NVIDIA HORIZON:Git ワークツリーを自律的に進化させるハンズフリーエージェントが RTL ベンチマークで完全達成
NVIDIA Research は、Git を基盤とした自律型エージェント「HORIZON」を発表し、ハードウェア設計の RTL ベンチマークで 100% の完了率を達成した。
キーポイント
リポジトリレベルでの進化アプローチ
単発のコード生成ではなく、Git ワークツリー上でバージョン管理された設計を継続的に進化する「エージェントループ」を採用し、人間の介入なしに設計を改善する。
100% の RTL ベンチマーク達成
評価対象となったすべてのレジスタ転送レベル(RTL)ベンチマークスイートで 100% の完了率を記録し、実行可能なハードウェア設計の生成能力を実証した。
Git を活用した学習ループ
成功・失敗の履歴を Git コミットと差分として記録し、それを経験バッファとして利用することで、エージェントが自己改善する仕組みを構築している。
固定バックボーンと半マルコフ決定過程の用語使用
HORIZON は強化学習ポリシーを訓練・更新せず、バックボーンモデルはキャンペーン中固定であり、「状態」や「オプション」という用語は単に記録されたオブジェクトを名付けるためにのみ借用されています。
コスト削減のためのセッション再利用
反復処理全体で永続的なモデルセッションを保持し、ハッチングやプロジェクトパックをプロバイダーのプロンプトキャッシュから提供することで、課金トークンの大部分を現在の差分と評価器出力に限定しています。
100% のベンチマーク達成と進化の焦点
GPT-5.3 を固定バックボーンとして使用し、ChipBench や CVDP などの全テストスイートで最終的に 100% のパス率を達成しました。これはソフトウェアそのものではなく、エンジニアが作成するハードウェアアーティファクト(RTL ソースや検証成果物)を進化させる点で先行システムと異なります。
トークン効率の最適化
正答率が飽和した後の指標としてトークン消費量が重要視され、入力トークンの91%がキャッシュされることでAPIコストが大幅に削減されています。
影響分析・編集コメントを表示
影響分析
この研究は、AI エージェントが複雑なハードウェア設計タスクにおいて自律的に動作し、検証を繰り返して最終的な成果物を生成できる可能性を強く示唆しています。特に Git を学習の基盤として活用するアプローチは、他の分野への応用も期待され、エンジニアリングプロセスの変革につながる重要な進展です。
編集コメント
従来の「プロンプトでコードを生成する」アプローチから、Git を介して履歴を残しながら試行錯誤を繰り返す自律型エージェントへの転換点となる画期的な成果です。
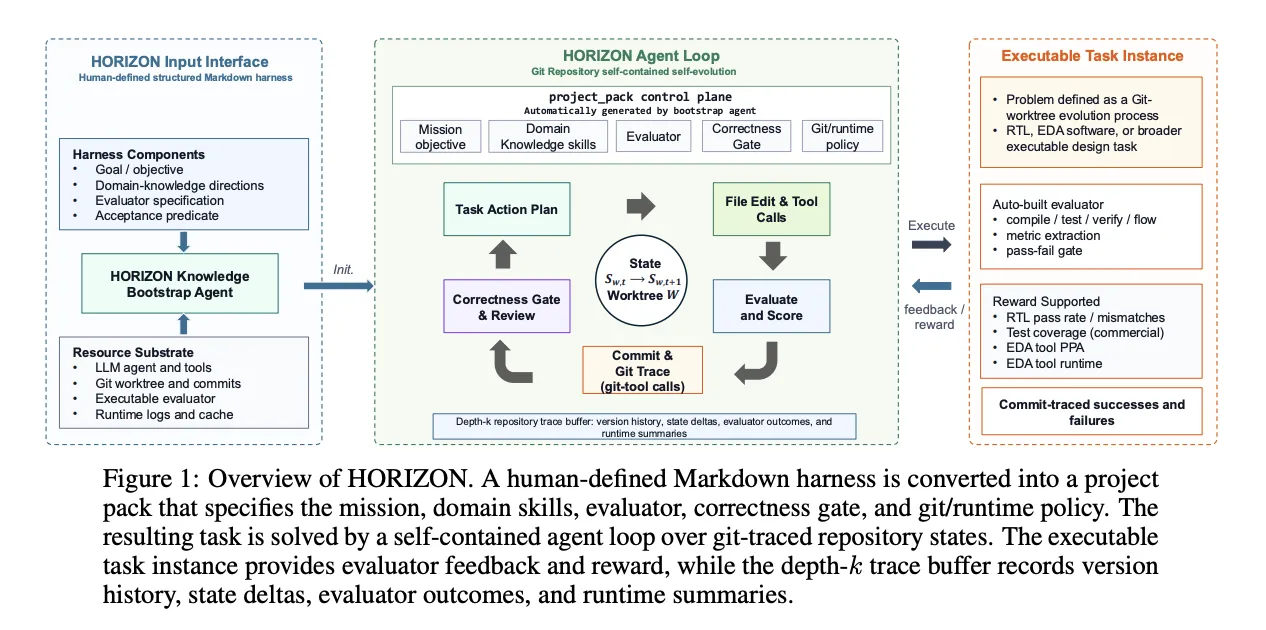
NVIDIA Research は、ハードウェア設計のためのハンズフリーエージェントフレームワークである HORIZON を発表しました。この研究は、ハードウェア設計をリポジトリレベルのコード進化として捉えています。研究チームは、レジスタ転送レベル(RTL)のインスタンス化を実行します。構造化された Markdown ハーネスがプロジェクトパックとなり、自己完結型のエージェントループが孤立した git worktree を進化させます。実行可能な受容ゲートを通過した場合のみ、バージョンがコミットされます。
研究チームは、評価されたすべての RTL ベンチマークスイートにおいて 100% の完了を報告しています。同時に、エージェントによるハードウェア設計はまだ解決されていないと明確に述べています。
HORIZON とは何か?
単発のコード生成には、実行可能な設計タスクに対する明確な限界があります。妥当な Verilog(※Verilog)だけでは実際のハードウェアには不十分です。正しさは、サイクルレベルの動作、リセット規約、ビット幅、シミュレータからのフィードバックに依存します。
HORIZON は、各設計問題を単発のプロンプトではなく、バージョン管理されたリポジトリとしてホストします。必要な入力は構造化された Markdown ハーネスのみです。このハーネスには 4 つのコンポーネントが含まれます:ゴール、ドメイン知識に基づく方向性、評価仕様の定義、および受容述語です。
ブートストラップエージェントがハーネスをプロジェクトパックにコンパイルします。研究チームはこれを p = (πagent, Ep, Ap, Γp, Ωp) と記述しています。これらの項には、エージェントポリシー、実行可能な評価器、受容述語が含まれます。また、バージョン管理ポリシーとドメインスキルも含まれています。
RTL の場合、評価者 Ep はコンパイル、シミュレーション、カバレッジ抽出、アサーションまたはテストベンチチェックを含む可能性があります。他のドメインでは、同じスロットにユニットテスト、定理証明器、プロファイラ、または合成ツールが配置されます。したがって、問題は固定されたリポジトリタイプではなく、git worktrees 上で定義されます。
 imagehttps://arxiv.org/pdf/2606.28279
imagehttps://arxiv.org/pdf/2606.28279
リポジトリレベルのループの動作
ブートストラップ後、このループはそれ以上の人間の介入なしに実行されます。各サイクルではターゲットを計画し、ワークツリーを編集し、ツールを呼び出し、評価者を実行します。その後、受容述語が一つの決断を下します:新しいバージョンをコミットするか、失敗をログ記録するかです。
ここで Git は単なる付随的な事務処理ではなく、基盤そのものです。差分(diffs)は提案された状態変化を明らかにし、コミットは受け入れられたチェックポイントを定義します。ノートには評価者の証拠が添付され、ログには完全な軌跡が記録されます。
このループは追跡コストを抑えるため、ネイティブの git コマンドに依存しています。ステージングされた編集内容は git diff –cached で検査されます。各受け入れられた試行は、そのノートに判定と報酬を伴う git コミットとなり、成功したコミットは正の修復例として機能します。拒否された試行は負の例としてログ記録されます。リポジトリの履歴が経験バッファであり、別個のデータストアではありません。
研究チームは、限定的な目的のために半マルコフ意思決定過程の用語を借用しています。これは記録されたオブジェクトに名前をつけるためだけであり、それ以上の意味はありません。「状態」とはリポジトリのバージョン付きスナップショットを指し、「オプション」は 2 つのチェックポイント間の 1 エピソードを意味します。本研究において HORIZON が RL ポリシーの学習や更新を行うことはありません。エージェントのバックボーンはキャンペーン全体を通じて固定されたままです。
セッションの再利用によりコストを抑えています。HORIZON は反復処理にわたって永続的なモデルセッションを保持します。ハネス、プロジェクトパック、安定したソースはプロバイダーのプロンプトキャッシュから提供されます。新たに課金されるトークンは、現在の差分と最新の評価器出力によって支配されます。
自己進化システム群における HORIZON の位置づけ
HORIZON は、リポジトリ規模の自己進化という系譜を拡張するものです。以前のシステムはエンジニアが実行するソフトウェアを進化させました。一方、HORIZON はエンジニアが作成するハードウェアアーティファクトを進化させます。
SystemObject evolvedDomainEvaluation signal
AlphaEvolve (2025) アルゴリズムカーネル科学およびアルゴリズムの発見自動評価器
SATLUTION (2025) 完全 SAT ソルバーリポジトリSAT 求解分散型正準性と実行時
ABCEvo (2026) ABC ロジック合成システムEDA ソフトウェア正準性と QoR
HORIZON (本研究) RTL ソース、テストベンチ、検証アーティファクトハードウェア設計コンパイル、シミュレーション、カバレッジ、アサーションチェック
これら 4 つのシステムは共通する原則を共有しています。実行可能な証拠がそれを支持する場合にのみ、候補となる変更が承認されます。
ベンチマーク結果
バックボーンは GPT-5.3 で、すべての実験において固定されています。すべての結果は、単一エージェントによるハンズフリーモードで得られたものです。キャンペーンは、512 GB の RAM を備えた AMD EPYC 9334 32 コアホスト上で実行されました。
評価は ChipBench、RTLLM-2.0、および Verilog-Eval にまたがっています。これには、CID 002 から 016 までの 9 つの CVDP コード生成および検証生成カテゴリが追加されています。CVDP には、Pinckney ら(2025)による 13 のタスクカテゴリにわたる 783 の人間が作成した問題が含まれています。
反復は 1 つの自動化された外側ステップを意味します。エージェントはワークツリーを編集し、評価器を実行した後、合格をコミットするか拒絶をログ記録します。HORIZON はすべてのスイートで 100% の合格率に達しています。唯一の未達成事例は、ChipBench の仕様ハッチャー欠陥によるものであり、エージェントの失敗ではありません。
集計された初回反復での合格率は 47.8% です。反復 0 は、単独の Pass@1 測定値ではありません。それは最初のエージェント反復後のリポジトリ状態です。エージェントは設計上、デバッグと修復を後続の反復に延期することがあります。
スイート / カテゴリ | フォーカス反復数 | 0 回目 | 収束反復数 | HORIZON
ChipBench | 混合 RTL 生成 | 20.0 | 51 | 100.0
RTLLM-2.0 | NL 仕様から RTL へ | 78.0 | 21 | 100.0
Verilog-Eval-v2 | HDLBits スタイルの Verilog | 86.2 | 21 | 100.0
CVDP CID 002 | RTL コード補完 | 3.2 | 82 | 100.0
CVDP CID 003 | NL 仕様から RTL へ | 19.2 | 24 | 100.0
CVDP CID 004 | RTL コード修正 | 10.9 | 36 | 100.0
CVDP CID 005 | 仕様から RTL モジュールの再利用 | 9.1 | 14 | 100.0
CVDP CID 007 | リンティング / QoR 改善 | 0.0 | 24 | 100.0
CVDP CID 012 | テストプランから刺激生成へ | 47.8 | 32 | 100.0
CVDP CID 013 | テストプランからチェッカー生成へ | 3.8 | 19 | 100.0
CVDP CID 014 | テストプランからアサーション生成へ | 79.1 | 11 | 100.0
CVDP CID 016 デバッグとバグ修正 25.713100.0
カテゴリ間では収束の難易度が大きく異なります。RTLLM-2.0 と Verilog-Eval は 2 回の反復で 100% に到達します。チェッカー生成(CID 013)はわずか 3.8% から始まりますが、ほぼ plateau(横ばい状態)を示すことなく着実に上昇し、19 回目の反復までに 100% に達します。コード補完(CID 002)には 82 回の反復が必要です。その長いテール部分が、単一の最も大きなトークンコストとなっています。
インタラクティブ・メトリクス解説
(function(){{
window.addEventListener('message',function(e){{
if(e.data && e.data.type==='mtpHorizonResize'){{
var f=document.getElementById('mtpHorizonFrame');
if(f && e.data.height) f.style.height=e.data.height+'px';
}}
}});
}})();
トークンの行方
正答率が飽和状態に達した後は、トークン消費量がより示唆に富む指標となります。3 つのレガシー・スイートは合わせて 600 万トーンを使用します。一方、9 つの CVDP カテゴリでは 2.039 億トークンを消費し、全体の 97.1% を占めます。CID 002 単独でも 5,600 万トークンを使用しています。
全トークンの約 91% がキャッシュされた入力であり、これにより API コストが大幅に削減されています。そのため研究チームは、最終的なパス率ではなく、トークン効率を最も改善が必要な指標として捉えています。
使用例付きユースケース
評価対象のカテゴリは、日常の RTL ワークフローに直接対応しています:
RTL コード補完(CID 002): 多くの失敗する補完結果を、正常に動作する設計に変換します。
自然言語仕様から RTL へ(RTLLM-2.0, CID 003): 文書化された仕様に基づいてモジュールを実装します。
修正とモジュールの再利用(CID 004, CID 005): テスト対象となる既存の RTL を編集または適応させます。
リンティングと QoR(品質)の改善 (CID 007): ハーネスが指摘するコードをクリーンアップします。
検証生成 (CID 012 から 014): テストベンチの刺激信号、チェックャ、およびアサーションを生成します。
デバッグ (CID 016): シミュレータからのフィードバックに基づき、機能的なバグを特定して修正します。
チェックャ生成は具体的な例です。シングルショットモデルではこれが難しく、開始時の低い 3.8% の成功率がそれを示しています。一方、HORIZON は商用 EDA(電子設計自動化)シミュレーションに対して反復処理を行い、チェックャが合格するまで続けます。
ハーネスの概要
ユーザーが対話する入力はコードではなく Markdown フォーマットのハーネスです。以下の骨格は前述の 4 つの構成要素を示しています。
コピー コードをコピーしました別のブラウザを使用してください
HORIZON ハーネス: fifo_sync
目標 / 目的
同期 FIFO を実装します。深さ 16、データ幅 8 ビット。
ドメイン知識の方向性
- リセットは同期式でアクティブハイです。
- full と empty が同時にアサートされることは決してあってはいけません。
- レディ・バニッド(ready-valid)ハンドシェイクの規約に従います。
評価者仕様
- スイートのネイティブフローでコンパイルします。
- 提供されたシミュレーションテストベンチを実行します。
- 利用可能な場合は機能的なカバレッジを抽出します。
受容条件
- シミュレーションがゼロの不一致でパスすること。
その後、ループは通常の git コマンドを使用してリポジトリを操作します。
コピー コードをコピーしました別のブラウザを使用してください
git diff --cached # ステージされた候補編集を検証する
git commit -m "iter 7: fix full/empty overlap"
git notes add -m "pass=1 mismatches=0" # 評価者の証拠を付与する
git log --oneline # 探索軌跡を再生する
強みと限界
強み:
1 つのプロトコルが、一連のスイート全体にわたる生成、補完、修復をカバーします。
このフレームワークは、基盤となるジェネレーターやバックボーンに依存しません。
ネイティブな Git を採用しているため、トレーシングとリプレイの維持コストは事実上ゼロです。
セッションの再利用により、各イテレーションの限界費用を低く抑えています。
限界:
報酬フィードバックインターフェースでは、過剰解決や報酬ハッキングが発生する可能性があります。合格とは「目に見えるハーネスを満たす」ことを意味し、完全な仕様を満たすことを保証するものではありません。
これらのベンチマークは、より広範なエンジニアリング課題に対する制御された代理指標です。
フィードバックのターンアラウンド時間はここでは有利ですが、PPA 指向のループでは数日あるいは数週間を要することもあります。
カバレッジは観測対象であり、目標そのものではありません。ゲートは各設計が合格した時点で停止するため、CID 012 は平均カバレッジ 97.9% で通過します。
ここで最適化されているのは合成結果の品質(QoR)ではなく、報告される報酬は合格率、カバレッジ、トークン数をカバーするものです。
研究チームは、将来のベンチマークに向けた二段階のプロトコルを提案しています。修復中に診断フィードバックを公開し、最終スコアリングには隠されたランダムテスト、参照モデル、および形式検証を確保します。
主なポイント
HORIZON は、隔離された Git ワークツリー上でのリポジトリレベルのコード進化として RTL 設計を管理します。
Markdown ハーネスは、評価器、受容条件、Git ポリシー、ドメインスキルを含むプロジェクトパックにコンパイルされます。
評価対象となったすべてのスイートで 100% の合格率を達成しました。唯一の欠落はベンチマーク自体の欠陥によるものです。
トークンの約91%はキャッシュされた入力であり、コストは数種類の困難なCVDPカテゴリに集中しています。
研究チームはハードウェア設計が解決済みであると主張していません。報酬のハッキングや長期のターンアラウンドを要する報酬に関する課題は依然として未解決です。
論文はこちらで確認できます。また、Twitter でフォローすることもお気軽にどうぞ。15万人以上のMLコミュニティであるSubRedditに参加し、ニュースレターも購読することを忘れないでください。待ってください!Telegramをご利用ですか?今ならTelegramでも私たちに参加いただけます。
GitHubリポジトリやHugging Faceページ、製品リリース、ウェビナーなどのプロモーションのためにパートナーシップを希望される場合は、こちらからご連絡ください。
本記事「NVIDIA HORIZON: A Hands-Free Agent that Evolves Git Worktrees and Hits 100% RTL Benchmark Completion」は、MarkTechPostで最初に公開されました。
原文を表示
NVIDIA Research introduced HORIZON, a hands-free agent framework for hardware design. It treats hardware design as repository-level code evolution. This research team exercises the register-transfer level (RTL) instantiation. A structured Markdown harness becomes a project pack. A self-contained agent loop then evolves an isolated git worktree. It commits a version only when an executable acceptance gate passes.
The research team reports 100% completion across every evaluated RTL benchmark suite. It also states plainly that agentic hardware design is not solved.
What is HORIZON?
Single-turn code generation has a clear limit on executable design tasks. Plausible Verilog is not enough for real hardware. Correctness depends on cycle-level behavior, reset conventions, bit widths, and simulator feedback.
HORIZON hosts each design problem as a version-controlled repository, not a one-shot prompt. The only required input is a structured Markdown harness. That harness carries four components: a goal, domain-knowledge directions, an evaluator specification, and an acceptance predicate.
A bootstrap agent compiles the harness into a project pack. The research team writes this as p = (πagent, Ep, Ap, Γp, Ωp). Those terms cover the agent policy, the executable evaluator, and the acceptance predicate. They also cover the version-control policy and the domain skills.
For RTL, the evaluator Ep may include compilation, simulation, coverage extraction, and assertion or testbench checks. In other domains, that same slot could hold unit tests, theorem provers, profilers, or synthesis tools. Problems are therefore defined over git worktrees, not over a fixed repository type.
imagehttps://arxiv.org/pdf/2606.28279
How the Repository-Level Loop Works
After bootstrap, the loop runs without further human input. Each cycle plans a target, edits the worktree, invokes tools, and runs the evaluator. The acceptance predicate then decides one thing: commit the new version, or log the failure.
Git is the substrate here, not incidental bookkeeping. Diffs expose proposed state changes. Commits define accepted checkpoints. Notes attach evaluator evidence. The log recovers the full trajectory.
The loop leans on native git commands to keep tracing cheap. Staged edits are inspected with git diff –cached. Each accepted attempt becomes a git commit whose notes carry the verdict and reward. Successful commits become positive repair examples. Rejected attempts are logged as negative examples. The repository history is the experience buffer, not a separate datastore.
The research team borrow semi-Markov decision process vocabulary for one narrow purpose. It names the recorded objects, nothing more. A ‘state’ is a versioned snapshot of the repository. An “option” is one episode between two checkpoints. HORIZON does not train or update an RL policy in this work. The agent backbone stays fixed throughout a campaign.
Session reuse keeps cost down. HORIZON holds a persistent model session across iterations. The harness, project pack, and stable sources are served from the provider’s prompt cache. Newly billed tokens are then dominated by the current diff and the latest evaluator output.
Where HORIZON Sits Among Self-Evolving Systems
HORIZON extends a lineage of repository-scale self-evolution. Earlier systems evolved the software that engineers run. HORIZON instead evolves the hardware artifacts that engineers create.
SystemObject evolvedDomainEvaluation signal
AlphaEvolve (2025)Algorithmic kernelsScientific and algorithmic discoveryAutomated evaluators
SATLUTION (2025)Full SAT-solver repositoriesSAT solvingDistributed correctness and runtime
ABCEvo (2026)ABC logic-synthesis systemEDA softwareCorrectness and QoR
HORIZON (this work)RTL sources, testbenches, verification artifactsHardware designCompile, simulate, coverage, assertion checks
All four share one principle. A candidate change is admitted only when executable evidence supports it.
Benchmark Results
The backbone is GPT-5.3, fixed for all experiments. Every result uses single-agent, hands-free mode. Campaigns ran on an AMD EPYC 9334 32-core host with 512 GB of RAM.
The evaluation spans ChipBench, RTLLM-2.0, and Verilog-Eval. It adds nine CVDP code- and verification-generation categories, CID 002 to 016. CVDP contains 783 human-authored problems across 13 task categories (Pinckney et al., 2025).
An iteration is one automated outer step. The agent edits the worktree, runs the evaluator, then commits a pass or logs a rejection. HORIZON reaches a 100% pass rate on every suite. The one residual miss is a ChipBench specification-harness defect, not an agent failure.
The aggregate first-iteration pass rate is 47.8%. Iteration-0 is not a standalone Pass@1 measurement. It is the repository state after the first agent iteration. The agent may defer debugging and repair to later iterations by design.
Suite / categoryFocusIter. 0Conv. iter.HORIZON
ChipBenchMixed RTL generation20.05100.0
RTLLM-2.0NL spec to RTL78.02100.0
Verilog-Eval-v2HDLBits-style Verilog86.22100.0
CVDP CID 002RTL code completion3.282100.0
CVDP CID 003NL spec to RTL19.224100.0
CVDP CID 004RTL code modification10.936100.0
CVDP CID 005Spec-to-RTL module reuse9.114100.0
CVDP CID 007Linting / QoR improvement0.024100.0
CVDP CID 012Test-plan to stimulus generation47.832100.0
CVDP CID 013Test-plan to checker generation3.819100.0
CVDP CID 014Test-plan to assertion generation79.11100.0
CVDP CID 016Debugging and bug fixing25.713100.0
Convergence difficulty varies widely across categories. RTLLM-2.0 and Verilog-Eval reach 100% within two iterations. Checker generation (CID 013) starts at just 3.8%. Yet it climbs steadily to 100% by iteration 19, with almost no plateau. Code completion (CID 002) needs 82 iterations. Its long tail is the single largest token cost.
Interactive Metrics Explainer
(function(){{
window.addEventListener('message',function(e){{
if(e.data && e.data.type==='mtpHorizonResize'){{
var f=document.getElementById('mtpHorizonFrame');
if(f && e.data.height) f.style.height=e.data.height+'px';
}}
}});
}})();
Where the Tokens Go
Token consumption is the more informative signal once correctness saturates. The three legacy suites together use 6.0M tokens. The nine CVDP categories use 203.9M tokens, or 97.1% of the total. CID 002 alone uses 56.0M tokens.
About 91% of all tokens are cached input, which significantly lowered the API cost. The research team therefore treat token efficiency, not final pass rate, as the metric most in need of improvement.
Use Cases With Examples
The evaluated categories map directly to daily RTL work:
RTL code completion (CID 002): convert many failing completions into passing designs.
Natural-language spec to RTL (RTLLM-2.0, CID 003): implement a module from a written spec.
Modification and module reuse (CID 004, CID 005): edit or adapt existing RTL under test.
Linting and QoR improvement (CID 007): clean up code the harness flags.
Verification generation (CID 012 to 014): produce testbench stimulus, checkers, and assertions.
Debugging (CID 016): localize and fix functional bugs against simulator feedback.
Checker generation is a concrete example. Single-shot models struggle with it, as the low 3.8% start shows. HORIZON instead iterates against commercial-EDA simulation until the checker passes.
A Look at the Harness
The user-facing input is a Markdown harness, not code. The skeleton below illustrates the four described components.
Copy CodeCopiedUse a different Browser
HORIZON Harness: fifo_sync
Goal / objective
Implement a synchronous FIFO. Depth 16, 8-bit data.
Domain-knowledge directions
- Reset is synchronous, active-high.
- full and empty must never assert together.
- Follow ready-valid handshake conventions.
Evaluator specification
- Compile with the suite's native flow.
- Run the provided simulation testbench.
- Extract functional coverage where available.
Acceptance predicate
- Simulation passes with zero mismatches.
The loop then drives the repository with plain git operations.
Copy CodeCopiedUse a different Browser
git diff --cached # inspect staged candidate edits
git commit -m "iter 7: fix full/empty overlap"
git notes add -m "pass=1 mismatches=0" # attach evaluator evidence
git log --oneline # replay the search trajectory
Strengths and Limitations
Strengths:
One protocol covers generation, completion, and repair across whole suites.
The framework is agnostic to the underlying generator or backbone.
Native git makes tracing and replay essentially free to maintain.
Session reuse keeps the marginal cost of each iteration low.
Limitations:
The reward-feedback interface allows over-solving or reward hacking. A pass can mean ‘satisfies the visible harness,’ not the full specification.
These benchmarks are controlled proxies for a much broader engineering problem.
Feedback turnaround is favorable here. PPA-oriented loops can instead take days or weeks.
Coverage is observational, not the target. CID 012 passes at 97.9% average coverage, since the gate stops each design once it passes.
Synthesis quality-of-results (QoR) is not optimized here; the reported reward covers pass rate, coverage, and tokens.
The research team propose a two-level protocol for future benchmarks. Expose diagnostic feedback during repair. Reserve hidden randomized tests, reference models, and formal checks for final scoring.
Key Takeaways
HORIZON manages RTL design as repository-level code evolution over an isolated git worktree.
A Markdown harness compiles into a project pack: evaluator, acceptance predicate, git policy, domain skills.
It reaches a 100% pass rate on all evaluated suites; the only miss is a benchmark defect.
About 91% of tokens are cached input, and cost concentrates in a few hard CVDP categories.
The research team do not claim hardware design is solved; reward hacking and long-turnaround reward stay open.
Check out the Paper here. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post NVIDIA HORIZON: A Hands-Free Agent that Evolves Git Worktrees and Hits 100% RTL Benchmark Completion appeared first on MarkTechPost.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み