共有辞書:エージェント駆動ウェブに対応する圧縮技術
CloudflareはAIエージェントによるWebアクセスの急増と頻繁なデプロイに伴うキャッシュ破綻問題を解決するため、クライアントとサーバー間で共有する圧縮辞書(Shared Dictionaries)のベータ版を2026年4月に公開する予定である。
キーポイント
AIエージェント時代におけるWeb負荷の急増とキャッシュ破綻
エージェントによる高頻度スキャンとAI支援開発によるデプロイ頻度の増加により、従来の静的キャッシュと圧縮技術では冗長なデータ転送が発生し、パフォーマンスが低下している。
Shared Dictionariesによる差分圧縮の仕組み
サーバーとクライアントが共有する辞書を活用し、既存のキャッシュ状態を認識して変更部分(diff)のみを送信することで、転送量とCPU/バンド幅の消費を大幅に削減する。
Cloudflareの技術導入とベータ公開予定
早期テストで転送効率の向上を確認済みであり、2026年4月30日より一般向けベータ提供を開始し、エージェント時代のパフォーマンス最適化を推進する。
共有辞書のコア概念
サーバーとクライアントが事前にキャッシュしたリソースを共有辞書として利用し、変更差分のみを送信することでクライアント側で完全なレスポンスを再構築する仕組み。
従来の圧縮アルゴリズムとの違い
BrotliやZstandardは組み込み・カスタム辞書を持つが、共有辞書ではクライアントの既存キャッシュそのものを動的な辞書として活用し、頻繁なデプロイ時の帯域節約を実現する。
デルタ圧縮のプロトコル
`Use-As-Dictionary`と`Available-Dictionary`のHTTPヘッダーを用いてサーバーとブラウザが辞書の保持・提供を協調し、別ファイルなしで差分圧縮を行う。
自動辞書生成(Phase 3)
顧客の手動設定不要で、ネットワーク全体のトラフィックパターンを監視しバージョン管理されたリソースを自動検出・辞書化することで、運用負荷をゼロにしている。
影響分析・編集コメントを表示
影響分析
AIエージェントがWebをスキャン・構築する「Agentic Web」時代において、従来の静的なキャッシュと圧縮技術は頻繁なデプロイに対応できなくなりつつある。CloudflareのShared Dictionaries導入は、バンド幅とCPUコストを削減しつつ、エージェントによる高頻度アクセスに耐えうるインフラ基盤の標準規格を確立するものと考えられる。これにより、AI駆動型Web開発のパフォーマンス最適化とスケーラビリティが一段階進化すると予想される。
編集コメント
エージェント時代におけるWebインフラの「キャッシュ破綻」を解消する実用的な圧縮技術であり、2026年の本格展開が業界の転送コスト標準に与える影響は大きい。
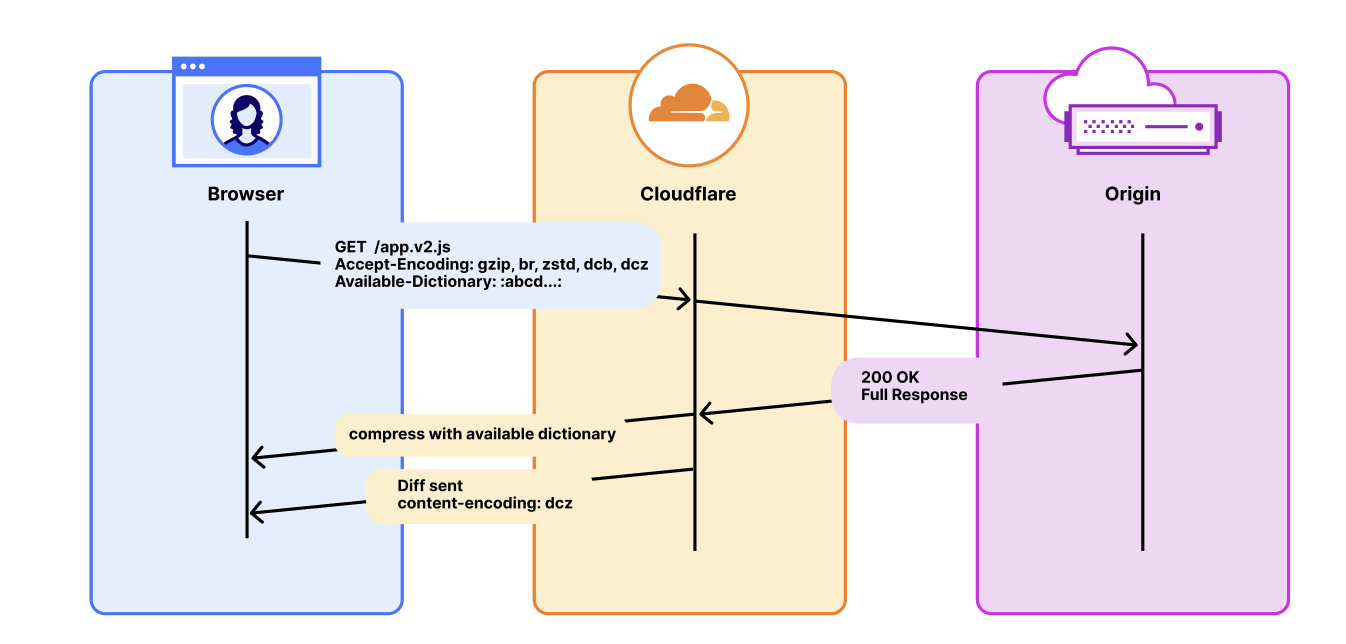
フェーズ1: パススルーサポートは現在、積極的に開発中です。Cloudflareは、Use-As-Dictionary、Available-Dictionary、dcbおよびdczコンテンツエンコーディングなど、共有辞書に必要なヘッダーとエンコーディングを、除去、変更、または再圧縮することなく転送します。キャッシュキーはAvailable-DictionaryとAccept-Encodingに基づいて拡張され、辞書圧縮されたレスポンスが正しくキャッシュされるようになります。このフェーズは、オリジン側で独自に辞書を管理するお客様に対応します。

フェーズ1のオープンベータは、2026年4月30日までに開始する予定です。これを使用するには、機能が有効化されたCloudflareゾーンにいること、正しいヘッダー(Use-As-Dictionary、Content-Encoding: dcbまたはdcz)で辞書圧縮されたレスポンスを提供するオリジンを持つこと、および訪問者がAccept-Encodingでdcb/dczを通知し、Available-Dictionaryを送信するブラウザを使用している必要があります。現時点では、これはChrome 130+およびEdge 130+を意味し、Firefoxのサポートは進行中です。
利用開始時期と使用方法に関する詳細なドキュメントについては、変更履歴にご注目ください。
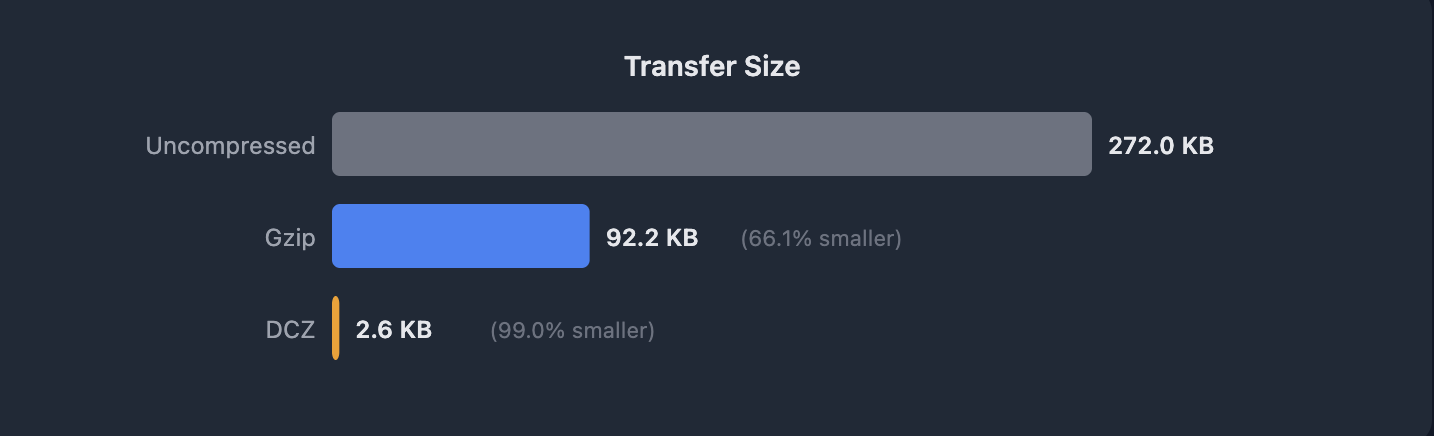
私たちはすでに内部でパススルーのテストを開始しています。管理されたテスト環境では、同一のウェブアプリケーションの連続したデプロイを模倣し、バージョン間で一部のローカライズされた変更のみが加えられた、2つのJSバンドルを順番にデプロイしました。非圧縮状態では、アセットは272KBでした。Gzipはこれを92.1KBに縮小し、66%の削減となりました。共有辞書圧縮(DCZ)を使用し、前のバージョンを辞書として用いると、同じアセットは2.6KBにまで減少しました。これは、すでに圧縮されたアセットからさらに97%削減したことになります。
同じラボテストで、クライアント側の2つのタイミング指標、すなわちタイム・トゥ・ファースト・バイト(TTFB)とダウンロード完了までの時間を測定しました。TTFBの結果は、示されていない点で興味深いものです。キャッシュミス(DCZがオリジンに対して辞書を用いた圧縮を行う必要がある場合)では、TTFBはgzipと比べてわずか約20ms遅いだけでした。転送におけるオーバーヘッドはほぼ無視できます。
違いが明確に現れるのはダウンロード時間です。キャッシュミス時、DCZは31msで完了したのに対し、gzipは166msでした(81%の改善)。キャッシュヒット時では、16ms対143ms(89%の改善)でした。レスポンスが非常に小さいため、開始時にわずかなペナルティがあっても、全体としてははるかに早く終了します。
これは最小限のJSバンドルの差分をシミュレートした初期のラボ結果であり、結果は辞書とアセット間の実際の差分によって異なります。

フェーズ2: ここでCloudflareはお客様に代わって作業を開始します。このフェーズでは、オリジン側で辞書ヘッダー、圧縮、フォールバックロジックを処理する代わりに、ルールを介してどのアセットを辞書として使用するかをCloudflareに指示し、残りは当社が管理します。当社はUse-As-Dictionaryヘッダーを挿入し、辞書のバイト列を保存し、古いバージョンに対して新しいバージョンを差分圧縮(デルタ圧縮)し、各クライアントに適切なバリアントを提供します。お客様のオリジンは通常のレスポンスを提供するだけで済みます。辞書に関する複雑さは、お客様のインフラストラクチャから当社のものに移行します。

これを実証するため、実際の動作を示すライブデモを構築しました。こちらでお試しください: Can I Compress (with Dictionaries)?
このデモは、典型的な本番環境のシングルページアプリケーションバンドルを模倣するため、毎分新しい約94KBのJavaScriptバンドルをデプロイします。コードの大部分はデプロイ間で静的です。毎回変更されるのは小さな設定ブロックのみであり、これは、バンドルの大部分が変更されないフレームワークやライブラリコードである実際のデプロイを反映しています。最初のバージョンが読み込まれると、Cloudflareのエッジはそれを辞書として保存します。次のデプロイが到着すると、ブラウザは既に保持しているバージョンのハッシュを送信し、エッジは新しいバンドルをそれに対して差分圧縮します。結果: 94KBが約159バイトに圧縮されます。これはgzipと比べて99.5%の削減です。なぜなら、ネットワーク上を転送されるのは実際の差分のみだからです。
デモサイトには解説も含まれており、curlまたはご使用のブラウザで圧縮率を直接確認できます。
フェーズ3: ウェブサイトに代わって辞書が自動生成されます。お客様が辞書として使用するアセットを指定する代わりに、Cloudflareが自動的に識別します。当社のネットワークは、数百万のサイト、数十億のリクエスト、そしてすべての新しいデプロイを含む、通過するすべてのリソースのすべてのバージョンをすでに監視しています。考え方はこうです。ネットワークが、連続したレスポンスがコンテンツの大部分を共有するがハッシュによって異なるURLパターンを観察したとき、そのリソースはバージョン管理されており、差分圧縮の候補であるという強いシグナルを得ます。前のバージョンを辞書として保存し、後続のバージョンをそれに対して圧縮します。お客様側の設定は不要です。メンテナンスも不要です。
これは単純なアイデアですが、実現は非常に困難です。プライベートデータの漏洩を防ぎつつ安全に辞書を生成すること、そして辞書が最も効果を発揮するトラフィックを特定することは、実際のエンジニアリング上の課題です。しかし、Cloudflareには適切な要素が揃っています。ネットワーク全体のトラフィックパターンを可視化でき、辞書が存在すべきキャッシュレイヤーをすでに管理しており、クライアントからのRUMビーコンは、辞書を提供する前に実際に圧縮が改善されることを確認する検証ループを提供するのに役立ちます。トラフィックの可視性、エッジストレージ、合成テストの組み合わせが自動生成を可能にしますが、まだ多くの要素を解明する必要があります。
フェーズ3のパフォーマンスと帯域幅のメリットは、私たちの動機の中核です。これにより、カスタム辞書を手動で実装するエンジニアリングリソースを持たない数百万のゾーンを含む、Cloudflareを利用するすべての方々が共有辞書を利用できるようになります。
全体像
ウェブの歴史の大部分において、圧縮はステートレスでした。すべてのレスポンスは、クライアントが以前に何も見たことがないかのように圧縮されました。共有辞書はこれを変えます。圧縮に記憶を持たせるのです。
これは5年前よりも今、より重要です。エージェント的なコーディングツールはデプロイ間隔を短縮すると同時に、それらを消費するトラフィックの割合も増加させています。現在、AIツールは大規模な差分を生成できますが、エージェントはより多くのコンテキストを獲得し、コード変更において外科的になっています。これに、より頻繁なリリースとより自動化されたクライアントが組み合わさり、すべてのリクエストでより多くの冗長なバイトが生じます。差分圧縮は、転送ごとのバイト数と、そもそも発生する必要がある転送回数の両方を減らすことで、この問題の両側面を解決します。
共有辞書の標準化には数十年を要しました。Cloudflareは、人間であれそうでなかれ、あなたのサイトにアクセスするすべてのクライアントが機能するインフラストラクチャを構築するお手伝いをしています。フェーズ1のベータは4月30日に開始します。皆様がお試しになるのを楽しみにしています。
_____
1ボット = 全HTTPリクエストの約31.3%。AI = 全ボットトラフィックの約29-30%(2026年3月)。
原文を表示
Web pages have grown 6-9% heavier every year for the past decade, spurred by the web becoming more framework-driven, interactive, and media-rich. Nothing about that trajectory is changing. What is changing is how often those pages get rebuilt and how many clients request them. Both are skyrocketing because of agents.
Shared dictionaries shrink asset transfers from servers to browsers so pages load faster with less bloat on the wire, especially for returning users or visitors on a slow connection. Instead of re-downloading entire JavaScript bundles after every deploy, the browser tells the server what it already has cached, and the server only sends the file diffs.
Today, we’re excited to give you a sneak peek of our support for shared compression dictionaries, show you what we’ve seen in early testing, and reveal when you’ll be able to try the beta yourself (hint: it’s April 30, 2026!).
The problem: more shipping = less caching
Agentic crawlers, browsers, and other tools hit endpoints repeatedly, fetching full pages, often to extract a fragment of information. Agentic actors represented just under 10% of total requests across Cloudflare's network during March 2026, up ~60% year-over-year.
Every page shipped is heavier than last year and read more often by machines than ever before. But agents aren’t just consuming the web, they’re helping to build it. AI-assisted development means teams ship faster. Increasing the frequency of deploys, experiments, and iterations is great for product velocity, but terrible for caching.
As agents push a one-line fix, the bundler re-chunks, filenames change, and every user on earth could re-download the entire application. Not because the code is meaningfully any different, but because the browser/client has no way to know specifically what changed. It sees a new URL and starts from zero. Traditional compression helps with the size of each download, but it can't help with the redundancy. It doesn't know the client already has 95% of the file cached. So every deploy, across every user, across every bot, sends redundant bytes again and again. Ship ten small changes a day, and you've effectively opted out of caching. This wastes bandwidth and CPU in a web where hardware is quickly becoming the bottleneck.
In order to scale with more requests hitting heavier pages that are re-deployed more often, compression has to get smarter.
What are shared dictionaries?
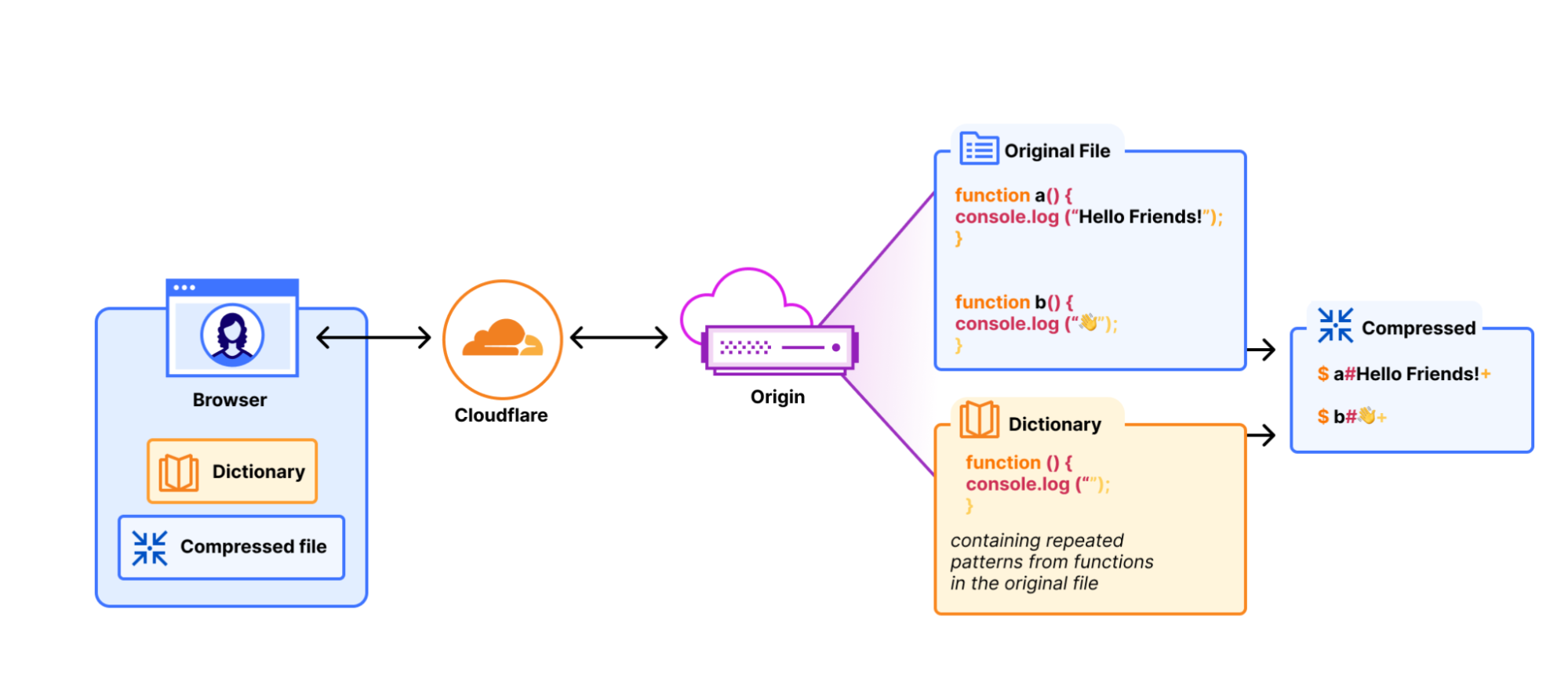
A compression dictionary is a shared reference between server and client that works like a cheat sheet. Instead of compressing a response from scratch, the server says "you already know this part of the file because you’ve cached it before" and only sends what's new. The client holds the same reference and uses it to reconstruct the full response during decompression. The more the dictionary can reference content in the file, the smaller the compressed output that is transferred to the client.
 image
image
This principle of compressing against what's already known is how modern compression algorithms pull ahead of their predecessors. Brotli ships with a built-in dictionary of common web patterns like HTML attributes and common phrases; Zstandard is purpose-built for custom dictionaries: you can feed it representative content samples, and it generates an optimized dictionary for the kind of content you serve. Gzip has neither; it must build dictionaries by finding patterns in real-time as it’s compressing. These “traditional compression” algorithms are already available on Cloudflare today.
Shared dictionaries take this principle a step further: the previously cached version of the resource becomes the dictionary. Remember the deploy problem where a team ships a one-line fix and every user re-downloads the full bundle? With shared dictionaries, the browser already has the old version cached. The server compresses against it, sending only the diff. That 500KB bundle with a one-line change becomes only a few kilobytes on the wire. At 100K daily users and 10 deploys a day, that's the difference between 500GB of transfer and a few hundred megabytes.
Delta compression
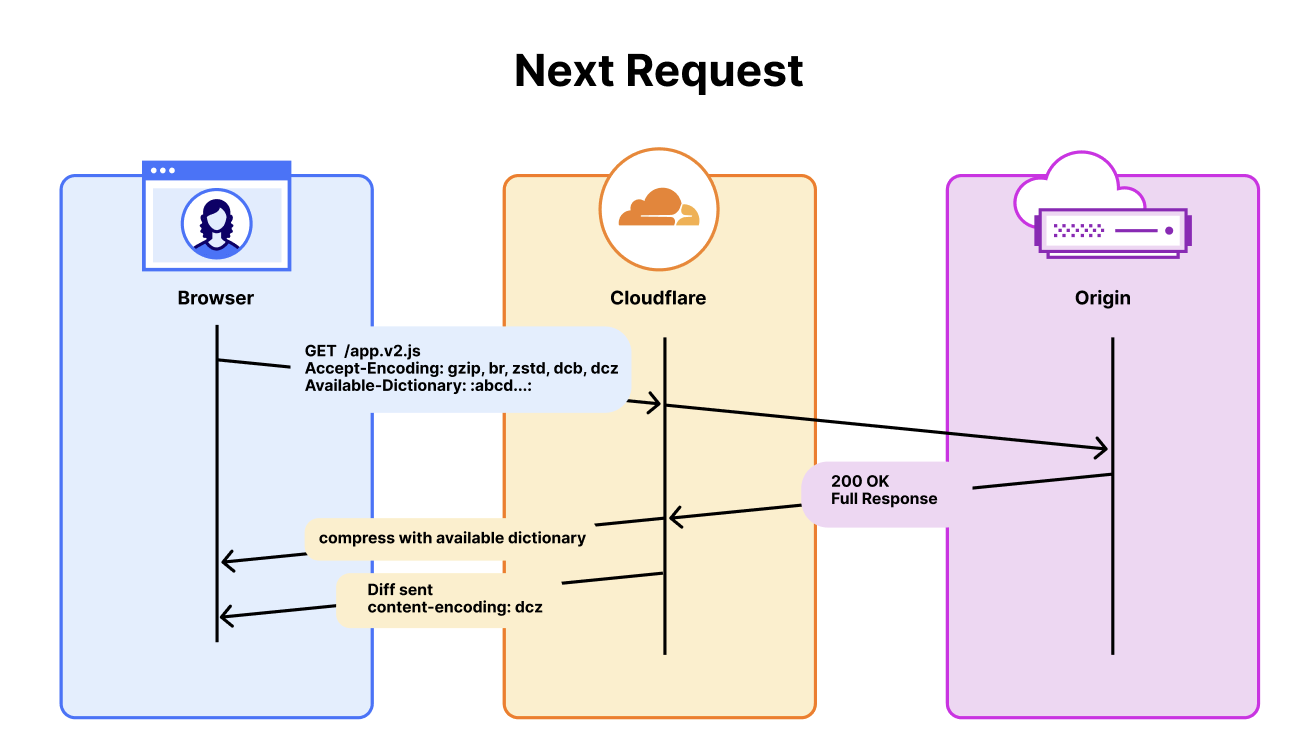
Delta compression is what turns the version the browser already has into the dictionary. The protocol looks to when the server first serves a resource, it attaches a Use-As-Dictionary response header, telling the browser to essentially hold onto the file because it’ll be useful later. On the next request for that resource, the browser sends an Available-Dictionary header back, telling the server, "here's what I've got." The server then proceeds to compress the new version against the old one and sends only the diff. No separate dictionary file needed.
 image
image
This is where the payoff lands for real applications. Versioned JS bundles, CSS files, framework updates, and anything that changes incrementally between releases. The browser has app.bundle.v1.js cached already and the developer makes an update and deploys app.bundle.v2.js. Delta compression only sends the diff between these versions. Every subsequent version after is also just a diff. Version three compresses against version two. Version 47 compresses against version 46. The savings don't reset, they persist across the entire release history.
There's also active discussion in the community about custom and dynamic dictionaries for non-static content. That's future work, but the implications are significant. We'll save that for another post.
So why the wait?
If shared dictionaries are so powerful, why doesn't everyone use them already?
Because the last time they were tried, the implementation couldn't survive contact with the open web.
Google shipped Shared Dictionary Compression for HTTP (SDCH) in Chrome in 2008. It worked well with some early adopters reporting double-digit improvements in page load times. But SDCH accumulated problems faster than anyone was able to fix them.
The most memorable was a class of compression side-channel attacks (CRIME, BREACH). Researchers showed that if an attacker could inject content alongside something sensitive that gets compressed (like a session cookie, token, etc.) the size of the compressed output could leak information about the secret. The attacker could guess a byte at a time, watch whether the asset size shrank, and repeat until they extracted the whole secret.
But security wasn't the only problem, or even the main reason why adoption didn’t happen. SDCH surfaced a few architectural problems like violating the Same-Origin Policy (which ironically is partially why it performed so well). Its cross-origin dictionary model couldn't be reconciled with CORS, and it lacked some specification regarding interactions with things like the Cache API. After a while it became clear that adoption wasn’t ready, so in 2017 Chrome (the only browser supporting at the time) unshipped it.
Getting the web community to pick up the baton took a decade, but it was worth it.
The modern standard, RFC 9842: Compression Dictionary Transport, closes key design gaps that made SDCH untenable. For example, it enforces that an advertised dictionary is only usable on responses from the same-origin, preventing many conditions that made side-channel compression attacks possible.
Chrome and Edge have shipped support with Firefox working to follow. The standard is moving toward broad adoption, but complete cross-browser support is still catching up.
The RFC mitigates the security problems but dictionary transport has always been complex to implement. An origin may have to generate dictionaries, serve them with the right headers, check every request for an Available-Dictionary match, delta-compress the response on the fly, and fall back gracefully when a client doesn't have a dictionary. Caching gets complex too. Responses vary on both encoding and dictionary hash, so every dictionary version creates a separate cache variant. Mid-deploy, you have clients with the old dictionary, clients with the new one, and clients with none. Your cache is storing separate copies for each. Hit rates drop, storage climbs, and the dictionaries themselves have to stay fresh under normal HTTP caching rules.
This complexity is a coordination problem. And exactly the kind of thing that belongs at the edge. A CDN already sits in front of every request, already manages compression, and already handles cache variants (watch this space for a soon-to-come announcement blog).
How Cloudflare is building shared dictionary support
Shared dictionary compression touches every layer of the stack between the browser and the origin. We've seen strong customer interest: some people have already built their own implementations like RFC author Patrick Meenan's dictionary-worker, which runs the full dictionary lifecycle inside a Cloudflare Worker using WASM-compiled Zstandard (as an example). We want to make this accessible to everyone and as easy as possible to implement. So we’re rolling it out across the platform in three phases, starting with the plumbing.
Phase 1: Passthrough support is currently in active development. Cloudflare forwards the headers and encodings that shared dictionaries require like Use-As-Dictionary, Available-Dictionary, and the dcb and dcz content encodings, without stripping, modifying, or recompressing them. The Cache keys are extended to vary on Available-Dictionary and Accept-Encoding so dictionary-compressed responses are cached correctly. This phase serves customers who manage their own dictionaries at the origin.
image
We plan to have an open beta of Phase 1 ready by April 30, 2026. To use it, you'll need to be on a Cloudflare zone with the feature enabled, have an origin that serves dictionary-compressed responses with the correct headers (Use-As-Dictionary, Content-Encoding: dcb or dcz), and your visitors need to be on a browser that advertises dcb/dcz in Accept-Encoding and sends Available-Dictionary. Today, that means Chrome 130+ and Edge 130+, with Firefox support in progress.
Keep your eyes fixed on the changelog for when this becomes available and more documentation for how to use it.
We’ve already started testing passthrough internally. In a controlled test, we deployed two js bundles in sequence. They were nearly identical except for a few localized changes between the versions representing successive deploys of the same web application. Uncompressed, the asset is 272KB. Gzip brought that down to 92.1KB, a solid 66% reduction. With shared dictionary compression over DCZ, using the previous version as the dictionary, that same asset dropped to 2.6KB. That's a 97% reduction over the already compressed asset.
image
In the same lab test, we measured two timing milestones from the client: time to first byte (TTFB) and full download completion. The TTFB results are interesting for what they don't show. On a cache miss (where DCZ has to compress against the dictionary at the origin) TTFB is only about 20ms slower than gzip. The overhead is near-negligible for transmission.
The download times are where the difference is. On a cache miss, DCZ completed in 31ms versus 166ms for gzip (an 81% improvement). On a cache hit, 16ms versus 143ms (89% improvement). The response is so much smaller that even when you pay a slight penalty at the start, you finish far ahead.
Initial lab results simulating minimal JS bundle diffs, results will vary based on the actual delta between the dictionary and the asset.
image
Phase 2: This is where Cloudflare starts doing the work for you. Instead of handling dictionary headers, compression, and fallback logic on the origin, in this phase you tell Cloudflare which assets should be used as dictionaries via a rule and we manage the rest for you. We inject the Use-As-Dictionary headers, store the dictionary bytes, delta-compress new versions against old ones, and serve the right variant to each client. Your origin serves normal responses. Any dictionary complexity moves off your infrastructure and onto ours.
image
image
To demonstrate this, we've built a live demo to show what this looks like in practice. Try it here: Can I Compress (with Dictionaries)?
The demo deploys a new ~94KB JavaScript bundle every minute, meant to mimic a typical production single page application bundle. The bulk of the code is static between deploys; only a small configuration block changes each time, which also mirrors real-world deploys where most of the bundle is unchanged framework and library code. When the first version loads, Cloudflare's edge stores it as a dictionary. When the next deploy arrives, the browser sends the hash of the version it already has, and the edge delta-compresses the new bundle against it. The result: 94KB compresses to roughly 159 bytes. That's a 99.5% reduction over gzip, because the only thing on the wire is the actual diff.
The demo site includes walkthroughs so you can verify the compression ratios on your own via curl or your browser.
Phase 3: The dictionary is automatically generated on behalf of the website. Instead of customers specifying which assets to use as dictionaries, Cloudflare identifies them automatically. Our network already sees every version of every resource that flows through it, which includes millions of sites, billions of requests, and every new deploy. The idea is that when the network observes a URL pattern where successive responses share most of their content but differ by hash, it has a strong signal that the resource is versioned and a candidate for delta compression. It stores the previous version as a dictionary and compresses subsequent versions against it. No customer configuration. No maintenance.
This is a simple idea, but is genuinely hard. Safely generating dictionaries that avoid revealing private data and identifying traffic for which dictionaries will offer the most benefit are real engineering problems. But Cloudflare has the right pieces: we see the traffic patterns across the entire network, we already manage the cache layer where dictionaries need to live, and our RUM beacon to clients can help give us a validation loop to confirm that a dictionary actually improves compression before we commit to serving it. The combination of traffic visibility, edge storage, and synthetic testing is what makes automatic generation feasible, though there are still many pieces to figure out.
The performance and bandwidth benefits of phase 3 are the crux of our motivation. This is what makes shared dictionaries accessible to everyone using Cloudflare, including the millions of zones that would never have had the engineering time to implement custom dictionaries manually.
The bigger picture
For most of the web's history, compression was stateless. Every response was compressed as if the client had never seen anything before. Shared dictionaries change that: they give compression a memory.
That matters more now than it would have five years ago. Agentic coding tools are compressing the interval between deploys, while also driving a growing share of the traffic that consumes them. While today AI tools can produce massive diffs, agents are gaining more context and becoming surgical in their code changes. This, coupled with more frequent releases and more automated clients means more redundant bytes on every request. Delta compression helps both sides of that equation by reducing the number of bytes per transfer, and the number of transfers that need to happen at all.
Shared Dictionaries took decades to standardize. Cloudflare is helping to build the infrastructure to make it work for every client that touches your site, human or not. Phase 1 beta opens April 30, and we’re excited for you to try it.
_____
1Bots = ~31.3% of all HTTP requests. AI = ~29-30% of all Bot traffic (March 2026).
関連記事
Vite 開発元 VoidZero が Cloudflare に参画
Vite や Vitest を開発する企業「VoidZero」がクラウドプロバイダー「Cloudflare」に合流し、同社全従業員も Cloudflare の一員となる。ただし、主要プロジェクトは引き続きオープンソースとして運営される方針を示した。
BGP AS_PATH の最初の AS を強制する仕組みの導入
Cloudflare は、Spamhaus が報告したルート乗っ取り事案を踏まえ、不正なアクターが未使用の自律システム番号(ASN)を利用して偽の AS_PATH を作成しトラフィックを誤誘導する手口に対処するため、BGP の経路情報において最初の AS 番号の検証を強化する措置を発表した。
Cloudflare のデータプラットフォームと AI エージェントの構築方法
Cloudflare は、毎秒数十億件のイベントを処理する膨大なデータを統合し、アクセスしやすくした上で、その上に AI エージェントを構築した手法について解説している。