AI時代のコードレビューTips ─ Cursorで実践する構造可視化と定型作業の自動化
DeNAのエンジニアは、AIコード生成ツールの普及で増大するコードレビュー負荷に対処するため、Cursorを活用した構造可視化と定型作業自動化の実践的Tipsを紹介している。
キーポイント
AIコード生成によるレビュー負荷の増大
AIによるコード生成ツールの進化で実装速度は向上したが、生成されるコード量の増加により、コードレビューが開発全体のボトルネックとなるケースが増えている。
インフラエンジニアのレビュー課題
アプリケーションコードのレビューに慣れていないインフラエンジニアにとって、機能間の依存関係や全体構造を把握し品質を保証することは容易ではない。
Cursorを活用した構造可視化
AI支援開発ツール「Cursor」を用いてコードの構造を可視化し、レビュアーが全体像を把握しやすくするアプローチが提案されている。
定型作業の自動化による効率化
レビューにおける定型作業を自動化することで、レビュアーの負荷軽減とレビュー品質の向上を図る具体的な方法が示されている。
影響分析・編集コメントを表示
影響分析
この記事は、AIコード生成ツールの普及に伴う開発現場の新たな課題を具体的に指摘し、実践的な解決策を提示している点で価値がある。特に、ツールの進化が生む副次的課題に焦点を当て、現場エンジニアの視点から問題を分析していることが特徴的である。
編集コメント
AIツールの導入が生む新たな課題に着目した実践的な内容で、特に現場エンジニアの悩みに直結するテーマを扱っている。技術トレンドの陰にある作業プロセスの変化を捉えた良質なケーススタディと言える。
こんにちは。IT本部IT基盤部第三グループの前田洋太です。
近年、AIによるコード生成ツールの進化は目覚ましく、開発現場ではコードの実装速度が飛躍的に向上しています。しかしその一方で、高速化された実装プロセスにコードレビューが追いつかず、開発全体のボトルネックとなるケースが増えているのではないでしょうか。AIが生成するコードの量は日々増加し、レビュアーは増え続けるコードの中から機能間の依存関係や全体構造を把握し、品質を保証しなければなりません。特に、アプリケーションコードのレビューに慣れていない我々インフラエンジニアにとって、この負荷は大きく、的確なレビューを行うのは容易ではありません。
原文を表示
こんにちは。IT 本部 IT 基盤部第三グループの前田洋太です。
近年、AI によるコード生成ツールの進化は目覚ましく、開発現場ではコードの実装速度が飛躍的に向上しています。しかし、その一方で、高速化された実装プロセスにコードレビューが追いつかず、開発全体のボトルネックとなるケースが増えているのではないでしょうか。AI が生成するコードの量は日々増加し、レビュアーは増え続けるコード量の中から機能間の依存関係や全体構造を把握し、品質を保証しなければなりません。特に、アプリケーションコードのレビューに慣れていない我々インフラエンジニアなどにとって、この負荷は大きく、的確なレビューを行うことは容易ではありません。
本記事では、このような AI 時代のコードレビューにおける課題に対し、AI エディター「Cursor」を積極的に活用したアプローチを紹介します。具体的な取り組みとして、AI を用いたコードの構造的可視化と、レビュー準備作業の自動化を通じて、レビュー効率と品質の向上を実現した事例をご紹介します。この記事が、AI 活用による開発プロセスの改善、特にコードレビューの効率化と品質向上に繋がるヒントとなれば幸いです。
AI 時代のコードレビューにおける課題
AI の導入により、これまで手作業で行っていたボイラープレートコードの生成や単純なロジックの実装が効率化され、開発速度は大幅に向上しました。しかし、この高速化は新たな課題を生み出しています。
- 開発速度とレビュー速度のギャップ: AI が生成するコードの量は日々増加していますが、人間のレビュアーがコードを読み解き、変更の意図や影響範囲を理解し、品質を保証する速度はそれに追いついていません。結果として、プルリクエスト(PR)がレビュー待ちのまま滞留し、開発サイクルが遅延する事態が発生しやすくなっています。
- コード行数増加による認知負荷の増大: 単純なコード量が増えるだけでなく、AI が生成するコードは時に冗長であったり、レビュアーの意図しない構造を持つこともあります。これにより、レビュアーはコードの表面的な変更だけでなく、潜在的な問題や意図せぬ影響を読み解くために、より高い認知負荷を強いられることになります。
- 1次元的なコードからの構造把握の難しさ: ソースコードは基本的に 1 次元のテキスト情報として並んでいます。関数呼び出しの依存関係やモジュール間の連携といった構造的な情報はテキストだけでは直感的に理解しづらく、レビュアーは多くの時間をかけてコードを追跡する必要があるでしょう。
- レビュー品質の属人化: コード量の増加に伴い、レビューの質はレビュアー個人の処理能力や経験に依存しやすくなります。標準化された手順がなければレビュープロセスが属人化する傾向があり、特に普段からアプリケーションコードに深く触れていないエンジニアにとって、その影響は顕著です。
これらの課題は、AI が開発に必須の存在となる時代において、エンジニアリングチーム全体で取り組むべきテーマとなっています。
課題解決のためのアプローチ
上記の課題を解決するため、私たちは以下の 4 つのアプローチに重点を置きました。AI の能力を単なるコード生成に留めず、開発プロセス全体、特にコードレビューの質と効率を高めるために活用するものです。
- AI エディターやコーディングエージェントの積極的な活用: Cursor のようなツールが持つ、コードの構造を理解し、それに基づいて情報を加工する能力を最大限に引き出します。これにより、レビュアーが直面する認知負荷を軽減することを目指します。
- 複雑なコード構造の可視化による理解促進: 関数呼び出しの依存関係やモジュール間の連携など、コードの構造情報を視覚的に表現することで、レビュアーが直感的に、かつ迅速にシステム全体を把握できるようにします。
- 定型的なレビュー準備・ドキュメント作成作業の自動化: プルリクエストの説明文作成や、レビューに必要な図の生成といった反復作業を自動化します。これにより、エンジニアは本質的なレビュー業務に集中できる時間を増やします。
- コマンド化による作業手順の標準化と品質の均一化: 特定の作業を AI エディター内のコマンドとして定義し、実行可能な形にすることで、作業手順の曖昧さを排除します。これにより、誰が行っても同じ品質のレビュー情報が生成されることを目指します。
次章からは、これらのアプローチを具体的な例とともに詳しく解説します。
AI を活用したコード構造の可視化
コードレビューにおける大きな課題の 1 つは、膨大なテキスト情報の中から、変更がシステム全体に与える影響や、関連する機能の構造を読み解くことです。この課題に対し、私たちは AI を用いたコード構造の可視化が非常に効果的であることを見出しました。
構造的可視化の重要性
関数呼び出しの依存関係やクラス間の連携、データフローなど、コードが内包する構造的な情報は、1 次元的に並んだコードテキストだけでは全体像を把握しにくいものです。このような場合に、視覚的な表現を用いることで、レビュアーの直感的な理解を促進し、認知負荷を大幅に軽減できます。AI はコードを高い精度で解釈できるため、この可視化プロセスにおいて強力なパートナーとなります。
可視化の具体例:関数呼び出しグラフ
私たちは、特定の処理における関数呼び出しの依存関係を「関数呼び出しグラフ」として可視化する取り組みを行いました。Graphviz の DOT 形式を用いてグラフを生成し、これを AI エディターである Cursor に指示して作成します。
AI エディターは、テンプレートファイルや既存のグラフを参照しながら、対象のコードから関数呼び出しの構造を抽出し、一貫したスタイルでグラフを生成できます。これにより、個々のレビュアーが手動でグラフを作成する手間が省けるだけでなく、グラフの表現スタイルが統一されるため、レビューに必要な情報が常に読みやすく、比較しやすい状態に保たれます。
以下の例は、セキュリティ部から毎日メールで送られてくる脆弱性情報について、AI を用いたレポートを作成し、Slack のチャンネルに送信する GAS (Google Apps Script) における関数の呼び出し構造を可視化したグラフです。
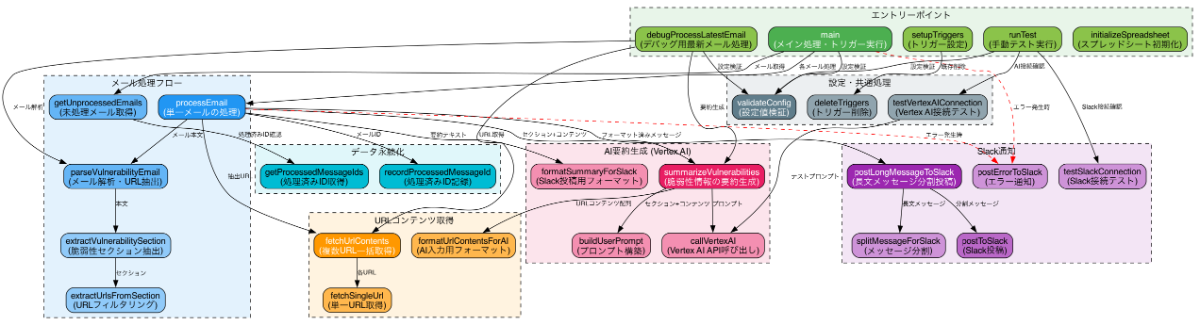
これらの関数はすべて AI のみによって書かれたものです。行数はそれほど多くないとはいえ、コードレビューに不慣れな人ではコードだけをみて構造を把握することが難しいかと思いますが、このように可視化することによって機能の役割ごとに色分けされたり、呼び出し関係にラベル付けされたりと理解しやすくなっています。
全体像を示したこの図だとややグラフが複雑になっていますが、その点については次のパートで解決を試みます。また、プロンプトを含む具体的な作成方法についてはその次のパートで説明します。
従来型ツールと比較した際の特徴
生成 AI の発展以前からコード可視化ツールは多数存在しますが、AI を活用したアプローチならではのメリットがあります。
まず、AI はコードを単なる構文としてとらえるだけではなく、そのロジック内での位置付けやビジネス上の役割といった上位レイヤーの情報を含めて理解することに長けています。たとえば、ある関数が「ユーザー認証」の役割を持つことや「データ永続化」に関連する処理であることなど、コードの字面だけからは読み取りにくい意味合いを、コードが書かれた文脈やドキュメントを理解することで図に反映させることが可能です。
また、AI はレビュアーが必要とする部分だけを抽出して見せる柔軟性を持っています。大規模なシステムでは、関数呼び出しグラフ全体を描画すると複雑すぎて可読性が損なわれることがあります。実際、先ほどの図は全体が把握できる一方でメインの処理やテスト関数がどのようになっているかの詳細を把握するには情報が多すぎます。
そこで AI を使うと、特定の関心領域や深さの指定を自然言語で指示するだけで、レビュアーが今まさに知りたい情報に焦点を当てたグラフを動的に生成できるのです。
以下の図はそれぞれ、メインの処理のみに注目したものとテスト関連の処理のみに注目したものです。追加の指示はそれぞれ「テストなどは無視して、メインの処理のみを抜き出したグラフを新しく作成して。」「今度は、テスト関連の処理だけに注目して。」のみです。
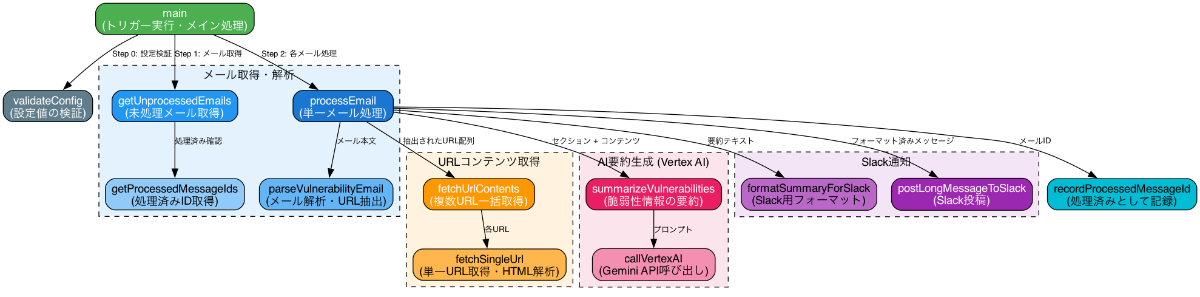
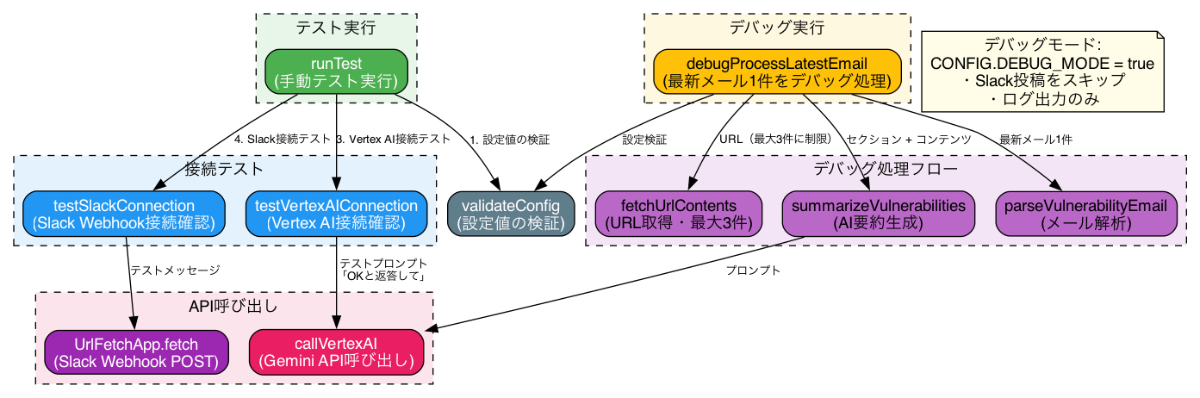
このようにすることで、情報の過負荷を防ぎ、レビューの効率をさらに向上させられます。
関数呼び出しグラフの作成プロセス
さて、ここでは、ここまでお見せしてきたような図を作成する工程を紹介します。今回のコーディングおよび図の作成は Cursor で実施しましたので以下の手順は Cursor を想定していますが、CLI 型のコーディングエージェントや AI チャットアプリでも試すことができると思います。
まず、AI に与えたプロンプトは以下です。
# 関数呼び出しの依存関係をGraphviz (DOT言語) 形式で出力する
選択したコードの関数呼び出しの依存関係を解析し、Graphviz (DOT言語) 形式で出力してください。
コードレビューの効率化のため、単なる構文解析ではなく「ビジネスロジックの流れ」が分かるように以下のルールで作成してください。
## 作成ルール
1. **基本設定**:
- `digraph G { ... }` ブロックを使用してください。
- グラフ全体の設定として `rankdir=TB;` (上から下) または `rankdir=LR;` (左から右) を適切に選んでください。
- ノードのデフォルト設定を `node [shape=box, style="rounded,filled", fillcolor=lightgrey, fontname="Helvetica"];` とし、読みやすくしてください。
2. **ノードの記述 (関数名 + 役割)**:
- 各ノードの `label` 属性に、「関数名」と「ビジネス上の役割(日本語)」を改行(`\n`)区切りで記述してください。
- 書式: `NodeID [label="関数名\n(役割の要約)"];`
- 例: `calc_tax [label="calcTax\n(消費税額の算出)"];`
3. **エッジの記述 (データの流れ)**:
- 呼び出しの際に渡されている主要なデータや目的を `label` 属性で添えてください。
- 書式: `NodeA -> NodeB [label="渡すデータ"];`
- 例: `order_process -> calc_tax [label="注文小計", fontsize=10];`
4. **フィルタリング**:
- ロギング、単純なGetter/Setter、標準ライブラリの細かな呼び出しは省略し、メインのロジックに関わる部分のみを抽出してください。
- 関連性の高い関数群は `subgraph cluster_X { ... }` でグループ化してラベルを付けてください。
## 出力例
```dot
digraph CodeFlow {
rankdir=LR;
node [shape=box, style="rounded,filled", fillcolor="#f0f0f0"];
main [label="main\n(アプリ起動・初期化)"];
auth [label="authenticateUser\n(認証トークン検証)"];
main -> auth [label="Request Header"];
}
---
## ファイル保存
* **ファイル保存:**
* 出力されたコードを `.dot` という拡張子で保存してください。
* 保存先は docs/figures にしてください。
* ファイル名は適切なものをつけてください。
* **画像出力:**
* dot ファイルだけでなく、png 画像も保存してください。
* コマンドは dot -Tpng input.dot -o output.png です。
---<p data-target-id="関数呼び出しグラフの作成プロセス">この指示を受けた AI は、指定されたソースファイルの内容を解析し、関数呼び出しの依存関係を抽出し、DOT 形式のグラフファイルを生成します。このファイルは <code>docs/figures/[ファイル名].dot</code> として保存されますし、Graphviz の <code>dot</code> コマンドを用いて DOT ファイルから PNG 画像を生成する工程も AI がやってくれます。</p>
<p data-target-id="関数呼び出しグラフの作成プロセス">更なる効率化として、このようなプロセスをコマンドとして事前に定義しておくという方法があります。誰でも一貫した品質で関数呼び出しグラフを生成しプルリクエストやドキュメントに添付できるようになりますので、それについて次の章で述べます。</p>
<h2 id="コードレビュー支援コマンドによる効率化" data-target-id="コードレビュー支援コマンドによる効率化">
<span>
コードレビュー支援コマンドによる効率化
</span>
</h2><p data-target-id="コードレビュー支援コマンドによる効率化">レビュー効率を最大化するためには、複雑な構造の可視化だけでなく、<strong>レビュー準備における定型作業を自動化し、作業手順を標準化する</strong>ことが不可欠です。私たちは、この目的のために Cursor のコマンド機能を活用しました。</p>
<h3 id="コマンド化の目的" data-target-id="コマンド化の目的">
<span>
コマンド化の目的
</span>
</h3><p data-target-id="コマンド化の目的">特定の作業を Cursor のコマンドとして定義することで、以下のメリットが得られます。</p>
<ul data-target-id="コマンド化の目的">
<li><strong>作業手順の曖昧さを排除し、実行を容易にする</strong>: 複雑な手順もコマンド 1 つで実行できるようになり、レビュアーの負担が軽減されます。</li>
<li><strong>定型作業の自動化により、レビュー準備の工数を削減</strong>: プルリクエストの説明文作成や、グラフの生成といった時間を要する作業を自動化し、レビュアーが本質的なレビューに集中できる時間を確保します。</li>
<li><strong>全員が同じ手順で作業することで、レビューに必要な情報の品質を均一化</strong>: コマンドを通じて統一された形式で情報が提供されるため、レビューの前提となる情報の信頼性と一貫性が向上します。コマンド自体も GitHub などを使って管理しておけばチーム内への配布も用意です。</li>
</ul>
<h3 id="関数呼び出しグラフ更新コマンド" data-target-id="関数呼び出しグラフ更新コマンド">
<span>
関数呼び出しグラフ更新コマンド
</span>
</h3><p data-target-id="関数呼び出しグラフ更新コマンド">先ほどのプロンプトを、ワークスペースの <code>.cursor/commands/make-function-call-graph.md</code> に保存し、GitHub などでソースコードなどと一緒に共有します。</p>
<p data-target-id="関数呼び出しグラフ更新コマンド">こうすると、Cursor のチャット欄では <code>/make-function-call-graph</code> と打つだけで誰でも同じように関数呼び出しグラフの図が作成できます。</p>
<p data-target-id="関数呼び出しグラフ更新コマンド">追加の指示をしたい場合は、「/make-function-call-graph テストなどは無視して、メインの処理のみを抜き出したグラフを新しく作成して。」と指示を付け加えるだけです。</p>
<p data-target-id="関数呼び出しグラフ更新コマンド">継続的な開発などで既存の図を頻繁にアップデートする必要がある場合は、コマンドを定義するマークダウンファイルでファイル名を指定し、「既存のファイルがある場合はアップデートされた内容で上書きして」などの指示を与えるとうまく動作します。</p>
<h3 id="プルリクエスト作成コマンド" data-target-id="プルリクエスト作成コマンド">
<span>
プルリクエスト作成コマンド
</span>
</h3><p data-target-id="プルリクエスト作成コマンド">図の作成だけでなくプルリクエストの作成もコマンド化しています。コマンドは、以下のステップで PR の作成と更新を支援します。</p>
<h4 id="説明文の自動生成" data-target-id="プルリクエスト作成コマンド">
<span>
説明文の自動生成
</span>
</h4><p data-target-id="プルリクエスト作成コマンド">AI は、変更内容に基づいてプルリクエストの説明文を自動で生成します。これにより、実装者が手動で詳細な説明文を作成する手間を省き、<strong>説明文の記述漏れや品質のばらつきを防ぎます</strong>。</p>
<p data-target-id="プルリクエスト作成コマンド">説明文の品質や形式は、テンプレートを利用させることで一定に保っています。
以下では、我々が実際に使っているプルリクエストのテンプレートを紹介します。</p>
<div data-target-id="プルリクエスト作成コマンド">
## 概要
## 変更ファイルとその概要
✅ 付きのファイルを中心にレビューお願いします
## テスト内容(参考までに)
## 関連issue
close #
</div><h4 id="プルリクエストの作成" data-target-id="プルリクエスト作成コマンド">
<span>
プルリクエストの作成
</span>
</h4><p data-target-id="プルリクエスト作成コマンド">ディスクリプションだけでなく、プルリクエスト自体の作成も含めて AI にやらせることで、作業を効率化し品質を一定に保ちやすくなります。</p>
<p data-target-id="プルリクエスト作成コマンド">そのためのプロンプトの例は以下です。これを <code>.cursor/commands/make-pr.md</code> に書いておくことで、 チャット欄では「/make-pr」と打つだけで作成してもらうことができます。比較先のブランチを main 以外にしたいといった場合でも、「/make-pr 比較先ブランチは main じゃなくて fix/foo にして」などと指示を付け加えるだけです。</p>
# 実装完了時のプルリクエスト作成アクション
実装が完了しましたので、以下の2つのアクションを行いGitHub上でプルリクエストを作成してください。 ただし、同じブランチを対象とした open なプルリクエストがすでにある場合は、作成ではなくアップデートしてください。
## 0. 既存プルリクエストの確認
同じブランチを対象とした open なプルリクエストがすでにあるかを確認してください。存在しない場合は新規作成、する場合はアップデートするということを覚えておいてください。
## 1. プルリクエストの説明文作成
@Branch の PR description を書いてください。 @.github/pull_request_template.md を使って書いてください。
出力先は tmp/pr_description.md にしてください。ファイルへの出力は、既存の内容を上書きする形にしてください。必要に応じて `tmp` ディレクトリを事前に作成してください(例: `mkdir -p tmp`)。
## 2. プルリクエスト作成
gh コマンドを用いて、上記の説明文とともにこのブランチを main ブランチにマージするためのプルリクエストを作成してください。ただし、同じブランチを対象とした open なプルリクエストがすでにある場合は、作成ではなくアップデートしてください。新規作成時は `gh pr create --draft` を使用してドラフトで作成し、既存PRがある場合はドラフトのまま `gh pr edit` でアップデートしてください。
gh コマンドでプルリクエストを作成/更新する際は、ベースブランチを明示し、説明文・Assignee・Reviewer を指定してください(例):
# 新規作成
gh pr create --draft --base main --body-file tmp/pr_description.md --assignee @me --reviewer itpf-3g-dena/itpf-3g
# 既存PRの更新
gh pr edit --body-file tmp/pr_description.md --add-assignee @me --add-reviewer itpf-3g-dena/itpf-3g
Assignee は gh コマンドで認証されているユーザー(@me)にしてください。
Reviewer は itpf-3g-dena/itpf-3g を指定してください。
備考: gh pr edit は --add-assignee / --add-reviewer を使用する仕様です。
## 3. 後片付け
tmp/pr_description.md を削除してください(例: `rm -f tmp/pr_description.md`)。コマンドと設定ファイルの管理
これらの Cursor コマンドは、専用のディレクトリ(.cursor/commands/)に配置し、Git でバージョン管理しています。.gitignore ファイルの設定を調整し、.cursor/ ディレクトリ全体と関連する設定ファイル(.cursorrules)をリポジトリに含めることで、チーム全体でコマンドを共有し、一貫した開発環境を維持できます。
これらの取り組みにより、レビューに不慣れなエンジニアでも質の高いレビュー情報を容易に準備できるようになり、チーム全体のレビュープロセスが大幅に改善されました。
まとめ
AI によるコード生成が開発速度を加速させる一方で、その恩恵を最大化するためには、コードレビュープロセスにおける新たなボトルネックへの対応が不可欠です。私たちは、特にレビューに不慣れなエンジニアが直面する課題に対し、Cursor を活用した実践的な解決策を導入しました。
本記事で紹介した取り組みの核心は以下の 2 点です。
- 複雑なコード構造の可視化: 関数呼び出しの依存関係など、テキストからは理解しにくい構造的な情報を AI の力を借りて可視化することで、レビュアーの認知負荷を軽減し、コード理解を促進します。
- 定型作業のコマンド化による自動化と標準化: 可視化するための図の作成やプルリクエストの作成といった反復的な作業を Cursor コマンドとして定義し、自動化しました。これにより、レビュー準備の効率が向上し、レビュアー間の情報品質が均一化されます。
これらのアプローチによって、私たちはレビュー効率の向上、PR 品質の均一化、そして何よりもコードに対する深い理解の促進という具体的な効果を得ることができました。定量的な面では、1 プロジェクトだけでもレビュー準備や構造把握にかかる工数をチーム全体で月間約 8 時間削減できており、その分を本質的なレビューや設計議論に充てられるようになっています。AI 時代の開発プロセスにおいて、構造的な情報の可視化、そして作業の自動化と標準化は、もはや不可欠な要素であると強く感じています。
おわりに
DeNA では、AI 技術を単なるコード生成の道具としてだけでなく、開発プロセス全体の課題を解決し、エンジニアリングの生産性を高めるための強力なツールとして捉え、積極的に活用しています。本記事でご紹介したコードレビューの効率化も、その一環です。
今後の展望としては、さらなる AI との連携を通じて、レビュープロセスの高度化を図っていきます。たとえば、AI による変更意図の自動要約や、潜在的なリスク箇所の事前検知、さらにはレビューコメントの自動提案など、AI の活用範囲は無限に広がっています。
また、今回紹介したコード構造の可視化やコマンド化のアプローチは、コードレビューにとどまらず、設計ドキュメントの自動生成やオンボーディング資料の作成など、他の開発フェーズやドキュメンテーション作業へも応用可能だと考えています。
DeNA Engineering Blog では、このような具体的な課題解決とそこから得られた学びを共有することで、開発体験の向上と技術コミュニティへの貢献を目指しています。この取り組みが、読者の皆様の開発現場における AI 活用のヒントになれば幸いです。
最後までお読みいただき、ありがとうございました。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み