エージェント型検索モデル(5 分読了)
TLDR AI は、従来のモリシックな検索システムから、ドメイン固有の知識を統合し全体像を把握する「エージェント型検索モデル」への移行が、汎用大規模言語モデルでは解決できない最後の 20% の課題を克服する鍵であると分析している。
キーポイント
従来の検索アーキテクチャの限界
埋め込み、再ランク付け、クエリ理解など個別のコンポーネントで構成される従来の「厚いモノリス型」システムは、各部分が全体像を把握できず、手動でのプログラム処理に依存している。
エージェント型検索モデルの登場
LLM を用いたエージェントが検索タスクを統括し、ツールや知識ベースを活用してユーザーのクエリに対して全体最適な解決策を導き出す新しいパラダイム。
汎用モデルとドメイン固有のギャップ
GPT-5 などの最先端モデルは一般的な検索には優れるが、家具店の「ビストロテーブル」やファッションの嗜好など、企業固有の文脈(最後の 20%)を理解できない。
専門特化型モデルの実用性
特定ドメインにトレーニングされたエージェント型モデルは、汎用モデルよりも小さく高速で展開しやすく、検索インフラへの統合が容易である。
ドメイン特化型アジェンティック検索モデルの台頭
汎用LLMに依存せず、SID-1やWaldoのような特定ドメイン向けに訓練された専用モデルが、簡易な検索バックエンドを効果的にオーケストレーションする未来が到来しています。
複雑なパイプラインから単純なツールの連携へ
従来の複雑なクエリ処理や再ランク付けの代わりに、エージェントがキーワード検索や埋め込みモデルといった基本的でスケーラブルな検索ツールを直接制御するアプローチへとシフトします。
汎用LLMと専用モデルのコスト・性能比較
汎用モデル(GPT-5等)に依存するとコンテキストエンジニアリングのトークンコストが高騰しますが、ドメイン特化型モデルはより小型で低遅延であり、検索結果の最終20%を効率的に処理できます。
影響分析・編集コメントを表示
影響分析
この記事は、検索技術の進化が単なるモデル性能の向上ではなく、「ドメイン固有知識」をどう統合するかというアーキテクチャのパラダイムシフトにあることを示唆しています。企業にとっては、汎用 LLM の導入だけでなく、自社の文脈を理解する専用エージェントの構築が競争優位性の鍵となることを意味しており、検索インフラ設計の根本的な見直しを迫る重要な示唆です。
編集コメント
検索システムの未来は「より大きなモデル」ではなく、「より文脈を理解するエージェント」にあるという視点は大変示唆に富んでいます。特に、汎用 AI が苦手とする「最後の 20% のドメイン知識」をどう扱うかが実装の鍵となる点は、エンジニアリングチームが直ちに検討すべき課題です。
検索において、レゴの部品についてはよく知っています。埋め込みベクトル(Embeddings)。再ランク付け器(Rerankers)。クエリ理解。BM25。標準的なスタックで組み合わせているすべての部品です。
しかし、新たな力が台頭しています:エージェント型検索モデルです。検索タスクを制御するために*特化して*訓練された大規模言語モデル(LLM)です。GPT-5 やその仲間と比較すると、これらのモデルは特定のタスクやドメインに焦点を当てることがあります。より小さく、高速で、検索インフラストラクチャへの展開も容易になります。
舞台設定をしましょう。
従来のレゴの部品を用いて構築するのは、このような厚い検索モノリスです:
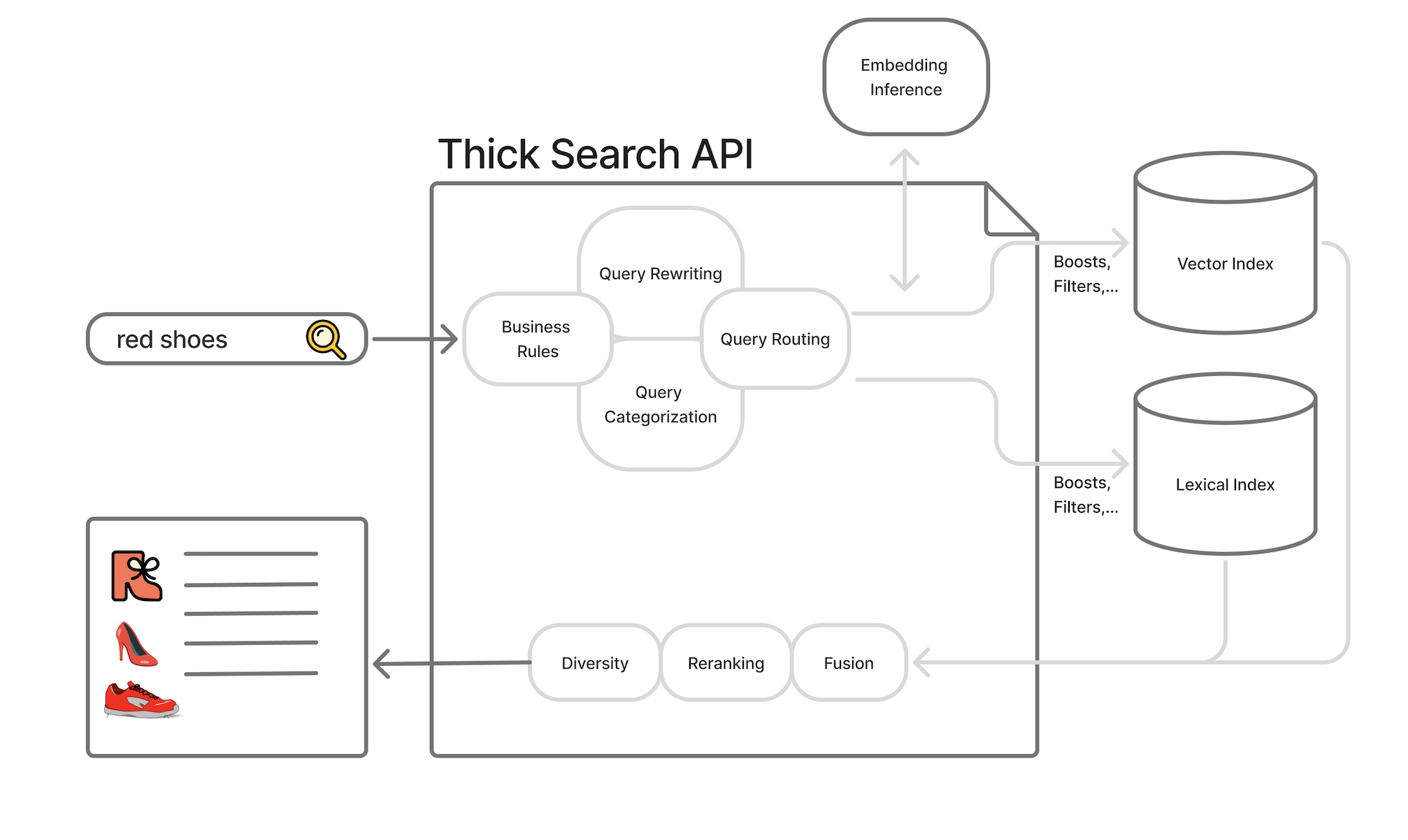
これが過去 1〜2 年間にわたって構築されてきたものです。クエリがシステムに流入します。ビジネスルールを適用し、クエリを分類します。1 つ以上の検索バックエンドを検索します。戻ってきた結果を後処理し、再ランク付けします。
すべてが非常に手動で、プログラム的であり、個別対応です。各部品は全体を見渡すことができません。各部分は問題の一部分(再ランク付け器、クエリ分類器等)に焦点を当てており、全体については無知です。
エージェント型検索は部品を統合して全体を統括する
エージェント型検索は部品を分解し、全体を見渡します。GPT-5 や Sonnet を基盤としたエージェントは、ツールを持っていることを認識しています。ユーザーのクエリを解決するために知識や文脈を与えられます。
このエージェントはユーザーを支援します:いくつかの単純な検索プリミティブを駆使し、候補を検索して関連する結果を返すのです。厚くモノリス的な検索ではなく、基盤となる検索ツールはバックエンドインデックスに対する薄いラッパーとなります。

従来のスタックとは異なり、エージェントはプロセス全体を把握します。これは単なる段階的な縮小の連続ではありません。代わりに、モデルは利用可能なリソース(検索ツール、他のサブエージェント、またはユーザーを案内するためのナレッジベース)を活用して、ユーザーのための解決策をオーケストレーションします。
つまり、アジェンティック・サーチは検索スタックを構成要素ごとに分解するものです。各パーツはまだ重要ですが、全体を単一の知的なモデルが管理できるようになります。
GPT-5 は検索の本質を本当に理解していない
フロンティアラボのモデル(GPT-5、Sonnet など)は 80% のケースでは良好に機能します。彼らは一般的な知識を用いてクエリを理解し、防御可能な検索結果を提示します。
しかし、実際に成果を変えるのは残りの 20% です。
その最後の 20% に何が含まれているのでしょうか? それは、私たちのユーザーやドメインにおける非自明な要素です。GPT-5 は、家具店において「ビストロテーブル」と検索すると、レストラン用機器ではなく「小さな屋外テーブル」を意味することを知らないのです。また、ファッション検索のユーザーが複雑なパターンよりもダークまたはシンプルなパターンをクリックする傾向があることも知りません。
なぜでしょうか?GPT-5 自体も検索で訓練されているのではないですか?
はい、もちろんそうです。
GPT-5 やその仲間たちは、「検索」を*ウェブ検索*として捉えています。主要なモデルは、ほぼ完璧に動作する検索ツールを期待し、自分たちが持っていない答えを提供するためにそれらを利用します。残念ながら、私たちの検索は Google のようにはいきません。私たちはより小規模で焦点を絞ったチームで活動しており、狭いドメイン向けによりシンプルな検索バックエンドを構築しています。私たちが求めているのは、単純な検索システムを推論しオーケストレーションできるように訓練されたエージェントです。
現在、Cheat at Search with Agents で私が教えている通り、モデルの周囲に制約とチェックを組み合わせて構築しています。しかし、この集中的なコンテキストエンジニアリングはトークンを大量に消費し、コストが嵩みます。
最後の 20% を担うアジェンティック検索モデル
LLM を検索に特化して訓練することはできないでしょうか?さらに言えば、私たちのドメイン内、あるいは私たちのユーザーのために検索する LLM はどうでしょうか?
この方向性のモデルが現れ始めています。SID が最初に SID-1 モデル を発表しました。その後、Glean が Waldo のリリースを発表し、Charcoal などのスタートアップも 独自のコーパスに特化 しています。
これらの代替手段を推進するチームは、文書*検索*に特化した訓練を行うことでアピールしています。彼らは有用な結果を見つけるために必要な最後の 20% に焦点を当てています。例えば Sid は、アジェンティック検索において GPT-5 と比較して より小型でレイテンシが低い 点を挙げています。
その帰結について考えてみましょう。私は以前、複雑なクエリと再ランク付けパイプラインを構築しない未来について説明しました。代わりにエージェントが単純な検索プリミティブをオーケストレーションします。基本的なキーワード検索や埋め込みモデルに数個のフィルターを加える程度です。これらは基本であり、スケーラブルでシンプルな検索ツールとなります。
次に、SID-1 のようなエージェント型検索モデルをデプロイします。このモデルは、私たちのドメインにおいて何が関連性があるかを理解しており、ユーザーを獲得します。そして、関連する検索結果を見つけるためにツールをオーケストレーションできるようになります。現在、確かに焦点は RAG(Retrieval-Augmented Generation)と古典的なパッセージ検索(つまりチャンク単位)から始まりますが、これは間違いなく、e コマースから求人検索まで異なるドメインを対象とするモデルのファミリーへと拡大していくでしょう。
今日、Huggingface には金融、法律、e コマースをターゲットにした多数の埋め込みモデルが存在します。なぜエージェント型検索モデルも多数存在しないのでしょうか?ドメインに特化されたモデルです。
埋め込みは問題の一部(類似性)しか解決できませんが、エージェント型検索モデルは、クエリ理解からハイブリッド検索に至るまでのプロセス全体を包括できます。確かに現時点ではサイト検索を駆動するには遅すぎますが、これは今後数年で確実に変化していくでしょう。
私はこの未来に興奮しています。検索のあり方は根本的に異なるものになるはずです。
これらのトピックについて学びたい場合は、月曜日から開始する私の「Cheat at Search w/ Agents」クラスをチェックしてください。
エージェントを搜索に活用し、より優れた RAG を構築し、クエリ理解に LLM(大規模言語モデル)を使用する方法を学ぶために、Cheat at Search with Agents にぜひご参加ください。
原文を表示
In retrieval, we know the lego pieces well. Embeddings. Rerankers. Query understanding. BM25. All the parts we put together in the standard stack.
But a new power is rising: agentic search models. LLMs trained *specifically* on controlling the search task. Compared to GPT-5 and pals, these models might focus on tasks / domains. They can be smaller, faster, and easier to deploy in our search infrastructure.
Let’s set the stage.
With the traditional lego pieces, we build something like this thick search monolith:
That’s what we’ve built for 1-2 decades. Queries flow into the system. We apply business rules and classify queries. We search one or more retrieval backends. We post-process and rerank what comes back.
It’s all very manual, programmatic, and bespoke. Each piece doesn’t see the whole. Every piece focuses on its part of the problem (rerankers, query classifiers, etc) ignorant of the whole.
Agentic search orchestrates the pieces
Agentic search unbundles the pieces to see the whole. An agent built on GPT-5 or Sonnet knows it has tools. It’s given knowledge / context to solve the user’s query.
The agent helps the user: driving a few simple retrieval primitives, exploring candidates to return what’s relevant. Instead of thick, monolithic search, the underlying search tools become thin wrappers on our backend indices.
Unlike the traditional stack, the agent sees the whole process. It’s not a series of reductive steps. Instead the model orchestrates a solution for the user using what’s available - retrieval tools, other subagents, or a knowledge base to guide the user.
In other words, agentic search unbundles the retrieval stack. The parts still matter. But the whole can be managed by a single, intelligent model.
GPT-5 doesn’t really know search
Frontier lab models (GPT-5, Sonnet and pals) do well in the 80% case. They understand the queries with general knowledge. They surface defensible search results.
But it’s the last 20% that moves the needle.
What’s in the last 20%? It’s the non-obvious stuff in our users / domain. GPT-5 doesn’t know that in our furniture store a search for “bistro tables” actually means “small outdoor tables” not restaurant equipment. GPT-5 doesn’t know our fashion search users click on dark or plain patterns over complex ones.
Why not? Isn’t GPT-5 itself also trained on search?
Yes, of course.
GPT-5 and pals think of ‘search’ as *web search.* Mainline models expect search tools that work near flawlessly. To give them answers they don’t have. Unfortunately, our search isn’t Google. We work on smaller, focused teams: building simpler search backends for our narrow domains. We need agents trained to reason and orchestrate simpler retrieval systems.
Currently, as I teach in Cheat at Search with Agents, we build constraints + checks around the model. But this intense level of context engineering eats up tokens and costs $$.
Agentic search models for the last 20%
What if we could train an LLM to focus on search specifically? Even better: search in our domain, for our users?
We’re beginning to see models in this direction: SID was first with their SID-1 model. We’ve since seen Glean release Waldo. Startups like Charcoal tailor to your corpus.
Teams advertise these replacements by training on document *search* specifically - they focus on that last 20% needed to find useful results. Sid, for example, points to smaller size and lower latency compared to GPT-5 for agentic search.
Think about the implications. I’ve described a future where we don’t build complex query + reranking pipeline. Instead agents orchestrate simpler retrieval primitives. A basic keyword search or embedding model with a few filters. Basic, scalable, and simple retrieval tools.
Then we deploy an agentic search model like SID-1. It knows what’s relevant in our domain. It gets our users. Now it can orchestrate the tools to find relevant search results. Currently, sure, the focus begins with RAG and classic passage retrieval (ie chunks). That will surely expand to a family of models, targeting different domains from e-commerce to job search to ??.
Today we have scores of embedding models on huggingface, targeting financial, legal, e-commerce. Why wouldn’t we also have many agentic search models? Tuned to domains?
An embedding only solves a narrow portion of the problem (similarity). An agentic search model could encompass the entire process from query understanding to hybrid search. Yes they’re too slow today to drive site search. But that will surely change in the years ahead.
It’s a future I’m excited about. Search will look radically different.
If you want to learn about these topics, check out my Cheat at Search w/ Agents class starting Monday.
I hope you join me at Cheat at Search with Agents to learn use agents in search. build better RAG and use LLMs in query understanding.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み