LLMで「何でも」できる時代のAIエンジニア生存戦略 - LLMのグラウンディング能力について
Algomatic は、LLM の座標出力の限界を指摘し、デザイン領域における次世代 AI エンジニアに求められる「グラウンディング能力」と「セマンティック理解」の組み合わせ戦略を提言している。
キーポイント
LLM/VLM のグラウンディング能力の限界
言語モデルは離散的なトークン処理に特化しており、画像内のオブジェクト位置(座標値)やサイズを定量的・高精度に出力する「グラウンディング」には本質的な困難を抱えている。
レイアウト理解に必要な 3 つの能力
デザイン領域での高度な AI 処理には、①空間的座標を特定するグラウンディング、②意味内容を捉えるセマンティック理解、③文脈から判断する推論能力の 3 要素が不可欠である。
次世代エンジニアへのスキル要件
単一のモデルで全てを解決しようとするのではなく、「グラウンディングに強いモデル」と「セマンティック理解に強いモデル」を組み合わせるアーキテクチャ設計が、今後の AI エンジニアの重要なスキルとなる。
実用例:ネオデザイン AI の課題
広告クリエイティブ生成において、既存のルールやテンプレート構造を維持しつつ要素を変更するには、ピクセルレベルから抽象概念までを深く理解する精密なレイアウト解析が必要だが、単一 VLM では精度不足に陥る。
Set-of-Mark手法の限界とクリエイティブへの不適合
画像にIDを直接描画するSet-of-Markは、セグメントが重なる場合や要素数が多いクリエイティブではID記載の精度が低下し実用性に欠ける。
LLMによる座標出力の仕組みとOCRの限界
LLMはトークン逐次予測のため座標出力に本質的な難しさがあり、既存OCRも文字認識特化でレイアウトやフォント属性の正確な把握には限界がある。
汎用モデルでは対応できないクリエイティブ特有の推論タスク
固有名詞の特定や空間的関係性の理解など、高度な推論能力とドメイン知識を要するクリエイティブ分野では、既存の物体検出・セグメントモデル単体では不十分である。
影響分析・編集コメントを表示
影響分析
この記事は、LLM が「何でもできる」という過信に対し、特に視覚情報と数値情報の結合(グラウンディング)における技術的ボトルネックを明確に指摘しており、業界全体で「単一モデル依存」から「マルチモーダル・ハイブリッドアーキテクチャ」への転換を促す重要な示唆を含んでいます。実務レベルの AI エンジニアリングにおいて、モデルの特性理解と適切な組み合わせ設計が、今後の競争優位性を決定づける核心スキルであることを浮き彫りにしています。
編集コメント
LLM の万能化が進む中で、あえて「できないこと(座標出力など)」を明確に定義し、解決策としてモデルの組み合わせを提案する視点は非常に鋭いです。実務で AI を導入・開発するエンジニアにとって、技術選定の指針となる重要な洞察です。

LLM(大規模言語モデル)や VLM(視覚言語モデル)で"何でも"できる時代において、LLM にはグラウンディングという苦手な事柄があります。
LLM/VLM を、グラウンディングができるモデルとうまく組み合わせるといいかもしれません。
この「グラウンディングをどうするか」が次世代の AI エンジニアに求められるスキルの一つかもしれません。
こんにちは。Algomatic の AX カンパニーでは現在 AI エージェントネイティブなデザインツール「ネオデザイン AI」を開発しています。
neodesign-ai.com
今回は、AI エンジニアとしてこのプロダクトの AI 技術開発に携わる中で得られた知見について、皆さんにお伝えしたいと思います。
- この記事は現在進行形で発展している技術領域についての考察であり、また、筆者の個人的な見解や推測を含んでいます。AI 技術の進歩は非常に速く、記事執筆時点での情報や分析が将来的に変わる可能性があります。また、技術的な内容については間違いや不正確な部分が含まれている場合もありますので、重要な判断を行う際は最新の情報や専門的な資料もあわせてご確認いただければと思います。
ネオデザイン AI の対象ドメインは、広告クリエイティブのデザインです。クリエイティブとは、SNS の広告などで使われる画像のことです。
このようにイベントの広告や商品の宣伝で使われるものがあります。
クリエイティブを制作するときには様々なステップがあります。例えば、クリエイティブを制作するための情報が載った企画書を理解し、テンプレートを選ぶ、細かくデザインを修正するなど、そのステップは多岐にわたります。
私たちが開発しているネオデザイン AI では以上のようなプロセスにおいて人の作業コストを減らすことを目標としています。今まではデザイナーが担当していた箇所をプロダクトが代わりに行うことで、非デザイナーでもクリエイティブの作成を行うことができるようになることを目指しています。
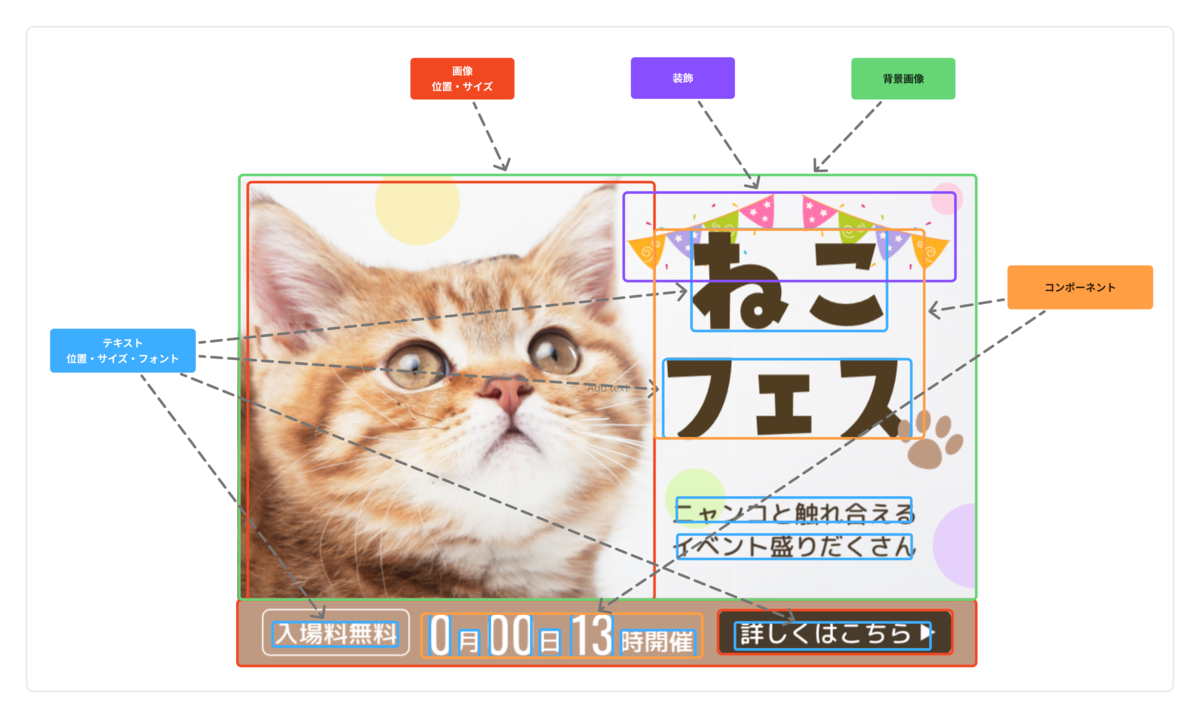
私たちが開発しているプロダクトにおいて重要なのは、AI がクリエイティブのレイアウトを深く理解する能力です。私たちはレイアウトの理解タスクを以下の要素を検出することと定義します。
位置・大きさ・フォント・ウェイト・カラー
画像+商品名テキストなどのまとまり
クリエイティブの要素の中でよく変更されるであろう要素
"深く"理解するとは?: 以下の図に示すように、レイアウトを理解するには位置や大きさといったピクセルレベルのものから、フォントやコンポーネント(構成部品)といった抽象度の高いものまで検出・理解する必要があります。
変数判定:レイアウト理解タスクにおける変数とは、あるクリエイティブのレイアウトを全く同じものを用いて、別のことを宣伝したい時に変更すべき箇所です。例えば、この猫フェスのクリエイティブのテンプレートを用いて犬のフェスの宣伝を行いたい場合には、「猫の画像」と「ねこフェスというテキスト」を変更する必要があることが考えられます。
これらがなぜ私たちのプロダクトにおいて重要かというと、例えば「会社が持つ既存のルールを守った高品質テンプレート生成」や「デザイン品質保証」には精密なレイアウト理解が不可欠だからです。
しかし、以上のように AI がデザインをうまく扱うにはいろいろな課題があると私たちは考えました。その中でも今回は、
VLM のグラウンディング能力の欠如
について解説したいと思います。
レイアウト理解タスクにおいて既存の AI が直面する最大の困難は、単一の技術では解決できない複合的な能力が要求されることです。具体的には、①グラウンディング能力、②セマンティックな理解能力、そして③推論能力という、異なる性質を持つ高度な能力を同時に必要とします。
①グラウンディング能力 "グラウンディング能力"とは、"AI が言葉や概念を、具体的なものや実際の世界と結びつけて理解する能力"のことです。LLM の"グラウンディング能力"として身近なものとしては、検索結果を利用して事実に基づく、という意味で聞いたことがあるかと思います。この「グラウンディング」という単語は他の分野、例えば画像分野でも使われます。画像分析におけるグラウンディング能力の一つは、AI が画像内で「どこに」オブジェクトが配置されているかを正確に特定する能力のことです。これは空間的な位置関係の理解に関わる基礎的な視覚認識能力です。
②セマンティックな理解能力 AI 分野におけるセマンティックとは、単純な物体認識を超えた抽象度の高い意味性の理解を意味します。例えば、クリエイティブの中に、「猫の画像」がある、などをいうことを意味します。例えば、猫という認識をせずにオブジェクトの位置だけを検出する場合はそれはセマンティックなタスクとは言わないことが多いでしょう。
③推論能力 さらに、近年話題になっている Reasoning という概念があります。LLM の場合だと、これは複雑な問題に対して理由をつけて (トークンを消費して) 回答をする能力を一般的には指しています。例えば、「画像の中で喉が渇いた時に欲しい物はどこにある?」という指示に対して、水の入ったペットボトルを見つけるには、喉が渇いた時に欲しい物とは何かを推論する必要があります。例えば、上記の例の画像の「ねこ」と「フェス」のテキストはグループになる、などというには、フォントが同じだから、とか、猫フェスで繋がるから、など推論能力が必要とされます。
このような技術が要求されるため、従来の手法ではレイアウト理解タスクにおいて十分な性能を発揮できませんでした。以下に具体的な事例を解説します。
私たちは開発当初、大規模言語モデル(LLM)と視覚言語モデル(VLM)を活用したレイアウト理解手法の開発に着手しました。最も直接的なアプローチとして、VLM にクリエイティブ画像を入力し、画像内の要素の位置情報を座標ベースで出力させる手法を試行しました。
しかし、この手法では期待された精度を得ることができませんでした。VLM や LLM は言語や画像のコンテキストでの理解に最適化されているため、「ここに商品画像が配置されている」といった定性的な記述は可能である一方、座標値(x, y)やサイズ情報(h, w)を数値として定量的に正確に出力することに本質的な困難を抱えていることが予想されます。この結果は、言語モデルの設計思想が連続的な数値処理よりも離散的なトークン処理に特化していることに起因すると考えられます。
Google は Gemini を用いて Spatial Understanding、つまり物体検出が可能であることを提案しています。これは Gemini に画像を与えて BoundingBox を JSON 形式で出力させるというものです。Bounding Box とは物体検出において広く用いられる座標の羅列形式です。例えば (x_min, y_min, x_max, y_max) という羅列です。これを用いると検出対象の物体を囲む四角形を描画することができます。以下に示すように私たちはこれを試しましたが、まだ精度が不十分です。
Set-of-Mark Prompting ではこれらの課題をスマートに解決しています。
Set-of-Mark ではまず、画像に対して SAM などのモデルを用いて"すべてに適当に"セグメントを行います。その後、セグメント領域全てに ID を振り、その ID を画像に直接描画します。その数字が描画された画像をクローズドな VLM(論文では GPT4V)に直接入力することで、出力のテキストの中で ID を用いて回答をセグメントマスクでグラウンディングできるようにします。こうすることで、VLM(GPT4V)にセグメントの情報が入力・出力できない問題を解決しています。
しかし、以下の問題が論文で指摘されています。
小さいセグメントの上に大きなセグメントが被る
番号が別のセグメントの上に重なる
セグメントの数が多くなったり、セグメント自体が小さくなると ID の数が膨大になり、画像に正確に ID を記載させるのが難しくなる
特にクリエイティブは、要素の数が多いのでこの手法では問題があります。
言語モデルで BoundingBox を出力させることは"正しい"のでしょうか?
LLM の基本的な動作原理は次トークンの確率分布を出力させて、高い確率を持つ単語を選択するというものです。(サンプリングの説明を省きます。)
この処理方式を Bounding Box の出力に適用した場合、座標の出力をする際に例えば座標値「123.45」を出力する場合、現代の言語モデルは「123」「.」「45」といった個別のトークンを再帰的に順次予測します。(というトークナイザーがあるとします。)
この画像の例のように、次のトークン予測になるため、「1.0」の「0」を出力する時には、「1.」の次に何が来るか、ということを考えることになります。これは従来の物体検出のモデルとは全く異なる仕組みです。従来の物体検出モデルは直接座標を出力するように学習されます。
実は Gemini Spatial Understanding では 0 から 1000 の値で座標値を出力させることで小数点をなくし、全ての数値を一つのトークンで表しています。つまり内部では擬似的に分類タスクになっているとも言えるかもしれません。しかし、ここで気になるのは「物体検出タスクを分類タスクとして解くことは精度が出やすいか?」ということです。
OCR(Optical Character Recognition)とは、画像上に存在するテキストの内容を検出・認識する技術です。しかし、従来の OCR は主にテキストの文字内容の識別に特化しており、位置情報や視覚的属性の正確な把握には本質的な限界があります。フォント属性認識における課題 OCR 技術が抱える主要な問題点として、以下が挙げられます:
位置・サイズ情報の不正確性 - テキストの配置や大きさを精密に捉えることが困難
フォントの差異を認識する限界 - フォントサイズやウェイト(太さ)の細かな違いを識別できない
視覚的階層の理解不足 - デザイン上の重要度やレイアウト構造を把握できない
OCR はすでに多くの API ベースのサービスとして展開されています。しかし、これらの既存の OCR サービスを用いた実験においても、文字サイズの正確な検出において顕著な精度不足が確認されました。これは、OCR 技術の根本的な設計思想が文字認識に重点を置いており、レイアウト解析には適していないことを示しています。
クリエイティブ画像内にあるテキストのフォントやフォントの色を検出するというタスクも必要です。フォントを検出することは、クリエイティブでは様々なフォントが使われるため、対応が難しいです。フォントカラーに関しては、理論上セグメンテーション(物体分割)が 100% の精度で可能であればテキストを切り取って、ルールベースで色を判定することができます。しかしそもそも先述したように、日本語のテキストに対するセグメンテーションの精度を高めるのは難しいでしょう。
物体検出・セグメンテーションタスクはグラウンディング( grounding )と密接な関係があります。これは位置を検出すること自体がグラウンディングと言えるからでしょう。物体検出やセグメントに関してはこれまでたくさんの研究がされ、OSS の訓練済みのモデルも発表されてきています。これらのモデルは一般的な物体検出タスクにおいて優れた性能を示すと考えられますが、クリエイティブ分野での応用や複雑な推論の要求されるタスクにおいて、これらのモデルのみを用いることは以下のような理由から重要な限界を抱えています。
セグメンテーション:セグメントに関しては、例えば Segment Anything Model などのモデルを用いるとセグメントができますが、どのような物体へのセグメントができているかが理解できていないのでこの結果を直接利用してレイアウトの分析をするのが難しいという課題があります。
推論能力・知識量の限界 さらに、これらのモデルの課題は推論能力や知識量の不足であると考えます。例えば、お菓子の〇〇 (商品名) を宣伝するクリエイティブ画像に対して、「〇〇 (商品名) の画像をセグメントして」のような固有名詞を含む指示がある場合、これらの従来のモデルは適切に対応できません。また、「右にある三つの商品画像のうち、真ん中にある商品だけをセグメントして」といった空間的関係性や順序性を要求する複雑なクエリの処理も困難です。このような高度な推論タスクに対応するためには、言語モデルのような推論能力が必要と予想されます。
クリエイティブの画像データとしての複雑性 クリエイティブ分野特有の問題として、複雑で多様なレイアウト構造があります。一般的な物体検出モデルは一般的なオブジェクトカテゴリで事前学習されているため、クリエイティブデザインの独特な要素や配置パターンに対する理解が不十分です。この学習データの偏りと実際のクリエイティブ制作現場でのニーズとの乖離が、実用性の阻害要因となっていると考えられます。
セグメントが可能な LLM モデル
LLM の推論能力とセグメントのグラウンディング能力を統合しようという取り組みが多くされています。多数の手法がある中でもここでは 2 つ簡単にご紹介します。一つ目は事前学習済みの LLM と別のセグメントができるモデルを組み合わせて LLM の出力をデコードしてセグメントにするようなアーキテクチャで、どちらのモデルも学習させる方法です。(LISA, GLaMM) 二つ目の方法として、一つ目の方法の中のマスク生成モデル(例えば SAM2)をフリーズして、LLM のみをチューニングし、最適なセグメントのマスクを得るために、マスク生成モデルに入力されるプロンプトを最適化するという手法があります。(Seg-R1, SAM-R1)
 セグメントが可能な LLM の主なアーキテクチャ (かなり単純化されており、省略されていることが多いので注意してください)
セグメントが可能な LLM の主なアーキテクチャ (かなり単純化されており、省略されていることが多いので注意してください)
弱点:二つ目の手法に関してはこのアーキテクチャで学習させたとしてもセグメントモデル自体の能力はパラメータレベルでは変わらないことがわかります。一つ目の手法に関しては LLM の推論能力が、訓練される OSS の LLM の能力に依存してしまいます。
Document AI とは、書類を理解するための AI であり、基本的には文章や画像がどこにあるかを理解することを目的としています。例えば、LayoutParser は書類について理解することを目的としています。クリエイティブを対象としていません。この文脈において私たちは、クリエイティブと Document の違いは、複雑性にあると考えています。クリエイティブでは例えば、多様なフォントが使われたり、テキストの配置に一定のルールが見られなかったりします。そのため Document AI の対象のドキュメントよりも「複雑」なものを対象とします。
デザインに関するエージェントの研究
既存研究デザインに対するエージェントには以下のようなものがあります。BannerAgency では、デザインのデータを JSON 形式で表現し LLM が生成できるようにしています。COLE は、デザインを JSON 形式で表し、そのデータ構造で、OSS の LLM モデルを訓練しています。StepbyStep で生成し、最初にレイアウト構成、画像は後から生成しています。PosterLlama では、背景画像を生成した上で HTML のような形式でテキストを生成しています。いずれもレイアウトを詳細に深く理解して分析するというグラウンディングの話はしておらず、一般的なレイアウト生成の話をしています。
興味深い点としては、BannerAgency では VLM を用いてフィードバックを行うプロセスを導入しています。しかしそもそも VLM が精度よく検出できる能力には限界があります。例えば、「テキストを 3px 左に動かせば背景画像の顔と被らない」などといったような細かな検出は不得意である事が予想されるため、そもそもフィードバックのシグナルを生成するのが難しいという課題があります。
学習コストの問題:一般的にこれらの AI モデルを開発するには、学習コストがかかります。セグメンテーションのモデルや物体検出のモデルを学習するのはとてもコストがかかりますし、学習したモデルには以下の 2 点の問題があります
精度が悪いリスクがある:特にクリエイティブの場合には、検出対象が多様で特徴量が安定しないだろうという仮説があるため、学習に大量のデータが必要と予想される。
柔軟性がなくなる:検出するものがデータセットに依存するため、例えば新しく検出したいものが変更された時に、新たなデータセットを作成して、再学習させる必要がある。
従来の AI には以上のような問題があるため私たちは独自の方法で解決しました。従来の AI とは違い、LLM(大規模言語モデル)、VLM(視覚言語モデル)では抽象度が高いことが柔軟にできるようになってきています。AI という分野の歴史において、初期の頃に可能だったことは抽象度の低いタスクでした。もしくは、抽象度が高い事象を低い次元に落とし込む、特徴量の抽出を行うことで対処してきました。当時と比較すると、現在は自然言語の高度な質問に対応するといった抽象度がとても高いことができるようになってきています。私たちはこの時代において、レイアウト分析のように、抽象度の低いタスクと抽象度の高いタスクを同時に行うことが必要な場合、LLM(特にクローズドなモデル)と他の専門家モデル、例えば専門性のある物体検出のモデルを組み合わせることでゼロショット解決できる可能性があるということを提案します。
そこで、LLM モデルと物体検出のようなモデルを組み合わせるアプローチを採用しました。

End-to-End ではない方向性にした理由:私たちが開発した AI モデルは、前述のように、一つのモデルではなく、複数のステップから成り立っています。それに対して、AI の分野においては、End-to-End(エンドツーエンド)なモデルが存在します。End-to-End な AI とは、中身を全てをブラックボックス化し、単純に入力と出力のペアを用意して、一つの AI モデルを学習させることです。End-to-End なモデルを開発することは AI の業界において長らく行われてきました。しかし、①現在エージェントが台頭しつつあることと、②クリエイティブの理解には様々な能力が要求される、③学習コスト削減のため、私たちはこちらの方向性をとっています。ですが将来的にはデータセットを自動で作成するなどを行い、End-to-End なモデルを開発することは考えています。
学習コストがゼロ:私たちの AI の優位性は、学習なしで汎用性があることです。これは汎用性が高く、別分野への応用もしやすいことが予想できます。学習させないゼロショットの推論をするモデルであるため、例えば新しく検出したいものが増えたり、検出したくないと思った場合にすぐに対応できます。
ノイズの問題:物体検出のようなプロンプトエンジニアリングによる即時調整が効かないモデルの弱点は、時として異常なノイズを出力することです。このノイズを含んだまま次のプロセスに進むと、その後のプロセスに大きな影響を及ぼします。一般的にこのようなノイズを修正したい場合には、モデルを学習させる必要があります。それと比較して LLM や VLM と組み合わせる場合は、「プロンプトエンジニアリング」を用いることで時間をかけずに学習なしで出力を制御できるという利点があります。そのため組み合わせることで、専門的なモデルが出力したノイズを、VLM 側で「プロンプトエンジニアリング」を通して吸収できるという利点があります。
以下に他のモデルとの違いを簡単に図示しました。定量的なものではないので参考程度にしていただければと思います。
私たちはさまざまな手法を検証したうえでプロダクトに実装しました。今回は私たちが開発している中でも簡単な例として、いくつかの事例を紹介します。
以上の考え方を応用して、私たちはさまざまな手法を提案・開発し、プロダクトに実装しています。今回は私たちが開発している中でも簡単な例として、いくつかの事例を紹介します。(技術保護の観点から詳しい方法はお伝えすることができないことをご了承ください。)
画像変数とはクリエイティブの中で入れ替えられる素材のことです。例えば、この猫のクリエイティブにおいては、他のフェス、例えば犬のフェスティバルなどを宣伝する場合には、「猫の画像」は犬の画像に入れ替える必要があります。これを見つけるためには大きく二つの要素が重要です。①VLM などの推論能力を用いて変数となる物体を認識して、②グラウンディングできるモデルを用いて位置を特定する必要があります。
私たちは以下の図に示されるように、LLM だけではなく従来の検出モデルを用いて、LLM の推論能力と物体検出系のモデルのグラウンディング能力(grounding capability)を組み合わせた手法を提案しました。
こちらの結果を見ると、画像変数となる箇所を自動で判断して検出を行うことができていることがわかります。
以下のように複雑な「推論」能力と、どこにあるかという「グラウンディング」(位置特定)が必要とされます。
この猫のクリエイティブにおいて難しいのは、どこを検出すべきかという点です。例えば、右上のリボンの装飾だけを検出対象として認識して、他の丸い装飾などは変数ではなく背景画像として認識したいという気持ちがあります。そのため「高度な推論能力」が必要とされるのです。
このクリエイティブの場合は、人・手持ち扇風機・バックなどを認識するのではなく、右側にある画像を人物まとまりに変数としたいのであっています。
私たちの開発している AI の特徴として、「ほぼプロンプトエンジニアリングのみで検出対象を柔軟に変えることができる」があります。例えば、上のクリエイティブで顔や扇風機を検出したいような要件が出てきた場合に、モデルを再学習させることなく、プロンプトエンジニアリングのみで要件変更に対応できるという強みがあります。
テキストの位置を検出できる低レベルのモデルと VLM を組み合わせました。検出モデルを用いて VLM の能力を補完し、その過程で起きたノイズを VLM で吸収するという手法です。OCR やその他検出系のモデルは特にノイズが出やすいです。前述した通り、それらのノイズを VLM などのモデルでうまく吸収するという方針になっています。
まだ改善途中ではあるもののそれぞれの文字に対して精度よくバウンディングボックスが検出できていることがわかります。
今後は定量的に評価できる実験を行っていく予定です。
これからの AI 開発に重要かもしれないこと
現代の AI 開発において、私たちは「抽象度ドリブン開発(Abstraction-Driven Development)」という名前を提案したいと思います。これは、独立したモデルを用いて低レベルのタスクを高精度で処理し、LLM/VLM のタスクと明確に分離することに焦点を当てた開発手法です。
LLM には得意分野と苦手分野が明確に存在します。例えば、文章の感情分析や内容理解は非常に得意ですが、文字数を正確に数えるような単純な作業は意外にも苦手としています。数学の問題かどうかを判定することはできても、実際に数式を解くことになると精度が落ちる傾向にあります。
日常的な推論においても同様の傾向が見られます。「喉が渇いたから水が欲しい」という論理的な推論は得意でも、実際に水を取りに行くためにロボットのモータをどの程度動かすべきかという具体的な制御信号を出力するのは困難です。クリエイティブな領域でも、商品画像の存在を認識することはできても、その画像が画面上のどの位置にあるかを正確に特定することは課題となります。
理想的には、ある単一のモデルですべての課題を解決できれば素晴らしいことでしょう。実際に、近い将来にはそのような汎用的なモデルが登場する可能性も十分にあります。現在も LLM にグラウンディング能力(grounding ability)を付与する研究は活発に行われており、着実に進歩を遂げています。
しかし現実的には、まだ多くの困難なタスクが残されているのが現状です。この課題の根本的な原因は、現在の AI が言語という抽象的で処理しやすい文脈に特化して発展してきたため、物理的な世界との対応関係(グラウンディング)が必要な文脈との親和性が低いことにあると考えられます。
そこで私たちが提案したいのは、目の前のタスクに取り組む際に「これは言語の文脈で解くべき問題なのか?」という視点から問題を見直すことです。この問いかけによって、より適切なアプローチを選択し、効率的な解決策を見出すことができるのではないでしょうか。
Tool-Driven Development(ツールドリブン開発)
私たちは、このエージェントの時代における AI 開発の新たな開発方針としてさらに「Tool-Driven Development」を考案しました。
従来のアプローチでは、複雑なタスクを一つの大きな E2E モデルで解決しようとしていました。私たちが提案する手法では、「最終的に実現したい複雑なタスクを小さな単位に分解し、それぞれのタスクに特化した AI モデルを開発することで、最終的に高度な機能を持つエージェントを構築する」ことを目指します。
具体例として、私たちのネオデザイン AI プロジェクトでは、「クリエイティブに特化した物体検出モデル」を独立した AI モデルとして開発し、それをエージェントがツールとして活用することで、より高度な機能を持つエージェントの開発が可能になると考えています。
このアプローチにより、各コンポーネントの専門性を高めつつ、全体としてより柔軟で拡張性の高い AI システムを構築することができます。
"LLM で何でもできる時代”の AI エンジニア生存戦略
昨今、生成 AI の進化は本当に目覚ましく、従来は専門的な知識や技術を必要としていた様々なタスクが、誰でも気軽に取り組めるような時代になってきているように思います。文章を書いたり、画像を作ったり、プログラムを組んだりといったことが、生成 AI を使えば驚くほど簡単にできるようになっています。
ただ、この記事でお話ししてきたように、言語や画像の理解において LLM(大規模言語モデル)が素晴らしい能力を見せてくれる一方で、現実世界の物理的な部分や具体的な制御との間には、まだまだギャップがあるのが実情かもしれません。このギャップこそが、AI エンジニアの皆さんにとって腕の見せどころになるのではないでしょうか。
LLM が中心となっている今の時代だからこそ、あえて LLM 以外の技術やアプローチを上手に使って、LLM ではカバーしきれない部分を補っていく。そんなスキルが、これからの AI エンジニアには重要になってくるかもしれません。
LLM を使いこなすだけでなく、その得意不得意をしっかりと理解して、必要に応じて他の技術と組み合わせながら、より実用的で信頼できる AI システムを作り上げていく。AI 技術がどんどん身近になっていく中でも、そういった専門的な視点と技術力こそが、エンジニアとしての価値を保ち続ける鍵になっていくのかもしれません。
Algomatic では現在積極的に採用活動を行っています。
jobs.algomatic.jp
著:Shure、実験:Ootsuka

回答をする能力を一般的には指しています。例えば、「画像の中で喉が渇いた時に欲しい物はどこにある?」という指示に対して、水の入ったペットボトルを見つけるには、喉が渇いた時に欲しい物とは何かを推論する必要があります。 例えば、上記の例の画像の「ねこ」と「フェス」のテキストはグループになる、などというには、フォントが同じだから、とか、猫フェスで繋がるから、など推論能力が必要とされます。
このような技術が要求されるため、従来の手法ではレイアウト理解タスクにおいて十分な性能を発揮できませんでした。以下に具体的な事例を解説します。
私たちは開発当初、大規模言語モデル(LLM)と視覚言語モデル(VLM)を活用したレイアウト理解手法の開発に着手しました。最も直接的なアプローチとして、VLMにクリエイティブ画像を入力し、画像内の要素の位置情報を座標ベースで出力させる手法を試行しました。
しかし、この手法では期待された精度を得ることができませんでした。 VLMやLLMは言語や画像のコンテキストでの理解に最適化されているため、「ここに商品画像が配置されている」といった定性的な記述は可能である一方、座標値(x, y)やサイズ情報(h, w)を数値として定量的に正確に出力することに本質的な困難を抱えていることが予想されます。 この結果は、言語モデルの設計思想が連続的な数値処理よりも離散的なトークン処理に特化していることに起因すると考えられます。
GoogleはGeminiを用いてSpatial Understanding、つまり物体検出ができることを提案しています。 これはGeminiに画像を与えてBoundingBoxをJSON形式で出力させるというものです。 Bounding Boxとは物体検出において広く用いられる座標の羅列形式です。 例えば (x_min, y_min, x_max, y_max) という羅列です。これを用いると検出対象の物体を囲む四角形を描画することができます。 以下に示すように私たちはこれを試しましたまだ精度が不十分です。
Set-of-Mark Promptingではこれらの課題をスマート解決しています。
Set-of-Markではまず、画像に対してSAMなどのモデルを用いて"すべてに適当に"セグメントを行います。 その後、セグメント領域全てにIDを振り、そのIDを画像に直接描画します。 その数字が描画された画像をクローズドなVLM(論文ではGPT4V)に直接入力することで、出力のテキストの中でIDを用いて回答をセグメントマスクでグラウンディングできるようにします。 こうすることで、VLM(GPT4V)にセグメントの情報が入力・出力できない問題を解決しています。
しかし、以下の問題が論文で指摘されています。
小さいセグメントの上に大きなセグメントが被る
番号が別のセグメントの上に重なる
セグメントの数が多くなったり、セグメント自体が小さくなるとIDの数が膨大になり、画像に正確にIDを記載させるのが難しくなる
特にクリエイティブは、要素の数が多いのでこの手法では問題があります。
言語モデルでBoundingBoxを出力させることは"正しい"のでしょうか?
LLMの基本的な動作原理は次トークンの確率分布を出力させて、高い確率を持つ単語を選択するというものです。(サンプリングの説明を省きます。)
この処理方式をBounding Boxの出力に適用した場合座標の出力をする際に 例えば座標値「123.45」を出力する場合、現代の言語モデルは「123」「.」「45」といった個別のトークンを再帰的に順次予測します。(というトークナイザーがあるとします。)
この画像の例のように、次のトークン予測になるため、「1.0」の「0」を出力する時には、「1.」の次に何が来るか、ということを考えることになります。 これは従来の物体検出のモデルとは全く異なる仕組みです。 従来の物体検出モデルは直接座標を出力するように学習されます。
実はGemini Spatial Understandingでは0から1000の値で座標値を出力させることで小数点をなくし、全ての数値を一つのトークンで表しています。 つまり内部では擬似的に分類タスクになっているとも言えるかもしれません。 しかし、ここで気になるのは「物体検出タスクを分類タスクとして解くことは精度が出やすいか?」ということです。
OCR(Optical Character Recognition)とは、画像上に存在するテキストの内容を検出・認識する技術です。しかし、従来のOCRは主にテキストの文字内容の識別に特化しており、位置情報や視覚的属性の正確な把握には本質的な限界があります。 フォント属性認識における課題 OCR技術が抱える主要な問題点として、以下が挙げられます:
位置・サイズ情報の不正確性 - テキストの配置や大きさを精密に捉えることが困難
フォント差異の認識限界 - フォントサイズやウェイト(太さ)の細かな違いを識別できない
視覚階層の理解不足 - デザイン上の重要度やレイアウト構造を把握できない
OCRはすでにたくさんのAPIベースのサービスとして展開されています。 しかし、これらの既存のOCRサービスを用いた実験においても、文字サイズの正確な検出において顕著な精度不足が確認されました。これは、OCR技術の根本的な設計思想が文字認識に重点を置いており、レイアウト解析には適していないことを示しています。
クリエイティブの画像内にあるテキストのフォントやフォントの色を検出するというタスクも必要です。 フォントを検出することは、クリエイティブでは色々なフォントが使われるため、対応が難しいです。 フォントカラーに関しては、理論上セグメントが100%の精度で可能であればテキストを切り取って、ルールベースで色を判定することができます。しかしそもそも先述したように、日本語のテキストに対するセグメントの精度を高めるのは難しいでしょう。
物体検出・セグメンテーションタスクはグラウンディングと密接な関係があります。 これは位置を検出すること自体がグラウンディングと言えるからでしょう。 物体検出やセグメントに関してはこれまでたくさんの研究がされ、OSSの訓練済みのモデルも発表されてきています。 これらのモデルは一般的な物体検出タスクにおいて優れた性能を示すと考えられますが、 クリエイティブ分野での応用や複雑な推論の要求されるタスクにおいて、これらのモデルのみを用いることは以下のような理由から重要な限界を抱えています。
セグメンテーション:セグメントに関しては、例えばSegment Anything Modelのようなモデルを用いるとセグメントができますが、どのような物体へのセグメントができているかが理解できていないのでこの結果を直接利用してレイアウトの分析をするのが難しいという課題があります。
推論能力・知識量の限界 さらに、これらのモデルの課題は推論能力や知識量の不足であると考えます。 例えば、お菓子の〇〇(商品名)を宣伝するクリエイティブの画像に対して、「〇〇(商品名)の画像をセグメントして」のような固有名詞を含む指示がある場合、これらの従来のモデルは適切に対応できません。 また、「右にある三つの商品画像のうち、真ん中にある商品だけをセグメントして」といった空間的関係性や順序性を要求する複雑なクエリの処理も困難です。このような高度な推論タスクに対応するためには、言語モデルのような推論能力が必要と予想されます。
クリエイティブの画像データとしての複雑性クリエイティブ分野特有の問題として、複雑で多様なレイアウト構造があります。一般的な物体検出モデルは一般的なオブジェクトカテゴリで事前学習されているため、クリエイティブデザインの独特な要素や配置パターンに対する理解が不十分です。この学習データの偏りと実際のクリエイティブ制作現場でのニーズとの乖離が、実用性の阻害要因となっていると考えられます。
セグメントが可能なLLMモデル
LLMの推論能力とセグメントのグラウンディング能力を統合しようという取り組みが多くされています。 多数の手法がある中でもここでは2つ簡単にご紹介します。 一つ目は事前学習済みのLLMと別のセグメントができるモデルを組み合わせてLLMの出力をデコードしてセグメントにするようなアーキテクチャで、どちらのモデルも学習させる方法です。(LISA, GLaMM) 二つ目の方法として、一つ目の方法の中のマスク生成モデル(例えばSAM2)をフリーズして、LLMのみをチューニングし、最適なセグメントのマスクを得るために、マスク生成モデルに入力されるプロンプトを最適化するという手法があります。(Seg-R1, SAM-R1)
セグメントが可能なLLMの主なアーキテクチャ(かなり単純化されており、省略されていることが多いので注意してください)
弱点: 二つ目の手法に関してはこのアーキテクチャで学習させたとしてもセグメントモデル自体の能力はパラメータレベルでは変わらないことがわかります。一つ目の手法に関してはLLMの推論能力が、訓練されるOSSのLLMの能力に依存してしまいます。
Document AIとは、書類を理解するためのAIであり、基本的には文章や画像がどこにあるかを理解することを目的としています。 例えば、LayoutParserは書類について理解することを目的としています。クリエイティブを対象としていません。 この文脈において私たちは、クリエイティブとDocumentの違いは、複雑性にあると考えています。クリエイティブでは例えば、多様なフォントが使われたり、テキストの配置に一定のルールが見られなかったりします。そのためDocument AIの対象のドキュメント、よりも「複雑」なものを対象とします。
デザインに関するエージェントの研究
既存研究デザインに対するエージェントには以下のようなものがあります。 BannerAgencyでは、デザインのデータをJSON形式で表現しLLMが生成できるようにしています。 COLEは、デザインをJSON形式で表し、そのデータ構造で、OSSのLLMモデルを訓練しています。StepbyStepで生成し、最初にレイアウト構成、画像は後から生成しています。 PosterLlamaでは、背景画像を生成した上でHTMLのような形式でテキストを生成しています。 いずれもレイアウトを詳細に深く理解して分析するというグラウンディングの話はしておらず、一般的なレイアウト生成の話をしています。
興味深い点としては、BannerAgencyではVLMを用いてフィードバックを行うプロセスを導入しています。しかしそもそもVLMが精度よく検出できる能力には限界があります。 例えば、「テキストを3px左に動かせば背景画像の顔と被らない」などといったような細かな検出は不得意である事が予想されるため、そもそもフィードバックのシグナルを生成するのが難しいという課題があります。
学習コストの問題: 一般的にこれらのAIモデルを開発するには、学習コストがかかります。 セグメンテーションのモデルや物体検出のモデルを学習するのはとてもコストがかかりますし、学習したモデルには以下の2点の問題があります
精度が悪いリスクがある: 特にクリエイティブの場合には、検出対象が多様で特徴量が安定しないだろうという仮説があるため、学習に大量のデータが必要と予想される。
柔軟性がなくなる: 検出するものがデータセットに依存するため、例えば新しく検出したいものが変更された時に、新たなデータセットを作成して、再学習させる必要がある。
従来のAIには以上のような問題があるため私たちは独自の方法で解決しました。 従来のAIとは違い、LLM、 VLMでは抽象度が高いことが柔軟にできるようになってきています。 AIという分野の歴史において、初期の頃に可能だったことは抽象度の低いタスクでした。もしくは、抽象度が高い事象を低い次元に落とし込む、特徴量の抽出を行うことで対処してきました。 当時と比較すると、現在は自然言語の高度な質問に対応するといった抽象度がとても高いことができるようになってきています。 私たちはこの時代において、レイアウト分析のように、抽象度の低いタスクと抽象度の高いタスクを同時に行うことが必要な場合、LLM(特にクローズドなモデル)と他の専門家モデル、例えば専門性のある、物体検出のモデルを組み合わせることでゼロショット解決できる可能性があるということを提案します。
そこで、LLMモデルと物体検出のようなモデルを組み合わせるアプローチを採用しました。
End-to-Endではない方向性にした理由: 私たちが開発したAIモデルは、前述のように、一つのモデルではなく、複数のステップから成り立っています。 それに対して、AIの分野においては、End-to-Endなモデル、が存在します。 End-to-EndなAIとは、中身を全てをブラックボックス化し、単純に入力と出力のペアを用意して、一つのAIモデルを学習させることです。 End-to-Endなモデルを開発することはAIの業界において長らく行われてきました。 しかし、①現在エージェントが台頭しつつあることと、②クリエイティブの理解には様々な能力が要求される、③学習コスト削減のため、私たちはこちらの方向性をとっています。 ですが将来的にはデータセットを自動で作成するなどを行い、End-to-Endなモデルを開発することは考えています。
学習コストがゼロ: 私たちのAIの優位性は、学習なしで汎用性があることです。これは汎用性が高く、別分野への応用もしやすいことが予想できます。学習させないゼロショットの推論をするモデルであるため、例えば新しく検出したいものが増えたり、検出したくないと思った場合にすぐに対応できます。
ノイズの問題: 物体検出のようなプロンプトエンジニアリングのような即時性のある調整の効かないモデルの弱点は、 時々異常なノイズを出力することです。 このノイズを含んだままその後のプロセスに進むとその後のプロセスに大きく影響します。 一般的にこのようなノイズを修正したい場合にはモデルを学習しなければなりません。 それと比較してLLM・VLMと組み合わせる場合は、「プロンプトエンジニアリング」を用いることで時間をかけずに学習なしで出力を制御できるという利点があります。 そのため組み合わせることで専門的なモデルで出力されたノイズを、VLM側で「プロンプトエンジニアリング」を通して吸収できるという利点があります。
以下に他のモデルとの違いを簡単に図にしたものです。定量的なものではないので参考程度にしていただければと思います。
私たちはさまざまな手法を検証したうえでプロダクトに実装しました。 今回は私たちが開発している中でも簡単な例として、いくつかの事例を紹介します。
以上の考え方を応用して、私たちはさまざまな手法を提案・開発し、プロダクトに実装しています。 今回は私たちが開発している中でも簡単な例として、いくつかの事例を紹介します。 (技術保護の観点から詳しい方法はお伝えすることができないことをご了承ください。)
画像変数とはクリエイティブの中で入れ替えられる素材、のことです。 例えば、この猫のクリエイティブにおいては、他のフェス、例えば、犬のフェスティバルなどを宣伝する場合には、「猫の画像」は犬の画像に入れ替える必要があります。 これを見つけるためには大きく二つの要素が重要です。 ①VLMなどの推論能力を用いて変数となる物体を認識して、 ②グラウンディングできるモデルを用いて位置を特定する必要があります。
私たちは以下の図に示されるように、LLMだけではなく従来の検出モデルを用いて、LLMの推論能力と物体検出系のモデルのグラウンディング能力を組み合わせる手法を提案しました。
こちらの結果を見ると画像変数となる箇所を自動で判断して、検出を行うことができていることがわかります。
以下のように複雑な「推論」能力と、どこにあるかという「グラウンディング」が必要とされます。
この猫のクリエイティブにおいて難しいのは どこを検出すべきか、という点です。 例えば、右上のリボンの装飾だけを検出対象として認識して、 他の丸の装飾などは変数ではなく、背景画像として認識したいという気持ちがあります。 そのため「高度な推論能力」が必要とされるのです。
このクリエイティブの場合は、人・手持ち扇風機・バックなどを認識するのではなく 右側にある画像を人まとまりに変数としたいのであっています。
私たちの開発しているAIの特徴として「ほぼプロンプトエンジニアリングのみで検出対象を柔軟に変えることができる」があります。例えば、上のクリエイティブで顔や扇風機を検出したいような要件が出てきた場合に、モデルを再学習させることなく」、プロンプトエンジニアリングのみで要件変更に対応できるという強みがあります。
テキストの位置を検出できる低レベルのモデルとVLMを組み合わせました。 検出モデルを用いてVLMの能力を補完し、その過程で起きたノイズをVLMで吸収するという手法です。 OCRやその他検出系のモデルは特にノイズが出やすいです。 前述した通り、それらのノイズをVLMなどのモデルでうまく吸収するという方針になっています。
まだ改善途中ではあるもののそれぞれの文字に対して精度よくbounding boxが検出できていることがわかります。
今後は定量的に評価できる実験を行っていく予定です。
これからのAI開発に重要かもしれないこと
現代のAI開発において、私たちは「抽象度ドリブン開発(Abstraction-Driven Development)」という名前を提案したいと思います。これは、独立したモデルを用いて低レベルのタスクを高精度で処理し、LLM/VLMのタスクと明確に分離することに焦点を当てた開発手法です。 LLMには得意分野と苦手分野が明確に存在します。例えば、文章の感情分析や内容理解は非常に得意ですが、文字数を正確に数えるような単純な作業は意外にも苦手としています。数学の問題かどうかを判定することはできても、実際に数式を解くことになると精度が落ちる傾向にあります。 日常的な推論においても同様の傾向が見られます。「喉が渇いたから水が欲しい」という論理的な推論は得意でも、実際に水を取りに行くためにロボットのモータをどの程度動かすべきかという具体的な制御信号を出力するのは困難です。クリエイティブな領域でも、商品画像の存在を認識することはできても、その画像が画面上のどの位置にあるかを正確に特定することは課題となります。 理想的には、ある単一のモデルですべての課題を解決できれば素晴らしいことでしょう。実際に、近い将来にはそのような汎用的なモデルが登場する可能性も十分にあります。現在もLLMにグラウンディング能力を付与する研究は活発に行われており、着実に進歩を遂げています。 しかし現実的には、まだ多くの困難なタスクが残されているのが現状です。この課題の根本的な原因は、現在のAIが言語という抽象的で処理しやすい文脈に特化して発展してきたため、物理的な世界との対応関係(グラウンディング)が必要な文脈との親和性が低いことにあると考えられます。 そこで私たちが提案したいのは、目の前のタスクに取り組む際に「これは言語の文脈で解くべき問題なのか?」という視点から問題を見直すことです。この問いかけによって、より適切なアプローチを選択し、効率的な解決策を見出すことができるのではないでしょうか。
Tool-Driven Development(ツールドリブン開発)
私たちは、このエージェントの時代におけるAI開発の新たな開発方針としてさらに「Tool-Driven Development」を考案しました。 従来のアプローチでは、複雑なタスクを一つの大きなE2Eモデルで解決しようとしていました。私たちが提案する手法では、「最終的に実現したい複雑なタスクを小さな単位に分解し、それぞれのタスクに特化したAIモデルを開発することで、最終的に高度な機能を持つエージェントを構築する」ことを目指します。 具体例として、私たちのネオデザインAIプロジェクトでは、「クリエイティブに特化した物体検出モデル」を独立したAIモデルとして開発し、それをエージェントがツールとして活用することで、より高度な機能を持つエージェントの開発が可能になると考えています。 このアプローチにより、各コンポーネントの専門性を高めつつ、全体としてより柔軟で拡張性の高いAIシステムを構築することができます。
"LLMで何でもできる時代”のAIエンジニア生存戦略
昨今、生成AIの進化は本当に目覚ましく、従来は専門的な知識や技術を必要としていた様々なタスクが、誰でも気軽に取り組めるような時代になってきているように思います。文章を書いたり、画像を作ったり、プログラムを組んだりといったことが、生成AIを使えば驚くほど簡単にできるようになっています。 ただ、この記事でお話ししてきたように、言語や画像の理解においてLLMが素晴らしい能力を見せてくれる一方で、現実世界の物理的な部分や具体的な制御との間には、まだまだギャップがあるのが実情かもしれません。 このギャップこそが、AIエンジニアの皆さんにとって腕の見せどころになるのではないでしょうか。LLMが中心となっている今の時代だからこそ、あえてLLM以外の技術やアプローチを上手に使って、LLMではカバーしきれない部分を補っていく。そんなスキルが、これからのAIエンジニアには重要になってくるかもしれません。 LLMを使いこなすだけでなく、その得意不得意をしっかりと理解して、必要に応じて他の技術と組み合わせながら、より実用的で信頼できるAIシステムを作り上げていく。AI技術がどんどん身近になっていく中でも、そういった専門的な視点と技術力こそが、エンジニアとしての価値を保ち続ける鍵になっていくのかもしれません。
Algomaticでは現在積極的に採用活動を行っています。
jobs.algomatic.jp
著: Shure, 実験:Ootsuka
![](https://c
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み