AWS AIリーグ:AtosがAI教育へのアプローチを微調整
アトスはAWSとの連携により、AWS AI Leagueを活用したゲーミフィケーション型の実践的AI教育を400人以上に提供し、2026年までの100% AIリテラシー workforce 達成を目指す。
キーポイント
従来のAI研修の限界
オンライン講座や認証プログラムだけでは、エンゲージメントの低下と実践スキルの不足が生じやすい。
AWS AI Leagueの活用
ゲーミフィケーションと競争要素を組み合わせた実践学習により、インフラの複雑さを抽象化しつつモデルカスタマイズを学べる。
大規模な workforce アップスキリング
400人以上の参加者を対象に、実務シナリオに基づいたAI活用能力を組織的に加速させる取り組みを実施。
影響分析・編集コメントを表示
影響分析
本記事は、大規模企業におけるAI人材育成の現実的な課題と解決策を示しており、AWSエコシステムを活用した教育プログラムの普及に寄与する。企業側は技術習得コストを下げつつ実践力を高められるため、AI導入の障壁低減に貢献する可能性がある。
編集コメント
企業PR色が強いものの、AI教育における「体験型学習」と「ゲーミフィケーション」の組み合わせは、大規模組織のスケーラビリティ確保において実証済みの有効なアプローチである。技術習得の壁を下げるプラットフォーム戦略として注目する価値がある。
*この投稿は、Atos の Mark Ross と共著です。*
AI 変革を推進する組織は、チームが AI を構築・展開・利用する方法を変えながら、大規模な workforce のスキルアップをどう行うかという、よくある課題に直面することがあります。従来の AI 研修アプローチ——オンラインコース、認定プログラム、教室での講義——は必要不可欠ですが、しばしば不十分です。これらは基礎知識の習得には役立ちますが、多くの組織で参加者の関与が低く、実践的な演習が不足しており、理論的理解と実世界での応用の間にギャップが生じています。その結果、チームは認定証を取得しても、ビジネス課題に AI を意味ある形で適用するために必要な自信や経験を得られないことがあります。
Atos と AWS のパートナーシップを通じて、私たちは長年、効果的な AI 活用には実践的な学習が不可欠な要素であると認識してきました。構造化された e ラーニングと認定パスウェイと組み合わせることで、体験型学習は知識を影響力に変換します。現在、Atos の従業員は 5,800 件以上の AWS 認定証と 11 着のゴールデンジャケット(※注:AWS の最高認定資格)を取得しており、クラウドおよび AI スキルにおける強固な基盤を示しています。しかし、2026 年までに AI に精通した workforce を 100% 達成するというコミットメントのもと、関与を大規模に拡大し、実践的なスキルを加速させ、エンジニアが現実的なシナリオで AI を適用するよう動機づける学習モデルが必要であることを私たちは知っていました。
これに対処するため、Atos は AWS と提携し、AWS AI League を通じて実践的でゲーム化された学習体験を提供しました。これは受動的な学習を超え、参加者を実際の AI チャレンジに没入させるために設計されています。本稿では、Atos がどのように AWS AI League を活用して 400 人以上の参加者に対する AI 教育を加速させたか、ゲーム化され経験に基づく学習の実感できるメリット、そしてご自身の AI エネーブルメントプログラムに応用可能な具体的な洞察について探ります。
AWS AI League による AI エネーブルメント
e ラーニングコースや認定資格は不可欠な基盤ですが、多くの組織では、その知識を実践的な経験、持続的な関与、そして実際のビジネスへの影響へと転換することに苦労しています。特に大規模展開においてはそれが顕著です。
このギャップを埋めるために AWS AI League が設計されました。概念的な学習にのみ焦点を当てるのではなく、このプログラムは実践的な実験と構造化された競争を組み合わせており、ビルダーが実際の環境で使用される生成 AI ツールを直接扱うことができます。Atos にとって、このアプローチは、関与、協力、そして測定可能な成果を維持しつつ、組織全体における応用 AI スキルの習得を加速させる手段となりました。
AWS AI League は、モデルのカスタマイズと評価の核心となるメカニズムを維持しつつ、深いインフラストラクチャの複雑さを抽象化することで、ビルダーが AI スキルを向上させるのを支援します。参加者は Amazon SageMaker および Amazon SageMaker JumpStart を用いて、大規模言語モデル(LLM)のファインチューニングを行い、企業における AI 導入においてますます中核的な役割を果たす技術に関する実践的経験を積みます。
ビジネスユースケースにおけるファインチューニングの重要性
大規模言語モデルのファインチューニングは、転移学習の一形態です。これは、事前学習済みモデルをゼロから訓練するのではなく、より小さくドメイン固有のデータセットを用いて適応させる機械学習技術です。ビジネスチームにとって、このアプローチはカスタマイズへの実用的な道筋を提供します。これにより、トレーニング時間と計算コストを削減しつつ、専門知識、用語、および意思決定ロジックを反映したモデルを実現することが可能になります。

実際、ファインチューニング(fine-tuning)を活用する組織は、精度、推論能力、説明可能性が極めて重要な特定ドメインに対して汎用モデルを適応させることができます。Atos にとっては、リスクプロファイル、保険約款の条件、免責事項、および保険料計算を理解するには、単なる一般的な言語流暢さ以上のものが必要となる保険引受領域にモデルをカスタマイズすることを意味しました。AWS AI League は、適切な構造とツールさえあれば、ソリューションアーキテクト、開発者、コンサルタント、ビジネスアナリストなど多様な役割のチームが、深い機械学習の専門知識を必要とせずにモデルのファインチューニングとデプロイが可能であることを示しています。これにより、顧客対応型の AI ソリューションの提供に注力するパートナー組織にとって、ファインチューニングは実用的な能力となります。
AWS AI リーグの仕組み
AWS AI リーグは、実践的で生産指向型の AI スキルを構築しつつ、継続的な動機と参加意欲を維持するために設計された 3 つの段階からなる構造を採用しています。プログラムは、SageMaker JumpStart を用いたファインチューニングの基礎を紹介する没入型ワークショップで始まります。SageMaker JumpStart は、ガイド付きインターフェースを通じて事前学習済みファウンデーションモデルへのアクセスを提供し、参加者がインフラ構築よりもむしろモデルの挙動や成果に集中できるようにします。その後、参加者は集中的なモデル開発フェーズへと移行します。この段階では、チームは複数のファインチューニング戦略を反復して試行し、データセットの構成、拡張手法、ハイパーパラメータ設定などを実験します。提出されたモデルは、AI ベースの評価システムによって駆動される動的リーダーボードで評価され、一貫した基準セットに基づいてパフォーマンスがベンチマークされます。この構造は迅速な実験を促し、進捗を可視化することで、チームが独自にカスタマイズしたモデルをより大規模なベースラインモデルと比較できるようにします。プログラムは、ライブでインタラクティブなフィナーレで幕を閉じます。上位チームはリアルタイムチャレンジを通じて自らのモデルを実演し、その出力は多次元スコアリングシステムを用いて評価されます。技術審査員が深さと正確性を評価し、AI ベンチマークが客観的なパフォーマンスを測定し、聴衆による投票が実用的でユーザー視点の要素を加えます。これら複数の次元が一体となることで、リーグの目的である「実践学習を実世界で良好に機能するモデルへと転換すること」が強化されます。
Atos のユースケース – インテリジェント保険引受
この基盤を整えた上で、Atos は実際の顧客ニーズに密着したユースケースとして「インテリジェント保険引受」を選択しました。AWS AI League イベントを通じて開発されたこのプロジェクトの目的は、複雑な保険シナリオを分析し、専門レベルの引受ガイダンスを提供できる大規模言語モデルを微調整することです。このモデルはリスク評価を行い、適切な保険条件や免責金額を推奨し、保険料の調整案を示し、各決定の根拠を明確に説明するよう設計されています。これらはすべて、業界の専門基準に準拠した形で行われます。
このユースケースは理論的な演習として選ばれたのではなく、生成 AI が一貫性と効率性を保険商品ライン全体で向上させることで、引受専門家をサポートできる現実的な例として選定されました。コスト効果の高い微調整済みオープンソースモデルを基盤とし、Amazon SageMaker、SageMaker Unified Studio、Amazon S3 によって駆動されるこのソリューションは、独自の引受データでトレーニングされた推論および推奨モジュールと知識ベースを組み合わせています。その結果、チームの生産性を高め、リスク評価の精度を向上させ、引受専門家がすでに信頼している本物の業界専門知識とシームレスに統合される、手頃な価格のカスタマイズ型アシスタントが実現しました。
Amazon SageMaker Studio と Amazon SageMaker JumpStart を用いたファインチューニング
AWS AI League の参加者は、機械学習のための完全に統合された Web ベースの開発環境である Amazon SageMaker Studio 内でモデルのファインチューニングを行っています。SageMaker Studio は、生成 AI モデルをエンドツーエンドで構築し、ファインチューニングし、デプロイし、監視するためのローコード/ノーコード (LCNC) インターフェースを提供します。このアプローチに従うことで、Atos の参加者はインフラストラクチャの管理ではなく、実験と革新に集中することができ、価値提供までの時間を短縮するのに役立ちます。AI League では現在、Amazon Bedrock AgentCore 上に構築された サーバーレス SageMaker モデルカスタマイズおよびエージェント型チャレンジ を通じて、Amazon Nova モデルのカスタマイズも提供しています。
ユーザーは Amazon SageMaker Studio 内で、簡素化された一連の手順に従います。
- モデルの選択 – SageMaker JumpStart は、テキスト生成、要約、画像作成などのタスク向けに、事前学習済みかつ公開利用可能なファウンデーションモデルのカタログを提供しています。参加者は主要プロバイダーからモデルをシームレスに閲覧・選択でき、これらはカスタマイズのために事前に統合されています。今回のコンテストでは、参加者は Amazon SageMaker Jumpstart を活用してノーコードで Meta Llama 3.2 3B Instruct モデルのファインチューニングを行う必要がありました。
- 学習用データセットの提供 – Amazon Simple Storage Service (Amazon S3) に保存されたデータセットは、SageMaker に直接接続され、ファインチューニングタスクのために事実上無制限のストレージ容量を活用します。
- ファインチューニングの実行 – ユーザーは、学習率、エポック数、バッチサイズなどのハイパーパラメータをファインチューニングジョブを実行する前に設定できます。SageMaker はその後、計算リソースのプロビジョニングや進捗のログ記録を含むトレーニングプロセスを管理します。
- モデルのデプロイ – トレーニングが完了すると、参加者は SageMaker Studio から直接モデルをデプロイして推論に使用したり、スケーラブルな本番環境での展開のための完全にマネージドされた環境を提供する Amazon Bedrock へインポートしたりできます。
- 評価と反復 – AWS AI League では、LLM-as-a-Judge(自動採点システム)を用いて評価が行われ、モデルの品質、精度、応答性を自動的にスコアリングしました。
上記に示されたこの簡略化されたワークフローは、AWS AI League のモデル開発ライフサイクルを示しており、性能、透明性、コスト効率を維持しつつ、専門的な AI モデルの開発と運用における複雑さをどのように軽減するかを示しています。Atos にとって、この実践的なプロセスは、生成 AI の機能を顧客向けソリューションに拡張するための実用的で本番環境対応の基盤となります。参加者は、JSON Lines (JSONL) 形式で保険ユースケースのデータセットを生成する必要がありました。各レコードは以下の 2 つのフィールドで構成されています:
- インストラクション – インテリジェント・インシュアランス・アンダーライター(Intelligent Insurance Underwriter)が検討すべきプロンプトまたは質問。
- レスポンス – 微調整済みモデルが生成するべき理想の回答の例。
これらのデータセットは、モデルのファインチューニング(fine-tuning:微調整)フェーズの基盤を形成しました。
データセット作成を簡素化するため、参加者には AWS が提供する PartyRock アプリケーションへのアクセス権が付与されました。このアプリケーションは、データの生成とエクスポートを行うための使いやすいインターフェースを提供しています。完了後、データセットは Amazon Simple Storage Service (Amazon S3) にアップロードされ、モデルのファインチューニングの入力として機能しました。
ファインチューニング中、参加者は以下の項目を含むがこれらに限定されない一連のパラメータ(ハイパーパラメータ)を調整し、ファインチューニングに影響を与えることができました:
- エポック数 – ファインチューニングプロセスがデータセットを通過する回数。
- 学習率 – モデルがデータを通過するたびに適用される更新に対する重み付け。
ファインチューニング完了後、参加者はカスタマイズした言語モデルを Amazon SageMaker にデプロイし、エンドポイントを使用して推論(inference:推論処理)を行いました。これにより、微調整済みモデルがサンプルとなる保険関連の問い合わせに対してどのように応答するかを観察し、出力の品質を評価することが可能になりました。
参加者間の結果にはばらつきがありました。いくつかのファインチューニング済みモデルは、文脈に即した強力で関連性の高い回答を提供しましたが、他のモデルでは「過学習(overfitting)」の兆候が見られました。これは、モデルが訓練データを過度に正確に学習してしまう状態であり、新しい入力に対して反復的または無関係な応答を引き起こす原因となります。例えば、過剰に訓練されたモデルは、未知のシナリオへの一般化よりも、データセットからのフレーズを模倣する傾向があります。これらの洞察を得た参加者は、自らのモデルのパフォーマンスを評価し、AWS AI League のリーダーボードに提出すべきバージョンと、さらに改良または廃棄すべきバージョンを決定しました。この反復的なプロセスは、高性能な生成AIモデルを実現するための鍵となる要素として、実験、データ品質、およびパラメータ調整の重要性を強調するものでした。
ゲーミフィケーションが参加意欲を刺激する
ハンズオンラボやワークショップは、実践を通じて学ぶ機会を提供する優れた方法ですが、他者と競争するゲーミフィケーションの手法を取り入れることで、そのレベルは一段階向上します。アトス(Atos)は AWS AI League でこの効果を実証しました。初期のキックオフワークショップの後、アトスの参加者は最初のモデルを作成・提出し、その後 2 週間にわたるバーチャルリーグにおいて、データセットを反復的に作成または改善し、ハイパーパラメータを調整することでリーダーボード上のスコア最大化に注力しました。バーチャルラウンドが完了する頃には、アトスはゲーミフィケーション型競技会として過去最高の参加レベルを達成し、リーダーボードには 409 名の参加者が登録され、4,100 件を超えるファインチューニング済みモデルが作成されました。

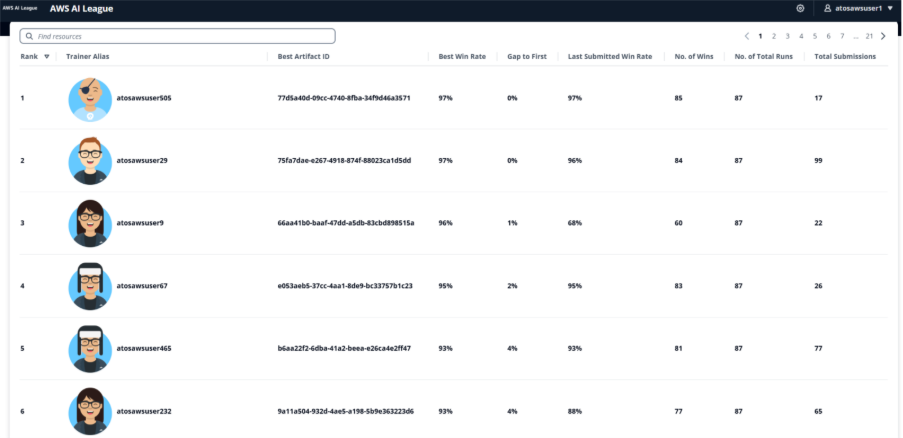
競技のゲーム化された性質にもかかわらず、コミュニケーションチャネルとオフィスアワーは、情報を共有し合う一方ですべてを明かさないようにする人々で溢れていました。これは、参加して向上したい人を十分にサポートしつつ、同時に自分自身でいくつかのことを考えさせる必要があるという素晴らしいバランスでした。この友好的な競争は非常に熾烈であり、上位 5 位に入るためには、参加者のファインチューニングされたモデルが、より大規模なモデルによって提供される回答に対して少なくとも 93% の勝率を達成する必要がありました。これは、ドメイン固有の知識に対するファインチューニング(fine-tuning)の力を示すものでした。競技の仮想ステージは完全に自動化されており、Llama 3.2 90B LLM が審査役としてスコアリングを行いました。仮想ラウンドが完了した後、上位 5 名の参加者が生放送のゲームショー形式のファイナルに進出し、12 月にラスベガスで開催される AWS re:Invent の決勝戦への出場権を争いました。
上位5位を決定するため、ライブファイナールでは追加の採点方法が導入され、ファイナリストには自らのモデルの回答に影響を与える機会も提供されました。ファイナールの採点は、LLM-as-a-Judge(LLMによる審査)に40%、アトス社の5人の人間専門家審査員に40%、観客投票に20%が割り当てられました。5ラウンドにわたる質問によりモデルのパフォーマンスを確認する十分な機会があり、各質問の間、ファイナリストはシステムプロンプティング(システム指示)と推論用のハイパーパラメータ調整(温度パラメータとtop pを用いて回答のランダム性と創造性を制御)を通じてモデル出力に影響を与えることができました。ファイナリストには推論の調整と最終回答の提出に90秒しか与えられていなかったため、非常に緊張感があり接戦となりました。
成功への道:ファインチューニングのヒント
ファインチューニング競争は、2つの主要な要素に帰着します。1つ目は、競技の主題に対して良質なデータセットを生成する参加者の能力であり、2つ目は、そのデータセットを用いてファインチューニングを行う際に最適なハイパーパラメータを見つける能力です。
AWS はデータセット生成のために PartyRock アプリケーションを提供しましたが、Atos の参加者の一部は提供されたアプリケーションからインスピレーションを得て、独自の Remix を作成しました。このアプリケーションの目的は、a) より多くのデータを生成すること、および b) AWS が提供するアプリケーションよりも改善された、多様でユニークなデータを生成することです。一部の参加者は、アクセス可能な他の生成 AI ツールを使用して独自の回答を生成しましたが、これにはシステムプロンプトの作成が必要でした。PartyRock アプリケーションは、データが正しい形式で提供されていることを確認するために(例えば)この処理を担当していました。
大規模なデータセットが必ずしもより良い結果につながるわけではないため、生成されたデータセットを見直し、どのように改善するかを検討する必要もありました。成功した参加者は、これにも生成 AI を活用し、改善方法に関する一般的な推奨事項(例:Atos のユースケースである保険分野がデータセットに欠けている場合など)を提供するとともに、データセットに対するより具体的な推奨事項とアクション(例えば、データセット内で類似しすぎた項目を削除するなど)を実行しました。その結果、新しい PartyRock アプリケーション が作成され、参加者間で共有されて改善のヒントを提供しています。
参加者は、微調整の結果に大きな影響を与えるいくつかの重要なハイパーパラメータを制御することができました。*Epochs(エポック)*は、トレーニングプロセスがデータセット全体を何回通過するかを決定します—エポック数が少なすぎるとモデルが十分に学習していないアンダーフィッティングが発生し、多すぎるとモデルが一般化能力ではなく訓練データの暗記に陥るオーバーフィッティングを引き起こす可能性があります。*Learning rate(学習率)*は、各トレーニングステップでモデルが行う更新の大きさを制御します—高い学習率はより高速なトレーニングを可能にしますが、最適な値を見逃すリスクがあり、低い学習率はより精密な調整を提供する一方で、より長いトレーニング時間を要します。
追加のパラメータには、トレーニングの安定性とメモリ使用量に影響を与える*batch size(バッチサイズ)*と、微調整プロセスの効率を制御する*Low-Rank Adaptation (LoRA) パラメータ*(lora_r や lora_alpha など)が含まれていました。成功した参加者は、ハイパーパラメータのチューニングを体系的にアプローチし、単一の値を一度に変更してその影響を分離するか、関連するパラメータを一緒に調整しながら結果を注意深く記録してパターンを特定しました。
Unde
原文を表示
*This post is co-written with Mark Ross from Atos.*
Organizations pursuing AI transformation can face a familiar challenge: how to upskill their workforce at scale in a way that changes how teams build, deploy, and use AI. Traditional AI training approaches—online courses, certification programs, and classroom-based instruction—are necessary, but often insufficient. While they build foundational knowledge, many organizations struggle with low engagement, limited hands-on practice, and a gap between theoretical understanding and real-world application. As a result, teams may earn certifications without gaining the confidence or experience required to apply AI meaningfully to business problems.
Through Atos’ partnership with AWS, we’ve long recognized that hands-on learning is the missing ingredient in effective AI enablement. When combined with structured e-learning and certification pathways, experiential learning helps translate knowledge into impact. Today, Atos employees hold over 5,800 AWS Certifications and 11 Golden Jackets, reflecting our strong foundation in cloud and AI skills. But with a commitment to achieving a 100% AI-fluent workforce by 2026, we knew we needed a learning model that could scale engagement, accelerate practical skills, and motivate engineers to apply AI in realistic scenarios.
To address this, Atos partnered with AWS to deliver a hands-on, gamified learning experience through the AWS AI League—designed to move beyond passive learning and immerse participants in real AI challenges. In this post, we’ll explore how Atos used the AWS AI League to help accelerate AI education across 400+ participants, highlight the tangible benefits of gamified, experiential learning, and share actionable insights you can apply to your own AI enablement programs.
AI enablement through the AWS AI League
While e-learning courses and certifications are an essential foundation, many organizations struggle to translate that knowledge into hands-on experience, sustained engagement, and real business impact—particularly at scale.
The AWS AI League was designed to address this gap. Rather than focusing solely on conceptual learning, the program combines hands-on experimentation with structured competition, so builders can work directly with generative AI tools used in real-world environments. For Atos, this approach offered a way to accelerate applied AI skills across the organization while maintaining engagement, collaboration, and measurable outcomes.
The AWS AI League helps builders level up their AI skills by abstracting away deep infrastructure complexity while preserving the core mechanics of model customization and evaluation. Participants work with Amazon SageMaker and Amazon SageMaker JumpStart to fine-tune large language models (LLMs), gaining practical experience with techniques that are increasingly central to enterprise AI adoption.
Why fine-tuning matters for business use cases
Fine-tuning a large language model is a form of transfer learning—a machine learning technique where a pre-trained model is adapted using a smaller, domain-specific dataset rather than being trained from scratch. For business teams, this approach offers a pragmatic path to customization: it helps reduce training time and computational cost while allowing models to reflect specialized knowledge, terminology, and decision logic.
In practice, organizations that use fine-tuning can adapt general-purpose models to specific domains where accuracy, reasoning, and explainability are critical. For Atos, this meant tailoring models to the insurance underwriting domain, where understanding risk profiles, policy conditions, exclusions, and premium calculations requires more than generic language fluency. The AWS AI League demonstrates that, with the right structure and tooling, teams across roles—including solutions architects, developers, consultants, and business analysts—can fine-tune and deploy models without requiring deep machine learning specialization. This makes fine-tuning a practical capability for partner organizations focused on delivering customer-ready AI solutions.
How the AWS AI League works
The AWS AI League follows a three-stage structure designed to build hands-on, production-oriented AI skills while maintaining momentum and engagement.The program begins with an immersive workshop that introduces the fundamentals of fine-tuning using SageMaker JumpStart. SageMaker JumpStart provides access to pre-trained foundation models through a guided interface, allowing participants to focus on model behavior and outcomes rather than infrastructure setup.Participants then move into an intensive model development phase. During this stage, teams iterate across multiple fine-tuning strategies, experimenting with dataset composition, augmentation techniques, and hyperparameter settings. Model submissions are evaluated on a dynamic leaderboard powered by an AI-based evaluation system, which benchmarks performance across a consistent set of criteria. This structure encourages rapid experimentation and makes progress visible, allowing teams to compare their customized models against larger baseline models.The program culminates in a live, interactive finale. Top-performing teams demonstrate their models through real-time challenges, with outputs evaluated using a multi-dimensional scoring system. Technical judges assess depth and correctness, an AI benchmark measures objective performance, and audience voting introduces a practical, user-oriented perspective. Together, these dimensions reinforce the League’s goal: turning hands-on learning into models that perform well in real-world scenarios.
Atos’s use case – Intelligent Insurance Underwriter
With this foundation in place, Atos selected a use case that closely reflects real customer needs: the Intelligent Insurance Underwriter. Developed through an AWS AI League event, the goal was to fine-tune a large language model capable of analyzing complex insurance scenarios and providing expert-level underwriting guidance. The model was designed to assess risk, recommend appropriate policy conditions or deductibles, suggest premium adjustments, and clearly explain the reasoning behind each decision — all while aligning with professional industry standards.This use case was chosen not as a theoretical exercise, but as a realistic example of how generative AI can support underwriting professionals by improving consistency and efficiency across insurance product lines. Built on cost-effective, fine-tuned open source models and powered by Amazon SageMaker, SageMaker Unified Studio, and Amazon S3, the solution incorporates a knowledge base alongside reasoning and recommendation modules trained on proprietary underwriting data. The result is an affordable, customized assistant that enhances team productivity, sharpens risk assessment accuracy, and integrates seamlessly with the authentic industry expertise underwriters already rely on.
Fine-tuning with Amazon SageMaker Studio and Amazon SageMaker JumpStart
AWS AI League participants do their model fine-tuning within Amazon SageMaker Studio—a fully integrated, web-based development environment for machine learning. SageMaker Studio provides a low-code/no-code (LCNC) interface to build, fine-tune, deploy, and monitor generative AI models end-to-end. By following this approach, Atos participants could focus on experimentation and innovation rather than infrastructure management, helping accelerate time-to-value. AI League now also offers customization of Amazon Nova models through serverless SageMaker model customization and agentic challenges built on top of Amazon Bedrock AgentCore.
Users follow a streamlined series of steps within Amazon SageMaker Studio:
- Select a model – SageMaker JumpStart offers a catalog of pre-trained, publicly available foundation models for tasks such as text generation, summarization, and image creation. Participants can seamlessly browse and select models from leading providers, which are pre-integrated for customization. For this competition, participants were required to fine-tune the Meta Llama 3.2 3B Instruct model, which is achieved in a no-code way utilizing Amazon SageMaker Jumpstart.
- Provide a training dataset – Datasets stored in Amazon Simple Storage Service (Amazon S3) are connected directly to SageMaker, leveraging its virtually unlimited storage capacity for fine-tuning tasks.
- Perform fine-tuning – Users can configure hyperparameters such as learning rate, epochs, and batch size before launching the fine-tuning job. SageMaker then manages the training process, including provisioning compute resources and logging progress.
- Deploy the model – Once training is complete, participants can deploy their models directly from SageMaker Studio for inference or import them into Amazon Bedrock, which provides a fully managed environment for scalable production deployment.
- Evaluate and iterate – During the AWS AI League, evaluation was performed using LLM-as-a-Judge, an internal judging system that automatically scored models on quality, accuracy, and responsiveness.
This simplified workflow, depicted above, shows the AWS AI League model development lifecycle and how it helps reduce the complexity of developing and operationalizing specialized AI models, while preserving performance, transparency, and cost-efficiency. For Atos, this hands-on process provides a practical, production-ready foundation for extending generative AI capabilities into customer-facing solutions. Participants were required to generate insurance use case datasets in JSON Lines (JSONL) format. Each record consisted of two fields:
- Instruction – the prompt or question for the Intelligent Insurance Underwriter to consider.
- Response – an example of the ideal answer the fine-tuned model should produce.
These datasets formed the foundation for the model fine-tuned phase.
To simplify dataset creation, participants were given access to an AWS provided PartyRock application which offered an simple-to-use interface for generating and exporting data. Once complete, the datasets were uploaded to Amazon Simple Storage Service (Amazon S3), where they served as the input for model fine-tuning.
During fine-tuning, participants could adjust a range of hyperparameters to influence the fine-tuning including, but not limited, to the following:
- Epochs – The number of times the fine-tuning process will pass over the dataset .
- Learning rate – The weighting applied to the updates the model makes each time it passes over the data.
After fine-tuning, participants deployed their customized language models in Amazon SageMaker and used the endpoints to perform inference. This allowed them to observe how the fine-tuned models responded to sample insurance queries and assessed the quality of their outputs
Results varied across participants. Some fine-tuned models delivered strong, contextually relevant answers, while others displayed signs of *overfitting* — a condition where a model learns the training data too precisely, leading to repetitive or irrelevant responses when exposed to new inputs. Overtrained models, for instance, tend to echo phrases from the dataset rather than generalizing to unseen scenarios. Armed with these insights, participants evaluated their models’ performance and determined which versions to submit to the AWS AI League leaderboard and which to refine or discard. This iterative process emphasized experimentation, data quality, and parameter tuning as key success factors in achieving high-performing generative AI models.
Gamification ignites participation.
Hands-on labs and workshops are a great way to provide people with an opportunity to learn by doing but providing a gamified approach where you’re competing with other people takes it to another level. Atos saw this with the AWS AI League. Following an initial kick-off workshop, Atos participants created and submitted initial models, before turning their approach to maximizing their scores on the leaderboard by iteratively creating or improving their datasets and tuning their hyperparameters over a two-week virtual league. By the completion of the virtual round, Atos had their best level of engagement for a gamified competition, with 409 participants on the leaderboard, with over 4,100 fine-tuned models having been created.
Despite the gamified nature of the competition, communication channels and office hours were full of people balancing sharing information with each other whilst avoiding giving everything away. It was a great balance which made sure those that wanted to take part and improve were supported enough, whilst also having to figure some things out for themselves. The friendly competition was incredibly fierce at the same time, and to make the top five a participant’s fine-tuned model was required to achieve at least a 93%-win rate against the answers provided by a much larger model, showing the power of fine-tuning for domain specific knowledge. The virtual stage of the competition was fully automated with a Llama 3.2 90B LLM as a judge providing the scoring. Upon completion of the virtual round, the top five participants were taken forward to a live gameshow finale, competing for a spot in the AWS finals during AWS re:Invent Las Vegas in December.
To rank the top five, the live finale introduced additional scoring methods, as well as providing the finalists with an opportunity to influence their model’s response. Finale scoring was split between 40% for LLM-as-a-Judge, 40% between our five human expert judges from Atos, and 20% for audience voting. Five rounds of questions provided an ample chance to check out the model’s performance, and during each question the finalists were able to influence model output with some system prompting, and hyperparameter tuning for inference (temperature and top p to control the randomness and creativity of the answer). Finalists only had 90 seconds to tune their inference and submit their final answers, so it was a tense and close competition.
Tips to fine-tune your way to success
The fine-tuning competition comes down to two key elements – the participants’ ability to generate a good dataset for the subject of the competition, and an ability to find the optimal hyperparameters to use for fine-tuning with the dataset.
Whilst AWS provided a PartyRock application to generate a dataset, some of the Atos participants took inspiration from the provided application and remixed their own. The idea of this application was to a) generate more data and b) generate diverse and unique data, both improvements over the AWS provided application. Some participants chose to use alternative generative AI tools they had access to, to generate their own responses, but this required them to create system prompts that the PartyRock application took care of to verify data was provided in the right format, for example.
Larger datasets didn’t necessarily lead to better results, so there was also a requirement to review the datasets that had been generated and work out how to improve them. Successful participants also used generative AI for this, with general recommendations on how to improve (e.g. for the Atos use case areas of insurance that may have been missing from the dataset), as well as more specific recommendations and actions being taken on the dataset, for example removing items in the dataset that were too similar. This resulted in a new PartyRock application being created and shared amongst participants to provide improvement tips.
Participants had control over several critical hyperparameters that significantly influenced fine-tuning outcomes. *Epochs* determine how many times the training process passes over the entire dataset—too few epochs result in underfitting where the model hasn’t learned enough, while too many can cause overfitting where the model memorizes training data rather than generalizing. *Learning rate* controls the magnitude of updates the model makes during each training step; a high learning rate enables faster training but risks overshooting optimal values, while a low learning rate provides more precise adjustments but requires longer training time.
Additional parameters included *batch size*, which affects training stability and memory usage, and *Low-Rank Adaptation (LoRA) parameters* such as lora_r and lora_alpha, which control the efficiency of the fine-tuning process. Successful participants approached hyperparameter tuning systematically, either changing single values at a time to isolate their effects or adjusting related parameters together while carefully logging results to identify patterns
Unde
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み