ハンティントン銀行:AWS を活用し 4 億件超の文書から機密データを除去
Huntington National Bank は AWS の機械学習サービスを活用し、10 年間で蓄積された 4 億件以上の文書から機密データを抽出・隠す作業を数年かかる見込みから数ヶ月で完了させることに成功した。
キーポイント
大規模データ処理の劇的短縮
従来見積もりでは数年かかるとされていた、4 億件以上の文書からの機密情報抽出・隠去作業を、AWS のスケーラブルなワークフローにより数ヶ月で完了させた。
厳格なコンプライアンスとセキュリティ要件の達成
PCI DSS 準拠サービスの利用、転送・保存中の暗号化、オンプレミスへのデータ返却など、金融機関特有の厳しい要件をすべて満たすアーキテクチャを構築した。
多様なフォーマットへの対応と高精度
異なるファイル形式に対応し、95% 以上の精度で機密データを検出・隠去する自動化ワークフローを実現し、コンプライアンス要件をクリアした。
影響分析・編集コメントを表示
影響分析
この事例は、金融業界のような高規制環境において、大規模な非構造化データを迅速かつ正確に処理する際のクラウドネイティブ・AI アーキテクチャの有効性を証明した画期的なケーススタディです。特に、オンプレミス資産を維持しつつクラウドの計算リソースを活用するハイブリッドアプローチは、多くの企業が直面しているデータ移行とコンプライアンス課題に対する具体的な解決策として示唆に富んでいます。
編集コメント
数年かかるはずのプロジェクトを数ヶ月で完了させた事例は、AI/ML の実装におけるROI(投資対効果)を示す非常に説得力のあるデータです。特に金融機関のような厳格なセキュリティ要件下での成功事例は、他業界への展開可能性も示唆しています。
ドキュメントリポジトリにほぼ10年間にわたって蓄積された数億ファイルが含まれている場合、数年を要することなく体系的に機密顧客データを見つけ、隠蔽する方法はありますか?これが、米国トップ10銀行の一つであるThe Huntington National Bank(Huntington)が直面した課題でした。
スケールする機密情報の隠蔽
2015年以来、Huntingtonのドキュメント管理システムは、オンプレミスで数億件のドキュメントを安全に保管してきました。2025年、積極的なコンプライアンスイニシアチブの一環として、Huntingtonはこのシステムのドキュメントを処理し、機密データを隠蔽する取り組みを開始しました。これらのドキュメントは異なる形式であるため、ソリューションには多様なファイルタイプを処理できる柔軟性と、数百万件のドキュメントを迅速に処理するために必要なスループットが必要でした。
当初の見積もりではこの作業に数年かかると示されていましたが、Amazon Textract、Amazon SageMaker、AWS Step Functions、およびAWS Lambdaを用いてスケーラブルな隠蔽ワークフローを設計したことで、Huntingtonはこの期間を数ヶ月に短縮しました。
ソリューションの概要
技術的な実装を検討する前に、このプロジェクトのためにハンティントン銀行が設定したコア要件を見てみましょう。同様の大規模なドキュメント処理課題に直面している場合、これらの要件は独自のソリューション設計のための出発点として機能します:
- データは保存時および転送時に暗号化されている必要があります。
- データが保存またはアクセスされる場所は、厳格なアクセス要件を満たす必要があります。
- 使用するサービスは PCI DSS コンプライアンスの範囲内である必要があります。
- 出力はオンプレミスのデータストアに複製して戻す必要があります。
- コンプライアンス要件を満たすために、赤文字化(情報隠蔽)の精度は 95% 以上である必要があります。
以下の図は、高レベルなソリューションアーキテクチャを示しています。
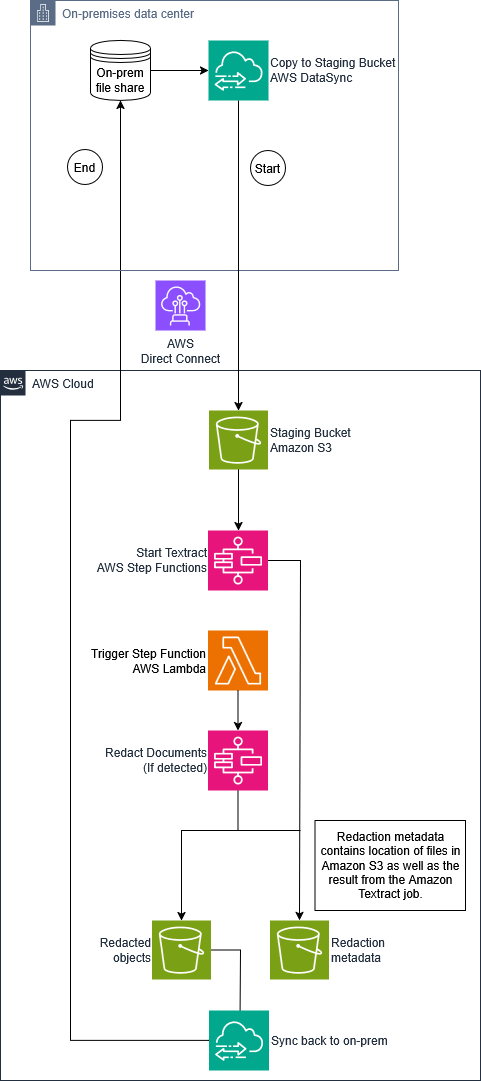
信頼を持ってデータを安全に移動する
ハンティントン銀行の最初の目標は、オンプレミスのファイル共有から Amazon Simple Storage Service(Amazon S3)バケットへドキュメントを移動することでした。ドキュメントの移動自体は単純ですが、この取り組みでは転送時に暗号化され、保存時にも暗号化された 4 億件以上のドキュメントを転送する必要がありました。これを実現するために、ハンティントン銀行は AWS DataSync、AWS Direct Connect、Amazon S3、および AWS Key Management Service(AWS KMS)を使用しました。
AWS DataSync は、オンプレミスのデータセンターにエージェントとしてデプロイして、構成されたソース(SMB ファイル共有など)を監視できます。ドキュメントを AWS へ転送して処理することは重要でしたが、このプロジェクトのもう一つの重要な要件であるように、AWS DataSync はデータをオンプレミスへ同期する機能もサポートしています。
Amazon Textract を用いた機密データの検出
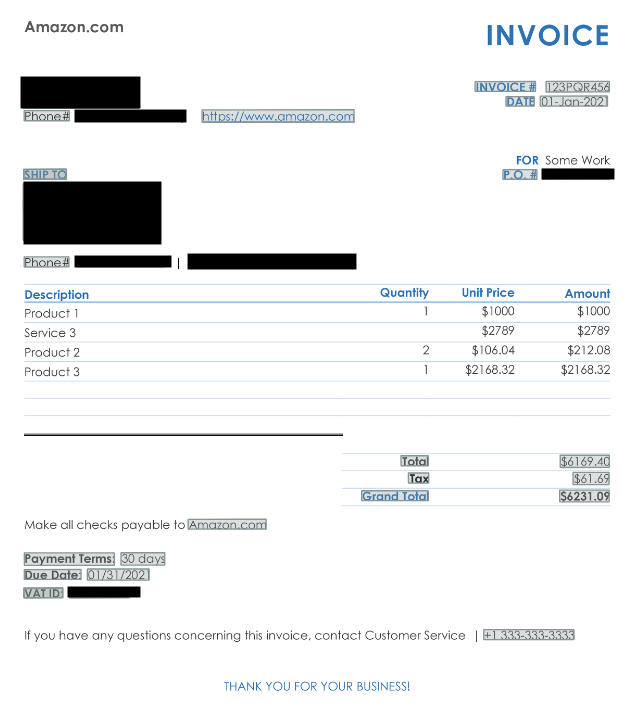
Amazon Textract は、スキャンされたドキュメントからテキスト、表、フォームを抽出する AWS の機械学習サービスです。金融機関は、口座明細書やローン申請書などのドキュメントを自動的に処理し、社会保障番号、口座番号、個人住所といった機密データを特定するためにこれを利用しています。以下のサンプル請求書はこの機能をデモンストレーションしたものです。

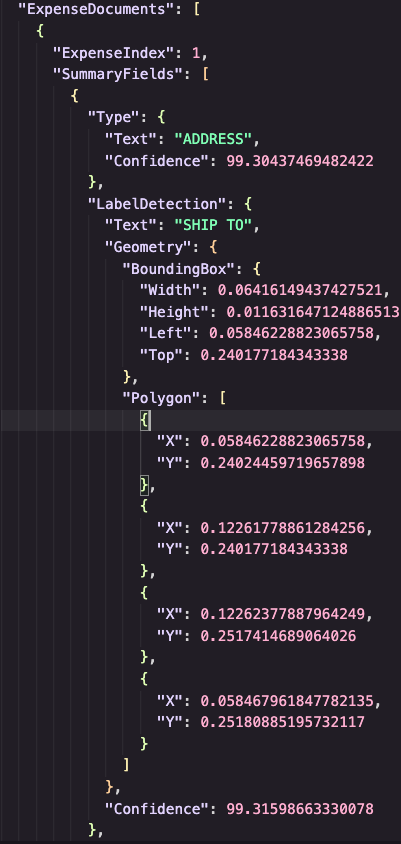
Amazon Textract はドキュメントからさまざまなフィールドを検出し、検出されたフィールドの座標やその他のメタデータを JSON 出力として提供します。
Huntington は、AWS Step Functions と連携したオーケストレーションプロセスで Amazon Textract を使用しました。このアプローチにより、大規模なドキュメント量にわたる機密情報の検出精度が向上すると同時に、手動レビューにかける時間を削減できました。
検出スループットの拡張
文書処理のための自動化パイプラインは価値がありますが、文書を順次処理していた場合、プロジェクトの完了までに数年を要するところでした。目標を達成するために、Huntington は毎日数百万件の文書を処理する必要がありました。
このレベルへのスケールには、主に 2 つの考慮事項に対処することが必要でした:サービスクォータ内で並行して実行できる Amazon Textract ジョブ数を最大化すること、およびスロットリングを回避するためにリクエストレートを制御することです。
AWS サービスには クォータ があり、ソフト制限とハード制限を通じて調整可能です。Amazon Textract の 1 秒あたりのジョブ数に関するクォータは、AWS Service Quotas コンソールを介してリクエストを送信することで増やすことができます。
スループットをサービスクォータに対して最大化するために、Huntington は AWS Step Functions の組み込み map state を使用しました。これは JSON、CSV、またはその他の形式のインプットのコレクションを処理する機能です。チームは Amazon S3 内のドキュメントを JSON コレクションとして整理し、より高い並行性を確保するために distributed mode で map state を実行しました。パイプラインの進捗を追跡するためには、AWS Step Functions の map run execution summaries と Amazon CloudWatch ダッシュボードを併用し、応答時間、スロットリング回数、成功数、エラー率を監視しました。
潜在的なスロットリングへの対応として、Huntington は CloudWatch ダッシュボードを監視して Amazon Textract によるリクエストの成功数とスロットリング回数を検証しました。必要に応じて、子ワークフロー実行の並行性制限を調整し、高いスループットを維持しつつ Amazon Textract のサービスクォータを下回ることを確認しました。ジョブが正常に完了すると、検出されたフィールドとメタデータは後日のレビュー用にバケットに書き込まれます。以下の図はこのアプローチを示しています:
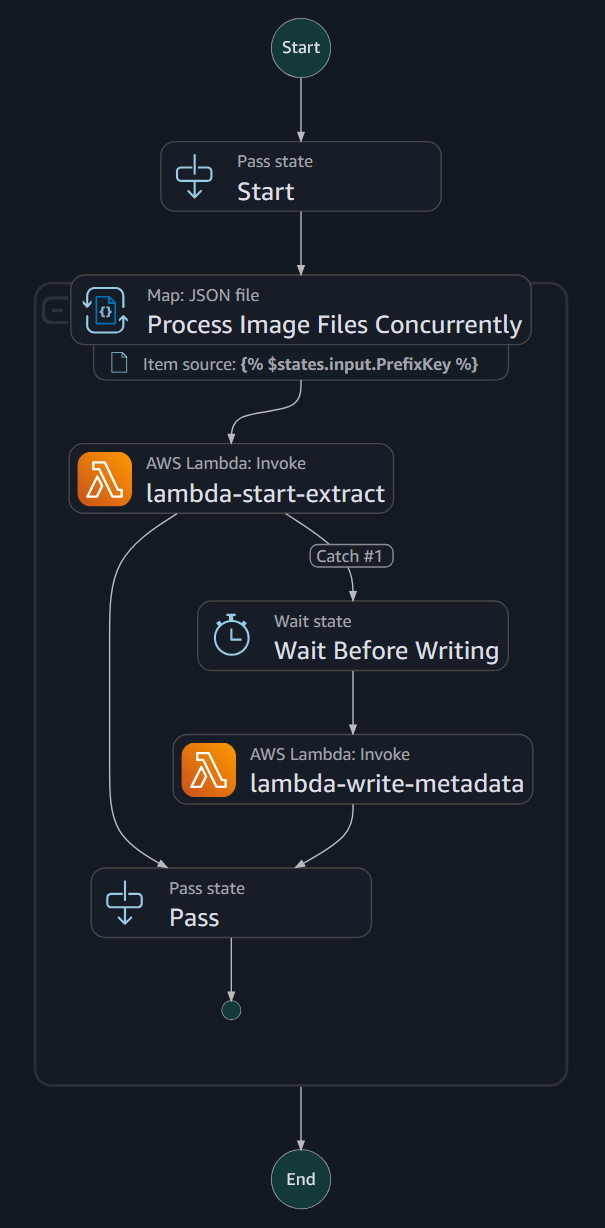
ステップ関数内の待機ブロックは、ジョブメタデータの書き込みと次の Amazon Textract 呼び出しの継続に進む準備ができたことを確認しました。失敗がない場合、状態機械は合格状態で終了します。失敗が発生した場合、AWS Step Functions は人間のレビューと再処理のためにログに記録します。
検出された機密情報の削除
これまでのプロセスは、Amazon S3 に書き込まれたメタデータファイル内で機密データの検出とカタログ化に焦点を当てていました。最終ステップは、ドキュメントの削除(redaction)とオンプレミスストレージへの送信です。
画像および PDF の削除は、いくつかのオープンソースおよびプロプライエタリなツールによってサポートされています。一般的なオープンソースの Python ライブラリには、PyMuPDF や PIL などの画像描画ライブラリが含まれます。以下の図は、前述の請求書のサンプル削除を示しています。Amazon Textract はさまざまなフィールドの検出をサポートしており、正規表現パターンを使用してカスタム分類も作成できます。削除ソフトウェアと組み合わせることで、検出されたフィールドを確信を持って削除できます。人間の介入のための閾値を作成したい場合、Amazon Textract は検証ワークフローをトリガーできる信頼度スコアを提供しています。
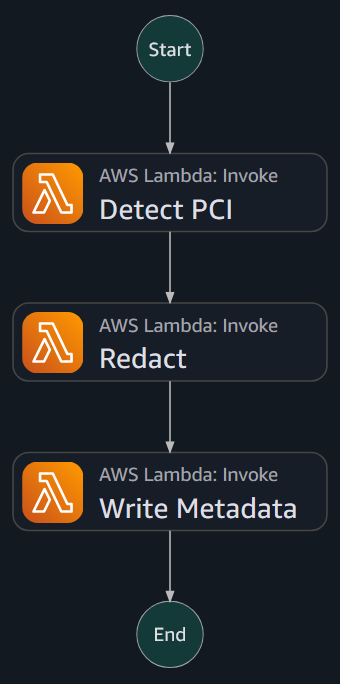
再び、ハンティントン銀行は同じアーキテクチャ上の課題に直面しました:どのようにしてこのスケーラビリティを実現するかです。AWS Step Functions が数百万のドキュメントを処理するための解決策を提供し、エラーハンドリングやリトライロジックのためのフックも用意されました。ドキュメント処理パイプラインが赤塗り(redaction)が必要なオブジェクトをカタログ化する際、ハンティントン銀行はそれらに対して単純なフローを実行しました。
精度と完全性を検証するため、ハンティントン銀行は赤塗りを実行する前に検出されたフィールドが期待されるパターンに一致していることを二重確認し、その後各ファイルのメタデータを更新しました。赤塗り済みのファイルは、AWS DataSync によって監視され、オンプレミスのファイルストレージへ転送される Amazon S3 の場所に配置されました。
結論
AWS を使用することで、ハンティントン銀行は1日あたり約1000万件のドキュメントを処理し、推定処理時間を数年から数ヶ月に短縮しました。ドキュメントリポジトリ全体を処理するコストは、当初の見積もりの約5%でした。赤塗り(redaction)の精度は95%を超え、コンプライアンス要件を満たし、データセキュリティの目標を達成しました。
このプロジェクトは、AWS サービスが大規模なデータ処理とコンプライアンスイニシアチブをどのように支援できるかを示しています。ハンティントン銀行は、合併・買収(M&A)などの高ボリュームな赤塗りニーズに対して引き続きこのフレームワークを使用する計画です。
このソリューションで使用されているサービスについて詳しく知りたい場合は、Amazon Textract の詳細ページをご覧ください。または、AWS Step Functions ドキュメント を探索してください。
謝辞
貢献いただいた以下の個人およびチームに心より感謝いたします:Xuelei Yuan, Robert Carnell, Jeanne Keith, Debbie Montgomery, Bill Gross, Jodi Pettiford, Jon Glazer, Marshall Doss, Bob Wojasinski, Tami Wolf, Marijane Eldridge, Pradeep Kumar Tata, Michael Burkhardt, Nirmal Antony, Trevor Pease, Bryan Griffith, Angus Ferguson (AWS), Randy Patrick (AWS), Stephanie Brenneman (AWS), Art Steele, Kevin Owen.
著者について

Rob Carnell
Rob は Huntington 社のエンタープライズデータおよびアナリティクスディレクターであり、AI、モデリング、キャンペーンテストとデザイン、インサイト、デジタル分野にまたがるクロスファンクショナルチームを統括し、統合ソリューションの推進とビジネスへの影響実現を担っています。

Timothy Gorman
Timothy は、Huntington National Bank で自動化および非構造化データ処理を専門とするリード AI エンジニアです。オハイオ州立大学で物理学の博士号を取得しており、原子物理学、レーザー工学、金融分野における AI 駆動型自動化など、多岐にわたる分野で経験があります。

Bobby Lumpkin
Bobby は、Huntington National Bank で AI/ML エンジニアとして勤務しており、金融サービスにおける人工知能(AI)、機械学習(ML)、および高度な統計手法を専門としています。数学の学士号に加え、数学、数理科学、応用統計学のそれぞれで修士号を 3 つ取得しています。

Xuelei Yuan
Xuelei は Huntington でデータサイエンスディレクターを務め、クラウド技術によって支えられたスケーラブルで本番環境対応可能なソリューションに焦点を当てた AI および機械学習のイニシアチブを率いています。

Ryan Doty
Ryan はニューヨークを拠点とする Amazon Web Services (AWS) のソリューションアーキテクトマネージャーです。彼は、革新的でスケーラブルなソリューションを設計するためのアーキテクチャガイドラインを提供することで、金融サービス業界のお客様が AWS クラウドの採用を加速できるよう支援しています。ソフトウェア開発とセールスエンジニアリングのバックグラウンドを持つ Ryan は、クラウドが世界にもたらす可能性に興奮を感じています。

Angus Ferguson
Angus は 2022 年から AWS の北米金融サービス業界チームに所属するシニアソリューションアーキテクトです。彼の役割では、ビジネス目標を技術的なビジョンへと変換し、お客様がクラウド上で成長と革新を実現できるよう支援しています。AWS 以外でも、ハッカソンなどの大規模イベントを通じて学生の情熱を育むことに情熱を持っており、そこで次世代のアメリカ人コンピュータエンジニアのメンターを務めています。

ランディ・パトリック
ランディは、AWS の北米金融サービス業界チームに所属するシニア・テクニカルアカウントマネージャーです。21 年にわたる IT 経験とサイバーセキュリティへの注力を持ち、厳格なコンプライアンスおよびデータ保護要件を満たす、安全でレジリエントなアーキテクチャを構築するようエンタープライズ顧客をサポートしています。
原文を表示
When your document repository contains hundreds of millions of files accumulated over nearly a decade, how do you systematically find and redact sensitive customer data without taking years to complete? This was the challenge facing The Huntington National Bank (Huntington), a top 10 bank in the United States.
Redacting sensitive information at scale
Since 2015, Huntington’s document management system has securely stored hundreds of millions of documents on-premises. In 2025, as part of a proactive compliance initiative, Huntington set out to process the documents in this system and redact sensitive data. These documents come in different formats, so the solution needed flexibility to handle varied file types while delivering the throughput required to process millions of documents quickly.
Original estimates indicated this effort would take years. However, by designing a scalable redaction workflow using Amazon Textract, Amazon SageMaker, AWS Step Functions, and AWS Lambda, Huntington reduced this timeline to months.
Solution overview
Before examining the technical implementation, let’s look at the core requirements Huntington established for this project. If you’re facing a similar large-scale document processing challenge, these requirements can serve as a starting point for your own solution design:
- Data must be encrypted at rest and in transit.
- Locations where data is stored or accessed must meet strict access requirements.
- Services used must be in-scope for PCI DSS compliance.
- Outputs must be replicated back to on-premises data stores.
- Redaction accuracy must meet or exceed 95% to meet compliance requirements.
The following diagram illustrates the high-level solution architecture.
Moving data securely, with confidence
Huntington’s first objective was to move documents from an on-premises file share to an Amazon Simple Storage Service (Amazon S3) bucket. Moving documents is straightforward, but this effort required transferring over 400 million documents, encrypted in transit and at rest. To accomplish this, Huntington used AWS DataSync, AWS Direct Connect, Amazon S3, and AWS Key Management Service (AWS KMS).
AWS DataSync can be deployed as an agent in your on-premises data center to monitor a configured source, such as an SMB file share. While getting documents to AWS was critical for processing, AWS DataSync also supports syncing data back to on-premises, which was another key requirement for this project.
Detecting sensitive data using Amazon Textract
Amazon Textract is an AWS machine learning service that extracts text, tables, and forms from scanned documents. Financial institutions use it to automatically process documents like account statements or loan applications, then identify sensitive data such as Social Security numbers, account numbers, and personal addresses. The following sample invoice demonstrates this capability.
Amazon Textract detects various fields from a document and provides coordinates of detected fields and other metadata within a JSON output.
Huntington used Amazon Textract in an orchestrated process with AWS Step Functions. This approach reduced manual review time while improving accuracy in detecting sensitive information across large document volumes.
Scaling detection throughput
Automated pipelines for document processing are valuable, but processing documents sequentially would have extended the project timeline to years. To meet their goal, Huntington needed to process millions of documents each day.
Scaling to this level required addressing two main considerations: maximizing concurrent Amazon Textract jobs within service quotas, and controlling request rates to avoid throttling.
AWS services have quotas that can be adjusted through soft and hard limits. The Amazon Textract jobs-per-second quota can be increased by submitting a request through the AWS Service Quotas console.
To maximize throughput against the service quota, Huntington used the AWS Step Functions built-in map state, which processes collections of inputs in JSON, CSV, or other formats. The team organized documents in Amazon S3 into a JSON collection and ran the map state in distributed mode for higher concurrency. To track pipeline progress, they used AWS Step Functions map run execution summaries alongside Amazon CloudWatch dashboards to monitor response times, throttle counts, successes, and error rates.
To address potential throttling, Huntington monitored their CloudWatch dashboard to verify Amazon Textract successful request counts and throttled counts. As needed, they adjusted concurrency limits for child workflow executions to confirm they remained under the Amazon Textract service quota while maintaining high throughput. When jobs completed successfully, detected fields and metadata were written to a bucket for later review. The following diagram depicts this approach:
The wait block within the step function verified the process was ready to proceed with writing job metadata and continuing with the next Amazon Textract invocation. When there are no failures, the state machine finishes with a pass state. When failures occur, AWS Step Functions writes to a log for human review and reprocessing.
Redacting detected sensitive information
Up to this point, the process focused on detecting sensitive data and cataloging it within metadata files written to Amazon S3. The final steps are to redact the documents and transmit them back to on-premises storage.
Image and PDF redaction is supported by several open-source and proprietary tools. Common open-source Python libraries include PyMuPDF or image drawing libraries like PIL. The following figure shows a sample redaction of the invoice shown earlier. Amazon Textract supports detection of various fields, and you can also create custom classifications using regex patterns. Combined with redaction software, you can confidently redact detected fields. If you want to create a threshold for human intervention, Amazon Textract provides confidence scores that can trigger validation workflows.
Once again, Huntington faced the same architectural challenge: how would this scale? AWS Step Functions provided the solution for processing millions of documents while offering hooks for error handling and retry logic. As the document processing pipeline cataloged objects requiring redaction, Huntington ran a simple flow against them:
To verify accuracy and thoroughness, Huntington double-checked that detected fields matched expected patterns prior to redaction, followed by a metadata update for each file. Redacted files were placed in an Amazon S3 location monitored by AWS DataSync for transmission back to on-premises file storage.
Conclusion
Using AWS, Huntington processed documents at a rate of approximately 10 million per day, reducing estimated processing time from years to just a few months. The cost of processing the entire document repository was approximately 5% of the original estimate. Redaction accuracy exceeded 95%, meeting compliance requirements and supporting data security objectives.
This project demonstrates how AWS services can support large-scale data processing and compliance initiatives. Huntington plans to continue using this framework for high-volume redaction needs such as mergers and acquisitions.
To learn more about the services used in this solution, visit the Amazon Textract detail page or explore the AWS Step Functions documentation.
Acknowledgements
Special thanks to the following individuals and teams for their contributions: Xuelei Yuan, Robert Carnell, Jeanne Keith, Debbie Montgomery, Bill Gross, Jodi Pettiford, Jon Glazer, Marshall Doss, Bob Wojasinski, Tami Wolf, Marijane Eldridge, Pradeep Kumar Tata, Michael Burkhardt, Nirmal Antony, Trevor Pease, Bryan Griffith, Angus Ferguson (AWS) Randy Patrick (AWS), Stephanie Brenneman (AWS), Art Steele, Kevin Owen.
About the authors
Rob Carnell
Rob is the Enterprise Data and Analytics Director at Huntington, overseeing cross-functional teams across AI, modeling, campaign testing and design, insights, and digital to drive integrated solutions and business impact.
Timothy Gorman
Timothy is a Lead AI Engineer at Huntington National Bank specializing in automation and unstructured data processing. He holds a doctorate in physics from The Ohio State University and has worked across disciplines including atomic physics, laser engineering, and AI-driven automation in finance.
Bobby Lumpkin
Bobby is an AI/ML Engineer at Huntington National Bank, specializing in artificial intelligence, machine learning, and advanced statistical methods in financial services. He holds a bachelor’s degree in mathematics and three master’s degrees in mathematics, mathematical sciences, and applied statistics, respectively.
Xuelei Yuan
Xuelei is a Data Science Director at Huntington, where she leads AI and machine learning initiatives, focusing on scalable, production-ready solutions powered by cloud technologies.
Ryan Doty
Ryan is a Solutions Architect Manager at Amazon Web Services (AWS), based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
Angus Ferguson
Angus is a Senior Solutions Architect with the North American Financial Service Industry team at AWS since 2022. In his role, Angus helps his customers to translate business objectives into a technical vision, enabling them to grow and innovate in the cloud. Outside of AWS, Angus also has a passion for cultivating student’s passions through large events, such as hackathons, where he gets to mentor America’s next generation of computer engineers.
Randy Patrick
Randy is a Senior Technical Account Manager with the North American Financial Services Industry team at AWS. With 21 years of IT experience and a focus on cybersecurity, Randy helps enterprise customers build secure, resilient architectures that meet rigorous compliance and data protection requirements.
関連記事
Mistral OCR 4:文書知能のための最先端 OCR ツール(9 分読了)
Mistral は、170 か国語に対応し、エンタープライズ検索や構造化データパイプラインに統合可能な文書知能ツール「OCR 4」をリリースした。同ツールは単一コンテナで展開可能であり、低リソース言語を含む高精度な抽出と他システムより 4 倍の高速処理を実現している。
Unlimited OCR Works(GitHub リポジトリ)
DeepSeek OCR をベースに定数 KV キャッシュ設計を組み合わせ、人間の作業記憶を模倣する「Unlimited OCR」モデルが開発された。この技術により、32K の最大長制限下で数十ページの文書を単一の順次処理で転写可能となり、音声認識や翻訳タスクにも応用できる。
Amazon Nova 2 Sonic を活用した医療予約エージェントの構築方法
AWS は、米国医療機関で問題となる欠席率の高さに対応するため、Amazon Nova 2 Sonic を使用して患者の予約確認や再調整を行う自動エージェントを構築する手法を公開しました。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み