ループの始め方について
Anthropic は、Claude AI を活用してプログラミングにおけるループ処理を効率的に開始・実装する方法に関するガイドラインを公開した。
キーポイント
ループ処理の効率的な開始方法
Claude AI をプロンプトエンジニアリングの支援として使い、複雑なループ構造を素早く生成・デバッグする手法を紹介している。
具体的な実装パターン
一般的なプログラミング言語における基本的なループ(for, while)から、条件分岐を含む高度なループ処理までの具体例を示している。
AI によるコード生成の活用
開発者が手動で記述する前に AI に指示を出し、エラーチェックや最適化を伴ったコードを即座に得るワークフローを推奨している。
影響分析・編集コメントを表示
影響分析
この記事は、特定の技術的革新というよりは、既存の LLM(Claude)を日常の開発ワークフローに組み込むための実践的なチュートリアルです。開発者が AI ツールを「魔法」のように使うのではなく、具体的なタスク(ループ処理など)に対してどう指示を出すかの基礎を固めることで、生産性向上への第一歩を示しています。
編集コメント
これは高度な新技術の発表ではなく、Claude の基本的な活用事例を解説する入門的な記事です。しかし、AI を実務で使いこなすための具体的なプロンプト例を知るには有用な資料と言えます。
ターンベースのループ
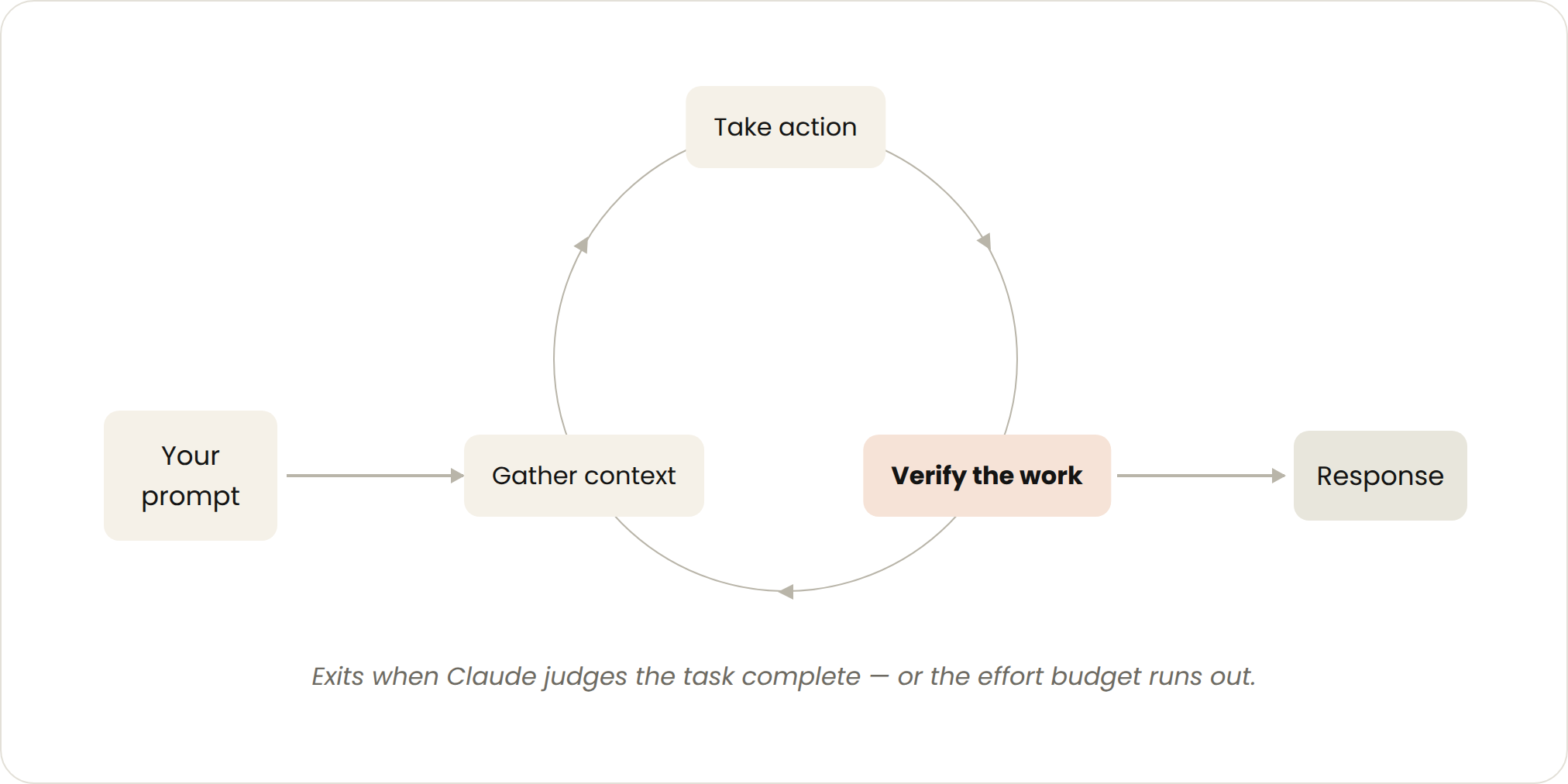
- トリガー: ユーザーからのプロンプト。
- 停止基準: クロードがタスク完了と判断した場合、または追加の文脈を必要とする場合。
- 最適な用途: 定期的なプロセスやスケジュールの一部ではない、比較的短いタスク。
- 管理方法: 具体的なプロンプトを作成し、スキル(SKILL)を活用して検証を強化することで、ターン数を削減する。
あなたが送信するすべてのプロンプトは、あなたが各ターンを指示する手動ループを開始します。クラウドは文脈を集約し、アクションを実行し、作業を確認し、必要に応じて繰り返し、応答します。これを「エージェント型ループ(agentic loop)」と呼びます。
例えば、クリックボタンを作成するようにクロードに依頼すると、彼はあなたのコードを読み込み、編集を行い、テストを実行し、*動作するものだと信じる*結果を返します。その後、あなたは手動で作業を確認し、次のプロンプトを入力します。
検証ステップを改善するには、手動手順を SKILL.md ファイルに記述して、クロードが自分の作業をより多く、エンドツーエンドでチェックできるようにします。これには、クロードが結果を*確認*・*測定*・*対話*できるようになるためのツールやコネクタを含める必要があります。検証が定量的であればあるほど、クロードによる自己検証は容易になります。
例えば、SKILL.md ファイルでは以下のように指定できます:
name: verify-frontend-change
description: UI 変更を完了と宣言する前に、エンドツーエンドで検証を行う。
フロントエンドの変更の検証
編集が成功しただけで UI 変更が完了したと報告してはいけません。人間のレビュアーが行うのと同じ方法で検証してください:
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等)は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{...}
- デベロッパーサーバーを起動し、編集したページをブラウザで開きます。
- 変更に対して直接操作を行います。新しいコントロール(ボタン、入力フィールド、トグルスイッチ)の場合、クリックして期待される状態変化を確認し、変更前後のスクリーンショットを撮影します。
- ブラウザのコンソールを確認し、新しいエラーや警告がゼロであることを確認します。
- Chrome Devtools MCP を使用してパフォーマンストレースを実行し、Core Web Vitals(コアウェブバイタル)を監査します。
いずれかのステップで失敗した場合は、その問題を修正してから手順 1 から再実行してください。部分的に検証された作業を手渡すことはしないでください。
ゴールベースのループ (/goal)
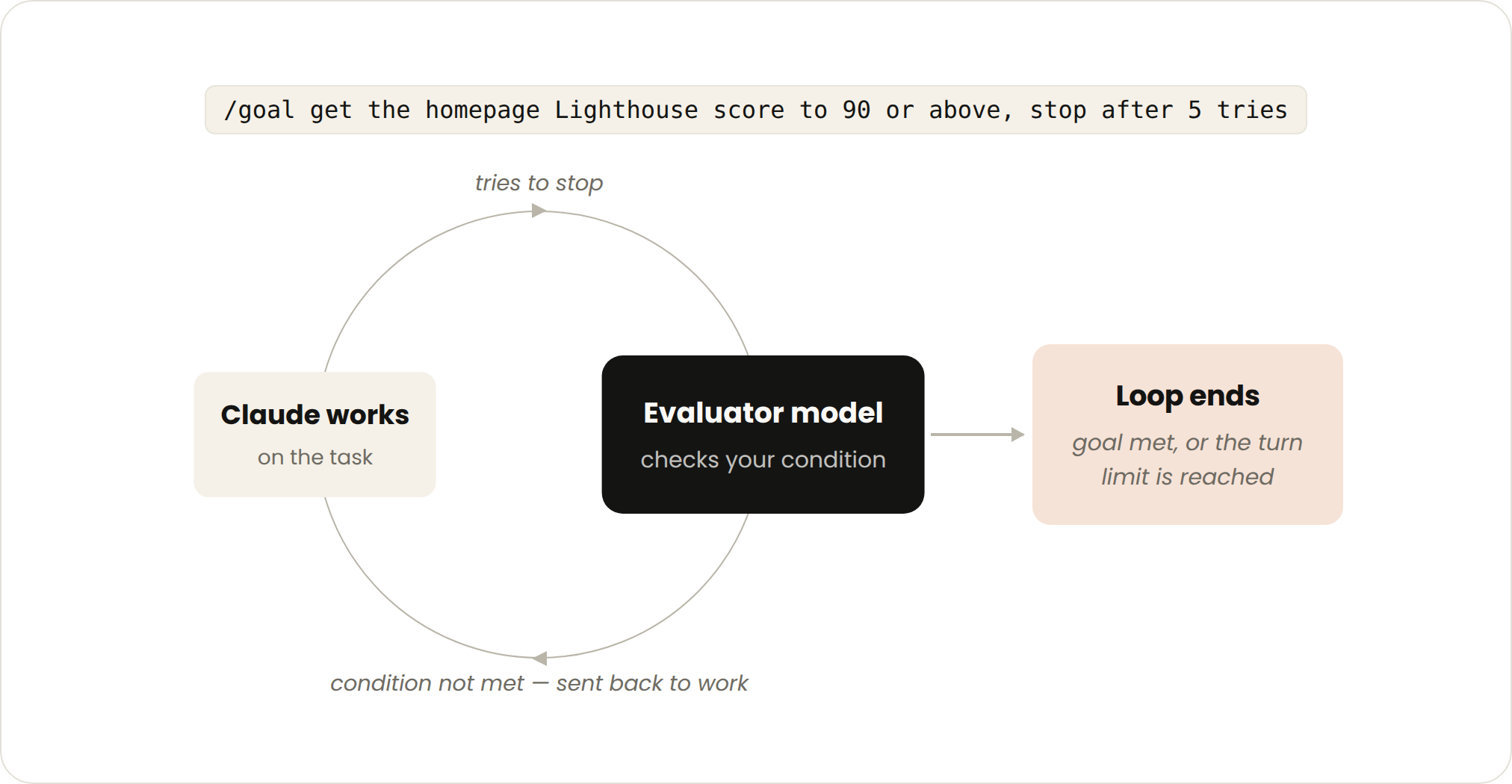
- トリガー:リアルタイムでの手動プロンプト。
- 停止条件:ゴール達成 または 最大ターン数到達。
- 最適な使用例:検証可能な終了基準を持つタスク。
- 管理方法:特定の完了基準と明示的なターン制限(例:「5 回試行後に停止」)を設定する。
場合によっては、1 ターンでは不十分なことがあります。特に複雑なタスクの場合です。エージェントは反復できる場合により良い成果を出します。/goal を使用して「完了した状態」を定義することで、Claude が反復を続ける期間を延長できます。
成功基準を定義すると、Claude は何が「十分か」を判断してループを早期に終了する必要がなくなります。Claude が停止を試みるたびに、評価モデルがあなたの条件を確認し、ゴールが達成されるか、あなたが定義したターン数に達するまで作業を続行します。
これが、合格したテスト数や特定のスコア閾値のクリアなど、決定論的な基準がこれほど効果的である理由です。
例えば:
/goal ホームページの Lighthouse スコアを 90 以上にし、5 回の試行で停止する。
タイムベースループ (/loop および /schedule)
- トリガー: 指定された時間間隔。
- 停止基準: ユーザーがキャンセルするか、作業が完了したとき(PR がマージされるか、キューが空になる)。
- 最適な用途: 定期的な作業や、外部環境/システムとの連携。
- 管理された使用法: より長い間隔を設定するか、時間ではなくイベントに基づいて反応する。
一部のエージェントによる作業は定期的です。タスク自体は変わらず、入力のみが変化します。例えば、毎朝の Slack メッセージの要約などが該当します。他の作業は外部システムに依存しており、それらと連携する簡単な方法は、一定間隔でチェックして変更に応答することです。例えば、コードレビューを受けたり CI に失敗したりする可能性のある PR などがあります。
これらに対しては、Claude が /loop で実行されたときにトリガーし、指定した間隔でプロンプトを再実行します。例:
/loop 5m check my PR, address review comments, and fix failing CI
/loop はあなたのコンピュータ上で動作するため、オフにすると停止します。ループをクラウド上に移動させるには、/schedule でルーチンを作成してください。
プロアクティブループ
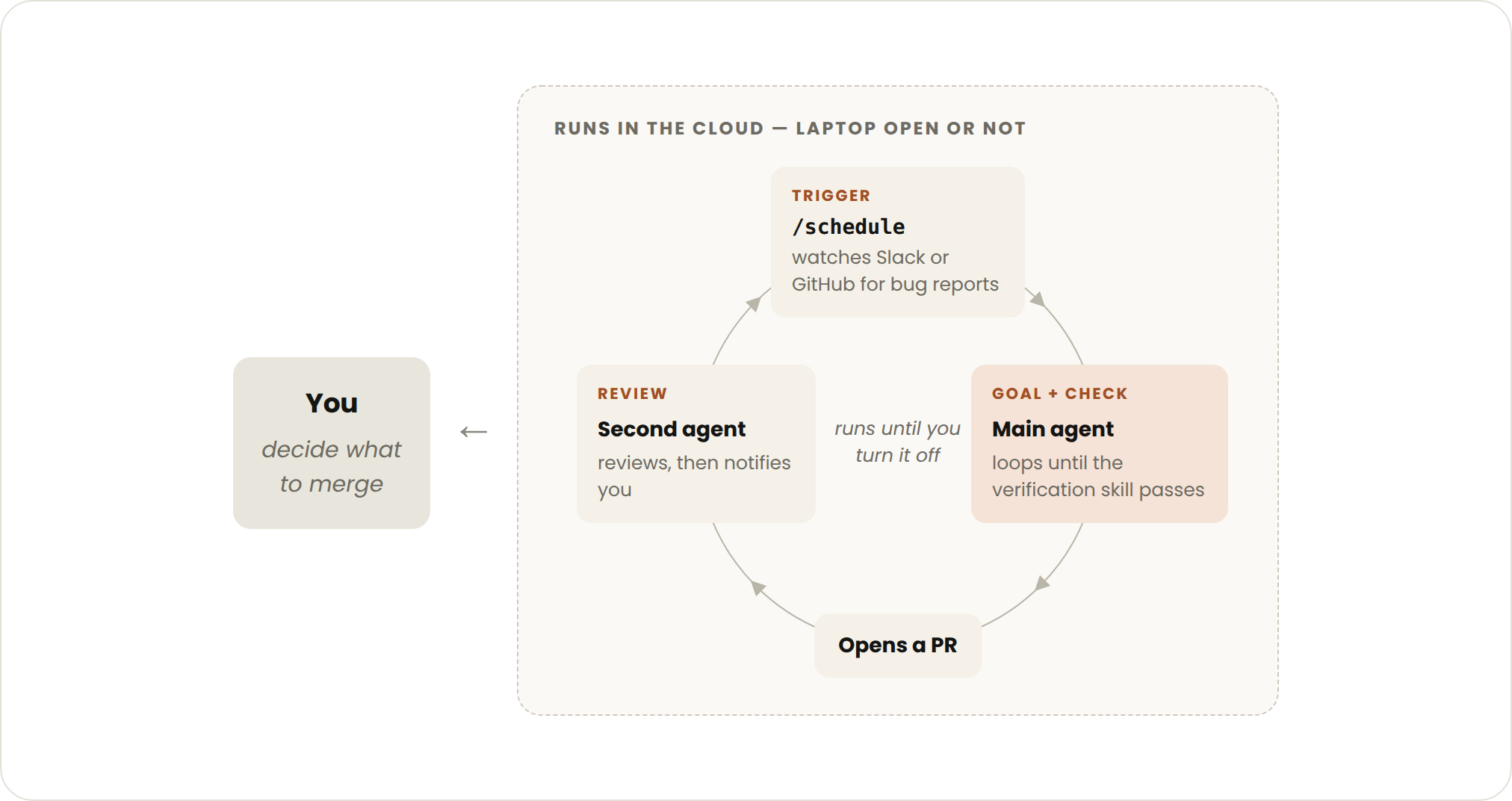
- トリガー:イベントまたはスケジュールによってトリガーされ、リアルタイムでは人間は関与しません。
- 停止条件:各タスクは目標が達成された時点で終了します。ルーチン自体は、あなたがオフにするまで実行されます。
- 最適な用途:バグレポート、イシューの選別、マイグレーション、依存関係のアップグレードなど、明確に定義された作業の反復ストリームに適しています。
- 管理された使用法:ルーチンをより小さく高速なモデルへルーティングし、判断が必要なケースには最も能力の高いモデルを使用します。
上記のプリミティブと、自動モードやダイナミックワークフロー(研究プレビュー)といった他の Claude Code の機能を組み合わせることで、長時間実行される作業のためのループを構築できます。
例えば、 incoming feedback(着信フィードバック)を処理するには以下を使用できます:
/schedule(研究プレビュー)を使用して、新しいレポートを確認するルーチンを実行します/goalを使用して完了の定義と、その検証方法を文書化するためのスキルを定義します- ダイナミックワークフローを使用して、各レポートを選別し、修正し、修正を検証するエージェントをオーケストレーションします
- 自動モードを使用することで、許可を求めるために停止することなくルーチンが実行されます
これらを組み合わせると、プロンプトは以下のようになります:
/schedule every hour: check #project-feedback for bug reports. /goal: don't stop until every report found this run is triaged, actioned, and responded to. When fixing a bug, use a workflow to explore three solutions in parallel worktrees and have a judge adversarially review them.
コード品質の維持
ループの出力の質は、それを支えるシステムに依存します。システムを設計する際に:
- コードベース自体を清潔に保つ:Claude は、コードベース内に既に存在するパターンや規約に従います。
- Claude 自身に検証手段を与える:あなたとチームにとっての「良い状態」をスキルとして定義してください。
- ドキュメントへのアクセスを容易にする:フレームワークやライブラリのドキュメントには、最新のベストプラクティスが記載されています。
- コードレビュー用にセカンドエージェントを使用する:新鮮な文脈を持つレビュアーはバイアスがかかりにくく、メインエージェントの推論に影響されません。組み込みの
/code-reviewスキルや GitHub 用の Code Review を利用できます。
個々の結果が基準を満たさない場合、その個別の問題を修正するだけで終わらず、将来のすべての反復においてシステム全体を改善するためにそれをエンコード(体系化)してください。
トークン使用量の管理
トークン使用量を管理するためには、ループに明確な境界線を設ける必要があります:
- 作業に適したプリミティブとモデルを選択する:小規模なタスクには複数のエージェントやループは不要です。一部のタスクでは、より安価で高速なモデルを使用できます。
- 明確な成功基準と停止条件を定義する:完了の状態を具体的に指定することで、Claude が早期に(ただし早すぎないタイミングで)解決策に到達できるようにします。
- 大規模実行前にパイロットテストを行う:動的ワークフローでは数百のエージェントが生成される可能性があります。まずは作業の一部を小さく切り取って使用状況を把握してください。
- 決定論的な作業にはスクリプトを使用する:手順を推論して実行するよりも、スクリプトを実行する方が安価です。例えば、PDF スキルでは、毎回コードを再導出するのではなく、Claude が毎回実行するフォーム入力用スクリプトを提供できます。
- 必要な頻度以上にルーチンを実行しない:監視対象が変化する頻度に合わせて間隔を設定してください
- 使用状況を確認する:
/usageコマンドでは、スキル、サブエージェント、MCP(Model Context Protocol)ごとの直近の使用状況を内訳表示します。引数なしの/goalコマンドでは、これまでのターン数とトークン使用量を表示し、/workflowsコマンドでは各エージェントのトークン使用状況を確認できます。また、いつでもエージェントを停止可能です。
始めに
要約すると:
- Loop(ループ): あなたが引き渡すもの - Turn-based(ターンベース): チェック - Use it when(使用するタイミング): 探索中または決定中 - Reach for(目指すべきもの): カスタム検証スキル
- Loop(ループ): あなたが引き渡すもの - Goal-based(ゴールベース): 停止条件 - Use it when(使用するタイミング): 完了の状態を知っている場合 - Reach for(目指すべきもの):
/goal
⟦CODE_0⟧
時間ベース
トリガー
作業はプロジェクト外でスケジュール通りに発生します
/loop, /schedule
能動的
プロンプト
作業は反復的で明確に定義されています
上記すべてに加え、動的ワークフローも利用可能です
ループの活用を始めるには、すでに実施している作業を見直してください。あなたがボトルネックとなっているタスクを一つ選び、どの部分を任せることができるか考えてみてください:検証チェックを書くことはできますか?目標は明確ですか?作業はスケジュール通りに届きますか?
アイデアが浮かんだら、ループを実行し、どこで停滞するかや過度に拡張していないかなど結果を観察してください。そして、それを反復して改善することに恐れる必要はありません。
詳細については、Claude Code のドキュメントにある「並列実行されるエージェント」running agents in parallel や、「ループ」loop、「スケジュール」schedule、「ゴール」goal、そして「動的ワークフロー」dynamic workflows のページをご覧ください。
*本記事は Delba de Oliveira と Michael Segner によって執筆されました*
原文を表示
Turn-based loops
- Triggered by: A user prompt.
- Stop criteria: Claude judges it has completed the task or needs additional context.
- Best used for: Shorter tasks that are not part of a regular process or schedule.
- Managed usage by: Write specific prompts and improve verification using skills to reduce the number of turns.
Every prompt you send starts a manual loop with you directing each turn. Claude gathers context, takes action, checks its work, repeats if needed, and responds. We call this the agentic loop.
For example, ask Claude to create a like button. It reads your code, makes the edit, runs the tests, and hands back something it *believes* works. You then manually check the work, and write the next prompt.
You can improve the verification step by encoding your manual steps as a SKILL.md so Claude can check more of its own work, end-to-end. This should include tools or connectors to allow Claude to *see*, *measure* or *interact* with the result. The more quantitative the checks are, the easier it is for Claude to self-verify.
For example, in your SKILL.md file you may specify:
---
name: verify-frontend-change
description: Verify any UI change end-to-end before declaring it done.
---
# Verifying frontend changes
Never report a UI change as complete based on a successful edit alone. Verify it the way a human reviewer would:
1. Start the dev server and open the edited page in the browser.
2. Interact with the change directly. For a new control (button, input, toggle): click it, confirm the expected state change, and screenshot before/after.
3. Check the browser console: zero new errors or warnings.
4. Use the Chrome Devtools MCP, run a performance trace and audit Core Web Vitals.
If any step fails, fix the issue and rerun from step 1 — do not hand back partially verified work.
Goal-based loop (/goal)
- Triggered by: A manual prompt in real-time.
- Stop criteria: Goal achieved OR maximum number of turns reached.
- Best used for: Tasks that have verifiable exit criteria.
- Managed usage by: Setting a specific completion criteria and explicit turn caps, “stop after 5 tries.”
Sometimes, a single turn is not enough, especially for more complex tasks. Agents do better when they can iterate. You can extend how long Claude keeps iterating by defining what done looks like with /goal.
When you define the success criteria, Claude doesn’t have to make a determination on what is “good enough” and end the loop early. Each time Claude tries to stop, an evaluator model checks your condition and sends it back to work until the goal is met or a number of turns you define is reached.
This is why deterministic criteria, such as number of tests passed or clearing a certain score threshold, are so effective.
For example:
/goal get the homepage Lighthouse score to 90 or above, stop after 5 tries.Time-based loop (/loop and /schedule)
- Triggered by: A specified time interval.
- Stop criteria: You cancel it, or the work completes (the PR merges, the queue is empty).
- Best used for: For recurring work, or interfacing with external environments / systems.
- Managed usage by: Set longer intervals or react based on events rather than time.
Some agentic work is recurring: the task stays the same and only the inputs change. For example, summarizing Slack messages every morning. Other work depends on external systems, and a simple way to interface with one is to check it on an interval and react to what changed. For example, a PR which may receive code reviews or fail CI.
For these, you can trigger when Claude runs with /loop which re-runs a prompt on an interval. For example:
/loop 5m check my PR, address review comments, and fix failing CI/loop runs on your computer, so if you turn it off, it stops. You can move the loop to the cloud by creating a routine with /schedule.
Proactive loops
- Triggered by: An event or schedule, with no human in real time.
- Stop criteria: Each task exits when its goal is met. The routine itself runs until you turn it off.
- Best used for: Recurring streams of well-defined work: bug reports, issue triage, migrations, dependency upgrades, etc.
- Managed usage by: Routing routines to smaller, faster models and using the most capable model for judgment calls.
The primitives above, along with other Claude Code features like auto mode and dynamic workflows (research preview) can be composed into a loop for long-running work.
For example, to handle incoming feedback, you can use:
/schedule(research preview) to run a routine that checks for new reports/goalto define what done looks and skills to document how to verify it- Dynamic workflows to orchestrate agents that triage each report, fix it, and review the fix
- Auto mode so the routine runs without stopping to ask for permission
Putting it together, a prompt could look like this:
/schedule every hour: check #project-feedback for bug reports. /goal: don't stop until every report found this run is triaged, actioned, and responded to. When fixing a bug, use a workflow to explore three solutions in parallel worktrees and have a judge adversarially review them.Maintaining code quality
The quality of a loop’s output depends on the system around it. When designing the system:
- Keep the codebase itself clean: Claude follows patterns and conventions that already exist in your codebase.
- Give Claude a way to verify its own work: Encode what good looks like for you and your team with skills.
- Make docs easy to reach: Frameworks and libraries docs have up-to-date best practices.
- Use a second agent for code reviews: A reviewer with fresh context is less biased and not influenced by the main agent’s reasoning. You can use the built-in
/code-reviewskill or Code Review for Github.
When an individual result doesn’t meet the standard, don’t stop at fixing the individual issue, try to encode it to improve the system for all future iterations.
Managing token usage
To manage token usage, loops should have clear boundaries:
- Choose the right primitive and model for the job: Smaller tasks don’t need multiple agents or loops. Some tasks can use cheaper and faster models.
- Define clear success and stop criteria: Be specific about what done looks like so Claude can arrive at the solution sooner (but not too soon).
- Pilot before a large run: Dynamic workflows can spawn hundreds of agents. Gauge usage on a smaller slice of the work first.
- Use scripts for deterministic work: Running a script is cheaper than reasoning through the steps. For example, a PDF skill can ship a form-filling script that Claude runs each time, instead of re-deriving the code.
- Don’t run routines more often that you need to: Match the interval to how often the thing you’re watching changes
- Review usage: The
/usagecommand breaks down recent usage by skills, subagents, and MCPs,/goalwith no arguments shows number of turns and token usage so far,/workflowsshows each agent’s token usage and you can stop an agent at any time.
Getting started
To summarize:
To get started with loops, look at the work you already do. Pick one task where you’re the bottleneck and ask which piece you could hand off: can you write the verification check? Is the goal clear enough? Does the work arrive on a schedule?
Once you have an idea, run the loop, observe the results like where it stalls or over-reaches, and don’t be afraid to iterate on it.
For more information, read the Claude Code docs on running agents in parallel, as well as the loop, schedule, goal, and dynamic workflows pages.
*This article was written by Delba de Oliveira and Michael Segner*
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み