生の相互作用から再利用可能な知識へ:AIエージェントのメモリ再考
Microsoft Researchは、AIエージェントの生の対話履歴を構造化された再利用可能な知識に変換するプラグイン型メモリモジュール「PlugMem」を発表し、従来のテキスト検索ベースのメモリシステムの課題を解決する新たなアプローチを提案した。
キーポイント
従来のAIエージェントメモリの課題
長い対話履歴を蓄積するが、再利用が困難で、検索時に大量の低価値なコンテキストに埋もれてしまう問題がある。
PlugMemの革新的アプローチ
生の対話履歴を命題的知識(事実)と処方的知識(再利用可能なスキル)に変換し、構造化された知識単位として保存する。
3つのコアコンポーネント
構造化(知識グラフ)、検索(タスクに合わせた知識単位の検索)、更新(継続的な学習と最適化)の3要素で構成される。
実証された性能向上
多様なエージェントベンチマークで性能を向上させながら、使用するメモリトークン数を削減できることを実証した。
認知科学に基づく設計思想
出来事の記憶、事実の知識、タスク実行方法の知識を区別する認知科学的枠組みをAIエージェントのメモリ設計に適用した。
汎用メモリの優位性
PlugMemは特定のタスクに特化せず、構造化された知識グラフを通じて適切な情報を適切なタイミングで提供することで、タスク特化型メモリよりも優れた性能を発揮する。
効率的なメモリ評価指標
コンテキスト消費量に対する有用な意思決定関連情報の比率を測定する指標を導入し、PlugMemがより少ないコンテキストでより多くの関連情報を提供することを実証した。
影響分析・編集コメントを表示
影響分析
この研究は、AIエージェントの実用化における根本的な課題であるメモリ管理に新たな解決策を提供し、より効率的で実用的な自律エージェントの開発を加速させる可能性がある。特に、構造化知識への変換というアプローチは、単なる技術的改善ではなく、AIシステムの設計思想そのものに影響を与える重要な進展と言える。
編集コメント
Microsoft Researchが発表したこの研究は、AIエージェント開発の実務的な課題に真正面から取り組んだもので、理論的枠組みと実証結果の両方を備えた説得力のある内容となっている。

概要
今日のAIエージェントは長い対話履歴を保存しますが、それを効果的に再利用することは困難です。
生のメモリ検索は、冗長で価値の低いコンテキストによってエージェントの処理能力を圧迫する可能性があります。
PlugMemは対話履歴を構造化された再利用可能な知識へと変換します。
単一の汎用メモリモジュールが、より少ないメモリトークンを使用しながら、多様なエージェントベンチマーク全体で性能を向上させます。
直感に反するかもしれませんが、AIエージェントにメモリを増やすと、かえって効率が低下することがあります。対話ログが蓄積するにつれて、その容量は増大し、無関係なコンテンツで埋まり、利用が次第に困難になるからです。
メモリが多いほど、エージェントは現在のタスクに関連する情報を見つけるために、より大量の過去の対話を検索しなければなりません。構造化されていない記録は、有用な経験と無関係な詳細とが混在し、検索を遅くし、信頼性を低下させます。課題は、より多くの経験を保存することではなく、エージェントがその時点で重要な情報を迅速に特定できるように、それらを整理することです。
私たちの最近の論文「PlugMem: A Task-Agnostic Plugin Memory Module for LLM Agents」では、生のエージェント対話を再利用可能な知識へと変換するプラグアンドプレイ型のメモリシステムを提案します。PlugMemは、メモリを単に検索対象のテキストとして扱うのではなく、エージェントが行動する際の意思決定を支援するように設計された、構造化された知識へと履歴を整理します。
ここで認知科学は有用な枠組みを提供します。それは、出来事を「想起する」こと、事実を「知っている」こと、タスクの実行方法を「知っている」ことの区別を示しています。過去の出来事は文脈を提供しますが、効果的な意思決定は、それらの出来事から抽出された事実とスキルに依存します。
この区別が、AIエージェントのメモリ設計に対する私たちの考え方を転換させる動機となりました。PlugMemはこの転換を実現し、対話、文書、ウェブセッションなどのエージェントの対話履歴を、タスクを超えて再利用可能な、構造化されたコンパクトな知識単位へと変換します。
PlugMemの仕組み
PlugMemと従来のAIメモリシステムとの主な違いは、保存する対象です。従来のアプローチはテキストの断片や固有名詞(人物、場所、概念への参照)を保存します。PlugMemは、事実と再利用可能なスキルをメモリの基本的な構成要素として使用します。この設計により、冗長性が減少し、情報密度が高まり、検索精度が向上します。その仕組みは以下の3つのコアコンポーネントを中心に構築されています。
構造化。生の対話は標準化され、命題的知識(事実)と規範的知識(再利用可能なスキル)へと変換されます。これらの知識単位は構造化されたメモリグラフに整理され、再利用のために設計された形式で知識が保存されます。
検索。長文のテキストを検索するのではなく、PlugMemは現在のタスクに適合した知識単位を検索します。高レベルの概念と推論された意図はルーティング信号として機能し、当面の意思決定に最も関連性の高い情報を引き出します。
推論。検索された知識は、ベースエージェントに渡される前に、簡潔でタスク実行可能なガイダンスへと集約され、意思決定に関連する知識のみがエージェントのコンテキストウィンドウに入力されることを保証します。
図1は、これらのコンポーネントがどのように連携するかを示しています。
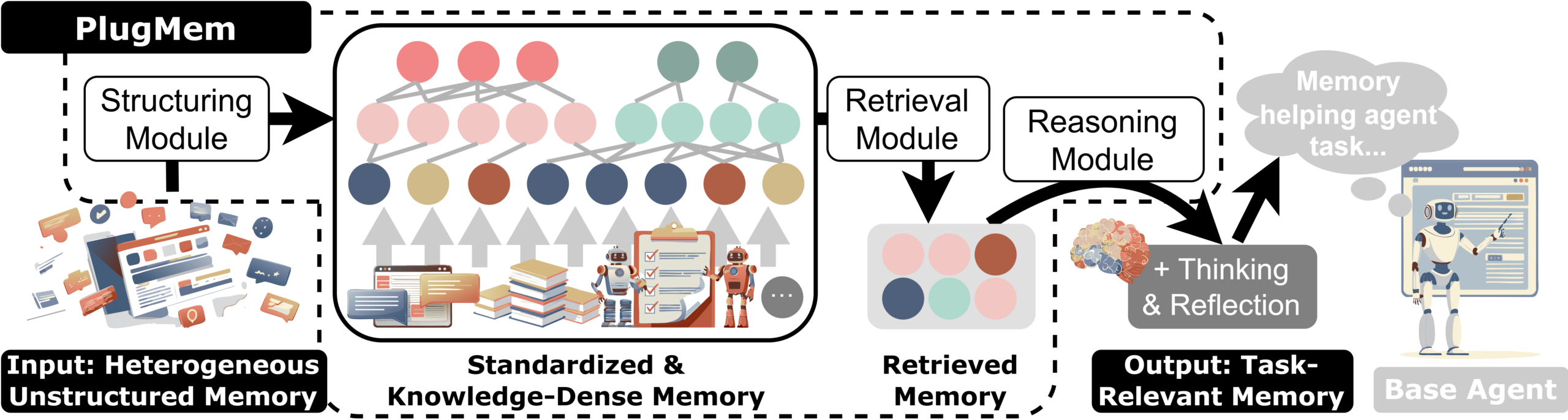 image図1. PlugMemは様々な種類のエージェント対話を知識中心のメモリグラフへと整理し、構造化検索と推論を可能にします。
image図1. PlugMemは様々な種類のエージェント対話を知識中心のメモリグラフへと整理し、構造化検索と推論を可能にします。
1つのメモリ、あらゆるタスク
ほとんどのAIメモリシステムは単一の用途のために構築されています。会話用メモリモジュールは対話を中心に設計され、知識検索システムは事実の参照に特化し、ウェブエージェントのメモリはページ遷移に最適化されています。それぞれは対象とする領域では優れた性能を発揮しますが、大幅な再設計なしに他の領域へ転用されることはほとんどありません。
PlugMemは異なるアプローチを取ります。これは、特定のタスク向けに変更を加える必要なく、あらゆるAIエージェントに接続可能な基礎的なメモリ層です。
PlugMemの評価
PlugMemを評価するため、私たちは同じメモリモジュールを、メモリに対して異なる要求を行う以下の3つのベンチマークでテストしました。
- 長いマルチターン会話にわたる質問応答
- 複数のWikipedia記事にまたがる事実の発見
- ウェブ閲覧を伴う意思決定
これら3つすべてにおいて、PlugMemは汎用的な検索手法とタスク固有に設計されたメモリの両方を一貫して上回り、その過程でAIエージェントが使用するメモリトークンの量を大幅に削減しました。
容量ではなく有用性でメモリを測定する
私たちは、モデルの容量が限られたコンテキストウィンドウを圧迫することなく、適切な情報が適切な瞬間にエージェントに届いているかどうかを評価したいと考えました。そのため、メモリモジュールが消費するコンテキスト量に対して、どれだけの有用で意思決定に関連する情報を提供するかを測定する指標を導入しました。
有用性をコンテキスト消費量に対してプロットすると、PlugMemは一貫して優れた結果を示しました。図2に示すように、他のアプローチと比べて、AIエージェントのコンテキストをより少なく消費しながら、より多くの意思決定関連情報を提供したのです。これらの結果は、生のログを保存・検索するのではなく、経験を知識へと変換することが、より有用で効率的なメモリを生み出すことを示唆しています。
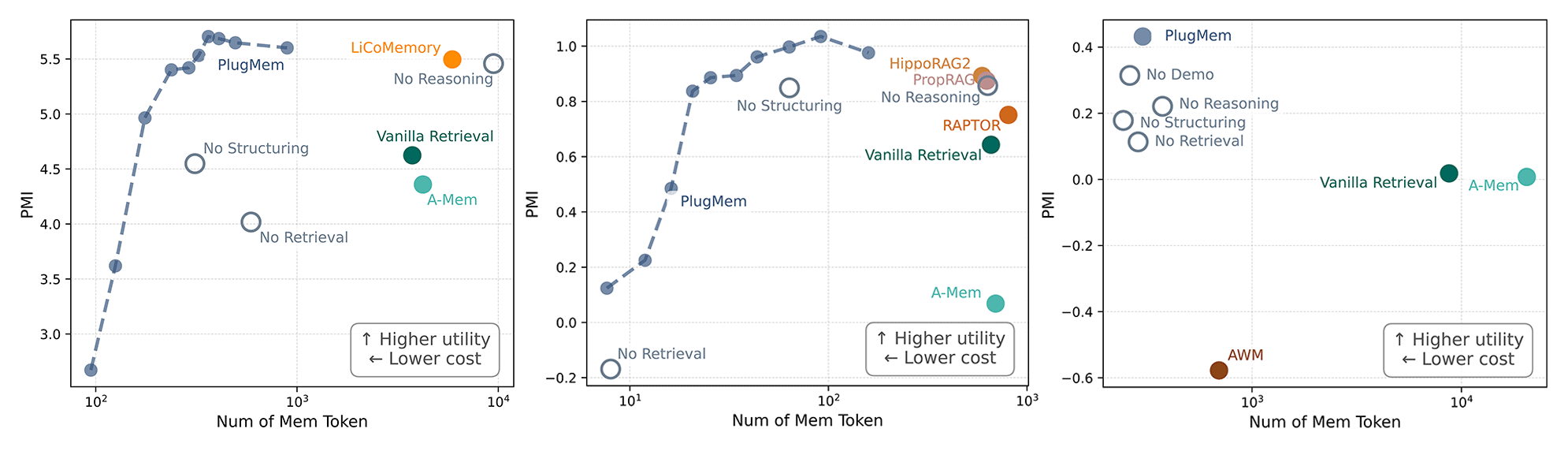 image図2. 3つのベンチマークすべてにおいて、PlugMemはエージェントのコンテキストウィンドウをより少なく消費しながら、より有用なメモリを提供しました。
image図2. 3つのベンチマークすべてにおいて、PlugMemはエージェントのコンテキストウィンドウをより少なく消費しながら、より有用なメモリを提供しました。
汎用メモリがタスク固有設計を上回る理由
汎用メモリモジュールが特定タスク向けシステムを上回り得るのは、決定的な要因が専門特化ではなく、エージェントが必要とする正確な瞬間に適切な知識を引き出せるかどうかだからです。構造化、検索、推論はそれぞれ異なる役割を果たし、単一のユースケースに最適化することよりも、これら3つすべてを適切に機能させることがより重要です。
PlugMemは、タスク固有のアプローチを置き換えることを意図したものではありません。それは、タスク適応を重ねていくための一般的なメモリ基盤を提供します。私たちの実験では、PlugMemとタスク固有の技術を組み合わせることで、さらなる性能向上が得られることが示されています。
エージェントのための再利用可能なメモリへ向けて
AIエージェントがより長く複雑なタスクを引き受けるにつれて、そのメモリは過去の対話を単に保存するものから、再利用可能な知識を積極的に供給するものへと進化する必要があります。目標は、エージェントが毎回ゼロから始めるのではなく、あるタスクから次のタスクへ有用な事実と戦略を持ち運べるようにすることです。
PlugMemはその方向への一歩を示しており、メモリ設計を認知原理に基づかせ、知識を再利用の主要な単位として扱います。エージェントの能力が拡大するにつれて、知識中心のメモリは、次世代の知的エージェントのための重要な構成要素となるかもしれません。
コードと実験結果はGitHubで公開されており、他の研究者が結果を再現し、独自の研究を行うことができます。
新しいタブで開く投稿「From raw interaction to reusable knowledge: Rethinking memory for AI agents」はMicrosoft Researchで最初に公開されました。
原文を表示
At a glance
Today’s AI agents store long interaction histories but struggle to reuse them effectively.
Raw memory retrieval can overwhelm agents with lengthy, low-value context.
PlugMem transforms interaction history into structured, reusable knowledge.
A single, general-purpose memory module improves performance across diverse agent benchmarks while using fewer memory tokens.
It seems counterintuitive: giving AI agents more memory can make them less effective. As interaction logs accumulate, they grow large, fill with irrelevant content, and become increasingly difficult to use.
More memory means that agents must search through larger volumes of past interactions to find information relevant to the current task. Without structure, these records mix useful experiences with irrelevant details, making retrieval slower and less reliable. The challenge is not storing more experiences, but organizing them so that agents can quickly identify what matters in the moment.
In our recent paper “PlugMem: A Task-Agnostic Plugin Memory Module for LLM Agents,” we introduce a plug-and-play memory system that transforms raw agent interactions into reusable knowledge. Rather than treating memory as text to retrieve, PlugMem organizes that history into structured knowledge designed to support decisions as the agent acts.
Cognitive science offers a useful framework here. It distinguishes between remembering events, knowing facts, and knowing how to perform tasks. Past events provide context, but effective decisions rely on the facts and skills extracted from those events.
This distinction motivated a shift in how we decided to design memory for AI agents. PlugMem implements this shift by converting the agent’s interaction history, such as dialogues, documents, and web sessions, into structured, compact knowledge units that can be reused across tasks.
How PlugMem works
A key difference between PlugMem and conventional AI memory systems is what gets stored. Traditional approaches store text chunks or named entities (references to people, places, and concepts). PlugMem uses facts and reusable skills as the fundamental building blocks of memory. This design reduces redundancy, increases information density, and improves retrieval precision. It’s built around three core components:
Structure. Raw interactions are standardized and transformed into propositional knowledge (facts) and prescriptive knowledge (reusable skills). These knowledge units are organized into a structured memory graph, enabling knowledge to be stored in a form designed for reuse.
Retrieval. Rather than retrieving long passages of text, PlugMem retrieves knowledge units that are aligned with the current task. High-level concepts and inferred intents serve as routing signals, surfacing the most relevant information for the decision at hand.
Reasoning. Retrieved knowledge is distilled into concise, task-ready guidance before being passed to the base agent, ensuring that only decision-relevant knowledge enters the agent’s context window.
Figure 1 illustrates how these components work together.
imageFigure 1. PlugMem organizes different types of agent interactions into a knowledge-centric memory graph, enabling structured retrieval and reasoning.
One memory, any task
Most AI memory systems are built for one job. A conversational memory module is designed around dialogue. A knowledge-retrieval system is tuned to look up facts. A web agent’s memory is optimized for navigating pages. Each performs well in its target setting but rarely transfers without significant redesign.
PlugMem takes a different approach. It is a foundational memory layer that can be attached to any AI agent without needing to modify it for a specific task.
Evaluating PlugMem
To test PlugMem, we evaluated the same memory module on three benchmarks that each make different demands on memory:
Answering questions across long multi-turn conversations
Finding facts that span multiple Wikipedia articles
Making decisions while browsing the web
Across all three, PlugMem consistently outperformed both generic retrieval methods and task-specific memory designs while allowing the AI agent to use significantly less memory token budget in the process.
Measuring memory by utility, not size
We wanted to evaluate whether the right information was reaching the agent at the right moment, without overwhelming the model’s context window, which has limited capacity. To do this, we introduced a metric that measures how much useful, decision-relevant information a memory module contributes relative to how much context it consumes.
When we plotted utility against context consumption, PlugMem consistently came out ahead: it delivered more decision-relevant information while consuming less of the AI agent’s context than other approaches, as shown in Figure 2. These results suggest that transforming experience into knowledge—rather than storing and retrieving raw logs—produces memory that is more useful and efficient.
imageFigure 2. Across all three benchmarks, PlugMem delivered more useful memory with less of the agent’s context window.
Why general-purpose memory can outperform task-specific designs
General-purpose memory modules can outperform systems tailored to specific tasks because the decisive factor is not specialization but whether memory can surface the right knowledge precisely when the agent needs it. Structure, retrieval, and reasoning each play a distinct role, and getting all three right matters more than optimizing for a single use case.
PlugMem is not meant to replace task-specific approaches. It provides a general memory foundation upon which task adaptations can be layered. Our experiments show that combining PlugMem with task-specific techniques yields further gains.
Toward reusable memory for agents
As AI agents take on longer and more complex tasks, its memory needs to evolve from storing past interactions to actively supplying reusable knowledge. The goal is for agents to carry useful facts and strategies from one task to the next rather than starting from scratch each time.
PlugMem represents a step in that direction, grounding memory design in cognitive principles and treating knowledge as the primary unit of reuse. As agent capabilities expand, knowledge-centric memory may prove to be a critical building block for the next generation of intelligent agents.
Code and experimental results are publicly available on GitHub (opens in new tab) so that others can reproduce the results and conduct their own research.
Opens in a new tabThe post From raw interaction to reusable knowledge: Rethinking memory for AI agents appeared first on Microsoft Research.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み