NVIDIA AI、空間推論のためのトレーニング不要エージェント「SpatialClaw」を発表:コードを行動インターフェースとして活用
NVIDIA Research は、コードを行動インターフェースとして活用するトレーニング不要のフレームワーク「SpatialClaw」を発表し、3D 空間推論における VLM の弱点を克服してベンチマークで大幅な精度向上を実現した。
キーポイント
コードベースの行動インターフェース
従来の固定されたツール呼び出しや単発コード実行に代わり、エージェントが Python コードを直接記述・実行して知覚ツールを組み合わせて操作する新しいアーキテクチャを採用している。
トレーニング不要の汎用性
モデルの再学習やファインチューニングを必要とせず、既存の VLM と Python カーネルを組み合わせるだけで、20 の異なるベンチマークで 59.9% という高い平均精度を達成した。
動的な推論プロセス
中間結果(マスクや深度マップ)を検証し、必要に応じて計算ロジック(例:scipy.spatial.KDTree の使用など)をリアルタイムで修正・再構成する柔軟なエージェントループを実現している。
高度な知覚ツールの統合
Depth Anything 3 や SAM 3 などの最先端モデルをプリミティブとして組み込み、深度、カメラ幾何学、マスク生成などを Python 変数として直接扱える環境を提供する。
コードをアクションとして扱うことで性能が大幅向上
SpatialClaw はコードをアクションインターフェースとして採用し、構造化ツール呼び出しや単発コードベースの手法と比較して平均スコアで最大+6.5ポイントの改善を達成しました。
動的タスクにおける顕著な成果
動画や複数視点を含む動的な幾何計算が必要なタスク(DSI-Bench や MindCube)において、特に大きな性能向上が見られました。
5段階のループと安全な実行環境
計画、コード生成、実行、フィードバック、回答提出という 5 段階のループを繰り返し、AST チェッカーによる安全性確保と LangGraph 基盤での実装が行われています。
影響分析・編集コメントを表示
影響分析
この発表は、Vision-Language Models が物理世界を正確に理解・推論するための新たなパラダイムを示唆しており、特にロボット制御や拡張現実(AR)などの分野で、複雑な空間タスクを処理するエージェントの実用化を加速させる可能性があります。モデルの再学習コストを排除し、コードによる柔軟な制御を可能にした点は、AI エージェント開発における「インターフェース設計」の重要性を浮き彫りにしています。
編集コメント
「コードをアクションとして扱う」という発想の転換は、AI エージェントが単なるツール呼び出しから、自律的なプログラミング能力へと進化する重要なステップです。特にトレーニング不要で既存モデルを強化できる点は、実世界への展開において極めて現実的な解決策と言えます。
NVIDIA Research は、空間推論のためのトレーニング不要フレームワークである SpatialClaw をリリースしました。これは、ビジョン・ランゲージモデル(VLM)の永続的な弱点をターゲットにしたものです。これらのモデルは依然として、物体がどこにあるか、それらがどのように関連し、3D 空間でどのように移動するかを判断することに苦戦しています。
SpatialClaw はモデルを再トレーニングするのではなく、エージェントが知覚ツールを呼び出す際に使用するアクションインターフェースを変更します。研究チームは、このインターフェースがボトルネックであると主張しています。その解決策として、コードをアクションインターフェースとして扱うことを提案しています。20 のベンチマーク全体で、SpatialClaw は平均 59.9% の精度を達成しました。これは直近の空間エージェントである SpaceTools を 11.2 ポイント上回る結果です。
SpatialClaw とは何か
SpatialClaw は、ステートフルな Python カーネル(注:状態を保持する実行環境)に囲まれたエージェントループです。このカーネルには、入力フレームとプリミティブのセットが事前にロードされています。知覚ツールは単なる Python の呼び出し可能な関数(コールアブル)であり、その出力であるマスク、深度マップ、カメラ幾何学情報、軌道などは、通常の Python 変数として扱われます。
このカーネルは 6 つのパブリックエントリーポイントを公開しています。InputImages はサンプリングされたフレームを保持します。Metadata にはフレームレート、持続時間、フレームインデックスが含まれます。tools は知覚および幾何学プリミティブを公開します。show() は画像をエージェントの次のコンテキストに埋め込みます。vlm はクエリを別の VLM セッションにディスパッチします。ReturnAnswer() は最終回答を提出します。
2 つの知覚ツールが中核を担っています。tools.Reconstruct は Depth Anything 3 をラップし、フレームごとの深度、カメラ内部パラメータ(イントリックス)、外部パラメータ(エクストリンスクス)、および密な点マップを返します。tools.SAM3 は SAM 3 をラップし、テキスト、ポイント、またはボックスのプロンプトから画像または動画のマスクを生成します。このフレームワークには、軽量ユーティリティとして tools.Geometry、tools.Mask、tools.Time、tools.Graph、tools.Draw が追加されています。
これはトレーニング不要です。同じシステムプロンプト、ツールセット、ハイパーパラメータがすべてのベンチマークとバックボーンで共通して使用されます。
 imagehttps://spatialclaw.github.io/static/pdfs/spatialclaw.pdf
imagehttps://spatialclaw.github.io/static/pdfs/spatialclaw.pdf
なぜアクションインターフェースが重要なのか
研究チームは、同じ質問に対して 3 つの異なるアクションインターフェースを検討しました。ヒーターとドアの間の最短距離を測定する場合を考えてみましょう。
シングルパスコードでは、一度に完全なプログラムを記述して実行します。中間マスクや深度マップを確認する前に、すでに戦略全体を確定してしまうため、誤った仮定がそのまま回答に伝播してしまいます。
構造化されたツール呼び出しは、固定された JSON スキーマを通じて名前付きツールを呼び出します。これでは、NumPy や SciPy と出力を自由に組み合わせてテスト時の計算式を表現することができません。最短点演算に対応する事前登録済みのツールがないため、結果が誤ってしまいます。
SpatialClaw はコード内でツールを構成し、結果を検証した上で修正を行います。まず重心距離を計算しますが、その際重心が中央値を使用していることに気づきます。そこでエージェントは scipy.spatial.KDTree に切り替え、真に最も近い点を見つけます。その結果、0.9 m の正解値に対して 0.9439 m を提出しました。
ベンチマーク
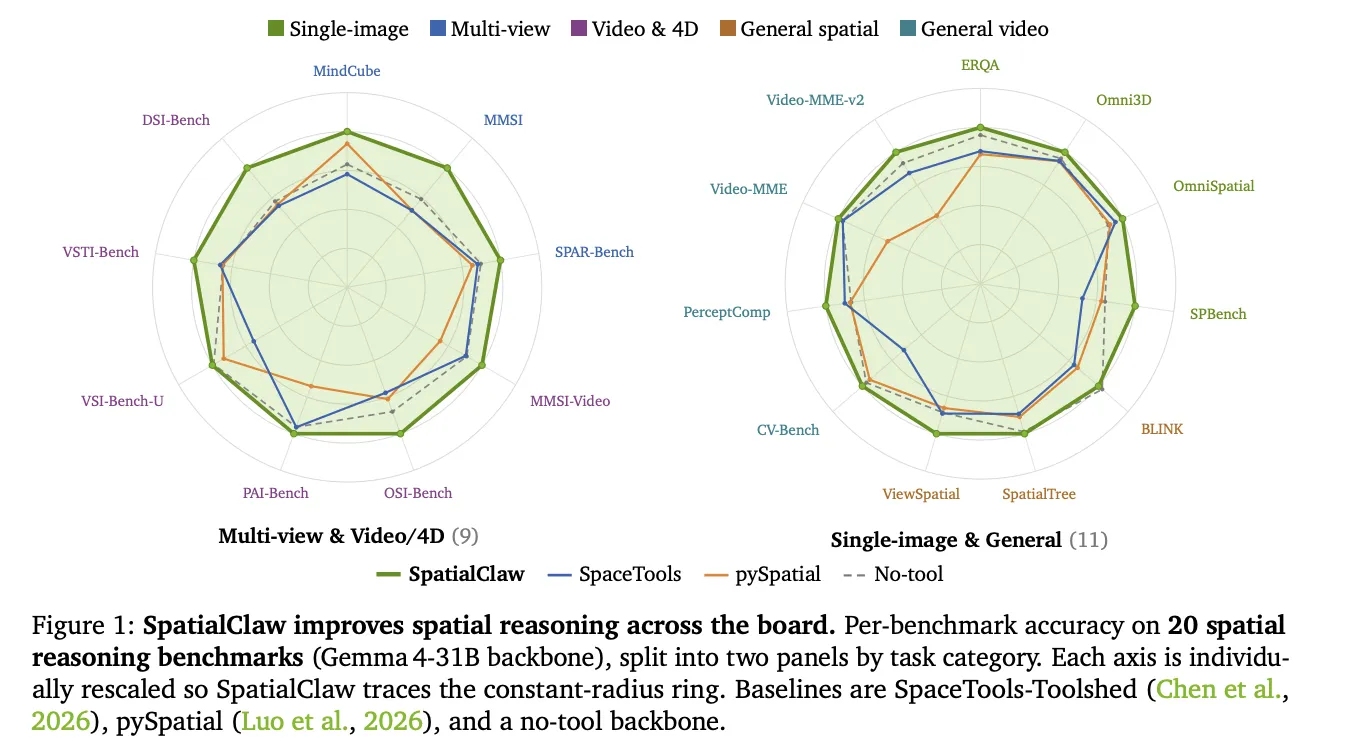
SpatialClaw は 5 つのカテゴリーにわたる 20 のベンチマークでテストされました。これらは単一画像、多視点、一般、動画、および一般動画理解の各領域を網羅しています。Qwen3.5/3.6 および Gemma4 ファミリーに属する 26B から 397B パラメータまでのバックボーンにおいて、ツールなしベースラインと比較してすべての 6 つのバックボーンで性能が向上しました。
インターフェースの影響を孤立させるための制御比較では、3 つの変種すべてが同じツールセットとプロンプトを共有しています。唯一異なるのはアクションインターフェースです。
アクションインターフェース | 平均 (20 ベンチ) | ツールなしとの差 Δ
---|---|---
ツールなしベースライン | 53.4 | —
シングルパスコード | 55.2 | +1.8
構造化ツール呼び出し | 56.7 | +3.3
SpatialClaw (コードをアクションとして) | 59.9 | +6.5
Gemma4-31B バックボーン、20 ベンチ平均。
同じ Gemma4-31B バックボーン上で先行する空間エージェントと比較すると、その差はさらに広がります。
手法 | インターフェース | 平均 | SpatialClaw との差 Δ
---|---|---|---
VADAR | シングルパス | 40.5* | −19.4
pySpatial | シングルパス | 47.8 | −12.1
SpaceTools-Toolshed | 構造化ツール呼び出し | 48.7 | −11.2
SpatialClaw | コードをアクションとして | 59.9 | 最高
VADAR は動画や多画像入力をサポートしておらず、単一画像ベンチマークのみが平均化されています。
最大の改善は動的タスクにおいて見られました。Gemma4-31B 上では DSI-Bench が +17.6 ポイント、MindCube が +15.3 ポイント向上しました。これらのカテゴリでは、フレーム間および視点にわたる連鎖的な幾何計算が必要です。
⟦CODE_0⟧
⟦CODE_1⟧
LLM-as-judge の評価による勝因の分析では、構造化されたツール呼び出しに対する優位性が説明されています。コード構成がその 52.2% を占め、制御フローが 19.5%、残りの 28.3% はインターフェースに依存しない要因です。
五段階ループの内部
各サンプルは、計画(planning)、コード生成(code generation)、コード実行(code execution)、フィードバック集約(feedback assembly)、回答提出(answer submission)という五つのステージからなるループを実行します。プランナーは画像を見ずに戦略を策定します。メインエージェントはステップごとに 1 つの Python セルを作成します。静的な AST チェッカーが実行前に不安全なコードを拒否します。このループは、ReturnAnswer() が呼び出されるか、30 ステップ経過するまで繰り返されます。
公式リポジトリは LangGraph ワークフローと永続的な Jupyter カーネル上で動作します。バックボーン(基盤モデル)は vLLM を介して提供され、知覚機能は FastAPI GPU サービスの背後で実行されます。単一のクイックスタートでは、1 つのマシンで 1 つのベンチマークを実行できます:
git clone --recursive https://github.com/NVlabs/SpatialClaw.git
cd SpatialClaw
bash spatial_agent/scripts/setup.sh
cp .env.example .env # API キーを追加するか、vLLM をセルフホストする
python -m spatial_agent.entrypoints.run \
--dataset spatial_agent/config/dataset/erqa.json \
--model spatial_agent/config/model/gemini-3-pro.json \
--concurrency 4代表的なエージェントセルは、知覚機能と幾何学(geometry)を組み合わせ、その後修正を行います:
{
"perception": "...",
"geometry": "..."
}シーンを再構築し、1 つのビデオパスで両方のオブジェクトをセグメント化する
recon = tools.Reconstruct.Reconstruct(InputImages)
seg = tools.SAM3.segment_video_by_text(["radiator heater", "door"])
show(seg.visualize(1)) # まずマスクを検証する
重心ではなく、KD ツリー(k-d tree)を用いた最接近点距離
pts_h = seg.get_masked_points(recon, frame=1, object=0) # オブジェクト 0 = ヒーター
pts_d = seg.get_masked_points(recon, frame=2, object=1) # オブジェクト 1 = ドア
dists, _ = scipy.spatial.KDTree(pts_d).query(pts_h, k=1)
ReturnAnswer(float(dists.min()))
エージェントは、質問自体からプリミティブ(基本要素)を選択します。距離に関する問いには KD ツリー検索とベクトルノルムが用いられ、方向に関する問いには内積が頼られます。カテゴリ固有のルーティングは適用されていません。
ユースケース
この設計は、段階的な幾何学的推論を必要とする問題に適しています。具体的な例としては以下があります:
- 動作する前にオブジェクト間の計測距離を測定するロボットや具現化エージェント(embodied agents)
- 複数のカメラアングルからオブジェクトの向きを復元するマルチビュー検査
- フレームにわたるオブジェクトまたはカメラの動きを追跡するビデオおよび 4D 解析
- 「ドアはシンクに対してどこにあるか?」といった屋内シーン質問応答
トレーニングフリー(学習不要)であるため、チームは新しいデータやファインチューニングを必要とせず、展開済みの VLM(Vision-Language Model:視覚言語モデル)を拡張できます。
インタラクティブ・エクスプローラー
(function(){
window.addEventListener('message',function(e){
if(e&&e.data&&e.data.type==='sc-resize'){
var f=document.getElementById('spatialclaw-demo');
if(f&&e.data.height){f.style.height=e.data.height+'px';}
}
});
})();
Key Takeaways
コードをアクションインターフェースとして: SpatialClaw は、VLM(視覚言語モデル)が各ステップごとに 1 つの Python セルを永続的なカーネルに記述することを可能にし、固定された計画にコミットするのではなく、知覚出力を組み合わせて修正します。
最先端かつトレーニング不要: 20 の空間ベンチマーク全体で平均 59.9% を達成し、事前のエージェントである SpaceTools よりも +11.2 ポイント向上しました。これは、ベンチマークやモデル固有の調整を行わずに達成された結果です。
インターフェースがレバーとなる: Gemma4-31B のアクションインターフェースのみを切り替えることで、精度は 56.7(構造化ツール呼び出し)から 59.9 に向上し、勝利の 52.2% がコードの組み合わせによるものです。
幾何学的連鎖において最大の改善: ダイナミックな 4D およびマルチビュータスクで上昇幅が最も大きく(DSI-Bench で +17.6、MindCube で +15.3)、これらはフレームや視点にわたってステップを組み立てる必要がある領域です。
知覚が上限となる: 改善効果は 6 つのバックボーン(26B〜397B)全体で転移しますが、残されたボトルネックは知覚品質であり、ライセンスは非商用に限られています。
論文、プロジェクト、リポジトリをご覧ください。また、Twitter でフォローしていただくことも歓迎します。150 万人以上の ML サブレッドに参加し、ニュースレターを購読することを忘れないでください。待ってください!Telegram をご利用ですか?今なら Telegram でも参加できます。
GitHub リポジトリや Hugging Face ページ、製品リリース、ウェビナーなどのプロモーションのためにパートナーシップをご検討の場合は、ご連絡ください。
NVIDIA AI が SpatialClaw を発表:空間推論のためのアクションインターフェースとしてコードを扱うトレーニング不要のエージェント(続き 7/7)
この投稿は、MarkTechPost で最初に公開された「NVIDIA AI Introduce SpatialClaw: A Training-Free Agent That Treats Code as the Action Interface for Spatial Reasoning」の続編です。
原文を表示
NVIDIA Research has released SpatialClaw, a training-free framework for spatial reasoning. It targets a persistent weakness in vision-language models (VLMs). These models still struggle to judge where objects are, how they relate, and how they move in 3D.
SpatialClaw does not retrain the model. Instead, it changes the action interface the agent uses to call perception tools. The research team argues the interface is the bottleneck. Their solution is to treat code as the action interface. Across 20 benchmarks, SpatialClaw reaches 59.9% average accuracy. It outperforms the recent spatial agent SpaceTools by 11.2 points.
What is SpatialClaw
SpatialClaw is an agent loop wrapped around a stateful Python kernel. The kernel is pre-loaded with input frames and a set of primitives. Perception tools are plain Python callables. Their outputs, including masks, depth maps, camera geometry, and trajectories, are ordinary Python variables.
The kernel exposes six public entry points. InputImages holds the sampled frames. Metadata carries frame rate, duration, and frame indices. tools exposes perception and geometry primitives. show() embeds an image into the agent’s next context. vlm dispatches queries to a separate VLM session. ReturnAnswer() submits the final answer.
Two perception tools are central. tools.Reconstruct wraps Depth Anything 3 and returns per-frame depth, camera intrinsics, extrinsics, and dense point maps. tools.SAM3 wraps SAM 3 and produces image or video masks from text, point, or box prompts. The framework adds lightweight utilities: tools.Geometry, tools.Mask, tools.Time, tools.Graph, and tools.Draw.
It is training-free. The same system prompt, tool set, and hyperparameters run across every benchmark and backbone.
imagehttps://spatialclaw.github.io/static/pdfs/spatialclaw.pdf
Why the Action Interface Matters
The research team studied three action interfaces on the same question. Consider measuring the closest distance between a heater and a door.
Single-pass code writes one complete program and runs it once. It commits to a full strategy before seeing any intermediate mask or depth map. A wrong assumption then propagates straight to the answer.
Structured tool-call invokes named tools through a fixed JSON schema. It cannot freely combine outputs with NumPy or SciPy to express test-time computations. The closest-point operation has no pre-registered tool, so the result is wrong.
SpatialClaw composes tools in code, inspects results, then revises. It first computes a centroid distance, then notices the centroid uses a median. The agent switches to scipy.spatial.KDTree to find the true closest point. It submits 0.9439 m against a 0.9 m ground truth.
Benchmark
SpatialClaw was tested on 20 benchmarks across five categories. These span single-image, multi-view, general, video and 4D, and general video understanding. It improves over the no-tool baseline on all six backbones tested. Backbones range from 26B to 397B parameters across the Qwen3.5/3.6 and Gemma4 families.
A controlled comparison isolates the interface. All three variants share the same toolset and prompt. Only the action interface differs.
Action interfaceAvg. (20 bench.)Δ vs no-tool
No-tool baseline53.4–
Single-pass code55.2+1.8
Structured tool-call56.7+3.3
SpatialClaw (code as action)59.9+6.5
Gemma4-31B backbone, 20-benchmark average.
Against prior spatial agents on the same Gemma4-31B backbone, the gap widens.
MethodInterfaceAvg.Δ vs SpatialClaw
VADARSingle-pass40.5*−19.4
pySpatialSingle-pass47.8−12.1
SpaceTools-ToolshedStructured tool-call48.7−11.2
SpatialClawCode as action59.9best
VADAR does not support video or multi-image inputs; only single-image benchmarks are averaged.
The largest gains land on dynamic tasks. On Gemma4-31B, DSI-Bench rose +17.6 points and MindCube rose +15.3 points. These categories need chained geometric computation across frames and viewpoints.
An LLM-as-judge attribution explains the wins over structured tool-call. Code composition accounts for 52.2% of them. Control flow accounts for 19.5%, and the remaining 28.3% are interface-neutral.
Inside the Five-Stage Loop
Each sample runs a five-stage loop: planning, code generation, code execution, feedback assembly, and answer submission. A planner drafts a strategy without seeing the images. The main agent then writes one Python cell per step. A static AST checker rejects unsafe code before execution. The loop repeats until ReturnAnswer() is called or 30 steps pass.
The official repo runs on a LangGraph workflow and a persistent Jupyter kernel. Backbones serve through vLLM. Perception runs behind a FastAPI GPU service. A single quickstart runs one benchmark on one machine:
Copy CodeCopiedUse a different Browser
git clone --recursive https://github.com/NVlabs/SpatialClaw.git
cd SpatialClaw
bash spatial_agent/scripts/setup.sh
cp .env.example .env # add API keys, or self-host vLLM
python -m spatial_agent.entrypoints.run \
--dataset spatial_agent/config/dataset/erqa.json \
--model spatial_agent/config/model/gemini-3-pro.json \
--concurrency 4
A representative agent cell composes perception with geometry, then revises:
Copy CodeCopiedUse a different Browser
Reconstruct the scene, then segment both objects in one video pass
recon = tools.Reconstruct.Reconstruct(InputImages)
seg = tools.SAM3.segment_video_by_text(["radiator heater", "door"])
show(seg.visualize(1)) # inspect the masks first
Closest-point distance via KD-tree, not centroids
pts_h = seg.get_masked_points(recon, frame=1, object=0) # object 0 = heater
pts_d = seg.get_masked_points(recon, frame=2, object=1) # object 1 = door
dists, _ = scipy.spatial.KDTree(pts_d).query(pts_h, k=1)
ReturnAnswer(float(dists.min()))
The agent picks primitives from the question itself. Distance questions invoke KD-tree search and vector norms. Direction questions rely on dot products. No category-specific routing was applied.
Use Cases
The design fits problems that need step-by-step geometric reasoning. Concrete examples include:
Robotics and embodied agents that measure metric distances between objects before acting.
Multi-view inspection, where an object’s facing direction is recovered from several camera angles.
Video and 4D analysis that tracks object or camera motion across frames.
Indoor scene question answering, such as “where is the door relative to the sink?”
Because it is training-free, teams can extend a deployed VLM without new data or fine-tuning.
Interactive Explainer
(function(){
window.addEventListener('message',function(e){
if(e&&e.data&&e.data.type==='sc-resize'){
var f=document.getElementById('spatialclaw-demo');
if(f&&e.data.height){f.style.height=e.data.height+'px';}
}
});
})();
Key Takeaways
Code as the action interface: SpatialClaw lets a VLM write one Python cell per step into a persistent kernel, composing and revising perception outputs instead of committing to a fixed plan.
State of the art, training-free: 59.9% average across 20 spatial benchmarks, +11.2 points over the prior agent SpaceTools, with no benchmark- or model-specific tuning.
The interface is the lever: swapping only the action interface on Gemma4-31B moves accuracy from 56.7 (structured tool-call) to 59.9, and 52.2% of wins trace to code composition.
Biggest gains where geometry chains: dynamic 4D and multi-view tasks lead the lifts (DSI-Bench +17.6, MindCube +15.3), where steps must compose across frames and viewpoints.
Perception is the ceiling: gains transfer across six backbones (26B–397B), but the remaining bottleneck is perception quality, and the license is non-commercial.
Check out the Paper, Project and Repo. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post NVIDIA AI Introduce SpatialClaw: A Training-Free Agent That Treats Code as the Action Interface for Spatial Reasoning appeared first on MarkTechPost.
関連記事
eve の紹介:エージェント構築・実行・スケーリングのためのオープンソースフレームワーク
Vercel は、生産環境での動作に必要な部品を組立ずに定義だけでエージェントを構築できるオープンソースフレームワーク「eve」を発表した。同社は自社のエージェント開発にこのフレームワークを採用している。
エージェント構築・運用・スケーリングのためのオープンソースフレームワーク「eve」の公開
Vercel が、ファイル構成でエージェントを定義し、耐久性実行やサンドボックス機能などを備えたオープンソースフレームワーク「eve」を一般プレビューとして発表した。
Zyphra が Zamba2-VL を公開:ハイブリッド Mamba2–Transformer 型ビジョン言語モデルが初トークン生成時間を約 10 倍短縮
Zyphra は、画像とテキストを同時に処理するオープンソースのビジョン言語モデル「Zamba2-VL」シリーズ(パラメータ数 1.2B/2.7B/7B)を公開した。同社は従来の密集型 Transformer に代わり、ハイブリッド状態空間設計を採用し、競合と同等の精度を維持しつつ初トークン生成時間を約 10 倍短縮する技術を実現した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み