GPT-5.5 登場後、エンジニアの間で Codex への支持が高まる
Anthropic の価格改定により、Claude のインタラクティブ利用と API 利用のクレジット体系が明確化された一方、開発者からは過去の割引優遇の終了を「 rug pull(詐欺)」と捉える声が上がっている。
キーポイント
Claude の新価格モデルと利用区分
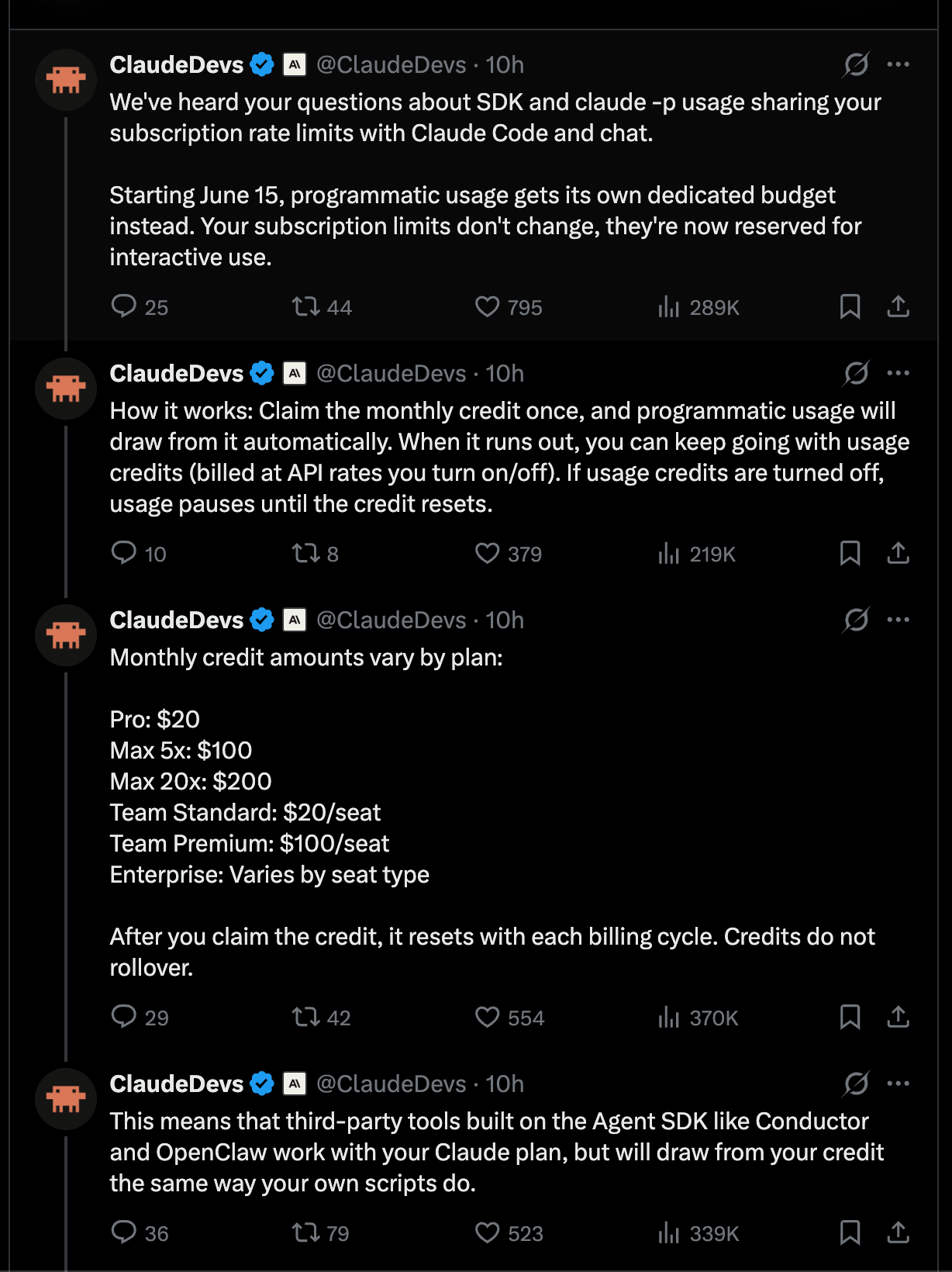
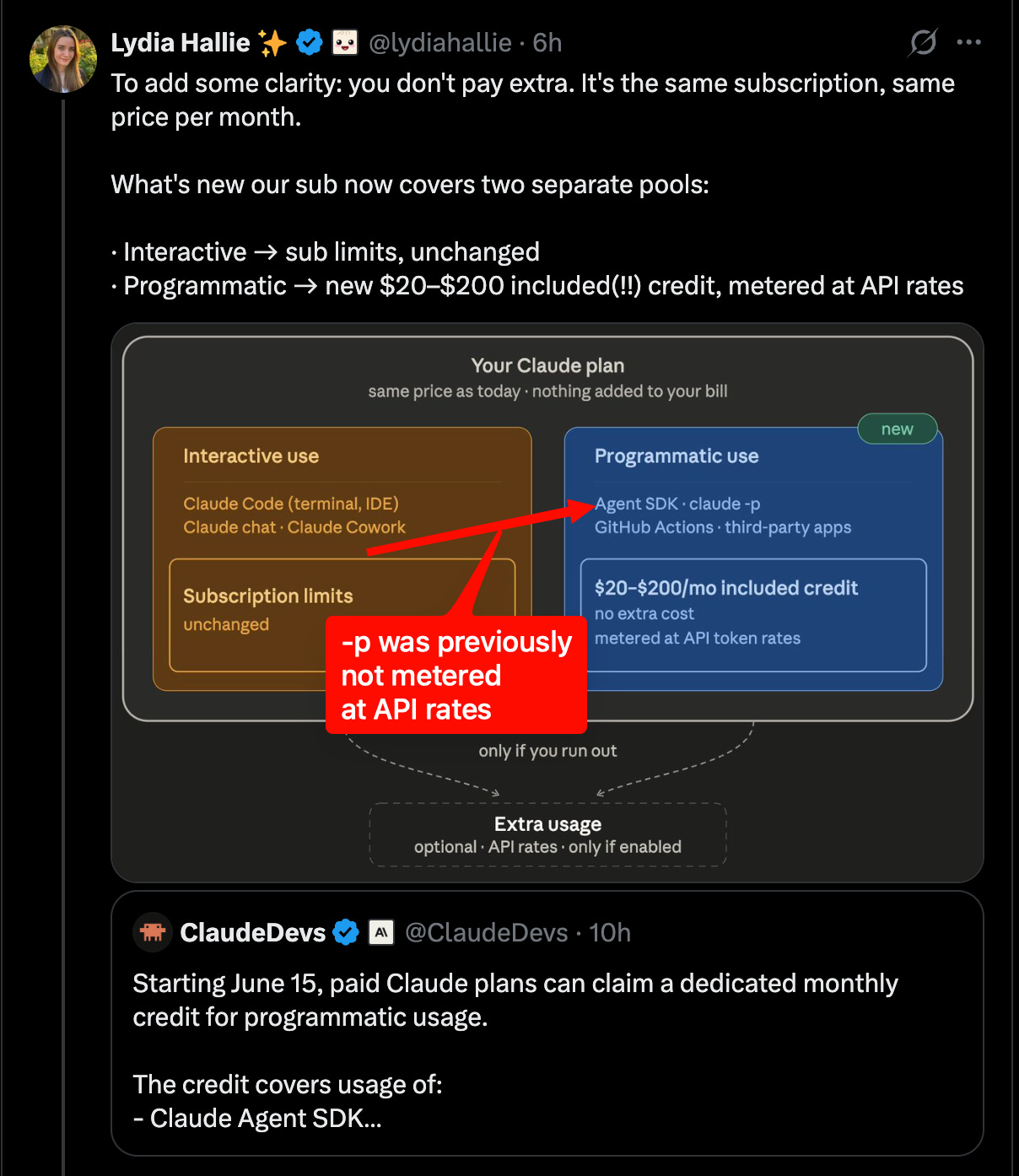
サブスクリプション料額に相当する API クレジットが付与される仕組みとなり、インタラクティブ利用(Anthropic 公式 harness)とプログラム利用(外部 harness)が明確に分離された。
開発者コミュニティの反応
過去に享受していた API 価格に対する大幅な割引(70-90%)が終了したことで、一部からは「 rug pull」という批判的な見方が出ている。
OpenAI との同時発表
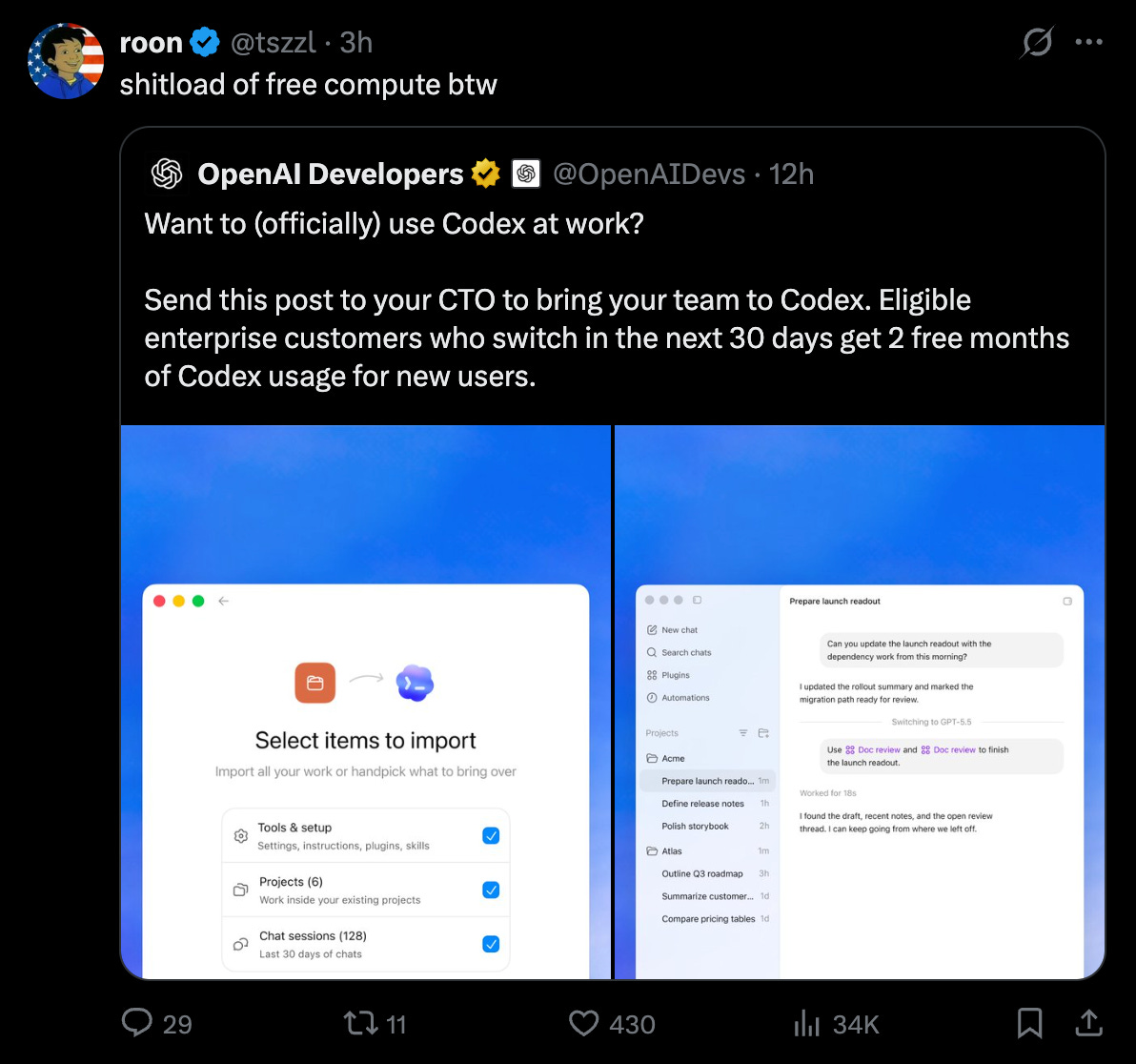
Anthropic の価格改定と同日に OpenAI が企業向けプロモーションを開始しており、両社とも業界標準の確立に向けて価格戦略を調整している状況にある。
価格戦略の逆転と市場動態
Anthropic は Claude Code のブランド確立に伴い、自社ツールに有利な価格設定を維持し他社をメーターリングする一方、対抗馬の Codex はより寛容な価格戦略を採用している。
エージェントインフラとプラットフォームの深化
Cline が SDK のオープンソース化でカスタムエージェントの基盤を強化し、LangChain が高速な観測データベース(SmithDB)や管理型ディープエージェントを提供するなど、開発者エコシステムが成熟している。
Notion における外部エージェントの統合
Notion の External Agents API により、Claude や Codex など複数の外部エージェントが Notion 内で直接動作し、共有かつレビュー可能なコンテキストレイヤーとして機能するようになった。
エージェント UX の進化:状態管理とオーケストレーションへ
チャット中心から、数週間〜数月にわたるジョブを処理するステートマシン、ストリーミング、およびツールネイティブな UI へと設計方向が移行しており、生産環境では永続的な実行と可視化可能な中間状態が不可欠となっている。
影響分析・編集コメントを表示
影響分析
この価格改定は、AI エンジニアリングにおけるコスト構造を根本から変えるものであり、開発者が外部 harness を利用する際の予算計画に直結する重要な転換点です。短期的には一部のユーザーからの反発を招く可能性がありますが、長期的には業界全体で透明性のある価格体系が確立されることで、市場の成熟を加速させる要因となります。
編集コメント
価格改定はビジネスモデルの成熟を示す必然的なステップですが、開発者コミュニティへの説明と移行支援が今後の信頼維持の鍵となります。
GPT-5.5 の発売から過去3週間は、二つの都市の物語でした。金融関係者は Anthropic の成長と、おそらく10 月の IPO を控えた CFO に魅了されている一方で、AI エンジニアの間では Codex 支持の感情が顕著に高まっています。これは、GPT-5.5 が非常に優れたモデル(一部のシナリオでは神話的レベル)であること、Codex for Everything Else の発売、そして今日のコラムの引き金となった第三の要因——より寛容な制限——の組み合わせによるものと思われます。
Claude の価格変更に関するメッセージングは全体的に非常にうまく機能しており、単に代替のハーンセス(harness)を利用するユーザーが聞きたくない内容だったというだけです。すべての Claude サブスクリプションには、月額 API トークンのクレジットが、Claude サブスクリプションプランのドル額と等しく付与されます。つまり、200 ドルを支払えば、Anthropic が所有するハーンセス(Claude.ai や Claude Code など)で Claude を利用するための独自の制限を持つ Claude サブスクリプション「インタラクティブな使用」と、claude-p、OpenClaw などを除くその他の場所での Claude の利用「プログラム的な使用」に使える200 ドル分の API クレジットの両方が得られます。
もし最初からこのように機能していれば、非常に良い取引として見られたはずです。
しかし、歴史的な補助金/価格設定の優遇措置(API 価格から推定 70〜90% の割引)があるため、人々はこれを一種の「 rug pull」(詐欺的な撤退)と捉えています。ただし、OpenClaw や OpenCode に対する選択的な標的化や、あまり使われていないハーンセスの不確実な状況とは対照的に、公式の方針が整備されているのは歓迎すべきことです。
これらの見出し記事が、OpenAI が企業向けスイッチプロモーションを開始した同じ日に発表されたことは、信じられないほどの偶然です:
結局のところ、どちらの方向への変動にも過度に読み込みすぎないよう注意を促したい。両方のラボは非常に順調であり、これは数十年続く業界を揺さぶりながらコーディングの未来を創り出しつつ最適な価格設定を探っている人々による、大局的には通常の価格シフトである。
Anthropic は当初よりやや寛容な姿勢だったが、今や Claude Code が持続可能なブランドとエージェント・ハネスとしての影響力を獲得したことで、Anthropic は自社のツールに対して最も有利な価格設定を適用し、それ以外のすべてをメーターリング(使用量計測)している。一方、挑戦者である Codex はあらゆる面でより寛容な姿勢をとっている。
もしかするとハードウェアが運命を決めるのかもしれない。あるいはこれは「mandate equinox(権限の春分点)」と呼ばれる、6 ヶ月周期で交互に訪れる長いサイクルの一部なのかもしれない。
2026 年 5 月 12 日〜13 日の AI ニュース。私たちは 12 のサブレッドと 544 の Twitter 投稿を確認し、Discord については追加情報はありませんでした。AINews のウェブサイトでは過去のすべての号を検索できます。念のためにお知らせしますが、AINews は現在 Latent Space の一部となっています。メールの配信頻度を選択・解除することも可能です!
AI Twitter リキャップ
エージェント基盤、ハネス、および開発者プラットフォーム
Cline、LangChain、Notion、Cursor はすべて、エージェントプラットフォームの領域にさらに深く進出しました。Cline は再構築された Cline SDK をオープンソース化し、TUI(ターミナルユーザーインターフェース)を備えた CLI を刷新して、エージェントチーム、スケジュールジョブ、コネクタ機能を追加し、そのハルネスをカスタムコーディングエージェントのための再利用可能な基盤として位置づけました。LangChain は Interrupt で、エージェントライフサイクルのインフラストラクチャ一大群をリリースしました:LangSmith Engine、SmithDB、サンドボックス、マネージドディープエージェント、LLM ゲートウェイ、コンテキストハブ、そして Deep Agents 0.6 です。技術的に最も注目すべき点は SmithDB で、これは大規模なペイロードを持つネスト型・長時間実行のトレース専用の観測性データベースであり、主要なワークロードで 12~15 倍の高速アクセスを実現したと報告されています。チームによると、これは Apache DataFusion と Vortex を基盤に構築されています。並行して、Notion の External Agents API は、Claude、Codex、Cursor、Decagon、Warp、Devin などのサードパーティ製エージェントが、別のサイロではなく、共有かつレビュー可能なコンテキストレイヤーとして Notion 内で直接動作することを可能にします。Cursor は、クローンされたリポジトリ、依存関係、バージョン履歴、ロールバック機能、スコープ付きの外部通信制限(egress)、隔離されたシークレットを含む、完全に設定済みの開発環境を備えたクラウドエージェントを拡大しました。
エージェント UX は、チャットよりもむしろ長期間実行される状態管理、ストリーミング、そしてオーケストレーション increasingly 重要になっています。複数の新機能リリースが同じデザイン方向に収束しました。Duet Agent は数週間から数ヶ月続くジョブのためのステートマシンハネスを提案し、親エージェントと子エージェントの調整やメモリ管理によってデータ圧縮を代替します。LangChain のオープンソースアップデートでは、ストリーミング型投影、チェックポイント保存、コードインタプリタ、ハネスプロファイル、モデル固有のチューニングが追加され、単なるトークンよりも豊かなエージェントイベントストリームを実現することを目指しています。Tabracadabra は自動補完からあらゆるテキストボックスで文脈を認識するアシスタントへと進化し、VS Code ではエージェントウィンドウが導入され、複数プロジェクトにわたるタスクレビューの改善が行われました。これらのリリース全体を通じて示されるアーキテクチャ上のメッセージは、本番環境のエージェントには、状態レスのプロンプト/レスポンスループではなく、永続的な実行、検証可能な中間状態、そしてツールネイティブな UI サフェースがますます必要であるということです。
モデルトレーニング、アーキテクチャ、およびデータ効率
事前学習の効率化とアーキテクチャの実験が、最も一貫した研究の糸となっていました。Nous Research の Token Superposition Training は、事前学習の初期段階を修正し、モデルが連続するトークンの塊を読み込んで予測した後、標準的な次トークン予測に戻る仕組みです。彼らは、FLOPs を同等に保ちながら推論時のアーキテクチャ変更なしで 2~3 倍の実行速度向上を実現したと報告しており、これは 270M から 3B の密集型モデルおよび 10B-A1B の MoE モデルで検証されています。Jonas Geiping らは、現在のメッセージベース/チャットトレーニングがエージェントを単一のストリームに過度に制約していると主張し、低レイテンシ、関心の明確な分離、より読みやすい並列推論・ツール使用を実現するマルチストリーム LLM の論文を発表しました。論文とコードはこちらでリンクされています。
δ-mem は、凍結されたフルアテンションバックボーンに外部のオンライン連想メモリを接続する提案を行いました。8×8 の状態により平均スコアが 1.10 倍向上し、非δ-mem ベースラインを 1.15 倍上回ったと報告されており、特にメモリー集約型のベンチマークではより大きな改善が見られました。
ポストトレーニング/圧縮およびデータキュレーションにおいても注目すべき結果が生み出されました:NVIDIA の Star Elastic は、1 回のポストトレーニング実行で推論モデルのサイズファミリーを導き出すことができると主張しており、そのコストは事前学習によるファミリー構築の 360 分の 1 で、SOTA(State-of-the-Art)圧縮手法よりも 7 倍優れています。Siddharth Joshi と Pratyush Maini が取り上げた Datology の VLM(Vision-Language Model:視覚言語モデル)に関する研究では、データキュレーション単独でも主要なマルチモーダル性能の向上が可能であると主張しています。具体的には、2B パラメータ規模で 20 の公開 VLM ベンチマーク全体で +11.7 ポイントの向上を達成し、InternVL3.5-2B を約 10 ポイント上回っています。これは学習計算量が約 17 分の 1 で実現されたものであり、Qwen3-VL-4B と比較して応答 FLOPs(Floating Point Operations:浮動小数点演算)が 3.3 分の一でほぼ最前線レベルの 4B パラメータ規模のパフォーマンスを達成しています。オープンデータ側では、Percy Liang が次の Marin の実行にはすでに 18T トークンが含まれていると語り、さらなる事前学習、中間トレーニング、SFT(Supervised Fine-Tuning:教師あり微調整)データの募集を続けており、そのためのコンパニオン・トークンビューアーもここで共有されています。
モデル構築と並行して、オープンな評価およびデータセットの取り組みも成熟しています:Kevin Li の SWE-ZERO-12M-trajectories は、最大のオープンエージェント追跡データセットとして位置づけられており、112B トークン、1200 万本のトラジェクトリ(経路)、122K の PR(Pull Request:プルリクエスト)、3000 のリポジトリ、16 の言語を扱っています。Victor Mustar は llama-eval を、より比較可能な llama.cpp コミュニティ評価への一歩として指摘しました。一方、Steve Rabinovich と Sayash Kapoor は、信頼できるエージェント評価には結果のみを指標とするのではなくログ分析が必要であると主張しています。その理由は、強力なエージェントほど隠されたベンチマークのバグや報酬ハッキングの経路を露呈させるからです。
エンタープライズ AI の価格設定、プラットフォーム競争、および流通
Anthropic と OpenAI の競争は、エンタープライズ向け配布と開発者ロックインの観点から激化しています。Andrew Curran が引用した Ramp のデータによると、4 月の企業採用において Anthropic は 34.4%、OpenAI は 32.3% で、ビジネス採用における最初の明確な首位交代が見られました。The Rundown も同様の数値を強調しました。同時に、Anthropic はプラン経済モデルを変更し、ClaudeDevs が発表したところによると、有料の Claude プランには、Agent SDK、claude-p、GitHub Actions、およびサードパーティ製 SDK アプリ全体でのプログラム利用(programmatic usage)のために専用月次クレジットが付与されます。これは直ちにパワーユーザーによって、サブスクリプションで補助されたハーンチ(harnesses)に対する重大な制限として解釈され、Theo、Jeremy Howard、Matt Pocock、Omar Sanseviero からの批判を招きました。Anthropic はこれに対し、7 月 13 日までの Claude Code の週間利用制限を 50% 引き上げる措置で部分的に反発を和らげました。これは以前発表された 2 倍の 5 時間制限拡大の上に重ねられたものです。
OpenAI は Codex エンタープライズ向けインセンティブを通じて攻撃的に応答しました。OpenAI Devs と Sam Altman は、今後 30 日以内に切り替えるエンタープライズ顧客に対し、Codex の利用を 2 ヶ月無料提供する方針を示しました。また OpenAI は、ローカルユーザー、ファイアウォールルール、ACL(アクセス制御リスト)、書き込み制限トークン、DPAPI(データ保護 API)、およびローカルファイルシステムやツールへのアクセスを持つコーディングエージェントを安全に実行するために必要なヘルパー実行ファイルなどを含む、Windows サンドボックス設計の技術的詳細も公開しました。現在の競争動態は、「最良のモデルが勝つ」というものよりも、「補助金+ワークフロー制御+ハーンチ互換性」のような様相を呈しています。
エンタープライズ採用は、ランタイム/セキュリティの保証とますます密接に結びついています。Perplexity は、ハードウェア隔離サンドボックスアーキテクチャを説明し、VPC レベルでの分離、短寿命のプロキシトークン、エージェントアクション前の外部コンテンツのスキャン、および暗号化と自動削除に関する追加詳細を提示しました。Aravind Srinivas 氏はこれを、Perplexity がエンタープライズ向け知識/研究プラットフォームとなるための基盤として位置づけました。より広範なパターンとして、エージェントベンダーはもはや知能だけを販売しているのではなく、制限された実行環境を販売するようになっています。
自律型科学、サイバー能力、およびロボティクス
再帰的自己改善は、アイデアからスタートアップクラスターへと移行しました。最も大きな単一のメタテーマは、科学の自動化と安全な自己改善を行う AI を構築するために設立された「Recursive」の立ち上げです。Richard Socher 氏、Josh Tobin 氏、Dominik Schmidt 氏、Jenny Zhang 氏、Shengran Hu 氏からの立ち上げ投稿は、オープンエンドネス、AI Scientist、および研究自動化の取り組みからチームが構成されていることを示唆しています。隣接する取り組みとして、Adaption の AutoScientist は、フロンティアラボの外で完全なトレーニング・研究ループを自動化することを目指しており、Sarah Hooker 氏は、モデルトレーニングの失敗の多くは計算資源の不足というよりも、研究ループの脆さによるものだと主張しています。
サイバー能力評価はさらに厳しさを増しています:英国 AI セキュリティ研究所(AISI)は、最先端モデルが完了できるサイバータスクの長さが数ヶ月ごとに倍増しており、最近のモデルは過去の傾向を上回っていると述べています。Anthropic/Glasswing の Logan Graham 氏は、Claude Mythos Preview が Cooling Tower を含む AISI のエンドツーエンドのサイバーレンジを両方とも解決した最初のモデルであり、研究所の 250 万トークン制限の下ですべてのタスクをクリアした唯一のモデルであると述べています。XBOW は「トークン対トークンで前例のない精度」を発見し、パートナーの利用により数週間で数千件の高/重大な脆弱性が表面化したと報じられています。scaling01 からの独立したコメントでは、新しい Mythos バージョンがサイバーレンジを 10 回中 6 回完了したのに対し、プレビューベースラインは 3 回中 3 回であったとされています。
ロボティクス分野では、具体的な長期展開デモが行われました:Figure の Brett Adcock は、Helix-02 を使用してパッケージ仕分けで完全な 8 時間の自律シフトを実行する二足歩行ロボットをストリーミングしました。続報によると、これらのロボットはカメラのピクセルから推論を行い、人間と同等の速度(約 3 秒/個)で動作し、オンデバイス推論を実行し、ネットワーク化されたフリートとして協調し、バッテリー残量が少なくなると自律的に交換し、必要に応じて自己診断を行いメンテナンスへフェールオーバーします。これは、短いベンチマーククリップではなく、マルチロボットによる長時間の無人オーケストレーションを明確に示した公的なデモの一つです。
主要なツイート(エンゲージメント順)
Claude Code の価格設定と制限:@ClaudeDevs が週間の利用制限を 50% 引き上げたと発表し、またプログラムによるクレジットに関する @ClaudeDevs の対応について、@theo からの開発者による反発が巻き起こりました。これにより、価格政策が当日の最も重要な開発者ニュースとなりました。
Codex の企業向け推進:@sama が切り替えユーザーに対して Codex の利用を 2 ヶ月無料提供する方針を示し、@OpenAIDevs の企業向け呼びかけも、極めて直接的な市場参入への対抗策として機能しました。
Figure の 8 時間人型ロボットシフト:@adcock_brett のライブストリーム投稿は多大な注目を集め、明確な技術的実質性を伴う数少ないバイラル投稿の一つとなりました。
Cline SDK のリリース:@cline による SDK の公開は、オープンソースのコーディングエージェント用ハネス(harness)に対する需要を反映し、真に技術的なリリースの中で最も高いエンゲージメントを記録しました。
トークン超位置学習(Token Superposition Training):@NousResearch の TST に関する投稿は、推論時のアーキテクチャを変更せずにトレーニング速度を 2~3 倍向上させるという具体的な主張が経済的に重要であるため、広く認知された稀な事前学習手法に関するツイートとして際立っていました。
AI Reddit まとめ
/r/LocalLlama および /r/localLLM のまとめ
- エッジデバイスにおける効率的な大規模言語モデル(LLM)推論
続きを読む
原文を表示
It has been a tale of two cities in the past 3 weeks since the launch of GPT 5.5; while the finance folks fall in love with Anthropic’s growth and CFO ahead of its likely October IPO, there has been a notable rise in pro-Codex sentiment among AI Engineers, likely a combination of GPT 5.5 being a really good (in some scenarios Mythos-tier) model, launch of Codex for Everything Else, and, a third thing, which is the trigger for today’s op-ed: more generous limits.
The messaging for Claude’s pricing change was generally pretty well done, it is simply not what uses of alternative harnesses wanted to hear: every Claude subscription now gets a monthly credit of API tokens equal to the dollar amount of the Claude subscription plan. So you pay $200, you get BOTH a Claude subscription with its own limits for using Claude on Anthropic-owned harnesses like Claude.ai and Claude Code (“interactive usage”), AND $200 worth of API credits for using Claude everywhere else including claude-p, OpenClaw and others (“programmatic usage”).
If things had worked this way from the start, it would have been viewed as a very good deal:
However, because of the historical subsidy/pricing advantages (estimated between 70-90% discount from API pricing), people are viewing it as a “rug pull” of sorts — however it’s nice to have an official policy in place as opposed to the selective targeting of OpenClaw, OpenCode, and uncertain status of less popular harnesses.
That these headlines come on the same day as OpenAI launches their enterprise switch promo is an incredible coincidence:
At the end of the day, we would caution against reading too much into swings either way - both labs are doing very well, and these are in the grand scheme of things normal pricing shifts by people inventing the future of coding while figuring out optimal pricing as they shake up a decades-old industry. Anthropic was more liberal in the beginning, but now that Claude Code has a sustainable brand and clout as an agent harness, Anthropic is putting its most favorable pricing behind its own tools and metering everything else, whereas Codex as the challenger is being more liberal with everything.
Perhaps hardware is destiny, perhaps this is part of a longer 6 month alternating cycle of the “mandate equinox”:
AI News for 5/12/2026-5/13/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Agent Infrastructure, Harnesses, and Developer Platforms
Cline, LangChain, Notion, and Cursor all pushed deeper into agent platform territory: Cline open-sourced a rebuilt Cline SDK and refreshed CLI with a TUI, agent teams, scheduled jobs, and connectors, positioning its harness as a reusable substrate for custom coding agents. LangChain shipped a large batch of agent lifecycle infrastructure at Interrupt: LangSmith Engine, SmithDB, Sandboxes, Managed Deep Agents, LLM Gateway, Context Hub, and Deep Agents 0.6. The most technically notable piece is SmithDB, a purpose-built observability database for nested, long-running traces with large payloads, reportedly yielding 12–15× faster access on key workloads; the team says it is built atop Apache DataFusion and Vortex. In parallel, Notion’s External Agents API lets third-party agents such as Claude, Codex, Cursor, Decagon, Warp, and Devin operate directly inside Notion as a shared, reviewable context layer rather than another silo. Cursor expanded cloud agents with fully configured development environments including cloned repos, dependencies, version history, rollback, scoped egress, and isolated secrets.
Agent UX is increasingly about long-running state, streaming, and orchestration rather than chat: Several launches converged on the same design direction. Duet Agent proposes a state-machine harness for jobs that last weeks or months, with parent/sub-agent coordination and memory replacing compaction. LangChain’s OSS updates added streaming typed projections, checkpoint storage, code interpreter, harness profiles, and model-specific tuning, all aimed at richer agent event streams than plain tokens. Tabracadabra moved from autocomplete to a context-aware assistant in any textbox, while VS Code introduced an Agents window and better multi-project task review. The architectural message across these releases is that production agents increasingly need durable execution, inspectable intermediate state, and tool-native UI surfaces rather than stateless prompt/response loops.
Model Training, Architecture, and Data Efficiency
Pretraining efficiency and architectural experimentation were the strongest research throughline: Nous Research’s Token Superposition Training modifies the early phase of pretraining so the model reads/predicts contiguous bags of tokens before reverting to standard next-token prediction; they report 2–3× wall-clock speedup at matched FLOPs with no inference-time architecture change, validated from 270M to 3B dense and 10B-A1B MoE. Jonas Geiping et al. argued current message-based/chat training overly constrains agents to a single stream and released a multi-stream LLM paper claiming lower latency, cleaner separation of concerns, and more legible parallel reasoning/tool use; paper and code are linked here. δ-mem proposed an external online associative memory attached to a frozen full-attention backbone, with an 8×8 state reportedly improving average score by 1.10× and beating non-δ-mem baselines by 1.15×, with larger gains on memory-heavy benchmarks.
Post-training/compression and data curation also produced notable results: NVIDIA’s Star Elastic claims one post-training run can derive a family of reasoning model sizes, at 360× lower cost than pretraining a family and 7× better than SOTA compression. Datology’s VLM work, highlighted by Siddharth Joshi and Pratyush Maini, argues data curation alone can produce major multimodal gains: +11.7 points across 20 public VLM benchmarks at 2B, beating InternVL3.5-2B by roughly 10 points at about 17× less training compute, and near-frontier 4B performance with 3.3× lower response FLOPs than Qwen3-VL-4B. On the open data side, Percy Liang said the next Marin run already has 18T tokens in its mix and is still seeking more pretraining, mid-training, and SFT data, with a companion token viewer shared here.
Open evaluation and dataset work is maturing alongside model building: Kevin Li’s SWE-ZERO-12M-trajectories is positioned as the largest open agentic trace dataset: 112B tokens, 12M trajectories, 122K PRs, 3K repos, 16 languages. Victor Mustar flagged llama-eval as a step toward more comparable llama.cpp community evals. Meanwhile, Steve Rabinovich and Sayash Kapoor argued credible agent evaluation requires log analysis, not outcome-only metrics, because stronger agents expose hidden benchmark bugs and reward-hacking paths.
Enterprise AI Pricing, Platform Competition, and Distribution
Anthropic vs OpenAI competition sharpened around enterprise distribution and developer lock-in: Ramp data cited by Andrew Curran showed Anthropic at 34.4% of businesses vs OpenAI at 32.3% in April, the first apparent lead change in business adoption; The Rundown amplified the same figures. At the same time, Anthropic changed plan economics: ClaudeDevs announced that paid Claude plans will get a dedicated monthly credit for programmatic usage across the Agent SDK, claude -p, GitHub Actions, and third-party SDK apps. This was immediately read by power users as a major restriction on subscription-subsidized harnesses, with criticism from Theo, Jeremy Howard, Matt Pocock, and Omar Sanseviero. Anthropic partially offset that backlash with a separate 50% increase in Claude Code weekly limits through July 13, stacked on the previously announced 2× 5-hour limit increase.
OpenAI responded aggressively with Codex enterprise incentives: OpenAI Devs and Sam Altman offered two months of free Codex usage for enterprise customers switching in the next 30 days. OpenAI also published more technical platform detail, including a Windows sandbox design write-up describing the combination of local users, firewall rules, ACLs, write-restricted tokens, DPAPI, and helper executables needed to safely run coding agents with local filesystem/tool access. The competitive dynamic now looks less like “best model wins” and more like subsidy + workflow control + harness compatibility.
Enterprise adoption is increasingly tied to runtime/security assurances: Perplexity described a hardware-isolated sandbox architecture with VPC-level separation, short-lived proxy tokens, and scanning of external content before agent actions, with additional details on encryption and auto-deletion. Aravind Srinivas framed this as foundational to Perplexity becoming an enterprise knowledge/research platform. The broader pattern: agent vendors are no longer selling only intelligence; they’re selling bounded execution environments.
Autonomous Science, Cyber Capability, and Robotics
Recursive self-improvement moved from idea to startup cluster: The largest single meta-theme was the launch of Recursive, founded to build AI that automates science and safely improves itself. Launch posts from Richard Socher, Josh Tobin, Dominik Schmidt, Jenny Zhang, and Shengran Hu suggest a team drawn from open-endedness, AI Scientist, and research automation work. In adjacent work, Adaption’s AutoScientist aims to automate the full training-research loop outside frontier labs, with Sarah Hooker arguing that most model training failures are due to research-loop brittleness rather than mere compute scarcity.
Cyber capability evaluations continue to steepen: The UK AI Security Institute said the length of cyber tasks frontier models can complete has been doubling every few months, and that recent models are beating prior trends. Anthropic/Glasswing’s Logan Graham said Claude Mythos Preview is the first model to solve both AISI end-to-end cyber ranges, including Cooling Tower, and the only one to clear every task under the institute’s 2.5M-token cap. XBOW reportedly found “token-for-token, unprecedented precision,” and partner usage allegedly surfaced thousands of high/critical vulnerabilities in weeks. Independent commentary from scaling01 claimed a newer Mythos version completed a cyber range 6/10 times vs 3/10 for the preview baseline.
Robotics got a concrete long-horizon deployment demo: Figure’s Brett Adcock streamed humanoid robots running a full 8-hour autonomous shift on package sorting using Helix-02, with follow-up details that the robots reason from camera pixels, operate around human parity (~3s/package), perform on-device inference, coordinate as a networked fleet, autonomously swap for low battery, and self-diagnose/fail over to maintenance when needed here. This is one of the clearer public demonstrations of multi-robot, long-duration, no-human-in-the-loop orchestration rather than a short benchmark clip.
Top tweets (by engagement)
Claude Code pricing and limits: @ClaudeDevs on 50% higher weekly limits, @ClaudeDevs on programmatic credits, and the ensuing developer backlash from @theo made pricing policy the day’s most consequential developer story.
Codex enterprise push: @sama offering two free months of Codex usage for switchers and @OpenAIDevs’ enterprise call-to-action signaled an unusually direct go-to-market counterpunch.
Figure’s 8-hour humanoid shift: @adcock_brett’s livestream post drew enormous attention and is one of the few viral posts in the set with clear technical substance.
Cline SDK launch: @cline’s SDK release was one of the highest-engagement genuinely technical launches, reflecting demand for open coding-agent harnesses.
Token Superposition Training: @NousResearch’s TST post stood out as a rare pretraining-method tweet that broke through widely, likely because the claim—2–3× training speedup without changing inference-time architecture—is concrete and economically important.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
- Efficient On-Device LLM Inference
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み