最速・最大・最強:NVIDIA Blackwell が MLPerf Training 6.0 で圧勝
NVIDIA の Blackwell プラットフォームが MLPerf Training 6.0 で全カテゴリを制し、特に MoE アーキテクチャの採用と 8192 GPU を用いた大規模トレーニングで業界新記録を樹立した。
キーポイント
MLPerf Training 6.0 における完全勝利
NVIDIA Blackwell は、7 つあるすべてのベンチマークで最速のトレーニング時間を達成し、かつ全カテゴリへの提出を行った唯一のプラットフォームとなった。
MoE アーキテクチャへの対応強化
今回の評価基準に DeepSeek-V3 671B や GPT-OSS-20B といった新しい混合専門家(MoE)事前学習ワークロードが追加されたが、Blackwell はこれらにも最適化され最速を記録した。
8,192 GPU を用いた最大規模トレーニング
NVIDIA Blackwell NVL72 システムを活用し、過去最大の 8,192 個の GPU を使用した大規模トレーニングを成功させ、インフラのスケーラビリティと信頼性を証明した。
コスト削減と収益化の加速
極限までのコードデザインにより、最前線のモデル構築を迅速化し、トレーニングコストを最小化して早期の収益生成を可能にするプラットフォームとしての地位を確立した。
影響分析・編集コメントを表示
影響分析
この結果は、NVIDIA の Blackwell アーキテクチャが次世代の大規模言語モデル(LLM)および MoE 構造の実装において事実上の標準インフラとして確立されたことを示しています。特に数千 GPU を超えるスケールでの安定稼働と高速化は、AI 開発のボトルネックとなっていた計算リソースとコストの問題を解決し、業界全体でより大規模かつ複雑なモデルの開発競争が加速する契機となります。
編集コメント
MLPerf の最新結果は、単なるベンチマークのスコア比較を超え、MoE アーキテクチャが主流化する中で、NVIDIA がそのインフラ要件を完全に支配していることを如実に示しています。特に 8000 GPU を超えるクラスターでの安定動作は、次世代 AI の開発におけるハードウェア選定の決定的な要素となるでしょう。
すべての画期的な AI モデルは同じ方法から始まります:トレーニング実行です。そのトレーニングジョブを実行するインフラストラクチャが、チームの反復速度、構築できるモデルのスケーラビリティ、そしてジョブが確実に完了するかどうかというすべてを形作ります。
モデルが大きくなり、複雑さや知能が増すにつれて、トレーニングインフラに対する要求も高まっています。
MLPerf Training 6.0 — AI トレーニング性能を評価するための厳格なピアレビュー付き業界ベンチマークのシリーズにおける最新のもの — では、NVIDIA Blackwell プラットフォームがすべてのカテゴリで首位に立ち、以下を実証しました:
- すべてのベンチマークにおいて最速のトレーニング時間
- NVIDIA Blackwell NVL72 システムを使用した 8,192 GPU を用いた最大規模のトレーニング
- スイート内の 7 つのすべてのベンチマークで提出を行った唯一のプラットフォーム
NVIDIA は、パフォーマンス、スケーラビリティ、信頼性を単一のプラットフォームに統合しました。これは極限までのコードサインを通じて設計され、AI モデルビルダーが最先端モデルをより迅速に立ち上げ、トレーニングコストを最小化し、早期に収益創出を開始できるように支援します。
パフォーマンス:すべてのベンチマークで最速のトレーニング時間
MLPerf Training 6.0 では、スイートに 2 つの新しい エキスパート混合 (MoE) プリートレーニングワークロードが追加されました:DeepSeek-V3 671B と GPT-OSS-20B です。これは、MoE アーキテクチャの中心的な役割が増大していることを反映しています。NVIDIA プラットフォームはすべてのベンチマークで提出された唯一のものであり、7 つすべてにおいて最速のトレーニング時間を達成しました。

今回のラウンドでは、NVIDIA は NVIDIA GB200 NVL72 および GB300 NVL72 ラックスケールシステム両方において結果を提出しました。各ラックスケールシステム内では、第 5 世代の NVIDIA NVLink スイッチがすべての 72 個の GPU を高帯域で接続し、計算とメモリを統合されたプールとして機能させ、あたかも巨大な 1 つの GPU のように動作できるようにしています。
大規模な MoE(Mixture of Experts:エキスパート混合モデル)トレーニングは、MoE インファレンス と同じくオール・トゥー・オール通信の課題に直面しており、トークンを GPU 間でルーティングして適切なエキスパートサブネットワークへ到達させる必要がありますが、NVLLink の帯域幅の優位性が、スケールしても高速かつ効率的な処理を可能にしています。
また、NVIDIA は NVFP4 トレーニング手法も披露しました。これは、大規模および小規模な事前トレーニング、さらにはファインチューニングワークロードにおいて、厳格な精度要件を満たしつつ性能を向上させるものです。NVIDIA は引き続き、異なるモデルアーキテクチャ全体で低精度トレーニングの革新を推進しており、最近では NVFP4 を用いて、5,500 億パラメータという巨大な NVIDIA Nemotron 3 Ultra モデルの事前トレーニングを行いました。
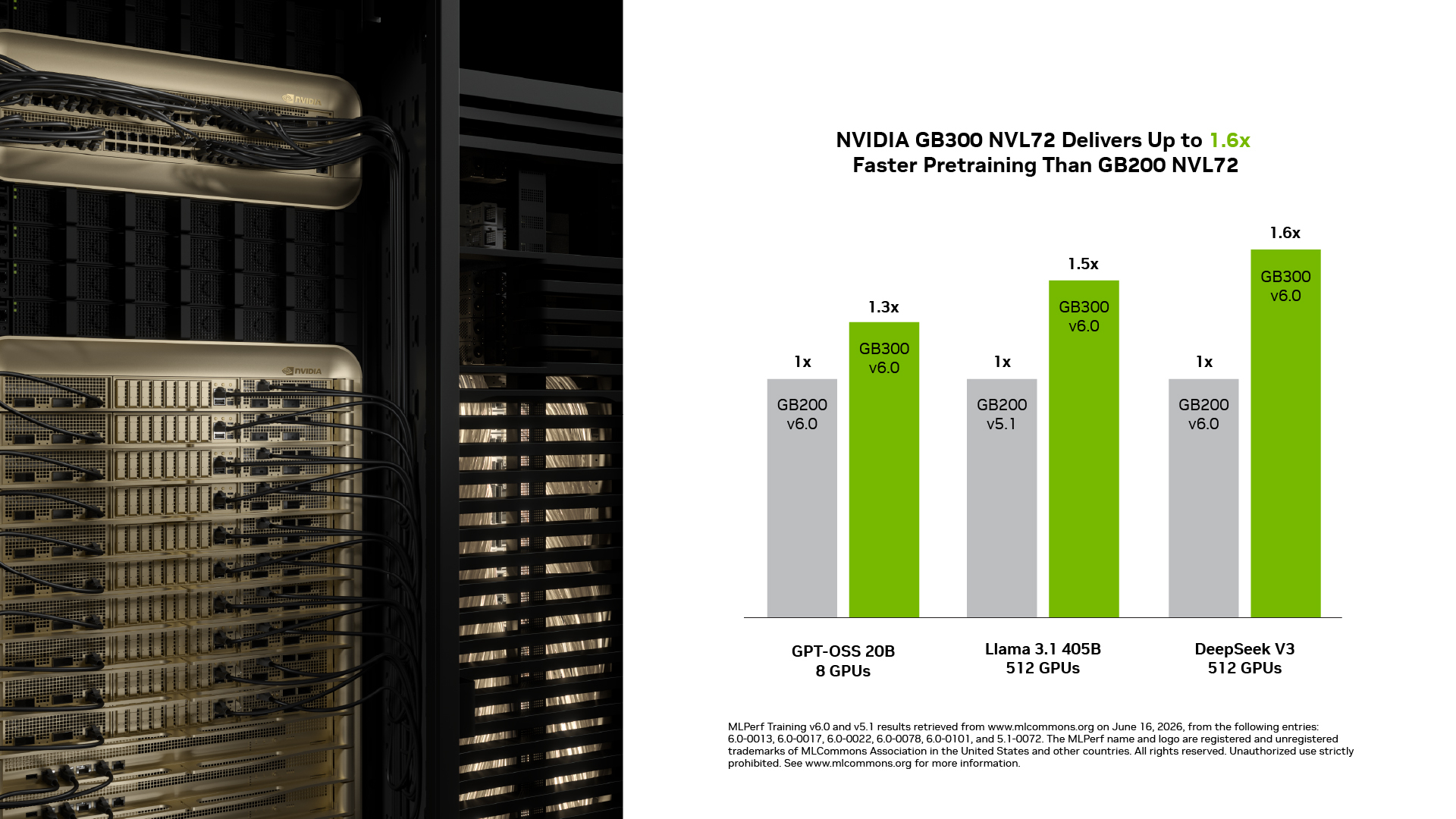
NVIDIA GB300 NVL72 が GB200 NVL72 に対して最大 1.6 倍の性能を達成: このラウンドにおいて、GB300 NVL72 は同じ規模で GB200 NVL72 よりも最大 1.6 倍高速なトレーニングを実現しました。NVIDIAFP4(NVFP4)による高い計算密度、拡張されたメモリ容量、そして GPU がピークパフォーマンスを維持できるより高い電力上限といった、Blackwell Ultra の主要機能がこの改善を牽引しています。
スケール: MLPerf トレーニングにおける最大規模の Blackwell クラスター
大規模な分散トレーニングをサポートするため、NVIDIA は 2 つの補完的なスケールアウト・ネットワークプラットフォームを提供しています。NVIDIA Quantum InfiniBand と NVIDIA Spectrum-X Ethernet です。これにより、データセンターは自社のインフラに最適化された大規模クラスターを構築する柔軟性を得られます。
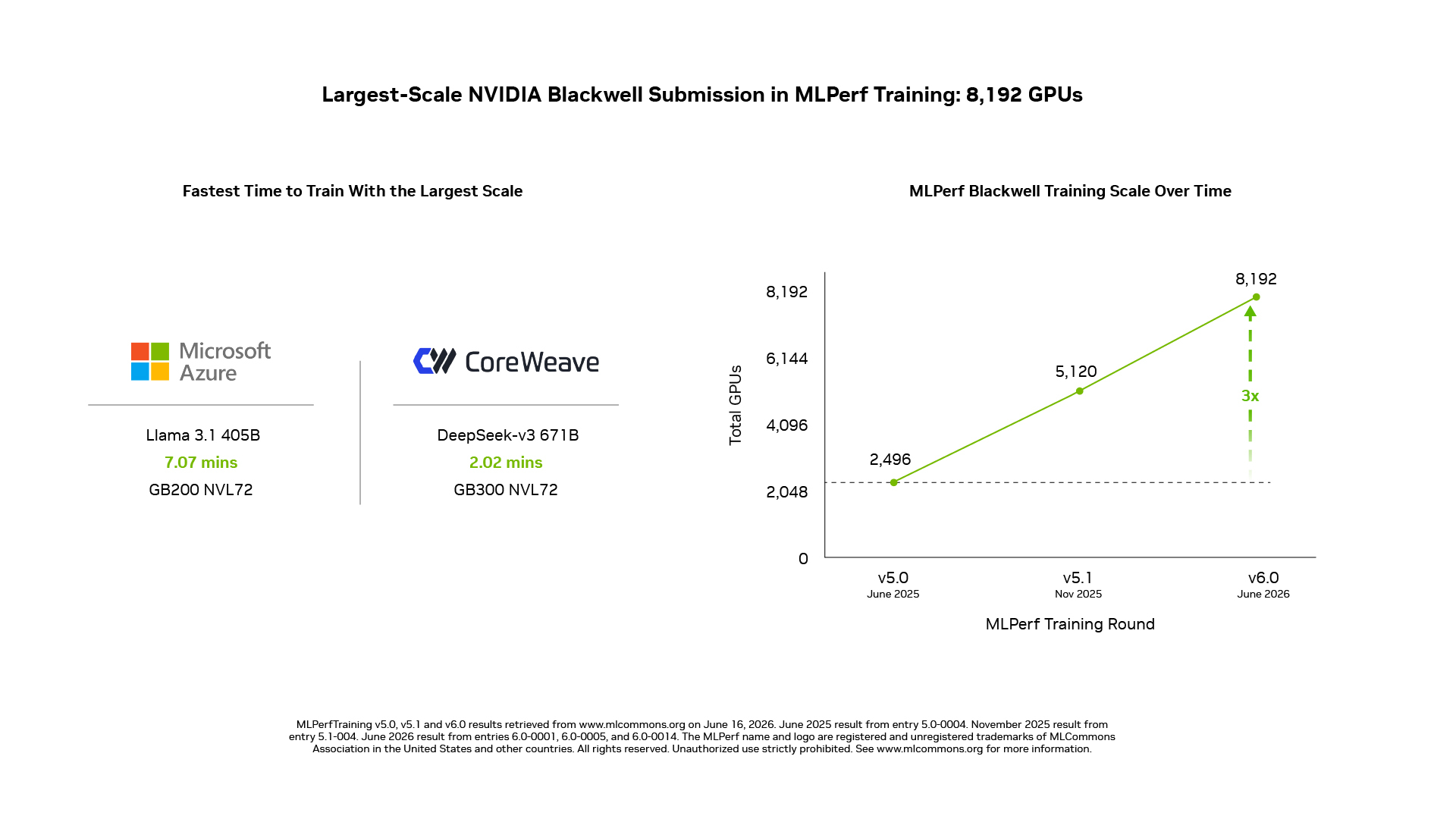
スイート内で最大の MoE モデルである DeepSeek-V3 671B では、NVIDIA は GB200 NVL72 システムを使用して 8,192 個の GPU を用いた提出を行いました。これは MLPerf トレーニングにおいてこれまでに発表された中で最大規模の Blackwell ベースの提出です。
また、スイート内で最大の密集型大規模言語モデル(LLM)の一つである Llama 3.1 405B においても、NVIDIA は NVIDIA GB200 NVL72 システムを使用して 5,120 個の GPU で結果を提出しました。
今回の結果は、システムアーキテクチャ、ネットワーク、ソフトウェアにおける NVIDIA とそのパートナーとの深い共同設計の成果も反映しています:
- Microsoft Azure は GB200 NVL72 システムを用いて 8,192 個の GPU で Llama 3.1 405B のトレーニングをスケーリングし、7.07 分でリファレンス品質目標に到達しました。これはこのベンチマークにおける最速のトレーニング時間です。
- CoreWeave は Spectrum-X Ethernet ネットワークで接続された GB300 NVL72 システムを用いて 8,192 個の GPU スケールで DeepSeek-V3 671B のトレーニングを行い、2.02 分で品質目標に到達しました。これが最速のトレーニング時間です。
大規模信頼性:本番向けに設計
本番環境でのトレーニングでは、数百数千の GPU にまたわり数週間から数ヶ月にわたる実行が行われることもあります。そのようなスケールにおいて、効果的なトレーニングスループットは、システムの性能と、時間をかけて再現性を可能にするレジリエンス(耐障害性)の両方に依存します。
上記の MLPerf Training v6.0 の結果は、NVIDIA プラットフォームの性能を示すものです。一方、レジリエンスについては、NVIDIA のプラットフォームが 2 つの次元にわたって設計されています:
- 中断の減少:NVIDIA GPU は、故障が発生する前にそれを回避するように設計されています。GPU がデータセンターに配備される前には、潜在的な欠陥を早期に検出するために、30 以上の製造工程におけるテスト段階で NVIDIA によってスクリーニングされます。一度配備されると、信頼性・可用性・保守性エンジン(Reliability, Availability and Serviceability Engine)がチップのほぼ全体を監視し、自己修復機能により検出された故障を自動的に迂回してワークロードの中断を防ぎます。ネットワークレベルでは、Spectrum-X Ethernet が失敗したリンクをミリ秒単位で迂回し、ジョブを妨害することなくファブリックを健全に保ちます。
- 中断発生時の迅速な回復:NVIDIA Resiliency Extension(NVRx)は、故障が発生した場合の損失時間を最小限に抑え、クラスタ全体にわたる故障検出、回復、ヘルスモニタリングの機能を備えています。パフォーマンスが低下しているノードを、他のノードの速度を低下させる前に自動的に検出して管理します。あるノードで中断が発生した際、システムはジョブ全体を再起動するのではなく、直近のチェックポイント(トレーニング状態のスナップショット)から再開します。
NVIDIA を基盤とした Frontier AI
NVIDIA エコシステムのパートナーもまた、このラウンドに広く参加し、ASUSTeK、Microsoft Azure、Cisco、CoreWeave、Dell Technologies、富士通、Giga Computing、Google Cloud、Hewlett Packard Enterprise、Inventec、Krai、Lambda、Nebius、Netweb Technologies India Ltd.、Quanta Cloud Computing (QCT)、ScitiX、Supermicro、TTA の 19 組織から魅力的な提出がありました。これらのパートナーの多くは、NVIDIA インフラ上で最も要求の高い AI トレーニングワークロードを実行しています。
Dell PowerRack システム内に NVIDIA インフラを収容し、Dell PowerEdge サーバーを搭載している CoreWeave は、これらのワークロードのいくつかをホストしています。Cohere は、GB200 NVL72 で北米向けエージェント AI プラットフォームのトレーニングを 3 倍高速化しました。Blackwell クラスターで v8 画像生成モデルのトレーニングを行った Midjourney は、今後登場する画像および動画モデルのトレーニングのために、CoreWeave 上で大規模な Blackwell Ultra GPU フリートをスケールさせています。
Google Cloud 上では、Thinking Machines Lab が、先行世代の GPU と比較して GB300 NVL72 でトレーニングおよび推論速度が 2 倍向上し、最先端モデルの研究と強化学習ワークロードを加速させました。
Nebius は、AI クラウド上で NVIDIA Blackwell および Blackwell Ultra インフラストラクチャを運用し、Higgsfield のモデル学習時間を 30% 短縮することを可能にしました。これにより、現在 2,200 万人のユーザーにサービスを提供し、1 日に 600 万点以上の AI コンテンツを生成するプラットフォームが支えられています。
MLPerf Training 6.0 の結果およびその背後にある最適化技術についてより詳細な技術的な解説をお読みになりたい場合は、こちらの 技術ブログ をご覧ください。
原文を表示
Every breakthrough AI model starts the same way: with a training run. The infrastructure running those training jobs shapes everything: how fast teams can iterate, what scale of model they can build and whether those jobs complete reliably.
As models grow in size, complexity and intelligence, the demands on training infrastructure are also rising.
In MLPerf Training 6.0 — the latest of a series of rigorous, peer-reviewed industry benchmarks for evaluating AI training performance — the NVIDIA Blackwell platform led across every category, demonstrating:
- Fastest time to train on every benchmark
- Largest-scale training across 8,192 GPUs using NVIDIA Blackwell NVL72 systems
- The only platform with submissions across all seven benchmarks in the suite
NVIDIA brings together performance, scale and reliability in a single platform engineered through extreme codesign to enable AI model builders to launch frontier models faster, minimize training costs and start generating revenue early.
Performance: Fastest Time to Train on Every Benchmark
MLPerf Training 6.0 added two new mixture-of-experts (MoE) pretraining workloads to the suite: DeepSeek-V3 671B and GPT-OSS-20B, reflecting the growing centrality of MoE architectures. The NVIDIA platform was the only one to be submitted across every benchmark, and delivered the fastest time to train on all seven.
This round, NVIDIA submitted results on both NVIDIA GB200 NVL72 and GB300 NVL72 rack-scale systems. Within each rack-scale system, fifth-generation NVIDIA NVLink Switches connect all 72 GPUs with high bandwidth, into a unified pool of compute and memory, enabling them to act as one giant GPU.
Large-scale MoE training faces the same all-to-all communication challenge as MoE inference — tokens must be routed across GPUs to reach the right expert subnetwork — and NVLink’s bandwidth advantage is what makes that fast and efficient at scale.
NVIDIA also showcased NVFP4 training methods that increase performance while meeting strict accuracy requirements across large- and small-scale pretraining as well as fine-tuning workloads. NVIDIA continues to push low-precision training innovation across different model architectures, most recently using NVFP4 to pretrain the massive 550-billion-parameter NVIDIA Nemotron 3 Ultra model.
NVIDIA GB300 NVL72 Delivered up to 1.6x Performance Over GB200 NVL72: In this round, GB300 NVL72 delivered up to 1.6x faster training than GB200 NVL72 at the same scale. Key Blackwell Ultra capabilities such as higher compute density with NVFP4, expanded memory capacity and a higher power ceiling that lets the GPU sustain peak performance drive this improvement.
Scale: Largest Blackwell Cluster in MLPerf Training
To support distributed training at scale, NVIDIA offers two complementary scale-out networking platforms — NVIDIA Quantum InfiniBand and NVIDIA Spectrum-X Ethernet — giving data centers the flexibility to build large-scale clusters optimized for their infrastructure.
On DeepSeek-V3 671B, the largest MoE model in the suite, NVIDIA scaled its submission to 8,192 GPUs using GB200 NVL72 systems, the largest-scale Blackwell-based submission in MLPerf Training to date.
NVIDIA also submitted results at 5,120 GPUs with NVIDIA GB200 NVL72 systems on Llama 3.1 405B, one of the largest dense LLMs in the suite.
This round’s results also reflect the deep co-engineering between NVIDIA and its partners on system architecture, networking and software:
- Microsoft Azure scaled Llama 3.1 405B training to 8,192 GPUs using GB200 NVL72 systems, and reached the reference quality target in 7.07 minutes, the fastest time to train for this benchmark.
- CoreWeave delivered the fastest time to train for DeepSeek-V3 671B, reaching the quality target in 2.02 minutes at 8,192-GPU scale using GB300 NVL72 systems connected with Spectrum-X Ethernet networking.
At-Scale Reliability: Built for Production
In production training environments, runs can span weeks or months across hundreds of thousands of GPUs. At that scale, effective training throughput depends on both the performance of the system and the resiliency that makes it reproducible over time.
The MLPerf Training v6.0 results above speak to the performance of NVIDIA’s platform. For resiliency, NVIDIA’s platform is engineered across two dimensions:
- Fewer interruptions: NVIDIA GPUs are built to avoid failures before they occur. Before a GPU reaches a data center, NVIDIA screens it across 30+ manufacturing test stages to catch potential faults early. Once deployed, the Reliability, Availability and Serviceability Engine monitors nearly the entire chip, and self-healing capabilities automatically route around detected faults without interrupting the workload. At the network level, Spectrum-X Ethernet reroutes around failed links in milliseconds, keeping the fabric healthy without disrupting the job.
- Faster recovery when interruptions happen: NVIDIA Resiliency Extension, or NVRx, minimizes the time lost when faults do occur, with capabilities spanning fault detection, recovery and health monitoring across the cluster. It automatically detects and manages underperforming nodes before they slow the rest of the cluster down. When a node experiences an interruption, rather than restarting the entire job, the system resumes from a recent checkpoint, aka a saved snapshot of the training state.
Frontier AI Built on NVIDIA
NVIDIA ecosystem partners also participated extensively this round, with compelling submissions from 19 organizations, including ASUSTeK, Microsoft Azure, Cisco, CoreWeave, Dell Technologies, Fujitsu, Giga Computing, Google Cloud, Hewlett Packard Enterprise, Inventec, Krai, Lambda, Nebius, Netweb Technologies India Ltd., Quanta Cloud Computing (QCT), ScitiX, Supermicro and TTA. Many of these partners are running some of the most demanding AI training workloads on NVIDIA infrastructure.
CoreWeave, which houses its NVIDIA infrastructure within Dell PowerRack systems with Dell PowerEdge servers, is home to several of these workloads. Cohere achieved 3x faster training on GB200 NVL72 for its North agentic AI platform. Midjourney, which trained its v8 image generation model on a Blackwell cluster, is now scaling a large fleet of Blackwell Ultra GPUs on CoreWeave to train upcoming image and video models.
On Google Cloud, Thinking Machines Lab saw 2x faster training and serving speeds on GB300 NVL72 compared with prior-generation GPUs, accelerating frontier model research and reinforcement learning workflows.
Nebius, running NVIDIA Blackwell and Blackwell Ultra infrastructure on its AI cloud, enabled Higgsfield to reduce model training time by 30%, supporting a platform that now serves 22 million users and generates over 6 million pieces of AI content per day.
For a deeper technical look at the MLPerf Training 6.0 results and the optimizations behind them, read this technical blog.
関連記事
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み