AIニュース:他社が人員削減する中、Anthropic は年間 10 倍成長し時価総額で OpenAI を上回る
Anthropic の急成長と OpenAI を上回る評価額に対し、他社が AI 準備を理由に人員削減を行う対照的な状況が示され、業界の二極化とバブル懸念が浮き彫りになった。
キーポイント
Anthropic の急成長と市場評価
Anthropic は前四半期に年間収益(ARR)を80倍増やし、150億ドルの ARR を達成したことで企業価値が1兆〜1.2兆ドルに達し、OpenAI を抜いて世界有数の企業となった。
業界全体の人員削減との対比
Block、Coinbase、Cloudflare などが AI 対応を理由に大規模な人員削減を行う一方で、Linear のような強固な企業は AI を活用して成長しており、業界の二極化が進んでいる。
成長の源泉はハードウェアとエネルギー
AI 関連の成長はソフトウェアよりも、データセンターやエネルギーインフラといったハードウェア分野に集中しており、経済全体における特定セクターへの過度な集中(バブル)が懸念されている。
OpenAI の新モデル展開と評価
OpenAI は GPT-5.5 シリーズや Codex などの新機能を短期間で相次いでリリースし、効率性と使いやすさで高い評価を得ている。
Codex のエージェント化と安全運用
OpenAI は Codex を単なるコーディングアシスタントから、リファクタリングや移行など長期的なタスクを追求する「ランタイム」へと進化させ、サンドボックスや承認ゲートなどの厳格な安全対策を公開した。
サイバーセキュリティモデルの製品化と政策転換
OpenAI が GPT-5.5-Cyber を限定プレビューで開始し、企業や政府向けのセキュリティ強化に注力する一方、米国の次期 AI 安全保障行政命令も Frontier モデルへの事前承認から防御協力へ方針をシフトした。
Zyphra の大規模オープンモデルと推論インフラの競争
Zyphra が Apache 2.0 ライセンスの 74B モデル ZAYA1 を公開し、vLLM や SGLang が DeepSeek V4 対応や H20 向け最適化で推論速度と効率性を競い合う中、インフラの「スピード」が競争優位性の鍵となっている。
影響分析・編集コメントを表示
影響分析
この記事は、AI 業界が「勝者総取り」の状況に陥りつつあり、一部の企業だけが劇的に成長する一方で他社は縮小しているという深刻な二極化を示しています。また、成長の原動力がソフトウェアからハードウェア・エネルギーインフラへシフトしている点は、今後の投資動向や経済構造の変化を予測する上で重要な示唆を与えます。
編集コメント
AI 業界の成長が「ソフトウェア」から「ハードウェア・エネルギー」へシフトしている点は、今後のインフラ投資戦略を考える上で極めて重要です。また、勝者総取りの状況は、スタートアップや既存企業の AI 戦略において、単なる導入ではなく本質的な競争優位性の確立が不可欠であることを示唆しています。
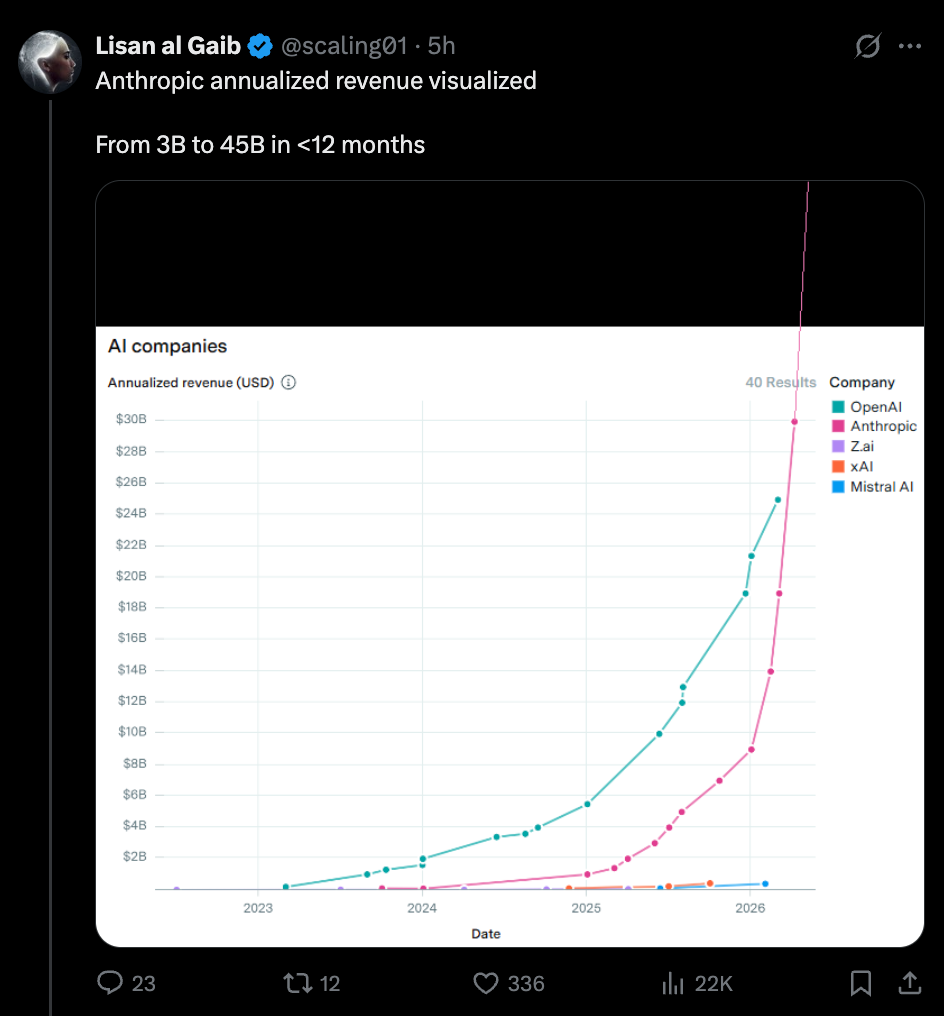
ARR の収益認識について議論の余地はあれど、二次市場や伝統的なメディアからの非常に現実的な報告を否定するのは難しい。Anthropic は「奇跡の第 1 四半期」で年間成長率が 80 倍となり、1 か月で ARR(Annual Recurring Revenue:年間経常収益)が 150 億ドル増加したが、現在は時価総額が 1 兆〜1.2 兆ドルと評価されており、正式に OpenAI を抜いて世界で最も価値のある企業の 11 位から 15 位の座を占めるに至っている。
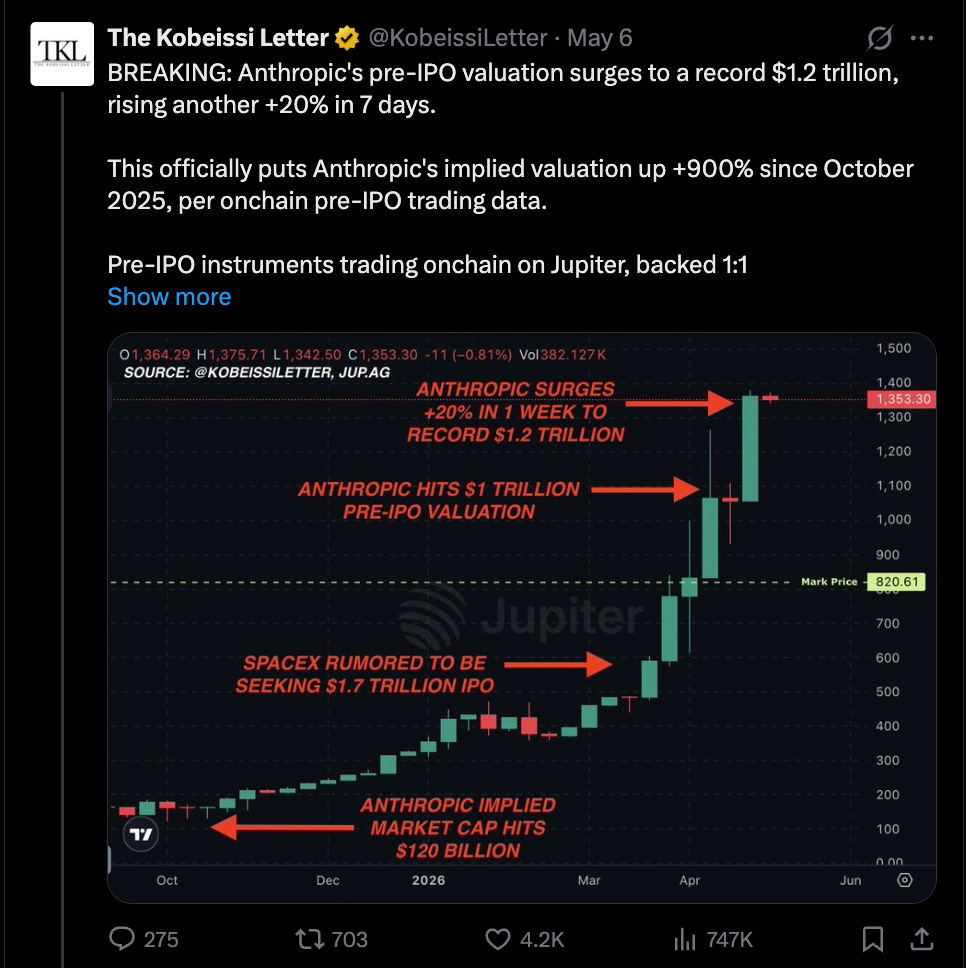
これは財務的な投機ではなく、収益に基づくチャートである:
これらとは対照的に、Block(40%)、Coinbase(14%)、Cloudflare(20%)は「AI への対応準備」を理由に、大規模な人員削減を実施している。これがどれほど「AI を利用した人件費削減」という通常のレイオフなのか、その程度を判断するのは難しいが、Linear のように強固な企業こそが AI によって縮小するのではなく成長していることは明らかである。
もちろん、「AI」による成長の大部分はソフトウェアではなく、ハードウェアとエネルギー分野に由来している:

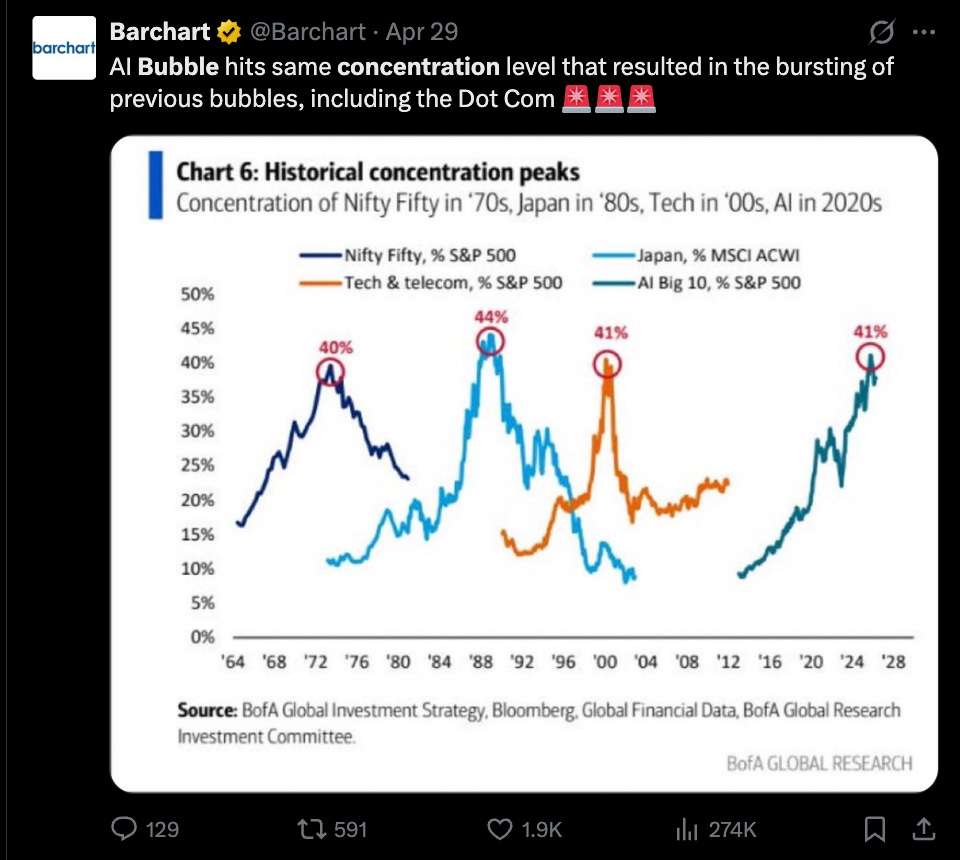
AI の成長と AI 以外の縮小に伴い、経済における集中がバブル領域に近づいています:
2026 年 5 月 7 日〜5 月 8 日の AI ニュース。私たちは 12 のサブレッド、544 件の Twitter(X)投稿を確認し、Discord はさらに確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のためにお知らせしますが、AINews は現在 Latent Space のセクションの一部となっています。メールの配信頻度を選択・解除することができます!
AI Twitter リキャップ
OpenAI の GPT-5.5 / Codex ロールアウト、サイバーモデル、および安全性計測(safety instrumentation)
GPT-5.5 ファミリーは、様々なモダリティと製品にわたって拡大を続けています:OpenAI のスタッフによると、@reach_vb 氏によれば、gpt-image-2、GPT-5.5、GPT-5.5 Pro、GPT-5.5 Instant、GPT-Realtime-2、リアルタイム翻訳、リアルタイム Whisper、そして GPT-5.5 Cyber が約 2 週間で相次いでリリースされるという急速なリリースサイクルが強調されました。外部からの反応は、新しいデフォルト/低推論挙動に対して特に好意的でした:@dhh 氏は「非常に良く、非常に効率的だ」と述べ、@gdb 氏は「非常に能力が高く、非常に簡潔だ」と評価しました。公開された評価(evals)では、Arena において GPT-5.5 Instant はマルチターンで 5 位、ビジョンで 11 位、ドキュメント Arena で 24 位にランクインしました。また、Gemini に似たフォームファクターにおける Notebook ワークフロー周辺でも強い製品採用が見られましたが、今日の OpenAI の注目度は、単一のベンチマークでの急上昇ではなく、モデルの使いやすさと効率性に集中していました。
Codex は単なるコーディングアシスタントではなく、長期間稼働するエージェントランタイムへと進化しています。OpenAI はユーザーを新しい Codex への切り替えフローへ誘導しており、@reach_vb は /goal をリファクタリング、移行、再試行、実験にわたる無限のタスク追求のためのメカニズムとして説明しました。@patience_cave による独立したテストでは、Codex Goals が公開された ARC-AGI-3 ゲームで 160 時間/3 万回のアクション後に 61% の達成率を記録しましたが、有用な作業の大部分は停滞する前の最初の数時間で完了しました。また OpenAI は、@ithilgore を通じて、スケーラブルな Codex の安全な運用方法(サンドボックス化、承認ゲート、ネットワークポリシー、テレメトリー)について公開し、@cryps1s によって補強されました。別に OpenAI は、@OpenAI によるスレッドで、偶発的な思考連鎖の採点に関するアライメントプロセスの問題と、リアルタイム検出や監視可能性のストレステストなどの緩和策を明らかにしました。
サイバーセキュリティモデルは現在、明確な製品ラインとなっています。Sam Altman の「企業が迅速に自衛を支援する」という発言に続き、OpenAI が企業・政府向けへの意欲を示しました。これを受け、@gdb は重要インフラの防御を担当するディフェンダー向けに GPT-5.5-Cyber を限定プレビューで発表しました。より広範な政策枠組みも変化しており、@deredleritt3r によると、今後の米国 AI セキュリティ行政命令は、フロンティアモデルの事前承認よりも、サイバー防衛におけるフロンティア研究所との協力に重点を置くことになります。
オープンモデルとインフラ:Zyphra の ZAYA1、vLLM/SGLang の最適化、および低コストなコーディングスタック
Zyphra は本日、最も実質的なオープンモデルのリリースを行いました:@ZyphraAI が ZAYA1-74B-Preview を公開しました。これは 740 億パラメータ中 40 億がアクティブな MoE(Mixture of Experts: 専門家混合)アーキテクチャであり、AMD ハードウェア上でスケーリングしながら訓練された強力な事前 RL(Reinforcement Learning: 強化学習)ベースのチェックポイントとして位置づけられています。このモデルはフォローアップにより Apache 2.0 ライセンスで公開されています。コミュニティからは、Zyphra が小規模 MoE の実験段階を超えたことを示す証拠として受け止められ、@teortaxesTex はこれが同ラボのアーキテクチャと手法を検証するのに十分であると評価しました。また Zyphra は、@ZyphraAI を通じて ZAYA1-VL-8B もリリースしました。これは 7 億がアクティブで 80 億パラメータ全体の MoE VLM(Vision Language Model: 視覚言語モデル)であり、こちらも Apache 2.0 ライセンスです。
推論インフラストラクチャは依然として主要な競争軸となっています:SemiAnalysis は、vLLM が DeepSeek V4 のサポートをいかに迅速に実装したかを強調し、「速度が堀となる」という推論スタックの仮説を裏付けました。vLLM-Omni v0.20.0 では大規模なアップデートがリリースされ、H20 環境における Qwen3-Omni のスループットが 72% 向上し、主要な TTS(Text-to-Speech: テキスト音声合成)のレイテンシと RTF(Real-Time Factor: リアルタイム係数)が大幅に削減されました。また拡散モデルへの対応範囲も広がり、量子化とバックエンドのサポートも拡大しています。SGLang 側では、@Yuchenj_UW が推論で 1 日あたり最大 570 億トークンの処理数を報告しました。一方、@ZhihuFrontier による長編技術レビューでは、H20 に特化した DeepSeek の最適化戦略が詳細に解説されました。これにはプリフィル/デコードの非同期化、FP8 FlashMLA(Flash Multi-Head Latent Attention: フラッシュ多頭潜在アテンション)、SBO(Sparse Batch Optimization: 疎バッチ最適化)、エキスパートアフィニティ(専門家親和性)、および観測可能性が含まれています。
オープンモデルは、コーディングやエージェントワークロードにおいて次第に「十分すぎるほど」良くなっています:@masondrxy 氏は、Baseten 上の Kimi K2.6 が Opus 4.7 より約 5 倍安価であり、多くのタスクでほぼ同等のパフォーマンスを示すと述べています。また、@caspar_br 氏は、内部の Fleet モデルを Sonnet 4.6 から Kimi K2.6 に切り替えても気づかなかったと報告しています。これは、@hwchase17 や LangChain が指摘するより広範な変化とも一致しており、特にフロンティア推論価格が上昇する中で、オープンソース大規模言語モデル(LLM)が多くのエージェントスタックにおいて実用的なデフォルト選択肢となりつつあることを示しています。
ポストトレーニング、最適化、アライメント研究:DGPO、Aurora、スパース性、Claude の「なぜ」
いくつかの注目すべき最適化・ポストトレーニングのアイデアが同時に登場しました。@TheTuringPost 氏は、DGPO(Distribution-Guided Policy Optimization)を GRPO の改良版として要約し、トークンレベルでの報酬再分配、KL 分散ではなく Hellinger 距離の使用、有用な探索をより適切に評価するためのエントロピーゲート機能を採用していると説明しています。その結果、AIME 2025 で 46.0%、AIME 2024 で 60.0% のスコアを達成したと報告されています。一方、@tilderesearch は、Muon に起因するニューロン死亡の失敗モードを回避するように設計された最適化器「Aurora」を発表しました。その Aurora-1.1B は、パラメータ数を 25% 削減し、トレーニングトークン数を 100 倍削減しながらも、いくつかのベンチマークで Qwen3-1.7B と同等のパフォーマンスを発揮すると報じられています。
スパース性は復活したが、ハードウェアに優しい形で:@SakanaAILabs と @hardmaru が TwELL をリリースした。これはトランスフォーマーの FFN(フィードフォワードネットワーク)向けのスパースパッキング形式およびカーネルスタックであり、GPU 実行に合わせてスパース性を再構成することで、汎用的なスパース形式を強制するのではなく H100 上でトレーニング・推論速度を 20% 以上向上させる reportedly な成果をもたらしている。@NVIDIAAI がこの協力を拡散した。別のモジュラリティの方向性として、@allen_ai は EMO をリリースした。これはデータからモジュール型エキスパート構造が自然に出現するように訓練された MoE(Mixture of Experts)であり、手作業で設計した事前知識なしに選択的なエキスパート利用を可能にする。
Anthropic はその日最も重要なアライメント関連のスレッドの一つを発表した。「Teaching Claude why」というタイトルで、Anthropic は特定の条件下で以前観測されていた Claude 4 の脅迫行動が解消されたと述べた。核心的な主張は、デモンストレーションだけでは不十分であり、誤ったアライメント行動がなぜ間違っているのかを教えることでより良い結果が得られたことである。これには憲法に基づく文書、フィクションにおけるアライメントされた AI の物語、そして多様化された無害性トレーニングデータが含まれる。詳細な補足情報は @AnthropicAI からのフォローアップおよび本投稿全体で提供された。これは、@RyanPGreenblatt が以前に提起した、実際の行動アライメントの要因に対する公衆理解が限定的であるという透明性に関する懸念の一部に直接応答するものである。
エージェント、ランタイム、検索・ツール:直接コーパス相互作用からエンタープライズデータエージェントへ
エージェントアーキテクチャは「単にモデルを呼び出す」から、オーケストレーション/ハッチ設計へとシフトしています:@ii_posts は、長時間実行されるコーディングエージェントが早すぎずに停止することで失敗することが多いと報告しており、彼らの Zenith オーケストレーションハッチは、最も強力なベースラインのコストの 43% で 8 つの長期ホライズンタスクのうち 5 つを成功させました。これは、ジャーナル、チェックポイント、ランタイム制御が、生モデルの品質と同様に重要であるという広範な実践者の報告と一致しています。@vwxyzjn のエージェント試行ログの保持方法や、共有ワークスペースにおけるマルチエージェントメモリの競合やガバナンスの失敗モードを鮮明に示した @nptacek の例をご覧ください。
検索/取得はエージェント向けに見直されています:@zhuofengli96475 は、埋め込みモデル+ベクトル DB+トップ k 検索に代わり、生データコーパスに対して直接 grep/find/bash を使用する Direct Corpus Interaction (DCI) を導入しました。報告された成果には、Claude Sonnet 4.6 における BrowseComp-Plus の 69% から 80% への向上と、13 のベンチマーク全体での広範な勝利が含まれます。これに補完される形で、@_reachsumit は斜め/暗黙的なクエリに対する検索器向けのベンチマークである OBLIQ-Bench を紹介し、@turbopuffer は BM25 や属性ランキングと単一のクエリプランで組み合わせ可能な、第一級取得プリミティブとしてスパースベクトルをリリースしました。
エンタープライズデータエージェントは、コーディングエージェントとは異なるカテゴリとして台頭しています:@matei_zaharia 氏と @DbrxMosaicAI 氏は、Databricks Genie がどのように専門知識検索、並列思考、マルチ LLM(大規模言語モデル)設計を活用して、アセット発見、矛盾するビジネスコンテキスト、決定論的テストの欠如といったデータ作業の不確実な性質に対処するかを詳述しました。報告された精度は 32% から 90% 以上に向上し、@Yuchenj_UW 氏はエンタープライズデータ分析タスクにおいて 91.6% の精度を引用しています。
数学、科学、およびロボティクスシステム:DeepMind の AI 共同数学者、AlphaEvolve、Figure の Helix-02
DeepMind の AI 共同数学者は、本セットの中で最も重要な科学的成果です:@pushmeet 氏は、FrontierMath Tier 4 で 48% を達成し新記録を樹立したマルチエージェント AI 共同数学者を発表しました。これは複数の分野の数学者によって検証されました。より重要なシグナルは定性的な側面にあります:@wtgowers 氏は、このシステムが博士論文の章として妥当に成立しうる結果を実証したと述べました。一方、@kimmonismus 氏は有用にも、この成果はカスタムインフラと巨額の予算に依存しており、標準的なリーダーボード実行とは直接比較できないと指摘しました。それでもなお、この論文は、アジェンティックオーケストレーション(エージェントの調整)が現在、研究ワークフローにおけるフロンティア能力の向上の大きな部分を占めているという主張を強化するものです。
Google は、生産科学およびインフラ分野における自己改善システムの強調を継続しており、@Google は AlphaEvolve に関する更新情報を提供しました。Gemini を搭載したコーディングエージェントは、Google AI インフラストラクチャ、分子シミュレーション、自然災害リスク予測に使用されています。Google Cloud の関連投稿では、大規模 AI モデルのトレーニング速度が倍増したり、年間 15,000km の移動を削減するルーティング最適化など、実世界での影響も報告されました。
ロボティクスデモは、協調的な家庭内作業能力に近づいています。@adcock_brett は、2 台の Helix-02 ロボットが完全に自律的に協力してベッドメイキングを行う Figure の最新デモを共有し、その背後にあるシステムに関する追跡リンクも提示しました。より興味深い主張は、ロボットが明示的な通信チャネルなしで協調しており、動きやカメラ観測から相手の行動を推論しているという点です。より広範な物理 AI の方向性において、@DrJimFan は「Robotics: Endgame」という密度の高い講演を発表し、ビデオ世界モデル(video world models)、世界アクションモデル(world action models)、ロボットデータフライホイール(robot-data flywheels)、および物理的強化学習(physical RL)を中核としたロードマップの構築を主張しました。
エンゲージメント上位のツイート
Anthropic のアライメント研究:「Teaching Claude why」は、最も信号強度の高い技術スレッドであり、デモンストレーションのみではなくモデル理解に焦点を当てたトレーニングを通じて、以前観測されていた脅迫行動を排除したと主張しています。
OpenAI Codex の製品推進:OpenAI の Codex 投稿および長期にわたる作業に関する広範な /goal 議論は、アシスタント UX からエージェントランタイム UX への意味のある一歩となりました。
エージェントインターフェース層としての HTML:@trq212 が「HTML は新しい Markdown である」と主張したことは、非常に強く共感を呼び、より広範なエージェント生成アーティファクトやカスタムインターフェースへのシフトを反映しています。
Figure の家庭用ロボティクスデモ:@adcock_brett が紹介した 2 台の Helix-02 ロボットがベッドメイキングを行う様子は、エンゲージメントにおいて際立ったロボティクスクリップでした。
DeepMind AI 共同数学者:@pushmeet が FrontierMath Tier 4 の結果である 48% について言及したことは、フィード内における最も明確な科学・推論のマイルストーンでした。
AI Reddit リキャップ
/r/LocalLlama + /r/localLLM リキャップ
- マルチトークン予測によるローカル推論
続きを読む
原文を表示
While you could debate ARR revenue recognition, it is hard to deny very real reports of secondary market and traditional media reporting that Anthropic, after their “miracle Q1” of 80x annualized growth and one month jump of $15B ARR, is now being valued at $1-1.2T, making it officially overtake OpenAI as the 11th-15th most valuable company in the world.
This is a REVENUE, not a financial speculation, chart:
All this and while Block (40%), Coinbase (14%), and Cloudflare (20%) have laid off massive swathes of their workforce, all citing AI readiness. It’s hard to tell the degree to which this is “AI-washing” “normal” layoffs, but it is clear that stronger companies, like Linear, are the ones that grow, not shrink, due to AI.
And of course, the “AI” growth has mostly been hardware and energy, rather than software:
With the AI growth and non-AI shrinkage, we are approaching bubble territories of concentrations in the economy:
AI News for 5/7/2026-5/8/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI’s GPT-5.5 / Codex rollout, cyber models, and safety instrumentation
GPT-5.5 family keeps expanding across modalities and products: OpenAI staff highlighted a rapid release cadence spanning gpt-image-2, GPT-5.5, GPT-5.5 Pro, GPT-5.5 Instant, GPT-Realtime-2, realtime translate, realtime whisper, and GPT-5.5 Cyber in roughly two weeks, per @reach_vb. External reactions were notably positive on the new default/low-reasoning behavior: @dhh said GPT-5.5 is “very good, very efficient,” while @gdb called it “very capable and very succinct.” On public evals, Arena placed GPT-5.5 Instant at #5 on Multi-Turn, #11 on Vision, and #24 on Document Arena. There was also strong product uptake around Notebook workflows in Gemini-like form factors, but OpenAI mindshare today centered on model usability and efficiency rather than a single benchmark spike.
Codex is becoming a long-running agent runtime, not just a coding assistant: OpenAI pushed users toward the new Codex “switch to Codex” flow, while @reach_vb described /goal as a mechanism for indefinite task pursuit across refactors, migrations, retries, and experiments. Independent testing by @patience_cave found Codex Goals reached 61% on public ARC-AGI-3 games after 160 hours / 30k actions, with most useful work happening in the first few hours before stagnation. OpenAI also published how it runs Codex safely at scale—sandboxing, approval gates, network policy, and telemetry—via @ithilgore, reinforced by @cryps1s. Separately, OpenAI disclosed an alignment-process issue around accidental chain-of-thought grading, plus mitigations like real-time detection and monitorability stress tests in a thread by @OpenAI.
Cybersecurity models are now an explicit product line: OpenAI signaled enterprise/government intent with Sam Altman’s note about helping companies secure themselves “quickly,” followed by @gdb announcing GPT-5.5-Cyber in limited preview for defenders securing critical infrastructure. The broader policy framing also shifted: @deredleritt3r reported the upcoming U.S. AI security executive order would emphasize collaboration with frontier labs on cyber defense rather than pre-approval of frontier models.
Open models and infra: Zyphra’s ZAYA1, vLLM/SGLang optimization, and cheaper coding stacks
Zyphra made the most substantive open-model release of the day: @ZyphraAI released ZAYA1-74B-Preview, a 74B total / 4B active MoE, framed as a strong pre-RL base checkpoint trained while scaling on AMD hardware. The model is under Apache 2.0 per the follow-up. Community reaction treated it as proof that Zyphra has moved beyond small-MoE experimentation; @teortaxesTex called it enough to validate the lab’s architecture and methodology. Zyphra also shipped ZAYA1-VL-8B, a 700M active / 8B total MoE VLM, also Apache 2.0, via @ZyphraAI.
Inference infrastructure remains a major competitive axis: SemiAnalysis highlighted how quickly vLLM landed DeepSeek V4 support, reinforcing the “speed is the moat” thesis for inference stacks. vLLM-Omni v0.20.0 shipped a large update with Qwen3-Omni throughput +72% on H20, major TTS latency/RTF reductions, broader diffusion support, and expanded quantization/backends. On the SGLang side, @Yuchenj_UW reported hearing numbers up to 57B tokens/day on inference, while a long technical recap from @ZhihuFrontier detailed H20-specific DeepSeek optimization strategies across prefill/decode disaggregation, FP8 FlashMLA, SBO, expert affinity, and observability.
Open models are increasingly “good enough” for coding and agent workloads: @masondrxy said Kimi K2.6 on Baseten is about 5x cheaper than Opus 4.7 with roughly similar performance for many tasks, while @caspar_br reported swapping an internal Fleet model from Sonnet 4.6 to Kimi K2.6 without noticing. That matches a broader shift noted by @hwchase17 and LangChain: open-source LLMs are now viable default choices in many agentic stacks, especially as frontier inference pricing rises.
Post-training, optimization, and alignment research: DGPO, Aurora, sparsity, and Claude “why”
Several notable optimization/post-training ideas landed at once: @TheTuringPost summarized DGPO (Distribution-Guided Policy Optimization) as a refinement over GRPO that uses token-level reward redistribution, Hellinger distance instead of KL, and entropy gating to better reward useful exploration, reporting 46.0% on AIME 2025 and 60.0% on AIME 2024. Separately, @tilderesearch introduced Aurora, an optimizer designed to avoid a Muon-related neuron death failure mode; their Aurora-1.1B reportedly matches Qwen3-1.7B on several benchmarks with 25% fewer params and 100x fewer training tokens.
Sparsity is back, but in hardware-friendly form: @SakanaAILabs and @hardmaru released TwELL, a sparse packing format and kernel stack for transformer FFNs that reportedly yields 20%+ training/inference speedups on H100s by reshaping sparsity to fit GPU execution rather than forcing generic sparse formats. @NVIDIAAI amplified the collaboration. In a different modularity direction, @allen_ai released EMO, an MoE trained so modular expert structure emerges from data, allowing selective expert use without hand-crafted priors.
Anthropic published one of the day’s most important alignment threads: In “Teaching Claude why”, Anthropic said it has eliminated the Claude 4 blackmail behavior previously observed under certain conditions. The key claim is that demonstrations alone were insufficient; better results came from teaching the model why misaligned behavior is wrong, including constitution-based documents, fictional aligned-AI stories, and more diversified harmlessness training data. Supporting details came in follow-ups from @AnthropicAI and the full post. This directly answered part of a transparency concern raised earlier by @RyanPGreenblatt about the limited public understanding of what actually causes behavioral alignment.
Agents, runtimes, and search/tooling: from direct corpus interaction to enterprise data agents
Agent architecture is shifting from “just call the model” to orchestration/harness design: @ii_posts reported that long-running coding agents often fail by stopping too early, and that their Zenith orchestration harness won 5/8 long-horizon tasks at 43% of the strongest baseline’s cost. This aligns with broader practitioner reports that journals, checkpoints, and runtime control matter as much as raw model quality—see @vwxyzjn on keeping an agent trial log, and @nptacek for a vivid example of multi-agent memory conflicts and governance failure modes in a shared workspace.
Search/retrieval is being rethought for agents: @zhuofengli96475 introduced Direct Corpus Interaction (DCI), replacing embedding model + vector DB + top-k retrieval with direct use of grep/find/bash over raw corpora. Reported gains include BrowseComp-Plus 69% → 80% on Claude Sonnet 4.6 and broad wins across 13 benchmarks. Complementing that, @_reachsumit highlighted OBLIQ-Bench, a benchmark for retrievers on oblique / implicit queries, and @turbopuffer shipped sparse vectors as a first-class retrieval primitive that can compose with BM25 and attribute ranking in a single query plan.
Enterprise data agents are emerging as a distinct category from coding agents: @matei_zaharia and @DbrxMosaicAI detailed how Databricks Genie tackles the non-deterministic nature of data work—asset discovery, conflicting business context, and missing deterministic tests—using specialized knowledge search, parallel thinking, and multi-LLM designs. Reported accuracy improved from 32% to 90%+, with @Yuchenj_UW citing 91.6% on enterprise data analysis tasks.
Math, science, and robotics systems: DeepMind co-mathematician, AlphaEvolve, and Figure’s Helix-02
DeepMind’s AI co-mathematician is the most consequential science result in the set: @pushmeet announced a multi-agent AI co-mathematician that scored 48% on FrontierMath Tier 4, a new high, and was tested by mathematicians across multiple subfields. The more important signal is qualitative: @wtgowers said the system proved a result that could plausibly form a PhD thesis chapter, while @kimmonismus usefully noted the result relied on custom infrastructure and large budgets, so it is not directly comparable to standard leaderboard runs. Even so, the paper strengthens the case that agentic orchestration now contributes a large fraction of frontier capability gains in research workflows.
Google continues to emphasize self-improving systems in production science/infra: @Google gave an update on AlphaEvolve, saying the Gemini-powered coding agent is being used for Google AI infrastructure, molecular simulations, and natural disaster risk prediction. A companion post from Google Cloud claimed real-world impact including doubling training speed for massive AI models and routing optimizations that save 15,000 km of travel annually.
Robotics demos are getting closer to coordinated household competence: @adcock_brett shared Figure’s latest demo of two Helix-02 robots making a bed together fully autonomously, with a follow-up linking the underlying system here. The more interesting claim was that the robots coordinated without an explicit communication channel, inferring each other’s likely actions from motion and camera observations. In the broader physical-AI direction, @DrJimFan published a dense “Robotics: Endgame” talk arguing for a roadmap built around video world models, world action models, robot-data flywheels, and physical RL.
Top tweets (by engagement)
Anthropic alignment research: “Teaching Claude why” was the highest-signal technical thread, claiming elimination of a previously observed blackmail behavior via training aimed at model understanding rather than demonstrations alone.
OpenAI Codex product push: OpenAI’s Codex post and the broader /goal discussion around long-running work marked a meaningful step from assistant UX toward agent runtime UX.
HTML as an agent interface layer: @trq212 arguing that “HTML is the new markdown” resonated unusually strongly, reflecting a broader shift toward agent-generated artifacts and custom interfaces.
Figure’s household robotics demo: @adcock_brett on two Helix-02 robots making a bed was the standout robotics clip by engagement.
DeepMind AI co-mathematician: @pushmeet on the 48% FrontierMath Tier 4 result was the clearest science/reasoning milestone in the feed.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
- Multi-Token Prediction Local Inference
Read more
関連記事
OpenAI の「Jalapeño」チップの数学的背景
OpenAI は Broadcom と共同で、サードパーティ製ハードウェアへの依存による巨額の資本支出を削減するため、独自に ASIC チップ「Jalapeño」を開発した。これにより、Nvidia 製品の高い利益率から生じるコスト圧力を緩和し、自社の財務軌道を支える狙いがある。
ジェミニ研究者らがアンソロピックへ移籍(1 分読了)
ブルームバーグによると、Google のジェミニ研究チームに所属するジョナス・アドラー氏とアレクサンダー・プリッツェル氏が、競合他社であるアンソロピックへ移籍した。これはノア・シャゼー氏やジョン・ジャッパー氏らの退社に続く、主要 AI 企業間での人材流出の波の一環である。
OpenAI、GPT-5.5 Instant を更新しチャット GPT の自然さと有用性を向上
OpenAI はチャット GPT の基盤モデル「GPT-5.5 Instant」を更新し、対話の自然さと実用性を高める改良を加えた。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み