Amazon Bedrock と AWS HealthLake を活用したエージェント型 AI 医療請求処理パイプラインの構築方法
AWS は、Amazon Bedrock Data Automation と AgentCore を活用した医療請求処理パイプラインの構築方法を解説し、手作業の削減と FHIR リソースへの自動変換を実現する具体的なアーキテクチャを提示している。
キーポイント
自動化された請求処理ワークフロー
S3 にアップロードされた CMS-1500 請求書(PDF)に対し、Lambda がトリガーとなり、Bedrock Data Automation で構造化データを抽出する。
AI エージェントによる高度な検証
Strands Agents を実行する Bedrock AgentCore が、HealthLake の既存レコードと照合してデータの完全性と整合性を自動的に検証する。
標準化されたデータ出力と通知
検証が成功すると、FHIR 形式の請求リソースとして HealthLake に保存され、処理担当者向けサマリーと患者向け説明を SNS で配信する。
影響分析・編集コメントを表示
影響分析
この記事は、医療保険請求処理という高コストかつミスが発生しやすい業務領域において、生成 AI とエージェント技術を実用的なワークフローとして統合する具体的な実装例を示しています。AWS HealthLake や Bedrock の新機能を組み合わせることで、業界標準である FHIR データ形式への自動変換を可能にし、医療機関と保険事業者双方の業務効率化に直結する重要な指針となります。
編集コメント
医療データという厳格な規制と精度が求められる領域において、AI エージェントによる検証プロセスを組み込んだ実装例は非常に示唆に富んでいます。単なる抽出だけでなく、既存データベースとの照合を行う「自律的な検証」の概念は、他の業界への展開も期待できる重要なステップです。
紙ベースのフォームを手動で処理することは、医療業界において依然として大きなコスト要因となっています。スキャンされた文書や画像からのデータ抽出技術は進歩していますが、通常は人間の監視が依然として必要とされます。フォーム作成者による入力ミスや、デジタル化における信頼度の低い抽出結果については、依然として修正が必要です。
本稿では、2 つの主要な Amazon Bedrock の機能を用いて、請求処理パイプラインを自動化する方法をご紹介します。1 つ目は、医療請求書からのインテリジェントな文書抽出を行う Amazon Bedrock Data Automation です。2 つ目は、抽出されたデータを検証し、FHIR(Fast Healthcare Interoperable Resources)リソースへ変換して AWS HealthLake にホストする AI エージェントを管理する Amazon Bedrock AgentCore です。これらのサービスを組み合わせることで、手動処理を削減しつつ、自動化された検証チェックを通じて精度を維持するエンドツーエンドのワークフローを作成する方法を学びます。
ソリューション概要
本ソリューションは、AI 駆動サービスを活用した医療請求書の処理における自動化ワークフローを示しています。医療提供者が CMS-1500 請求書(PDF 形式)を Amazon Simple Storage Service (Amazon S3) バケットにアップロードすると、AWS Lambda を起点とする処理パイプラインがトリガーされ、以下の 3 つの主要な機能を実行します:
- Amazon Bedrock Data Automation は、インテリジェントドキュメント処理(Intelligent Document Processing)を用いて、フォームから構造化データを抽出します。
- Amazon Bedrock AgentCore で実行される Strands Agents による AI エージェントが、AWS HealthLake に保存された既存の患者およびプロバイダー記録と照合し、データの完全性と一貫性を検証します。
- すべての検証に合格した場合、エージェントは HealthLake 内に標準化された FHIR クレームリソースを作成します。また、クレーム処理担当者向けの技術要約と、患者向けに分かりやすく説明したクレームステータス解説も生成されます。これらは両方とも、Amazon Simple Notification Service (Amazon SNS) を介して通知として送信されます。
この自動化されたワークフローは、AI 支援による検証を通じて精度を維持しつつ、手作業での処理時間を短縮するのに役立ちます。
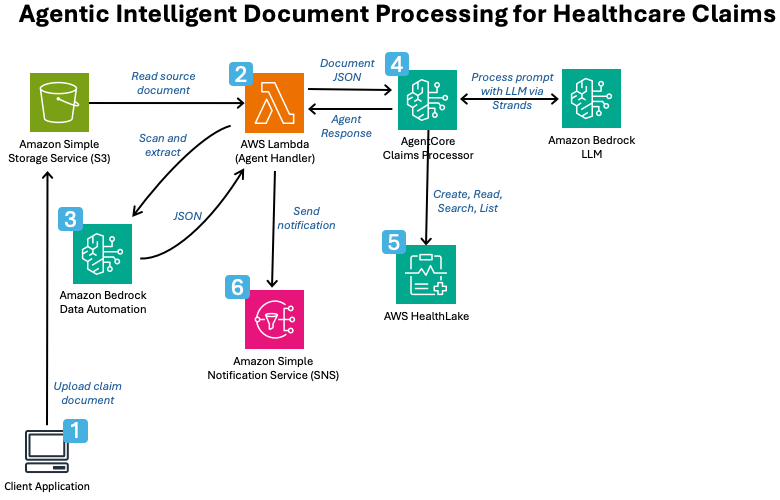
*図 1: 本ソリューションのアーキテクチャビュー。
上記の図は、以下の手順を示しています。
- 提出者は請求書ドキュメントを Amazon S3 にアップロードします。
- ファイルが到着すると AWS Lambda がトリガーされます。
- Amazon Bedrock Data Automation がドキュメントから情報を抽出し、結果を JSON フォーマットで出力します。
- その後、AWS Lambda は AgentCore を呼び出し、処理のためにドキュメントを渡します。
- AgentCore は AWS HealthLake にクエリを実行して請求書を作成し、要約された JSON 応答を生成します。
- AWS Lambda は Amazon SNS を呼び出して、エラー応答または成功応答を送信します。
Lambda は S3 でドキュメントが作成された際のイベントトリガーとして使用され、エージェント型ワークフローに対する決定論的な管理者の役割を果たします。各ドキュメントが処理されるか、例外処理のためにデッドレターキュー(dead letter queue)に送られることを検証します。
Bedrock Data Automation は生成 AI の開発を簡素化し、ドキュメント、画像、オーディオ、ビデオを含むワークフローを自動化します。ドキュメント処理においては、従来の光学文字認識(OCR: Optical Character Recognition)、機械学習(ML: Machine Learning)モデル、および生成 AI を組み合わせて、正確にデータを抽出します。Blueprints(アーティファクト)を使用して、ドキュメントからどのデータを抽出するか、またどのように抽出するかを指定できます。事前構築されたテンプレートを使用したり、ユースケースに合わせてカスタム構成を作成したりすることが可能です。出力には、抽出されたフィールドおよびテーブルの信頼度スコアとバウンディングボックスデータが含まれます。ここでのカスタム出力は、フォーマットの変動を超えて CMS-1500 請求書フォームの予測可能な JSON 表現を生成します。
AgentCore は Strands エージェントをホストしています。このエージェントは、HealthLake と対話するために create_fhir_claim および search_fhir_resources という 2 つのツールを使用します。
エージェントは以下のワークフローを使用します:
- AWS HealthLake から、請求書フォームでの参照として使用する被保険者、患者、医療従事者、および補償情報を検索します。最初の試行では直接メソッド呼び出しとデフォルトの検索パラメータが使用されます。それ以降は、エージェントは以下のプロンプトを実行してツール呼び出しを確認し、必要に応じて再検索を試みます:
被保険者リソースを特定してください。まず過去のツール呼び出しを確認します。一致するものが見つからない場合は、請求書 JSON から異なる検索パラメータを使用してさらに 2 回試みてください。高い信頼スコアを持つ属性に焦点を当て、どのように一致を見つけたかを報告してください。
- 参照情報が見つかった場合、請求書の FHIR レプレゼンテーションを作成し、AWS HealthLake に送信します。
- 完了した作業を記録する JSON オブジェクトを作成します。このオブジェクトには、作成された場合は請求書 ID、人間のプロセッサ向けの応答、および患者向けの応答が含まれます。プロセッサ向け応答はアラートまたは観測として機能し、患者向け応答はエラー修正が必要な場合に送信者に通知するシグナルとなります。
前提条件
ソリューションをデプロイする前に、以下の準備が整っていることを確認してください:
- 管理者権限を持つ AWS アカウント。
- Amazon Bedrock 上の Anthropic Claude Sonnet 4.6 へのアクセス。詳細については、「Amazon Bedrock のファウンデーションモデルへのアクセス」をご覧ください。
- NodeJS バージョン 24 以降。
- Node Package Manager (npm) バージョン 11.5 以降。
- Python バージョン 3.13 以降。
- AWS Cloud Development Kit (AWS CDK) バージョン 2.1025 以降。
ソリューションのデプロイ
本ソリューションのデプロイには、AWS Cloud Development Kit (CDK) と AgentCore コマンドラインインターフェースが使用され、以下の手順で行います:
- リポジトリをクローンします:
git clone https://github.com/aws-samples/sample-agenticidptohealthlake.git
- リポジトリのルートディレクトリから以下のコマンドを実行します:
npm install
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
pip install -r requirements.txt --python-version 3.12 --platform manylinux2014_aarch64 --target ./packaging/_dependencies --only-binary=:all:
cd agentcore
agentcore configure --entrypoint claimsprocessor.py
agentcore launch
python ./bin/package_for_lambda.py
npx cdk bootstrap
npx cdk deploy
SNS トピックの購読による通知受信
- Amazon SNS コンソールにアクセスします。
- [Topics] を選択します。
- [Agent-Notifications] を選択します。
- [Create subscription] を選択します。
- プロトコルとして [email] を選択します。
- メールアドレスを入力します。
- [Create subscription] を選択します。
- 受信した確認メール内のリンクをクリックして、購読を確認します。
ソリューションの活用
以下のセクションでは、2 つのシナリオ(失敗シナリオと成功シナリオ)について順を追って説明します。
- 失敗シナリオ:AWS HealthLake の必要な参照リソースのうち 1 つを欠落させることで、失敗をシミュレートします。
プロジェクトコードには sampledata フォルダが含まれています。load_sampledata.py を使用してデータをステージングしてください。ここで <code>healthlake_datastore_arn</code> は、CDK デプロイ出力から取得した HealthLakeDatastoreArn です:
python load_sampledata.py bda_output_insuredid_error.json Patient,Insured,Practitioner
サンプルファイル sample1_cms-1500-P.pdf を、/input という名前のフォルダ配下に S3 バケットにアップロードします。ここでは意図的に必要なリソースの 1 つを読み込んでいません。
これにより、SNS を介して以下のようなメッセージが生成されるはずです:
*We were unable to process your claim because we couldn't find your insurance coverage information in our system. Please contact your insurance provider to verify your policy number G4683A with AnyHealth Plus Medicare plan, or call our office to update your coverage information.*
これは、エージェントが問題を認識し、請求失敗に対して人間に優しい応答を生成する様子をシミュレートしたものです。
- 成功シナリオ:必要な HealthLake リソースが存在するように設定することで、正常な処理をシミュレートします。このシナリオでは、エージェントが乗り越えるべきデータの不整合を挿入しています。以下のサンプルデータでは、被保険者の ID 番号が変更されています。
HealthLake に不足している参照を作成してください:
python load_sampledata.py bda_output_insuredid_error.json Coverage
上記の手順を用いて PDF を再処理してください。SNS を介して、以下のようなメッセージを受信します。
*患者 John Doe の CMS 1500 クレームフォームが正常に処理されました。診断名は腰痛(M54.9)です。患者は生年月日(1960-10-10)によって特定されました。クレーム ID(11-2234-10190)とデータベース ID(11-2234-1019O)の最終文字が異なる不一致により ID 検索が失敗したため、名前の検索によって被保険者 Jane Doe が特定されました。紹介医は Dr. Jane Smith で、ID は 123456 です。AnyHealth Plus から発行された Medicare ポリシー G4683A の下で補償が確認されました。このクレームには 4 つの手技が含まれています:2005-10-15 の CPT 97810($170)、2005-10-20 の CPT 73521($120)、2005-10-30 の CPT 98940($250)、および 2005-10-30 の CPT 97124($120)で、合計は $660 です。
このメッセージは、人間によるレビュー担当者が成功したクレームのクイックな要約と、エージェントによって行われたその他の観察事項を一目で把握するためのシグナルとして機能します。
ベストプラクティス
設計時の AI は実行時の AI より優れています。 このソリューションでは、オーケストレーションロジックは事前に把握されています。ドキュメント処理の手順は予測可能であり、HealthLake に対する初期クエリも一貫したパターンに従います。これらの要件が設計時に明確に定義されているため、モデルコンテキストプロトコル(Model Context Protocol: MCP)サーバーに実行時の操作順序の推論を任せるのではなく、ロジックを明示的にエンコードしました。その結果、より信頼性が高く保守性の高いソリューションが実現します。構築には、自然言語仕様から動作するコードへ変換するエージェント型 IDE である Kiro を使用しました。Kiro は Lambda 内で Bedrock Data Automation への API 呼び出しを生成し、エージェント内のツールも構築しました。実行時に広範で探索的なプロンプトを発行するのではなく、設計時に精密かつターゲットを絞ったコードを生成したことで、Bedrock への呼び出し回数を削減できました。これにより運用コストの低減と開発ライフサイクルの短縮が実現しました。
エージェントは決定論的に監視してください。 このアーキテクチャで S3 と Lambda を使用したのは意図的な選択です。エージェントは主に二つの基本的な動作を行います:明示的なツール呼び出しを観察すること、および HealthLake にロードする FHIR リソースを生成することです。その後、請求書の成否の最終決定者として機能する Lambda 関数へ結果を報告します。
クリーンアップ
以下のコマンドを実行することで、ソリューションを削除できます:
cd agentcore
python cleanup_resources.py
npx cdk destroyコスト
以下に、各サービスに関するコスト検討事項をリストします。
注記: 以下のコスト検討事項は、公開時点の AWS の価格に基づいており、情報提供のみを目的としています。実際の費用は変動する可能性があります。最新の価格については、それぞれのサービスの価格ページをご参照ください。
- AgentCore Runtime の料金は vCPU 時間あたり 0.0895 ドル、メモリは GB 時間あたり 0.00945 ドルであり、文書あたりのコストは僅少となります。
- Amazon Bedrock Data Automation は、30 フィールド以下のブループリントでページあたり 0.04 ドル、30 を超える追加フィールドごとに 1 フィールドあたり 0.0005 ドルです。
- エージェントのモデル料金は Anthropic Claude Sonnet 3.7 V1 を使用します。テスト文書では、トークンは入力約 76,000、出力約 6,000 です。オンデマンド価格の場合、入力が 0.23 ドル/トークン、出力が 0.09 ドル/トークンとなり、文書あたり合計 0.32 ドルとなります。
- AWS HealthLake は時間あたりのストレージ量で課金され、最初の 10 GB で時間あたり 0.27 ドルです。
- Lambda、S3、SNS の料金は、本アーキテクチャでは文書あたり無視できるほど僅少です。
結論
本番環境における医療請求処理には、このソリューションを超える追加ステップが存在することが多いですが、このパターンは AI エージェントをドキュメントワークフローに統合する力を示しています。AI エージェントに処理ツールへの直接アクセスを与えることで、以下の複数の方法で貴重な洞察を提供できます:潜在的な請求問題の特定、人間のレビューが必要な領域の強調表示、患者向けのステータスメッセージの生成です。この AI 支援アプローチは、請求処理担当者の業務効率を向上させつつ、正確性を維持したまま処理時間を短縮するのに役立ちます。前述の例は、文字「o」と数字「0」の間に見られるようなデータの不整合という典型的なシナリオを示しています。このような状況において、エージェントはその不整合を解決し、請求を正確に処理します。
インテリジェントなドキュメント処理ソリューションの構築についてさらに詳しく知りたい場合は、Amazon Bedrock のドキュメント をご覧ください。または、AWS アーキテクチャセンター で他の医療関連ソリューションもご確認ください。
著者について

トロイ・パレット
トロイは、AWS のシニアソリューションアーキテクトであり、ヘルスケアおよびライフサイエンスのエンタープライズ顧客に所属しています。彼は、AI ファーストの思考でクラウドを戦略的に採用し、活用することを支援しています。開発者体験への情熱を持ち、コードとしてのインフラストラクチャ(Infrastructure as Code)やその他の開発分野を専門としています。

デイブ・クラムバッカー
デイブは、AWS のシニアソリューションアーキテクトであり、顧客がクラウドへの移行と近代化を支援しています。彼はクラウド戦略、アプリケーションの近代化、AI/ML(人工知能・機械学習)を専門としており、ヘルスケア、製造業、およびその他の業界にわたる複雑なビジネスおよび技術課題を解決するためのアーキテクチャガイダンスを提供しています。
原文を表示
Manually processing paper-based forms remains a significant cost in the healthcare industry. Despite advancements in data extraction of scanned documents and images, human oversight is usually still needed. Entry error by the individual creating the form or lower-confidence extractions from the digitization still must be remediated.
In this post, we show you how to build an automated claims processing pipeline using two key Amazon Bedrock capabilities: Amazon Bedrock Data Automation for intelligent document extraction from healthcare claim forms, and Amazon Bedrock AgentCore for hosting an AI agent that validates and transforms the extracted data into FHIR (Fast Healthcare Interoperable Resources) resources in AWS HealthLake. You will learn how to combine these services to create an end-to-end workflow that reduces manual processing while maintaining accuracy through automated validation checks.
Solution overview
The solution demonstrates an automated workflow for processing healthcare claim forms using AI-powered services. When a healthcare provider uploads a CMS-1500 claim form (in PDF format) to an Amazon Simple Storage Service (Amazon S3) bucket, it triggers a processing pipeline starting with AWS Lambda that performs three main functions:
- Amazon Bedrock Data Automation extracts structured data from the form using intelligent document processing.
- An AI agent using Strands Agents running on Amazon Bedrock AgentCore validates this data against existing patient and provider records in AWS HealthLake, checking for completeness and consistency.
- If all validations pass, the agent creates a standardized FHIR claim resource in HealthLake. It also generates a technical summary for claims processors and a patient-friendly explanation of the claim status. Both go out as Amazon Simple Notification Service (Amazon SNS) notifications.
This automated workflow helps reduce manual processing time while maintaining accuracy through AI-assisted validation.
*Figure 1: An architectural view of the solution.*
The preceding diagram illustrates the following steps:
- A submitter uploads a claim document to Amazon S3.
- AWS Lambda gets triggered when the file arrives.
- Amazon Bedrock Data Automation extracts the information from the document and outputs the result in JSON format.
- AWS Lambda then calls AgentCore and passes the document for processing.
- AgentCore queries AWS HealthLake, creates the claim, and creates a summary JSON response.
- AWS Lambda invokes Amazon SNS to deliver an error response or a success response.
Lambda is used as an event trigger when a document is created in S3 and serves as a deterministic supervisor over the agentic workflow. It validates that each document is processed or sent to a dead letter queue for exception handling.
Bedrock Data Automation streamlines generative AI development and automates workflows involving documents, images, audio, and videos. For document processing, Bedrock Data Automation combines traditional optical character recognition (OCR), machine learning (ML) models, and generative AI to extract data accurately. You can use Blueprints (artifacts) to specify what data to extract from a document and how to extract it. You can use pre-built templates or build custom configurations tailored to your use cases. The output includes confidence scores and bounding box data for the extracted fields and tables. The custom output here produces a predictable JSON representation of the CMS-1500 claim form across its format variations.
AgentCore hosts the Strands agent. The agent uses two tools to interact with HealthLake: create_fhir_claim and search_fhir_resources.
The agent uses the following workflow:
- Find the Insured, Patient, Practitioner, and Coverage information in AWS HealthLake to use as a reference in the claim form. The first attempt uses direct method calls and default search parameters. Beyond that, the agent runs the following prompt to check the tool calls and re-attempt searches if necessary:
Identify the insured resource, first by looking at prior tool calls. If there is no match, try two more attempts to find a match by using different search parameters from the claim JSON. Focus on high confidence score attributes and report how you found the match.
- If the references are found, create a FHIR representation of the claim and send it to AWS HealthLake.
- Create a JSON object that captures the work completed. The object includes the claim ID (if one was created), a response for the human processor, and a response for the patient. The processor response acts as an alert or observation. The patient response signals back to the submitter when errors need to be corrected.
Prerequisites
Before you deploy the solution, make sure you have the following:
- An AWS account with administrator permissions.
- Access to Anthropic Claude Sonnet 4.6 on Amazon Bedrock. For more details, see Access Amazon Bedrock foundation models.
- NodeJS version 24 or later.
- Node Package Manager (npm) version 11.5 or later.
- Python version 3.13 or later.
- AWS Cloud Development Kit (AWS CDK) version 2.1025 or later.
Deploy the solution
The AWS Cloud Development Kit (CDK) and the AgentCore command line interface are used for deployment with the following steps:
- Clone the repository:
git clone https://github.com/aws-samples/sample-agenticidptohealthlake.git- Run the following commands from the repository root:
npm install
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
pip install -r requirements.txt --python-version 3.12 --platform manylinux2014_aarch64 --target ./packaging/_dependencies --only-binary=:all:
cd agentcore
agentcore configure --entrypoint claimsprocessor.py
agentcore launch
python ./bin/package_for_lambda.py
npx cdk bootstrap
npx cdk deploySubscribe to the SNS topic to receive notifications
- Access the Amazon SNS console.
- Choose Topics.
- Choose Agent-Notifications.
- Choose Create subscription.
- For protocol, choose email.
- Enter your email address.
- Choose Create subscription.
- Follow the link in the confirmation notice in your email to confirm your subscription.
Use the solution
The following sections walk through two scenarios: a failure scenario and a success scenario.
- Failure scenario: Simulate a failure by leaving out one of the required reference resources in AWS HealthLake.
The project code includes a sampledata folder. Use load_sampledata.py to stage some data, where ` is the HealthLakeDatastoreArn from the cdk deploy` output:
python load_sampledata.py bda_output_insuredid_error.json Patient,Insured,PractitionerUpload sample1_cms-1500-P.pdf to the S3 bucket under a folder named /input. We’re intentionally not loading one of the required resources.
This should generate a message similar to the following through SNS:
*We were unable to process your claim because we couldn’t find your insurance coverage information in our system. Please contact your insurance provider to verify your policy number G4683A with AnyHealth Plus Medicare plan, or call our office to update your coverage information.*
This simulates how the agent recognizes a problem and generates a human-friendly response to the claim failure.
- Successful scenario: Simulate successful processing by making sure the required HealthLake resources exist. In this scenario, we insert a data discrepancy for the agent to help us overcome. In the following sample data, the Insured’s ID number has been changed.
Create the missing reference in HealthLake:
python load_sampledata.py bda_output_insuredid_error.json CoverageUsing the preceding steps, reprocess the PDF. You will receive a message like the following through SNS:
*Successfully processed CMS 1500 claim form for patient John Doe with diagnosis of Back Pain M54.9. Patient was identified by DOB (1960-10-10). Insured party Jane Doe was identified by name search after ID search failed due to a discrepancy between claim ID (11-2234-10190) and database ID (11-2234-1019O) – final character differs. Dr. Jane Smith was identified as the referring physician by ID 123456. Coverage was verified under Medicare policy G4683A issued by AnyHealth Plus. The claim includes 4 procedures: CPT 97810 on 2005-10-15 ($170), CPT 73521 on 2005-10-20 ($120), CPT 98940 on 2005-10-30 ($250), and CPT 97124 on 2005-10-30 ($120), totaling $660.*
This message can signal to a human reviewer a quick glance summary of the successful claim and any other observations made by the agent.
Best practices
Design-time AI is better than runtime AI. In this solution, the orchestration logic is known in advance. The document processing steps are predictable, and the initial queries to HealthLake follow a consistent pattern. Because these requirements are well-defined at design time, we explicitly encoded the logic instead of relying on Model Context Protocol (MCP) servers to infer the order of operations at runtime. The result is a more reliable, maintainable solution. To build it, we used Kiro, an agentic IDE that translates natural language specifications into working code. Kiro generated the API calls to Bedrock Data Automation inside Lambda and built the tools inside the agent. By producing precise, targeted code at design time rather than issuing broad, exploratory prompts at runtime, Kiro reduced the number of calls to Bedrock. That helped lower operational costs and shorten the development lifecycle.
Deterministically supervise the agents. Using S3 and Lambda in this architecture was intentional. The agent does two basic things: observe the explicit tool calls, and generate the FHIR resource to load into HealthLake. It then reports back to the Lambda function, which acts as the final arbiter of success or failure for the claim.
Clean up
The following commands can be invoked to remove the solution:
cd agentcore
python cleanup_resources.py
npx cdk destroyCosts
The following lists cost considerations for each service used.
Note: The following cost considerations are based on AWS pricing as of the time of publishing and are provided for informational purposes only. Actual costs may vary. For the most current pricing, refer to the respective services’ pricing pages.
- AgentCore Runtime charges of $0.0895 per vCPU-hour and Memory at $0.00945 per GB-hour will present a nominal per document cost.
- Amazon Bedrock Data Automation is $0.04 per page for blueprints with 30 fields or less, $0.0005 for every additional field beyond 30.
- Model charges for the agent using Anthropic Claude Sonnet 3.7 V1. In our test document the tokens are approximately 76 thousand input and 6 thousand output. For on-demand pricing, that’s $0.23/in and $0.09 out or $0.32/document.
- AWS HealthLake is charged by storage per hour, at $0.27 per hour for the first 10 GB.
- Lambda, S3, and SNS charges are negligible per document in this architecture.
Conclusion
While production healthcare claims processing often involves additional steps beyond this solution, this pattern demonstrates the power of integrating AI agents into document workflows. By giving the AI agent direct access to processing tools, it can provide valuable insights in multiple ways: identifying potential claim issues, highlighting areas that need human review, and generating patient-friendly status messages. This AI-assisted approach can help claims processors work more efficiently and reduce processing times while maintaining accuracy. The preceding example showcases a likely scenario: a data discrepancy between the letter *o* and the number zero. In this situation, the agent navigates the discrepancy and accurately processes the claim.
To learn more about building intelligent document processing solutions, explore the Amazon Bedrock documentation or check out other healthcare solutions in the AWS Architecture Center.
About the authors
Troy Parrett
Troy is a Senior Solutions Architect at AWS aligned to healthcare and life sciences enterprise customers, helping them adopt and leverage cloud strategically with an AI-first mindset. He has a passion for developer experience and specializes in infrastructure as code and other developer disciplines.
Dave Crumbacher
Dave is a Senior Solutions Architect at AWS, helping customers adopt and modernize on the cloud. He specializes in cloud strategy, application modernization, and AI/ML, delivering architecture guidance to solve complex business and technology challenges across healthcare, manufacturing, and other industries.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み