汎用アクセシビリティエージェントの構築と、その過程で得た教訓
GitHub は、Copilot を活用した実験的な汎用アクセシビティエージェントの導入により、コードレビューにおける自動修正率 68% を達成し、デジタル環境における障壁除去への AI の実用的な応用を示した。
キーポイント
Copilot 統合による二重の目標
エンジニア向けの即座の回答提供と、本番環境へのデプロイ前の自動修正という 2 つの主要目的のために、GitHub Copilot CLI および VS Code 統合にアクセシビティエージェントをパイロット導入している。
実証された効果と課題
これまでに 3,535 のプルリクエストを検査し、68% の解決率を達成しており、構造的関係の明確化や代替テキストの提供など、支援技術ユーザーにとっての主要な障壁を特定・除去している。
社会モデルに基づくアプローチ
アクセシビティ問題を「個人の欠陥」ではなく「環境構築による障壁」と捉える社会モデルに基づき、エージェントは万能薬(シルバーブレット)としてではなく、人間の努力を補完・増強するツールとして位置づけられている。
規制対応と業界への寄与
欧州アクセシビリティ法(EAA)などの法的要件に対応しつつ、この実験の成功と教訓を共有することで、他チームや組織のアクセシビティ向上への道筋を示すことを目指している。
構造化された手動修正データがエージェントの基盤となる
LLM は不正確なコードを学習するバイアスを持つため、組織内で手動で特定・修正され、構造化された過去の課題とプルリクエストの事例をトレーニングデータとして活用することが不可欠です。
曖昧な指示ではなく文脈に即した具体例が必要
"アクセシビリティベストプラクティスを使用する"といった抽象的な指示では不十分であり、組織のコンテキストや規約に沿った具体的なコード例を提供することで、誤ったアンチパターンを回避できます。
包括的な文脈理解がトークン消費と出力品質に影響
アクセシビリティは設計やコピーなど多岐にわたる分野と関連するため、適切なアドバイスには問題の全体像が必要であり、これがトークンの大量消費を招き、結果として応答速度の低下や信頼性の低い出力を生み出します。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェントが単なるコード生成ツールを超え、社会的責任であるデジタルインクルージョンの実現において具体的な成果を出し始めていることを示しています。特に、自動修正率という定量的な指標と「社会モデル」に基づく設計思想の融合は、業界全体が AI を倫理的かつ実用的に活用する際の重要な指針となります。
編集コメント
アクセシビリティ分野における AI の実用化事例として、単なる技術紹介ではなく「社会モデル」に基づいた設計思想と具体的な数値成果を提示しており、業界標準の確立に向けた重要な一歩と言えます。
エージェントがコードと連携する手段として人気を集めていることは、控えめに言っても事実です。GitHub は多くの取り組みにおいて、エージェントベースのコード作成および編集を採用しており、その一環としてアクセシビリティへのコミットメントを支援するためのエージェントの実証実験も実施しています。
現在、GitHub では実験的な汎用型アクセシビティエージェントを実証中であり、主な目的は以下の 2 つです:
GitHub Copilot CLI および Copilot VS Code 統合において、エンジニアがアクセシビリティに関する質問に対して信頼性の高い、その場限りの回答を提供すること。
本番環境に展開される前に、単純で客観的なアクセシビリティの問題を検出し、自動的に修正すること。
2 つ目の目的のために、このアクセシビティエージェントは、フロントエンドコードを変更する変更点を自動的に評価するように設定されています。
これまでに、エージェントは 3,535 のプルリクエストをレビューし、解決率は 68% に達しています。発生順に上位 5 つの問題タイプは以下の通りです:
支援技術に対して構造と関係性を明確にすること
対話型コントロールに対して明確で簡潔な名前を提供すること
重要な告知がユーザーに認識されていることを保証すること
非テキストコンテンツに対して代替テキストが存在することを保証すること
キーボードフォーカスがページやビュー内を論理的な順序で移動するようにすること
これらの各問題タイプは、支援技術を利用・依存する人々の GitHub 利用を阻害していた摩擦と障壁であり、これらが自動的に除去されました。以下にその動作のスクリーンショットを示します:
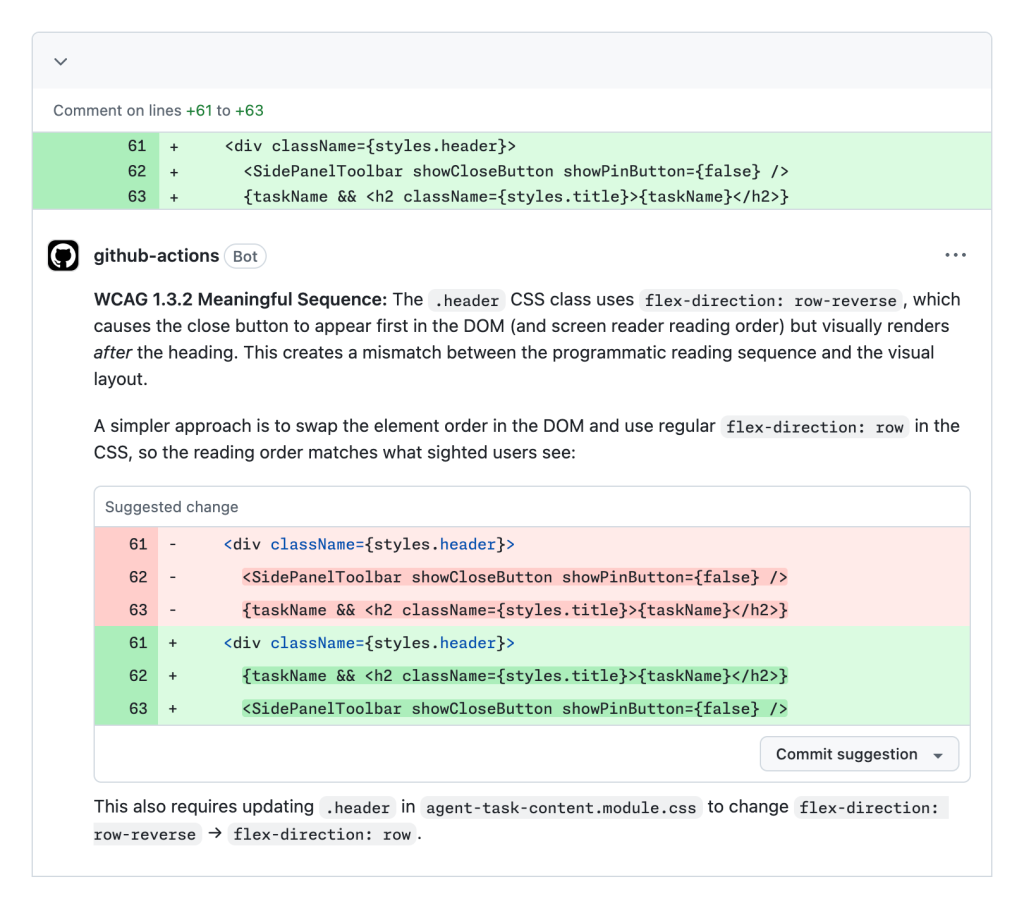
興味をお持ちいただけましたか?この実験における成功事例と教訓を共有し、他のチームのアクセシビリティへの取り組みに役立てることを願っています。
LLM とエージェントとは何か?
注:本記事では、LLM(大規模言語モデル)、エージェント、および関連概念について少なくとも基本的な理解があることを前提としています。これらの用語に不慣れな場合は、当社のブログで LLM についてさらに詳しく学ぶことができます。
特に役立つと思われる以下の投稿もご参照ください:
GitHub Copilot でどの AI モデルを使用するかを決定するためのガイド
GitHub 入門:LLM に望む動作を実行させる方法
優れた agents.md の作成法:2,500 以上のリポジトリからの教訓
マルチエージェントワークフローはしばしば失敗します。失敗しないように設計する方法はこちら。
マインドセット
障害の社会的モデルは、環境の構築方法によってアクセス障壁が生まれ、結果として障害が生じ得ることを教えてくれます。この考え方はデジタル体験にも当てはまります。
アクセシビリティエージェントを用いて、私たちは孤立して「アクセシビリティ問題を解決する」ことを目指しているわけではありません。むしろ、GitHub のユーザーインターフェースを構築する過程で生じる可能性のある障壁を取り除くために、同僚の取り組みを補完し、より効果的に支援することを目指しています。
このエージェントは、あらゆる仮説的なシナリオを自動的に処理できる「万能薬」ではありません。この点を理解し、尊重し、広く共有することで、エージェントの責任範囲を明確に設定できます。これにより実験の立ち上げが加速し、取り組みに対する支持が高まりました。
過去の取り組み
欧州アクセシビリティ法が現在施行されています。米国障害者法(Americans with Disabilities Act)の第 II 編では、2027 年 4 月に WCAG 2.1 AA を「完了」の法的定義として確立する予定です。LLM エージェントはアクセシビリティツリーを読み取り、アクションを実行できます。
率直に言えば、組織がすでに手動でアクセシビリティの問題を特定し是正することに投資していない場合、不利な立場に置かれます。これには多くの理由があり、その一つがアクセシビティエージェントの構築です。
この点において、GitHub にはアクセシビリティ問題のログ記録および修正内容が意図通りに機能していることを検証するための成熟したシステムが既に整備されています。具体的には以下の要素が含まれます:
問題報告のための構造化されたテンプレート
問題の再現手順
問題の深刻度レベル、サービス領域、適用される WCAG 成功基準に関する豊富なメタデータ層
問題に対処したプルリクエストへのクロスリンク
受入基準
さらに、すべての問題は単一のリポジトリに集約されています。この問題ログ作成の取り組みは LLM ツールの人気爆発以前から存在していましたが、その非常に一貫性があり構造化された性質が、アクセシビティエージェントが参照する理想的なコンテンツコーパスとなりました。
そのため、私たちはエージェントに対してこれらの問題を調査し、そこから推論可能な関連コードや言語スニペットがないかを確認するように指示しました。これは LLM の非決定論的な「ファジーマッチング」挙動が、潜在的なリスクではなく資産として機能する領域の一つです。
旧金(Old gold)
他の専門分野と同様に、スキルファイル内のあいまいな指示では不十分です。LLM に「アクセシビティのベストプラクティスを使用する」という短い例リストと共に指示しても、うまく機能しません。
コードを生成する際、現在利用可能な主要な大規模言語モデル(LLM)はすべて、何十年にもわたる非アクセシブルなコードで訓練されているため、アクセシビリティのアンチパターンを生成する傾向に不運なバイアスがあります。
これを克服するためには、エージェントが参照できるより良質なコンテンツが必要です。
したがって、手動によるアクセシビリティ問題のカタログ化と修正への投資を強く推奨します。ある程度の進捗が見られた後、このデータをエージェントに取り込むことができます。
これらの問題と対応するプルリクエストは、組織内で設定された規約に従って記述されており、大規模言語モデル(LMM)が参照するための文脈に富んだ例を提供します。この問題とコードのコレクションは、現在までで最も強力な資産の一つであり、エージェントがこれに依存しています。
効率的なトークン消費
アクセシビリティは包括的な懸案事項であり、ユーザーインターフェース作成に関わるコード、デザイン、コピーライティングなど、多くの他の分野と交差します。
また、アクセシビリティ作業の多くは非常に文脈依存性が高く、通常、適切なアドバイスを提供する前に問題の完全な動作状況を知る必要があります。
これらの2つの要因により、汎用性の高いアクセシビティエージェントが作業を実行する際に膨大な数のトークンを消費してしまいます。これには3 つのネガティブな結果があります:
信頼性の低い出力量の増加
応答時間の遅延
運用コストの増加
エージェントを構築する際には、慎重に構成することが重要です。ここでは、そのために私たちがどのように取り組んだかをご紹介します。
サブエージェントを活用する
アクセシビリティエージェントは当初、単一のモノリシックなエージェントとして始まりましたが、すぐにこのアプローチの限界を超えて成長しました。そのため、私たちはこれを進化させ、サブエージェントアーキテクチャを採用することになりました。
多くのガイドでは、それぞれに特定の責任領域を持つ大規模なサブエージェント群を作成することを推奨しています。ここでは、各サブエージェントは並列で実行され、メインのエージェントがその出力を統合・調整します。
驚くべきことに、このアプローチはアクセシビリティエージェントにとっては逆効果となりました。代わりに、私たちは2 つの専任サブエージェントを使用することにしました。
最初のサブエージェントは、受動的なレビューアーおよびリサーチャーとして機能します。
2 番目のサブエージェントは、能動的な実行者として機能します。
これら 2 つのサブエージェントはサンドボックス化されており、互いに直接コンテンツを渡すことはできません。代わりに、構造化されたテンプレート形式の出力を生成します。この出力はその後、アクセシビリティを調整する親エージェントに提供され、消費・検証・ルーティングされます。
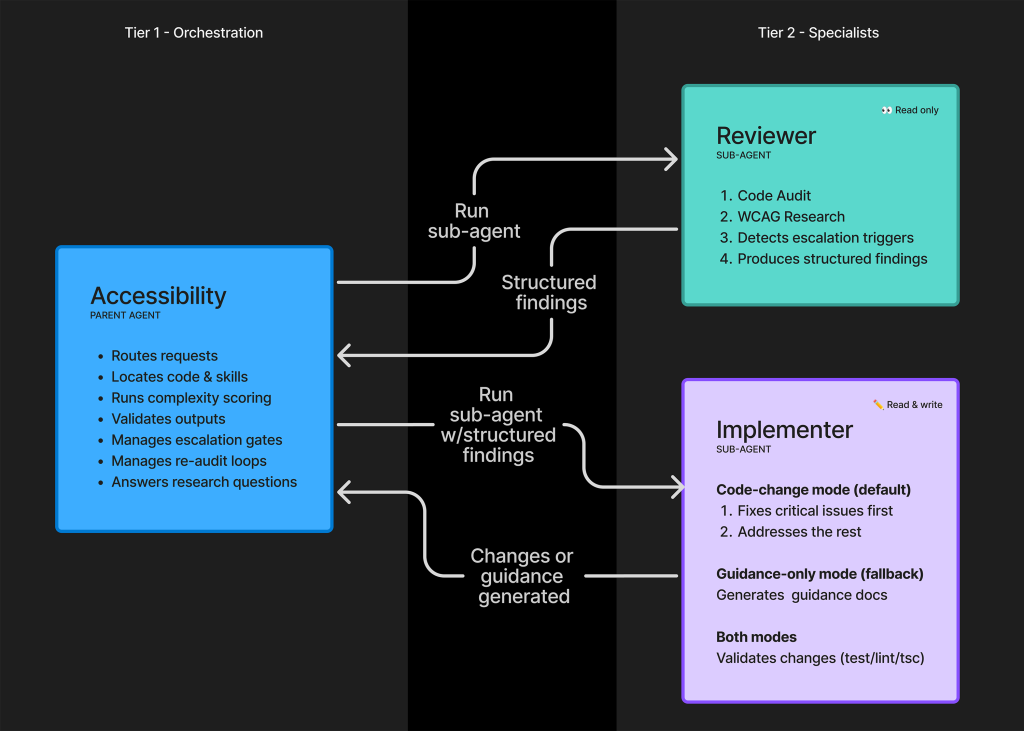
このアプローチにはいくつかの理由があります:
エスカレーションチェックポイント。レビューアーは、人間の介入が必要となる可能性が高い領域をチェックします。これには、複数の高深刻度 WCAG(Web Content Accessibility Guidelines)違反や、アクセシビリティ対応が難しいことが知られているパターンのリストが含まれます。
複雑性に基づく動作。エージェントは、基盤となるコードが過度に複雑であると判断された場合、専門的なガイダンス専用モードで動作するように指示されます。ここでは、親アクセシビリティエージェントが仲裁役として機能し、レビューアエージェントは「意見を持たず」、指示通りに発見事項を報告するだけです。
フィルタリング。レビューアは見つけたものをすべて提示します。その後、親アクセシビリティエージェントがリソースとスキルを活用して、どの情報がリクエストに関連するかを判断します。もしレビューアが発見したすべての内容を実装者に渡すとしたら、コストがかかりすぎ、かつ無関係で逆効果なタスクに導く恐れがあります。
追跡可能性。サブエージェント間の直接通信は、ユーザーおよびエージェントの意思決定に関する監査証跡を作成・検証する能力を失わせます。これは、エージェントが複雑なパターンに関する指示に従う必要があること、ならびにアクセシビリティ作業が極めて文脈依存であるという性質を考慮すると重要です。
命令を線形順序で実行する
包括的な配慮であるだけでなく、効果的なデジタルアクセシビリティ作業には、体系的で細部まで注意を払ったアプローチも求められます。
LLM の応答速度を向上させるためにサブエージェントを使用することへの懸念は、その結果の正確性が必要であるという要請によって相殺されます。私たちは、エージェントがサブエージェントに対する命令を固定された順序で実行することを強制することが鍵であると発見しました。
まず、順序付けられたフェーズからなる親セットを確立します。各フェーズ自体には、関連するリソースとスキルを伴う子 ordered ステップ(順序付けられた手順)の命令が含まれています:
この順序の面白い点は、私が個人的に監査、修正、報告の業務を遂行する際に取るアプローチと一致していることです。
テンプレートスキーマを使用してサブエージェントのコンテンツを巡回させる
サンドボックス化されたサブエージェントのすべての操作は、テンプレートスキーマファイルを中心に構築されています。これらのファイルは、エージェントが焦点を絞り、軌道に乗った状態を保つために不可欠な一貫性を生み出します。
2 つのスキーマテンプレートがあります:
レビューア用テンプレートスキーマ:これは何を監査し、それに関する関連情報をどのように見つけるかに焦点を当てています。
実行者用テンプレートスキーマ:これは何を修正し、どのように修正するかに焦点を当てています。
スキーマファイルが整備されていない場合、各エージェントは互いに恣意的な通信を試みることになります。これにより、トークン使用量の増加、望ましくないハルシネーション(幻覚)、不要なコード変更が生じ、さらにエージェントによる監査の観点からは困難、あるいは不可能な振る舞いが引き起こされます。
制限事項の認識
アクセシビリティエージェントを構築する際のもう一つの重要な側面は、エージェントが不足する可能性がある領域を理解することです。
このエージェントはアクセシビリティのための即席の「ソリューション」ではないため、人間のユーザーがその出力を検証しきれないようなエラーが生じる状況を避ける必要があります。これは、デジタルアクセシビリティに関する考慮事項や実践に詳しくない人が利用する場合、特に重要です。
エージェントの制限に対応するために私たちが行ったことは以下の通りです:
コードの複雑性を評価する
私たちは、エージェントが「アクセシブル」と判断した解決策を見直すために、コストのかかり、時間がかかる作業を余儀なくされるような状況を避けたいと考えています。
この問題に対処するため、アクセシビリティ・エージェントは、作業対象となるコードを分析する小さなシェルスクリプトを使用します。このスクリプト自体は単純で、基本的なヒューリスティック(heuristic)のセットを用いて相対的な複雑さを評価し、それをスコアに集約します。
このスコアはその後、エージェントによって取り込まれます。スコアが設定された閾値を超えた場合、エージェントにはコード変更を実行しないよう指示が出されます。代わりに、LLM(大規模言語モデル)を使用している人に、実行しようとしていることについてアクセシビリティ・チームに相談するよう案内します。
高リスクのパターンを特定する
これは理解しにくい点ですが、自動的なアクセシビリティチェックには合格しても、機能的には使用できないコードが存在することは完全にあり得ることを知っておいてください。
コードの複雑さへの対応として、アクセシビリティ・エージェントは、アクセシビリティ・チームが高リスクと特定したパターンに対するコード生成を試みないよう指示されています。これには、ドラッグ&ドロップ(drag and drop)、トースト通知(toasts)、リッチテキストエディタ(rich text editors)、ツリービュー(tree views)、データグリッド(data grids)などが含まれますが、これらに限定されません。
これらのパターンは、非常に集中的な注意と細部への配慮を必要とし、現在のアシストテクノロジー(assistive technology)で実際に機能する形で生成することは、LLM の現在の能力の範囲外にあります。
高リスクのパターンや複雑度の高いコード環境を禁止しないことは、誰もが時間を費やして再対応する必要が生じるだけでなく、アクセシビリティチームの評判にもリスクをもたらします。これを避けるために、LLM がこの経路を進む能力をシャットダウンしています。
行動へのバイアスを減らす
私は LLM に人間のような性質を帰属させることを好まませんが、それらがすべて共有しているように見える一つの特質は、コンテンツを生み出そうと必死に願っている点です。Copilot の場合、それは多くの場合コードの生成を意味します。
人間の専門知識が必要な場合にコードを生成しないという指示に従わせないよう、LLM が巧妙な抜け道を作らないための「ゲーム対策」指示を作成する必要がありました。これにより、LLM 自身が介入指示に違反するのを防ぎました。
プログラムで決定可能な問題がすべてを網羅しているわけではないことを知る
エージェントの成功指標は、より大きな文脈の中に位置づけられます。
WCAG レベル A および AA の成功基準 55 項目のうち、決定論的な自動コードチェッカーによって検出可能なのは 35 項目のみです。つまり、レベル A および AA の成功基準の約 36% は自動的に発見できないことを意味します。
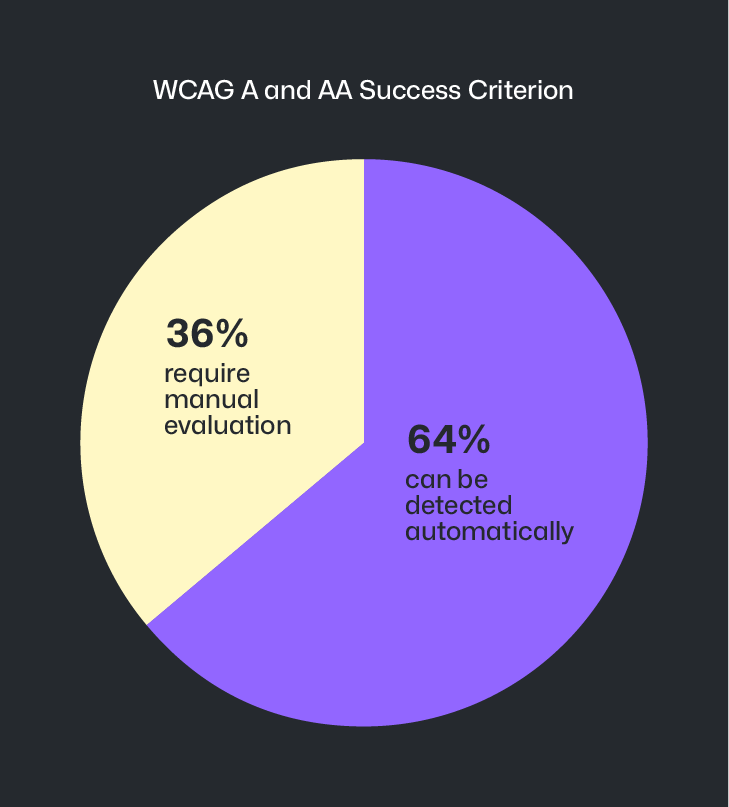
LLM を活用したエージェント運用はこの約 36% のギャップに切り込み始めていますが、完璧な科学ではありません。このため、アクセシビリティ問題の大半が発生する領域である、設計およびプロトタイピングの初期段階で手動によりアクセシビリティバリアを特定することが重要になります。
この考え方は、エージェントのエスカレーションロジックにも反映されており、アクセシビリティチームのメンバーはデザイナーとペアを組んで代替アプローチを検討し、ビジネス目標を達成しつつアクセシビリティを損なわない解決策をブレインストーミングするのを支援します。
この介入と支援は、潜在的な下流の問題や、コストがかかり時間のかかる再設計が萌芽する前に阻止されることを目的としています。
エージェントの出力を手動で評価し、期待通りに動作していない部分を調整する
私たちは定期的にエージェントの出力を手動レビューしてその精度と有効性を確認しています。さらに、プルリクエストレビュアーの感情を捉えるためのツールも用意されており、これらは両方とも、エージェントにより明確な指示や新しいリソース・スキルが必要となる領域を示す強力なシグナルとなります。
オープンでの学習
要約すると、私たちは以下のことを学びました。つまり、このエージェントは:
既存のアクセシビリティ取り組みを代替するのではなく、それを支援し強化するために使用されること。
特定の環境における手動監査および修正済みのアクセシビリティ課題でトレーニングされた場合、著しく効果が高まること。
サブエージェントを活用することでトークン消費がはるかに効率的になること。
体系的かつ線形的な手順に従って指示を実行する際に、より正確かつ効果的であること。
情報をやり取りするために事前フォーマットされたテンプレートを使用するように設定されている場合、一貫性が高まること。
自身の限界を理解し、代替サポートシステムへユーザーを誘導するように設定されていること。
出力結果を定期的にレビューして改善が必要な領域を特定することで、より向上します。
この取り組みはまだ完了していません。アクセシビリティエージェントは、GitHub がすべての開発者にとってアクセス可能で包括的なプラットフォームとなるよう確実にするために、継続的に改良されています。
私たちは最終的に、オープンソースソフトウェアのアクセシビティを大規模に改善するという私たちの約束の一環として、このエージェントをオープンソース化できることを願っています。それまでの間、この取り組みを通じて得た教訓を共有することで、他のチームが自らのアクセシビリティ活動のためのリファレンスとして参照できる資源になれば幸いです。
「汎用型アクセシビリティエージェントの構築と、その過程で学んだこと」という投稿は、最初に The GitHub Blog で掲載されました。
原文を表示
It is an understatement to say agents have become a popular way of working with code. GitHub has adopted agent-based code creation and editing for many of its initiatives, including piloting an agent to help with our commitment to accessibility.
GitHub is currently piloting an experimental general-purpose accessibility agent to achieve two main goals:
Providing engineers with reliable, just-in-time answers to accessibility questions in the GitHub Copilot CLI and the Copilot VS Code integration.
Catching and automatically remediating simple, objective accessibility issues before they go to production.
For purpose number two, the accessibility agent is set to automatically evaluate changes that modify our front-end code.
To date, the agent has reviewed 3,535 pull requests, with a 68% resolution rate. In order of occurrence, the top five issue types center around:
Making structure and relationships clear to assistive technologies
Providing clear and concise names for interactive controls
Ensuring users are aware of important announcements
Ensuring there are text alternatives for non-text content
Moving keyboard focus through pages and views in a logical order
Each of these issue types represents friction and barriers automatically removed that would have otherwise inhibited use of GitHub for people who use and rely on assistive technology. Here’s a screenshot of it in action:
Interested? We’ll be outlining successes and lessons learned with this experiment, with the hopes that it can help with other teams’ accessibility journeys.
What are LLMs and agents?
Note: This post assumes at least some understanding of LLMs, agents, and their related concepts. If you’re not familiar, you can learn more about LLMs on our blog.
Some specific posts you may find helpful are:
A guide to deciding what AI model to use in GitHub Copilot
GitHub for Beginners: How to get LLMs to do what you want
How to write a great agents.md: Lessons from over 2,500 repositories
Multi-agent workflows often fail. Here’s how to engineer ones that don’t.
Mindset
The social model of disability teaches us that access barriers—and consequently impairment—can be created because of how an environment is built. The same thinking applies to digital experiences.
With the accessibility agent, we are not attempting to “solve” accessibility in isolation. We are instead attempting to augment our peers’ efforts, to better help them remove the barriers that may be created as a result of how we construct GitHub’s user interfaces.
The accessibility agent is not a “silver bullet” that can automatically address every hypothetical scenario. Understanding, honoring, and socializing this better helps set the agent’s scope of responsibility. This sped up the experiment’s launch, leading to more buy-in for the effort.
Past efforts
The European Accessibility Act is now in effect. Title II of the Americans with Disabilities Act is set to establish meeting WCAG 2.1 AA as the legal definition of done in April of 2027. LLM agents can read and take action on the accessibility tree.
To say it plainly: Organizations will be at a disadvantage if they have not already invested in manually identifying and remediating accessibility issues. There are many reasons for this, including building an accessibility agent.
To that point, GitHub has a mature system in place for logging accessibility issues, as well as verifying fixes to issues are working as intended. This includes:
A structured template for reporting problems
Steps to reproduce the issue
A rich layer of metadata about the issue’s severity level, service area, and applicable WCAG success criterion
Crosslinks to the Pull Request that addressed the issue
Acceptance criteria
In addition, all the issues are centralized to a single repository. While this issue-logging effort predated the explosion in popularity of LLM tooling, its highly consistent and structured nature made it an ideal corpus of content for the accessibility agent to reference.
Because of this, we instructed the agent to investigate these issues to see if there are related code and language snippets it can extrapolate from. This is one area where the non-deterministic “fuzzy matching” behavior of LLMs acts as an asset rather than a possible liability.
Old gold
Much like with any other specialized domain area, vague instructions in a skill file won’t cut it. Telling an LLM to “use accessibility best practices” with a short list of examples won’t work well.
When generating code, LLMs have an unfortunate bias towards producing accessibility antipatterns since every major LLM currently available is trained on decades of inaccessible code.
To counteract this, the agent needs better content to draw from.
So, I enthusiastically recommend investing in manually cataloging and remediating accessibility issues. After some progress, this data can be incorporated into the agent.
The issues and their corresponding pull requests provide highly contextual examples for the LMM to reference, written using the conventions set up by the organization it is deployed in. This collection of issues and code is by far one of the strongest assets the agent draws from.
Efficient token consumption
Accessibility is a holistic concern, intersecting with code, design, copywriting, and numerous other disciplines involved with creating user interfaces.
A lot of accessibility work is also highly contextual, meaning that someone typically needs the full working picture of a problem before they’re able to give the appropriate advice for what to do.
Because of these two factors, a general-purpose accessibility agent can consume a ton of tokens when it performs work. This has three negative outcomes:
An increased amount of unreliable output
Slower response times
Increased operational costs
It’s important to be diligent when structuring the agent. Here’s how we went about doing just that.
Use sub-agents
The accessibility agent started as a single monolithic agent, but quickly grew past the limitations of this approach. Because of this, we evolved it to use a sub-agent architecture.
A lot of guides recommend creating a large suite of sub-agents, each with its own specific area of responsibility. Here, the sub-agents are executed in parallel, with the main agent reconciling their output.
Surprisingly, this approach worked against us for the accessibility agent. Instead, we wound up using two dedicated sub-agents:
The first sub-agent acts as a passive reviewer and researcher.
The second sub-agent acts as an active implementer.
The two sub-agents are sandboxed and cannot directly pass content to each other. Instead, they generate a structured, templatized output. This output is then served to the parent orchestrating accessibility agent to consume, validate, and route.
There are a few reasons for this approach:
Escalation checkpoints. The reviewer checks for areas where human intervention will likely be needed. This includes multiple high-severity WCAG failures, as well as a list of patterns that are known to be difficult to make accessible.
Complexity-based behavior. The agent is instructed to operate in a specialized guidance-only mode if the underlying code is deemed too complicated. Here, the parent accessibility agent acts as an arbiter, while the reviewer agent is “opinionless” and just reports the findings as instructed.
Filtering. The reviewer presents everything it finds. The parent accessibility agent then utilizes resources and skills to determine what is relevant to the request. The reviewer passing all its findings to the implementer would be costly and potentially set it on irrelevant and counter-productive tasks.
Traceability. Direct communication between sub-agents would remove the ability to create and review an audit trail of user and agent decisions. This is important given the agent’s instruction around complex patterns, as well as the highly contextual nature of accessibility work.
Execute instructions in a linear order
In addition to being a holistic concern, effective digital accessibility work also demands a methodical, detail-oriented approach.
The concern of using sub-agents to increase the speed of the LLM’s reply is counterbalanced by our need for its results to be accurate. We found that compelling the agent to execute its sub-agent instructions in a fixed order was key.
We first establish a parent set of ordered phases. Each phase itself contains child ordered steps of instructions, which are accompanied by relevant resources and skills:
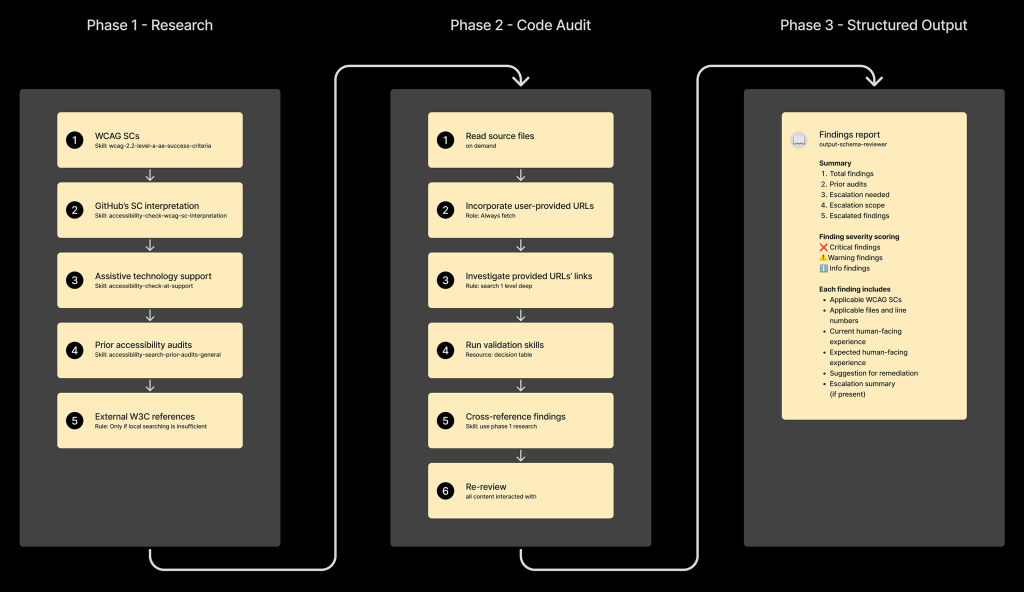
The interesting bit about this linear order is that it mirrors how I would personally approach performing auditing, remediating, and reporting duties.
Use a template schema pass around sub-agent content
The entire operation of the sandboxed sub-agents is built around template schema files. These files create consistency that is vital to keeping the agent focused and on track.
The two schema templates are:
Reviewer template schema: This focuses on what to audit, and how to find applicable information about it.
Implementer template schema: This focuses on what to fix and how to fix it.
Without the schema files in place, the agents would all attempt to arbitrarily communicate with each other. This would create increased token expenditure, undesirable hallucinations, unnecessary code changes, and difficult-to-impossible behavior for agent auditing purposes.
Acknowledging limitations
Another vital aspect of creating the accessibility agent is understanding areas where agents can fall short.
As the agent is not a turnkey “solution” for accessibility, we want to avoid situations where the agent’s output in error may not be sufficiently interrogated by the human using it. This is especially relevant when someone is not well-versed in digital accessibility considerations and practices.
Here’s what we did to accommodate the agent’s limitations:
Evaluate code complexity
We want to avoid scenarios where we would need to perform costly and time-intensive work to revisit an inaccessible solution that the agent “thinks” is accessible.
To aid with this problem, the accessibility agent uses a small shell script to analyze the code it is set to work on. The script itself is simple, using a small set of basic heuristics to evaluate the relative complexity and distill it down into a score.
This score is then ingested by the agent. If the score passes a set threshold, the agent is instructed to not execute code changes. Instead, it will inform the person using the LLM that they should reach out to the accessibility team to consult on what they are attempting to do.
Identify high-risk patterns
It is a subtle thing to understand, but know that it is entirely possible to have code that passes automated accessibility checks, yet is functionally unusable.
As a companion to code complexity, the accessibility agent is instructed to avoid attempting code generation for patterns the accessibility team has identified as high-risk. This includes, but is not limited to: drag and drop, toasts, rich text editors, tree views, and data grids.
These patterns require a ton of focused attention and detail and currently sit outside of an LLM’s current capabilities to produce in a way that actually works with assistive technology.
Not prohibiting high-risk patterns and high-complexity code environments would lead to unnecessary demands of everyone’s time to readdress, and also represents reputational risk for the accessibility team. We avoid this by shutting off the LLMs capability to go down this pathway.
Reduce bias to action
I am loathe to anthropomorphize LLMs, but one quality they all seem to share is desperately wanting to produce content. For Copilot, that often means generating code.
We had to create anti-gaming instructions to prevent the LLM from creating sneaky ways to get around its instructions to not generate code when human expertise is needed. This prevented it from violating its own intervention instructions.
Know that programmatically determinable issues don’t cover everything
Agent success metrics live within a larger context.
Of the 55 total WCAG level A and AA Success Criterion, only 35 of them can be detected via deterministic automated code checkers. This means that ~36% of level A and AA Success Criterion cannot be discovered automatically.
LLM-powered agent operation is making inroads on this ~36% gap, but it is not a perfect science. Because of this, it becomes important to manually identify accessibility barriers earlier during design and prototyping efforts—the area where the majority of accessibility issues originate.
This thinking is also reflected in the agent’s escalation logic, in that members of the Accessibility team can pair with designers to help consider alternate approaches and brainstorm solutions that achieve business goals without compromising on accessibility.
This intervention and assistance is done to thwart potential downstream issues—and costly and time-consuming redesigns—are stopped before they ever have a chance to get off the ground.
Manually evaluate agent output and adjust things that aren’t working as expected
We periodically perform manual review of agent output to determine its accuracy and efficacy. In addition, we have tooling in place to capture pull request reviewer sentiment. Both serve as strong signals for areas where the agent needs better instruction, as well as new resources and skills.
Learning in the open
To recap, we learned that the agent is:
Used to aid and augment existing accessibility efforts, not to replace them.
Significantly more effective when trained on manually audited and remediated accessibility issues for your specific experience.
Far more efficient with token consumption when utilizing sub-agents.
More accurate and effective when executing instructions in a methodical, linear fashion.
More consistent when set to use preformatted templates to pass information around.
Set to understand its limitations and route people to alternative support systems.
Improved when its output is periodically reviewed to identify areas it needs better instruction.
This journey is also not yet complete. The accessibility agent continues to be iterated upon in the hopes of helping ensure GitHub is an accessible and inclusive platform for all developers.
We hope that we can eventually open source the agent as part of our pledge to help improve the accessibility of open source software at scale. Until then, we hope that in sharing our learnings with this undertaking that other teams can have a resource to reference for their own accessibility efforts.
The post Building a general-purpose accessibility agent—and what we learned in the process appeared first on The GitHub Blog.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み