AIエージェントの体系的デバッグ:AgentRxフレームワークの紹介
Microsoft Researchは、AIエージェントの失敗原因を特定する自動デバッグフレームワーク「AgentRx」と関連ベンチマークをオープンソースで公開した。
キーポイント
エージェントデバッグの課題
長期・確率的・マルチエージェントな実行軌道において、従来の手法では根本原因が埋もれやすく、失敗の特定が困難である。
AgentRxの動作原理
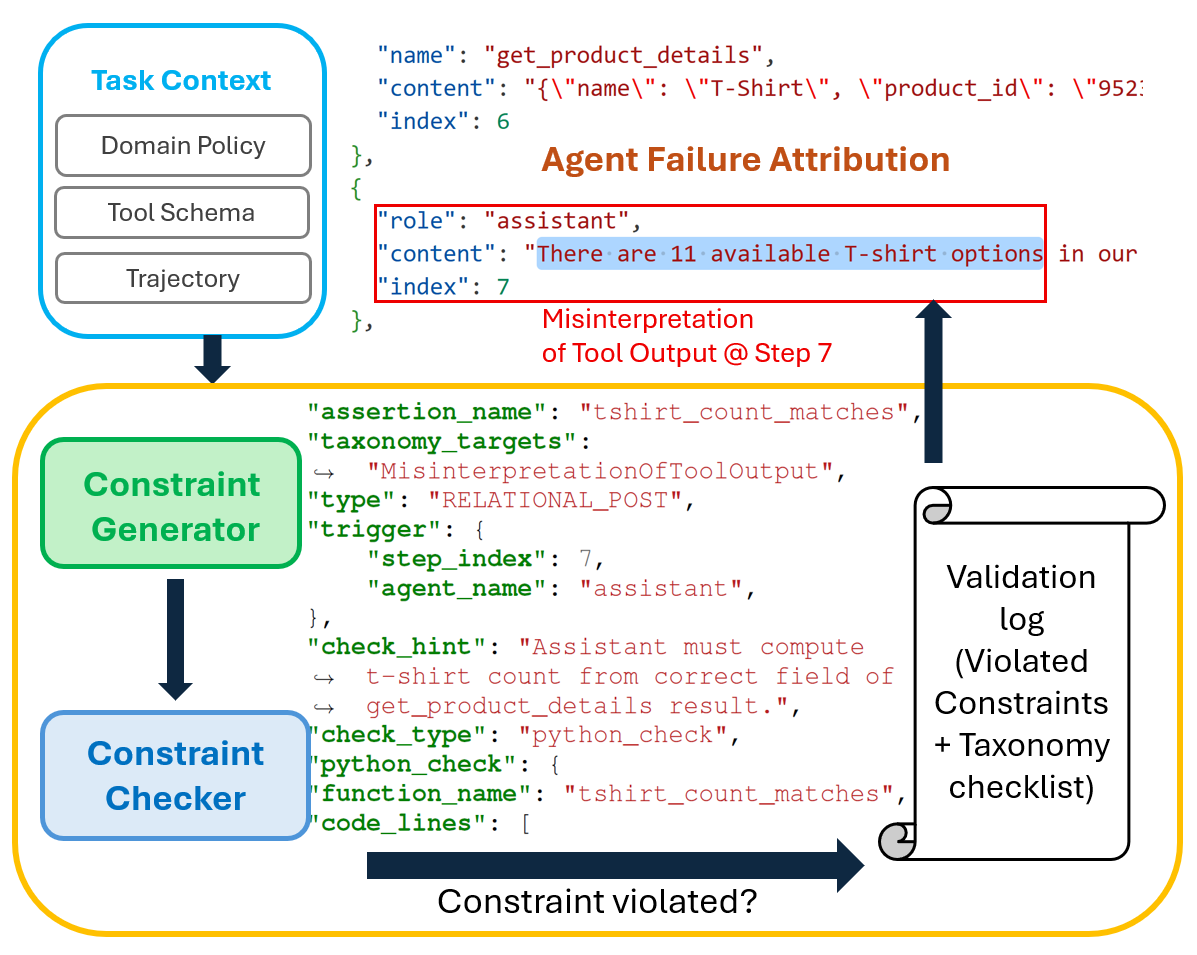
ツールスキーマとドメインポリシーから実行可能な制約を自動合成し、失敗が発生した「クリティカルステップ」を構造化して特定・ログ出力する。
ベンチマークと失敗分類の公開
τ-bench、Flash、Magentic-Oneから115件の手動注釈付き失敗軌道と9カテゴリの失敗分類タクソノミーをセットで公開した。
定量評価とオープンソース化
プロンプトベースの手法と比較し、失敗局所化が+23.6%、根本原因帰属が+22.9%向上し、コードとデータセットを公開した。
AgentRxの自動化デバッグパイプライン
ツールスキーマとドメインポリシーから制約を自動生成し、ステップごとのガード付き評価で監査可能な違反ログを作成した後、LLM判事が最初の重大な失敗ステップと根本原因を特定する。
多様なドメイン対応の失敗ベンチマークと分類体系
小売・サービス、インシデント管理、マルチエージェントシステムなど3領域の115件失敗事例を分析し、「計画違反」や「情報発明(ハルシネーション)」など9カテゴリの失敗分類タクソノロジーを確立。
既存手法を上回る高精度な失敗解析
AgentRxはLLMベースのプロンプティング比較群に対し、失敗の局所化精度で+23.6%、根本原因の帰属精度で+22.9%という大幅な改善を示した。
影響分析・編集コメントを表示
影響分析
本リリースは、自律型AIエージェントの実用化において不可欠な「透明性と信頼性」の課題に直接アプローチしている。構造化された制約合成と定量ベンチマークの提供により、開発現場でのデバッグ工数の大幅削減とエージェントの安全保証基準の確立に寄与する。今後はマルチエージェントシステムや複雑なAPI連携環境における標準デバッグツールとして普及が進むと予想される。
編集コメント
複雑化するエージェント実行環境において、単なる「成功/失敗」判定を超えた構造化デバッグ手法の標準化は必須である。本フレームワークがオープンソースで提供されることで、業界全体のデバッグ標準と評価指標の統一が進むことが期待される。

一言で言うと
問題:AI エージェントの失敗をデバッグするのは困難です。その理由は、実行軌跡(trajectories)が長く、確率的であり、しばしば複数エージェントにまたがるため、真の原因が埋もれてしまうからです。
解決策:AgentRx は、ツールスキーマとドメインポリシーからガード付きの実行可能制約を合成し、ステップごとに証拠に基づく違反をログ出力することで、回復不能な(「クリティカルファイル」)最初のステップを特定します。
ベンチマーク+分類体系:τ-bench、Flash、Magentic-One における手動注釈済み失敗軌跡 115 件を含む AgentRx Benchmark と、根拠のある 9 つのカテゴリからなる失敗分類体系を公開します。
結果とリリース:AgentRx はプロンプティングベースラインと比較して、失敗の局在化(+23.6%)と根本原因の帰属(+22.9%)を改善し、本フレームワークとデータセットはオープンソース化されます。
AI エージェントが単純なチャットボットから、クラウドインシデントの管理や複雑な Web インターフェースの操作、多段階 API ワークフローの実行が可能になる自律システムへと移行するにつれ、新たな課題が浮上しました:透明性です。
人間がミスを犯した場合、通常は論理を追跡して原因を特定できます。しかし、AI エージェントが失敗した場合はどうでしょうか。例えば、ツール出力のハルシネーション(幻覚)や、50 ステップからなるタスクの 10 ステップ目でのセキュリティポリシーからの逸脱などによって失敗した場合、どこで、なぜ間違えたのかを特定するのは、骨の折れる手作業となります。
本日、私たちはエージェントの軌跡における「致命的な失敗ステップ」を特定するために設計された、自動化されドメインに依存しないフレームワークである AgentRx(新しいタブで開く)のオープンソースリリースを発表できることを嬉しく思います。このフレームワークとともに、コミュニティがより透明性が高く、回復力のあるエージェントシステムを構築できるよう支援するための、手動注釈付きの失敗した軌跡 115 件からなるデータセット「AgentRx Benchmark」(新しいタブで開く)も公開いたします。
課題:なぜ AI エージェントはデバッグが難しいのか
現代の AI エージェントは往々にして以下の特性を持っています:
長期ホライズン(Long-horizon): 長時間にわたって数十回のアクションを実行します。
確率的(Probabilistic): 同じ入力でも異なる出力が生じるため、再現が困難です。
マルチエージェント(Multi-agent): 失敗がエージェント間で「引き継がれ」、根本原因が隠蔽されることがあります。
従来の成功指標(例:タスクは完了したか?)だけでは不十分です。安全なエージェントを構築するには、軌跡が回復不能となる正確な瞬間を特定し、そのステップで何が起きたのかという証拠を記録する必要があります。
AgentRx の紹介:自動化された診断「処方箋」
AgentRx(略称:Agent Diagnosis)は、エージェントの実行を検証が必要なシステムトレースとして扱います。単一の LLM にエラーを「推測」させるのではなく、構造化された多段階パイプラインを採用しています:
軌跡正規化(Trajectory normalization): 異なるドメインからの非一様なログを、共通の中間表現に変換します。
制約合成:本フレームワークは、ツールスキーマ(例:「API は有効な JSON 応答を返す必要がある」)およびドメインポリシー(例:「ユーザーの確認なしにデータを削除してはならない」)に基づいて実行可能な制約を自動的に生成します。
ガード付き評価:AgentRx は制約を段階的に評価し、各制約が適用される条件(ガード条件)のみをチェックしながら、証拠に基づく違反の監査可能な検証ログを生成します。
LLM による判定:最後に、LLM 判事が検証ログと根拠のある失敗分類体系を用いて、回復不能な最初のエラーである「クリティカル・フェイルステップ」を特定します。
 imageAgentRx のワークフロー:失敗した軌跡、ツールスキーマ、ドメインポリシーが与えられた場合、AgentRx はガード付き制約を合成し、段階的に評価して証拠付きの違反監査ログを生成します。その後、LLM 判事を用いてクリティカル・フェイルステップと根本原因カテゴリを予測します。
imageAgentRx のワークフロー:失敗した軌跡、ツールスキーマ、ドメインポリシーが与えられた場合、AgentRx はガード付き制約を合成し、段階的に評価して証拠付きの違反監査ログを生成します。その後、LLM 判事を用いてクリティカル・フェイルステップと根本原因カテゴリを予測します。
エージェント失敗のための新たなベンチマーク
AgentRx を評価するために、私たちは手動注釈付きのベンチマークを開発しました。これは 3 つの複雑なドメインにわたる 115 の失敗した軌跡で構成されています:
τ-bench:小売およびサービスタスクのための構造化された API ワークフロー。
Flash:現実世界のインシデント管理とシステムトラブルシューティング。
Magentic-One:一般化されたマルチエージェントシステムを用いた、オープンエンドな Web およびファイルタスク。
グラウンデッド・理論アプローチを用いて、これらのドメイン全体に一般化される 9 つのカテゴリからなる失敗分類体系を導出しました。この分類体系は、開発者が「計画遵守の失敗」(エージェントが自身のステップを無視した場合)と「新情報の発明」(ハルシネーション)を区別するのを助けます。
分類カテゴリの説明
計画遵守の失敗:必要なステップを無視した/計画上ない追加行動を行った
新情報の発明:追跡やツール出力に基づかない事実を変更した
不正な呼び出し:ツールの呼び出しが不備である/引数が欠落している/スキーマに適合しない
ツール出力の誤解釈:ツール出力を正しく読まず、誤った前提に基づいて行動した
意図と計画の不整合:ユーザーの目標や制約を読み違え、誤った計画を立てた
未指定のユーザー意図:必要な情報が利用できないため進行不能となった
サポートされていない意図:要求された作業を実行できる利用可能なツールが存在しない
ガードレール発動:セキュリティまたはアクセス制限により実行がブロックされた
システム障害:接続性やツールエンドポイントの失敗

ドメイン全体にわたる失敗密度の分析。Magentic-One などのマルチエージェント・システムでは、経路に複数のエラーが含まれることがよくありますが、AgentRx は最初の重要な違反を特定することに焦点を当てています。
主要な結果
実験において、AgentRx は既存の LLM ベースのプロンプト手法と比較して顕著な改善を示しました:
失敗の局所化精度で絶対値 23.6% の向上。
+22.9% の根本原因特定精度の向上。
監査可能なログを通じて失敗の「理由」を提供することで、AgentRx は開発者が試行錯誤的なプロンプトから脱却し、体系的なエージェント工学へと移行することを可能にします。
コミュニティへの参加:オープンソース化
私たちは、エージェントの信頼性が実世界での展開における前提条件であると信じています。これを支援するため、私たちは AgentRx フレームワークと完全な注釈付きベンチマークをオープンソース化しました。
論文を読む: AgentRx: 実行軌跡から AI エージェントの失敗を診断する
コードとデータを探す: https://aka.ms/AgentRx/Code (新しいタブで開く)
私たちは、研究者や開発者に対し、AgentRx を用いて自分たちのエージェントワークフローを診断し、増加しつつある失敗制約ライブラリへの貢献を呼びかけます。共に、単に強力であるだけでなく、監査可能で信頼性の高い AI エージェントを構築していきましょう。
謝辞
私たちは、このプロジェクトに貢献してくれた Avaljot Singh 氏と Suman Nath 氏に感謝いたします。
新しいタブで開く「体系的な AI エージェントのデバッグ: AgentRx フレームワークの紹介」という投稿は、Microsoft Research の記事として最初に掲載されました。
原文を表示
At a glance
Problem: Debugging AI agent failures is hard because trajectories are long, stochastic, and often multi-agent, so the true root cause gets buried.
Solution: AgentRx (opens in new tab) pinpoints the first unrecoverable (“critical failure”) step by synthesizing guarded, executable constraints from tool schemas and domain policies, then logging evidence-backed violations step-by-step.
Benchmark + taxonomy: We release AgentRx Benchmark (opens in new tab) with 115 manually annotated failed trajectories across τ-bench, Flash, and Magentic-One, plus a grounded nine-category failure taxonomy.
Results + release: AgentRx improves failure localization (+23.6%) and root-cause attribution (+22.9%) over prompting baselines, and we are open-sourcing the framework and dataset.
As AI agents transition from simple chatbots to autonomous systems capable of managing cloud incidents, navigating complex web interfaces, and executing multi-step API workflows, a new challenge has emerged: transparency.
When a human makes a mistake, we can usually trace the logic. But when an AI agent fails, perhaps by hallucinating a tool output or deviating from a security policy ten steps into a fifty-step task, identifying exactly where and why things went wrong is an arduous, manual process.
Today, we are excited to announce the open-source release of AgentRx (opens in new tab), an automated, domain-agnostic framework designed to pinpoint the “critical failure step” in agent trajectories. Alongside the framework, we are releasing the AgentRx Benchmark (opens in new tab), a dataset of 115 manually annotated failed trajectories to help the community build more transparent, resilient agentic systems.
The challenge: Why AI agents are hard to debug
Modern AI agents are often:
Long-horizon: They perform dozens of actions over extended periods.
Probabilistic: The same input might lead to different outputs, making reproduction difficult.
Multi-agent: Failures can be “passed” between agents, masking the original root cause.
Traditional success metrics (like “Did the task finish?”) don’t tell us enough. To build safe agents, we need to identify the exact moment a trajectory becomes unrecoverable and capture evidence for what went wrong at that step.
Introducing AgentRx: An automated diagnostic “prescription”
AgentRx (short for “Agent Diagnosis”) treats agent execution like a system trace that needs validation. Instead of relying on a single LLM to “guess” the error, AgentRx uses a structured, multi-stage pipeline:
Trajectory normalization: Heterogeneous logs from different domains are converted into a common intermediate representation.
Constraint synthesis: The framework automatically generates executable constraints based on tool schemas (e.g., “The API must return a valid JSON response”) and domain policies (e.g., “Do not delete data without user confirmation”).
Guarded evaluation: AgentRx evaluates constraints step-by-step, checking each constraint only when its guard condition applies, and produces an auditable validation log of evidence-backed violations.
LLM-based judging: Finally, an LLM judge uses the validation log and a grounded failure taxonomy to identify the Critical Failure Step—the first unrecoverable error.
imageThe AgentRx workflow: Given a failed trajectory, tool schemas, and domain policy, AgentRx synthesizes guarded constraints, evaluates them step-by-step to produce an auditable violation log with evidence, and uses an LLM judge to predict the critical failure step and root-cause category.
A New Benchmark for Agent Failures
To evaluate AgentRx, we developed a manually annotated benchmark consisting of 115 failed trajectories across three complex domains:
τ-bench: Structured API workflows for retail and service tasks.
Flash: Real-world incident management and system troubleshooting.
Magentic-One: Open-ended web and file tasks using a generalist multi-agent system.
Using a grounded-theory approach, we derived a nine-category failure taxonomy that generalizes across these domains. This taxonomy helps developers distinguish between a “Plan Adherence Failure” (where the agent ignored its own steps) and an “Invention of New Information” (hallucination).
Taxonomy CategoryDescription
Plan Adherence FailureIgnored required steps / did extra unplanned actions
Invention of New InformationAltered facts not grounded in trace/tool output
Invalid InvocationTool call malformed / missing args / schema-invalid
Misinterpretation of Tool OutputRead tool output incorrectly; acted on wrong assumptions
Intent–Plan MisalignmentMisread user goal/constraints and planned wrongly
Under-specified User IntentCould not proceed because required info wasn’t available
Intent Not SupportedNo available tool can do what’s being asked
Guardrails TriggeredExecution blocked by safety/access restrictions
System FailureConnectivity/tool endpoint failures
imageAnalysis of failure density across domains. In multi-agent systems like Magentic-One, trajectories often contain multiple errors, but AgentRx focuses on identifying the first critical breach.
Key Results
In our experiments, AgentRx demonstrated significant improvements over existing LLM-based prompting baselines:
+23.6% absolute improvement in failure localization accuracy.
+22.9% improvement in root-cause attribution.
By providing the “why” behind a failure through an auditable log, AgentRx allows developers to move beyond trial-and-error prompting and toward systematic agentic engineering.
Join the Community: Open Source Release
We believe that agent reliability is a prerequisite for real-world deployment. To support this, we are open sourcing the AgentRx framework and the complete annotated benchmark.
Read the Paper: AgentRx: Diagnosing AI Agent Failures from Execution Trajectories
Explore the Code & Data: https://aka.ms/AgentRx/Code (opens in new tab)
We invite researchers and developers to use AgentRx to diagnose their own agentic workflows and contribute to the growing library of failure constraints. Together, we can build AI agents that are not just powerful, but auditable, and reliable.
Acknowledgements
We would like to thank Avaljot Singh and Suman Nath for contributing to this project.
Opens in a new tabThe post Systematic debugging for AI agents: Introducing the AgentRx framework appeared first on Microsoft Research.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み