Seedance が話題を呼ぶ、Nvidia の AI 活用チップ設計、ロボットの記憶保持支援
Seedance が注目を集め、Nvidia は AI を活用したチップ設計を発表し、ロボットが情報を忘れないよう支援する技術が開発された。
親愛なる皆様、
AI による雇用崩壊は起こりません。
AI が大規模な失業をもたらすという物語は、不必要な恐怖を煽るものです。AI も他の技術と同様に雇用に影響を与えますが、大規模な失業に関する誇張された話を広めることは無責任であり、有害です。これを止めにしましょう。
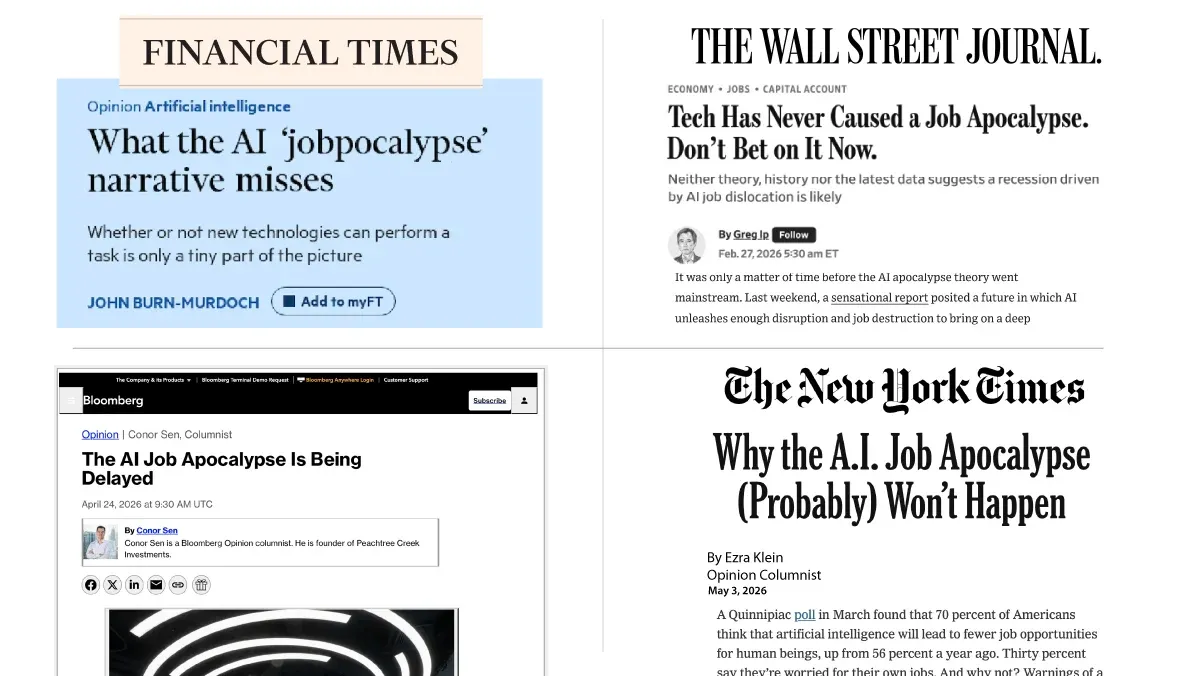
私は以前の書簡で、雇用崩壊説に対して懐疑的な見解を示してきました。今や一般メディアがこの物語に反論し始めているのを見て嬉しく思います。以下の画像には、最近の見出しがいくつか掲載されています。
コーディングエージェントが先を争って進む中、ソフトウェアエンジニアリング分野は AI ツールによって最も大きな影響を受けています。しかし、ソフトウェアエンジニアの採用は依然として堅調です。AI が職を奪う事例が存在する一方で、全体的な傾向は、技術の以前の波と同様に、ネットでの雇用創出が雇用の喪失を大幅に上回っていることを強く示唆しています。さらに、AI におけるすべての目覚ましい進歩にもかかわらず、米国の失業率は健全な 4.3% を維持しています。
なぜ AI による職の終焉という物語がこれほど人気があるのでしょうか?その理由の一つは、最先端の AI ラボには、AI 技術をより強力なものとして見せるような物語を語る強い動機があるからです。極端な場合、彼らは AI が「支配」して人類を絶滅させるという SF シナリオを推進します。ある技術が多くの従業員を代替できるなら、その技術は確かに非常に価値があるに違いない!
また、多くの SaaS ソフトウェア会社はユーザーあたり年間 100 ドルから 1,000 ドル程度を請求しています。しかし、AI 企業が年収 10 万ドルの従業員を代替したり、生産性を 50% 向上させたりできるのであれば、1 万ドルという料金でも妥当に見えてきます。典型的な SaaS の価格ではなく、従業員の給与に基準を置くことで、AI 企業ははるかに高い料金を請求できるようになるのです。
 imageさらに、企業側には、レイオフ(人員削減)が AI によって引き起こされたかのように語る強い動機があります。結局のところ、少ないスタッフで AI を活用してはるかに生産性を高めていると話すことは、彼らを賢く見せることになります。これは、金利の低下と巨額の政府財政刺激策により資本が豊富だったパンデミック期間中に過剰採用を行ったことを認めるよりも、はるかに良いメッセージなのです。
imageさらに、企業側には、レイオフ(人員削減)が AI によって引き起こされたかのように語る強い動機があります。結局のところ、少ないスタッフで AI を活用してはるかに生産性を高めていると話すことは、彼らを賢く見せることになります。これは、金利の低下と巨額の政府財政刺激策により資本が豊富だったパンデミック期間中に過剰採用を行ったことを認めるよりも、はるかに良いメッセージなのです。
明確に言っておきますが、AI が多くの人々の仕事を大きく変えていることは認識しています。これは困難です。ストレスを伴います。(そして、ある人々にとっては楽しいことでもあります。)影響を受けるすべての人に共感します。同時に、これは労働市場の崩壊を予測することとは全く異なります。
社会は、現実の根拠がほとんどなく、社会全体の意思決定を誤らせるような物語を何年も語り続けることができます。例えば、原子力発電所の安全性への懸念が、原子力発電への投資不足につながりました。1960 年代における「人口爆弾」への恐怖は、各国に厳しい人口削減政策の実施をもたらしました。また、食事の脂肪分への不安から、政府は何十年もの間、不健康な高糖質食を推進してきました。
今や主流メディアが雇用崩壊説に対して公然と懐疑的になっているので、これらの物語も力を失い始めることを願っています(AI による人類絶滅への恐怖と同様に)。
AI による雇用崩壊という予測とは逆に、私はその逆を予言します:AI による雇用拡大の波が到来するでしょう!AI は多くの良い AI エンジニアリング職を生み出し、私は全体的な労働市場の未来にも楽観的です。AI エンジニアが行う仕事は従来のソフトウェアエンジニアリングとは異なり、これらの職の多くは開発者を伝統的に大規模に雇用してきた企業以外の分野で生まれます。AI に関与しない役割においても、必要なスキルは AI の影響によって変化します。だからこそ、今こそより多くの人々に AI に精通するよう促し、未来の多様でありながら豊富な仕事に備えておくことが重要なのです!
引き続き構築を続けましょう。
アンドリュー
DEEPLEARNING.AI からのメッセージ
ほとんどのエージェントはテキストで応答しますが、チャートやフォーム、インタラクティブなユーザーインターフェースをレンダリングするエージェントの構築方法を学びましょう。このコースでは、LangChain エージェントを React フロントエンドに接続し、生成型ユーザーインターフェースのスペクトラム全体にわたって構築します。最終的には、ユーザーとエージェントが共有状態上で作業できるフルスタックアプリを完成させます。無料で登録する
ニュース

ByteDance が動画分野でのリーダーシップを確立
OpenAI が Sora の運用を終了する準備を進める中、ByteDance は独自の動画生成モデルを数億人のユーザーに提供しました。
何の新情報: ByteDance は、その多モーダル動画生成モデルである Seedance 2.0 を、人気のある動画編集アプリ CapCut に追加しました。今年初めに中国で発売されたこのモデルは、現在、東南アジア、ラテンアメリカ、アフリカ、中東、ヨーロッパの一部、日本、そして米国における有料の CapCut ユーザーにも提供されています。
- 入力/出力:テキスト、画像、オーディオ、ビデオ(最大 3 クリップの動画、9 枚の画像、3 クリップの音声)、同期されたビデオおよびオーディオ出力(短辺が 480 または 720 ピクセルで 6 つのアスペクト比:21:9、16:9、4:3、1:1、3:4、9:16 のいずれかで 4〜15 秒)
- 機能:多言語でのリップシンクロ対応の対話、環境音、音楽、カットを含む単一クリップ内の複数のカメラアングル、プロンプトによるカメラおよび照明制御、不可視ウォーターマークによる出力マーキング、CapCut を経由した実在する顔や著作権のあるキャラクターを含む入力画像のブロック
- パフォーマンス:Arena AI および Artificial Analysis のビデオリーダーボードで上位 2 位以内
- 利用可能状況/価格:CapCut(中国では Jianying)の有料プラン、Dreamina ウェブインターフェース、BytePlus および Volcengine を通じた ByteDance サービスの API、Higgsfield.ai などを含むサードパーティプロバイダー経由。出力 1 秒あたり 0.30 ドル(720 ピクセル、オーディオ込み)または SeeDance 2.0 Fast による高速処理で 1 秒あたり 0.24 ドル
- 非公開:アーキテクチャ、パラメータ数、トレーニングデータおよび手法
仕組み: Seedance 2.0 は、ByteDance の以前の作業を拡張し、オーディオ・ビデオストリームを並列に同期生成するものから、統合システム内での共同生成へと移行しました。ByteDance の 発表 では、このアーキテクチャを「スパース(疎)」と特徴づけています。
- モデルは、4 つのタスクに対してビデオ・オーディオ参照入力を受け付けます:(i) 参照ベース生成では、被写体、動き、視覚効果、および/またはスタイルの手がかりを新しい出力に適用します。(ii) 編集では、既存のビデオ内の指定された領域、キャラクター、アクション、および/またはオーディオを変更します。(iii) 拡張機能は、既存のビデオに先行する、または後続する出力を生成します。(iv) 組み合わせモードでは、これらの機能をペアリングします(例:既存のビデオの被写体を参照画像からのものへ置き換える)。
- オーディオはビデオと同時に生成され、ステレオ形式の対話、効果音、および背景オーディオが作成されます。
- モデルは個別のクリップを生成して組み立てるのではなく、1 回のパスで連続するショットとカットを生成するため、キャラクターやシーンの一貫性を維持するのに役立ちます。
パフォーマンス: Seedance 2.0 は、人間による盲検投票を通じてモデルを順位付けする 2 つの独立したリーダーボードにおいて、1 位と 2 位を獲得しました。Alibaba の HappyHorse-1.0 が両方のリーダーボードで最も近い挑戦者です。
- arena.ai において、Seedance 2.0 はテキストから動画への生成性能で Elo 1,460、画像から動画への生成性能で Elo 1,454 を記録し、両カテゴリとも HappyHorse-1.0(それぞれ Elo 1,444)を僅差で上回りました。ただし、リーダーボードでは Seedance 2.0 と HappyHorse-1.0 の結果は暫定扱いとされています。
- Artificial Analysis では、アリババの HappyHorse-1.0 が音声なしの画像から動画への生成、および音声あり・なしのテキストから動画への生成を含む 4 つのカテゴリのうち 3 つで首位に立っており、Seedance 2.0 は 2 位です。一方、同期された音声を伴う画像から動画への生成性能では Seedance 2.0 が Elo 1,182 で首位に立ち、HappyHorse-1.0(Elo 1,168)や Sky Work AI の SkyReels V4(Elo 1,091)を抜いています。
- ByteDance は、詳細な安定性、「超リアルさ」、音声の歪み、複数被写体の一貫性、テキストレンダリングの精度、そして「複雑」な編集効果における限界を指摘しています。ただし: ByteDance が中国で Seedance 2.0 をリリースした直後、トム・クルーズとブラッド・ピットの顔立ちを模倣した生成動画が公開されたことを受け、ハリウッドの主要スタジオ 6 社が同社に対し、著作権素材を用いたモデルの学習停止および、著作権素材に基づく動画のユーザーによる生成ブロックを求めました。この紛争は未だ解決していません。ByteDance は CapCut に 保護措置 を追加しましたが、これらがサードパーティ製 API を経由して生成された出力にも適用されるかどうかは依然として不明です。
ニュースの背景: ビデオ生成市場は過去1ヶ月で急速に再編成されました。米国の開発者は消費者市場から撤退し、中国の開発者は加速するペースで新モデルをリリースしています。
- 3 月、OpenAI は Sora アプリおよび API の終了を発表しました。報道によると、同社は Sora の日次アクティブユーザー数がローンチ時の約 100 万人から 50 万人未満に減少したことを踏まえ、計算リソースをコーディングやビジネス製品へシフトさせました。また、このサービスの運営には一日あたり推定 100 万ドルのコストがかかっています。
- Alibaba の HappyHorse-1.0 は、4 月初旬にまだクローズドベータテスト中にもかかわらず、独立した動画リーダーボードでデビューし、複数のカテゴリで首位を獲得しました。
- その直後、Alibaba はゲームや映画の開発向けに 3D 環境を生成する AI システム「HappyOyster」を発表しました。ユーザーはテキストまたは画像から 3D 環境を生成し、リアルタイムで操作することができます。
- Tencent も同日、Hunyuan 3D の更新版をオープンソース化しました。
なぜ重要なのか: 競合他社が動画ジェネレーターか編集アプリのいずれかを提供している中、ByteDance はその両方を保有しています。さらに、同社の編集ツールは圧倒的な規模のリーチを持っています。CapCut 報道によると は、モバイル上で月間アクティブユーザー数 7.36 億人を誇り、ChatGPT に次ぐ世界第 2 位の消費者向け AI プロダクトです。Seedance 2.0 が CapCut に登場したことは、一つの企業が両方の領域を支配した場合に何が可能になるかを示しています。
私たちが考えていること: OpenAI の Sora 撤退は、ある厳しい真実を指し示しています。現在の計算コストを考慮すると、AI 生成動画は高価な消費者向け製品なのです。
Nvidia が AI を用いてチップを設計する方法
Nvidia のチーフサイエンティストは、AI モデルに新しい GPU の設計を命じ、そのシステムが作業を行う間に数日間スキーを楽しむという夢を描いています。彼は、この目標に向けた Nvidia の進捗状況と、まだ道のりの長さについて説明しました。
最新動向: Nvidia で約 300 名の研究者を率いるビル・ダリー(Bill Dally)は、3 月中旬に開催された同社の GTC コングレスでステージ上に立った Google のジェフ・ディーン氏との対談において、AI が同社チップ設計における役割を拡大している様子について説明しました。彼の例(動画の約 24 分付近から)は、チップの構成要素を配置する強化学習システムから、数十年にわたる独自文書で訓練された大規模言語モデルまで多岐にわたります。
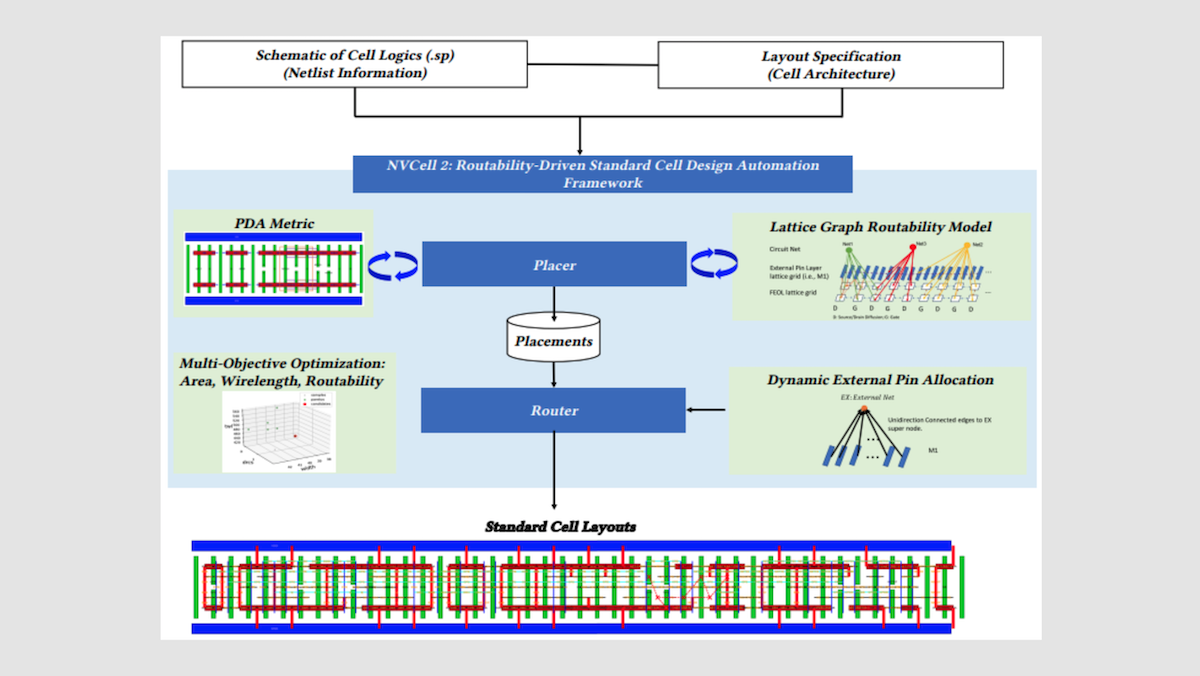
仕組み: Nvidia は、チップ設計の 5 つの段階で AI を適用しています。それは、コンポーネントのレイアウト、算術回路(加算器やカウンタなど、2 進数に対して数学的演算を行うコンポーネント)の設計、一般的なエンジニアリング支援、完成した設計の検証、そして新規なレイアウトの探索です。
- Nvidia が新しい半導体製造プロセスを活用するたびに(一般的にコンポーネントのサイズを縮小し、シリコン面積あたりに収容できる数を増やすため)、ロジックゲートやメモリアラッチなどの約 2,500〜3,000 の再利用可能な小さなレイアウトブロック、すなわちセルを再設計する必要があります。この作業を行うのが NVCell と呼ばれる AI システムです。NVCell は候補レイアウトを提案する遺伝的アルゴリズムと、設計ルールの違反(例えば、配線が近すぎる場合など)を段階的に修正する強化学習エージェントを組み合わせています。このエージェントは違反を解消するたびに報酬を受け取り、各ステップごとにわずかなペナルティを負うため、クリーンなデザインへの最短経路を見つけるインセンティブとなります。ルールチェッカーが違反を指摘し、エージェントはそれを修正する方法を学習します。NVCell は以前なら 8 人のエンジニアに約 10 か月かかっていた作業を、単一の GPU で一夜で完了する処理へと短縮しました。その結果は、各セルが占める面積、消費電力、信号の伝播速度のいずれにおいても人間による設計と同等か、それを超えています。
- もう一つの強化学習システムである PrefixRL は、GPU 演算ユニットの中核をなす微小回路の設計を行います。このエージェントは、チップが占める面積や消費電力を最小化しつつ、タイミング制約を満たす回路設計が完成した際に報酬を受け取ります。Dally 氏によると、その結果生じるコンポーネントは「奇妙」な構成であり、人間による設計よりも 20〜30 パーセント優れているといいます。例えば、PrefixRL が設計した 64 ビット加算器(2 つの二進数を合計する回路)が占めるチップ面積は、業界標準のチップ設計ツールによって作成された同等の設計と比較して 25 パーセント少ないものです。
- Nvidia は内部利用のために ChipNeMo と BugNeMo という 2 つの大規模言語モデルを構築しました。チームは、同社が生産したすべての GPU の低レベル設計コードおよびそれに付随するハードウェア仕様書を含む Nvidia の社内ドキュメントを用いて、オープンウェイトの LLaMA 2 ベースモデル(70 億パラメータと 130 億パラメータ)をファインチューニングしました。2023 年の論文では、このモデルの 3 つの用途が記述されています:(i) エンジニアからの Nvidia ハードウェアに関する質問への回答、(ii) 専門的なチップ設計言語でのコードスニペット生成、(iii) バグレポートの要約です。この研究において、ドメイン適応されたモデルは、広範なチップ設計タスクにおいてその 5 倍もの規模を持つ汎用ベースモデルと同等か、それ以上の性能を示しました。
- 完成した設計が意図通りに動作することを確認する検証(Verification)工程は、最も長い段階です。Dally のチームは、AI を用いてこの工程を圧縮しようとしています。
ただし: Dally 氏によると、プロンプトに基づいて GPU をエンドツーエンドで設計することは、まだ遠い目標となっています。
ニュースの背景: AI はまだゼロからチップを設計している段階ではありませんが、その目標に向かって着実に進歩しています。
- AI チップ設計スタートアップの Verkoran が 4 月に発表した論文では、219 語の仕様書を与えられたエージェント型 AI システムが、自律的に 1.48 ギガヘルツの RISC-V CPU チップを設計したと記されています。これは 2011 年製の Intel Celeron SU2300 とほぼ同等の性能です。著者たちはシミュレーション上でこの設計を検証しましたが、実際に製造は行っていません。
- 昨年は、プリンストン大学とインド工科大学マドラス校の研究チームが、深層学習と進化アルゴリズムを用いて無線通信回路を生成し、従来の経験則には反する高性能な設計を実現しました。
- 2023 年には、Google が強化学習(reinforcement learning)を活用して、Tensor Processing Units の表面にコンポーネントを配置する方法について発表しています。
- Nvidia は 2021 年に NVCell を初めて紹介し、その後 2022 年に PrefixRL アッダー、2023 年に ChipNeMo が続きました。
なぜ重要なのか: チップ設計における探索空間は膨大であり、人間の直感ではその一部しかカバーできません。Nvidia の報告によると、同社の強化学習エージェントが生成する回路は特異なものであると同時に測定可能なほど優れており、これは AI が人間エンジニアが考慮しない解決策を見つけることで問題を解決するというより広範なパターンを反映しています。さらに、同社は次世代 GPU を設計するための AI システムをトレーニングするために GPU を使用しており、各世代のチップは次の世代の設計を加速するだけでなく、その設計に貢献したツールを実行するのに適したチップを生産することになります。
私たちが考えていること:「AI が新人エンジニアに会社の技術を理解させるのを助ける」ことと、「AI が次世代 GPU を設計する」ことの間には、かなりの距離があります。ダリー氏の期待値を抑制しようとする姿勢は refreshing です。
現場における AI の定量化
米国労働者の半数が昨年、職場で少なくとも数回 AI を利用しました。これは米国の職場における AI 採用が着実に増加している兆候です。
新しい動き: ガラップ社(広範なトピックについて世論調査を行う組織)が実施した アンケート によると、AI を利用した米国の労働者の多くが、それが生産性の向上につながったと認識しています。回答者は、その技術が自身の業務スタイルに適合し、雇用主がそれを支援している場合に最も頻繁に利用する傾向がありました。それでもなお、従業員および雇用主の相当な割合がまだ様子見の状態です。
仕組み: ガラップは、2 月 4 日から 2 月 19 日の間に、AI と仕事に関連する一連の質問について米国の従業員 23,700 人を対象に調査を行いました。彼らは、この技術が生産性に与える影響、ワークフローが変化しているかどうか、そして組織がその利用を支援し統合しているかどうかを探りました。一部の従業員は AI に懐疑的ですが、調査結果は、AI が生産性を向上させ、その利用を支援し適切なツールを提供する組織においてより大きな役割を果たすことを示唆しています。
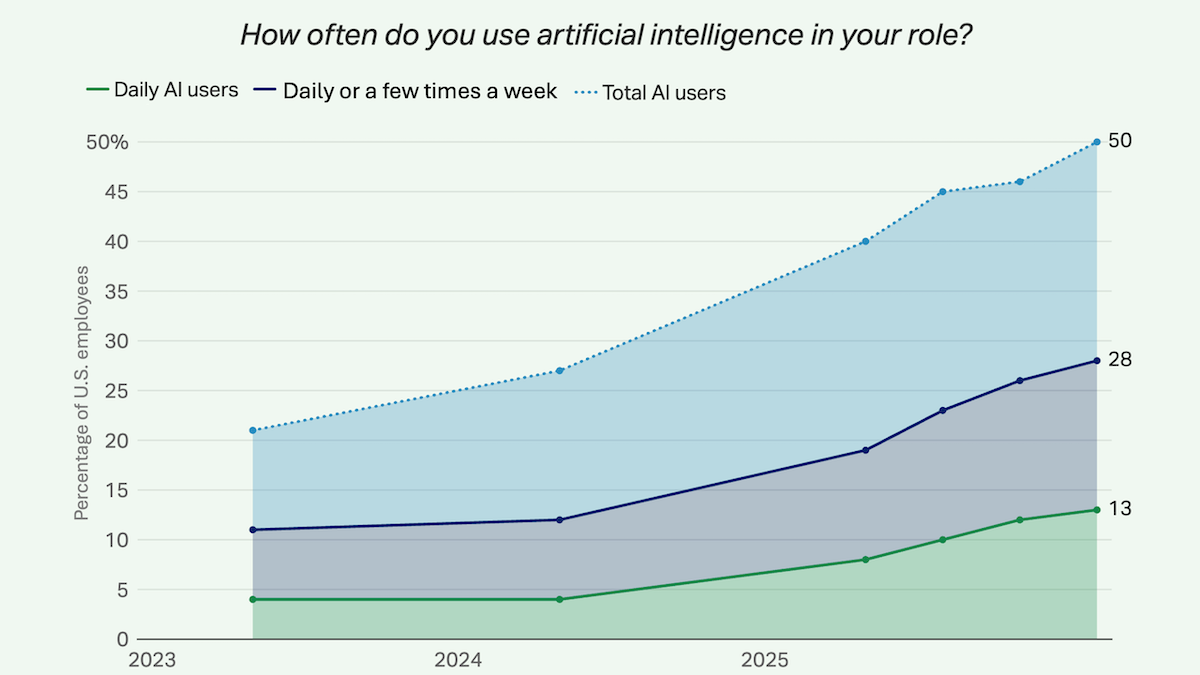
- AI の利用は着実に増加しています。例えば、回答者の 13% が毎日 AI を使用しており、28% は週に数回利用していると答えました。これらの数字は、2023 年のそれぞれ 4% と 11% から上昇したものです。組織レベルでは、労働者の 5 人に 2 人が雇用主が職場に AI ツールを導入したと回答し、企業の 4 分の 1 が明確な AI ストラテジーを有していました。
- AI は生産性を向上させていますが、まだ確立されたプロセスを代替する段階には至っていません。AI を活用している企業内では、従業員の 65% が生産性の向上につながったと回答し、31% が仕事のやり方が変化したと答えました。AI を利用している組織で働く回答者のうち、AI が仕事の仕方に影響を与えたとの認識に反対したのはわずか 7% でした。
- マネージャーの支援は従業員の行動や見解に影響を与えます。AI を活用する組織内で強力な支援を行うマネージャーの下で働く従業員ほど、AI を利用し、それが仕事を変革したと同意する傾向が強まりました。
- AI の利用者少ない層および非利用者の多くが、現在の業務を継続したいという意向を示しました。AI 導入における他の一般的な障壁には、倫理的懸念、データプライバシーへの不安、そして「AI は役に立たない」という信念や経験が含まれていました。
ニュースの背景: ある 報道 によると、AI の影響は技術の信奉者たちが約束したものに比べて失望させるものだったとされています。投資会社アポロ(Apollo)の首席エコノミストであるトルステン・スロック氏は、「AI は雇用、生産性、インフレを測る指標といった今後のマクロ経済データには現れていない」と述べています。一方、別の研究 では、AI が労働市場に影響を与えているという証拠が蓄積されつつあると指摘されています。スタンフォード大学の経済学者らが昨年発表した研究では、ソフトウェア開発者やカスタマーサービス担当者など AI の影響を受ける可能性のある職種の労働者において雇用が減少していることが明らかになりました。
なぜ重要なのか: ガラップ社の調査結果は、労働者が AI を自分の仕事を代行させるのではなく、仕事を手伝うために利用していることを示唆しています。これは、単調な作業から解放される可能性のある労働者にとって、また生産性が向上する可能性がある雇用主にとっても良いことです。しかし、AI は一部の職種を完全に自動化する可能性があります。AI に起因する生産性向上が全体的な雇用に与える影響(減少させるのか増加させるのか)については、まだ結論が出ていません。
私たちが考えていること: 一部の業界では AI による大規模な雇用喪失を予測するのが流行っていますが、現在の信号は矛盾しており、AI が雇用を増加させていることを示すものもあります。例えば、2025 年の ブルッキングス研究所の研究 では、AI に投資した企業がより多くの労働者を雇用していることが明らかになりました。労働者が AI を想像力豊かで生産的な方法で活用することで、際立つための無数の機会が存在します。

新タスクに適応するロボット
ニューラルネットワークは新しいタスクを学習する際に、以前に習得したタスクの実行方法を忘却してしまう可能性があります。この問題に対するシンプルな解決策が、特にロボティクス応用におけるビジョン・ランゲージモデル(画像と言語を組み合わせたモデル)のために提案されています。
何が新しいか: ジアヘン・フー、ジェイ・シム、およびテキサス大学オースティン校、カリフォルニア大学ロサンゼルス校、南洋理工大学、ソニーの共同研究者らは、強化学習と低ランク適応(LoRA)を組み合わせて大規模ビジョン言語行動モデルを訓練し、シミュレーションにおけるロボット学習のための既存手法を上回る成果を上げました。彼らのアプローチは、タスクを順次学習する際に発生する可能性のある「壊滅的忘却」を軽減しました。
重要な洞察: 大規模事前学習済みモデル、LoRA、オンポリシー強化学習を組み合わせることで、モデルが訓練中に忘却する情報の量を削減できます。
- 大規模事前学習モデルへの傾向は、ポストトレーニング中にモデルがどの程度忘却するかを制限します。パラメータ数が膨大なモデルでは、小さな更新は既存の知識に干渉しない可能性が高いです。
- LoRA は、2 つの小型行列の積を加算することでモデル重みを調整するため、モデルが変化できる範囲を制限します。したがって、推論時に適用されると、忘却する程度も制限されます。
- GRPO などのオンポリシー強化学習手法も更新を制限します。なぜなら、これらの手法はモデル自身が生成した行動に対して報酬を与えるからです。つまり、新しいことを学習しながらもモデルが忘却する程度を制限することになります。一方、教師あり微調整やオフポリシー強化学習(これは別の方策によって選択された行動をとったモデルに報酬を与える手法)では、モデルが以前には行わなかった可能性のある行動を学習した場合、大きな更新が生じる可能性があります。
仕組み: 著者らは、シミュレートされたロボットアームで実行される LIBERO ベンチマークの 3 つのタスクスイートそれぞれにおいて、大規模事前学習ビジョン・言語・アクション (VLA: Vision-Language-Action) モデル (OpenVLA-OFT) を微調整しました。各スイートには、引き出しを開ける、または物体を目標位置へ移動させるなど、5 つのタスクが含まれていました。著者らは、モデルを各タスクに対して順次微調整しました。
- 各ステップにおいて、モデルは画像と指示を入力として受け取り、ロボットアームおよびグリッパーを制御するための連続した動作シーケンスを予測しました。
- 著者らは、GRPO と LoRA を用いてモデルのファインチューニングを行い、新しいタスクの学習には過去のタスクデータを再利用しませんでした。GRPO の実行中、モデルは各タスクを完了するごとに報酬を受け取りました。
結果: 著者らの手法は、GRPO と LoRA を組み合わせて公平な比較を行った際、反復的なロボットタスク学習において先行手法と同等かそれ以上の性能を示しました。これにより、忘却が極めて少なく抑えられつつ、ファインチューニング中にモデルが遭遇しなかったタスクにおいてもわずかな改善が見られました。個々の構成要素を一つでも除去するとパフォーマンスは崩壊し、強い忘却が生じました。
- リベロ・スペイシャルタスクにおいて、著者らの手法は平均成功率 81.2% に達しました。この結果は、データを再利用するアプローチである Dark Experience Replay(73.4)、出力層で学習率を高く、初期層で低く設定して訓練中に初期層の変化を抑える SLCA(69.9)、および過去のタスクに重要な重みへの変更をペナルティとして課すことで知識の保持を目指す Elastic Weight Consolidation(66.1)を上回りました。
- リベロ・スペイシャルタスクにおいて、著者らの手法は既習タスクに対する成功率の平均低下が 0.3 パーセントポイントとほぼゼロの忘却を示し、Elastic Weight Consolidation(0.7)や Dark Experience Replay(4.7)よりも低く、SLCA(-0.6。これは早期タスクのパフォーマンスがわずかに向上したことを意味する)と同程度でした。
- 訓練中に遭遇しなかった追加の 5 つのリベロ・スペイシャルタスクにおいて、著者らの手法は平均成功率 57.1% に達し、Elastic Weight Consolidation(52.6)や Dark Experience Replay(55.2)を上回りました。
ただし: 比較において、著者らは既存の手法に LIBERO データセットを用いて LoRA と GRPO を追加しました。しかし、これらの既存手法はそれらの技術と組み合わせるようには設計されておらず、またそのデータを使用するものでもありませんでした。もし意図通りに厳密に適用された場合、どのように比較されるかは明確ではありません。例えば、Dark Experience Replay は新しいタスクでモデルをファインチューニングする際、過去のタスクのファインチューニングで使用された例を再導入することで忘却を防ぐことを目指していますが、LoRA を追加すると新タスクの学習に影響を与える可能性があります。
なぜ重要なのか: ロボットにすべてのタスクを一度に学習させることは効果的ですが、そのためには事前にすべてのタスクをマッピングしておく必要があります。タスクが変更された場合、一度に一つのタスクで学習する方が有益となり、多くのケースでは以前の学習内容を保持することが価値があります。従来の手法と比較すると、著者らの逐次的ファインチューニングアプローチはよりシンプルで理解しやすく、彼らがテストした条件下ではより効果的です。(著者らは、この手法がロボティクス以外の分野でも有効かどうかについては調査していません。)
私たちが考えていること: ロボットは急速に新たな環境や状況に進出しています。柔軟な運用には、その場で新しいタスクに適応できるロボットが不可欠です。
原文を表示
Dear friends,
There will be no AI jobpocalypse.
The story that AI will lead to massive unemployment is stoking unnecessary fear. AI — like any other technology — does affect jobs, but telling overblown stories of large-scale unemployment is irresponsible and damaging. Let’s put a stop to it.
I’ve expressed skepticism about the jobpocalypse in previous letters. I’m glad to see that the popular press is now pushing back on this narrative. The image below features some recent headlines.
Software engineering is the sector most affected by AI tools, as coding agents race ahead. Yet hiring of software engineers remains strong! So while there are examples of AI taking away jobs, the trends strongly suggest the net job creation is vastly greater than the job destruction — just like earlier waves of technology. Further, despite all the exciting progress in AI, the U.S. unemployment rate remains a healthy 4.3%.
Why is the AI jobpocalypse narrative so popular? For one thing, frontier AI labs have a strong incentive to tell stories that make AI technology sound more powerful. At their most extreme, they promote science-fiction scenarios of AI “taking over” and causing human extinction. If a technology can replace many employees, surely that technology must be very valuable!
Also, a lot of SaaS software companies charge around $100-$1000 per user/year. But if an AI company can replace an employee who makes $100,000 — or make them 50% more productive — then charging even $10,000 starts to look reasonable. By anchoring not to typical SaaS prices but to salaries of employees, AI companies can charge a lot more.
Additionally, businesses have a strong incentive to talk about layoffs as if they were caused by AI. After all, talking about how they’re using AI to be far more productive with fewer staff makes them look smart. This is a better message than admitting they overhired during the pandemic when capital was abundant due to low interest rates and a massive government financial stimulus.
To be clear, I recognize that AI is causing a lot of people’s work to change. This is hard. This is stressful. (And to some, it can be fun.) I empathize with everyone affected. At the same time, this is very different from predicting a collapse of the job market.
Societies are capable of telling themselves stories for years that have little basis in reality and lead to poor society-wide decision making. For example, fears over nuclear plant safety led to under-investment in nuclear power. Fears of the “population bomb” in the 1960s led countries to implement harsh policies to reduce their populations. And worries about dietary fat led governments to promote unhealthy high-sugar diets for decades.
Now that mainstream media is openly skeptical about the jobpocalypse, I hope these stories will start to lose their teeth (much like fears of AI-driven human extinction have).
Contrary to the predictions of an AI jobpocalypse, I predict the opposite: There will be an AI jobapalooza! AI will lead to a lot more good AI engineering jobs, and I’m also optimistic about the future of the overall job market. What AI engineers do will be different from traditional software engineering, and many of these jobs will be in businesses other than traditional large employers of developers. In non-AI roles, too, the skills needed will change because of AI. That makes this a good time to encourage more people to become proficient in AI, and make sure they’re ready for the different but plentiful jobs of the future!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI
Most agents respond with text. Learn to build agents that render charts, forms, and interactive user interfaces. In this course, you’ll connect a LangChain agent to a React front end and build across the generative user-interface spectrum, ending with a full-stack app that enables users and agents work on a shared state. Enroll for free!
News
ByteDance Bids for Video Leadership
As OpenAI prepares to shut down Sora, ByteDance made its own video generation model available to hundreds of millions of users.
What’s new: ByteDance added Seedance 2.0, its multimodal video generator, to its popular video-editing app CapCut. Launched earlier this year in China, the model now reaches paying CapCut users in Southeast Asia, Latin America, Africa, the Middle East, parts of Europe, Japan, and the United States.
- Input/output: Text, images, audio, and video in (up to 3 video clips, 9 images, and 3 audio clips), synchronized video and audio out (4 to 15 seconds at 480 or 720 pixels on the shorter edge in 6 aspect ratios: 21:9, 16:9, 4:3, 1:1, 3:4, and 9:16)
- Features: Lip-synced dialogue in multiple languages, ambient sound, music, multiple camera shots with cuts in a single clip, camera and lighting controlled by prompts, outputs marked by invisible watermark, blocking of input images that contain real faces or copyrighted characters (via CapCut)
- Performance: Within top two on Arena AI and Artificial Analysis video leaderboards
- Availability/price: Via CapCut (Jianying in China) paid tier, Dreamina web interface, API via the ByteDance services BytePlus and Volcengine, and third-party providers including Higgsfield.ai for $0.30 per second of output (720 pixels, audio included) or $0.24 per second for faster processing by SeeDance 2.0 Fast
- Undisclosed: Architecture, parameter count, training data and methods
How it works: Seedance 2.0 extends ByteDance’s earlier work from synchronous generation of audio-video streams in parallel to joint generation within a unified system. ByteDance’s launch announcement characterizes the architecture as “sparse.”
- The model accepts video-audio reference input for four tasks: (i) Referenced-based generation applies subject, motion, visual effects, and/or style cues to new output. (ii) Editing modifies specified regions, characters, actions, and/or audio within existing video. (iii) Extension produces output that precedes or succeeds existing video. (iv) Combination modes pair these (for example, replacing the subject in an existing video with one from a reference image).
- Audio is generated simultaneously with video, producing stereo dialogue, sound effects, and background audio.
- The model generates sequential shots and cuts in a single pass rather than generating and assembling separate clips, which helps to maintain character and scene consistency.
Performance: Seedance 2.0 ranks first and second on two independent leaderboards that rank models through blind votes of human preference in head-to-head matchups. Alibaba’s HappyHorse-1.0 is the closest challenger on both leaderboards.
- On arena.ai, Seedance 2.0 achieved 1,460 Elo on text-to-video performance and 1,454 Elo on image-to-video performance, narrowly leading both categories over HappyHorse-1.0 (1,444 Elo on each). However, the leaderboard labels Seedance 2.0 and HappyHorse-1.0 results as preliminary.
- On Artificial Analysis, Alibaba’s HappyHorse-1.0 leads three of four video categories (image-to-video without audio and text-to-video with and without audio), while Seedance 2.0 ranks second. Seedance 2.0 leads image-to-video performance with synchronized audio, achieving 1,182 Elo, ahead of HappyHorse-1.0 (1,168 Elo) and Sky Work AI’s SkyReels V4 (1,091 Elo).
- ByteDance flags limitations in detail stability, “hyper-realism,” audio distortion, multi-subject consistency, text-rendering accuracy, and “complex” editing effects.
Yes, but: Shortly after ByteDance released Seedance 2.0 in China, a generated clip that featured likenesses of actors Tom Cruise and Brad Pitt spurred six top Hollywood studios to demand that the company stop training its models on copyrighted material and block users from generating clips based on copyrighted material. The dispute remains unresolved. ByteDance added safeguards on CapCut, but it remains unclear whether they extend to outputs generated via third-party APIs.
Behind the news: The video generation market has reshuffled quickly over the past month. U.S. developers have retreated from the consumer market, and Chinese developers have released new models at an accelerating pace.
- In March, OpenAI announced it would discontinue the Sora app and API. Reports indicated that the company had shifted compute to coding and business products after Sora’s daily active user count fell from about 1 million at launch to under 500,000, while the service costs an estimated $1 million a day to operate.
- Alibaba’s HappyHorse-1.0 debuted on independent video leaderboards in early April, while it was still undergoing a closed beta test, and rose to first place across multiple categories.
- Shortly after, Alibaba unveiled HappyOyster, an AI system that generates 3D environments for developing games and films. Users can generate 3D environments from text or images and steer them in real time.
- Tencent open-sourced an updated version of its Hunyuan 3D the same day.
Why it matters: While competitors offer either a video generator or an editing app, ByteDance owns both. Moreover, its editor appears to have gargantuan reach. CapCut reportedly has 736 million monthly active users on mobile, the second-largest consumer AI product behind only ChatGPT. Seedance 2.0’s arrival on CapCut shows what one company can do when it controls both.
We’re thinking: OpenAI’s withdrawal of Sora points to a hard truth: Given the current cost of computation, AI-generated video is an expensive consumer product.
How Nvidia Uses AI to Design Chips
Nvidia’s chief scientist dreams of telling an AI model to design a new GPU, then skiing for a couple days while the system does the job. He outlined Nvidia’s progress toward that goal and how far it has to go.
What’s new: Bill Dally, who leads roughly 300 researchers at Nvidia, described AI’s growing role in designing the company’s chips in a conversation with his Google counterpart, Jeff Dean, onstage at Nvidia’s GTC conference in mid-March. His examples (starting in the video at around 24 minutes) ranged from a reinforcement learning system that lays out a chip’s building blocks to large language models trained on decades of proprietary documents.
How it works: Nvidia applies AI at five stages of chip design: laying out components, designing arithmetic circuits (components that perform math on binary numbers, like adders and counters), general engineering assistance, verifying finished designs, and exploring novel layouts.
- Each time Nvidia takes advantage of a new semiconductor manufacturing process — generally to shrink component sizes, which makes it possible to fit more of them per area of silicon — it must redesign around 2,500 to 3,000 small reusable layout blocks, or cells, such as logic gates and memory latches. An AI system called NVCell does this work. NVCell pairs a genetic algorithm that proposes candidate layouts with a reinforcement learning agent that incrementally corrects violations of design rules (for instance, wires placed too close together). The agent receives a reward each time it clears a violation and a small penalty for each step it takes, an incentive to find the shortest path to a clean design. A rule checker flags violations, and the agent learns to fix them. NVCell cuts work that previously occupied eight engineers for roughly 10 months to an overnight run on a single GPU. The results match or exceed human designs with respect to the area each cell occupies, the power it consumes, and how quickly signals propagate through it.
- Another reinforcement learning system, PrefixRL, designs the microscopic circuits at the heart of GPU arithmetic units. The agent receives a reward when the circuit design meets timing constraints while minimizing the chip area it occupies and the power it draws. The resulting components are “bizarre” configurations that are 20 percent to 30 percent better than human designs, Dally said. For instance, a 64-bit adder (a circuit that sums two binary numbers) designed by PrefixRL occupies 25 percent less chip area than an equivalent design produced by industry-standard chip-design tools.
- Nvidia built two large language models, ChipNeMo and BugNeMo, for internal use. The team fine-tuned open-weights LLaMA 2 base models (7 billion and 13 billion parameters) on Nvidia’s internal documentation, including the low-level design code for every GPU the company has produced along with the accompanying hardware specifications. A 2023 paper describes three uses: (i) answering engineers’ questions about Nvidia hardware, (ii) generating code snippets in specialized chip-design languages, and (iii) summarizing bug reports. In that work, the domain-adapted models matched or outperformed a general-purpose base model five times their size on a range of chip design tasks.
- Verification, which confirms that a finished design behaves as intended, is the longest stage. Dally’s team is working to compress it using AI.
Yes, but: Designing a GPU from end-to-end based on a prompt remains a distant goal, Dally said.
Behind the news: AI is not yet designing chips from scratch, but it is making steady progress toward that goal.
- A paper published in April by Verkoran, an AI chip-design startup, described an agentic AI system that, given a 219-word specification, autonomously designed a 1.48 gigahertz RISC-V CPU chip, roughly equivalent to a 2011-vintage Intel Celeron SU2300. The authors validated the design in simulation but did not fabricate it.
- Last year, researchers at Princeton and Indian Institute of Technology Madras used deep learning and an evolutionary algorithm to generate wireless communications circuits, producing high-performing designs that defied conventional rules of thumb.
- In 2023, Google described its use of reinforcement learning to arrange components on the surface of its Tensor Processing Units.
- Nvidia first highlighted NVCell in 2021; the PrefixRL adder followed in 2022, and ChipNeMo in 2023.
Why it matters: In chip design, the search space is enormous and only thinly covered by human intuition. Nvidia’s report that its reinforcement learning agents produce unusual but measurably superior circuits echoes a broader pattern in which AI solves problems by finding solutions that human engineers would not consider. And the company is using GPUs to train the AI systems that have been designing its next generation of GPUs, so each chip generation both accelerates the design of the next and produces chips better suited to running the tools that helped to design it.
We’re thinking: There’s a considerable distance between “AI helps a junior engineer understand the company’s technology” and “AI designs the next GPU.” Dally’s willingness to temper expectations is refreshing.
AI at Work, Quantified
Half of workers in the United States used AI at work at least a few times last year, a sign of steadily rising AI adoption in U.S. workplaces.
What’s new: Most U.S. workers who used AI found that it boosted their productivity, according to a poll conducted by Gallup, an organization that surveys public opinion on a wide variety of topics. Respondents were most likely to use the technology when it fit into the way they worked and their employers supported it. Still, a sizable portion of employees and employers are holding out.
How it works: Gallup surveyed 23,700 U.S. employees between February 4 and February 19 on a range of questions related to AI and work. They explored the technology’s impact on productivity, whether it is changing workflows, and whether organizations are supporting and integrating it. Some employees remain skeptical of AI, but the findings suggest that AI improves productivity and plays a larger role in organizations that support its use and provide suitable tools.
- Regular AI use is rising steadily. For example, 13 percent of respondents said they used AI daily, and 28 percent used it a few times a week. These figures are up from 4 percent and 11 percent respectively in 2023. At the organization level, two in five workers said their employers had introduced AI tools into the workplace and a quarter of companies had clear AI strategies.
- AI is boosting productivity but doesn’t yet substitute for established processes. Within companies where AI was used, 65 percent of employees said it improved their productivity, while 31 percent said it had changed the ways they worked. Only 7 percent of respondents who worked in organizations where AI was used disagreed that AI had affected how they worked.
- Managerial support influences employees’ behavior and outlook. Employees with strongly supportive managers in organizations that used AI were more likely to use AI and agree it had transformed their work.
- Low users and non-users widely indicated a desire to keep doing the work they do now. Other common barriers to AI adoption included ethical concerns, data privacy, and a belief or experience that AI wasn’t useful.
Behind the news: According to some accounts, AI’s impact has been disappointing relative to the promises made by tech evangelists. “AI is everywhere except in the incoming macroeconomic data,” such as metrics that gauge employment, productivity, and inflation, writes Torsten Slok, chief economist at the investment firm Apollo. By other accounts, evidence is mounting that AI is impacting the job market. Research published by Stanford economists last year found that employment was declining for workers whose jobs may be affected by AI, such as software developers and customer-service representatives.
Why it matters: The Gallup results suggest that workers use AI to help them do their jobs, not to do their jobs for them. This can be good both for workers, who may be freed of monotonous tasks, and their employers, which may gain productivity. But AI has the potential to automate some positions entirely. The jury is still out regarding whether AI-driven productivity gains will reduce or increase overall employment.
We’re thinking: While it’s trendy in some circles to forecast massive job losses due to AI, current signals are conflicting, and some show that AI is boosting employment. For instance, a 2025 study by Brookings found that companies that invested in AI hired more workers. There are endless opportunities for workers to stand out by applying AI in imaginative, productive ways.
Robots That Adapt to New Tasks
Neural networks can forget how to perform earlier tasks as they learn new ones. A simple recipe addresses this problem for vision-language models, specifically in robotics applications.
What’s new: Jiaheng Hu, Jay Shim, and colleagues at University of Texas Austin, University of California Los Angeles, Nanyang Technological University, and Sony trained large vision-language-action models using a combination of reinforcement learning and low-rank adaptation (LoRA) to outperform established methods for robotics training in simulation. Their recipe reduced catastrophic forgetting, which can occur when models learn tasks sequentially.
Key insight: Together, large pretrained models, LoRA, and on-policy reinforcement learning reduce the amount of information a model can forget while training.
- The trend toward large pretrained models limits how much models can forget during post-training. In a model that has a huge number of parameters, small updates are likely to not interfere with existing knowledge.
- LoRA, which adjusts model weights by adding to them the product of two small matrices, limits how much models can change. Thus, when it’s applied at inference, it limits how much they can forget.
- On-policy reinforcement learning methods such as GRPO also limit updates, since they reward actions the model itself generated — so they, too, limit how much models can forget while learning new things. In contrast, supervised fine-tuning and off-policy reinforcement learning, which rewards models for taking actions that were chosen by a separate policy, can result in large updates if a model learns actions it might not have performed previously.
How it works: The authors fine-tuned a large pretrained vision-language-action (VLA) model (OpenVLA-OFT) on each of three task suites in the LIBERO benchmark executed by a simulated robot arm. Each suite contained five tasks such as opening a drawer or moving an object to a target location. The authors fine-tuned the models on each task sequentially.
- At each step, a model took as input an image and instruction, and it predicted a sequence of continuous actions to control the robot arm and gripper.
- The authors fine-tuned the models using GRPO and LoRA without reusing data from previous tasks to train on new tasks. During GRPO, the model received a reward for completing each task.
Results: The authors’ method matched or outperformed earlier methods for iteratively learning robotics tasks, which the authors combined with GRPO and LoRA for fair comparison. It resulted in very little forgetting as well as slight improvement on tasks that models had not encountered during fine-tuning. Removing any individual component caused performance to collapse and led to strong forgetting.
- On the libero-spatial tasks, the authors’ method reached 81.2 percent average success rate. This result exceeded Dark Experience Replay (73.4), an approach that reuses data; SLCA (69.9), which uses higher learning rates in output layers and lower learning rates in earlier layers, so early layers change less during training; and Elastic Weight Consolidation (66.1), which aims to preserve knowledge by penalizing changes to weights that were important for previous tasks.
- The authors’ method showed near-zero forgetting (0.3 percentage point average drop in success rate on previously learned tasks) on libero-spatial, lower than Elastic Weight Consolidation (0.7) and Dark Experience Replay (4.7), and comparable to SLCA (-0.6, meaning performance on earlier tasks improved slightly).
- On five additional libero-spatial tasks, the model did not encounter during training, the authors’ method reached 57.1 percent average success rate, outperforming Elastic Weight Consolidation (52.6) and Dark Experience Replay (55.2).
Yes, but: In their comparisons, the authors added to the earlier methods LoRA and GRPO using the LIBERO dataset. But the earlier methods weren’t designed to combine with those techniques or use that data, and it’s not clear how they would have compared had they been applied strictly as intended. For instance, Dark Experience Replay, while fine-tuning a model on a new task, aims to avoid forgetting by re-introducing examples that were used in fine-tuning for earlier tasks. Adding LoRA may affect the learning of new tasks.
Why it matters: Training a robot on all tasks at once can be effective, but it requires that all tasks are mapped out ahead of time. If tasks change, it becomes helpful to train on one task at a time, and in many cases it’s valuable to retain earlier training. Relative to prior methods, the authors’ sequential fine-tuning approach is simpler, easier to understand, and more effective under the conditions they tested. (The authors didn’t explore whether it would be effective beyond robotics.)
We’re thinking: Robots are rapidly entering new environments and situations. Nimble operations will benefit from robots that adapt to new tasks on the fly.
関連記事
Gemini Flash の価格上昇、AI 法施行延期、エージェントがオンライントラフィックを牽引
The Batch は、シリコンバレーで注目される AI フォワードデプロイメントエンジニア(FDE)の役割について報じ、顧客組織に常駐してワークフローをカスタマイズする専門職の台頭を紹介した。
ヘルメス対オープンクロー、サイバーセキュリティ警報の鳴動、より対話的な会話、エージェントは人間の仕事ができるか?
The Batch は、AI エージェント間の比較(ヘルメスとオープンクロー)、サイバーセキュリティの警報発生、対話機能の高度化、そして AI エージェントが人間の業務を代替できる可能性について論じています。
中国がメタの自律型 AI 野望を阻止、米国は次期モデル評価中、AI がマンモグラムの診断を実施
中国政府がメタ社の自律型 AI 技術の展開を阻害し、米政府機関が次世代 AI モデルの評価を進めている。また、医療分野では AI がマンモグラムの画像診断に活用されている。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み