LLM 0.32a0 は主要な後方互換性のあるリファクタリング
Simon Willison が公開した LLM ライブラリ 0.32a0 は、従来の単純なプロンプト・レスポンスモデルから、現代の多様な入力出力や会話履歴を扱えるメッセージシーケンスおよびストリーム型レスポンスへアーキテクチャを刷新した。
キーポイント
アーキテクチャの大規模リファクタリング
従来の「テキスト入力→テキスト出力」という単純なモデルから、現代の LLM が持つ多様な能力(画像・音声処理、構造化データ生成など)を表現できる新しい抽象化レイヤーへ移行した。
プロンプト入力のメッセージシーケンス化
LLM の入力形式を単一のテキスト文字列から、会話履歴(ユーザーとアシスタントのやり取り)を保持する一連のメッセージ配列として扱う仕様に変更された。
レスポンスのストリーム型多要素化
モデルからの応答が単一のテキスト文字列ではなく、テキスト、画像、ツール呼び出しなど異なる型のパーツから構成されるストリームとして扱えるようになった。
影響分析・編集コメントを表示
影響分析
このリリースは、LLM アプリケーション開発における抽象化レイヤーの限界を示し、単なるテキスト処理から多モーダル・エージェント機能を持つ複雑なワークフローへ移行する必要性を浮き彫りにしています。開発者にとっては、既存コードの修正が必要となる重大なアップデートですが、同時に最新の AI モデル機能をより柔軟かつ標準的に実装できる基盤を提供します。
編集コメント
Simon Willison の LLM ライブラリは、複雑化する AI エコシステムにおいて、開発者が最新のモデル機能を標準化された形で利用するための重要な橋渡し役を果たしています。今回の大規模リファクタリングは、単なる機能追加ではなく、現代の LLM が持つ本質的な能力(会話履歴の保持や多様な出力形式)を正しく表現するための不可欠な進化と言えます。
LLM 0.32a0 をリリースしました。これは、LLM にアクセスするための私の Python ライブラリおよび CLI ツールである LLM のアルファ版であり、長期間取り組んできた重要な変更が含まれています。
以前の LLM バージョンは、プロンプトとレスポンスという観点から世界をモデル化していました。テキストプロンプトをモデルに送信し、テキストレスポンスを受け取るという仕組みです。
import llm
model = llm.get_model("gpt-5.5")
response = model.prompt("Capital of France?")
print(response.text())
これは私が 2023 年 4 月にこのライブラリの開発を始めた当時は理にかなっていました。しかし、それ以来多くのことが変わりました!
LLM は プラグインシステム を通じて数千もの異なるモデルに対する抽象化を提供しています。テキスト入力に対してテキスト出力が返されるという元の抽象化では、私が必要とするすべての機能を表現できなくなっていました。
時を経て LLM 自体も成長し、アタッチメント を追加して画像、オーディオ、ビデオの入力を扱えるようになり、次に構造化 JSON の出力のための スキーマ が追加され、さらにツール呼び出しを実行するための ツール が追加されました。一方、LLM 自体も進化を続け、推論サポートの追加や画像の返却機能など、あらゆる興味深い機能を備えるようになりました。
LLM は、今日の最先端モデルが処理できる多様な入力・出力タイプをより適切に扱うために進化する必要があります。
0.32a0 アルファ版には 2 つの主要な変更があります。1 つ目は、モデルの入力をメッセージのシーケンスとして表現できるようにしたこと、2 つ目は、モデルの応答を異なるタイプのパーツからなるストリームとして構成できるようにしたことです。
プロンプトをメッセージのシーケンスとして
LLM はテキストを入力として受け付けますが、ChatGPT が双方向の対話型インターフェースの価値を実証して以来、最も一般的なプロンプトの与え方は、その入力を一連の対話ターンとして扱うことです。
最初のターンは以下のようになります。
user: フランスの首都は?
assistant:
(その後、モデルが assistant 側の応答を埋めます。)
しかし、それ以降の各ターンでは、その時点までの会話をすべて再演する必要があります。まるで台本のようにです。
user: フランスの首都は?
assistant: パリ
user: ドイツは?
assistant:
主要ベンダーの JSON API のほとんどがこのパターンに従っています。以下に、他のプロバイダによって広く模倣されている OpenAI チャット完了 API を使用した場合の上記の内容を示します。
curl https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5.5",
"messages": [
{
"role": "user",
"content": "Capital of France?"
},
{
"role": "assistant",
"content": "Paris"
},
{
"role": "user",
"content": "Germany?"
}
]
}'
0.32 より前のバージョンでは、LLM はこれらを会話としてモデル化していました:
model = llm.get_model("gpt-5.5")
conversation = model.conversation()
r1 = conversation.prompt("Capital of France?")
print(r1.text())
出力: "Paris"
r2 = conversation.prompt("Germany?")
print(r2.text())
出力: "Berlin"
これは、モデルからの会話を最初から構築する場合に機能しましたが、初期段階で既存の会話をフィードする手段は提供していませんでした。これにより、OpenAI チャット完了 API のエミュレーションを構築するようなタスクが、本来あるべきよりもはるかに困難になっていました。
llm CLI ツールでは、SQLite を使用した会話の永続化と拡張のためのカスタムメカニズムでこの問題を回避していましたが、これは LLM API の安定した一部にはなりませんでした。また、ストレージ層として SQLite にコミットすることなく Python ライブラリを使用したいケースは数多く存在します。
新しいアルファ版では、これがサポートされるようになりました:
import llm
from llm import user, assistant
model = llm.get_model("gpt-5.5")
response = model.prompt(messages=[
user("Capital of France?"),
assistant("Paris"),
user("Germany?"),
])
print(response.text())
llm.user() および llm.assistant() 関数は、messages=[] 配列内で使用するように設計された新しいビルダー関数です。
従来の prompt= オプションも引き続き動作しますが、LLM は内部でこれを単一アイテムの messages 配列にアップグレードします。
また、会話構築の代わりに、レスポンスに対して *reply*(返信)することも可能になりました:
response2 = response.reply("How about Hungary?")
print(response2) # デフォルトの __str__() は .text() を呼び出します
ストリーミング部分
アルファ版におけるもう一つの主要な新機能は、プロンプトから結果をストリーミングして返すインターフェースに関するものです。
以前、LLM は以下のようにストリーミングをサポートしていました:
response = model.prompt("Generate an SVG of a pelican riding a bicycle")
for chunk in response:
print(chunk, end="")
あるいは、この非同期(async)バリアントも利用可能です:
import asyncio
import llm
model = llm.get_async_model("gpt-5.5")
response = model.prompt("Generate an SVG of a pelican riding a bicycle")
async def run():
async for chunk in response:
print(chunk, end="", flush=True)
asyncio.run(run())
今日の多くのモデルは、混合された種類のコンテンツを返します。Claude に対して実行したプロンプトでは、推論出力が返され、次にテキスト、その後ツール呼び出しのための JSON リクエスト、さらに追加のテキストコンテンツが返される可能性があります。
一部のモデルでは、サーバーサイドでツールを実行することも可能です。例えば、OpenAI の code interpreter tool や Anthropic の web search が該当します。これにより、モデルからの結果にはテキスト、ツール呼び出し、ツールの出力、その他の形式が組み合わさったものが含まれることになります。
マルチモーダル出力モデルも登場し始めており、ストリーミング応答の中に画像や 音声のスニペット を混ぜて返すことが可能になっています。
新しい LLM アルファモデルでは、これらを型付きメッセージパーツのストリームとして扱います。Python API の利用者にとってこれがどのようなものかを示します:
import asyncio
import llm
model = llm.get_model("gpt-5.5")
prompt = "invent 3 cool dogs, first talk about your motivations"
def describe_dog(name: str, bio: str) -> str:
"""仮想的な犬の名前と経歴を記録する。"""
return f"{name}: {bio}"
def sync_example():
response = model.prompt(
prompt,
tools=[describe_dog],
)
for event in response.stream_events():
if event.type == "text":
print(event.chunk, end="", flush=True)
elif event.type == "tool_call_name":
print(f"\nTool call: {event.chunk}(", end="", flush=True)
elif event.type == "tool_call_args":
print(event.chunk, end="", flush=True)
async def async_example():
model = llm.get_async_model("gpt-5.5")
response = model.prompt(
prompt,
tools=[describe_dog],
)
async for event in response.astream_events():
if event.type == "text":
print(event.chunk, end="", flush=True)
elif event.type == "tool_call_name":
print(f"\nTool call: {event.chunk}(", end="", flush=True)
elif event.type == "tool_call_args":
print(event.chunk, end="", flush=True)
sync_example()
asyncio.run(async_example())
Sample output (from just the first sync example):
私の動機は、それぞれが独自の物語の主人公になり得るような印象を与えるために、3 頭の記憶に残る犬を異なる「クール」なスタイルで創作することです。1 頭は映画のような雰囲気、1 頭は冒険家風、もう 1 頭は魅力的に混沌としたスタイルです。
ツール呼び出し:describe_dog({"name": "Nova Jetpaw", "bio": "小さなアビエーターゴーグルを着用し、月光を浴びたビーチでスプリントするのが好きな、スリムな銀灰色のウィペット。ノヴァは勇敢でエレガントであり、単なる楽しみのためにドローンを追い越すという噂もあります。
ツール呼び出し:describe_dog({"name": "Mochi Thunderbark", "bio": "ドラマチックな黒と金のバンダナを身につけたふさふさのコージ。ロックスターのような自信に満ちています。モーチは短く、大声で、忠実であり、リスだけで構成された近所の「警備パトロール」を率いています。
ツール呼び出し:describe_dog({"name": "Atlas Snowfang", "bio": "氷のような青い目と、トレイル用のスナックがたっぷり入ったバックパックを持つ巨大な白いハスキー。アトラスは冷静で英雄的であり、吹雪や霧、あるいは混乱するキャンプ旅行中であっても、いつも帰る道を知っています。
応答の最後には response.execute_tool_calls() を呼び出して実際にリクエストされた関数を実行するか、response.reply() を送信してこれらのツールを呼び出し、その戻り値をモデルに送り返すことができます:
print(response.reply("Tell me about the dogs"))
この新しいトークンタイプのストリーミング機構により、CLI ツールは最終応答内のテキストとは異なる色で「思考」テキストを表示できるようになりました。思考テキストは stderr に出力されるため、他のツールにパイプされた結果には影響しません。
この例では、Anthropic のモデルが思考テキストをレスポンスの一部として返すため、Claude Sonnet 4.6(llm-anthropic プラグインの更新されたストリーミングイベント版を使用)を利用しています:
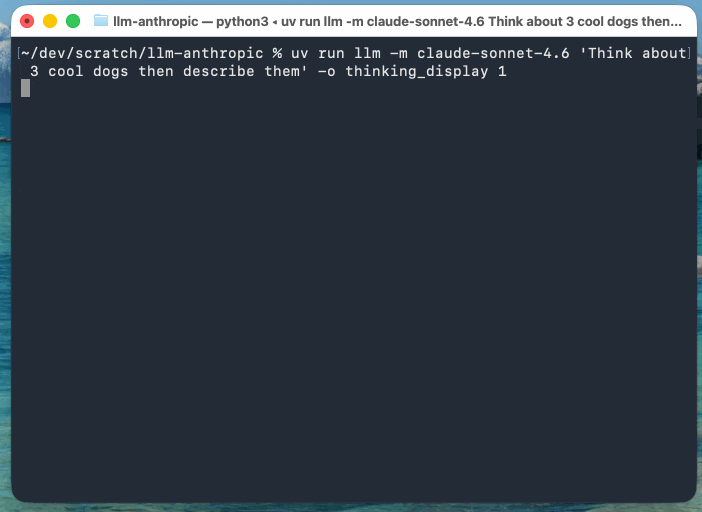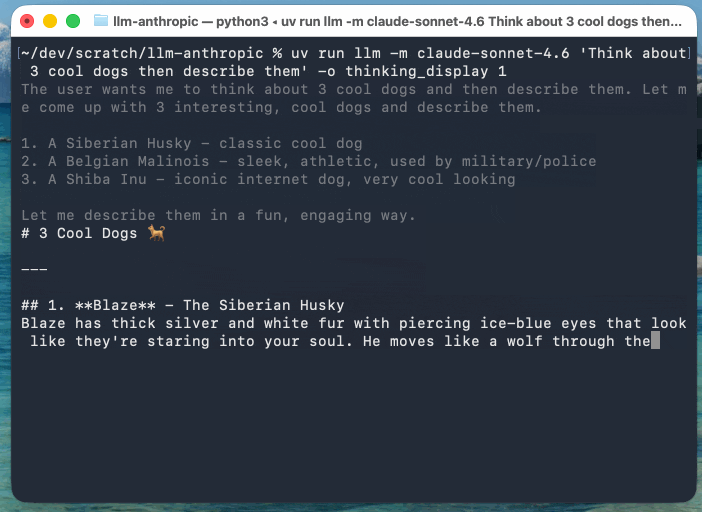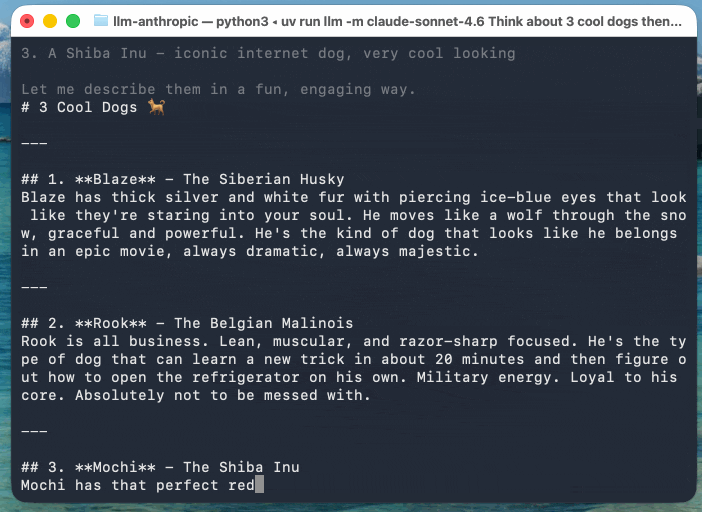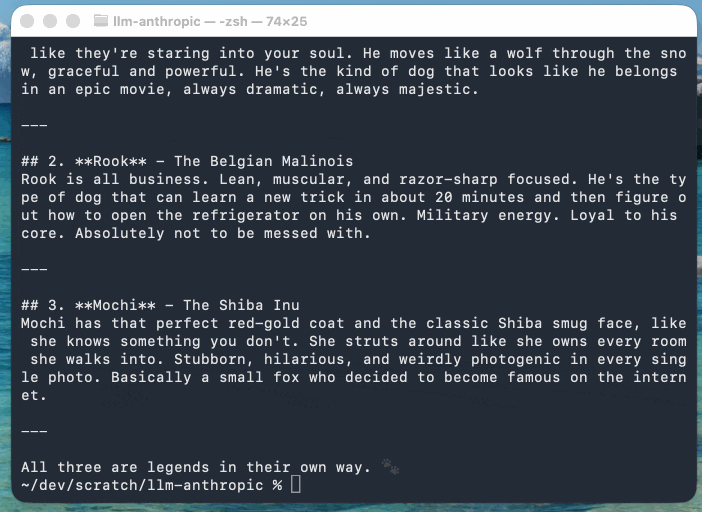
llm -m claude-sonnet-4.6 'Think about 3 cool dogs then describe them' \
-o thinking_display 1
新しい -R/--no-reasoning フラグを使用して、思考トークンの出力を抑制することができます。驚くべきことに、今回のリリースにおける CLI 向けの唯一の変更点がこれでした。
レスポンスのシリアライズおよびデシリアライズの仕組み
前述した通り、LLM は現在、会話を SQLite に永続化するためのコードが非常に柔軟性に欠けています。0.32a0 では、Python API ユーザーが独自の代替手段を実装できるようにする新しいメカニズムを追加しました:
serializable = response.to_dict()
serializable は JSON 形式の辞書です
どこにでも保存し、その後復元します:
response = R
原文を表示
I just released LLM 0.32a0, an alpha release of my LLM Python library and CLI tool for accessing LLMs, with some consequential changes that I've been working towards for quite a while.
Previous versions of LLM modeled the world in terms of prompts and responses. Send the model a text prompt, get back a text response.
import llm
model = llm.get_model("gpt-5.5")
response = model.prompt("Capital of France?")
print(response.text())This made sense when I started working on the library back in April 2023. A lot has changed since then!
LLM provides an abstraction over thousands of different models via its plugin system. The original abstraction - of text input that returns text output - was no longer able to represent everything I needed it to.
Over time LLM itself has grown attachments to handle image, audio, and video input, then schemas for outputting structured JSON, then tools for executing tool calls. Meanwhile LLMs kept evolving, adding reasoning support and the ability to return images and all kinds of other interesting capabilities.
LLM needs to evolve to better handle the diversity of input and output types that can be processed by today's frontier models.
The 0.32a0 alpha has two key changes: model inputs can be represented as a sequence of messages, and model responses can be composed of a stream of differently typed parts.
Prompts as a sequence of messages
LLMs accept input as text, but ever since ChatGPT demonstrated the value of a two-way conversational interface, the most common way to prompt them has been to treat that input as a sequence of conversational turns.
The first turn might look like this:
user: Capital of France?
assistant:
(The model then gets to fill out the reply from the assistant.)
But each subsequent turn needs to replay the entire conversation up to that point, as a sort of screenplay:
user: Capital of France?
assistant: Paris
user: Germany?
assistant:
Most of the JSON APIs from the major vendors follow this pattern. Here's what the above looks like using the OpenAI chat completions API, which has been widely imitated by other providers:
curl https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5.5",
"messages": [
{
"role": "user",
"content": "Capital of France?"
},
{
"role": "assistant",
"content": "Paris"
},
{
"role": "user",
"content": "Germany?"
}
]
}'Prior to 0.32, LLM modeled these as conversations:
model = llm.get_model("gpt-5.5")
conversation = model.conversation()
r1 = conversation.prompt("Capital of France?")
print(r1.text())
# Outputs "Paris"
r2 = conversation.prompt("Germany?")
print(r2.text())
# Outputs "Berlin"This worked if you were building a conversation with the model from scratch, but it didn't provide a way to feed in a previous conversation from the start. This made tasks like building an emulation of the OpenAI chat completions API much harder than they should have been.
The llm CLI tool worked around this through a custom mechanism for persisting and inflating conversations using SQLite, but that never became a stable part of the LLM API - and there are many places you might want to use the Python library without committing to SQLite as the storage layer.
The new alpha now supports this:
import llm
from llm import user, assistant
model = llm.get_model("gpt-5.5")
response = model.prompt(messages=[
user("Capital of France?"),
assistant("Paris"),
user("Germany?"),
])
print(response.text())The llm.user() and llm.assistant() functions are new builder functions designed to be used within that messages=[] array.
The previous prompt= option still works, but LLM upgrades it to a single-item messages array behind the scenes.
You can also now *reply* to a response, as an alternative to building a conversation:
response2 = response.reply("How about Hungary?")
print(response2) # Default __str__() calls .text()Streaming parts
The other major new interface in the alpha concerns streaming results back from a prompt.
Previously, LLM supported streaming like this:
response = model.prompt("Generate an SVG of a pelican riding a bicycle")
for chunk in response:
print(chunk, end="")Or this async variant:
import asyncio
import llm
model = llm.get_async_model("gpt-5.5")
response = model.prompt("Generate an SVG of a pelican riding a bicycle")
async def run():
async for chunk in response:
print(chunk, end="", flush=True)
asyncio.run(run())Many of today's models return mixed types of content. A prompt run against Claude might return reasoning output, then text, then a JSON request for a tool call, then more text content.
Some models can even execute tools on the server-side, for example OpenAI's code interpreter tool or Anthropic's web search. This means the results from the model can combine text, tool calls, tool outputs and other formats.
Multi-modal output models are starting to emerge too, which can return images or even snippets of audio intermixed into that streaming response.
The new LLM alpha models these as a stream of typed message parts. Here's what that looks like as a Python API consumer:
import asyncio
import llm
model = llm.get_model("gpt-5.5")
prompt = "invent 3 cool dogs, first talk about your motivations"
def describe_dog(name: str, bio: str) -> str:
"""Record the name and biography of a hypothetical dog."""
return f"{name}: {bio}"
def sync_example():
response = model.prompt(
prompt,
tools=[describe_dog],
)
for event in response.stream_events():
if event.type == "text":
print(event.chunk, end="", flush=True)
elif event.type == "tool_call_name":
print(f"\nTool call: {event.chunk}(", end="", flush=True)
elif event.type == "tool_call_args":
print(event.chunk, end="", flush=True)
async def async_example():
model = llm.get_async_model("gpt-5.5")
response = model.prompt(
prompt,
tools=[describe_dog],
)
async for event in response.astream_events():
if event.type == "text":
print(event.chunk, end="", flush=True)
elif event.type == "tool_call_name":
print(f"\nTool call: {event.chunk}(", end="", flush=True)
elif event.type == "tool_call_args":
print(event.chunk, end="", flush=True)
sync_example()
asyncio.run(async_example())Sample output (from just the first sync example):
My motivation: create three memorable dogs with distinct “cool” styles—one cinematic, one adventurous, and one charmingly chaotic—so each feels like they could star in their own story.
Tool call: describe_dog({"name": "Nova Jetpaw", "bio": "A sleek silver-gray whippet who wears tiny aviator goggles and loves sprinting along moonlit beaches. Nova is fearless, elegant, and rumored to outrun drones just for fun."}
Tool call: describe_dog({"name": "Mochi Thunderbark", "bio": "A fluffy corgi with a dramatic black-and-gold bandana and the confidence of a rock star. Mochi is short, loud, loyal, and leads a neighborhood 'security patrol' made entirely of squirrels."}
Tool call: describe_dog({"name": "Atlas Snowfang", "bio": "A massive white husky with ice-blue eyes and a backpack full of trail snacks. Atlas is calm, heroic, and always knows the way home—even during blizzards, fog, or confusing camping trips."}
At the end of the response you can call response.execute_tool_calls() to actually run the functions that were requested, or send a response.reply() to have those tools called and their return values sent back to the model:
print(response.reply("Tell me about the dogs"))This new mechanism for streaming different token types means the CLI tool can now display "thinking" text in a different color from the text in the final response. The thinking text goes to stderr so it won't affect results that are piped into other tools.
This example uses Claude Sonnet 4.6 (with an updated streaming event version of the llm-anthropic plugin) as Anthropic's models return their reasoning text as part of the response:
llm -m claude-sonnet-4.6 'Think about 3 cool dogs then describe them' \
-o thinking_display 1You can suppress the output of reasoning tokens using the new -R/--no-reasoning flag. Surprisingly that ended up being the only CLI-facing change in this release.
A mechanism for serializing and deserializing responses
As mentioned earlier, LLM has quite inflexible code at the moment for persisting conversations to SQLite. I've added a new mechanism in 0.32a0 that should provide Python API users a way to roll their own alternative:
serializable = response.to_dict()
serializable is a JSON-style dictionary
store it anywhere you like, then inflate it:
response = R
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み