Devin Fusion:コストを 35% 削減しながら最前線の性能を実現
Cognition は、最前線のモデルと低コストなサイドキックを並列実行する「Devin Fusion」を発表し、FrontierCode ベンチマークで最高水準の性能を維持しながらタスクあたりのコストを 35% 削減することに成功した。
キーポイント
コスト削減と性能維持の両立
Devin Fusion は、FrontierCode ベンチマークにおいて Fable 5 と同等のスコア(57.6)を達成しつつ、タスクあたりの平均コストを約 35% 削減($5.12 から $3.00)する成果を示した。
サイドキック・アーキテクチャ
最前線モデルと低コストな「サイドキック」モデルを並列で実行し、それぞれが独自のツールセットと文脈管理能力を持つことで、効率的なタスク処理を実現する。
動的セッションルーティング
単なる静的なラウティングではなく、セッション中盤に状況に応じてモデルを動的に切り替える技術により、実世界でのコード記述品質と統合可能性を向上させている。
影響分析・編集コメントを表示
影響分析
この発表は、AI エンジニアリングチームが「高コストな最前線モデルをすべてのタスクに使用するという非効率な慣行」から脱却するための具体的な解決策を示すものであり、LLM の実運用における ROI(投資対効果)の向上に直結する。特に、コード生成という複雑なタスクにおいて、単一モデル依存からの脱却とコスト最適化を両立させる手法は、業界全体のパラダイムシフトを促す重要な進展である。
編集コメント
単なるコスト削減ではなく、実用的なコード品質を維持したままの最適化は、企業導入における最大の課題解決となるため注目度が高い。ただし、ベンチマーク結果が実際の複雑な開発現場でどれほど再現されるかは、今後の実証が鍵となる。
Devin Fusion: フロンティア性能をコスト35%削減で実現
Cognition チーム 06.30.26
エンジニアリングチームは、資金を燃やしているようなものです。
すべてのタスクに最も高価なモデルを使用するのはもはや持続可能ではありません。しかし、既存のモデル混合ツールはひどいものです。多くのベンチマークでは美しく見えますが、実際にマージできるコードを書くことには失敗します。
Cognition では、知能を犠牲にすることなくフロンティアモデル間をルーティングすることに特化しています。本日、私たちはコスト削減と実世界での使用における知能維持を保ちながら、モデル混合において大幅に優れた新しい種類のマルチモデルハネスであるDevin Fusionに関する私たちの取り組みを発表します。私たちは、コードの正しさと品質の両方を測定する新しい最先端コーディングベンチマーク FrontierCode において、コストを35%削減しながらフロンティアおよび Fable 5 レベルのパフォーマンスを維持することを見出しました。
Devin Fusion: フロンティア性能をコスト35%削減で実現
FrontierCode 拡張ベンチマークでのスコアとタスクあたりの平均コスト
コスト スコア
$3.00
Fusion + Fable 5
57.6
$5.12
Fable 5(medium)
57.0
$3.24
Opus 4.8(high)
48.8
$2.38
Fusion
47.9
$3.64
GPT-5.5(high)
44.8
$2.70
GLM-5.2
43.0
この投稿の後半では、なぜ優れたモデルルーティングがそれほど難しいのか、そしてそれをすべて可能にする 2 つの技術について解説します:「サイドキック」アプローチとセッション中の動的ルーティングです。
プレビュー版で Devin Fusion をお試しください。app.devin.ai/signup よりアクセス可能です。
The Trick: Sidekick
私たちのアーキテクチャの鍵となるアイデアは、2 つの並列エージェントを実行することです。1 つは最先端モデルを備えたものであり、もう 1 つはよりコスト効率の良い「サイドキック」モデルです。両者とも独自のツールセットと、自らのコンテキストに基づいて情報を収集・行動する能力を持つ、完全に機能するエージェントです。
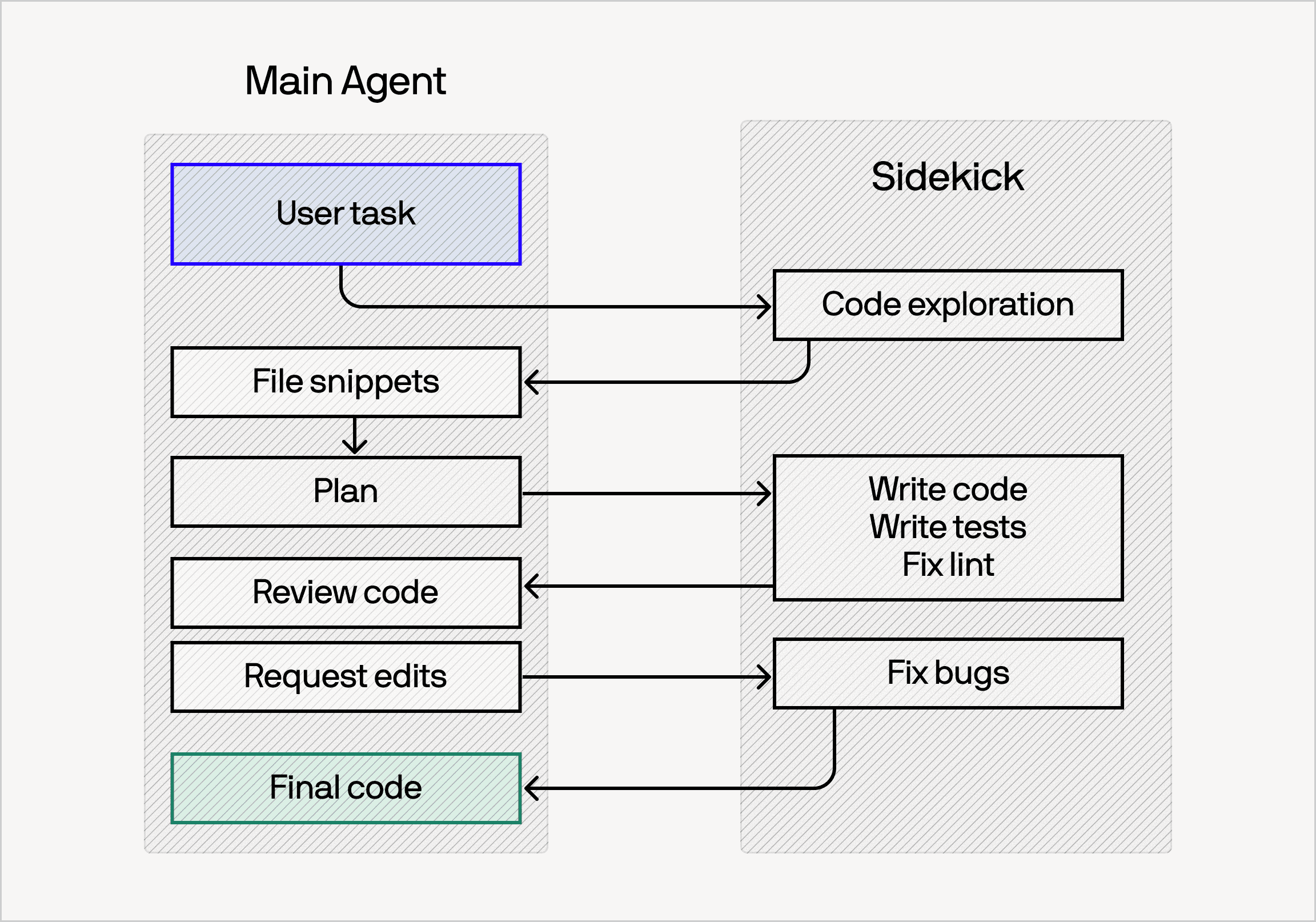 imageタスクが進行するにつれて、メインのエージェントはどのタスクをサイドキックに任せるか、どのタスクを自分自身で行うかを決定します。しかし、実務においてサイドキックを効果的に機能させるためには、相互作用のパターンを深く調整する必要があります。私たちは、メインエージェントは最小限のアクションにとどめ、絶対に必要な情報だけを参照すべきであることを発見しました。デフォルトでは、計画策定、曖昧さの解釈、最終レビューといった重要な決定を行いながら、タスクの委任と監視を行うべきです。
imageタスクが進行するにつれて、メインのエージェントはどのタスクをサイドキックに任せるか、どのタスクを自分自身で行うかを決定します。しかし、実務においてサイドキックを効果的に機能させるためには、相互作用のパターンを深く調整する必要があります。私たちは、メインエージェントは最小限のアクションにとどめ、絶対に必要な情報だけを参照すべきであることを発見しました。デフォルトでは、計画策定、曖昧さの解釈、最終レビューといった重要な決定を行いながら、タスクの委任と監視を行うべきです。
このアプローチにより、より基本的なモデルルーティングにおける主要な問題が解決されます:
- 「ベンチマークスコア」に基づく知能ではなく、実際の最前線の知能を保持します。ルーターは特定のベンチマークに過剰適合する傾向があります。混合された最前線モデルを維持することで、サイドキックアプローチは最前線モデルの創造性と一般知能からの恩恵を受け続けます。
- 単一のプロンプトタスクや質問応答を超えて汎化します。モデルルーターは多くの場合、タスク全体に対して単一のモデルにルーティングします。プロンプトにはタスクの難易度を適切に見極めるための十分な情報が含まれていないことが多く、さらにユーザーが単純な初期プロンプトに対して困難なフォローアップを行う可能性もあります。スマートモデルとサイドキックを動的に行き来できる能力により、このシステムははるかに堅牢になります。
- モデル間でルーティングする際の高コストなキャッシュミス(キャッシュミス)を回避します。私たちは以前「スマートフレンズ」というツールを検討し、Anthropic も同様の「アドバイザー」ツールをリリースしました。これらのアイデアの核心は、あるモデルに別のモデルから有益なアドバイスを問い合わせるためのツールを与えることにあります。しかし、課題があります。他のモデルへの呼び出しごとに、タスクのコンテキストがキャッシュされる形で共有されず、非常に高価なコストを支払うことになります。サイドキック設定では、メインモデルとサイドキックモデルの両方がそれぞれ独自の永続的かつキャッシュされたコンテキストを維持します。
もちろん、Devin Fusion の機能を達成するために克服する必要があった実装の詳細は数多くあります。例えば、ほとんどのキャッシュ入力には 5 分の有効期限しかありません。読者の方には、この課題をどのように工学的に回避するかについて考えていただければ幸いです。情報交換 を大歓迎します!
Sidekick scales better as models get smarter
最近のモデル、特に Fable 5 は、これらのマルチエージェント設定において非常に優れたパフォーマンスを発揮します。Fable はより知的に作業を委任し、文脈の要求をより効率的に行い、計画をより精密に実行するため、知能への影響を最小限に抑えながら、コスト面でより大きな改善をもたらします。これは、ベースモデルが向上するにつれて、サイドキックパターンがさらに有用になっていくことを示唆しています。
私たちのテストでは、Fable 5 を使用した Fusion は、純粋な Fable 5 ハーネスと比較して 41% 安価であり、Opus や GPT-5.5 レベルのモデルを使用した場合の 35% という結果よりも優れています。この差は一見地味に思えるかもしれませんが、実際には真の違いを過小評価していると考えられます。Fable を使用しない数値は、Devin Fusion ハーネスに対する多数の調整ラウンドを反映したものであり、Fable 5 の数値はそうではありません。なぜなら、調整を適用する前にアクセス権が切断されたためです。
Examples of Sidekick in Action
サイドキックがどのように機能するかをよりよく理解するために、FrontierCode タスクの代表的なサンプルにおいて、サイドキックの使用がコストとパフォーマンスにどのような影響を与えるかを調査しました。ここでは、サイドキック使用における良い例と悪い例の両方を提示します。
Dynamic Mid-Session Routing
サイドキックを武器に持つとしても、タスクに対して適切なモデルを選択する必要があります。メインエージェントとサイドキックには、タスクの種類や複雑度に応じて異なるモデルを選定します。しかし、開始時にモデルを選んでから後で別のモデルの方が適していることに気づくのは危険です。同様に、タスクが難しすぎることが判明した場合、サイドキックからメインエージェントへタスクを戻したいと考えることもあるでしょう。これらのケースに対応するため、タスク実行中に軽量な分類器を使用して、メインエージェントに切り替える必要がある場合や、全く別のモデルを使用する必要がある場合にシグナルを送ります。
モデル間の切り替え時にはキャッシュ効率を高めたいと考えており、そのためには巧妙なエンジニアリングが必要です。私たちはコンテキスト圧縮のタイミングでモデルを切り替えることでこれを達成します。これは本来キャッシュミスを引き起こすタイミングであり、各回の圧縮トリガー時に状況を評価して担当するモデルを切り替える機会と捉え、実質的に「無料」でモデルの切り替えを実現しています。つまり、追加のキャッシュペナルティなしにサイドキックモデルをメインモデルに戻ることなく「アップグレード」することも可能になります。
具体例として、Devin Fusion を使用した社内開発からのタスクを選びました。
Results
Fable 5* の利用可否あり・なしの両構成で新しいハネスをベンチマークし、どちらの構成においてもエキサイティングな改善が見られました。
Fable 5 を含まない場合、Devin Fusion のマルチモデルハッチは、GPT-5.5 や Opus 4.8 などのフロンティアモデルと比較して FrontierCode でコストを 35% 改善しつつも、フロンティアレベルのパフォーマンスを維持しています。
Fable 5 はこのマルチモデルハッチにおいて極めて高いパフォーマンスを示し、従来のエージェントハッチにおける Fable 5 と同等の性能を維持しながら、コストを 41% 削減しました。現在 Fable は一般利用可能なモデルではありませんが、アクセスが復元され次第、Devin Fusion のユーザーへ Fable を提供できることを楽しみにしています。
FrontierCode ExtendedScore vs Cost
$1$2$3$4$5$6$7avg cost (USD) per rollout4045505560ScoreFable 5*Fusion + Fable 5*Opus 4.8FusionGPT-5.5GLM 5.2
- 2026 年 6 月 12 日、米国政府の指令 (anthropic.com/news/fable-mythos-access) に従い、Fable 5 へのアクセスが停止されました。本ブログ投稿時点では、まだアクセスは復元されていません。Fable 5 を用いた結果は、この停止前の測定値および当時の内部バージョンの Devin Fusion に基づいて報告されています。
健全性チェック
私たちはベンチマークで高い性能を発揮するだけでなく、実際の使用感においても良好であるハッチを構築することを目指しました。Cognition 社内で一部のユーザーに Fusion を有効化しましたが、その結果、マージされた PR の 88% が完全に自動化された Fusion ルーターによって駆動されていることが判明しました。
もちろん、私たちの最終的な目標は、社内での利用範囲よりもはるかに広範なタセットに対してこのハネスをテストすることです。そのため、クラウドエージェントのユーザー向けにDevin Fusionのプレビュー版をリリースすることを大変嬉しく思っています。
ハイブリッドモデルハネスの重要性の高まり
すべての業務で1つのモデルを使用する時代は終わりを迎えています。 小規模から大規模なエンジニアリング組織において、最先端知能のコストは抑制不可能な水準に達し始めています。さらに現在、価格と知能レベルが異なる多様なモデルオプションが増加しており、適切なプロンプトを使用すれば、多くのサブフロンティアモデルはエンジニアリング作業の大部分を完全に遂行する能力を持っています。スーパーカーであるランボルギーニを近所のスーパーに運転して行くことはしないでしょう。それと同じで、ソフトウェアのゼロデイ脆弱性を発見できるようなモデルを、単にボタンを1つ押すために使うべきではありません。
さらに、マルチモデル・ハーネスを使用することで、さまざまな最先端モデルの相対的な強みを把握することが可能になります。例えば、Cognition では、一部のモデルが UI テストに特に優れており、別のモデルが PR 内の複雑なバグの特定に得意であることが分かっています。また、有能なオープンソースモデル のセットも増え続けています。これにより、特定のドメインに特化したインテリジェンスを訓練しやすくなります。そして、特定の言語、タスク、ライブラリで卓越したモデルが次々と登場する中で、マルチモデル機能への投資はますます重要になっていきます。
エージェントビルダーにとって、増大する多様なインテリジェントモデルを活用することが今後さらに重要になるため、私たちがここで使用する技術を共有します。私たちはまだ始まったばかりであり、Devin Fusion はこの旅路における多くのステップの一つに過ぎません。
実際のタスクで試していただき、どこで失敗するかをぜひ教えてください。app.devin.ai/signup でお試しください。また、私たちの仕事に興味を持っていただけた場合は、一緒に働いていただくこと をご検討ください!
原文を表示
Devin Fusion: Frontier Performance at 35% Lower Cost
By The Cognition Team06.30.26
Engineering teams are lighting money on fire.
It's no longer sustainable to use the most expensive models on every task. But existing tools for mixing models suck. They look nice on most benchmarks but fail to write code you'd actually merge.
At Cognition, we specialize in routing across frontier models without sacrificing intelligence. Today, we're sharing our work on a new kind of multi-model harness, Devin Fusion, that is substantially better at mixing models while reducing costs and maintaining intelligence on real-world usage. We found it maintains frontier and Fable 5-level performance at 35% lower cost on FrontierCode, a new state-of-the-art coding benchmark that measures both code correctness and quality.
In the rest of this post, we break down why good model routing is so hard, and the two techniques that make it all work: the "sidekick" approach and dynamic mid-session routing.
We welcome you to try Devin Fusion in preview at app.devin.ai/signup.
The Trick: Sidekick
The key idea behind our architecture is to run two parallel agents: one with a frontier model, the other with a more cost-effective "sidekick" model. Both are fully capable agents with their own toolsets and ability to gather & act on their own context.
As the task progresses, the main agent decides which tasks to give the sidekick and which tasks to do itself. Making sidekick work well in practice, however, requires deeply tuning the interaction patterns. We've found that the main agent should take minimal actions, and only read what is absolutely necessary. By default it should delegate and monitor, while making the significant decisions: the plan, the interpretation of ambiguity, the final review.
This approach fixes the primary problems with more basic model routing:
- It retains real frontier intelligence rather than "benchmark-score" intelligence. Routers often over-fit to specific benchmarks. By keeping a frontier model in the mix, the sidekick approach continues to benefit from frontier model creativity and general intelligence.
- It generalizes beyond single-prompt tasks and question-answering. Model routers often route to a single model for the entire task. Prompts often do not contain enough information about the task to properly discern difficulty. Moreover, the user might have difficult followups to simple initial prompts. Being able to move between the smart model and sidekick dynamically makes this system much more robust.
- It avoids costly cache misses when routing between models. We've previously explored a "Smart Friend" tool, and Anthropic released a similar "Advisor" tool. The core of both these ideas is to give one model a tool to query another model for helpful advice. The catch? Upon every call to the other model, the context for the task is not shared in a way that is cached, and you pay a very expensive price. In the sidekick setup, both the main model and sidekick model maintain their own persistent, cached contexts.
Of course, there are many implementation details we had to overcome to achieve the capabilities of Devin Fusion. For example, most cached inputs only have a 5-minute expiry. We encourage the reader to think about how to engineer around this. We'd love to trade notes!
Sidekick scales better as models get smarter
Recent models, and Fable 5 especially, perform unusually well in these multi-agent setups. Fable delegates work more intelligently, requests context more efficiently, and plans more precisely, all of which yield a larger cost improvement with minimal impact on intelligence. This suggests that the sidekick pattern is one that will become more useful as base models get better.
In our testing, Fusion with Fable 5 is 41% cheaper than a pure Fable 5 harness, versus 35% with Opus and GPT-5.5-level models. That gap may look modest, but we believe it understates the real difference. The non-Fable numbers reflect many rounds of tuning of the Devin Fusion harness; the Fable 5 numbers don't, since access was cut off before we could apply them.*
Examples of Sidekick in Action
To better understand how the sidekick works, we inspected how using sidekick impacts cost and performance on a representative sample of FrontierCode tasks. Here we present both good and bad examples of sidekick usage.
Dynamic Mid-Session Routing
With sidekick in your arsenal, you must still make sure to choose the right models for the task. We decide on different models for the main agent or sidekick depending on task type and complexity. It can be dangerous, however, to choose a model at the start and then realize later on that a different one would be better suited. Similarly, you might also want to move the task from the sidekick back to the main agent if it is proving too challenging. To handle these cases, we use lightweight classifiers during task execution to signal when we need to switch to the main agent or use a different model entirely.
We would like to be cache-efficient when switching between models, and doing so requires some artful engineering. We accomplish this by switching the model during context compaction, which would trigger a cache miss anyway. Each time we trigger compaction, we take it as an opportunity to evaluate the situation and switch the model that's in charge, effectively getting model switching “for free”. Note that this means we can even “upgrade” our sidekick model without going back to the main model, at no extra cache penalty.
To illustrate, we chose a task from our internal development that used Devin Fusion.
Results
We benchmarked our new harness with and without the ability to use Fable 5*, and found exciting improvements with both configurations.
Without including Fable 5, our Devin Fusion multi-model harness gives a 35% cost improvement on FrontierCode relative to frontier models like GPT-5.5 and Opus 4.8, while maintaining performance matching the frontier.
Fable 5 proved to be exceptionally performant in this multi-model harness, achieving a 41% cost reduction, while maintaining the same performance as Fable 5 in a traditional agent harness. While Fable is currently not a generally available model, we are excited to extend Fable to users of Devin Fusion once access is restored.
The Sanity Check
We set out to build a harness that not only performs well on benchmarks, but actually feels good in real use. We enabled Fusion for a set of users internally at Cognition, and we found that 88% of their merged PRs were driven entirely by the automated Fusion router.
Of course, our end desire is to test this harness on a much wider set of tasks than what our internal usage covers. That's why we're very excited to release a preview of Devin Fusion to users in our cloud agent.
The rising importance of hybrid-model harnesses
The age of using one model for all of your work is coming to an end. The rising costs of frontier intelligence are reaching prohibitive levels in engineering organizations small and large. Moreover, there is now a growing range of model options at different price and intelligence levels, and with the right prompting, many of the sub-frontier models are fully capable of doing most engineering work. You wouldn't drive a Lamborghini to the grocery store, so why should you take a model that can discover zero-day vulnerabilities in software and use it to round the corner of a button?
Moreover, using a multi-model harness allows you to capture the relative strengths of various frontier models. For example, at Cognition, we find some models to be particularly good at UI testing, and different models to be good at identifying complicated bugs in PRs. There is also a growing set of capable open-source models. This makes it easier to train specialized intelligence on specific domains. And as models emerge that excel at particular languages, tasks, or libraries, investing in multi-model capabilities only becomes more important.
We share the techniques we use here, because it will only become more important for agent builders to harness the growing diversity of intelligent models. We're just getting started, and Devin Fusion is just one of many steps on this journey.
We'd love for you to put it to work on real tasks and tell us where it breaks. Try it at app.devin.ai/signup, and if you find our work interesting, consider working with us!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み