G7eインスタンスでAmazon SageMaker AI上の生成AI推論を加速
AWSはSageMaker AI上でNVIDIA Blackwell GPUを搭載したG7eインスタンスをリリースし、大規模オープンソースLLMの推論コスト削減と高性能化を実現した。
キーポイント
Blackwell GPU搭載によるメモリ容量の倍増
NVIDIA RTX PRO 6000 Blackwell Server Edition GPUを採用し、1GPUあたり96GBのGDDR7メモリを提供。G6e比でGPUメモリが倍増し、単一ノードでの35Bパラメータモデル実行を可能にした。
柔軟なノード構成と大規模モデルのデプロイ
1〜8ノード構成に対応し、最大300Bパラメータのモデルを8GPUノードで実行可能。GPT-OSS-120BやQwen3.5などのオープンソース基盤モデルのホスティングに最適化されている。
推論パフォーマンスとネットワーク帯域の大幅向上
G6e比で最大2.3倍の推論速度を実現し、EFAネットワーク帯域を最大1600Gbpsへ拡張。これにより低遅延のマルチノード推論やファインチューニングが実用的なレベルに達した。
影響分析・編集コメントを表示
影響分析
本リリースは、クラウド上での大規模言語モデル推論インフラの標準を再定義するものとなる。Blackwell GPUと高速EFAネットワークの組み合わせにより、従来はオンプレミスや専用ハードウェアに依存していた大規模モデルの低コスト推論が、クラウド上でスケーラブルに実行可能になる。これにより、オープンソースAIエコシステムの普及と企業の実務導入が加速すると期待される。
編集コメント
推論特化型のクラウドGPUインスタンスがBlackwell世代へ移行し、メモリ帯域とネットワーク帯域の両面でボトルネックを解消した。今後は単一ノードでの大規模モデル実行が標準化し、推論コストの劇的な削減が見込まれる。
生成 AI (generative AI) への需要が高まる中、開発者や企業は自らのニーズに応えるため、より柔軟でコスト効率に優れ、高性能なアクセラレータを求めています。本日、Amazon SageMaker AI 上で NVIDIA RTX PRO 6000 Blackwell Server Edition GPU (NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs) を搭載した G7e インスタンス (G7e instances) の利用を開始できることを発表いたします。
1、2、4、8基の RTX PRO 6000 GPU を搭載したノードをプロビジョニングでき、各GPUには96 GBのGDDR7メモリ (GDDR7 memory) が搭載されています。今回のリリースにより、GPT-OSS-120B、Nemotron-3-Super-120B-A12B(NVFP4 バリアント)、Qwen3.5-35B-A3B といった強力なオープンソースのファウンデーションモデル(FMs)(foundation models (FMs)) をホストできる単一GPUノードの G7e.2xlarge インスタンスを使用する機能が提供され、組織に対してコスト効率と高性能を両立するオプションを提供します。これにより、推論ワークロード (inference workloads) において高いパフォーマンスを維持しつつコスト削減を図る方々に適しています。G7e インスタンスの主な特徴は以下の通りです:
- G6e インスタンスと比較してGPUメモリが2倍となり、FP16 (FP16) で最大以下の大規模言語モデル(LLMs)(large language models (LLMs)) のデプロイを可能にします:
35B parameter model on a single GPU node (G7e.2xlarge)
- 150B parameter model on a 4 GPU node (G7e.24xlarge)
- 300B parameter model on an 8 GPU node (G7e.48xlarge)
- ネットワークスループット (networking throughput) は最大1,600 Gbps
- G7e.48xlarge では最大768 GBのGPUメモリ
Amazon Elastic Compute Cloud(Amazon EC2)(Amazon Elastic Compute Cloud (Amazon EC2)) G7e インスタンスは、クラウドにおけるGPUアクセラレーションによる推論 (GPU-accelerated inference) において大きな飛躍を表しています。前世代の G6e インスタンスと比較して、最大2.3倍の推論パフォーマンスを実現します。各 G7e GPU は 1,597 GB/s の帯域幅を提供し、G6e のGPUメモリを2倍、G5 の4倍に拡大しています。最大サイズの G7e では EFA(Elastic Fabric Adapter)(EFA) によりネットワークが 1,600 Gbps にスケールし、G6e の4倍、G5 の16倍の向上となります。これにより、以前は Gシリーズインスタンス (G-series instances) では現実的ではなかった低レイテンシのマルチノード推論およびファインチューニング (fine-tuning) のシナリオが可能になります。以下の表は、8 GPUティアにおける世代間の進化をまとめたものです:
| 仕様 | G5 (g5.48xlarge) | G6e (g6e.48xlarge) | G7e (g7e.48xlarge) |
|---|---|---|---|
| GPU | 8x NVIDIA A10G | 8x NVIDIA L40S | 8x NVIDIA RTX PRO 6000 Blackwell |
| GPUメモリ(1基あたり) | 24 GB GDDR6 | 48 GB GDDR6 | 96 GB GDDR7 |
| 総GPUメモリ | 192 GB | 384 GB | 768 GB |
| GPUメモリ帯域幅 | 600 GB/s per GPU | 864 GB/s per GPU | 1,597 GB/s per GPU |
| vCPU数 | 192 | 192 | 192 |
| システムメモリ | 768 GiB | 1,536 GiB | 2,048 GiB |
| ネットワーク帯域幅 | 100 Gbps | 400 Gbps | 1,600 Gbps (EFA) |
| ローカルNVMeストレージ | 7.6 TB | 7.6 TB | 15.2 TB |
| 推論パフォーマンス(G6e比) | ベースライン | ~1x | 最大2.3倍
単一インスタンスで合計 768 GB の GPU メモリ(GPU Memory)を搭載する G7e は、従来 G5 や G6e でマルチノード構成(Multi-node Setup)を必要としていたモデルをホスト可能であり、運用の複雑さとノード間レイテンシ(Inter-node Latency)を低減します。第 5 世代 Tensor コア(Tensor Cores)による FP4 精度(FP4 Precision)のサポートと、EFAv4 を介した NVIDIA GPUDirect RDMA(GPUDirect RDMA)に対応していることから、G7e インスタンスは AWS 上での大規模言語モデル(LLM)、マルチモーダル AI、アジェンティック推論ワークロードのデプロイにおいて最適な選択肢として位置づけられています。
G7e に適したユースケース
G7e が備えるメモリ密度、帯域幅、ネットワーク機能の組み合わせは、幅広い現代の生成 AI ワークロードに適合しています。
- チャットボットおよび会話型 AI – G7e の低い TTFT(Time To First Token)と高いスループットにより、重い同時負荷下でもインタラクティブな体験が応答性を維持します。
- アジェンティックおよびツール呼び出しワークフロー – CPU から GPU への帯域幅が 4 倍向上した G7e は、取得ストアからの高速なコンテキスト注入が重要な Retrieval Augmented Generation(RAG)パイプラインやアジェンティックワークフローにおいて特に効果的です。
- テキスト生成、要約、ロングコンテキスト推論 – G7e の GPU あたり 96 GB のメモリは、拡張されたドキュメントコンテキスト用の大容量 KV キャッシュ(KV Cache)を収容可能であり、切り捨てを減らしながら長い入力に対する高度な推論を実現します。
- 画像生成およびビジョンモデル – 以前のインスタンスでは大規模なマルチモーダルモデルでメモリ不足エラー(Out-of-Memory Error)が発生する箇所において、G7e の倍増したメモリがこれらの制限を明確に解消します。
- フィジカル AI および科学計算 – G7e の Blackwell 世代のコンピューティング性能、FP4 サポート、空間計算機能(DLSS 4.0、第 4 世代 RT コア)により、デジタルツイン、3D シミュレーション、フィジカル AI モデルの推論への適用範囲が拡大します。
デプロイメントの手順
前提条件
SageMaker AI を使用してこのソリューションを試すには、以下の前提条件が必要です。
- すべての AWS リソースを格納する AWS アカウント。
- Amazon SageMaker AI にアクセスするための AWS Identity and Access Management(IAM)ロール。IAM が SageMaker AI とどのように連携するか詳しくは、「Amazon SageMaker AI 用の Identity and Access Management」をご覧ください。
- Amazon SageMaker Studio、SageMaker ノートブックインスタンス、または PyCharm や Visual Studio Code などのインタラクティブ開発環境(IDE)へのアクセス権限。シンプルなデプロイメントと推論には Amazon SageMaker Studio の使用を推奨します。
- Amazon SageMaker AI エンドポイント使用のための ml.g7e.2xlarge [またはそれ以上] インスタンス 1 つ分のクォータ。Service Quotas コンソールを通じてクォータの増加分をリクエストできます。
デプロイメント
リポジトリをクローンし、こちら で提供されているサンプルノートブックを使用できます。
パフォーマンスベンチマーク
世代間の改善を定量化するため、G6eおよびG7eインスタンスでQwen3-32B(BF16)のベンチマークを、同一ワークロード(リクエストあたり入力トークン約1,000個、出力トークン約560個)を用いて実施しました。これは文書の要約や修正タスクを代表するものです。両方の構成とも、プレフィックスキャッシング(prefix caching)を有効にしたネイティブvLLMコンテナを使用しています。
これらの結果を生成するために使用されたベンチマークスイートは、サンプルのJupyterノートブックで公開されています。以下の3つのステップに従います:(1)ネイティブvLLMコンテナを使用してモデルをSageMaker AIエンドポイントにデプロイする、(2)1〜32の並列リクエストレベルで負荷テストを実行する、(3)結果を分析し、以下のパフォーマンステーブルを作成する。
G6eのベースライン: ml.g6e.12xlarge [4x L40S、$13.12/時間]
4基のL40S GPUとテンソル並列度(tensor parallelism degree)4を用いるG6eは、強力なリクエストあたりのスループットを実現します:単一並列時で37.1 tok/s、C=32で21.5 tok/sです。
C
Success
p50 (s)
p99 (s)
tok/s
RPS
Agg tok/s
$/M tokens
1
100%
16.1
16.3
37.1
0.07
37
$38.09
8
100%
19.8
20.2
30.3
0.42
242
$5.85
16
100%
23.1
23.5
26.0
0.73
416
$3.41
32
100%
26.0
29.2
21.5
1.21
686
$2.06
G7e: ml.g7e.2xlarge [1x RTX PRO 6000 Blackwell、$4.20/時間]
G7eは、単一GPUでテンソル並列度(tensor parallelism degree)1を用い、同じ32Bパラメータモデルを実行します。G6eの4 GPU構成と比較してリクエストあたりのtok/sは低いものの、コスト面では劇的に異なります。
C
Success
p50 (s)
p99 (s)
tok/s
RPS
Agg tok/s
$/M tokens
1
100%
27.2
27.5
22.0
0.04
22
$21.32
8
100%
28.7
28.9
20.9
0.28
167
$2.81
16
100%
30.3
30.6
19.9
0.53
318
$1.48
32
100%
33.2
33.3
18.5
0.99
592
$0.79
この数字が示すもの
本番環境の並列数(C=32)において、G7eは100万出力トークンあたり$0.79を達成し、G6eの$2.06と比較してコストが2.6倍削減されています。これは、G7eの大幅に低い時間単価($4.20対$13.12)と、負荷下でも一貫したスループットを維持できる能力という2つの要因によるものです。G7eの単一GPUアーキテクチャは、より滑らかにスケールします。C=1からC=32にかけてのレイテンシ増加はG7eで22%(27.2秒から33.2秒)であるのに対し、G6eでは62%(16.1秒から26.0秒)です。テンソル並列度(tensor parallelism degree)が1の場合、以下の特徴があります:
- GPU間同期のオーバーヘッド(No inter-GPU synchronization overhead)
- 各Transformerレイヤーでのall-reduce演算(No all-reduce operations)
- GPU間KVキャッシュのフラグメンテーション(No cross-GPU KV cache fragmentation)
- NVLink通信のボトルネック(No NVLink communication bottleneck)
並列処理(concurrency)が増加しGPUがより飽和状態に達すると、この調整オーバーヘッドの欠如によりレイテンシ(latency)が予測可能に保たれます。低コンカレンシーかつレイテンシが敏感なワークロードでは、G6eの4-GPU並列処理が依然として高速な個別応答を提供します。大規模展開においてトークンあたりのコストを最適化する本番環境向けデプロイメントでは、G7eが明確な選択肢であり、次のセクションで示すように、G7eにEAGLE(Extrapolation Algorithm for Greater Language-model Efficiency)のspeculative decoding(推測デコーディング:speculative decoding)を組み合わせることで、この優位性はさらに高まります。
## 統合ベンチマーク:G7e + EAGLE speculative decoding(推測デコーディング)
G7eによるハードウェアの改善は単体でも顕著ですが、EAGLE speculative decoding(推測デコーディング)と組み合わせることで相乗効果が生まれます。EAGLEは、モデル自身のhidden representations(隠れ表現)から複数の未来トークンを予測し、単一のforward pass(順伝播:forward pass)でそれらを検証することで、LLMのデコーディングを加速します。これにより、1ステップあたりに複数のトークンを生成しながらも同等の出力品質を維持します。SageMaker AI上でのEAGLEの詳細な手順、最適化ジョブのセットアップ、Base vs Trained EAGLEのワークフローについては、Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inferenceをご覧ください。
このセクションでは、BF16形式のQwen3-32Bモデルを用い、ベースラインからG7e + EAGLE3までの累積的な改善度を測定します。ベンチマークワークロードは、リクエストあたり約1,000のinput tokens(入力トークン:input tokens)と約560のoutput tokens(出力トークン:output tokens)を使用し、文書の要約や修正タスクを代表するものです。EAGLE3は、num_speculative_tokens=4を設定したcommunity-trained speculator(コミュニティ訓練済みの推測モデル)を有効化することで実装されます。
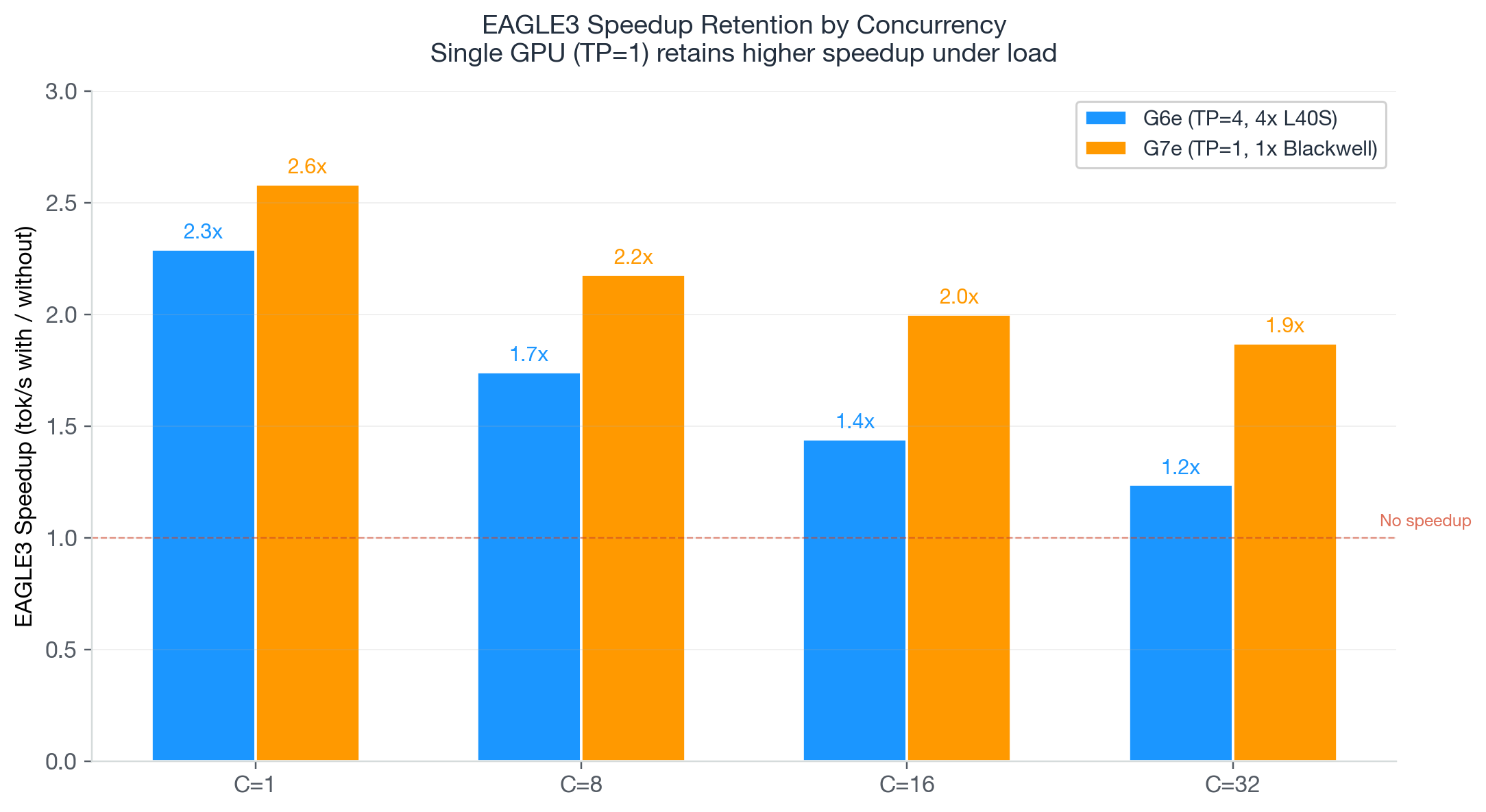 image
image
G7e + EAGLE3は、前世代のベースラインと比較してthroughput(スループット:throughput)が2.4倍向上し、コストを75%削減します。出力トークン100万個あたり$0.41という価格で、より高いスループットを提供しながらも、G6e + EAGLE3($1.72)と比較して4倍のコスト効率を実現しています。
EAGLE3の有効化
ファインチューニング済みモデルを備えた本番環境向けデプロイメントにおいて、SageMaker AIの
原文を表示
As the demand for generative AI continues to grow, developers and enterprises seek more flexible, cost-effective, and powerful accelerators to meet their needs. Today, we are thrilled to announce the availability of G7e instances powered by NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs on Amazon SageMaker AI.
You can provision nodes with 1, 2, 4, and 8 RTX PRO 6000 GPU instances, with each GPU providing 96 GB of GDDR7 memory. This launch provides the capability to use a single-node GPU, G7e.2xlarge instance to host powerful open source foundation models (FMs) like GPT-OSS-120B, Nemotron-3-Super-120B-A12B (NVFP4 variant), and Qwen3.5-35B-A3B, offering organizations a cost-effective and high-performing option. This makes it well suited for those looking to improve costs while maintaining high performance for inference workloads. The key highlights for G7e instances include:
- Twice the GPU memory compared to G6e instances, enabling deployment of large language models (LLMs) in FP16 up to:
35B parameter model on a single GPU node (G7e.2xlarge)
- 150B parameter model on a 4 GPU node (G7e.24xlarge)
- 300B parameter model on an 8 GPU node (G7e.48xlarge)
- Up to 1600 Gbps of networking throughput
- Up to 768 GB GPU Memory on G7e.48xlarge
Amazon Elastic Compute Cloud (Amazon EC2) G7e instances represent a significant leap in GPU-accelerated inference on the cloud. They deliver up to 2.3x inference performance compared to the previous-generation G6e instances. Each G7e GPU provides 1,597 GB/s bandwidth, doubling the per-GPU memory of G6e and quadrupling that of G5. Networking scales to 1,600 Gbps with EFA on the largest G7e size—a 4x jump over G6e and 16x over G5—unlocking low-latency multi-node inference and fine-tuning scenarios that were previously impractical on G-series instances. The following table summarizes the generational progression at the 8-GPU tier:
Spec
G5 (g5.48xlarge)
G6e (g6e.48xlarge)
G7e (g7e.48xlarge)
GPU
8x NVIDIA A10G
8x NVIDIA L40S
8x NVIDIA RTX PRO 6000 Blackwell
GPU Memory per GPU
24 GB GDDR6
48 GB GDDR6
96 GB GDDR7
Total GPU Memory
192 GB
384 GB
768 GB
GPU Memory Bandwidth
600 GB/s per GPU
864 GB/s per GPU
1,597 GB/s per GPU
vCPUs
192
192
192
System Memory
768 GiB
1,536 GiB
2,048 GiB
Network Bandwidth
100 Gbps
400 Gbps
1,600 Gbps (EFA)
Local NVMe Storage
7.6 TB
7.6 TB
15.2 TB
Inference vs. G6e
Baseline
~1x
Up to 2.3x
With 768 GB of aggregate GPU memory on a single instance, G7e can host models that previously required multi-node setups on G5 or G6e, reducing operational complexity and inter-node latency. Combined with support for FP4 precision using fifth-generation Tensor Cores and NVIDIA GPUDirect RDMA over EFAv4, G7e instances are positioned as the go-to choice for deploying LLMs, multimodal AI, and agentic inference workloads on AWS.
Use cases well suited for G7e
G7e’s combination of memory density, bandwidth, and networking capabilities makes it well suited for a broad range of modern generative AI workloads:
- Chatbots and conversational AI – G7e’s low TTFT and high throughput keep interactive experiences responsive even under heavy concurrent load.
- Agentic and tool-calling workflows – The 4x improvement in CPU-to-GPU bandwidth makes G7e particularly effective for Retrieval Augmented Generation (RAG) pipelines and agentic workflows where fast context injection from retrieval stores is critical.
- Text generation, summarization, and long-context inference – G7e’s 96 GB per-GPU memory accommodates large KV caches for extended document contexts—reducing truncation and enabling richer reasoning over long inputs.
- Image generation and vision models – Where earlier instances encounter out-of-memory errors on larger multimodal models, G7e’s doubled memory resolves these limitations cleanly.
- Physical AI and scientific computing – G7e’s Blackwell-generation compute, FP4 support, and spatial computing capabilities (DLSS 4.0, 4th-gen RT cores) extend its applicability to digital twins, 3D simulation, and physical AI model inference.
Deployment walkthrough
Prerequisites
To try this solution using SageMaker AI, you need the following prerequisites:
- An AWS account that will contain all your AWS resources.
- An AWS Identity and Access Management (IAM) role to access Amazon SageMaker AI. To learn more about how IAM works with SageMaker AI, see Identity and Access Management for Amazon SageMaker AI.
- Access to Amazon SageMaker Studio or a SageMaker notebook instance, or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using Amazon SageMaker Studio for straightforward deployment and inference.
- Quota for one instance of ml.g7e.2xlarge [or larger] for Amazon SageMaker AI endpoint usage. You can request a quota increase through the Service Quotas console.
Deployment
You can clone the repository and use the sample notebook provided here.
Performance benchmarks
To quantify the generational improvement, we benchmarked Qwen3-32B (BF16) on both G6e and G7e instances using the same workload: ~1,000 input tokens and ~560 output tokens per request. This is representative of document summarization or correction tasks. Both configurations use the native vLLM container with prefix caching enabled.
The benchmarking suite used to produce these results is available in the sample Jupyter notebook. It follows a three-step process: (1) deploy the model on a SageMaker AI endpoint using the native vLLM container, (2) load test at concurrency levels from 1–32 simultaneous requests, and (3) analyze the results to produce the following performance tables.
G6e Baseline: ml.g6e.12xlarge [4x L40S, $13.12/hr]
With 4x L40S GPUs and tensor parallelism degree 4, G6e delivers strong per-request throughput: 37.1 tok/s at single concurrency and 21.5 tok/s at C=32.
C
Success
p50 (s)
p99 (s)
tok/s
RPS
Agg tok/s
$/M tokens
1
100%
16.1
16.3
37.1
0.07
37
$38.09
8
100%
19.8
20.2
30.3
0.42
242
$5.85
16
100%
23.1
23.5
26.0
0.73
416
$3.41
32
100%
26.0
29.2
21.5
1.21
686
$2.06
G7e: ml.g7e.2xlarge [1x RTX PRO 6000 Blackwell, $4.20/hr]
G7e runs the same 32B-parameter model on a single GPU with tensor parallelism degree 1. While per-request tok/s is lower than G6e’s 4-GPU configuration, the cost story is dramatically different.
C
Success
p50 (s)
p99 (s)
tok/s
RPS
Agg tok/s
$/M tokens
1
100%
27.2
27.5
22.0
0.04
22
$21.32
8
100%
28.7
28.9
20.9
0.28
167
$2.81
16
100%
30.3
30.6
19.9
0.53
318
$1.48
32
100%
33.2
33.3
18.5
0.99
592
$0.79
What the numbers tell us
At production concurrency (C=32), G7e achieves $0.79 per million output tokens, a 2.6x cost reduction compared to G6e’s $2.06. This is driven by two factors: G7e’s significantly lower hourly rate ($4.20 vs $13.12) and its ability to maintain consistent throughput under load.G7e’s single-GPU architecture also scales more gracefully. Latency increases 22% from C=1 to C=32 (27.2s to 33.2s), compared to 62% for G6e (16.1s to 26.0s). With tensor parallelism degree 1, there is:
- No inter-GPU synchronization overhead
- No all-reduce operations at every transformer layer
- No cross-GPU KV cache fragmentation
- No NVLink communication bottleneck
As concurrency rises and the GPU becomes more saturated, this absence of coordination overhead keeps latency predictable. For latency-sensitive workloads at low concurrency, G6e’s 4-GPU parallelism still delivers faster individual responses. For production deployments optimizing for cost per token at scale, G7e is the clear choice, and as we show in the next section, combining G7e with EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency) speculative decoding pushes the advantage even further.
Combined benchmarks: G7e + EAGLE speculative decoding
The hardware improvements from G7e are significant on their own but combining them with EAGLE speculative decoding produces compounding gains. EAGLE accelerates LLM decoding by predicting multiple future tokens from the model’s own hidden representations, then verifying them in a single forward pass. This produces identical output quality while generating multiple tokens per step. For a detailed walkthrough of EAGLE on SageMaker AI, including optimization job setup and the Base vs Trained EAGLE workflow, see Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inference.
In this section, we measure the stacked improvement from baseline through G7e + EAGLE3 using Qwen3-32B in BF16. The benchmark workload uses ~1,000 input tokens and ~560 output tokens per request, representative of document summarization or correction tasks. EAGLE3 is enabled using a community-trained speculator (~1.56 GB) with num_speculative_tokens=4.
G7e + EAGLE3 delivers a 2.4x throughput improvement and 75% cost reduction over the previous-generation baseline. At $0.41 per million output tokens, it is also 4x cheaper than G6e + EAGLE3 ($1.72) despite offering higher throughput.
Enabling EAGLE3
For production deployments with fine-tuned models, the SageMaker AI <a href="https://aws.amazon.com/blogs/machine-learning/amazon-sagemaker-ai-introduces-eagle-based-adaptive-speculative-decoding-to-accelerate-generative-ai-infe
関連記事
NVIDIA RTX PRO 4500 Blackwell Server EditionとvGPU 20でAI対応データセンターを拡張する
NVIDIAはRTX PRO 4500 Blackwell Server EditionとvGPU 20を提供し、Officeや設計ツールなどへのAI統合を支援する。
AWS TrainiumとvLLMを用いた推測的デコードによるデコード負荷の高いLLM推論の高速化
AWS TrainiumとvLLMを用いた推測的デコードにより、Qwen3モデルのトークン生成速度が最大3倍向上し、出力品質を維持したままトークンあたりのコスト削減とスループット向上が実現された。
トレーニングプランを使用して設定済みGPU容量でSageMaker AI推論エンドポイントをデプロイ
AWSは、Amazon SageMaker AIのトレーニングプランを使用して、指定期間のGPU容量を予約し、大規模言語モデルの推論デプロイを効率化する方法を発表した。