AI時代にどのようなデータが企業の資産になるのか
Algomatic CEO は、AI 時代におけるデータ資産の定義が、従来の構造化データから非構造化データや文脈を含むデータへとシフトする必要があると指摘している。
キーポイント
構造化データの限界と過去のアプローチ
過去の DX やディープラーニング時代は、顧客 ID をキーにしたトランザクションやログといった「整然とした構造化データ」を貯めることが資産の源泉と考えられていた。
AI 時代の新たなデータ資産の定義
生成 AI の普及により、単なる数値やログだけでなく、文脈を理解し推論に活用できる非構造化データこそが真の資産として再評価されるべきである。
技術基盤の変遷と人材ニーズの変化
Hadoop や Spark による分散処理でビッグデータを扱う時代から、LLM を活用して多様なデータを統合・分析する新しいスキルセットが求められている。
非構造データの価値と技術的転換点
企業のデータの8割を占める非構造データ(文書、画像など)は、埋め込み技術やTransformerモデルの進化により「意味を持った数値」へ変換され、機械が理解・処理可能な資産となった。
基盤インフラの進化による実用化
スキーマを事前に定義する必要がないデータレイクの普及と、意味の近さで検索できるベクトルデータベースの登場により、非構造データを貯蔵・活用する土壌が整った。
生成AI時代における新たな課題
単なる類似文書の検索(RAG)を超え、異なるデータ間の複雑な「関係性」や因果関係を推論できる仕組みの必要性が浮き彫りになっている。
AI投資が経営指標に直結しない理由
データやAIツールを整備しても、組織体制や業務プロセスが変わらなければ売上や生産性といった経営指標への効果は現れにくい。
影響分析・編集コメントを表示
影響分析
この記事は、企業が長年築き上げてきた「構造化データ中心」の資産観を見直すよう促しており、生成 AI の実装においてデータの質と種類を再定義する重要性を浮き彫りにしています。企業にとっては、単なるデータ蓄積から、LLM が処理・推論可能な形でデータを整備・活用する戦略への転換が急務であることを示唆しています。
編集コメント
技術的な詳細よりも、経営視点での「データの資産価値」の再定義に焦点を当てた良質な記事です。生成 AI の普及に伴い、企業は従来のデータ戦略を見直す必要があります。

こんにちは、AI 時代の企業 OS をつくっています、Algomatic CEO の鴨居です。
今回は弊社で取り組んでいる『Algomatic 初夏のアドベントカレンダー』の最終日です!
アドカレとしては最後の記事ですが、7 月以降もテックブログは更新されていきます。ぜひこれからも見にきていただけると嬉しいです!
前回の記事はこちら👇
さて本日のテーマは企業が蓄積すべきデータについてです。AI 時代にはデータが命だということは、いまやあらゆる場面で語られています。実は、データがここまで重要視されるようになったのは 10 年以上前のことで、当時は「データは新しい石油である」なんて言われたりもしていました。
ただ、ひとくちにデータと言っても、その種類はさまざまです。本記事では、AI 時代に「資産」となるデータとはどういうものなのかを、これまでの歴史をたどりながら紐解いていきたいと思います。最後には、少しだけ角度を変えた問いも置いてみます。
これまで企業が集めてきたのは「構造化データ」だった
ふりかえってみると、これまでの DX(デジタルトランスフォーメーション)、そしてディープラーニングが盛り上がった第三次 AI ブームの時代、企業の関心はとてもはっきりしていました。まず「データを貯める箱」をつくることです。データウェアハウス(DWH)を整え、それでは足りないとなればデータレイクを構築する。そうやって貯められていたのは、その多くが行と列にきれいに整形された構造化データでした。
たとえば、顧客 ID がひとつあって、それに紐づく形で、
- そのお客様が Web サービス上で起こしたトランザクションデータ(いつ・何を・いくらで購入したか)
- アプリの操作ログや位置情報といった、ユーザーの行動データ
がずらりと並んでいる。こうしたデータを顧客 ID をキーに突き合わせて、「この行動をとった人は解約しやすい」「この層は次にこれを買いやすい」といった分析につなげていく。テーブルとカラムで扱えるデータを集めて掛け合わせることが、価値を生む王道でした。

そして、こうした大規模なテーブルデータの処理がビジネス上でも重要視されるようになり、Hadoop や Spark といった分散処理の仕組みが生まれてきました。1 台のマシンではとてもさばけない量のデータを、何十台ものマシンに分散して一気に処理する。この技術が、ビッグデータ活用の土台になりました。
かくいう私自身も、当時はデータサイエンティストとして、こうしたビッグデータを扱う側にいました。余談ですが、私がいた現場では、Python から Spark を操る PySpark を書きこなせるデータサイエンティストや、EMR(クラウド上の分散処理基盤)のパフォーマンスチューニングで処理コストをぐっと下げられるエンジニアが、とても重宝されていたのを覚えています。
この時代の「資産観」を一言でいうと、整然と構造化されたデータこそが価値の源泉だ、というものでした。
もっとも、現場で手を動かしていた立場から正直に言うと、その多くは活用されないまま眠っていました。せっかく貯めた石油が、精製されないままタンクの底に溜まっていく。そんな感覚を、当時を過ごした方なら少し共感していただけるかもしれません。
技術の進歩により、非構造データの価値が見出された
ニューラルネットワークやディープラーニングなどの技術的な台頭により、テーブルデータ以外の非構造データにも注目が集まるようになりました。
一説には、企業のなかにあるデータの 8 割以上は非構造データだとも言われます。それなのに私たちは長いあいだ、扱いやすい構造化データばかりを見てきました。
非構造データというのは、たとえばこういうものです。
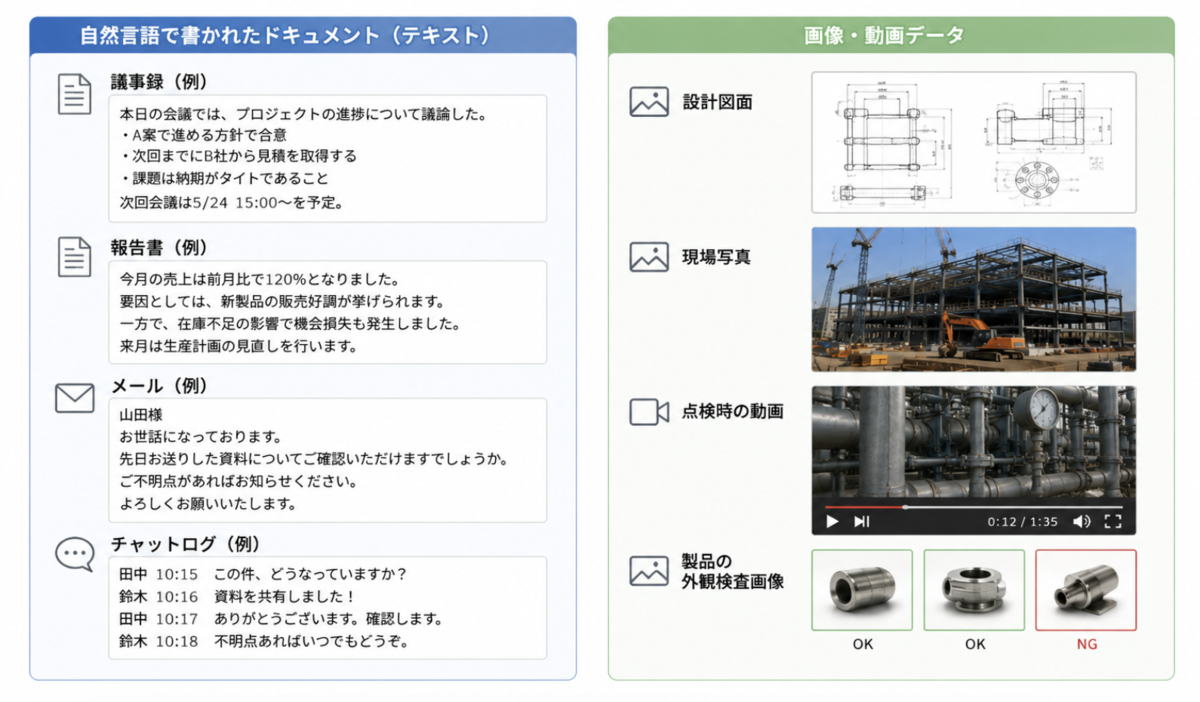
- 自然言語で雑多に書かれたドキュメント:議事録、報告書、提案書、マニュアル、契約書、メール、チャットのログ。フォーマットも粒度もバラバラで、人が読むことを前提に書かれた文章たちです。
- 画像・動画データ:設計図面、現場写真、点検時の動画、製品の外観検査画像など。
これらはテーブルにきれいには収まりません。だから従来は、分析の対象から外れていました。ところが自然言語処理技術の登場で、機械がこうした「人間向けの情報」をある程度読めるようになりました。
では、何がこの状況を変えたのでしょうか。鍵になったのは、非構造データを「意味を持った数値(ベクトル)」に変換できるようになった、という技術的な進歩でした。
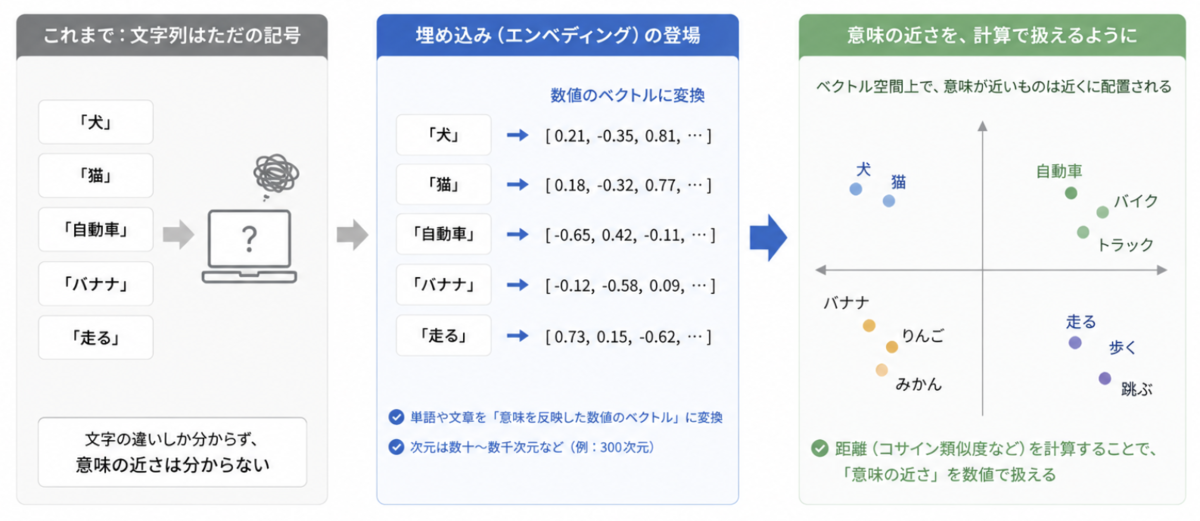
大元なる技術進化は、埋め込み(エンベディング)の登場です。2013 年の Word2Vec あたりから、単語や文章を「意味を反映した数値のベクトル」に変換できるようになりました。それまで機械にとって文字列はただの記号でしたが、これで「意味の近さ」を計算で扱えるようになります。
その後、2017 年あたりから Transformer という仕組みが登場し、それを使った BERT(2018 年)などの事前学習モデルに注目が集まりました。大量の文章を前もって学習させることで、文脈をふまえて言葉を理解する精度が一気に上がりました。これは GPT モデルのベースにもなっている技術です。また、画像のほうも、ディープラーニング(CNN)などによりデータに価値を見出すことができるようになっていました。
ここまではモデル側、つまり「機械が意味を読めるようになった」話です。これと両輪だったのが、データ基盤側の進化でした。
まずデータレイクの普及です。従来のDWH(データウェアハウス)は「先にスキーマ(表の形)を決めてから入れる」仕組みだったので、形の定まらない文書や画像は入れづらかった。これに対してデータレイクは、PDFでも画像でもログでも、とりあえず生のまま安く放り込んでおける(スキーマ・オン・リード)。非構造データの「置き場所」が、ここでようやくできました。
そして非構造データの活用に直結したのが、ベクトルデータベース/ベクトル検索です。埋め込みで数値化した文書を貯めておき、「意味の近いもの」を高速に探し出す。これが生成AI時代によく語られるRAG(Retrieval-Augmented Generation)の基盤技術です。
こうして、モデルが「意味を読めるようになった」のと、基盤が「大量の非構造データを貯めて・取り出せるようになった」のが同じ時期に噛み合い、非構造データはようやく“実務で使える資産候補”になったのです。
構造データや非構造データの活用が進みましたが、生成AI時代はそれだけでは不足するユースケースが出てきました。例えば、非構造データをベクトル化してRAGで返せるようになりましたが、似た文章は見つけられても、データとデータの“関係”をたどって推論することはできません。「この顧客の契約はどの製品に紐づき、その製品はいまどの障害の影響を受けているのか」といった、つながりを追う問いには弱いのです。
そこで次のデータ資産として語られるようになったのが、オントロジーです。米国のPalantirが「企業のオントロジー」という概念を前面に出してきたことが、この流れを象徴しています。
オントロジーは「会社の地図」
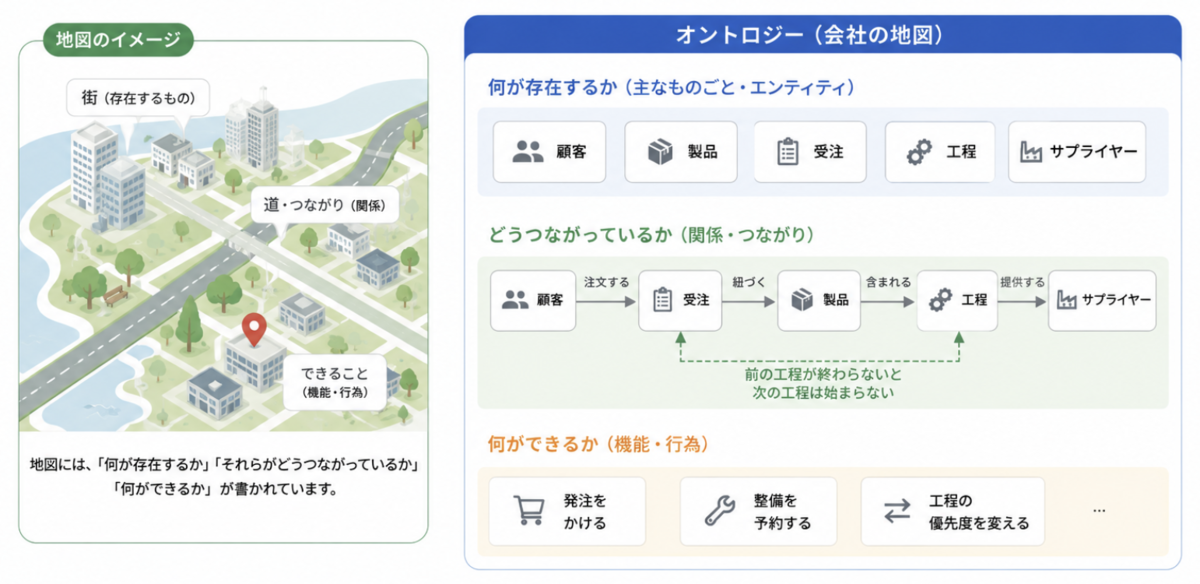
オントロジーと聞くと難しそうですが、本質はシンプルです。私は、「会社の地図」だと捉えるのがいちばん分かりやすいと思っています。
地図には、「何が存在するか(街など)」と、「それらがどうつながっているか」、そして「何ができるか」が書いてあります。
オントロジーも同じで、自分の会社について、
- 何が存在するか:顧客、製品、受注、工程、サプライヤー
- どうつながっているか:この受注はこの製品に紐づく、この工程は前の工程が終わらないと始まらない
- 何ができるか:発注をかける、整備を予約する、工程の優先度を変える
「名詞」に対応する「動詞」を与える
Palantirがよく使う、もう一つ分かりやすい説明があります。オントロジーは「名詞」と「動詞」でできている、というものです。
まず名詞は、「存在するモノ」です。顧客、製品、受注、工程……。これらを、ただのデータとしてではなく「現実に存在するモノ」として定義し、つながりも一緒に持たせます。たとえば、こんな具合です。
**〈顧客A〉は法人顧客です
〈顧客A〉は〈契約123〉を持っています
〈契約123〉は〈製品X〉に紐づいています
〈製品X〉はいま〈障害K〉の影響を受けています
〈障害K〉は〈FAQ記事F〉で説明されています
ポイントは、個々のデータを「点」として置くだけでなく、データ同士の「関係」も一緒に持っていることです。こうしておくと、AI は「似た文章」を探すのではなく、つながりを辿って推論できます。「顧客 A から問い合わせが来た」という一報から、契約 → 製品 → 障害 → 対処法まで一気に引き当てられる、というわけです。
ただ、名詞だけだと「見えるだけ」で終わってしまいます。そこで効いてくるのが動詞**、つまり業務上のアクションです。「発注する」「承認する」「優先度を変える」。これらが名詞と組み合わさって、はじめて「この受注を承認する」という"文"になります。そしてこの動詞を実行すると、分析画面の中だけで終わらず、実際の調達システムや生産管理システムに書き戻される。「見るだけ」から「動かす」へ、という進化です。
なぜ生成 AI と相性がいいのか
オントロジーが生成 AI 時代に重視されるのは、AI に「データ」ではなく「文脈」を渡せるからです。
たとえばデータベースに ord_amt という列があって、AI に「これは 1000 です」と渡しても、何の金額なのか分かりません。でもオントロジー越しなら、「取引先 A の今月の注文金額が 100 万円で、先月比 30% 増。しかもその取引先は来週納期の案件を 3 件抱えている」と、業務上の意味とセットで渡せます。AI の答えが、一気に実用的になるわけです。
ほかにも、「この関係は存在する/しない」を明示できるので幻覚(ハルシネーション)を抑えやすかったり、同じ一人の人物を、営業から見れば「有望な見込み客」、サポートから見れば「クレーム履歴のある要注意顧客」というように、部門ごとの意味を矛盾なく重ねられたりします。
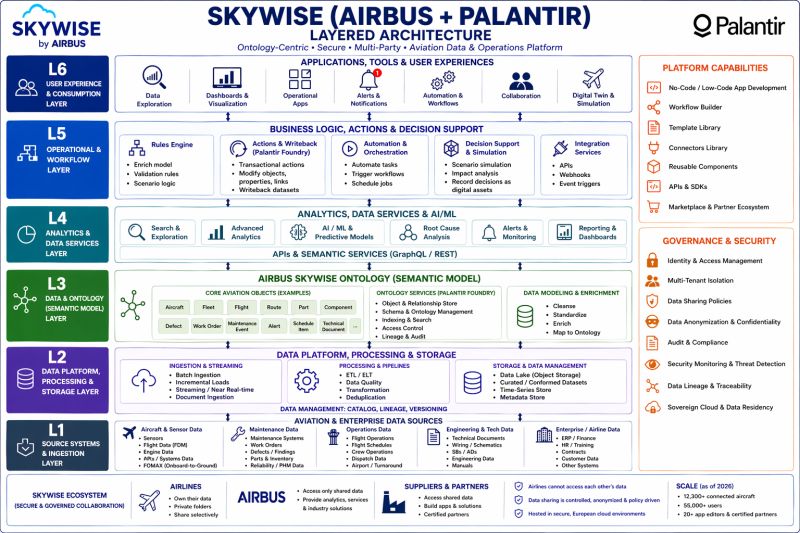
分かりやすい実例が、Airbus です。1 機あたり約 500 万個の部品からなる A350 は、かつて「完成まで全体像を誰も把握できない」状態でした。そこに Palantir が入り、バラバラだったデータを「ひとつの飛行機」という地図として立ち上げた結果、納入スピードが 33% 向上したと言われています。魔法のような AI を使ったわけではなく、自社の業務世界を丁寧に地図にしたことが効いた、という話です。
ここまでが、「生成 AI 時代の資産は、オントロジー化された業務データである」という、いまのところの通説です。
では、そのデータはどう「資産」として活かすべきか
さて、ここで少し角度を変えた問いを置いてみたいと思います。
オントロジー化された業務データは、どうすれば本当に「資産」として活きるのでしょうか。
というのも、日本企業の現場を見ていると、気になる景色があるからです。AI ツールを契約し、開発会社にも協力してもらいながら AI エージェント開発を進める。やればやるほど、コストは積み上がっていきます。 けれども、売上・利益・一人あたり生産性といった経営指標には、なかなかヒットしてこない。いま多くの企業が、この壁の前に立っているように見えます。
なぜ、これだけ整えても経営指標に効かないのでしょうか。私は、理由はわりとシンプルだと思っています。
データと AI を整えても、組織がそのままだからです。
たとえば、AI がある業務の 3 割を巻き取れるようになったとします。けれど、その 3 割分の人員配置も役割もまったく変わらなければ、コストは減っていません。むしろ、人が今まで通りやっている仕事の横で、AI の利用料がそのまま上乗せされます。いわば二重コストの状態です。これでは、経営指標がよくなりにくいのも無理はありません。
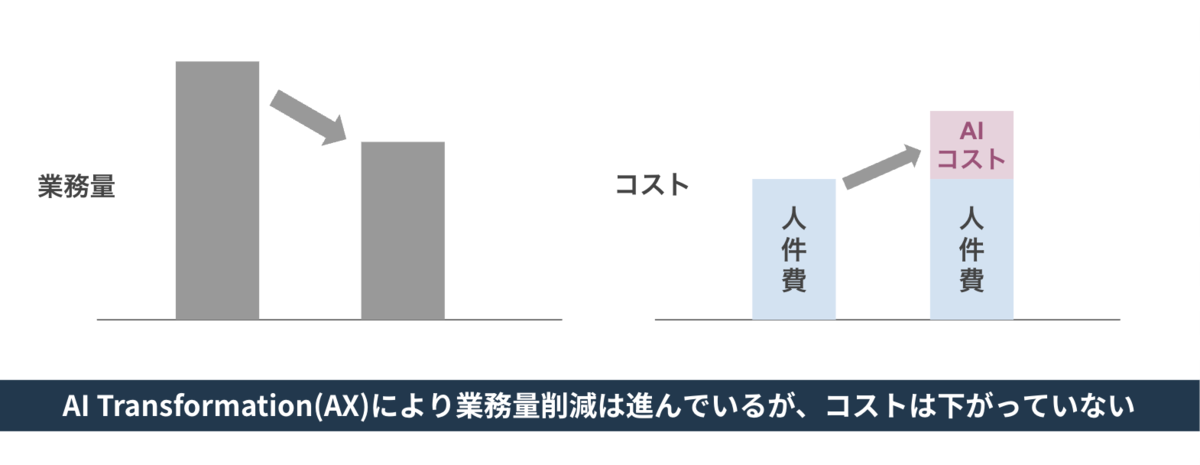
だから AI を本当に効かせるには、人の再配置を伴う組織の最適化が、どうしても必要になります。AI に任せられる業務を見極めて、人の役割を定義し直し、空いた人を付加価値の高い仕事へ動かす。ここまでやって、ようやくコスト構造が変わり、経営指標が動き始めます。
そう考えたとき、オントロジーには、もう一つの使い道が見えてきます。「人と AI の役割を、どう組み替えるか」を考えるためのデータとしての使い道です。
一般的な人事異動や組織編成は、「この部署にはこういう業務がある。だからこそ、こういうスキルを持った人が必要だ」という考え方で組まれていきます。業務とスキルが、ある程度ひも付いていることが前提になっているわけです。
ところが、AI Transformation(AI 変革)が進むと、この前提が揺らぎます。ある業務に必要なスキルそのものが、変わってしまうことがあるのです。
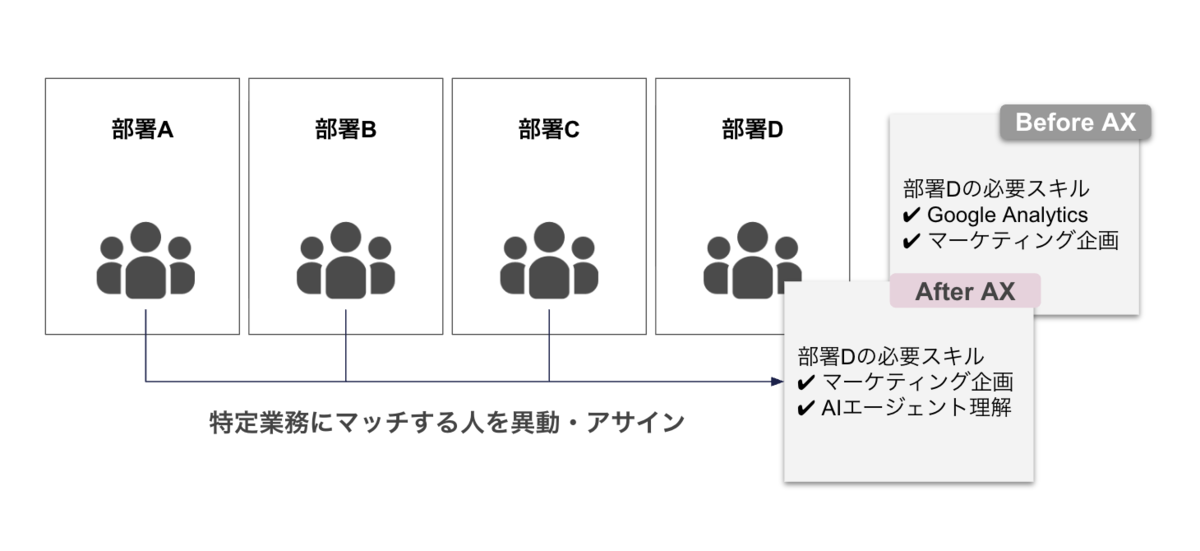
たとえば、AWS 上で動くシステムの保守運用を担っている人を考えてみます。これまでは、AWS の各サービスの細かい仕様や、障害が起きたときの切り分け手順を、知識として深く持っていることが何より大事でした。ところが、こうした監視や一次対応、定型的な復旧作業を、AI エージェントがかなりの部分こなせるようになってきています。すると、その業務で求められるものが変わってきます。AWS そのものの細かな知識を覚えていること以上に、「AI エージェントに何をどこまで任せ、その判断や出力をどう検証するか」「エージェントでは捌けない例外や、システム全体の設計をどう決めるか」といった力のほうが効いてくる。同じ「システムを保守運用する」という業務でも、必要なスキルが大きく入れ替わるのです。
こうした「業務 × スキル」の組み替えを、勘や肌感覚だけで追いかけるのは、なかなか大変です。だからこそ、業務の構造そのものをデータとして持っているオントロジーが効いてきます。
オントロジー、つまり業務の「名詞」と「動詞」と「つながり」を構造化したデータがあれば、どの業務の、どの操作を、人がやり、どこからを AI に委ねるのかを、地図の上にマッピングできます。「この受注の承認は人が、与信チェックは AI が」「この問い合わせの一次対応は AI が、例外処理は人が」というように、役割の境界を業務の地図の上に引いていく。すると、「この業務は AI 主導に切り替わったから、人にはこちらのスキルが要る」という再配置の判断を、データにもとづいて下せるようになります。
そして大事なのは、それを年に一度の大きな組織改編ではなく、四半期くらいの短いスパンで、人事異動に反映できるデータとして回していくことだと思います。AI の能力は数か月単位で変わります。だとすれば、人と AI の分担も、必要なスキルも、組織のかたちも、同じくらいの速さで更新し続けたいところです。
データそのものに価値があるというより、オントロジーが「人と AI の役割を定義し、組織を短いサイクルで最適化し続ける」運用に組み込まれてはじめて、資産になる。墓場で眠るデータと、生きた資産を分けるのは、技術そのものよりも、それを組織の意思決定にどうつなげるか、なのだと思います。
おわりに
企業のデータ活用の歴史は、構造化データから非構造データへ、そしてオントロジーへと、確かに重心を移してきました。
ただ、日本企業における本当の勝負どころは、そのデータをどう組織変革に生かすかだと思います。AI と人の役割を明確にして、組織のかたちを最適化し続けられるかどうか。 そこに、企業の競争力としていちばん大きな差が出るように思います。
データを貯めた会社でも、AI を導入した会社でもなく、それを使って自社の組織を絶え間なくつくりかえていける会社が、これからの時代を生き残っていく。AI 時代に資産になるのは、突き詰めると、その「つくりかえる力」そのものなのかもしれません。
エンジニアを募集しています!
ここまで読んでいただきありがとうございました!
Algomatic では、「AI 時代の企業 OS をつくる」をミッションに、変化の速い領域で大きな取り組みにチャレンジしたいエンジニアを募集しています。
少しでもご興味をお持ちいただけましたら、カジュアル面談に足を運んでいただけるとうれしいです!
原文を表示
こんにちは、AI時代の企業OSをつくっています、 Algomatic CEOの鴨居です。
今回は弊社で取り組んでいる『Algomatic 初夏のアドベントカレンダー』の最終日です!
アドカレとしては最後の記事ですが、7月以降もテックブログは更新されていきます。ぜひこれからも見にきていただけると嬉しいです!
前回の記事はこちら👇
さて本日のテーマは企業が蓄積すべきデータについてです。AI時代にはデータが命だということは、いまやあらゆる場面で語られています。実は、データがここまで重要視されるようになったのは10年以上前のことで、当時は「データは新しい石油である」なんて言われたりもしていました。
ただ、ひとくちにデータと言っても、その種類はさまざまです。本記事では、AI時代に「資産」となるデータとはどういうものなのかを、これまでの歴史をたどりながら紐解いていきたいと思います。最後には、少しだけ角度を変えた問いも置いてみます。
これまで企業が集めてきたのは「構造化データ」だった
ふりかえってみると、これまでのDX、そしてディープラーニングが盛り上がった第三次AIブームの時代、企業の関心はとてもはっきりしていました。まず「データを貯める箱」をつくることです。データウェアハウス(DWH)を整え、それでは足りないとなればデータレイクを構築する。そうやって貯められていたのは、その多くが行と列にきれいに整形された構造化データでした。
たとえば、顧客IDがひとつあって、それに紐づく形で、
- そのお客様がWebサービス上で起こしたトランザクションデータ(いつ・何を・いくらで購入したか)
- アプリの操作ログや位置情報といった、ユーザーの行動データ
がずらりと並んでいる。こうしたデータを顧客IDをキーに突き合わせて、「この行動をとった人は解約しやすい」「この層は次にこれを買いやすい」といった分析につなげていく。テーブルとカラムで扱えるデータを集めて掛け合わせることが、価値を生む王道でした。
そして、こうした大規模なテーブルデータの処理がビジネス上でも重要視されるようになり、HadoopやSparkといった分散処理の仕組みが生まれてきました。1台のマシンではとてもさばけない量のデータを、何十台ものマシンに分散して一気に処理する。この技術が、ビッグデータ活用の土台になりました。
かくいう私自身も、当時はデータサイエンティストとして、こうしたビッグデータを扱う側にいました。余談ですが、私がいた現場では、PythonからSparkを操るPySparkを書きこなせるデータサイエンティストや、EMR(クラウド上の分散処理基盤)のパフォーマンスチューニングで処理コストをぐっと下げられるエンジニアが、とても重宝されていたのを覚えています。
この時代の「資産観」を一言でいうと、整然と構造化されたデータこそが価値の源泉だ、というものでした。
もっとも、現場で手を動かしていた立場から正直に言うと、その多くは活用されないまま眠っていました。せっかく貯めた石油が、精製されないままタンクの底に溜まっていく。そんな感覚を、当時を過ごした方なら少し共感していただけるかもしれません。
技術の進歩により、非構造データの価値が見出された
ニューラルネットワークやディープラーニングなどの技術的な台頭により、テーブルデータ以外の非構造データにも注目が集まるようになりました。
一説には、企業のなかにあるデータの8割以上は非構造データだとも言われます。それなのに私たちは長いあいだ、扱いやすい構造化データばかりを見てきました。
非構造データというのは、たとえばこういうものです。
- 自然言語で雑多に書かれたドキュメント:議事録、報告書、提案書、マニュアル、契約書、メール、チャットのログ。フォーマットも粒度もバラバラで、人が読むことを前提に書かれた文章たちです。
- 画像・動画データ:設計図面、現場写真、点検時の動画、製品の外観検査画像など。
これらはテーブルにきれいには収まりません。だから従来は、分析の対象から外れていました。ところが自然言語処理技術の登場で、機械がこうした「人間向けの情報」をある程度読めるようになりました。
では、何がこの状況を変えたのでしょうか。鍵になったのは、非構造データを「意味を持った数値(ベクトル)」に変換できるようになった、という技術的な進歩でした。
大元なる技術進化は、埋め込み(エンベディング)の登場です。2013年のWord2Vecあたりから、単語や文章を「意味を反映した数値のベクトル」に変換できるようになりました。それまで機械にとって文字列はただの記号でしたが、これで「意味の近さ」を計算で扱えるようになります。
その後、2017年あたりからTransformerという仕組みが登場し、それを使ったBERT(2018年)などの事前学習モデルに注目が集まりました。大量の文章を前もって学習させることで、文脈をふまえて言葉を理解する精度が一気に上がりました。これはGPTモデルのベースにもなっている技術です。また、画像のほうも、ディープラーニング(CNN)などによりデータに価値を見出すことができるようになっていました。
ここまではモデル側、つまり「機械が意味を読めるようになった」話です。これと両輪だったのが、データ基盤側の進化でした。
まずデータレイクの普及です。従来のDWHは「先にスキーマ(表の形)を決めてから入れる」仕組みだったので、形の定まらない文書や画像は入れづらかった。これに対してデータレイクは、PDFでも画像でもログでも、とりあえず生のまま安く放り込んでおける(スキーマ・オン・リード)。非構造データの「置き場所」が、ここでようやくできました。
そして非構造データの活用に直結したのが、ベクトルデータベース/ベクトル検索です。埋め込みで数値化した文書を貯めておき、「意味の近いもの」を高速に探し出す。これが生成AI時代によく語られるRAGの基盤技術です。
こうして、モデルが「意味を読めるようになった」のと、基盤が「大量の非構造データを貯めて・取り出せるようになった」のが同じ時期に噛み合い、非構造データはようやく“実務で使える資産候補”になったのです。
構造データや非構造データの活用が進みましたが、生成AI時代はそれだけでは不足するユースケースが出てきました。例えば、非構造データをベクトル化してRAGで返せるようになりましたが、似た文章は見つけられても、データとデータの“関係”をたどって推論することはできません。「この顧客の契約はどの製品に紐づき、その製品はいまどの障害の影響を受けているのか」といった、つながりを追う問いには弱いのです。
そこで次のデータ資産として語られるようになったのが、オントロジーです。米国のPalantirが「企業のオントロジー」という概念を前面に出してきたことが、この流れを象徴しています。
オントロジーは「会社の地図」
オントロジーと聞くと難しそうですが、本質はシンプルです。私は、「会社の地図」だと捉えるのがいちばん分かりやすいと思っています。
地図には、「何が存在するか(街など)」と、「それらがどうつながっているか」、そして「何ができるか」が書いてあります。
オントロジーも同じで、自分の会社について、
- 何が存在するか:顧客、製品、受注、工程、サプライヤー
- どうつながっているか:この受注はこの製品に紐づく、この工程は前の工程が終わらないと始まらない
- 何ができるか:発注をかける、整備を予約する、工程の優先度を変える
「名詞」に対応する「動詞」を与える
Palantirがよく使う、もう一つ分かりやすい説明があります。オントロジーは「名詞」と「動詞」でできている、というものです。
まず名詞は、「存在するモノ」です。顧客、製品、受注、工程……。これらを、ただのデータとしてではなく「現実に存在するモノ」として定義し、つながりも一緒に持たせます。たとえば、こんな具合です。
〈顧客A〉は法人顧客です
〈顧客A〉は〈契約123〉を持っています
〈契約123〉は〈製品X〉に紐づいています
〈製品X〉はいま〈障害K〉の影響を受けています
〈障害K〉は〈FAQ記事F〉で説明されています
ポイントは、個々のデータを「点」として置くだけでなく、データ同士の「関係」も一緒に持っていることです。こうしておくと、AIは「似た文章」を探すのではなく、つながりを辿って推論できます。「顧客Aから問い合わせが来た」という一報から、契約 → 製品 → 障害 → 対処法まで一気に引き当てられる、というわけです。
ただ、名詞だけだと「見えるだけ」で終わってしまいます。そこで効いてくるのが動詞、つまり業務上のアクションです。「発注する」「承認する」「優先度を変える」。これらが名詞と組み合わさって、はじめて「この受注を承認する」という"文"になります。そしてこの動詞を実行すると、分析画面の中だけで終わらず、実際の調達システムや生産管理システムに書き戻される。「見るだけ」から「動かす」へ、という進化です。
なぜ生成AIと相性がいいのか
オントロジーが生成AI時代に重視されるのは、AIに「データ」ではなく「文脈」を渡せるからです。
たとえばデータベースに ord_amt という列があって、AIに「これは1000です」と渡しても、何の金額なのか分かりません。でもオントロジー越しなら、「取引先Aの今月の注文金額が100万円で、先月比30%増。しかもその取引先は来週納期の案件を3件抱えている」と、業務上の意味とセットで渡せます。AIの答えが、一気に実用的になるわけです。
ほかにも、「この関係は存在する/しない」を明示できるので幻覚(ハルシネーション)を抑えやすかったり、同じ一人の人物を、営業から見れば「有望な見込み客」、サポートから見れば「クレーム履歴のある要注意顧客」というように、部門ごとの意味を矛盾なく重ねられたりします。
分かりやすい実例が、Airbusです。1機あたり約500万個の部品からなるA350は、かつて「完成まで全体像を誰も把握できない」状態でした。そこにPalantirが入り、バラバラだったデータを「ひとつの飛行機」という地図として立ち上げた結果、納入スピードが33%向上したと言われています。魔法のようなAIを使ったわけではなく、自社の業務世界を丁寧に地図にしたことが効いた、という話です。
ここまでが、「生成AI時代の資産は、オントロジー化された業務データである」という、いまのところの通説です。
[https://www.linkedin.com/posts/rammohanthiru_palantir-airbus-skywise-activity-7453256746145468416-CP92よりはいs](https://cdn-ak.f.st-hatena.com/images/fotolife/h/hktech/20260629/20260629145959.jpg)
では、そのデータはどう「資産」として活かすべきか
さて、ここで少し角度を変えた問いを置いてみたいと思います。
オントロジー化された業務データは、どうすれば本当に「資産」として活きるのでしょうか。
というのも、日本企業の現場を見ていると、気になる景色があるからです。AIツールを契約し、開発会社にも協力してもらいながらAIエージェント開発を進める。やればやるほど、コストは積み上がっていきます。 けれども、売上・利益・一人あたり生産性といった経営指標には、なかなかヒットしてこない。いま多くの企業が、この壁の前に立っているように見えます。
なぜ、これだけ整えても経営指標に効かないのでしょうか。私は、理由はわりとシンプルだと思っています。
データとAIを整えても、組織がそのままだからです。
たとえば、AIがある業務の3割を巻き取れるようになったとします。けれど、その3割分の人員配置も役割もまったく変わらなければ、コストは減っていません。むしろ、人が今まで通りやっている仕事の横で、AIの利用料がそのまま上乗せされます。いわば二重コストの状態です。これでは、経営指標がよくなりにくいのも無理はありません。
だからAIを本当に効かせるには、人の再配置を伴う組織の最適化が、どうしても必要になります。AIに任せられる業務を見極めて、人の役割を定義し直し、空いた人を付加価値の高い仕事へ動かす。ここまでやって、ようやくコスト構造が変わり、経営指標が動き始めます。
そう考えたとき、オントロジーには、もう一つの使い道が見えてきます。「人とAIの役割を、どう組み替えるか」を考えるためのデータとしての使い道です。
一般的な人事異動や組織編成は、「この部署にはこういう業務がある。だからこそ、こういうスキルを持った人が必要だ」という考え方で組まれていきます。業務とスキルが、ある程度ひも付いていることが前提になっているわけです。
ところが、AI Transformation(AI変革)が進むと、この前提が揺らぎます。ある業務に必要なスキルそのものが、変わってしまうことがあるのです。
たとえば、AWS上で動くシステムの保守運用を担っている人を考えてみます。これまでは、AWSの各サービスの細かい仕様や、障害が起きたときの切り分け手順を、知識として深く持っていることが何より大事でした。ところが、こうした監視や一次対応、定型的な復旧作業を、AIエージェントがかなりの部分こなせるようになってきています。すると、その業務で求められるものが変わってきます。AWSそのものの細かな知識を覚えていること以上に、「AIエージェントに何をどこまで任せ、その判断や出力をどう検証するか」「エージェントでは捌けない例外や、システム全体の設計をどう決めるか」といった力のほうが効いてくる。同じ「システムを保守運用する」という業務でも、必要なスキルが大きく入れ替わるのです。
こうした「業務 × スキル」の組み替えを、勘や肌感覚だけで追いかけるのは、なかなか大変です。だからこそ、業務の構造そのものをデータとして持っているオントロジーが効いてきます。
オントロジー、つまり業務の「名詞」と「動詞」と「つながり」を構造化したデータがあれば、どの業務の、どの操作を、人がやり、どこからをAIに委ねるのかを、地図の上にマッピングできます。「この受注の承認は人が、与信チェックはAIが」「この問い合わせの一次対応はAIが、例外処理は人が」というように、役割の境界を業務の地図の上に引いていく。すると、「この業務はAI主導に切り替わったから、人にはこちらのスキルが要る」という再配置の判断を、データにもとづいて下せるようになります。
そして大事なのは、それを年に一度の大きな組織改編ではなく、四半期くらいの短いスパンで、人事異動に反映できるデータとして回していくことだと思います。AIの能力は数か月単位で変わります。だとすれば、人とAIの分担も、必要なスキルも、組織のかたちも、同じくらいの速さで更新し続けたいところです。
データそのものに価値があるというより、オントロジーが「人とAIの役割を定義し、組織を短いサイクルで最適化し続ける」運用に組み込まれてはじめて、資産になる。墓場で眠るデータと、生きた資産を分けるのは、技術そのものよりも、それを組織の意思決定にどうつなげるか、なのだと思います。
おわりに
企業のデータ活用の歴史は、構造化データから非構造データへ、そしてオントロジーへと、確かに重心を移してきました。
ただ、日本企業における本当の勝負どころは、そのデータをどう組織変革に生かすかだと思います。AIと人の役割を明確にして、組織のかたちを最適化し続けられるかどうか。 そこに、企業の競争力としていちばん大きな差が出るように思います。
データを貯めた会社でも、AIを導入した会社でもなく、それを使って自社の組織を絶え間なくつくりかえていける会社が、これからの時代を生き残っていく。AI時代に資産になるのは、突き詰めると、その「つくりかえる力」そのものなのかもしれません。
エンジニアを募集しています!
ここまで読んでいただきありがとうございました!
Algomatic では、「AI時代の企業OSをつくる」をミッションに、変化の速い領域で大きな取り組みにチャレンジしたい エンジニアを募集しています。
少しでもご興味をお持ちいただけましたら、カジュアル面談に足を運んでいただけるとうれしいです!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み