インテリジェントドキュメント処理のためのスキーマ生成自動化
AWS は、文書クラスを事前に知らなくても自動的にクラスタリングとスキーマ生成を行う新機能により、インテリジェントドキュメント処理(IDP)の導入障壁を大幅に低下させた。
キーポイント
多文書発見機能の登場
未知の大量文書を自動的に分析し、視覚的埋め込みを用いてタイプごとにクラスタリングする新機能が追加された。
スキーマ生成の自動化
生成AI エージェントを活用して、各クラスタに対して抽出すべきフィールド定義を含むスキーマを自動的に作成する。
IDP Accelerator との連携強化
既存の IDP Accelerator の Discovery モジュールが補完され、事前の文書分類知識なしで即座に処理パイプラインを構築可能になった。
影響分析・編集コメントを表示
影響分析
この発表は、文書処理プロジェクトの初期段階における最大のボトルネックである「スキーマ設計と分類」を自動化することで、企業が大規模なドキュメントデータを即座に活用可能にする重要な転換点です。特に未整理の大量データを持つ組織にとって、AI 導入の壁を下げ、ROI を早期に達成するための実用的な手段を提供します。
編集コメント
文書処理の自動化において、最も時間がかかる「前処理(分類とスキーマ定義)」を解消する画期的なアップデートです。実務レベルでの導入コスト低下に直結するため、注目すべき進展と言えます。
インテリジェントドキュメント処理(IDP)の手法を用いて文書から情報を抽出するには、まず各文書クラスに対して何を抽出するかを定義するスキーマが必要です。しかし、数千もの文書があり、どのようなクラスが存在するかさえわからない場合に、どのようにしてスキーマを作成すればよいのでしょうか?これを大規模に実行しようとすると多大な手作業が必要となり、その後の IDP 取り組みの正当性を説明することが困難になります。
本記事では、当社のマルチドキュメント発見機能がこの問題をどのように解決するかをご紹介します。これは自動化された前処理ステップとして機能し、未知の文書を分析してタイプ別にクラスタリングし、IDP Accelerator で使用可能なスキーマを生成します。新しい機能では、自動クラスタリングにビジュアルエンベディング(視覚的埋め込み)を、スキーマ生成にはエージェントを活用する方法について解説します。また、ご自身の文書コレクションでこのソリューションを実行する手順もご案内します。
IDP アクセラレーター
IDP Accelerator は、ドキュメントの自動処理と情報抽出のためのスケーラブルでサーバーレスなオープンソースソリューションです。このソリューションを特定のドキュメントタイプに合わせてカスタマイズするには、クラスとフィールドを指定する 設定ファイル が必要です。最小限の設定例については、IDP Accelerator の GitHub リポジトリ を参照してください。
ドキュメントタイプを十分に理解していない場合、このスキーマを作成するのは困難です。IDP Accelerator には ディスカバリーモジュール が含まれており、単一のサンプルドキュメントからクラス設定を初期化できます。ただし、すでにドキュメントクラスを知っており、各クラスに対して代表的なサンプルドキュメントを特定できる必要があります。本記事で紹介するマルチドキュメントディスカバリー機能は、この前提条件を取り除き、ラベル付けされていないドキュメントコレクションに IDP Accelerator を適用するための道のりを加速します。
ソリューション概要
以下の動画は、IDP Accelerator コンソールにおけるソリューションを示しています。
多文書発見機能は、分類されていないドキュメントコレクションを、下流の IDP イニシアチブに備えた構造化されたスキーマへ自動的に変換します。このソリューションは、IDP アクセラレータの既存の Discovery モジュールに統合されています。これは、「単一ドキュメント」発見機能に並ぶ新しい「複数ドキュメント」機能です。オーケストレーションとサーバーレスコンピューティングには、AWS Step Functions ステートマシンと AWS Lambda 関数が提供されます。このソリューションは、Amazon Simple Storage Service (Amazon S3) バケットまたは Zip ファイルのアップロードからドキュメントを処理します。Amazon Bedrock を通じて利用可能なモデルがスキーマを生成し、自動的に IDP Accelerator 設定ファイルに統合されます。以下の図は完全なワークフローを示しています。
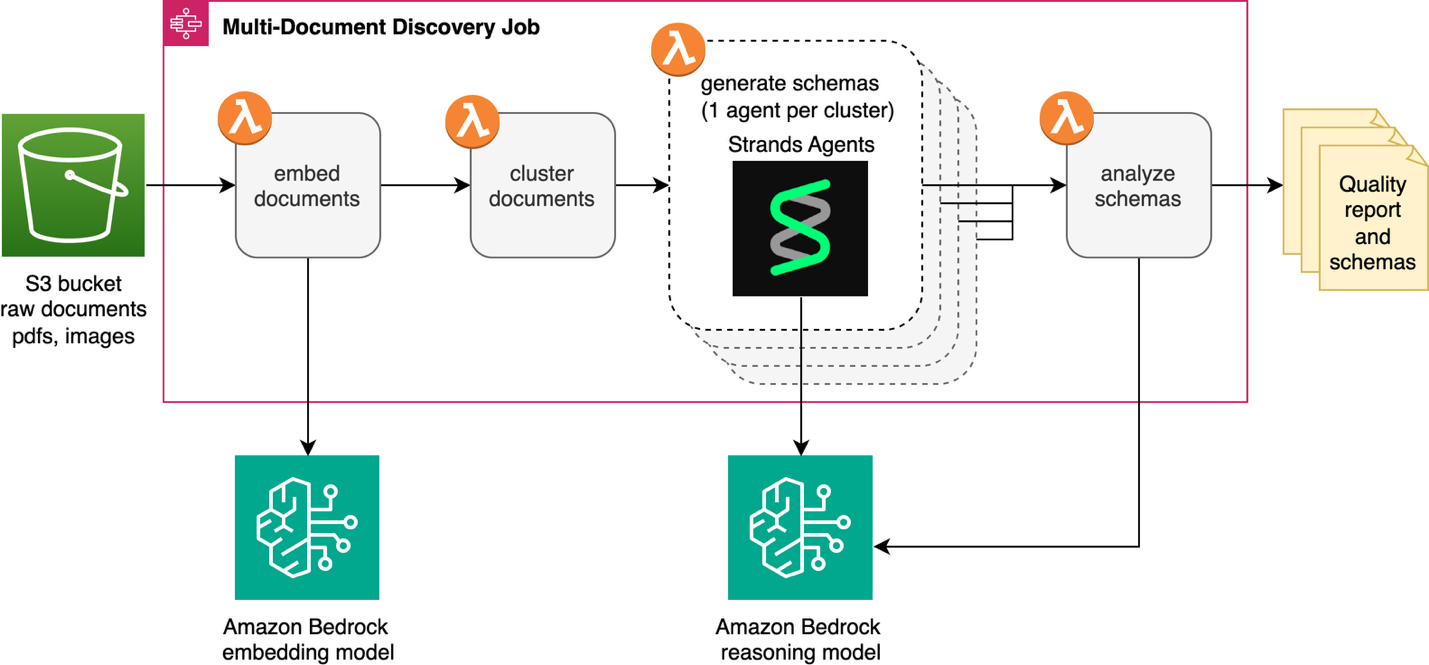
発見ジョブは、Amazon S3 内の各ドキュメントを Amazon Bedrock で利用可能な埋め込みモデルを使用してベクトル埋め込みに変換することから始まり、類似するドキュメントをクラスタリングします。Strands Agents と Amazon Bedrock の大規模言語モデル(LLM)で構築されたエージェントが各クラスタを分析し、ドキュメントの種類を特定してスキーマを生成します。最後に、リフレクションステップでスキーマを相互にレビューし、最終的な確認前に重複や不整合を検出します。
技術詳細
プロセスの各ステップを順を追って説明し、重要な意思決定と実装の詳細について解説します。
埋め込み生成
このワークフローでは、各ドキュメントに対して埋め込みを作成し、視覚的特徴を数値表現に変換します。多ページドキュメントの場合、最初のページのみが使用されます。現在、このワークフローは OCR ベースのテキストではなく視覚的埋め込みを使用しています。これは、テキストコンテンツが類似している場合でも、ドキュメントの種類を区別するレイアウト、書式、構造的な手がかりを視覚的埋め込みが捉えることができるためです。本ソリューションでは、発見ジョブのデフォルト埋め込みモデルとして Cohere Embed v4 を Amazon Bedrock 経由で使用しています。埋め込みステップは、画像圧縮、リトライロジック、レート制限といった一般的な課題や障害を自動的に処理します。
ドキュメントクラスタリング
マルチドキュメント発見機能は、シルエットスコア) を用いて、コレクション内に存在するドキュメントタイプの数を学習します。この文脈において、シルエットスコアはクラスター間の分離度合いと、各クラスター内のドキュメントの凝集度を測る指標として機能します。k-means クラスタリング(k-means clustering)を用いて、エージェントはデフォルトで k 値を 2 から 20 の範囲でテストし、最も高いシルエットスコアを示すグループ化を選択します。ここで k は、コレクション内の異なるドキュメントタイプの数を表します。意味のあるクラスターを作成するためには、各クラスターに少なくとも 2 つのドキュメントが含まれている必要があります。必要に応じて、この制約を満たすために k の上限値は 20 よりも低い値に引き下げられます。
エンベディングとクラスタリングの評価
エンベディングおよびクラスタリングのアプローチを検証するため、OCR-benchmark データセット のテストセットバケットに含まれるサブセットに対して、Cohere Embed v4 を用いた実験を行いました。このバケット名を確認するには、CloudFormation コンソールにアクセスし、IDP Accelerator スack を選択して「Outputs」タブを開き、「S3TestSetBucketName」というキーを探してください。
このデータセットは単一ページのドキュメントタイプで構成されています。デプロイされたサブセットには、9 つのドキュメントタイプ(銀行小切手、商業賃貸借契約書、クレジットカード明細書、配送伝票、機器点検記録、用語集、請願書フォーム、不動産関連書類、シフトスケジュール)にわたる 293 ドキュメントが含まれています。
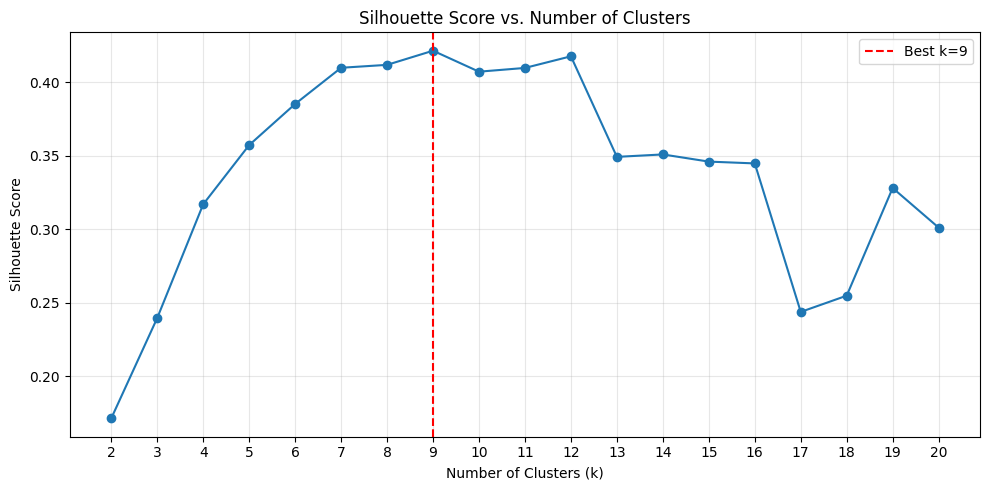
Cohere 埋め込みモデルを使用して、k-means クラスタリングがこれらのグループを正しく識別できるかを評価するために、最適な k 値を選択するための指標としてシルエットスコア(silhouette score)を検証しました。パイプラインの最初の 2 つの段階(埋め込みとクラスタリング)を実行し、k 値が 2 から 20 の範囲にわたるシルエットスコアを分析しました。以下のプロットは、これらの k 値におけるシルエットスコアの分布を示しています。最も高いシルエットスコアは k=9 で得られ、これはデータセット内の文書タイプの真の値(ground truth)と一致します。
TSNE プロット(t-distributed Stochastic Neighbor Embedding plot、高次元データを 2 次元空間に圧縮しつつデータ点間の関係を保持する可視化手法)は、これらの埋め込みを 2 次元空間で可視化したものであり、クラスタ分類の結果は凡例に表示されています。
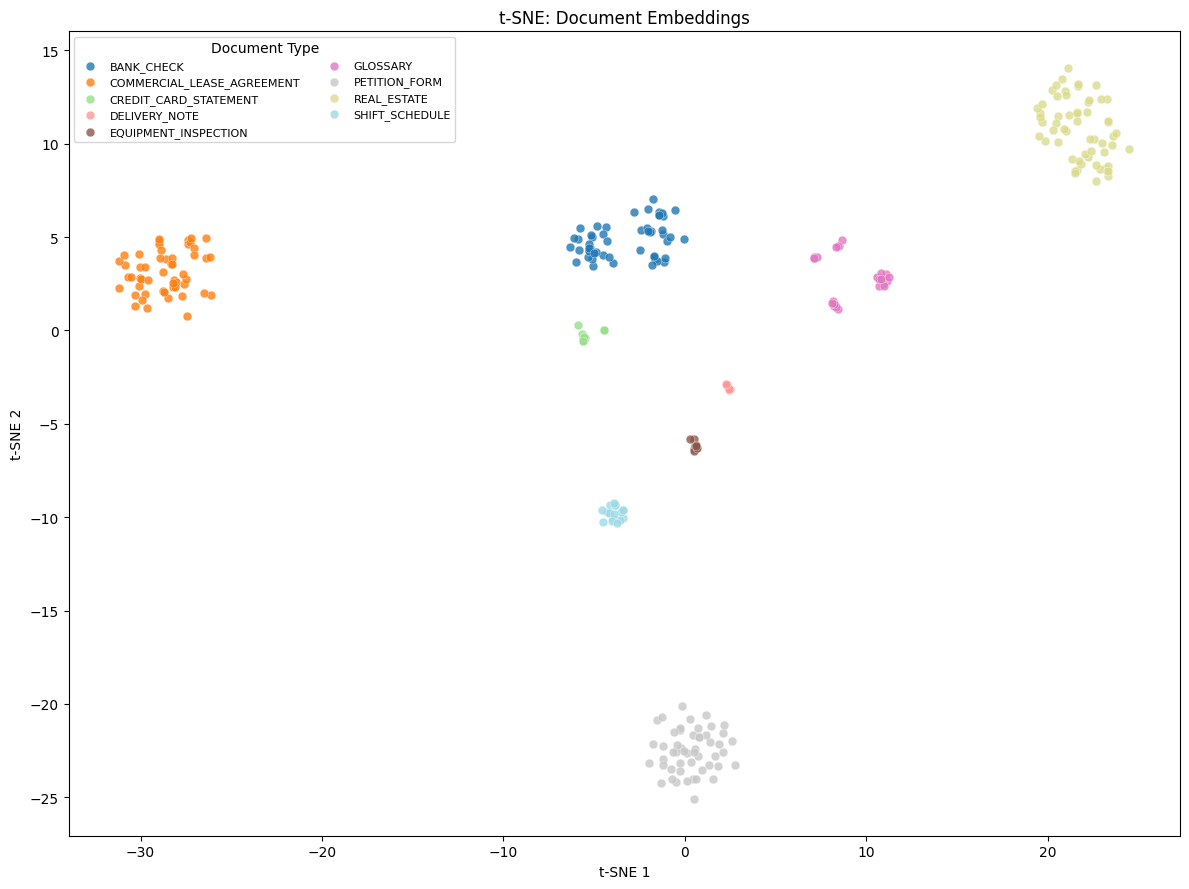
クラスタリングは、調整兰德指数(ARI)と正規化相互情報量(NMI)においてともに 1.0 という完璧な値を達成しました。ARI はクラスタリングが真のグループ分けとどれだけ一致しているかを測定する指標であり、NMI は予測されたクラスタと実際のクラスタの間で共有される情報の量を定量化するものです。すべてのクラスタは、100% の純度をもって、真の文書クラスと 1 対 1 で対応しています。これらの結果は、高品質なマルチモーダル埋め込みが、教師なしでの文書分類を可能にすることを示しています。これらの埋め込みは、ラベル付き学習データを用いずに、銀行小切手、不動産書類、クレジットカード明細など多様な文書タイプを正確に分離します。
注: このベンチマークデータセットにおけるパフォーマンスが、特定の文書データにおいても同様の結果を保証するものではありません。なぜなら、データセットの特性が結果の品質に直接影響を与えるからです。
エージェント型スキーマ生成
クラスタが特定された後、パイプラインはエージェントフェーズに入ります。各クラスタに対して Strands Agent が呼び出され、ドキュメントタイプの判定とスキーマの生成が行われます。モデル駆動アプローチを採用した Strands Agents を選定しました。これにより、モデルが各スキーマを自律的に推論する柔軟性が得られます。エージェントは、スキーマを生成する前にクラスタ内のさまざまな場所でドキュメントを戦略的に可視化し、多様性を十分に把握する必要があります。具体的には、中心付近のドキュメント 1 つ、周辺部のドキュメント 1 つ、そして中間距離にあるドキュメント 1 つを検査します。より決定論的で固定されたサンプリングアプローチではここでの要件を満たすことはできません。なぜなら、クラスタリングの品質は特定のドキュメントに大きく依存するためです。これを実現するために、エージェントには 2 つの専門ツールが用意されています。
- クラスタ分析ツール – クラスタ中心からの距離順に並べられたドキュメント ID を取得し、エージェントがクラスタ内の多様性の範囲全体を戦略的にサンプリングできるようにします。
- ドキュメントビューアツール – ドキュメント画像を取得・圧縮して視覚的な検査を可能にし、モデルのコンテキストウィンドウに対するサイズ制約を自動的に処理します。
エージェントのシステムプロンプトには、JSON Schema の慣習および IDP Accelerator 設定 の要件に関するドメイン専門知識が組み込まれています。このプロンプトはエージェントに対して以下を指示します。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
- 十分なカバレッジがあると確信できる場合は、戦略的にサンプルドキュメントを選択し、早期に停止する。
- 適切なメタデータ、型定義、および説明を含む JSON スキーマを生成する。
- x-aws-idp-document-type や x-aws-idp-evaluation-method など、IDP Accelerator 固有のアノテーションを含める。x-aws-idp-evaluation-method は、Stickler ベースの評価拡張機能によって使用される。
- 住所、行項目、税情報などの一般的な構造に対して再利用可能な $defs を作成する。
- フィールドのタイプに基づいて適切な評価方法を適用する:文字列には EXACT、数値には NUMERIC_EXACT、複雑なまたはネストされたオブジェクトには LLM を使用する。
これらのツール、プロンプト、およびモデルは、エージェントが自身のサンプリング戦略について推論する能力を備えるように装備している。これらのエージェントは並列で実行されるため、次のクラスターを開始する前に各クラスターの完了を待つ必要はない。
スキーマ分析
各エージェントが独立してスキーマを生成した後、スキーマ分析ステップでは出力間の全体的な差異性を評価します。発見されたドキュメントのグループ分けが明確に分離されているか、それとも重複しているかを検証し、生成されたスキーマが完全かつ一貫性があるかも確認します。また、ドキュメントタイプ間での冗長性や重複がないかも調査します。これらの知見に基づき、クラスタの統合やフィールド定義の精緻化など、具体的な推奨事項を提示します。さらに、クラスに関する人間が読みやすい概要を含むサマリーレポートを生成します。この品質レポートは、IDP Accelerator の Discovery Job 詳細画面で確認可能です。
ドキュメントでのジョブ実行
ご自身のドキュメントに対してマルチドキュメント発見ワークフローを実行するには、IDP Accelerator コンソールで以下の手順に従ってください。
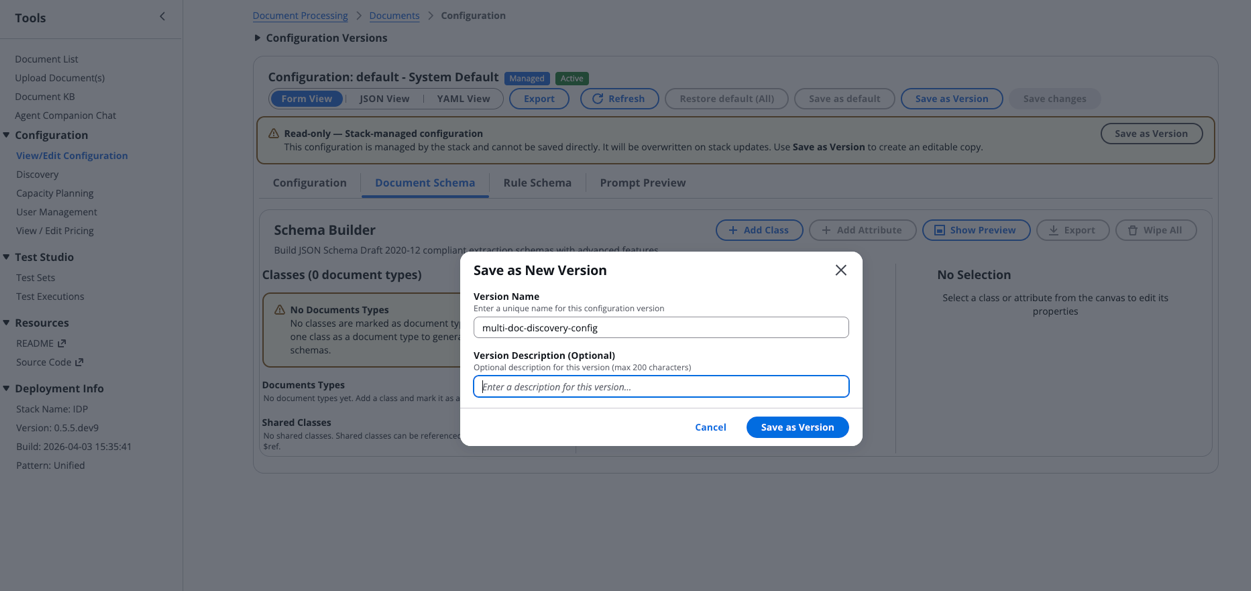
ステップ 1: 新しい設定の作成
まず、IDP Accelerator コンソールで新しい設定を作成します:
- 「Configuration」セクションに移動し、「View/Edit Configuration」を選択します。
- 「Document Schema」>「Wipe All」を選択して、新しい空の設定を作成します。
- 「Save as Version」を選択し、説明的なバージョン名を入力した後、再度「Save as Version」を選択します。
ステップ 2: マルチドキュメント発見の実行
設定が準備できたら、発見プロセスを開始します:
- Discovery セクションに移動し、[Multiple Documents] オプションを選択します。
- 先ほど作成した構成バージョンを選択します。
- ドキュメントソースを設定します:
[S3 Path] または [Zip Upload] のいずれかを選択してください。
- ソースバケットを選択します。
- ドキュメントが保存されている S3 プレフィックスを指定します。
注: Source Bucket オプションを使用するには、ドキュメントを IDP Accelerator の既存のバケット(Discovery Bucket、Test Bucket、または Input Bucket)のいずれかに追加する必要があります。
- [Start Discovery] を選択してステートマシンを開始します。
##
ステップ 3: 発見ジョブの監視と結果の確認
発見ジョブの進行状況を追跡します:
- [Multi-Document Discovery Jobs] テーブルに、実行ステータス、現在のステップ、メタデータを示す新しいエントリが表示されます。
- ジョブが完了したら、[Source] フィールドを選択して結果を表示します:
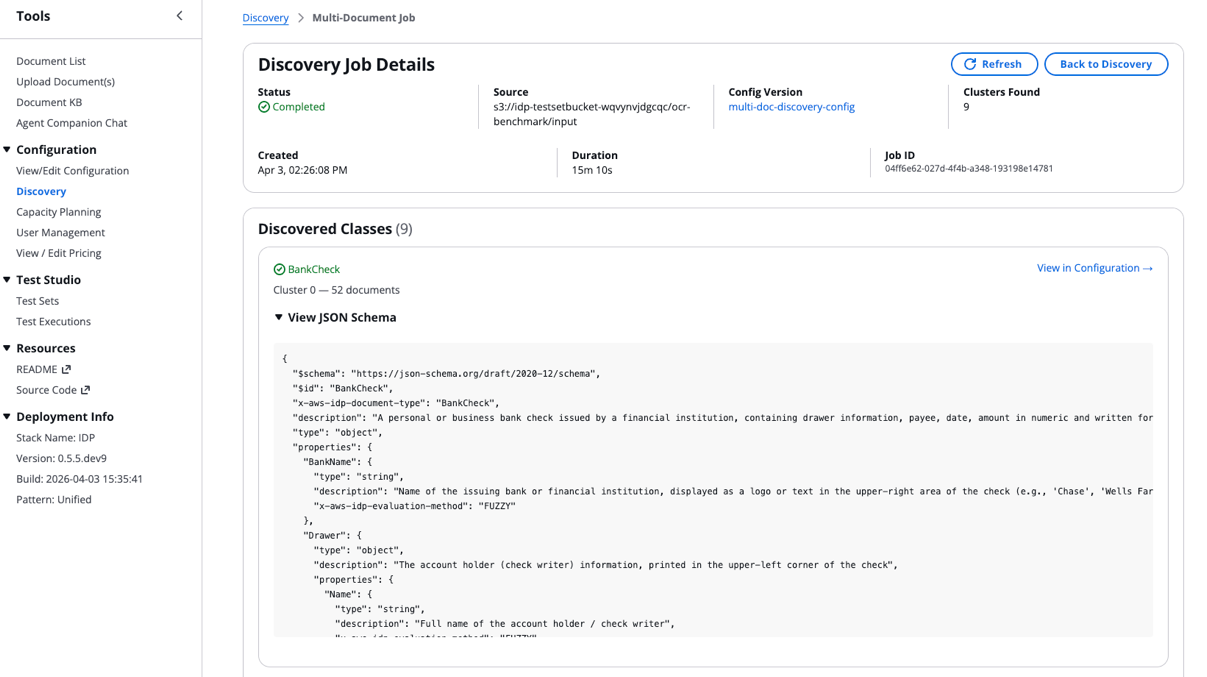
- Discovery Job Details の下部にスクロールして、Quality Report にアクセスします:
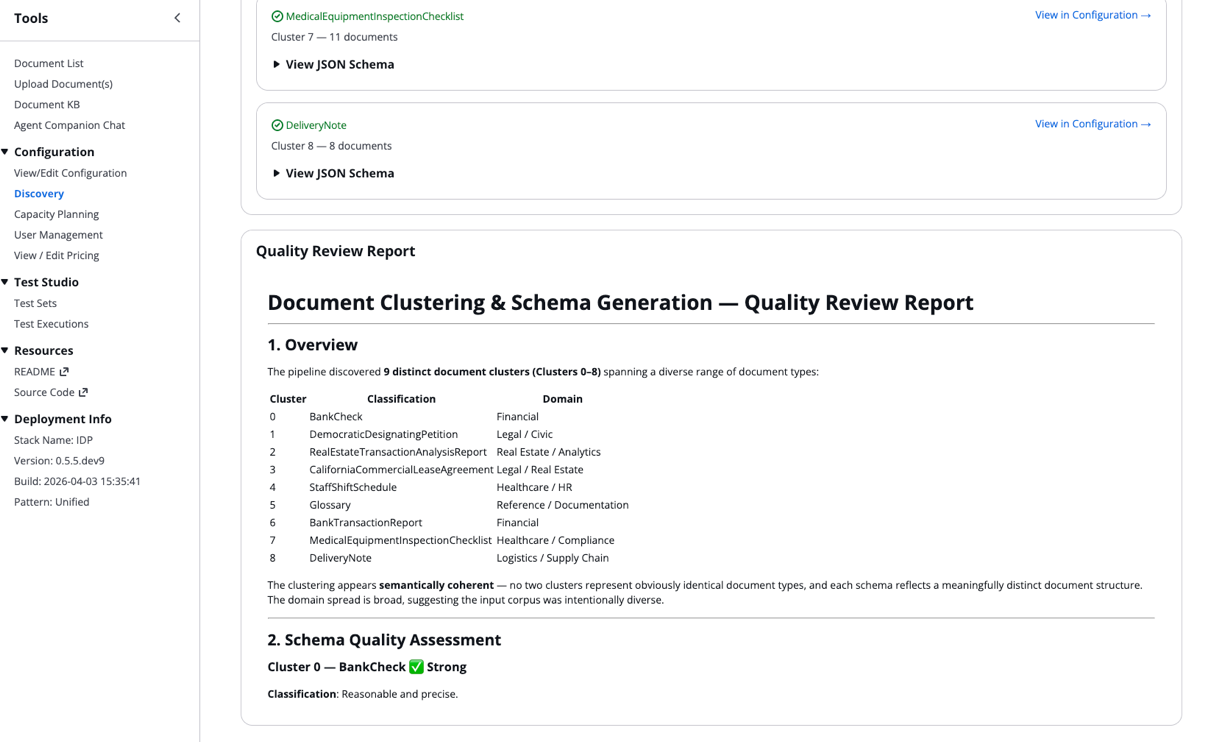
発見されたクラスとその JSON スキーマは、自動的に構成ファイルに統合されます。
Best practices for optimal results
スケーリングされたマルチドキュメント発見ジョブを実行する前に、念頭に置いておくべきいくつかのベストプラクティスがあります。現在のワークフローは各 PDF の最初のページのみを処理するため、入力ファイルが単一ドキュメントファイルであることを確認してください。複数ドキュメントのパケットはまだサポートされていません。初期結果を取得した後、スキーマを確定する前に、重複するクラスターや不均等なドキュメント分布といった問題を見逃さないよう、品質レポートのサマリーを徹底的にレビューしてください。
Next steps
ここから進むべき道は、ワークフローが文書内で発見した内容によって異なります:
- スキーマがクリーンで、品質レポートで重複率が低い場合: 文書に対して IDP をスケーリングして実行する準備が整いました。スキーマは自動的に IDP Accelerator の設定における classes フィールドに追加されます。
- 品質レポートで重複クラスターが警告された場合: レコメンデーションを確認し、それらを使用して生成されたスキーマを精緻化してください。これには、類似したスキーマを単一のクラスターに統合するか、重複を減らすためにフィールド定義を調整することが含まれる可能性があります。
- クラスター間でスキーマの品質が不均一な場合: ドキュメントコレクション内にドキュメントタイプの分布が極端に偏っていないか確認してください。よりバランスの取れたサブセットに対して発見ジョブを実行することで、エージェントがより信頼性の高いクラスターとスキーマを生成できるようになります。
結論
本記事では、ドキュメントを処理する前にスキーマが必要であるという課題と、スキーマを構築する前にドキュメントを処理する必要があるという課題を解決するマルチドキュメント発見機能についてご紹介しました。このソリューションは、ビジュアル埋め込み(visual embeddings)、自動クラスタリング、そして多モーダル大規模言語モデル(LLM)を用いたエージェント型スキーマ生成を組み合わせたものです。これにより、不明な文書の不透明なコレクションを、構造化されレビュー可能なドキュメントクラスおよびスキーマへと変換します。埋め込みの生成、クラスタの調整、並列分類とスキーマ生成のワークフロー処理方法をご覧いただいたことでしょう。また、リフレクションステップが、エージェントによって生成された出力に対する人間によるレビューのための透明な分析を提供する方法もご覧いただきました。
マルチドキュメント発見機能がお客様のドキュメントコレクションでどのように機能するか、ぜひお聞かせください。結果や質問、ご提案をコメント欄でお知らせください。
原文を表示
Before you can extract information from documents using intelligent document processing (IDP) techniques, you need a schema for each document class that defines what to extract. But how do you create schemas when you have thousands of documents and don’t know what classes exist? Doing this at scale can take substantial manual effort, making downstream IDP initiatives difficult to justify.
In this post, we’ll show you how our multi-document discovery feature solves this problem. It serves as an automated pre-processing step, analyzing unknown documents, clustering them by type, and generating schemas ready for the IDP Accelerator. You’ll learn how the new capability uses visual embeddings for automatic clustering and agents for schema generation. We’ll also walk you through running the solution on your own document collections.
IDP Accelerator
The IDP Accelerator is a scalable, serverless, open-source solution for automated document processing and information extraction. To customize the solution to your specific document types, it requires a configuration file where you specify the classes and fields. For a minimal configuration example, see the IDP Accelerator GitHub repo.
Without a good understanding of your document types, creating this schema can be difficult. The IDP Accelerator includes a Discovery Module that can bootstrap a class configuration from a single example document. However, you must already know your document classes and be able to identify a representative example document for each class. The multi-document discovery feature introduced in this post removes that prerequisite, accelerating your path to applying the IDP Accelerator to a collection of unlabeled documents.
Solution overview
The following video shows the solution in the IDP Accelerator Console.
The multi-document discovery feature automates the transformation of unclassified document collections into structured schemas ready for downstream IDP initiatives. This solution is integrated into the IDP accelerator’s existing Discovery Module. It’s a new “Multiple Document” capability alongside the “Single Document” discovery feature. An AWS Step Functions state machine and AWS Lambda function provide orchestration and serverless compute. The solution processes documents from an Amazon Simple Storage Service (Amazon S3) bucket or Zip file upload. Models available through Amazon Bedrock generate schemas that automatically integrate into the IDP Accelerator configuration file. The following diagram shows the full workflow.
The discovery job starts by converting each document in Amazon S3 into a vector embedding using an embedding model available on Amazon Bedrock, then groups similar documents into clusters. An agent built with Strands Agents and an Amazon Bedrock LLM analyzes each cluster to identify the document type and generate a schema. Finally, a reflection step reviews schemas together to catch overlaps and inconsistencies before your final review.
Technical details
We’ll walk through each step of the process, highlighting key decisions and implementation details.
Embedding generation
The workflow creates an embedding for each document, converting visual features into numerical representations. For multi-page documents, only the first page is used. Currently, the workflow uses visual embeddings rather than OCR-based text because visual embeddings capture layout, formatting, and structural cues that distinguish document types, even when the text content is similar. The solution uses Cohere Embed v4 through Amazon Bedrock as the default embedding model for the discovery job. The embedding step automatically handles common pain points and obstacles like image compression, retry logic, and rate limiting.
Document clustering
The multi-document discovery feature learns how many document types are in your collection using the silhouette score). In this context, the silhouette score provides a measure of how well-separated the clusters are from one another and how compact documents are within each cluster. Using k-means clustering, the agent tests k values from 2 to 20 by default and selects the grouping with the highest silhouette score. Here k represents the number of distinct document types in your collection. To create meaningful clusters, each must contain at least two documents. If necessary, the upper k bound is reduced below 20 to satisfy this constraint.
Benchmarking embeddings and clustering
To validate the embedding and clustering approach, we ran experiments with Cohere Embed v4 on the subset of the OCR-benchmark dataset available in the test set bucket deployed with the IDP Accelerator CloudFormation stack. To find your bucket name, go to the CloudFormation console, select your IDP Accelerator stack, open the Outputs tab, and look for the key S3TestSetBucketName.
This dataset consists of single-page document types. The deployed subset contains 293 documents across 9 document types: bank check, commercial lease agreement, credit card statement, delivery note, equipment inspection, glossary, petition form, real estate, and shift schedule.
To evaluate if k-means clustering can correctly identify these groupings using the Cohere embedding model, we tested the silhouette score as a metric for selecting the optimal k value. We ran the first two stages of the pipeline (embedding and clustering) and analyzed the silhouette score across k values ranging from 2 to 20. The following plot shows the silhouette score distribution across these k values. The highest silhouette score occurs at k=9, which matches the ground truth number of document types in the dataset.
The TSNE-plot (t-distributed Stochastic Neighbor Embedding plot, a visualization technique that reduces high-dimensional data to 2D space while preserving relationships between data points) shows the visualization of these embeddings in 2-dimensional space, with the cluster classification shown in the legend.
The clustering achieved a perfect Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI) of 1.0. ARI measures how well the clustering matches the true groupings, while NMI quantifies the amount of information shared between the predicted and actual clusters. Every cluster maps one-to-one to a ground truth document class at 100% purity. These results demonstrate that high-quality multimodal embeddings can enable fully unsupervised document classification. The embeddings accurately separate diverse document types, such as bank checks, real estate forms, and credit card statements, without labeled training data.
Note: Performance on this benchmark dataset does not guarantee similar results on your specific document data because the characteristics of your dataset directly influence the quality of the results.
Agentic schema generation
After the clusters are identified, the pipeline enters the agentic phase. For each cluster, a Strands Agent is invoked to determine the document type and generate a schema. We chose Strands Agents for its model-driven approach. It gives the model the flexibility to reason through each schema autonomously. The agent needs to strategically visualize documents at various locations within the cluster to capture the full variety before generating a schema. For example, it examines one document near the center, one at the periphery, and one at a middle distance. A more deterministic, fixed sampling approach wouldn’t work here because clustering quality depends heavily on your specific documents. To do this, the agent is equipped with two specialized tools:
- Cluster Analysis Tool – Retrieves document IDs ordered by distance from the cluster centroid, enabling the agent to sample strategically across the range of variation within the cluster.
- Document Viewer Tool – Fetches and compresses document images for visual inspection, automatically handling size constraints for the model’s context window.
The agent’s system prompt encodes domain expertise about JSON Schema conventions and IDP Accelerator configuration requirements. It instructs the agent to:
- Sample documents strategically, stopping early if confident it has sufficient coverage.
- Generate JSON Schemas with proper metadata, type definitions, and descriptions.
- Include IDP Accelerator-specific annotations such as x-aws-idp-document-type and x-aws-idp-evaluation-method. x-aws-idp-evaluation-methodis used by the Stickler-based evaluation extension.
- Create reusable $defs for common structures like addresses, line items, and tax information.
- Apply appropriate evaluation methods based on field type: EXACT for strings, NUMERIC_EXACT for numbers, LLM for complex or nested objects.
The tools, prompt, and model equip the agent with capabilities to reason about its own sampling strategy. These agents run in parallel, so you’re not waiting for each cluster to finish before the next one starts*.*
Schema analysis
After each agent independently generates a schema, the schema analysis step evaluates the holistic differentiation between the output. It assesses whether the discovered document groupings are well-separated or overlapping, and whether the generated schemas are complete and consistent. It looks for redundancies or duplication across document types. Based on these findings, it surfaces concrete recommendations such as merging clusters or refining field definitions. It produces a summary report including a human-readable overview of your classes. This quality report is visible to you in the Discovery Job details of the IDP Accelerator.
Running a job on your documents
To run the multi-document discovery workflow on your own documents, follow these steps in the IDP Accelerator Console.
Step 1: Create a new configuration
Start by creating a fresh configuration in the IDP Accelerator Console:
- Navigate to the Configuration section and select View/Edit Configuration.
- Choose Document Schema > Wipe All to create a new empty configuration.
- Select Save as Version, provide a descriptive Version Name, then choose Save as Version.
Step 2: Run multi-document discovery
With your configuration ready, initiate the discovery process:
- Navigate to the Discovery section and select the Multiple Documents option.
- Choose the configuration version you just created.
- Configure your document source:
Select either S3 Path or Zip Upload.
- Choose your source bucket.
- Specify the S3 prefix where your documents are stored.
Note: Your documents must be added to one of the IDP Accelerator’s existing buckets (Discovery Bucket, Test Bucket, or Input Bucket) to use the Source Bucket option.
- Choose Start Discovery to trigger the state machine.
##
Step 3: Monitor discovery job and view results
Track your discovery job progress:
- A new entry will appear in the Multi-Document Discovery Jobs table showing execution status, current step, and metadata.
- After the job completes, choose the Source field to view results:
- Scroll to the bottom of the Discovery Job Details to access the Quality Report:
The discovered classes and their JSON schemas automatically integrate into your configuration file.
Best practices for optimal results
Before you run the multi-document discovery job at scale, there are a few best practices worth keeping in mind. Because the workflow currently processes only the first page of each PDF, make sure your input files are single-document files. Multi-document packets aren’t yet supported. After you have initial results, thoroughly review the quality report summary to catch issues like overlapping clusters or uneven document distributions before you finalize your schemas.
Next steps
Where you go from here depends on what the workflow found in your documents:
- If your schemas look clean and the quality report shows low overlap: You’re ready to move forward with running IDP at scale on your documents. The schemas are automatically added to the classes field of the IDP Accelerator configuration.
- If the quality report flagged overlapping clusters, review the recommendations and use them to refine the generated schemas. This might include merging similar schemas into a single class or adjusting field definitions to reduce overlap.
- If schema quality is inconsistent across clusters: Check whether your document collection has a highly uneven distribution of document types. Running the discovery job on a more balanced subset can help the agent produce more reliable clusters and schemas.
Conclusion
In this post, we showed you how the multi-document discovery feature solves the challenge of needing schemas before you can process documents but needing to process documents before you can build schemas. The solution combines visual embeddings, automatic clustering, and agentic schema generation with multimodal LLMs. It transforms an opaque collection of unknown documents into structured, review-ready document classes and schemas. You’ve seen how the workflow handles embedding generation, cluster tuning, and parallel classification and schema generation. You’ve also seen how the reflection step gives you a transparent analysis into the agent’s generated output for human review.
We’d love to hear how the multi-document discovery feature works on your document collections. Share your results, questions, or suggestions in the comment
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み