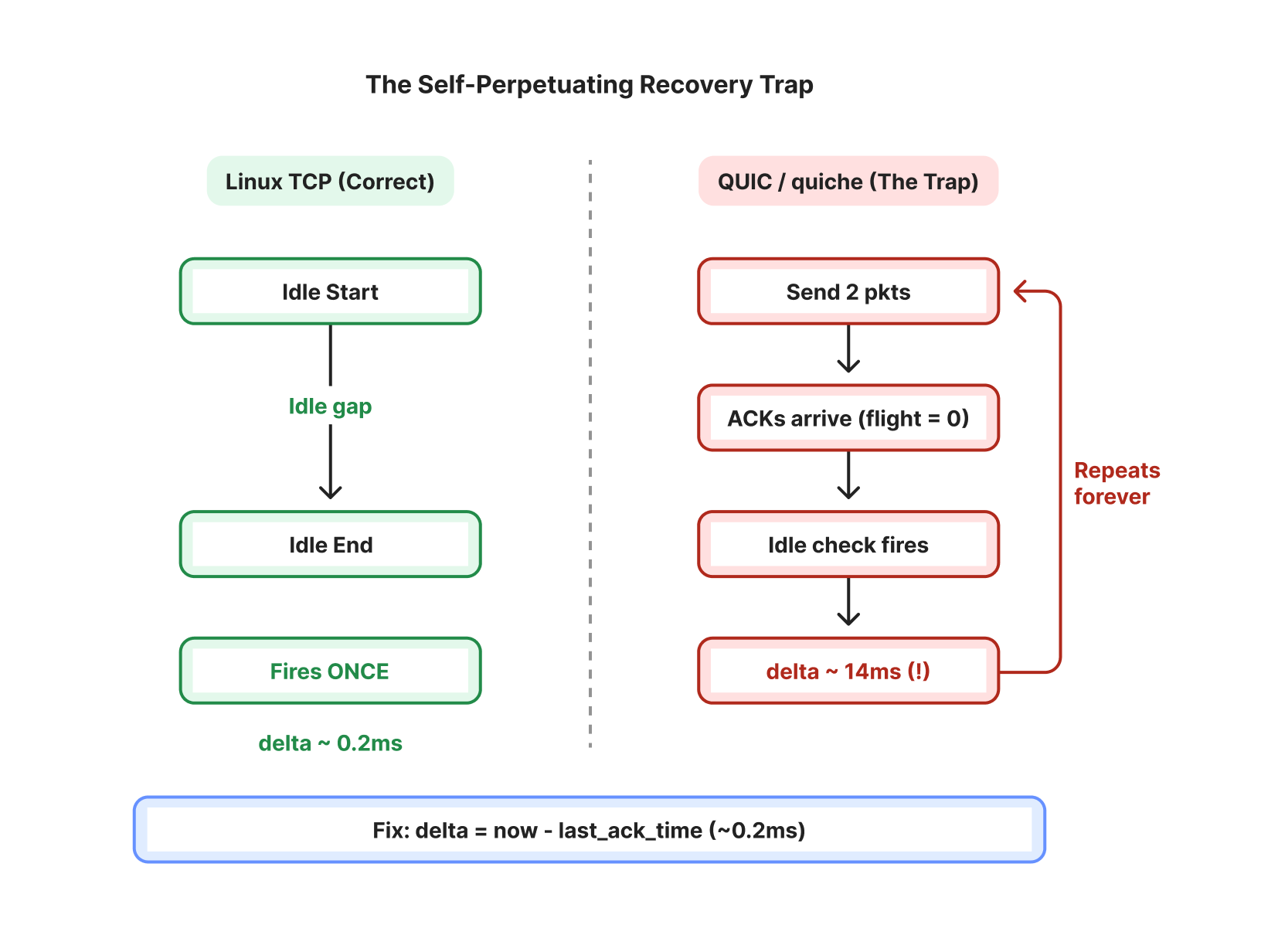
自己完結型の回復罠。最小の cwnd(2 パケット)では、すべての ACK サイクルが膨らんだデルタ値を伴うアイドル期間調整を引き起こします。
cwnd が最小(2 パケット)の場合、接続のダイナミクスは「デススパイラル」に陥り、アイドル期間最適化が自己成就予言となります。この罠は以下の連続ループで動作します:
パケット送信と ACK 処理:送信側は 2 パケット分のウィンドウ全体を送信します。1 RTT(約 14ms)後、両方のパケットに ACK が返され、bytes_in_flight(飛行中のバイト数)がゼロになります。
誤ったアイドル検出:次のバーストが送信される際、on_packet_sent() が bytes_in_flight == 0 を確認し、接続がアイドル状態だったと判断しますが、実際には輻輳制御によって制限されていました。
過大評価されたデルタ値:計算では now - last_sent_time を用いてアイドル継続時間を決定します。輻輳ウィンドウ (cwnd) が最小値にある場合、last_sent_time は前回の RTT サイクル開始時のタイムスタンプとなります。その結果生じるデルタは約 14ms(接続の RTT に追加的な丸め誤差を加えたもの)になります。この RTT サイズのデルタが誤って「アイドル時間」として適用されます。実際には、接続がアイドルだった時間(最後の ACK が到着してから次のパケットが送信されるまでの処理ギャップ)は実質的に 0 です。真のギャップではなく全体の RTT を測定することで、デルタ値が著しく過大評価され、回復開始時刻が前向きに大きくシフトし、場合によっては未来へと押しやられてしまいます。
認識された回復:回復開始時刻が未来となったため、in_congestion_recovery() のチェックは受信するすべての ACK に対して true を返します。次の ACK の処理により回復状態から脱却し、回復開始時刻を last_sent_time よりも大きい ACK 送信時間に設定します。これにより、次回の送信時に輻輳制御アルゴリズムが回復時間をさらに未来へと押しやる可能性が高まります。
停滞:CUBIC アルゴリズムは、回復期間中にあると認識されたパケットに対してウィンドウ成長をスキップするため、ウィンドウサイズは 2 パケットに固定されたままとなり、次の ACK でパイプが完全に空になり、サイクルが再開されます。
このループは数千回繰り返され、スケジューラのジッターや ACK 処理のばらつきによる小さな誤差が蓄積することで、in_congestion_recovery() 内の <= バウンダリが次のパケットの送信時刻よりも遅れてしまい、サイクルが破綻します。
修正:適切な時点からのアイドル時間測定
デススパイラルを解消するには、バイト数(bytes_in_flight)が実際にゼロに遷移した時点(最後に処理された ACK の時刻)からアイドル時間を計測する必要があります。これは最後の送信パケットの時刻ではなく、後者の時刻に基づいて計算する従来の方法とは異なります。
コードの変更点
CUBIC 状態に last_ack_time タイムスタンプを追加します。
ACK が到着した際にこのタイムスタンプを更新します。
アイドル時間差の計算にこれを使用します:
// cubic.rs — on_packet_sent() 関数内
fn on_packet_sent(&mut self, bytes_in_flight: usize, now: Instant, ...) {
// このパケット送信前に接続がアイドル状態だったかを確認する。
if bytes_in_flight == 0 {
if let Some(recovery_start_time) = r.congestion_recovery_start_time {
// 最も最近のアクティビティ、つまり直近の ACK(bytes_in_flight がゼロになった時刻の近似値)または最後のデータ送信のうち、より遅い方からアイドル時間を計測する。
// last_sent_time のみを単独で使用すると、cwnd が小さく、ACK と送信の間で bytes_in_flight が一時的にゼロになる場合に、計算される時間差が RTT 分だけ過大評価されてしまいます。
let idle_start = cmp::max(cubic.last_ack_time, cubic.last_sent_time);
if let Some(idle_start) = idle_start {
if idle_start < now {
let delta = now - idle_start;
r.congestion_recovery_start_time =
Some(recovery_start_time + delta);
}
}
}
}
現在、delta は最後の ACK 以降の実際のギャップを反映しているため、回復境界は送信時刻を追いかけることをやめました:
 image
image
旧コード:境界はサイクルごとに RTT (Round-Trip Time: 往復遅延時間) だけ前進し、常に次の送信時刻以降に位置します。
 image
image
修正:境界はほとんど移動せず、次の送信はこの境界より先に行われ、cwnd (Congestion Window: 輻輳ウィンドウ) が成長します。
真にアイドル状態の接続では、last_ack_time は過去にあり、同じ式が完全なアイドル期間を捉えるため、元の Epoch シフト動作は維持されます。
検証
修正を適用した結果、quiche テストスイートの 100% のパス率が回復しました。

修正後、cwnd(送信ウィンドウサイズ)は期待される CUBIC 曲線に沿って成長し、ダウンロードは約 4〜5 秒で完了します。
接続の末尾でのパケット損失については心配していません。これはルーターに割り当てられたバッファを完全に活用した結果として予想される現象です。つまり、このテストケースでは利用可能な帯域幅を最大限に活用していることになります。
教訓
「アイドル状態」とは、言葉ほど単純には定義できないものです。小さなウィンドウサイズにおける通常のパイプライン遅延は、単純なチェックではアイドル状態と誤認されることがあります。
最小 cwnd の動的挙動は、ユニークなコーナーケースです。このバグは高速環境では検出できず、深刻なパケット損失が発生した後にのみトリガーされました。
この動作の複雑さに比べれば、修正内容は驚くほど小さかったものです。根本原因を特定するために数週間にわたり qlogs(QUIC ログ)の計測と可視化データの分析を重ねた結果、解決策はたった 3 行のコード変更で済みました。調査中に私たちが指摘した通り、バグを発見するための労力は膨大でしたが、修正自体は実質的に 1 行のロジック変更でした。
本記事で説明した修正は、Cloudflare が提供する QUIC および HTTP/3 のオープンソース実装である cloudflare/quiche に貢献されました。当社の CCA(Congestion Control Algorithm)の取り組みは損失ベースのアルゴリズムに留まらず、quiche のモジュラー型輻輳制御設計を活用して、モデルベースの BBRv3 実装を試し、調整しています。現在、この BBRv3 は増加し続ける QUIC デプロイメントの一部で有効化されています。QUIC 輻輳制御の実装とパフォーマンスに関する今後の更新にもご注目ください。
輻輳制御やトランスポートプロトコルに興味がある方、あるいはオープンソースのネットワークコードへの貢献を検討されている方は、quiche リポジトリをご覧ください。このような問題に深く取り組むことを愛する優秀なエンジニアを常に募集していますので、ぜひ当社の求人ページもご参照ください。
原文を表示
CUBIC, standardized in RFC 9438, is the default congestion controller in Linux, and as a result governs how most TCP and QUIC connections on the public Internet probe for available bandwidth, back off when they detect loss, and recover afterward. At Cloudflare, our open-source implementation of QUIC, quiche, uses CUBIC as its default congestion controller, meaning this code is in the critical path for a significant share of the traffic we serve.
In this post, we’ll tell the story of a bug in which CUBIC's congestion window (cwnd) gets permanently pinned at its minimum and never recovers from a congestion collapse event.
The story starts with a Linux kernel change aimed at bringing CUBIC into line with the app-limited exclusion described in RFC 9438 §4.2-12 — a fix to a real problem in TCP that, when ported to our QUIC implementation, surfaced unexpected behaviors in quiche. It has a happy ending: an elegant (near-)one-line fix that broke the cycle.
CUBIC's logic in a nutshell
Before we dive into the core problem, a quick refresher on CCAs may help to set the stage.
The central knob a CCA turns is the congestion window (cwnd): the sender-side cap on how many bytes can be in flight (sent but not yet acknowledged) at any moment. A larger cwnd lets the sender push more data per round trip; a smaller cwnd throttles it. Every loss-based CCA, CUBIC included, is ultimately a policy for how to grow cwnd when the network looks healthy and how to shrink it when it doesn't.
In essence, CCAs aim to maximize data transfer by inferring the "available bandwidth" of the network; because no one wants to pay for a 1 Gbps subscription and only use a fraction of it. The family of loss-based algorithms, to which CUBIC belongs, operate on a fundamental premise: (1) if there is no packet loss, increase the sending rate (i.e. increase the bandwidth utilization); (2) if there is loss, loss-based algorithms assume that the network's capacity has been exceeded, and the sender must back off (i.e. decrease the bandwidth utilization).
image
This logic is built on several assumptions that have been revisited over the years. However, we'll save that discussion for another time.
The symptom: a test that fails 61% of the time
Our investigation started with the report of unexpected failures in our ingress proxy integration test pipeline. This erratic behavior appeared in tests where CUBIC was evaluated in a scenario of heavy loss in the early part of the connection.
Recovery after congestion collapse is an uncommon regime, but it is exactly the regime a congestion controller exists to handle. Most congestion control tests exercise the steady-state and growth phases of an algorithm; far fewer probe what happens at minimum cwnd, after the connection has been beaten down. Bugs in this corner of the state space are invisible in throughput dashboards, undetectable by static review, and only surface when you deliberately drive a CCA into it and watch whether it can climb back out — which is exactly what this test did.
The simulated test setup includes the following details:
image
Quiche HTTP/3 client and server running at locally (localhost)
RTT = 10ms (set up in the configuration)
A 10 MB file download over HTTP/3
Using CUBIC congestion control
With 30% random packet loss injected during the first two seconds
After two seconds, loss stops entirely
The test has a generous 10-second timeout to complete the download, which is expected to be completed in four or five seconds
The expected behavior is straightforward: CUBIC should take some hits during the loss phase, reduce its congestion window, and once loss stops, steadily ramp up and finish the download well within the timeout. Instead, we observed in multiple 100-time runs that around 60% of our tests were not able to complete the download within the generous 10-second timeout.
The anomaly: 999 state transitions with zero loss
We instrumented quiche's qlog output with packet loss events and built visualizations to understand what was happening inside the congestion controller:
image
Connection overview of a failing test. After T=2s, packet loss stops entirely — yet cwnd remains pinned at the minimum floor and the congestion state oscillates between recovery and congestion avoidance every ~14ms.
After the two-second (2000 ms) mark, packet loss stops entirely. However, the number of bytes in flight remains flat, which contradicts the core logic of the CUBIC algorithm: in the absence of loss, apply more gas to increase throttle (more bytes in our world). This raises the question: if the network is no longer dropping packets, why is the congestion window failing to grow?
When we zoom into that region, our analysis shows that CUBIC enters a rapid oscillation, shown in our plot as an extended recovery phase, between congestion avoidance state (the operational regime phase) and recovery state (the packet loss recovery state) — 999 transitions in approximately 6.7 seconds. That’s one transition every ~14ms — suspiciously close to the connection's RTT (10ms). Throughout this entire period, cwnd is locked at the minimum floor: 2700 bytes, or two full-size packets.
Clearly something in CUBIC's logic is misinterpreting the state of the connection. The key clue is the oscillation period: ~14ms matches the RTT. Whatever is triggering the recovery/avoidance flip is happening once per round trip, in lockstep with connection's ACK clock; the self-clocking rhythm in which each round-trip's ACKs from the client trigger the server's next send. Because this is a download (server to client), the ACKs in question travel client to server, and CUBIC's state machine runs on the server side: every time those ACKs land, bytes_in_flight drops to zero and the server sends the next two-packet burst, which is what triggers the bug.
To confirm this behavior was CUBIC-specific, we ran the same test with Reno, another member of the loss-based family but with a different growth rate. The results were conclusive: 100% pass rate, showing Reno recovered cleanly after the loss phase, and revealing that this is a CUBIC-related bug.
image
Reno recovers cleanly after the loss phase ends at T=2s and completes the download by ~5s
Tracing the root cause
Loss-based algorithms have two pedals, gas and brake, with a difference in how they accelerate. Well, CUBIC comes with some extra features. Here we are going to focus on bytes_in_flight == 0.
TCP CUBIC after idle (Linux, 2017)
To understand the bug, we first need to understand the optimization it came from. In 2017,an issue was found with Linux kernel's CUBIC implementation. The commit message explains:
The epoch is only updated/reset initially and when experiencing losses. The delta "t" of now - epoch_start can be arbitrary large after app idle as well as the bic_target. Consequentially the slope (inverse of ca->cnt) would be really large, and eventually ca->cnt would be lower-bounded in the end to 2 to have delayed-ACK slow-start behavior.
This particularly shows up when slow_start_after_idle is disabled as a dangerous cwnd inflation (1.5 x RTT) after few seconds of idle time.
The epoch is the reference timestamp CUBIC uses to anchor its growth curve: W_cubic(delta_t) is parameterized by delta_t = now - epoch_start, and the epoch is reset whenever CUBIC restarts its growth function — most notably after a loss event reduces cwnd. Between resets, delta_t grows monotonically with wall-clock time.
When an application goes idle (stops sending) for a while and then resumes, the CUBIC growth function W_cubic(delta_t) computes delta_t as now - epoch_start, as illustrated in the figure below. Since the epoch wasn't updated during idle, delta_t is huge, producing an enormous target window — and CUBIC would immediately try to inflate cwnd to an unreasonable value.
image
Jana Iyengar's initial fix was to reset epoch_start when the application resumes sending. But Neal Cardwell pointed out the flaw in that approach:
…it would ask the CUBIC algorithm to recalculate the curve so that we again start growing steeply upward from where cwnd is now (as CUBIC does just after a loss). Ideally we'd want the cwnd growth curve to be the same shape, just shifted later in time by the amount of the idle period.
The elegant solution, authored by Eric Dumazet, Yuchung Cheng, and Neal Cardwell, was to shift the epoch forward by the idle duration rather than resetting it. This preserves the shape of the CUBIC growth curve — just sliding it in time so that the algorithm picks up where it left off.
The port to quiche (2020)
When CUBIC was first implemented in quiche, this idle-period adjustment was ported. However, QUIC, which runs in the user space, doesn't have TCP's kernel-level CA_EVENT_TX_START callback. Instead, the quiche implementation checks for the idle condition inside on_packet_sent():
// cubic.rs — on_packet_sent() (simplified)
/// Updates the state when a packet is sent.
fn on_packet_sent(&mut self, bytes_in_flight: usize, now: Instant, ...) {
// If the sending burst is restarting (i.e., bytes_in_flight was zero before this send),
// adjust the congestion recovery start time to account for the gap in sending.
if bytes_in_flight == 0 {
let delta = now - self.last_sent_time;
self.congestion_recovery_start_time += delta;
}
// Record the time of this send event.
self.last_sent_time = now;
}
Where it breaks: the QUIC difference
The fix ported to quiche included a bug in the original kernel change which was fixed by a followup change to the kernel cubic module about a week later. The commit message for the second fix explains:
tcp_cubic: do not set epoch_start in the future
Tracking idle time in bictcp_cwnd_event() is imprecise, as epoch_start
is normally set at ACK processing time, not at send time.
Doing a proper fix would need to add an additional state variable,
and does not seem worth the trouble, given CUBIC bug has been there
forever before Jana noticed it.
Let's simply not set epoch_start in the future, otherwise
bictcp_update() could overflow and CUBIC would again
grow cwnd too fast.
As mentioned in the commit message, recovery start time is set during ACK processing, and the computation of the adjustment based on sent times can push the recovery start time into the future. This explains the oscillation between recovery and congestion avoidance seen on our test. The trap only consistently triggers when every incoming ACK drives bytes_in_flight all the way to zero — which in practice means cwnd has collapsed to its minimum (two packets) and the application has data ready to send another full window the moment an ACK arrives. Outside this regime, bytes_in_flight == 0 is less likely to hold on every send, so it is less likely to trigger the bug.
Why doesn't this also happen at connection start? The bug only triggers when the connection exits slow-start and switches over to congestion avoidance. Before exiting slow-start, congestion_recovery_start_time is not set, so the buggy branch in on_packet_sent has no recovery boundary to advance. During slow start CUBIC's cwnd grows by the same Reno-style ack-based rule shared by all loss-based CCAs — the cubic curve and its sensitivity to congestion_recovery_start_time only enter the picture once the connection is in congestion avoidance, meaning the trap needs three things at once: a real loss event to set the recovery boundary, congestion avoidance to be running, and cwnd collapsed to the two-packet floor.
image
The self-perpetuating recovery trap. At minimum cwnd, every ACK cycle triggers the idle period adjustment with an inflated delta.
At a minimum cwnd (two packets), the dynamics of the connection shift into a "death spiral" where the idle period optimization becomes a self-fulfilling prophecy. This trap operates in a continuous loop:
Send and ACK packets: The sender transmits the entire two-packet window. After one RTT (~14ms), both packets are ACKed, causing bytes_in_flight to drop to zero.
False idle detection: When the next burst is sent, on_packet_sent() sees bytes_in_flight == 0 and assumes the connection was idle, but it was congestion limited.
Inflated delta: The calculation uses now - last_sent_time to determine the idle duration. When the congestion window (cwnd) is at its minimum, last_sent_time is the timestamp of the start of the previous RTT cycle. Therefore, the resulting delta is approximately 14ms (the connection's RTT + additional rounding errors). This RTT-sized delta is incorrectly applied as the "idle" time. The actual time the connection was idle (the processing gap between the last ACK arriving and the next packet being sent) is effectively 0. By measuring the full RTT instead of the true gap, the delta is inflated significantly, aggressively shifting the recovery start time forward, possibly into the future.
Perceived recovery: Because the recovery start time is now in the future, the in_congestion_recovery() check returns true for every incoming ACK. Processing of the next ACK exits recovery and sets the recovery start to the ACK time which is larger than last_sent_time, making it likely for the congestion controller to push the recovery time into the future when doing the next send.
Stagnation: Since CUBIC skips cwnd growth for any packet perceived to be in a recovery period, the window remains pinned at two packets — ensuring the pipe drains completely on the next ACK and restarting the cycle.
And this loop repeats for thousands of cycles until the accumulation of small deviations — from scheduler jitter and ACK processing variance — lets the <= boundary in in_congestion_recovery() slip behind the next packet's send time, breaking the cycle.
The fix: measuring idle from the right moment
Fixing the death spiral involves measuring the idle duration from when bytes_in_flight actually transitioned to zero (the last ACK processed) rather than the last packet sent.
The code change
Add last_ack_time timestamp to the CUBIC state.
Update that timestamp when ACKs arrive.
Use it for the idle delta computation:
// cubic.rs — on_packet_sent()
fn on_packet_sent(&mut self, bytes_in_flight: usize, now: Instant, ...) {
// Check if the connection was idle before this packet was sent.
if bytes_in_flight == 0 {
if let Some(recovery_start_time) = r.congestion_recovery_start_time {
// Measure idle from the most recent activity: either the
// last ACK (approximating when bif hit 0) or the last data
// send, whichever is later. Using last_sent_time alone
// would inflate the delta by a full RTT when cwnd is small
// and bif transiently hits 0 between ACK and send.
let idle_start = cmp::max(cubic.last_ack_time, cubic.last_sent_time);
if let Some(idle_start) = idle_start {
if idle_start < now {
let delta = now - idle_start;
r.congestion_recovery_start_time =
Some(recovery_start_time + delta);
}
}
}
}
With the delta now reflecting the actual gap since the last ACK, the recovery boundary stops chasing the send time:
image
Old code: boundary advances one RTT per cycle, always landing on or ahead of the next send.
image
Fix: boundary barely moves; the next send lands ahead of it and cwnd grows.
For genuinely idle connections, last_ack_time is far in the past and the same expression captures the full idle duration, the original epoch-shift behavior is preserved.
Validation
With the fix applied, the 100% pass rate of our quiche testing suite was restored.
image
After the fix, cwnd grows along the expected CUBIC curve and the download completes in ~4-5 seconds.
We don't worry about the losses at the end of the connection — that's expected because we fully utilized the router's allocated buffer. In other words, we are fully utilizing the available bandwidth in this test case.
Takeaways
"Idle" is harder to define than it sounds. Normal pipeline delays at small windows can look like idleness to simple checks.
Minimum-cwnd dynamics are a unique corner case. The bug was invisible at high speeds and only triggered after severe loss.
The fix was surprisingly small compared to the complexity of the behavior. After weeks of instrumenting qlogs and analyzing visualizations to find the root cause, the solution required changing just three lines of code. As we noted during the investigation: the effort to find the bug was massive, but the fix itself was basically one line of logic.
The fix described in this post has been contributed to cloudflare/quiche, Cloudflare's open-source implementation of QUIC and HTTP/3. Our CCA efforts go beyond loss-based algorithms: we also use quiche’s modular congestion control design to experiment with and tune our model-based BBRv3 implementation, now enabled for a growing percentage of our QUIC deployments. Stay tuned for further updates on QUIC congestion control implementation and performance.
If you're interested in congestion control, transport protocols, or contributing to open-source networking code, check out the quiche repository. We're always looking for talented engineers who love digging into problems like these, please explore our open positions.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み