Qwen3をゼロから理解し実装する
Sebastian Raschka が、Qwen3 のアーキテクチャを純粋な PyTorch でゼロから実装し、その動作原理と構築ブロックを詳細に解説する技術記事。
キーポイント
Qwen3 の人気要因と市場地位
Apache License v2.0 の完全オープンソースでありながら、LMArena で Claude Opus 4 と並ぶ最高水準のパフォーマンスを誇り、0.6B から 480B モデルまで多様なサイズを提供している。
ゼロからの実装アプローチ
概念図だけでなく、純粋な PyTorch で Qwen3 の Dense および MoE アーキテクチャを実装し、コードを通じて内部動作を深く理解することを目的としている。
最新モデルのベンチマーク結果
2025 年 9 月 5 日に公開された 1T パラメータのクローズドソース版「max」が、既存の主要オープンウェイトおよびプロプライエタリモデルをすべて上回る性能を示したことが言及されている。
開発者向けの実践的価値
複雑なコード記述を通じて、読者が独自の実験やプロジェクトに応用可能な具体的な構築ブロック(building blocks)を獲得できることを強調している。
影響分析・編集コメントを表示
影響分析
この記事は、Qwen3 のような最先端 LLM の内部構造をコードレベルで理解したい開発者にとって極めて貴重なリソースであり、単なる利用法を超えたアーキテクチャの改変や新モデルの実装への道を開く。特に、クローズドソースの超大規模モデルと比較されるオープンウェイト版の性能が示されたことで、オープンソースコミュニティにおける Qwen3 の戦略的価値を再確認させる内容となっている。
編集コメント
Qwen3 の実装コードを詳細に解説する本記事は、LLM アーキテクチャの理解を深めたいエンジニアにとって必読の技術ドキュメントです。最新のベンチマークデータと併せて、オープンソース LLM の現状と可能性を把握するのに最適な内容となっています。
Qwen3をゼロから理解し実装する
主要なオープンソースLLMの詳細な考察
 Sebastian Raschka, PhDSep 06, 2025∙ Paid119612Share以前、『The Big LLM Architecture Comparison』で2025年の注目すべきオープンウェイトアーキテクチャを比較しました。その後、焦点を絞り、『From GPT-2 to gpt-oss: Analyzing the Architectural Advances』で概念レベルでの様々なアーキテクチャ構成要素について議論しました。
Sebastian Raschka, PhDSep 06, 2025∙ Paid119612Share以前、『The Big LLM Architecture Comparison』で2025年の注目すべきオープンウェイトアーキテクチャを比較しました。その後、焦点を絞り、『From GPT-2 to gpt-oss: Analyzing the Architectural Advances』で概念レベルでの様々なアーキテクチャ構成要素について議論しました。
良いことはすべて三度あるということで、この夏の注目すべき研究のハイライトを紹介する前に、今度はこれらのアーキテクチャを実際にコードで手を動かして深く掘り下げたいと思います。一緒に進めることで、その内部が実際にどのように動作するかを理解し、自身の実験やプロジェクトに適応できる構成要素を獲得できるでしょう。
このために、Qwen3(5月に初リリース、7月に更新)を選びました。なぜなら、本記事執筆時点で最も広く好まれ、使用されているオープンウェイトモデルファミリーの一つだからです。
私の見解では、Qwen3モデルがこれほど人気がある理由は以下の通りです:
開発者と商業利用に友好的なオープンソース(Apache License v2.0)であり、元のオープンソースライセンス条項を超えた追加の制約がない(他の一部のオープンウェイトLLMは追加の使用制限を課しています)
パフォーマンスが非常に優れている。例えば、本記事執筆時点で、オープンウェイトの235B-InstructバリアントはLMArenaリーダーボードで8位にランクされており、プロプライエタリなClaude Opus 4と同率です。これより上位にランクされている他のオープンウェイトLLMは、DeepSeek 3.1(3倍大きい)とKimi K2(4倍大きい)の2つのみです。9月5日、Qwen3はプラットフォーム上で1Tパラメータの「max」バリアントをリリースし、主要なすべてのベンチマークでKimi K2、DeepSeek 3.1、Claude Opus 4を上回りました。ただし、このモデルは現時点ではクローズドソースです。
異なる計算予算とユースケースに対応するため、0.6Bの密モデルから480BパラメータのMixture-of-Expertsモデルまで、様々なモデルサイズが利用可能です。
これは純粋なPyTorchによるゼロからのコードを含むため、長い記事になります。コードセクションは冗長に見えるかもしれませんが、概念図だけよりも構成要素をよりよく説明するのに役立つことを願っています!
ヒント1:この記事をメール受信箱で読んでいる場合、行幅が狭いためコードスニペットが不自然に折り返される可能性があります。より良い体験のためには、ウェブブラウザで開くことをお勧めします。
ヒント2:ウェブサイト左側の目次を使用して、セクション間を簡単に移動できます。
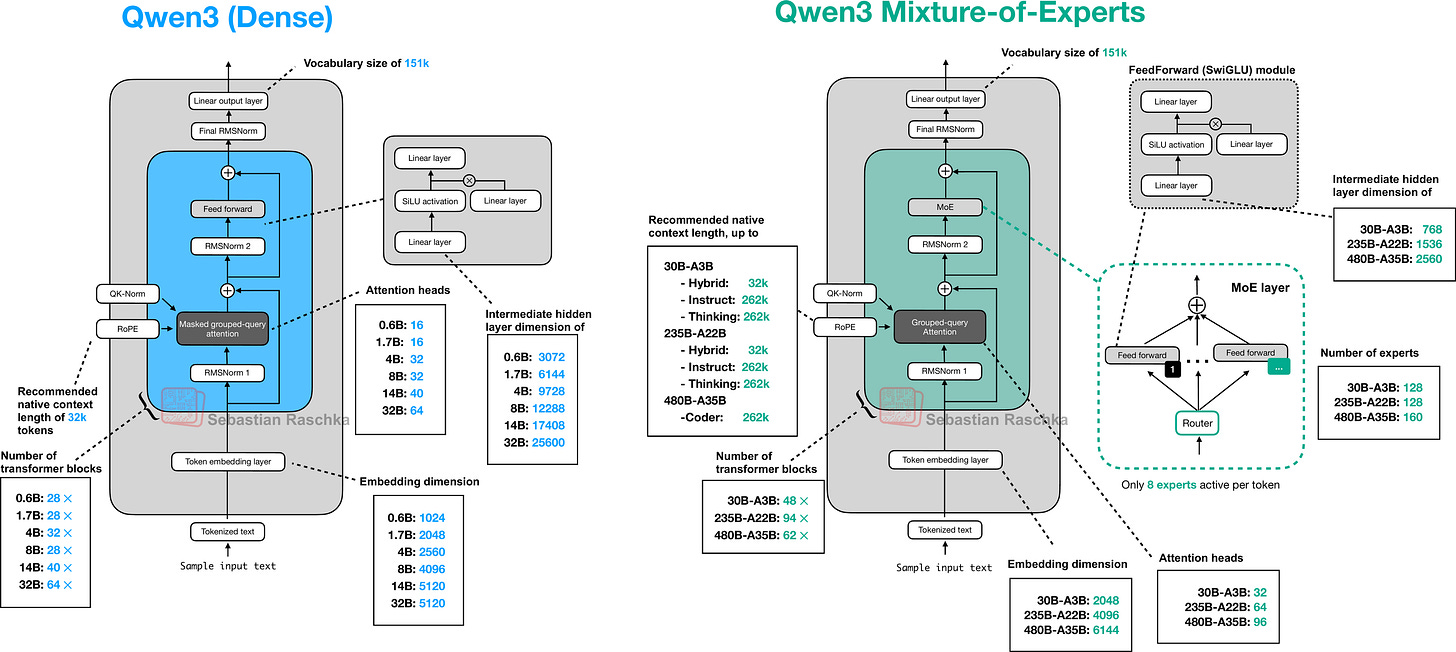 図1:本記事で議論し、純粋なPyTorchで(再)実装するQwen3の密アーキテクチャとMixture-of-Expertsアーキテクチャのプレビュー。
図1:本記事で議論し、純粋なPyTorchで(再)実装するQwen3の密アーキテクチャとMixture-of-Expertsアーキテクチャのプレビュー。
この投稿は有料購読者向けです
原文を表示
Understanding and Implementing Qwen3 From Scratch
A Detailed Look at One of the Leading Open-Source LLMs
Sebastian Raschka, PhDSep 06, 2025∙ Paid119612SharePreviously, I compared the most notable open-weight architectures of 2025 in The Big LLM Architecture Comparison. Then, I zoomed in and discussed the various architecture components in From GPT-2 to gpt-oss: Analyzing the Architectural Advances on a conceptual level.
Since all good things come in threes, before covering some of the noteworthy research highlights of this summer, I wanted to now dive into these architectures hands-on, in code. By following along, you will understand how it actually works under the hood and gain building blocks you can adapt for your own experiments or projects.
For this, I picked Qwen3 (initially released in May and updated in July) because it is one of the most widely liked and used open-weight model families as of this writing.
The reasons why Qwen3 models are so popular are, in my view, as follows:
A developer- and commercially friendly open-source (Apache License v2.0) without any strings attached beyond the original open-source license terms (some other open-weight LLMs impose additional usage limits)
The performance is really good; for example, as of this writing, the open-weight 235B-Instruct variant is ranked 8 on the LMArena leaderboard, tied with the proprietary Claude Opus 4. The only 2 other open-weight LLMs that rank higher are DeepSeek 3.1 (3x larger) and Kimi K2 (4x larger). On September 5th, Qwen3 released a 1T parameter “max” variant on their platform that beats Kimi K2, DeepSeek 3.1, and Claude Opus 4 on all major benchmarks; however, this model is closed-source for now.
There are many different model sizes available for different compute budgets and use-cases, from 0.6B dense models to 480B parameter Mixture-of-Experts models.
This is going to be a long article due to the from-scratch code in pure PyTorch. While the code sections may look verbose, I hope that they help explain the building blocks better than conceptual figures alone!
Tip 1: If you are reading this article in your email inbox, the narrow line width may cause code snippets to wrap awkwardly. For a better experience, I recommend opening it in your web browser.
Tip 2: You can use the table of contents on the left side of the website for easier navigation between sections.
Figure 1: Preview of the Qwen3 Dense and Mixture-of-Experts architectures discussed and (re)implemented in pure PyTorch in this article.
This post is for paid subscribers
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み