LumberChunker: 長編物語文書のセグメンテーション
LumberChunkerは、長編物語文書を意味的に独立したチャンクに分割するLLMベースの手法を提案し、RAGシステムの検索品質向上を目指す研究である。
キーポイント
従来手法の問題点
長編物語文書の分割において、章や段落などの表面的な構造に依存したチャンキングでは、意味的な連続性が損なわれ、RAGシステムの検索品質が低下する問題がある。
LumberChunkerのアプローチ
LLMを用いて、物語の流れ(例:場面の変化、新たな登場人物の導入)に基づく意味的なシフトを検出し、より自然で意味的に独立したチャンクを作成する手法を提案している。
目的と利点
この手法により、RAGシステムが適切な情報をより正確に検索できるようになり、下流タスクのパフォーマンス向上が期待される。
実用性と公開
研究の実用性を示すため、論文、コード、データが公開されており、実際のRAGシステムへの適用が可能である。
影響分析・編集コメントを表示
影響分析
この研究は、RAGシステムの根本的な課題である文書分割の質を向上させる可能性があり、情報検索や質問応答などの実用アプリケーションの性能改善に直接寄与する。意味理解に基づく分割は、従来の固定長や構造依存の手法を超える新たな標準となり得る。
編集コメント
RAGの実用化が進む中、その基盤となる文書前処理の重要性を再認識させる研究。コードとデータの公開は再現性と実装の容易さを高めており、現場での早期導入が期待できる。
jQuery('.post-authors').width(0.33 * jQuery('.post-authors').parent().width());
jQuery('.affiliations').width(0.33 * jQuery('.affiliations').parent().width());
jQuery('.date').width(0.33 * jQuery('.date').parent().width());
jQuery('.post-authors').empty();
jQuery('.post-authors').append('Authors
');
jQuery('.post-authors').append('André V. Duarte, João Marques, Miguel Graça, Miguel Freire, Lei Li, Arlindo Oliveira');
jQuery('.affiliations').append('IST, NeuralShift AI, CMU
');
jQuery('.doi').remove();
リンク:
論文 | コード | データ

LumberChunkerは、長編ストーリーをどこで分割すべきかをLLM(大規模言語モデル)に決定させ、Retrieval Augmented Generation(RAG)システムが適切な情報を検索できるよう、より自然なチャンクを作成します。
導入
長編ナラティブ文書は通常、章やセクションなどの明示的な構造を持っていますが、これらの単位は検索タスクにはしばしば広すぎます。より低いレベルでは、これらの大きなセグメント内で、目に見える構造的な区切りなしに重要な意味的変化が起こります。段落や固定トークンウィンドウなどのフォーマットの手がかりだけでテキストを分割すると、同じナラティブ単位に属する箇所が分離されたり、無関係なコンテンツが一緒にグループ化されたりすることがあります。構造と意味のこの不一致は、不完全または混在した文脈を含むチャンクを生み出し、検索品質を低下させ、下流のRAGパフォーマンスに影響を与えます。このため、セグメンテーションは、文書構造のみに依存するのではなく、意味的に独立したチャンクを作成することを目指すべきです。
では、ストーリーの流れを保ちながら、チャンキングを実用的に保つにはどうすればよいでしょうか?
多くの場合、読者はナラティブが変化し始める場所を簡単に認識できます。例えば、テキストが別のシーンに移ったり、新しいエンティティを導入したり、目的を変えたりするときです。難しいのは、ほとんどの自動チャンキング手法がこの意味的シグナルを考慮せず、表面構造のみに依存していることです。その結果、フォーマットの観点では合理的に見えるが、基礎となるナラティブの一貫性を壊すセグメンテーションを生成する可能性があります。
これを具体的にするために、以下の短い文章を考え、最適なチャンキング境界を決定してください!
LumberChunker: セグメント2(クイズ)
.quiz-section {
padding: 1.5rem;
border-radius: 12px;
margin: 0;
box-shadow: none;
}
.quiz-container {
display: flex;
flex-direction: column;
gap: 0;
background: white;
border-radius: 12px;
padding: 32px 40px;
box-shadow: 0 1px 3px rgba(0, 0, 0, 0.06);
border: 1px solid #eaeaea;
max-width: 780px;
margin: 0 auto;
}
.quiz-step-label {
display: inline-flex;
align-items: center;
gap: 8px;
font-size: 0.7em;
font-weight: 600;
text-transform: uppercase;
letter-spacing: 0.08em;
color: #909090;
margin-bottom: 12px;
}
.quiz-step-label .step-number {
display: inline-flex;
align-items: center;
justify-content: center;
width: 20px;
height: 20px;
border-radius: 50%;
background-color: #e8e8e8;
color: #666;
font-size: 0.75em;
font-weight: 700;
line-height: 1;
}
.quiz-divider {
width: 100%;
height: 1px;
background: #ebebeb;
margin: 20px 0;
}
.passage-sentence {
margin: 0;
padding: 3px 14px;
line-height: 1.5;
color: #3a3a3a;
border-radius: 4px;
transition: background-color 0.3s ease, border-left-color 0.3s ease;
border-left: 3px solid transparent;
font-size: 0.88em;
box-sizing: border-box;
font-family: Georgia, 'Times New Roman', serif;
}
.passage-sentence.chunk-1 {
background-color: #fff5f5;
border-left-color: #e57373;
}
.passage-sentence.chunk-2 {
background-color: #f0f8ff;
border-left-color: #64b5f6;
}
.options-container {
display: flex;
flex-direction: column;
gap: 10px;
margin-bottom: 0;
padding: 0;
}
.option-card {
border: 1.5px solid #e4e4e4;
border-radius: 10px;
padding: 14px 18px;
cursor: pointer;
transition: all 0.25s ease;
background-color: #fafafa;
}
.option-card.selected {
border-color: #464646;
background-color: #f0f1f3;
}
.option-header {
display: flex;
align-items: center;
gap: 12px;
}
.option-header label {
flex: 1;
cursor: pointer;
font-size: 0.92em;
color: #424242;
line-height: 1.4;
}
.quiz-controls {
padding-top: 28px;
padding-bottom: 8px;
text-align: center;
}
.quiz-btn {
border-radius: 10px;
background-color: #F0F3F7;
border: none;
color: #515151;
text-transform: uppercase;
font-weight: bold;
font-size: 0.92em;
padding: 0.75rem 1.5rem;
box-shadow: 0 4px 0 #cccccc;
cursor: pointer;
transition: all 0.1s ease-in-out;
letter-spacing: 0.02em;
}
.solution-phase {
transition: opacity 0.4s ease-in-out;
}
.result-header {
text-align: center;
padding: 14px 16px;
border-radius: 8px;
margin-bottom: 14px;
}
.result-header.correct {
background-color: #f1f8f4;
border: 1.5px solid #a5d6a7;
}
.feedback-box {
background-color: #f8f9fa;
border-left: 3px solid #b0b0b0;
padding: 12px 14px;
font-size: 0.84em;
color: #444;
}
.reasoning-box {
background-color: #fffef0;
border-left: 4px solid #ffd54f;
padding: 8px;
border-radius: 4px;
font-size: 0.75em;
}
テキスト
セグメンテーションクイズ
この文章を意味的チャンクに分割する最良の方法を
選択してください
1 文章を読む
2 最良の
セグメンテーションを選ぶ
回答を送信
← もう一度試す
私たちの目標は、この種のセグメンテーションの決定を大規模に実用的なものにすることです。課題は、人間レベルの品質の境界検出にはナラティブ(物語)の文脈理解が必要であり、長編文書の数千の段落にわたってそれを適用するのはコストがかかることです。
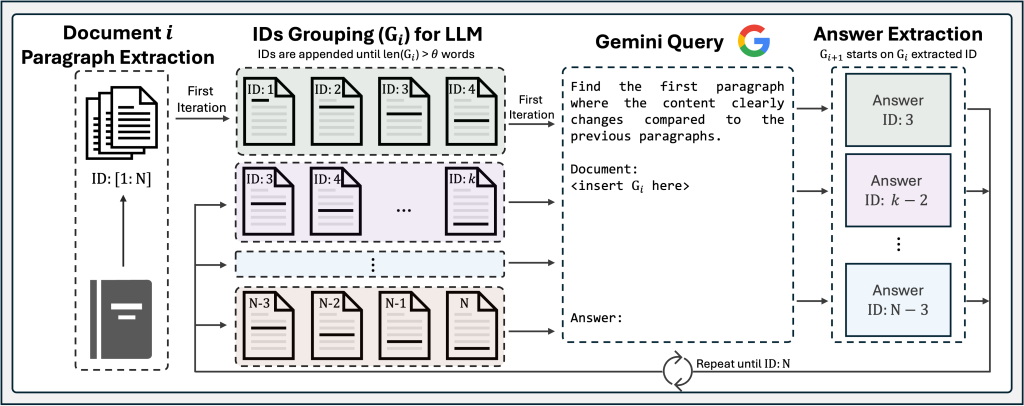
LumberChunkerは、セグメンテーションを境界発見問題として扱うことでこの課題に取り組みます:連続する短い段落のシーケンスが与えられたとき、言語モデル(Language Model)に、内容が明確に変化する最も早い時点を特定するよう依頼します。この定式化により、セグメントの長さは可変でありながら、基礎となるナラティブ構造に沿ったままにすることができます。実際には、LumberChunkerは以下のステップで構成されます:
1) 文書段落抽出
書籍を段落にきれいに分割し、安定したID(ID:1, ID:2, …)を割り当てます。これにより、文書の自然な談話単位が保持され、安全な候補境界が得られます。
例:小説から抽出:
ID:1 「朝日がほこりっぽい窓から差し込んだ…」
ID:2 「彼女はゆっくりとドアへ歩き、ためらった…」
ID:3 「一方、街の向こう側では、モリソン刑事が事件ファイルを確認していた…」
ID:4 「前夜の出来事は彼を困惑させていた…」
各段落には、境界を追跡するための一意のIDが与えられます。
2) LLM(大規模言語モデル)のためのIDグループ化
グループの長さがトークン予算θに達するまで段落を追加して、グループG_iを構築します。これにより、モデルがトピックやシーンが実際にいつ変化するかを判断するのに十分な文脈が提供されます。
例:θ = 550トークンの場合、例ごとに構築:
G_1 = [ID:1, ID:2, ID:3, ID:4, ID:5, ID:6]
このウィンドウは複数の段落にまたがることで、文脈内に少なくとも1つの意味のあるナラティブの変化が存在する可能性を高めます。
3) LLMクエリ
G_i内の段落をプロンプトとしてモデルに与え、内容がそれ以前の内容と比較して明確に変化する最初の段落を返すよう依頼します。返されたIDをチャンク境界として使用し、次のグループをその段落から開始し、書籍の終わりまで繰り返します。
例:G_1 = [p1, p2, p3, p4, p5, p6]が与えられた場合、LLMは応答:p3
回答抽出:
p3を境界として抽出します。これにより以下が作成されます:
チャンク1: [p1, p2]
次のグループ(G_2)はp3から開始
GutenQA: 長編ナラティブ検索のためのベンチマーク
私たちのチャンキング(文書分割)アプローチを評価するために、100冊の注意深くクリーンアップされたパブリックドメイン書籍と、3,000の干し草の山の中の針(needle-in-a-haystack)タイプの質問をペアにしたベンチマークであるGutenQAを紹介します。これにより、検索品質を直接測定し、より良い検索がどのように
原文を表示
jQuery('.post-authors').width(0.33 * jQuery('.post-authors').parent().width());
jQuery('.affiliations').width(0.33 * jQuery('.affiliations').parent().width());
jQuery('.date').width(0.33 * jQuery('.date').parent().width());
jQuery('.post-authors').empty();
jQuery('.post-authors').append('Authors
');
jQuery('.post-authors').append('André V. Duarte, João Marques, Miguel Graça, Miguel Freire, Lei Li, Arlindo Oliveira');
jQuery('.affiliations').append('IST, NeuralShift AI, CMU
');
jQuery('.doi').remove();
Links:
Paper | Code | Data
LumberChunker lets an LLM decide where a long story should be split, creating more natural chunks that help Retrieval Augmented Generation (RAG) systems retrieve the right information.
Introduction
Long-form narrative documents usually have an explicit structure, such as chapters or sections, but these units are often too broad for retrieval tasks. At a lower level, important semantic shifts happen inside these larger segments without any visible structural break. When we split text only by formatting cues, like paragraphs or fixed token windows, passages that belong to the same narrative unit may be separated, while unrelated content can be grouped together. This misalignment between structure and meaning produces chunks that contain incomplete or mixed context, which reduces retrieval quality and affects downstream RAG performance. For this reason, segmentation should aim to create chunks that are semantically independent, rather than relying only on document structure.
So how do we preserve the story’s flow and still keep chunking practical?
In many cases, a reader can easily recognize where the narrative begins to shift—for example, when the text moves to a different scene, introduces a new entity, or changes its objective. The difficulty is that most automated chunking methods do not consider this semantic signal and instead rely only on surface structure. As a result, they may produce segmentations that look reasonable from a formatting perspective but break the underlying narrative coherence.
To make this concrete, consider the short passage below and decide the optimal chunking boundary!
LumberChunker: Segment 2 (Quiz)
.quiz-section {
padding: 1.5rem;
border-radius: 12px;
margin: 0;
box-shadow: none;
}
.quiz-container {
display: flex;
flex-direction: column;
gap: 0;
background: white;
border-radius: 12px;
padding: 32px 40px;
box-shadow: 0 1px 3px rgba(0, 0, 0, 0.06);
border: 1px solid #eaeaea;
max-width: 780px;
margin: 0 auto;
}
.quiz-step-label {
display: inline-flex;
align-items: center;
gap: 8px;
font-size: 0.7em;
font-weight: 600;
text-transform: uppercase;
letter-spacing: 0.08em;
color: #909090;
margin-bottom: 12px;
}
.quiz-step-label .step-number {
display: inline-flex;
align-items: center;
justify-content: center;
width: 20px;
height: 20px;
border-radius: 50%;
background-color: #e8e8e8;
color: #666;
font-size: 0.75em;
font-weight: 700;
line-height: 1;
}
.quiz-divider {
width: 100%;
height: 1px;
background: #ebebeb;
margin: 20px 0;
}
.passage-sentence {
margin: 0;
padding: 3px 14px;
line-height: 1.5;
color: #3a3a3a;
border-radius: 4px;
transition: background-color 0.3s ease, border-left-color 0.3s ease;
border-left: 3px solid transparent;
font-size: 0.88em;
box-sizing: border-box;
font-family: Georgia, 'Times New Roman', serif;
}
.passage-sentence.chunk-1 {
background-color: #fff5f5;
border-left-color: #e57373;
}
.passage-sentence.chunk-2 {
background-color: #f0f8ff;
border-left-color: #64b5f6;
}
.options-container {
display: flex;
flex-direction: column;
gap: 10px;
margin-bottom: 0;
padding: 0;
}
.option-card {
border: 1.5px solid #e4e4e4;
border-radius: 10px;
padding: 14px 18px;
cursor: pointer;
transition: all 0.25s ease;
background-color: #fafafa;
}
.option-card.selected {
border-color: #464646;
background-color: #f0f1f3;
}
.option-header {
display: flex;
align-items: center;
gap: 12px;
}
.option-header label {
flex: 1;
cursor: pointer;
font-size: 0.92em;
color: #424242;
line-height: 1.4;
}
.quiz-controls {
padding-top: 28px;
padding-bottom: 8px;
text-align: center;
}
.quiz-btn {
border-radius: 10px;
background-color: #F0F3F7;
border: none;
color: #515151;
text-transform: uppercase;
font-weight: bold;
font-size: 0.92em;
padding: 0.75rem 1.5rem;
box-shadow: 0 4px 0 #cccccc;
cursor: pointer;
transition: all 0.1s ease-in-out;
letter-spacing: 0.02em;
}
.solution-phase {
transition: opacity 0.4s ease-in-out;
}
.result-header {
text-align: center;
padding: 14px 16px;
border-radius: 8px;
margin-bottom: 14px;
}
.result-header.correct {
background-color: #f1f8f4;
border: 1.5px solid #a5d6a7;
}
.feedback-box {
background-color: #f8f9fa;
border-left: 3px solid #b0b0b0;
padding: 12px 14px;
font-size: 0.84em;
color: #444;
}
.reasoning-box {
background-color: #fffef0;
border-left: 4px solid #ffd54f;
padding: 8px;
border-radius: 4px;
font-size: 0.75em;
}
Text
Segmentation Quiz
Choose the best way to segment this passage into
semantic chunks
1 Read the passage
2 Pick the
best segmentation
Submit Answer
← Try Again
const QUIZ_DATA = {
passage: [
'"What about a story?" I said.',
'"Could you very sweetly tell Winnie-the-Pooh one?"',
'"I suppose I could," I said. "What sort of stories does he like?"',
'"About himself. Because he\'s that sort of Bear."',
'"Oh, I see."',
'"So could you very sweetly?"',
'"I\'ll try," I said.',
'So I tried.',
'Once upon a time, a very long time ago now, about last Friday, Winnie-the-Pooh lived in a forest all by himself under the name of Sanders.',
'"What does \'under the name\' mean?" asked Christopher Robin.'
],
question: "How should this passage be segmented for optimal semantic chunking?",
options: [
{
id: 'A', label: 'One chunk per sentence — 10 chunks total', breaks: [0, 1, 2, 3, 4, 5, 6, 7, 8],
chunks: Array.from({ length: 10 }, (_, i) => ({ sentences: [i], name: Chunk ${i + 1} })),
feedback: "This creates too many tiny chunks, isolating each sentence and losing the semantic connections between related dialogue. This approach makes retrieval inefficient and fails to capture the conversational flow."
},
{
id: 'B', label: 'No split, keep the full passage — 1 chunk', breaks: [],
chunks: [{ sentences: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], name: "Entire Passage" }],
feedback: "This treats the entire passage as one chunk, mixing two distinct sections: the dialogue setup and the story beginning. The shift from meta-conversation to storytelling represents a clear semantic boundary that should be captured."
},
{
id: 'C', label: 'Split between dialogue and story — 2 chunks', breaks: [7],
chunks: [
{ sentences: [0, 1, 2, 3, 4, 5, 6, 7], name: "Dialogue Setup", reasoning: "These sentences form a complete dialogue where Christopher Robin asks for a story about Winnie-the-Pooh. They establish the context and setup for what follows, showing the conversational flow from request to agreement." },
{ sentences: [8, 9], name: "Story Beginning", reasoning: "These sentences transition from the setup dialogue into the actual storytelling. The narrator begins the story with a classic fairy tale opening, immediately followed by Christopher Robin's interruption with a question about the story." }
],
feedback: "This segmentation recognizes the semantic boundary between the meta-dialogue about what story to tell and the actual storytelling. The split cleanly separates the setup conversation from the narrative opening.",
isCorrect: true
}
],
correctAnswer: 'C'
};
class TextChunkingQuiz {
constructor() {
this.quizData = QUIZ_DATA;
this.selectedOption = null;
this.hasSubmitted = false;
this.init();
}
init() {
this.renderProgressIndicator();
this.renderQuiz();
this.setupEventListeners();
}
renderProgressIndicator() {
const container = d3.select('#progressIndicator');
container.selectAll('*').remove();
const svg = container.append('svg').attr('width', 300).attr('height', 10);
svg.append('rect').attr('width', 300).attr('height', 8).attr('rx', 4).attr('fill', '#e8e8e8');
svg.append('rect').attr('class', 'progress-bar-fill').attr('width', 0).attr('height', 8).attr('rx', 4).attr('fill', '#464646');
}
updateProgress(value) {
d3.select('.progress-bar-fill').transition().duration(400).attr('width', value * 300);
}
renderQuiz() {
this.renderPassage();
this.renderOptions();
}
renderPassage() {
const container = d3.select('#passageContainer');
container.selectAll('*').remove();
container.selectAll('.passage-sentence').data(this.quizData.passage).join('div').attr('class', 'passage-sentence').text(d => d);
}
renderOptions() {
const container = d3.select('#optionsContainer');
container.selectAll('*').remove();
const options = container.selectAll('.option-card').data(this.quizData.options).join('div').attr('class', 'option-card').on('click', (event, d) => this.selectOption(d));
const header = options.append('div').attr('class', 'option-header');
header.append('input').attr('type', 'radio').attr('name', 'chunking-option').property('checked', d => this.selectedOption === d.id);
header.append('label').html(d => Option ${d.id}: ${d.label});
}
selectOption(option) {
if (this.hasSubmitted) return;
this.selectedOption = option;
d3.selectAll('.option-card').classed('selected', d => d.id === option.id);
d3.selectAll('input[name="chunking-option"]').property('checked', d => d.id === option.id);
this.highlightPassageChunks(option);
this.updateProgress(0.5);
}
highlightPassageChunks(option) {
const sentences = d3.selectAll('.passage-sentence');
sentences.attr('class', 'passage-sentence');
if (!option) return;
option.chunks.forEach((chunk, i) => {
sentences.filter((d, idx) => chunk.sentences.includes(idx)).attr('class', passage-sentence chunk-${(i % 3) + 1});
});
}
setupEventListeners() {
d3.select('#submitBtn').on('click', () => this.submitAnswer());
d3.select('#backBtn').on('click', () => this.hideResults());
}
submitAnswer() {
if (!this.selectedOption || this.hasSubmitted) return;
this.hasSubmitted = true;
this.updateProgress(1);
this.showResults();
}
showResults() {
const answerPhase = d3.select('#answerPhase');
const solutionPhase = d3.select('#solutionPhase');
const submitBtn = d3.select('#submitBtn');
const backBtn = d3.select('#backBtn');
answerPhase.transition().duration(300).style('opacity', 0).on('end', () => {
answerPhase.style('display', 'none');
const solutionContent = d3.select('#solutionContent');
solutionContent.selectAll('*').remove();
const header = solutionContent.append('div').attr('class', result-header ${this.selectedOption.isCorrect ? 'correct' : 'incorrect'});
header.append('h3').text(this.selectedOption.isCorrect ? 'Correct!' : 'Not Quite');
header.append('p').text(this.selectedOption.isCorrect ? 'You identified the optimal semantic boundary.' : 'This segmentation could be improved.');
solutionContent.append('div').attr('class', feedback-box ${this.selectedOption.isCorrect ? 'correct-feedback' : ''}).text(this.selectedOption.feedback);
if (this.selectedOption.isCorrect) {
const defs = solutionContent.append('div').attr('class', 'chunk-definitions').style('margin-top', '15px');
this.selectedOption.chunks.forEach((chunk, i) => {
const def = defs.append('div').attr('class', chunk-display chunk-definition chunk-${i + 1});
def.append('h5').text(chunk.name);
def.append('div').attr('class', 'reasoning-box').html(Why: ${chunk.reasoning});
});
}
submitBtn.style('display', 'none');
backBtn.style('display', 'inline-block');
solutionPhase.style('display', 'flex').style('opacity', 0).transition().duration(400).style('opacity', 1);
});
}
hideResults() {
const answerPhase = d3.select('#answerPhase');
const solutionPhase = d3.select('#solutionPhase');
const submitBtn = d3.select('#submitBtn');
const backBtn = d3.select('#backBtn');
this.selectedOption = null;
this.hasSubmitted = false;
this.updateProgress(0);
solutionPhase.transition().duration(300).style('opacity', 0).on('end', () => {
solutionPhase.style('display', 'none');
backBtn.style('display', 'none');
submitBtn.style('display', 'inline-block');
this.highlightPassageChunks(null);
d3.selectAll('.option-card').classed('selected', false);
d3.selectAll('input[name="chunking-option"]').property('checked', false);
answerPhase.style('display', 'flex').style('opacity', 0).transition().duration(400).style('opacity', 1);
});
}
}
document.addEventListener('DOMContentLoaded', () => {
if (document.getElementById('quizContainer')) new TextChunkingQuiz();
});
The LumberChunker Method
In the example above, Option C provides the most coherent segmentation. The boundary aligns with the point where the narrative becomes semantically independent from the preceding context.
Our goal is to make this type of segmentation decision practical at scale. The challenge is that human-quality boundary detection requires understanding narrative context, which is expensive to apply across thousands of paragraphs in long-form documents.
LumberChunker approaches this by treating segmentation as a boundary-finding problem: given a short sequence of consecutive paragraphs, we ask a language model to identify the earliest point where the content clearly shifts. This formulation allows segments to vary in length while remaining aligned with the underlying narrative structure. In practice, LumberChunker consists of these steps:
1) Document Paragraph Extraction
Cleanly split the book into paragraphs and assign stable IDs (ID:1, ID:2, …). This preserves the document’s natural discourse units and gives us safe candidate boundaries.
Example: From a novel, we extract:
ID:1 “The morning sun filtered through the dusty windows…”
ID:2 “She walked slowly to the door, hesitating…”
ID:3 “Meanwhile, across town, Detective Morrison reviewed the case files…”
ID:4 “The previous night’s events had left him puzzled…”
Each paragraph gets a unique ID for tracking boundaries.
2) IDs Grouping for LLM
Build a group G_i by appending paragraphs until the group’s length reaches a token budget θ. This provides enough context for the model to judge when a topic/scene actually shifts.
Example: With θ = 550 tokens, we build, per example:
G_1 = [ID:1, ID:2, ID:3, ID:4, ID:5, ID:6]
This window, by spanning multiple paragraphs, increases the chance that at least one meaningful narrative shift is present within the context.
3) LLM Query
Prompt the model with the paragraphs in G_i and ask it to return the first paragraph where content clearly changes relative to what came before. Use that returned ID as the chunk boundary; start the next group at that paragraph and repeat to the end of the book.
Example: Given G_1 = [p1, p2, p3, p4, p5, p6], the LLM responds: p3
Answer Extraction:
We extract p3 as the boundary. This creates:
Chunk 1: [p1, p2]
Next group (G_2) starts at p3
GutenQA: A Benchmark for Long-Form Narrative Retrieval
To evaluate our chunking approach, we introduce GutenQA, a benchmark of 100 carefully cleaned public-domain books paired with 3,000 needle-in-a-haystack type of questions. This allows us to measure retrieval quality directly and then observe how better retrieval leads to
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み